Web kazıma yasal mı? Girişimcilerden pazarlamacılara ve veri meraklılarına her hafta duyduğum milyon dolarlık soru bu.
Artık tüm internet trafiğinin %51’i botlardan geliyor—otomatik trafiğin ilk kez insan faaliyetini geçtiği an—and bunun önemli bir kısmı iş zekâsı, satış ve AI eğitimi için yapılan web kazımadan oluşuyor. Bu yüzden herkesin hukuki sınırların nerede başladığını ve bittiğini anlamaya çalışması hiç şaşırtıcı değil.
Bir gün, kamuya açık verilerin kazınmasının serbest olduğuna dair bir mahkeme kararını manşette görürsünüz. Ertesi gün düzenleyiciler sosyal medyadan "hukuka aykırı" veri toplama konusunda uyarı yapar. Bu kafa karıştırıcı; hele benim gibi günlerini bünyesinde AI web kazıma araçları geliştirmekle geçirenler için bile.
Peki, web kazıma yasal mı? Cevap basit bir evet ya da hayır değil. Ne kazıdığınıza, nereden kazıdığınıza, veriyi nasıl kullandığınıza ve ülkenizdeki yasanın ne dediğine bağlı.
Bu derinlemesine incelemede hukuki tabloyu parçalara ayıracak, yaygın efsaneleri çürütecek ve uyumlu kalmak için pratik ipuçları paylaşacağım—ister tek başına çalışan bir kurucu olun ister Fortune 500 ölçeğinde bir veri ekibi.
Web Kazıma ve Hukuk: Net Bir Çizgi Var mı?
Tek cümlelik bir cevap umuyorsanız sizi biraz zaman kazandırayım: hukuk, web kazıma için parlak ve net bir çizgi çizmiş değil.
Bunun yerine, üst üste binen kurallardan oluşan bir yama işi var—veri sahipliği, gizlilik, fikrî mülkiyet, siber saldırı karşıtı yasalar ve meşhur Kullanım Şartları (ToS). Bunların her biri devreye girebilir; cevap çoğu zaman sizin özel senaryonuza bağlıdır ().
Üç ana hukuki başlığı şöyle ayırabiliriz:
- Veri Sahipliği: Genel olarak, gerçekler ve kamuya açık bilgiler (fiyatlar veya telefon numaraları gibi) telif hakkıyla korunmaz. Ancak yaratıcı içerikler (makaleler, görseller) ve tescilli veritabanları korunabilir—özellikle de "veritabanı haklarının" geçerli olduğu AB’de ().
- Gizlilik: Modern gizlilik yasaları (Avrupa’daki GDPR, Çin’deki PIPL gibi) kişisel veriyi, kamuya açık olsa bile, düzenlemeye tabi bir varlık olarak görür. İsimleri, e-postaları veya sosyal profilleri hukuki dayanak olmadan kazımak başınızı derde sokabilir ().
- Sözleşmeler (Kullanım Şartları): Birçok site ToS içinde kazımayı açıkça yasaklar. ToS yasa değildir, ama mahkemeler onları bağlayıcı sözleşmeler olarak değerlendirebilir. Bunları ihlal etmek dava açılmasına yol açabilir; bazı durumlarda teknik engelleri aşarsanız siber saldırı karşıtı yasalar da devreye girebilir ().
Yani, web kazıma yasal mı? Bazen evet, bazen hayır, çoğu zaman da "duruma bağlı." Ayrıntılarda şeytan gizli.
Hukuki Bakışları Karşılaştırmak: ABD, AB, Birleşik Krallık, Çin
Büyük bölgelerin web kazımaya nasıl yaklaştığını gösteren hızlı bir tablo:
This paragraph contains content that cannot be parsed and has been skipped.
(, )
Web Kazıma Yasal mı? Dikkate Alınması Gereken Temel Hukuki Faktörler
Peki, bir kazıma projesinin yasal mı yoksa riskli mi olduğunu gerçekte ne belirler? İşte ana faktörler:
- Kamuya Açık Veri vs. Özel Veri: Açık web’de herkesin görebildiği verileri kazımak genelde daha güvenlidir. Peki giriş, ücret duvarı veya teknik bir engelin arkasındaki herhangi bir şey? Bu büyük olasılıkla yasa dışıdır ().
- Verinin Niteliği: Kişisel veriler (isimler, e-postalar, profiller) gizlilik yasalarını tetikler. Telifli içerikler (makaleler, görseller) topluca kopyalanamaz. Saf gerçekler (fiyatlar, hava durumu) ise çoğu zaman serbesttir ().
- Amaçlanan Kullanım: İç analiz veya araştırma, kazınmış veriyi yeniden yayımlamaya ya da satmaya göre daha toleranslı değerlendirilir. Kazınmış veriyi kaynağa doğrudan rakip olacak şekilde kullanmak? Bu, davayı davet etmektir ().
- Web Sitesi Kurallarına Uyum: robots.txt ve ToS’u mutlaka kontrol edin. robots.txt hukuken bağlayıcı değildir, ama ona saygı göstermek en iyi uygulamadır. ToS ihlalleri sivil davalara, hatta daha da kötüsüne yol açabilir ().
- Teknik Önlemler: İnsan gibi hızlarla kazımak ve güvenlik önlemlerini aşmamak kilit noktadır. Bir sunucuyu aşırı zorlamak ya da CAPTCHA’lardan kaçmak çizgiyi hackleme tarafına geçebilir ().
2024–2026’da Ne Değişti: Önemli Mahkeme Kararları ve Düzenlemeler
2023’ten bu yana web kazımaya ilişkin hukuki tablo dramatik biçimde değişti. İşte her kazıyıcının bilmesi gereken gelişmeler:
Büyük Mahkeme Kararları
-
Meta v. Bright Data (2024): ABD federal mahkemesi, Meta’nın Kullanım Şartlarının giriş yapmamış kullanıcılar tarafından kamuya açık verilerin kazınmasını yasaklamadığına hükmetti. Hâkim, "hesabı olmayan biri 'kullanıcı' sayılmaz" dedi. Meta kısa süre sonra kalan iddialarını geri çekti. Bu, kamuya açık veri kazıma açısından dönüm noktası niteliğinde bir kazanım.
-
X Corp v. Bright Data (2024): Twitter (şimdiki X) benzer bir davayı kaybetti ve aynı ilke pekişti: Giriş yapmadan kamuya açık verileri kazımak ToS ihlali değildir, çünkü kazıyıcı bu şartları hiç kabul etmemiştir.
-
Reddit v. Perplexity AI (Ekim 2025): Reddit, DMCA’ya dayanarak ve bot karşıtı sistemlerin aşılması iddiasıyla Perplexity AI ve birkaç kazıma sağlayıcısına dava açtı. Bu, yeni bir hukuki stratejiyi işaret ediyor: platformlar CFAA yerine telif ve anti-circumvention iddialarına yöneliyor.
-
NYT v. OpenAI (Mart 2025): Federal bir yargıç, OpenAI’nin davayı düşürme talebini reddederek New York Times’ın OpenAI’ye karşı açtığı telif davasının devam etmesine izin verdi. Bu, AI modellerini eğitmek için içerik kazımanın "fair use" sayılıp sayılmayacağı konusunda önemli bir emsal oluşturabilir.
-
Anthropic Uzlaşması (Eylül 2025): Anthropic, AI modelini eğitmek için telifli metinler kullanması nedeniyle açılan ABD telif sınıf davasını sonuçlandırmak için 1,5 milyar dolar ödemeyi kabul etti—bu da AI için kazıma maliyetlerinin son derece gerçek olduğunu gösteriyor.
Büyük Eğilim: CFAA’dan Sözleşme ve Telif Hukukuna
Tablo net: CFAA (Computer Fraud and Abuse Act), kamuya açık veri kazıyıcılarına karşı silah olarak gücünü yitiriyor. Meta, X, LinkedIn gibi kamuya açık veri kazımaya karşı CFAA’yı kullanmaya çalışan şirketler büyük ölçüde başarısız oldu. Bunun yerine hukuki savaş alanı şuralara kayıyor:
- Sözleşme hukuku (ToS ihlalleri—ama mahkemeler, kullanıcı olmayanların ToS’a bağlı olmadığını söylüyor)
- Telif iddiaları (özellikle AI eğitim verileri için)
- Anti-circumvention yasaları (DMCA Bölüm 1201)
Kazıyıcılar için bu, hukuki riskin ortadan kalkmadığı; sadece yer değiştirdiği anlamına geliyor.
Düzenleyici Değişiklikler
- CCPA 2026 Güncellemeleri: Kaliforniya’nın revize edilmiş CCPA düzenlemeleri ; otomatik karar verme teknolojisi (ADMT), risk değerlendirmeleri ve veri komisyoncusu yükümlülükleri için yeni kurallar ekledi.
- Yeni ABD Eyalet Gizlilik Yasaları: Indiana, Kentucky ve Rhode Island, 2026’da yürürlüğe giren kapsamlı gizlilik yasaları çıkardı.
- AB Yapay Zekâ Yasası: Tam uygulama başlıyor—AI geliştiricilerinin eğitim verisi kaynaklarını açıklamasını, telif hakkı vazgeçme tercihlerini dikkate almasını ve AI sistemleri için yüz görüntüsü kazımayı yasaklıyor.
- Yayıncılar için AI Hesap Verebilirliği Yasası (Şubat 2026): AI şirketlerinin içeriklerini kazımadan önce izin almasını ve yayıncılara ödeme yapmasını gerektirecek önerilen bir ABD yasası.
Büyük Platformların Kazıma Politikaları: Bilmeniz Gerekenler
Tüm web siteleri kazımaya aynı şekilde yaklaşmaz. İşte en büyük sitelerin neye izin verdiğini, neyi engellediğini ve mahkemelerin ne dediğini platform bazında özetleyen bir tablo:
| Platform | ToS’ta Kazıma | Teknik Savunmalar | Hukuki Uygulama | Pratikte Güvenli Olan |
|---|---|---|---|---|
| Google (Arama & Maps) | ToS içinde otomatik erişimi yasaklar. Maps Platform’da açık bir "No Scraping" maddesi vardır. | SearchGuard JS zorlukları, CAPTCHA’lar, oran sınırlama. 2025’te robots.txt AI tarayıcılarını engelleyecek şekilde güncellendi. | 2025 Aralık’ta DMCA kullanarak kazıyıcılara dava açtı. AI tarayıcılarını (Anthropic, Meta, OpenAI) aktif olarak engelliyor. | Kamuya açık Google Maps işletme verilerini kazımak hukuken savunulabilir (hiQ emsali), ancak teknik engeller bekleyin. Mümkünse resmi API’leri kullanın. |
| Amazon | Kullanım Koşulları’nda tüm kazımayı açıkça yasaklar ("robot, spider, scraper veya başka herhangi bir otomatik araç yok"). | Agresif bot tespiti, CAPTCHA, IP engelleme. robots.txt, Googlebot/Bingbot dışındaki tüm botları engeller. 2025’ten beri AI tarayıcılarını da açıkça engelliyor. | 2025 Kasım’da Perplexity AI’ye dava açtı. Düzenli olarak ihtar mektupları gönderiyor. Mart 2026’da AI agent kurallarıyla BSA’yı güncelledi. | Kamuya açık ürün verileri (fiyatlar, listelemeler) ABD hukukunda gerçek veridir ve kazınabilir; ancak Amazon sert karşı koyar. İstek hızını düşürün ve kişisel veriden kaçının. |
| ToS’da kazımayı yasaklar; hizmete erişim için kullanıcı onayı ister. | Çoğu profil verisi için giriş duvarı, bot karşıtı tespit, oran sınırlama. | hiQ davası, kamuya açık profil kazımanın CFAA ihlali olmadığını doğruladı; ancak sahte hesaplar kullanıldığında LinkedIn sözleşme/haksız rekabet iddialarında kazandı. | Giriş yapılmadan görülebilen kamuya açık profilleri kazımak hukuken savunulabilir. Asla sahte hesap oluşturmayın veya giriş yapılmış verileri kazımayın. | |
| Meta (Facebook & Instagram) | ToS kazımayı yasaklar; giriş yapılmış ve çıkış yapılmış veri için ayrı kurallar vardır. | Çoğu içerik için giriş duvarı, gelişmiş bot tespiti. | 2024’te Bright Data’ya karşı kaybetti—mahkeme ToS’un giriş yapmamış kazıyıcılara uygulanmadığına hükmetti. Kalan iddialar geri çekildi. | Giriş olmadan görülebilen kamuya açık veri (işletme sayfaları, herkese açık gönderiler) daha güvenli zemindedir. Asla özel profilleri veya giriş arkasındaki verileri kazımayın. |
| X (Twitter) | 2023’te ToS’u güncelleyerek yazılı onay olmadan tüm kazıma ve taramayı yasakladı. Eski robots.txt istisnasını kaldırdı. | robots.txt tüm tarayıcıları engeller (Disallow: /). Cloudflare Turnstile zorlukları. Sıkı oran sınırları (saatte 300 istek). IP itibar puanlaması. | Kamuya açık veride Bright Data’ya karşı kaybetti; ancak teknik erişimi agresif biçimde kısıtlıyor. | Kamuya açık tweet’ler ve profiller hukuken savunulabilir; ancak X’in teknik bariyerleri 2026’da en zorlayıcı olanlar arasında. Premium proxy altyapısı olmadan engeller bekleyin. |
Özet: Mahkemeler, giriş yapmadan kamuya açık verilerin kazınmasının CFAA’yı ihlal etmediğine tutarlı biçimde hükmetti. Ama platformlar yine de sözleşme hukuku, telif ya da anti-circumvention gerekçeleriyle peşinize düşebilir—ve teknik engellerle hayatınızı zorlaştırırlar. Her zaman sorumlu şekilde kazıyın.
AI Eğitim Verileri ve Web Kazıma: Yeni Hukuki Sınır
2026’daki haberleri takip ediyorsanız, AI modellerini eğitmek için veri kazıma konusunun en sıcak hukuki cepheye dönüştüğünü biliyorsunuzdur. İşte olanlar:
- Telif davaları artıyor. New York Times, yazarlar ve yayıncılar OpenAI, Anthropic ve diğerlerine dava açtı; gerekçe, LLM’leri eğitmek için telifli içeriklerin topluca kazınmasının "fair use" olmadığı iddiası. Anthropic, 2025’te 1,5 milyar dolarlık büyük bir toplu davayı uzlaşmayla kapattı—AI için kazıma maliyetlerinin çok gerçek olduğunu gösteriyor.
- "Fair use" savunması zayıf. ABD mahkemeleri, kazınmış verilerle AI eğitiminin fair use olup olmadığına dair henüz kesin bir karar vermiş değil. İlk kararlar bunun büyük ölçüde verinin nasıl elde edildiğine ve AI çıktısıyla ne yapıldığına bağlı olduğunu gösteriyor.
- Yeni mevzuat geliyor. (Şubat 2026’da sunuldu), AI şirketlerinin içeriklerini kazımadan önce izin almasını ve ödeme yapmasını hedefliyor.
- AB Yapay Zekâ Yasası ( tam uygulama) AI geliştiricilerinden eğitim verisi kaynaklarını açıklamasını, makine tarafından okunabilir telif hakkı vazgeçmelerine saygı göstermesini (Telif Direktifi’nin TDM istisnası kapsamında) ve AI tarafından üretilen içeriği etiketlemesini istiyor. Ayrıca internetten yüz görüntüsü kazıyan AI sistemlerini yasaklıyor.
- AI/LLM tarayıcıları patlıyor. AI tarayıcılarının web trafiğindeki payı sadece sekiz ayda %2,6’dan %10,1’e çıktı. Sadece OpenAI’nin GPTBot’u %305 büyüdü. Buna karşılık büyük siteler (Amazon, Reddit, NYT) robots.txt’yi AI tarayıcılarını açıkça engelleyecek şekilde güncelliyor.
Bu sizin için ne anlama geliyor? Eğer veriyi geleneksel iş amaçları için kazıyorsanız (lead üretimi, fiyat takibi, pazar araştırması), bu AI’ya özgü kurallar doğrudan uygulanmayabilir. Ama kazınmış veriyi AI modellerine besliyorsanız, çok dikkatli olun—ve hukuki danışmanlık alın.
Dünyada Web Kazıma Yasaları: Hızlı Karşılaştırma
Şimdi biraz uzaklaşıp kuralların küresel ölçekte nasıl şekillendiğine bakalım:
- Amerika Birleşik Devletleri: Toplu bir yasak yok. Kamuya açık sitelerin kazınması genel olarak yasaldır (), ve 2024’teki Meta ile X Corp kararları kamuya açık veri kazıma lehine tabloyu daha da güçlendirdi. Ancak giriş arkasındaki ya da teknik engellerin arkasındaki veriyi kazımak CFAA’yı tetikleyebilir. Eğilim artık şirketlerin bunun yerine sözleşme hukuku ve telif iddialarını kullanması yönünde. Gizlilik yasaları hızla genişliyor: CCPA, 1 Ocak 2026 itibarıyla büyük güncellemeler aldı; otomatik karar verme ve veri komisyoncusu yükümlülükleri için yeni kurallar getirildi. Indiana, Kentucky ve Rhode Island da 2026’da kapsamlı gizlilik yasaları çıkardı.
- Avrupa Birliği: Sıkı gizlilik yasaları. GDPR, kamuya açık kişisel veriye bile uygulanır. Veritabanı hakları, yapılandırılmış verinin büyük ölçekli kazınmasını engelleyebilir (). YENİ: 2 Ağustos 2026’da tam uygulamaya geçiyor, AI geliştiricilerinin eğitim verisi kaynaklarını açıklamasını ve telif hakkı vazgeçmelerine saygı göstermesini zorunlu kılıyor. Yasa, AI sistemleri için internetten yüz görüntüsü kazımayı yasaklıyor.
- Birleşik Krallık: Brexit sonrası AB kurallarına benzer. Kamuya açık veri kazınabilir, ama kişisel bilgi kazıma sıkı biçimde düzenlenir. Computer Misuse Act yetkisiz erişimi suç sayabilir.
- Çin: Çok kısıtlayıcı. PIPL ve Veri Güvenliği Yasası, kişisel veriler için rıza ister. Mahkemeler, işletmelere zarar veren kazımayı engellemek için haksız rekabet hukukunu kullanır ().
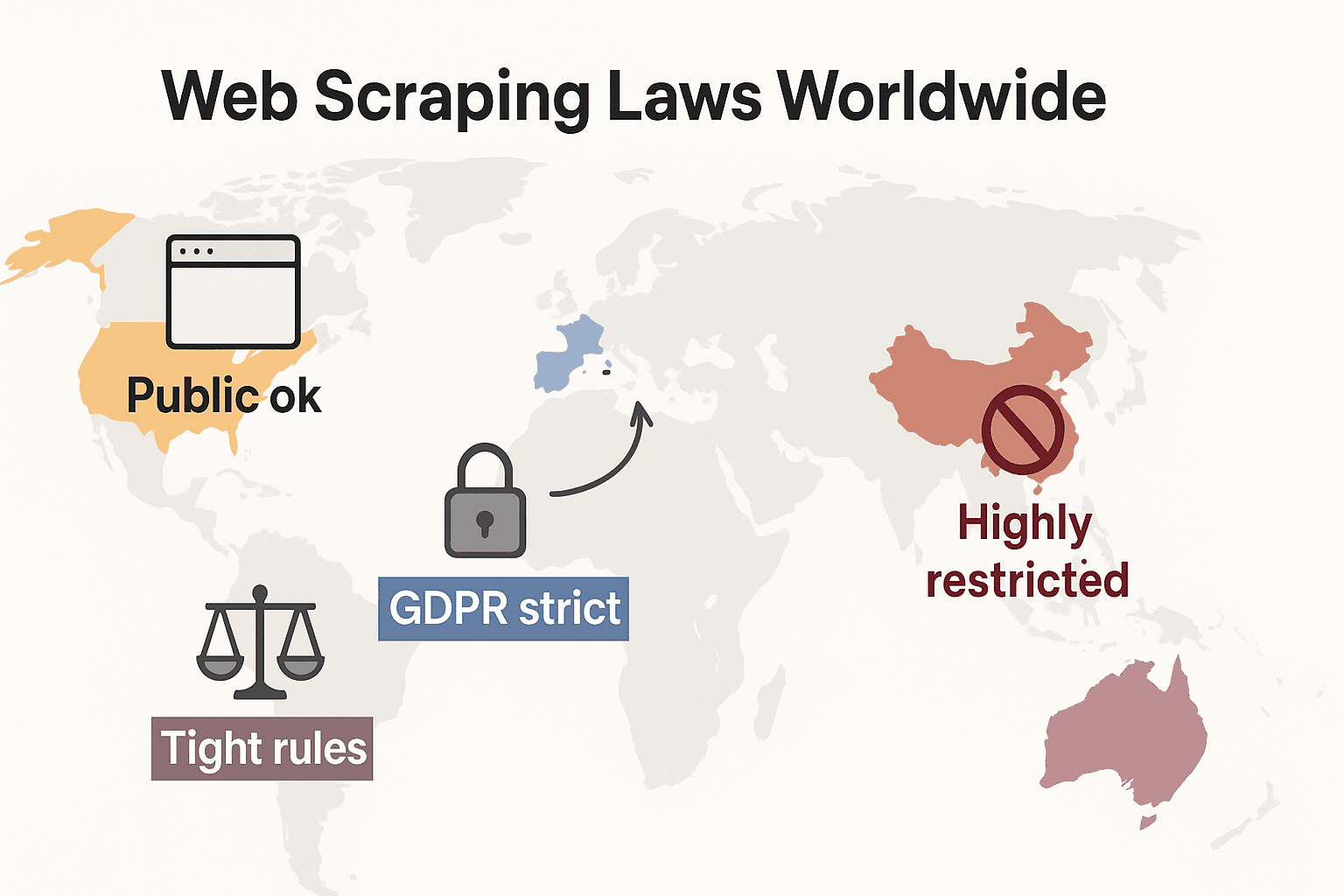
Özetle: dahili kullanım için kamuya açık, kişisel olmayan verileri kazımak genelde en güvenli yoldur. Bunun dışındaki her şey için yerel yasaları kontrol edin ve temkinli ilerleyin.
Web Kazıma Yasallığı Hakkındaki Yaygın Efsaneler
Sürekli duyduğum birkaç efsaneyi çürüteyim:
- Efsane 1: "Web kazıma düpedüz yasa dışıdır."
Yanlış. Tüm web kazımayı yasaklayan bir yasa yok. Önemli olan neyi ve nasıl kazıdığınız (). - Efsane 2: "Veri halka açıksa onunla istediğimi yapabilirim."
Tam olarak değil. Kamuya açık veriler yine de gizlilik veya telif yasalarıyla korunabilir; ToS belirli kullanımları kısıtlayabilir (). - Efsane 3: "Web kazıma hackleme ile aynıdır."
Hayır. Kamuya açık web sayfalarını kazımak hackleme değildir. Giriş engellerini veya teknik bariyerleri aşmak başka bir hikâye (). - Efsane 4: "Yakalanmazsam sorun yok."
Riskli düşünce. Birçok site bot karşıtı teknoloji kullanır ve sizi fark eder. Sessizlik, rıza değildir. - Efsane 5: "Kaynak göstermek veya veriyi dahili kullanmak bunu kabul edilebilir kılar."
Atıf, telif veya gizlilik yasalarının üstüne çıkmaz. Dahili kullanım daha güvenlidir, ama serbest geçiş kartı değildir. - Efsane 6: "Tüm web kazıma gizliliği ihlal eder."
Her kazıma kişisel veri içermez. Ama çok büyük miktarda kişisel bilgiyi güvenlik önlemleri olmadan kazımak neredeyse her zaman yasa dışıdır (). - Efsane 7: "Bir web sitesinin ToS’u kazımayı yasaklıyorsa, kazımak her zaman yasa dışıdır."
Şart değil. 2024’te mahkemeler Meta v. Bright Data ve X Corp v. Bright Data davalarında, ToS’u hiç kabul etmemiş kullanıcıların bu sözleşmelerle bağlanamayacağına hükmetti—yani giriş yapmadan veya hesap oluşturmadan kazıma yapıyorsanız, sitenin ToS’u size uygulanmayabilir. Bu alan hâlâ gelişiyor, ama önemli bir değişim bu.
Veriyi Yasal Olarak Nasıl Kazırsınız: Uyum İçin En İyi Uygulamalar
Hukuka ve etik kurallara uygun web kazıma için benim olmazsa olmaz kontrol listem:
- Sitenin Kullanım Şartlarını okuyun ve saygı gösterin. "Kazıma yok" diyorlarsa, durmayı düşünün veya izin isteyin ().
- Kamuya açık veride kalın. Bir parola gerekiyorsa, bu kısıtlıdır—kazımayın ().
- robots.txt’yi kontrol edin ve nazikçe tarayın. Hukuken bağlayıcı olmasa da iyi bir görgü kuralıdır. Sunucuları dövmeyin—isteklerinizi aralıklı gönderin ().
- Hukuki dayanağınız yoksa kişisel veriden kaçının. Toplamanız gerekiyorsa GDPR/CCPA’ya uyun ve topladığınız veriyi en aza indirin.
- Kazınmış içeriği topluca yeniden yayımlamayın. Üstüne değer veya analiz ekleyin ya da izin alın ().
- Telif kontrolü yapmadan kazınmış içeriği AI modellerine beslemeyin. Hukuki tablo hızla değişiyor—bu sizin kullanım durumunuzsa danışmanlık alın.
- Mümkünse resmi API’leri veya veri dışa aktarımlarını kullanın. Bu amaç için tasarlanırlar ve genellikle daha güvenlidir ().
- Şeffaf ve hesap verebilir olun. Kişisel veri topluyorsanız insanları bilgilendirin ve faaliyetlerinizi kayıt altına alın.
- Verinizi asgari seviyede tutun ve güvenli saklayın. Sadece ihtiyacınız olanı toplayın, doğru tuttuğunuzdan emin olun ve güvenle depolayın.
- Bilgili kalın ve sınır durumlarda hukuki destek alın. Yasalar ve mahkeme kararları hızla değişiyor—özellikle AB Yapay Zekâ Yasası ve ABD eyalet gizlilik yasaları. Emin değilseniz bir uzmana sorun.
Web Kazıma Araçlarını Yasal Olarak Kullanmak: İşletmelerin Bilmesi Gerekenler
gibi web kazıma araçları, kod yazmayan kişiler için veri toplamayı erişilebilir hale getiriyor; ama yine de bunları sorumlu şekilde kullanmanız gerekir:
- Uyumluluk odaklı araçlar seçin. Örneğin Thunderbit, yalnızca tarayıcınızda görebildiğiniz şeyleri kazır—gizli API hileleri veya yetkisiz erişim yok ().
- Meşru kullanım alanlarında kalın. Dahili analiz, pazar araştırması ve rakip fiyat takibi genelde güvenlidir. Kazınmış veriyi yeniden yayımlamak veya satmak? Çok daha riskli.
- Araçları uyumlu olacak şekilde yapılandırın. Tarama gecikmesi ayarlayın, robots.txt’ye uyun ve yalnızca ihtiyacınız olanı toplayan şablonlar kullanın.
- Veriyi içeride tutun. Kazınmış veriyi dahili kullanmak, yeniden yayımlamaktan daha güvenlidir.
- Ekibinizi eğitin. Herkesin kuralları ve en iyi uygulamaları bildiğinden emin olun.
- Yerleşik uyumluluk özelliklerinden yararlanın. Thunderbit, riskli siteler konusunda kullanıcıları uyarır, insan benzeri hızlarda kazır ve verinizi kendi sunucularında saklamaz.
- Zorlamayın. Bir araç bir siteyi kazıyamıyorsa, etrafından dolaşmaya çalışmayın. Her veri risksiz şekilde elde edilemez.
Thunderbit’in Yaklaşımı: Uyumlu AI Web Kazımayı Mümkün Kılmak
olarak uyumluluk üzerine epey düşündük. İşte AI Web Scraper’ımızın kullanıcıların yasanın doğru tarafında kalmasına nasıl yardımcı olduğu:
- Yalnızca görebildiğinizi kazır. Thunderbit tarayıcı oturumunuz içinde çalışır; yani elinizle kopyalayamayacağınız verilere erişemez.
- Uyarılarla yol gösterir. Sıkı kazıma karşıtı politikalara sahip bir siteyi kazımaya çalışırsanız Thunderbit sizi uyarır.
- İnsan benzeri kazıma hızları. İster yerelde ister bulutta kazıyın, Thunderbit sunucuları aşırı zorlamaz.
- Özelleştirilebilir veri seçimi. AI’mız ilgili sütunları önerir, böylece yalnızca ihtiyacınız olanı toplarsınız.
- Alt sayfa ve sayfalama desteği. Thunderbit, yapısını gözeterek sitelerde gerçek bir kullanıcı gibi gezinir.
- Gizlilik ve güvenlik. Veriniz sizde kalır—Thunderbit onu saklamaz veya yeniden kullanmaz.
- Uyumluluğa uygun dışa aktarımlar. Güvenli ve dahili kullanım için doğrudan Google Sheets, Airtable, Notion veya CSV’ye aktarın.
- Zamanlama ve otomasyon. Sorumlu aralıklarla tekrarlayan kazımalar ayarlayın.
- Çoklu dil desteği. Thunderbit’in arayüzü 34 dili destekler; böylece uyumluluk küresel ölçekte erişilebilir olur.
- Düzenli şablon güncellemeleri. Popüler siteler için anlık şablonlarımız, hukuki ve teknik değişikliklere göre güncel tutulur.
Uyumluluğu ürünün içine yerleştirerek Thunderbit, ekiplerin ihtiyaç duyduğu veriyi hukuki baş ağrısı yaşamadan toplamasına yardımcı olur.
Bir Adım Önde Kalmak: Web Kazımada Hukuki ve Teknik Değişimlere Uyum Sağlamak
Web kazıma, kurulumunu yapıp unutacağınız bir oyun değil. Yasalar ve web sitesi yapıları sürekli değişiyor. Önde kalmak için şunları yapın:
- Hukuki gelişmeleri takip edin. Değişim hızı 2024–2026 döneminde arttı—teknoloji hukuku haberlerini, düzenleyici güncellemeleri ve sektör bloglarını izleyin. AB Yapay Zekâ Yasası’nın yürürlüğünü (Ağustos 2026), yeni ABD eyalet gizlilik yasalarını ve devam eden AI telif davalarını takip edin.
- Teknik değişimlere uyum sağlayın. Siteler düzenlerini ve bot karşıtı savunmalarını sürekli güncelliyor. Büyük platformlar (Amazon, X, Google) 2025–2026’da savunmalarını ciddi biçimde sıkılaştırdı. Thunderbit’in AI’si ve şablonları otomatik uyum için tasarlanmıştır.
- Mümkün olduğunda resmi API’leri benimseyin. Bir site ücretli API modeline geçerse, güvenilirlik ve uyumluluk için bunu değerlendirin.
- Kazıma işlemlerinizi düzenli olarak denetleyin. Kaynaklarınızı belgeleyin, ToS veya politika değişikliklerini kontrol edin ve stratejinizi gerektiğinde ayarlayın.
- Thunderbit’in şablon güncellemelerini kullanın. Ekibimiz şablonları güncel tutar; böylece kırıcı değişiklikler veya yeni uyumluluk gereksinimleri konusunda endişelenmezsiniz.
- Esnek kalın. Bir veri kaynağı fazla riskli hale gelirse başka birine geçin veya bir ortaklık arayın.
Doğru araçlar ve doğru zihniyetle, hukuki mayınlara basmadan veri hattınızı akmaya devam ettirebilirsiniz.
Sonuç: Web Kazımanın Hukuki Tablosunda Yol Almak
Web kazıma doğası gereği yasa dışı değildir—iş, araştırma ve inovasyon için güçlü bir araçtır. Ama her araç gibi bunun da kuralları vardır. Önemli olan neyi kazıdığınızı, nasıl kazıdığınızı ve veriyi ne yapacağınızı anlamaktır. Yerel yasalara saygı gösterin, web sitesi politikalarına uyun ve operasyonlarınızı yasal sınırlar içinde tutmak için gibi uyumluluk odaklı araçlar kullanın.
2024–2026 mahkeme kararları (Meta v. Bright Data, X Corp v. Bright Data), kamuya açık verilerin kazınması lehine tabloyu güçlendirdi; ancak AI eğitim verileri, telif iddiaları ve AB Yapay Zekâ Yasası etrafında yeni riskler ortaya çıkıyor. Platforma özgü politikalar büyük farklılık gösteriyor—Google, Amazon, LinkedIn, Meta ve X kurallarını farklı şekillerde uyguluyor—bu yüzden kazımadan önce ortamı bilin.
Eğer hiç emin değilseniz, özellikle büyük veya hassas projelerde hukuki danışmanlık alın. Ve unutmayın: hukuki tablo sürekli değişiyor, bu yüzden bilgili ve çevik kalın.
Web kazıma, uyumluluk ve otomasyon hakkında daha fazla bilgi edinmek ister misiniz? Daha fazla rehber için sayfasına göz atın ya da kendiniz deneyin.
SSS
1. Web kazıma her yerde yasa dışı mı?
Hayır. Web kazıma doğası gereği yasa dışı değildir; ancak yasallığı neyi kazıdığınıza, nasıl kazıdığınıza ve nerede olduğunuza bağlıdır. İç kullanım için kamuya açık, kişisel olmayan verileri kazımak çoğu bölgede genelde izinlidir; fakat kişisel ya da telifli verileri kazımak veya site şartlarını ihlal etmek yasa dışı olabilir ().
2. robots.txt’yi görmezden gelirsem kazıma yasa dışı olur mu?
robots.txt hukuken bağlayıcı değildir, ama ona saygı göstermek en iyi uygulamadır. robots.txt’yi görmezden gelmeniz tek başına dava nedeni olmayabilir; ancak bir anlaşmazlık çıkarsa sizi "kötü niyetli aktör" gibi gösterebilir ().
3. Google, Amazon veya LinkedIn’i kazıyabilir miyim?
Bu karmaşık. Üçü de ToS’larında kazımayı yasaklıyor; ancak mahkemeler, giriş yapmamış kullanıcılar için ToS’un bağlayıcı olmayabileceğine hükmetti (bkz. 2024 tarihli Meta v. Bright Data ve X Corp v. Bright Data). Kamuya açık verileri (ürün fiyatları, işletme listeleri, kamu profilleri) kazımak ABD’de genelde hukuken savunulabilir. Ancak her platform kurallarını farklı uygular: Amazon hukuki adımlarda en agresif olanıdır (Kasım 2025’te Perplexity AI’ye dava açtı); LinkedIn teknik engellere ve sözleşme iddialarına dayanır; Google giderek DMCA temelli yaptırımlar kullanıyor. Her zaman sorumlu şekilde kazıyın ve teknik karşı önlemler bekleyin.
4. Facebook veya Instagram’ı kazıyabilir miyim?
Meta v. Bright Data (2024) sonrasında, Facebook ve Instagram’dan giriş yapmadan kamuya açık veri kazımak hukuki açıdan daha güçlü bir zemine sahip. Mahkeme, Meta’nın ToS’unun kullanıcı olmayanlara uygulanmadığına hükmetti. Ama asla sahte hesap açmayın veya giriş duvarlarının arkasındaki veriyi kazımayın—bu çizgiyi aşar.
5. X’i (Twitter) kazıyabilir miyim?
X, 2023’te ToS’unu güncelleyerek yazılı onay olmadan tüm kazımayı yasakladı ve agresif teknik savunmalar devreye aldı (Cloudflare Turnstile, saatte 300 istek sınırı, IP itibar puanlaması). Ancak Bright Data benzer gerekçelerle davayı kazandı—hesap olmadan kazınan kamuya açık veri X’in ToS’una bağlı değildir. Teknik açıdan X, 2026’da kazınması en zor platformlardan biridir.
6. AI modellerini eğitmek için veri kazımak yasal mı?
Bu, 2026’daki en büyük açık soru. Büyük davalar (NYT v. OpenAI, Anthropic’in 1,5 milyar dolarlık uzlaşması) ciddi hukuki risk olduğunu gösteriyor. AB Yapay Zekâ Yasası, eğitim verisi kaynaklarının açıklanmasını ve telif hakkı vazgeçmelerine saygı gösterilmesini istiyor. Önerilen AI Accountability for Publishers Act ise izin ve ödeme şartı getirecek. AI eğitimi için kazıma yapıyorsanız, başlamadan önce hukuki danışmanlık alın.
7. Thunderbit gibi web kazıma araçlarını kullanmanın en güvenli yolu nedir?
Kamuya açık veriyi kazımaya odaklanın, site şartlarına saygı gösterin, hukuki dayanağınız yoksa kişisel bilgilerden kaçının ve veriyi dahili kullanın. Thunderbit, yalnızca tarayıcınızda görüneni kazıyarak ve riskli siteler konusunda sizi uyararak uyumlu kalmanıza yardımcı olacak şekilde tasarlanmıştır ().
8. Veriyi ticari kullanım için kazıyabilir miyim?
Duruma bağlı. Kazınmış veriyi dahili analiz veya araştırma için kullanmak genelde daha güvenlidir. Özellikle telifli ya da kişisel verileri yeniden yayımlamak veya satmak çok daha risklidir ve izin ya da lisans gerektirebilir.
9. Web kazımada hukuki ve teknik değişimleri nasıl takip ederim?
Teknoloji hukuku haberlerini takip edin, hedef sitelerinizdeki ToS veya politika değişikliklerini izleyin ve şablonlarını ile uyumluluk özelliklerini düzenli olarak güncelleyen Thunderbit gibi araçlar kullanın. 2026’da dikkat edilmesi gereken başlıca konular: AB Yapay Zekâ Yasası’nın yürürlüğü (Ağustos), devam eden AI telif davaları ve yeni ABD eyalet gizlilik yasaları. Emin olmadığınızda bir hukuk uzmanına danışın.