

Web, değerli verilerle dolu. İster satış, ister e-ticaret, ister pazar araştırması yapıyor olun; web scraping, potansiyel müşteri oluşturma, fiyat takibi ve rekabet analizi için adeta gizli bir silahtır. Ama işin asıl zorluğu burada başlıyor: Daha fazla işletme scraping’e yöneldikçe, web siteleri de eskisinden çok daha sert önlemler almaya başladı. Değişim artık çok net: 2024 ppc.land analizi en büyük 1.000 sitenin üçte birinden fazlasının artık yalnızca OpenAI’nin crawler’ını bile engellediğini gösterdi — ayrıca IP banları, CAPTCHA'lar ve browser fingerprinting gibi yöntemler artık istisna değil, standart haline geldi.
Python script'inizin 20 dakika boyunca sorunsuz çalışıp ardından bir anda 403 hataları duvarına çarptığını gördüyseniz, o hayal kırıklığını çok iyi bilirsiniz.
Yıllardır SaaS ve otomasyon alanında çalışıyorum; scraping projelerinin bir anda "vay be, bu çok kolay" aşamasından "neden her yerde engelleniyorum?" noktasına nasıl geldiğini bizzat gördüm. O yüzden gelin, pratik konuşalım: Python'da engellenmeden web scraping nasıl yapılır, bunu adım adım anlatalım; en iyi teknikleri ve kod örneklerini paylaşayım; ayrıca Thunderbit gibi Thunderbit yapay zekâ destekli alternatifleri ne zaman değerlendirmek gerektiğini de göstereyim. İster deneyimli bir Python kullanıcısı olun ister sadece idare ediyor olun, sonunda elinizde güvenilir ve engellenmeden veri çıkarmak için bir araç seti olacak.
Python'da Engellenmeden Web Scraping Nedir?
Özünde Python'da engellenmeden web scraping, sitelerin anti-bot savunmalarını tetiklemeden veri çıkarmak demektir. Python dünyasında bu, sadece bir requests.get() döngüsü yazmaktan fazlasıdır — sisteme karışmak, gerçek kullanıcıları taklit etmek ve tespit mekanizmalarından bir adım önde kalmak gerekir.
Neden Python? Python, web scraping için en popüler dildir — basit sözdizimi, devasa ekosistemi (requests, BeautifulSoup, Scrapy, Selenium gibi) ve hızlı betiklerden dağıtık tarayıcılara kadar uzanan esnekliği sayesinde. Ama popülerliğin bir bedeli var: birçok anti-bot sistemi artık Python tabanlı scraping kalıplarını tanıyacak şekilde ayarlanmış durumda.
Dolayısıyla güvenilir scraping yapmak istiyorsanız, temel seviyenin ötesine geçmeniz gerekir. Bu da sitelerin botları nasıl tespit ettiğini anlamak ve etik ya da yasal sınırları aşmadan onları nasıl aşabileceğinizi bilmek demektir.
Python Web Scraping Projelerinde Engellerden Kaçınmak Neden Önemli?
Engellenmek sadece teknik bir aksaklık değildir — tüm iş akışlarını altüst edebilir. Gelin bunu parçalara ayıralım:
| Kullanım Senaryosu | Engellenmenin Etkisi |
|---|---|
| Potansiyel Müşteri Oluşturma | Eksik veya güncel olmayan aday listeleri, kaybedilen satışlar |
| Fiyat Takibi | Rakip fiyat değişikliklerinin kaçırılması, kötü fiyatlandırma kararları |
| İçerik Toplama | Haber, yorum veya araştırma verilerinde boşluklar |
| Pazar İstihbaratı | Rakip veya sektör takibinde kör noktalar |
| Emlak İlanları | Hatalı veya güncelliğini yitirmiş mülk verileri, kaçan fırsatlar |
Bir scraper engellendiğinde yalnızca veri kaybetmiş olmazsınız — kaynak israf edersiniz, uyumluluk sorunlarıyla karşılaşma riskiniz artar ve eksik bilgiye dayanarak yanlış iş kararları alabilirsiniz. İşletmelerin %79'unun potansiyel müşteri oluşturma için web scraping'e güvendiği bir dünyada güvenilirlik her şeydir.
Web Siteleri Python Web Scraper'ları Nasıl Tespit Edip Engeller?
Web siteleri botları tespit etme konusunda oldukça zeki hale geldi. Karşılaşacağınız en yaygın anti-scraping savunmaları şunlardır (Medium, Bright Data):
- IP Adresi Kara Listeleme: Tek bir IP'den çok fazla istek mi geliyor? Engellenirsiniz.
- User-Agent ve Header Kontrolleri: Eksik veya genel header'lara sahip istekler (örneğin Python'un varsayılan
python-requests/2.25.1değeri) hemen dikkat çeker. - Rate Limiting: Kısa sürede çok fazla istek gönderirseniz hızınız düşürülür veya yasaklanırsınız.
- CAPTCHA'lar: Botların kolayca çözemediği "insan olduğunuzu kanıtlayın" bulmacaları.
- Davranış Analizi: Siteler, aynı butona aynı aralıklarla tıklamak gibi robotik kalıpları izler.
- Honeypot'lar: Yalnızca botların etkileşime gireceği gizli bağlantılar veya alanlar.
- Browser Fingerprinting: Otomasyon araçlarını tespit etmek için tarayıcınız ve cihazınız hakkında ayrıntılar toplanır.
- Çerez ve Oturum Takibi: Çerezleri veya oturumları doğru yönetmeyen botlar işaretlenir.
Bunu havaalanı güvenliği gibi düşünün: herkes gibi görünür, davranır ve hareket ederseniz rahatça geçersiniz. Ama trençkot ve güneş gözlüğüyle gelirseniz, fazladan soruya hazır olun.
Python'da Engellenmeden Web Scraping İçin Temel Teknikler
Gelelim asıl konuya: Python ile scraping yaparken engellerden gerçekten nasıl kaçınabilirsiniz? İşte her scraper'ın bilmesi gereken temel stratejiler:

Dönen Proxy'ler ve IP Adresleri
Neden önemli: Tüm istekleriniz aynı IP'den geliyorsa, IP banı için kolay bir hedef olursunuz. Dönen proxy'ler istekleri birden çok IP'ye dağıtarak sizi engellemeyi çok daha zor hale getirir.
Python'da nasıl yapılır:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...daha fazla proxy
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# yanıtı işle
Daha güvenilir sonuçlar için ücretli proxy hizmetleri (konut proxy'leri veya dönen proxy'ler gibi) kullanabilirsiniz (ScrapingBee).
User-Agent ve Özel Header Ayarlama
Neden önemli: Python'un varsayılan header'ları adeta "ben botum" diye bağırır. User-agent ve diğer header'ları ayarlayarak gerçek tarayıcıları taklit edin.
Örnek kod:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Ekstra gizlilik için user-agent'ları döndürün (ZenRows).
İstek Zamanlamasını ve Kalıplarını Rastgeleleştirme
Neden önemli: Botlar hızlı ve tahmin edilebilirdir; insanlar ise yavaş ve rastgele hareket eder. Aralara gecikme ekleyin ve gezinme biçiminizi çeşitlendirin.
Python ipucu:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # 2–7 saniye bekle
Selenium kullanıyorsanız tıklama yollarını ve kaydırma kalıplarını da rastgeleleştirebilirsiniz.
Çerezleri ve Oturumları Yönetme
Neden önemli: Birçok site, içeriğe erişmek için çerez veya oturum belirteçleri ister. Bunları görmezden gelen botlar engellenir.
Python'da nasıl yönetilir:
import requests
session = requests.Session()
response = session.get(url)
# session çerezleri otomatik olarak yönetir
Daha karmaşık akışlar için çerezleri yakalayıp yeniden kullanmak üzere Selenium kullanın.
Headless Tarayıcılarla İnsan Davranışını Taklit Etme
Neden önemli: Bazı siteler gerçek kullanıcı sinyali olarak JavaScript, fare hareketi veya kaydırma davranışını izler. Selenium veya Playwright gibi headless tarayıcılar bu eylemleri taklit edebilir.
Selenium örneği:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Bu yöntem, davranış analizi ve dinamik içeriği aşmanıza yardımcı olur (ScrapingBee).
İleri Seviye Stratejiler: Python'da CAPTCHA ve Honeypot'ları Aşmak
CAPTCHA'lar botları anında durdurmak için tasarlanmıştır. Bazı Python kütüphaneleri basit CAPTCHA'ları çözebilse de, ciddi scraper'ların çoğu bunları ücret karşılığında çözmek için 2Captcha veya Anti-Captcha gibi üçüncü taraf hizmetlere güvenir (Medium).
Örnek entegrasyon:
# 2Captcha API kullanımı için sözde kod
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Çözüm gelene kadar bekle, sonra isteğinle birlikte gönder
Honeypot'lar, yalnızca botların etkileşime gireceği gizli alanlar veya bağlantılardır. Gerçek bir tarayıcıda görünmeyen hiçbir şeye tıklamayın ya da hiçbir şey göndermeyin (ZenRows).
Python Kütüphaneleriyle Güçlü İstek Header'ları Tasarlama
User-agent dışında, daha iyi gizlenmek için başka header'ları da döndürebilir ve rastgeleleştirebilirsiniz (Referer, Accept, Origin gibi).
Scrapy ile:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Daha fazla header
}
}
Selenium ile: Header'ları ayarlamak için tarayıcı profilleri veya eklentiler kullanın ya da JavaScript üzerinden ekleyin.
Header listenizi güncel tutun — ilham almak için tarayıcı DevTools kullanarak gerçek tarayıcı isteklerini kopyalayın.
Geleneksel Python Scraping Yeterli Olmadığında: Anti-Bot Teknolojisinin Yükselişi
Gerçek şu: scraping popülerleştikçe anti-bot geliştirmeleri de artıyor. Büyük siteler artık yalnızca bariz botları değil, gelişmiş headless tarayıcıları ve dönen proxy'leri de engelliyor. Yapay zekâ destekli tespit, dinamik istek eşikleri ve browser fingerprinting, gelişmiş Python script'lerinin bile fark edilmeden kalmasını her zamankinden zor hale getiriyor (Medium).
Bazen kodunuz ne kadar akıllıca olursa olsun bir duvara çarparsınız. İşte tam o noktada farklı bir yaklaşımı düşünme zamanı gelir.
Thunderbit: Python Scraping'e Yapay Zekâ Destekli Bir Alternatif
Python sınırlarına ulaştığında, Thunderbit kod yazmadan kullanılabilen, iş kullanıcıları için tasarlanmış yapay zekâ destekli bir web scraper olarak devreye girer. Proxy'ler, header'lar ve CAPTCHA'larla uğraşmak yerine Thunderbit'in AI ajanı web sitesini okur, çıkarılması en uygun alanları önerir ve alt sayfa gezinmesinden veri dışa aktarıma kadar her şeyi halleder.
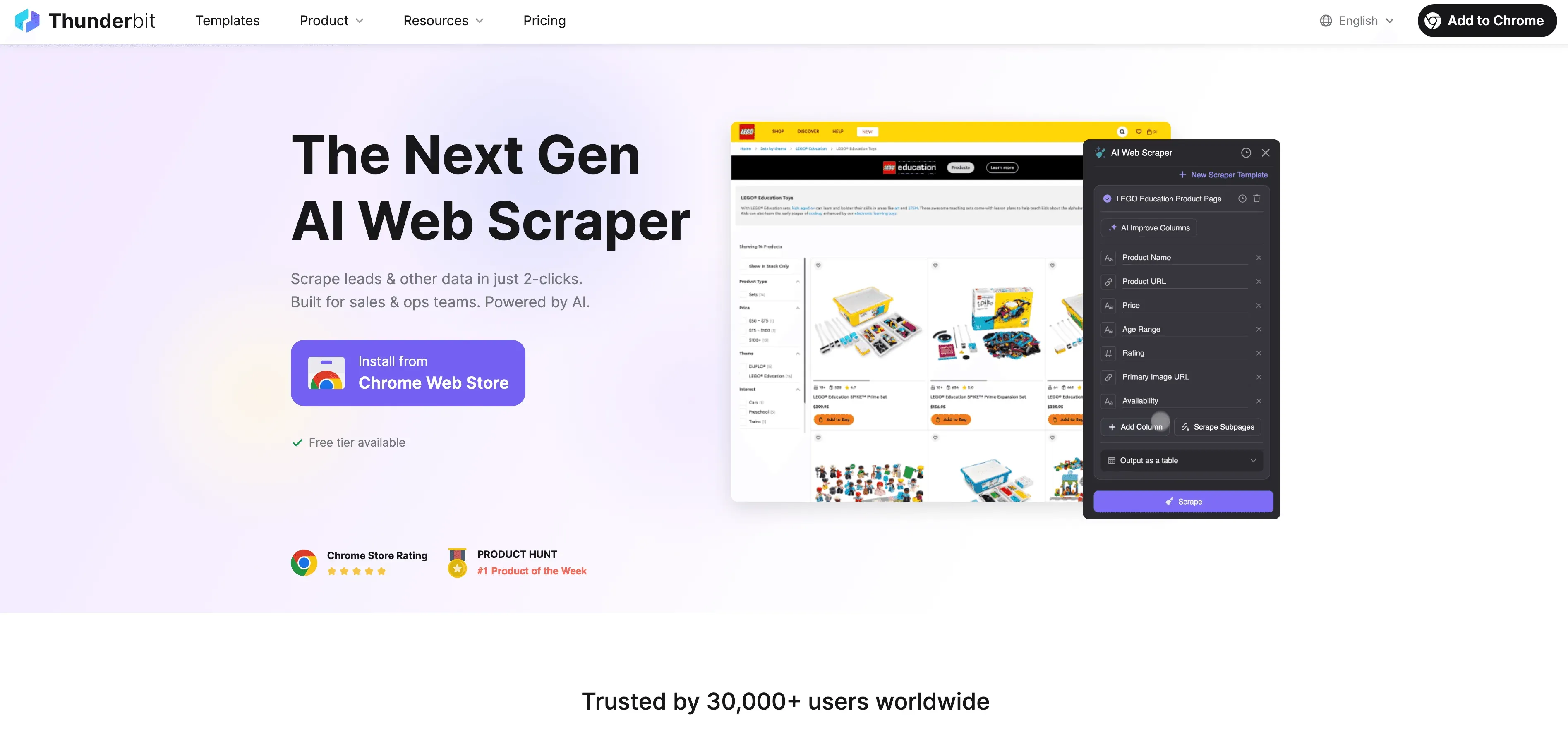
Thunderbit'i farklı kılan nedir?
- AI Alan Önerisi: "AI Suggest Fields"e tıklayın; Thunderbit sayfayı tarar, sütunları önerir ve hatta çıkarma talimatları üretir.
- Alt Sayfa Scraping: Thunderbit her alt sayfayı (ürün detayları veya LinkedIn profilleri gibi) ziyaret edip tablonuzu otomatik olarak zenginleştirebilir.
- Bulut veya Tarayıcı Scraping: En hızlı seçeneği seçin — herkese açık siteler için bulut, giriş gerektiren sayfalar için tarayıcı.
- Zamanlanmış Scraping: Bir kez ayarlayın ve unutun — Thunderbit zamanlı olarak scraping yapabilir, böylece veriniz her zaman güncel kalır.
- Anında Şablonlar: Popüler siteler için (Amazon, Zillow, Shopify vb.) Thunderbit tek tıkla şablonlar sunar — kurulum gerekmez.
- Ücretsiz Veri Dışa Aktarma: Excel, Google Sheets, Airtable veya Notion'a dışa aktarın — ek ücret yok.
Thunderbit'e dünya çapında 100.000'den fazla kullanıcı güveniyor ve tek satır kod yazmanız gerekmiyor.
Herhangi bir web sitesinden AI ile veri çıkarın Get Started Free
Thunderbit Kullanıcıların Engellerden Kaçınmasına ve Veri Çıkarmayı Otomatikleştirmesine Nasıl Yardımcı Olur?
Thunderbit'in AI'ı yalnızca insan davranışını taklit etmekle kalmaz — her siteye gerçek zamanlı olarak uyum sağlar ve engellenme riskini azaltır. İşte nasıl:
- AI düzen değişikliklerine uyum sağlar: Bir site tasarımını güncellediğinde daha az yeniden iş gerekir — her hafta selector'ları yeniden ayarlamak zorunda kalmazsınız.
- Alt sayfa ve sayfalama yönetimi: Thunderbit, bir insanın tıklayarak ilerlemesi gibi bağlantıları ve sayfalı listeleri sizin için takip eder.
- Toplu bulut scraping: İşleri dizüstü bilgisayarınız yerine Thunderbit'in bulutundan çalıştırın; planınıza göre toplu işlem boyutları belirlenir (güncel sınırlar için fiyatlandırma sayfasına bakın).
- Daha az bakım gereksinimi: Bir site değiştiğinde gece yarısı bozuk selector'ların peşinde siz koşmazsınız; AI sayfayı yeniden okur.
Daha derin bir inceleme için AI Kullanarak Herhangi Bir Web Sitesi Nasıl Scrape Edilir yazısına göz atın.
Python Scraping ve Thunderbit Karşılaştırması: Hangisini Seçmelisiniz?
Yan yana koyalım:
| Özellik | Python Scraping | Thunderbit |
|---|---|---|
| Kurulum Süresi | Orta-Yüksek (script'ler, proxy'ler vb.) | Düşük (2 tık, gerisini AI yapar) |
| Teknik Beceri | Kodlama gerekir | Kodlama gerekmez |
| Güvenilirlik | Değişken (kırılması kolay) | Yüksek (AI değişikliklere uyum sağlar) |
| Engellenme Riski | Orta-Yüksek | Düşük (AI kullanıcıyı taklit eder, uyum sağlar) |
| Ölçeklenebilirlik | Özel kod/bulut kurulumu ister | Yerleşik bulut/toplu scraping |
| Bakım | Sık (site değişiklikleri, engeller) | Minimum (AI otomatik ayarlar) |
| Dışa Aktarma Seçenekleri | Manuel (CSV, DB) | Doğrudan Sheets, Notion, Airtable, CSV'ye |
| Maliyet | Ücretsiz (ama zaman alıcı) | Ücretsiz plan, ölçek için ücretli planlar |
Python ne zaman kullanılmalı:
- Tam kontrol, özel mantık veya diğer Python iş akışlarıyla entegrasyon gerektiğinde.
- Anti-bot savunmaları zayıf siteleri scrape ederken.
Thunderbit ne zaman kullanılmalı:
- Hız, güvenilirlik ve sıfır kurulum istediğinizde.
- Karmaşık veya sık değişen siteleri scrape ederken.
- Proxy'ler, CAPTCHA'lar veya kodla uğraşmak istemediğinizde.
Thunderbit AI Web Scraper'ı Ücretsiz Deneyin
Adım Adım Rehber: Python'da Engellenmeden Web Scraping Kurulumu
Şimdi pratik bir örneğe geçelim: anti-blocking en iyi uygulamalarını uygulayarak örnek bir siteden ürün verisi scrape edelim.
1. Gerekli Kütüphaneleri Kurun
pip install requests beautifulsoup4 fake-useragent
2. Script'inizi Hazırlayın
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # URL'lerinizi buraya koyun
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Veriyi burada çıkarın
print(soup.title.text)
else:
print(f"{url} üzerinde engellendiniz veya hata oluştu: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Rastgele gecikme
3. Proxy Döndürme Ekleyin (İsteğe Bağlı)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Daha fazla proxy
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...kodun geri kalanı
4. Çerezleri ve Oturumları Yönetin
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...kodun geri kalanı
5. Sorun Giderme İpuçları
- Çok sayıda 403/429 hatası görüyorsanız isteklerinizi yavaşlatın veya yeni proxy'ler deneyin.
- CAPTCHA'ya takılıyorsanız Selenium veya CAPTCHA çözme hizmeti kullanmayı düşünün.
- Sitenin
robots.txtdosyasını ve kullanım şartlarını mutlaka kontrol edin.
Sonuç ve Temel Çıkarımlar
Python'da web scraping güçlüdür — ancak anti-bot teknolojisi geliştikçe engellenme riski her zaman vardır. Engellerden kaçınmanın en iyi yolu nedir? Teknik en iyi uygulamaları (dönen proxy'ler, akıllı header'lar, rastgele gecikmeler, oturum yönetimi ve headless tarayıcılar) site kurallarına ve etiğe duyarlı bir yaklaşımla birleştirmektir.
Ama bazen en iyi Python numaraları bile yeterli olmaz. İşte o noktada Thunderbit gibi AI araçları devreye girer — kod gerektirmez, düzen değişiklikleri ve sayfalama gibi katı script'leri zorlayan durumları ele almak için tasarlanmıştır ve akşamlarını bir Selenium işini başında bekleyerek geçirmek istemeyen iş kullanıcılarını hedefler.
Scraping'in ne kadar kolay olabileceğini görmek ister misiniz? Thunderbit'in Chrome Uzantısını indirin ve kendiniz deneyin — ya da daha fazla scraping ipucu ve eğitim için blogumuzu inceleyin.
SSS
1. Web siteleri neden Python web scraper'larını engeller?
Web siteleri verilerini korumak, sunucu aşırı yükünü önlemek ve otomatik botların hizmetlerini kötüye kullanmasını durdurmak için scraper'ları engeller. Python script'leri varsayılan header'lar kullanıyorsa, çerezleri yönetmiyorsa veya çok kısa sürede çok fazla istek gönderiyorsa kolayca fark edilir.
2. Python ile scraping yaparken engellenmemenin en etkili yolları nelerdir?
Dönen proxy'ler kullanın, gerçekçi user-agent ve header'lar ayarlayın, istek zamanlamasını rastgeleleştirin, çerezleri/oturumları yönetin ve Selenium veya Playwright gibi araçlarla insan davranışını taklit edin.
3. Thunderbit, Python script'lerine kıyasla engellerden kaçınmaya nasıl yardımcı olur?
Thunderbit, site düzenlerine uyum sağlamak, insan gibi gezinmeyi taklit etmek ve alt sayfalar ile sayfalamayı otomatik olarak yönetmek için AI kullanır. Sisteme karışarak ve yaklaşımını gerçek zamanlı güncelleyerek engellenme riskini azaltır — kodlama ya da proxy gerekmez.
4. Python scraping ile Thunderbit gibi bir AI aracı arasında ne zaman seçim yapmalıyım?
Özel mantık, diğer Python kodlarıyla entegrasyon veya basit siteleri scrape etme ihtiyacınız olduğunda Python kullanın. Hızlı, güvenilir ve ölçeklenebilir scraping için Thunderbit'i kullanın — özellikle siteler karmaşıksa, sık değişiyorsa veya script'leri agresif biçimde engelliyorsa.
5. Web scraping yasal mı?
Web scraping, herkese açık veriler için yasal olabilir; ancak her sitenin kullanım şartlarına, gizlilik politikalarına ve ilgili yasalara uymanız gerekir. Hassas veya özel verileri asla scrape etmeyin ve her zaman etik ve sorumlu şekilde hareket edin.
Daha akıllı scraping yapmaya hazır mısınız? Thunderbit'i deneyin ve engelleri geride bırakın.
Daha Fazla Bilgi:
- Python ile Google News Scraping: Adım Adım Rehber
- Python Kullanarak Best Buy için Fiyat Takip Aracı Oluşturma
- Engellenmeden Web Scraping Yapmanın 14 Yolu
- Web Scraping Yaparken Engellenmeme İçin 10 En İyi İpucu
AI Web Scraper'ı Deneyin Get Started Free




