
Terminali açıp tek bir komut yazdığında, ham web verisinin ekrana Matrix’in perdesini aralıyormuşsun gibi akması var ya… O his gerçekten eskimeyen cinsten. Geliştiriciler ve teknik kullanıcılar için tam anlamıyla böyle bir “sihirli değnek”: Gösterişsiz bir komut satırı aracı ama bulut sunuculardan akıllı buzdolabına kadar milyarlarca cihazda sessiz sedasız iş görüyor. 2026’da bile ortalık no-code ve yapay zekâ destekli kazıma araçlarıyla doluyken, curl ile web kazıma hâlâ hız, kontrol ve betiklenebilirlik isteyenlerin gözdesi olmaya devam ediyor.
 Yıllardır otomasyon araçları geliştiriyorum; ekiplerin web verisiyle boğuştuğu anlarda da hep yanlarındayım. Bir sayfayı hızlıca çekmek, bir API’yi debug etmek ya da bir kazıma akışını “hızlı prototip” olarak kurmak gerektiğinde elim hâlâ cURL’e gidiyor. Bu rehberde, hem temelleri hem de profesyonel tüyoları içeren bir curl web kazıma eğitimini adım adım anlatacağım: gerçek komut örnekleri, pratik öneriler ve cURL’ün nerede parladığı (ve nerede duvara tosladığı) konusunda net bir değerlendirme ile. Komut satırına hiç girmek istemeyen bir iş kullanıcısıysan da, (yapay zekâ destekli web kazıyıcımız) ile “şu veriye ihtiyacım var” noktasından “al, e-tablon hazır” noktasına iki tıkla nasıl geçebileceğini göstereceğim—kod yazmadan.
Yıllardır otomasyon araçları geliştiriyorum; ekiplerin web verisiyle boğuştuğu anlarda da hep yanlarındayım. Bir sayfayı hızlıca çekmek, bir API’yi debug etmek ya da bir kazıma akışını “hızlı prototip” olarak kurmak gerektiğinde elim hâlâ cURL’e gidiyor. Bu rehberde, hem temelleri hem de profesyonel tüyoları içeren bir curl web kazıma eğitimini adım adım anlatacağım: gerçek komut örnekleri, pratik öneriler ve cURL’ün nerede parladığı (ve nerede duvara tosladığı) konusunda net bir değerlendirme ile. Komut satırına hiç girmek istemeyen bir iş kullanıcısıysan da, (yapay zekâ destekli web kazıyıcımız) ile “şu veriye ihtiyacım var” noktasından “al, e-tablon hazır” noktasına iki tıkla nasıl geçebileceğini göstereceğim—kod yazmadan.
Hadi başlayalım: cURL’ün 2025’te web kazıma için neden hâlâ geçerli olduğunu, nasıl verimli kullanılacağını ve ne zaman daha güçlü bir çözüme geçmenin mantıklı olduğunu birlikte görelim.
cURL Nedir? cURL ile Web Kazımanın Temeli
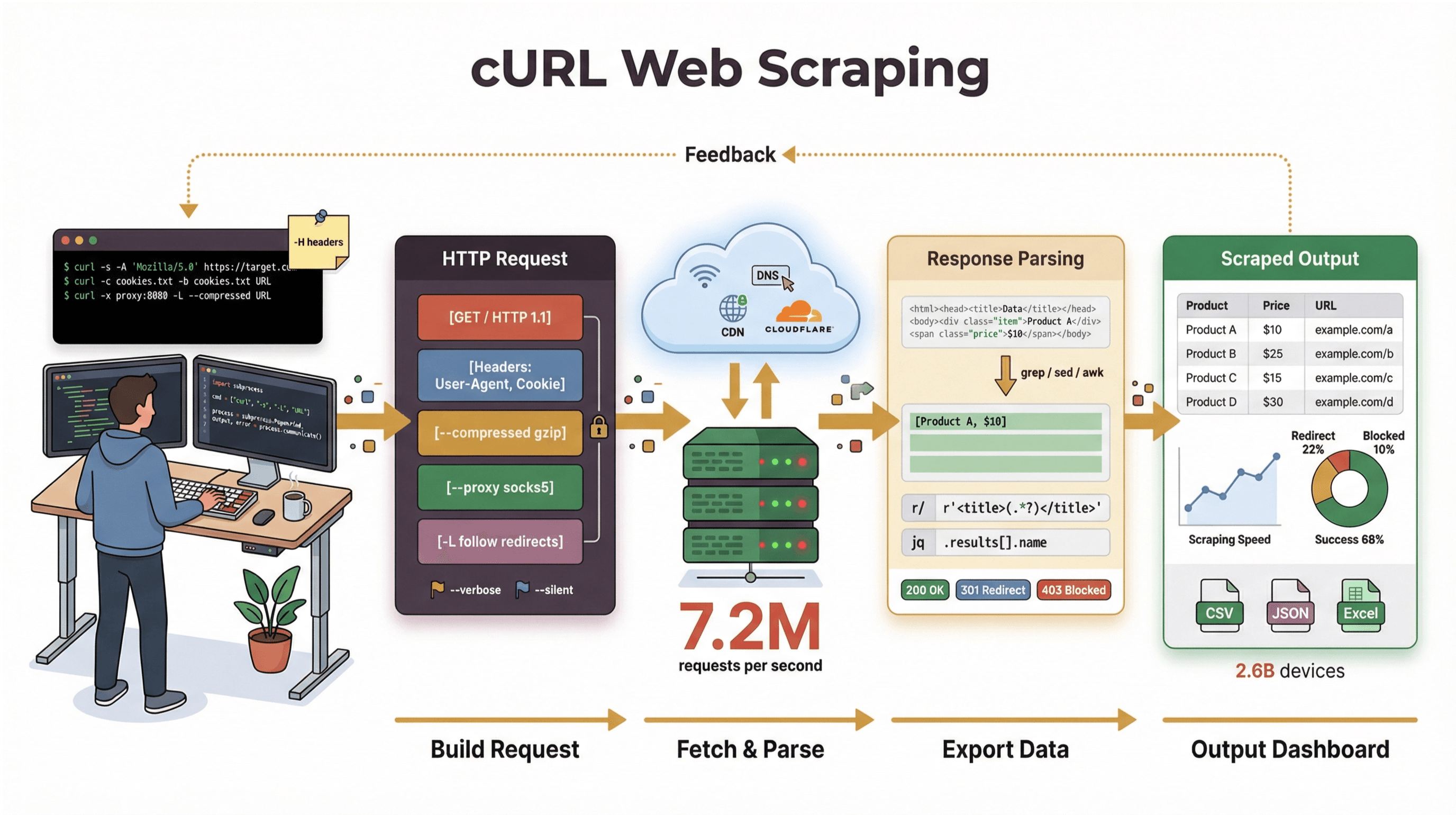
En basit tanımıyla , URL’ler üzerinden veri transferi yapmaya yarayan bir komut satırı aracı ve kütüphanesidir. Neredeyse 30 yıldır hayatımızda (evet, cidden) ve her yerde: işletim sistemlerine gömülü, betikleri çalıştırıyor ve veri aktarımını sessizce sırtlıyor. Bir web sayfasını çekmek, bir API’yi test etmek ya da dosya indirmek için hızlı bir komut çalıştırdıysan, büyük ihtimalle cURL’e dokunmuşsundur.
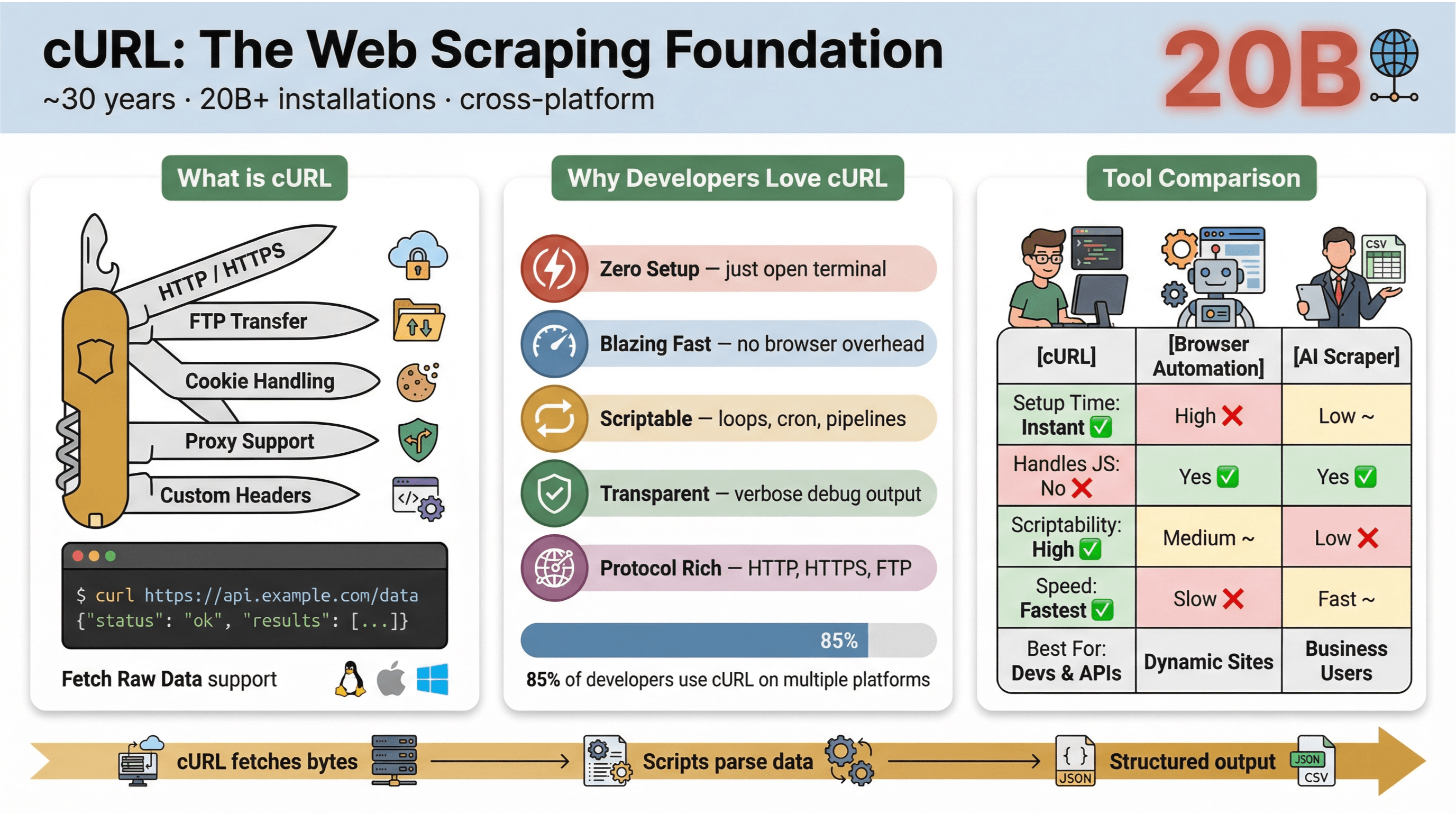 cURL’ü web kazıma tarafında bu kadar popüler yapan şeyler şunlar:
cURL’ü web kazıma tarafında bu kadar popüler yapan şeyler şunlar:
- Hafif ve platform bağımsız: Linux, macOS, Windows ve hatta gömülü cihazlarda çalışır.
- Protokol desteği: HTTP, HTTPS, FTP ve daha fazlasını destekler.
- Betiklenebilir: Otomasyon, cron işleri ve “yapıştırıcı” kodlar için biçilmiş kaftan.
- Etkileşim gerektirmez: Baştan sona etkileşimsiz kullanım için tasarlanmıştır—toplu işler ve pipeline’lar için çok uygundur.
Ama net konuşalım: cURL’ün ana işi ham veriyi çekmektir—HTML, JSON, görsel… ne istersen. Bu veriyi senin yerine ayrıştırmaz, render etmez ya da yapılandırmaz. cURL’ü web kazımanın “ilk kilometresi” gibi düşün: baytları getirir; bunu yapılandırılmış bilgiye çevirmek için başka araçlara (Python betikleri, grep/sed/awk ya da bir AI web scraper gibi) ihtiyaç duyarsın.
Resmî kaynak istersen göz atabilirsin.
Web Kazıma İçin Neden cURL? (cURL web kazıma eğitimi)
Peki geliştiriciler ve teknik kullanıcılar, bu kadar yeni araç varken neden web kazıma için dönüp dolaşıp cURL’e geliyor? cURL’ü öne çıkaran başlıca sebepler:
- Minimum kurulum: Kurulum yok, bağımlılık yok—terminali aç, başla.
- Hız: Tarayıcının açılmasını beklemeden veriyi anında çekersin.
- Betiklenebilirlik: URL’ler üzerinde döngü kurmak, istekleri otomatikleştirmek ve komutları zincirlemek kolaydır.
- Protokol ve özellik zenginliği: Çerezler, proxy, yönlendirmeler, özel header’lar ve daha fazlası.
- Şeffaflık: Verbose/debug çıktılarıyla ne olduğunu adım adım görürsün.
, katılımcıların %85’inden fazlası cURL komut satırı aracını kullandığını söylüyor ve neredeyse tamamı birden fazla platformda kullandığını belirtiyor. Hâlâ HTTP istekleri, hızlı veri çekme ve sorun giderme için tam bir İsviçre çakısı.
cURL ile diğer kazıma yöntemlerinin hızlı bir karşılaştırması:
| Özellik | cURL | Tarayıcı Otomasyonu (örn. Selenium) | AI Web Scraper (örn. Thunderbit) |
|---|---|---|---|
| Kurulum Süresi | Anında | Yüksek | Düşük |
| Betiklenebilirlik | Yüksek | Orta | Düşük (kod gerekmez) |
| JavaScript Desteği | Hayır | Evet | Evet (Thunderbit: tarayıcı üzerinden) |
| Çerez/Oturum Desteği | Manuel | Otomatik | Otomatik |
| Veriyi Yapılandırma | Manuel (sonradan parse) | Manuel (sonradan parse) | AI/Şablon tabanlı |
| En Uygun Olduğu Durum | Geliştiriciler, hızlı çekimler | Karmaşık, dinamik siteler | İş kullanıcıları, yapılandırılmış dışa aktarma |
Özet: Statik sayfalar, API’ler ve basit otomasyonlar için cURL gerçekten çok güçlü. Ama iş HTML ayrıştırmaya, JavaScript’e ya da yapılandırılmış çıktıya (tablo/e-tablo) gelince daha “özel” bir araca geçmek istersin.
Başlangıç: Temel cURL Web Kazıma Komut Örnekleri
Şimdi işin pratiğine girelim. Aşağıda cURL ile temel web kazıma işlerini adım adım nasıl yapacağını göreceksin.
cURL ile Ham HTML Çekme
En temel senaryo: Bir sayfanın HTML’ini almak.
1curl https://books.toscrape.com/Bu komut, web kazıma için hazırlanmış herkese açık demo site ana sayfasını çeker. Terminalde ham HTML’i görürsün—<title> gibi etiketleri ya da “In stock” gibi parçaları arayabilirsin.
Çıktıyı Dosyaya Kaydetme
HTML’i sonra ayrıştırmak için saklamak mı istiyorsun? -o bayrağı tam bunun için:
1curl -o page.html https://books.toscrape.com/Artık elinde tam HTML içeriğini barındıran page.html dosyası var. Bu, başka araçlarla analiz/parse yapmak için ideal.
cURL ile POST İstekleri Gönderme
Form göndermen veya bir API ile konuşman mı gerekiyor? POST için -d bayrağını kullan. HTTP testleri için tasarlanmış ile örnek:
1curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"Gönderdiğin veriyi sana geri yansıtan bir JSON yanıt alırsın—test ve prototipleme için aşırı kullanışlı.
Header’ları İnceleme ve Debug
Bazen yanıt header’larını görmek ya da isteği debug etmek istersin:
-
Sadece header (HEAD isteği):
1curl -I https://books.toscrape.com/ -
Header + body birlikte:
1curl -i https://httpbin.org/get -
Verbose/debug çıktısı:
1curl -v https://books.toscrape.com/
Bu bayraklar, perde arkasında neler döndüğünü anlamana yardım eder—sorun giderme için kritik.
Komutlar için hızlı referans tablosu:
| İş | Komut Örneği | Notlar |
|---|---|---|
| HTML çekme | curl URL | HTML’i terminale basar |
| Dosyaya kaydetme | curl -o file.html URL | Çıktıyı dosyaya yazar |
| Header inceleme | curl -I URL veya curl -i URL | -I sadece HEAD, -i header’ı body ile birlikte verir |
| POST form verisi | curl -d "a=1&b=2" URL | Form-encoded veri gönderir |
| İstek/yanıt debug | curl -v URL | Ayrıntılı istek/yanıt bilgisi gösterir |
Daha fazla örnek için bakabilirsin.
Seviye Atlama: cURL ile İleri Düzey Web Kazıma (cURL ile web kazıma)
Temellere alışınca, cURL’ün daha “dişli” kazıma senaryolarında da işe yarayan güçlü özellikleri var.
Çerezler ve Oturumlar
Birçok site, giriş oturumunu sürdürmek veya kullanıcıyı takip etmek için çerez ister. cURL ile çerezleri kaydedip sonraki isteklerde tekrar kullanabilirsin:
1# Giriş sonrası çerezleri kaydet
2curl -c cookies.txt https://example.com/login
3# Sonraki isteklerde çerezleri kullan
4curl -b cookies.txt https://example.com/accountBöylece tarayıcı oturumunu taklit edebilirsin (tabii JavaScript tabanlı bir engel yoksa).
User-Agent Taklidi ve Özel Header’lar
Bazı siteler User-Agent veya header’lara göre farklı içerik döndürür. Varsayılan olarak cURL kendini “curl/VERSION” diye tanıtır; bu da engellenmeye veya farklı içerik gelmesine yol açabilir. Tarayıcı gibi görünmek için:
1curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/Dil tercihi gibi özel header’lar da ekleyebilirsin:
1curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/Böylece gerçek bir tarayıcının gördüğüne daha yakın içerik alırsın.
Web Kazıma İçin Proxy Kullanımı
İstekleri bir proxy üzerinden geçirmek mi istiyorsun (coğrafi test veya IP engellerinden kaçınma gibi)? -x bayrağını kullan:
1curl -x http://proxy.example.org:4321 https://remote.example.org/Proxy kullanırken sitenin kullanım şartlarına uygun ve sorumlu davranmayı unutma.
Çok Sayfalı Kazımayı Otomatikleştirme
Sayfalama (pagination) olan listelerden birden fazla sayfa çekmek mi istiyorsun? Basit bir shell döngüsü işini görür:
1for p in $(seq 2 5); do
2 curl -s -o "books-page-${p}.html" \
3 "https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
4 sleep 1
5doneBu, Books to Scrape kataloğunun 2–5. sayfalarını indirir ve her birini ayrı dosyaya kaydeder. (1. sayfa ana sayfadır.)
cURL ile Web Kazımanın Sınırları: Bilmeniz Gerekenler
cURL’ü seviyorum ama her işin ilacı değil. Zayıf kaldığı yerler şunlar:
- JavaScript çalıştırmaz: İçeriği render etmek veya bot engellerini aşmak için JavaScript gereken sayfalarda cURL yetersiz kalır ().
- Ayrıştırma tamamen sana kalır: Ham HTML/JSON alırsın; parse için ek betik/araç gerekir.
- Oturum yönetimi sınırlı: Karmaşık girişler, token’lar, çok adımlı formlar hızla çetrefilleşir.
- Yerleşik yapılandırma yok: cURL sayfayı satır/sütun/tablo/e-tablo formatına dönüştürmez.
- Bot tespitine açık: Birçok site gelişmiş bot savunmaları (JavaScript, fingerprinting, CAPTCHA) kullanır; cURL bunları aşamaz ().
Hızlı karşılaştırma:
| Sınırlama | Sadece cURL | Modern Kazıma Araçları (örn. Thunderbit) |
|---|---|---|
| JavaScript Desteği | Hayır | Evet |
| Veriyi Yapılandırma | Manuel | Otomatik (AI/Şablon) |
| Oturum Yönetimi | Manuel | Otomatik |
| Anti-bot Aşma | Sınırlı | Gelişmiş (tarayıcı tabanlı/AI) |
| Kullanım Kolaylığı | Teknik | Teknik olmayan kullanıcıya uygun |
Statik sayfalar ve API’ler için cURL şahane. Daha dinamik veya korumalı senaryolarda ise araç zincirinde bir üst vitese geçmek gerekir.
Teknik Olmayan Kullanıcılar İçin Thunderbit mi cURL mü? En İyi Yaklaşım
Şimdi tarafına gelelim: Yapay zekâ destekli web kazıyıcı Chrome eklentimiz. Satış, pazarlama veya operasyon ekiplerindeysen ve komut satırına girmeden bir curl web sitesi yerine doğrudan bir web sitesinden veriyi Excel’e, Google Sheets’e veya Notion’a aktarmak istiyorsan, Thunderbit tam “işini görür” kategorisinde.
Thunderbit ile cURL karşılaştırması:
| Özellik | cURL | Thunderbit |
|---|---|---|
| Arayüz | Komut satırı | Tıkla-çalıştır (Chrome eklentisi) |
| AI Alan Önerisi | Hayır | Evet (AI sayfayı okur, sütun önerir) |
| Sayfalama/Alt sayfalar | Manuel betik | Otomatik (AI algılar ve çeker) |
| Dışa aktarma | Manuel (parse + kaydet) | Doğrudan Excel, Google Sheets, Notion, Airtable |
| JavaScript/Korumalı sayfalar | Hayır | Evet (tarayıcı tabanlı kazıma) |
| No-code | Hayır (betik gerekir) | Evet (herkes kullanabilir) |
| Ücretsiz katman | Her zaman ücretsiz | 6 sayfaya kadar ücretsiz (deneme artışıyla 10) |
Thunderbit’te eklentiyi açıp “AI Suggest Fields”e tıklarsın; AI hangi verilerin çıkarılacağını kendisi önerir. Tabloları, listeleri, ürün detaylarını kazıyabilir; hatta alt sayfalara otomatik girip veriyi toplayabilir. Sonra veriyi doğrudan iş araçlarına aktarabilirsin—parse yok, uğraş yok.
Thunderbit’e dünya genelinde güveniyor; özellikle satış, e-ticaret ve emlak ekipleri hızlı ve yapılandırılmış veriye ihtiyaç duyduğunda çok tercih ediliyor.
Denemek ister misin? .
cURL ve Thunderbit’i Birlikte Kullanmak: Esnek Web Kazıma Stratejileri
Teknik bir kullanıcıysan tek bir araca mahkûm değilsin. Hatta birçok ekip maksimum esneklik için cURL ve Thunderbit’i birlikte kullanıyor:
- cURL ile prototip: Endpoint’leri hızlıca test et, header’ları incele, sitenin nasıl yanıt verdiğini çöz.
- Thunderbit ile ölçekle: Yapılandırılmış veri, çok sayfalı kazıma veya tekrarlanabilir bir akış gerektiğinde Thunderbit’e geç.
Pazar araştırması için örnek bir akış:
- cURL ile birkaç sayfa çekip HTML yapısını incele.
- İstediğin alanları belirle (örn. ürün adı, fiyat, yorum).
- Thunderbit’i aç, “AI Suggest Fields”e tıkla; AI kazıyıcıyı kursun.
- Tüm sayfaları (alt sayfalar ve sayfalama dahil) kazı ve Google Sheets’e aktar.
- Veriyi analiz et, paylaş ve aksiyon al—manuel parse gerekmez.
Hızlı karar tablosu:
| Senaryo | cURL kullan | Thunderbit kullan | İkisini de kullan |
|---|---|---|---|
| Hızlı API veya statik sayfa çekme | ✅ | ||
| E-tabloda yapılandırılmış veri ihtiyacı | ✅ | ||
| Header/çerez debug | ✅ | ||
| Dinamik/JS ağırlıklı sayfalar | ✅ | ||
| Tekrarlanabilir, no-code iş akışı | ✅ | ||
| Prototipleyip sonra ölçekleme | ✅ | ✅ | Hibrit akış |
cURL ile Web Kazımada Yaygın Zorluklar ve Tuzaklar
cURL ile gaza basmadan önce, gerçek hayatta karşına çıkabilecek zorluklara bir bakalım:
- Anti-bot sistemleri: JavaScript challenge’ları, CAPTCHA, fingerprinting gibi savunmaları cURL aşamaz ().
- Veri kalitesi sorunları: HTML değişiklikleri, eksik alanlar veya tutarsız düzenler betiklerini bozabilir.
- Bakım yükü: Site her değiştiğinde parse mantığını güncellemen gerekir.
- Hukuki ve uyumluluk riskleri: Kazımadan önce kullanım şartlarını, robots.txt’yi ve ilgili mevzuatı kontrol et. Verinin herkese açık olması, serbestçe kullanılabileceği anlamına gelmez (, ).
- Ölçekleme sınırları: Küçük işler için cURL mükemmel; büyük ölçekte proxy, rate limit ve hata yönetimini senin kurgulaman gerekir.
Sorun giderme ve uyum için ipuçları:
- İzinli veya demo sitelerle başla (örn. ).
- Rate limit’lere saygı göster—endpoint’leri bombardımana tutma.
- Hukuki dayanağın yoksa kişisel veri kazımaktan uzak dur.
- JavaScript veya CAPTCHA duvarına takılırsan Thunderbit gibi tarayıcı tabanlı bir araca geç.
Adım Adım Özet: cURL ile Web Sitelerinden Veri Çekme
cURL ile web kazıma için hızlı kontrol listesi:
- Hedef URL(ler)i belirleyin: Statik sayfa veya API endpoint’i ile başlayın.
- Sayfayı çekin:
curl URL - Çıktıyı dosyaya kaydedin:
curl -o file.html URL - Header/debug inceleyin:
curl -I URL,curl -v URL - POST verisi gönderin:
curl -d "a=1&b=2" URL - Çerez/oturum yönetin:
curl -c cookies.txt ...,curl -b cookies.txt ... - Özel header/User-Agent ayarlayın:
curl -A "..." -H "..." URL - Yönlendirmeleri takip edin:
curl -L URL - Proxy kullanın (gerekirse):
curl -x proxy:port URL - Çok sayfalı kazımayı otomatikleştirin: Shell döngüleri veya betikler.
- Veriyi ayrıştırıp yapılandırın: Gerektikçe ek araç/betik kullanın.
- Yapılandırılmış, no-code kazıma veya dinamik sayfalar için Thunderbit’e geçin.
Sonuç ve Öne Çıkanlar: Doğru Web Kazıma Aracını Seçmek
cURL ile web kazıma, 2026’da da teknik kullanıcılar için sağlam bir yetenek—özellikle hızlı veri çekme, prototipleme ve otomasyon tarafında. cURL’ün hızı, betiklenebilirliği ve her yerde bulunması onu her geliştiricinin araç çantasının demirbaşı yapıyor. Ama web daha dinamik ve daha korumalı hale geldikçe, bir de iş kullanıcıları kod yazmadan yapılandırılmış veri isteyince, gibi araçlar “mümkün olanı” yeniden tanımlıyor.
Öne çıkanlar:
- Statik sayfalar, API’ler ve hızlı prototipleme için cURL kullan—özellikle tam kontrol istiyorsan.
- Yapılandırılmış veri gerektiğinde, dinamik/JavaScript ağırlıklı sayfalarla çalışırken veya no-code, iş odaklı bir akış istediğinde Thunderbit’e (veya benzeri AI web scraper’lara) geç.
- En yüksek esneklik için ikisini birleştir: cURL ile prototip, Thunderbit ile ölçek ve yapılandırma.
- Sorumlu kazı—site şartlarına, rate limit’lere ve hukuki sınırlara uy.
Web kazımanın ne kadar kolay olabileceğini görmek ister misin? ve yapay zekâ destekli veri çıkarımını kendin gör. Daha derine inmek için sayfasında daha fazla eğitim, ipucu ve sektör içgörüsü bulabilirsin. Şunlar da ilgini çekebilir:
İyi kazımalar—verin her zaman temiz, düzenli ve bir komut (ya da tık) kadar yakın olsun.
SSS
1. cURL, JavaScript ile render edilen web sayfalarını kazıyabilir mi?
Hayır. cURL JavaScript çalıştırmaz; sunucunun gönderdiği ham HTML’i indirir. Bir sayfa içeriği göstermek veya bot engellerini aşmak için JavaScript’e ihtiyaç duyuyorsa, cURL veriye erişemez. Bu tür durumlarda gibi tarayıcı tabanlı araçları kullanın.
2. cURL çıktısını doğrudan dosyaya nasıl kaydederim?
-o bayrağını kullanın: curl -o filename.html URL. Böylece yanıt gövdesi terminale basılmak yerine dosyaya yazılır.
3. Web kazıma için cURL ile Thunderbit arasındaki fark nedir?
cURL, ham web verisini çekmeye yarayan bir komut satırı aracıdır—teknik kullanıcılar ve otomasyon için idealdir. Thunderbit ise, herhangi bir web sitesinden yapılandırılmış veri çıkarmak, dinamik sayfaları yönetmek ve Excel/Google Sheets gibi araçlara doğrudan aktarmak isteyen iş kullanıcıları için tasarlanmış yapay zekâ destekli bir Chrome eklentisidir—kod gerekmez.
4. cURL ile web sitesi kazımak yasal mı?
ABD’de yakın dönem mahkeme kararları sonrası herkese açık veriyi kazımak genel olarak yasal kabul edilse de, her zaman sitenin kullanım şartlarını, robots.txt’yi ve ilgili mevzuatı kontrol edin. İzin olmadan kişisel veya korumalı veriyi kazımaktan kaçının; rate limit’lere ve etik ilkelere uyun (, ).
5. Ne zaman cURL’den Thunderbit gibi daha gelişmiş bir araca geçmeliyim?
Dinamik/JavaScript ağırlıklı sayfaları kazımanız gerekiyorsa, veriyi e-tabloda yapılandırılmış şekilde istiyorsanız veya no-code bir iş akışını tercih ediyorsanız Thunderbit daha doğru seçimdir. cURL’ü hızlı teknik işler için; Thunderbit’i iş odaklı, tekrarlanabilir veri çıkarımı için kullanın.
Daha fazla web kazıma ipucu ve eğitim için sayfasını ziyaret edin veya göz atın.