eBay kazıma hakkında internette dolaşan çoğu rehberin kullanım ömrü yaklaşık üç aydır. Bunu biliyorum çünkü Thunderbit ekibimiz, geliştiricilerin bozuk kod parçacıkları, güncelliğini yitirmiş CSS seçiciler ve iki kez yenilenen eBay arayüzü yüzünden sessizce çalışmayı bırakmış “çalışıyor” görünümlü GitHub depoları arasında gidip geldiğine defalarca şahit oldu.
eBay, açık web’de Amazon’dan sonra en büyük uzun kuyruk fiyatlandırma veri seti olan sahip. Bu veri; ikinci el satış fiyatlamasından rekabet istihbaratına kadar pek çok alanın temelini oluşturuyor. Ancak bu verilere programatik olarak ulaşmak sürekli değişen bir hedef gibi: eBay’in React tabanlı ön yüzü CSS sınıf adlarını sık sık değiştiriyor, A/B testleri farklı kullanıcılara farklı DOM yapıları gösteriyor ve HTML ile senin aranda Akamai Bot Manager duruyor. Bu rehber sana bugün çalışan Python kodlarını verir, tarayıcıların neden bozulduğunu açıklar ki daha sağlam çözümler kurabilesin, eBay API ile kazıma arasındaki seçimi dürüstçe ele alır ve Python kurulumuna değmeyecek durumlarda kullanabileceğin kodsuz bir çıkış yolu sunar.
Python ile eBay Kazımak Ne Anlama Gelir?
Python ile eBay kazıma, eBay sayfalarını programatik biçimde indirip, HTML’i (ya da gizli JSON verisini) ayrıştırarak başlık, fiyat, satıcı bilgisi, satış tarihi, varyant detayları gibi yapılandırılmış verileri CSV, tablo veya veritabanı gibi gerçekten kullanabileceğin bir formata dönüştüren scriptler yazmak demektir.
Şu tür eBay sayfalarını kazıyabilirsin:
- Arama sonuçları (ör. tüm “AirPods Pro” ilanları)
- Tekil ürün detay sayfaları (tam teknik özellikler, görseller, satıcı bilgisi)
- Satılmış/tamamlanmış ilanlar (gerçek işlem fiyatları ve tarihleri)
- Satıcı profilleri ve yorumlar
Bu iş için Python tercih edilen dildir. Requests, BeautifulSoup, lxml, pandas gibi ekosistemi sayesinde sayfa çekmek, HTML ayrıştırmak ve veriyi düzenlemek oldukça kolaydır. Yine de web sitesi HTML’sini kazımak ile eBay’in resmi API’sini kullanmak arasında önemli bir fark vardır — birazdan onu da ele alacağım.
eBay Neden Kazınır? İş Ekipleri İçin Gerçek Kullanım Senaryoları
Bunu okuyorsan muhtemelen zaten bir nedenin vardır. Yine de konuyu somut iş değeri üzerinden ele almak faydalı, çünkü eBay verisinin ROI’si gerçekten etkileyici. Bain, yol açabildiğini; McKinsey ise perakendede dinamik fiyatlamanın sağlayabildiğini belirtiyor.
En sık gördüğüm kullanım alanları:
| Kullanım Alanı | Gereken Veri | İş Sonucu |
|---|---|---|
| Fiyat takibi ve yeniden fiyatlama | Aktif ilan fiyatları, kargo, ürün durumu | Rekabetçi fiyatlama, marj koruması |
| Rakip analizi | Ürün çeşitleri, kampanyalar, kargo koşulları | Stratejik konumlandırma, ürün gamı boşlukları |
| Pazar araştırması ve trend takibi | İlan hacmi, kategori trendleri, talep desenleri | Yeni ürün fırsatları, talep tahmini |
| İkinci el fiyatlama / ekspertiz | Satış fiyatları, satış tarihleri, ürün durumu | Adil piyasa değeri, alım kararı |
| Duygu analizi | Yorumlar, puanlar, iade politikası | Ürün kalitesi içgörüsü, müşteri memnuniyeti |
| Lead oluşturma | Satıcı profilleri, mağaza bilgileri, iletişim detayları | Yüksek ciro yapan satıcılara B2B erişim |
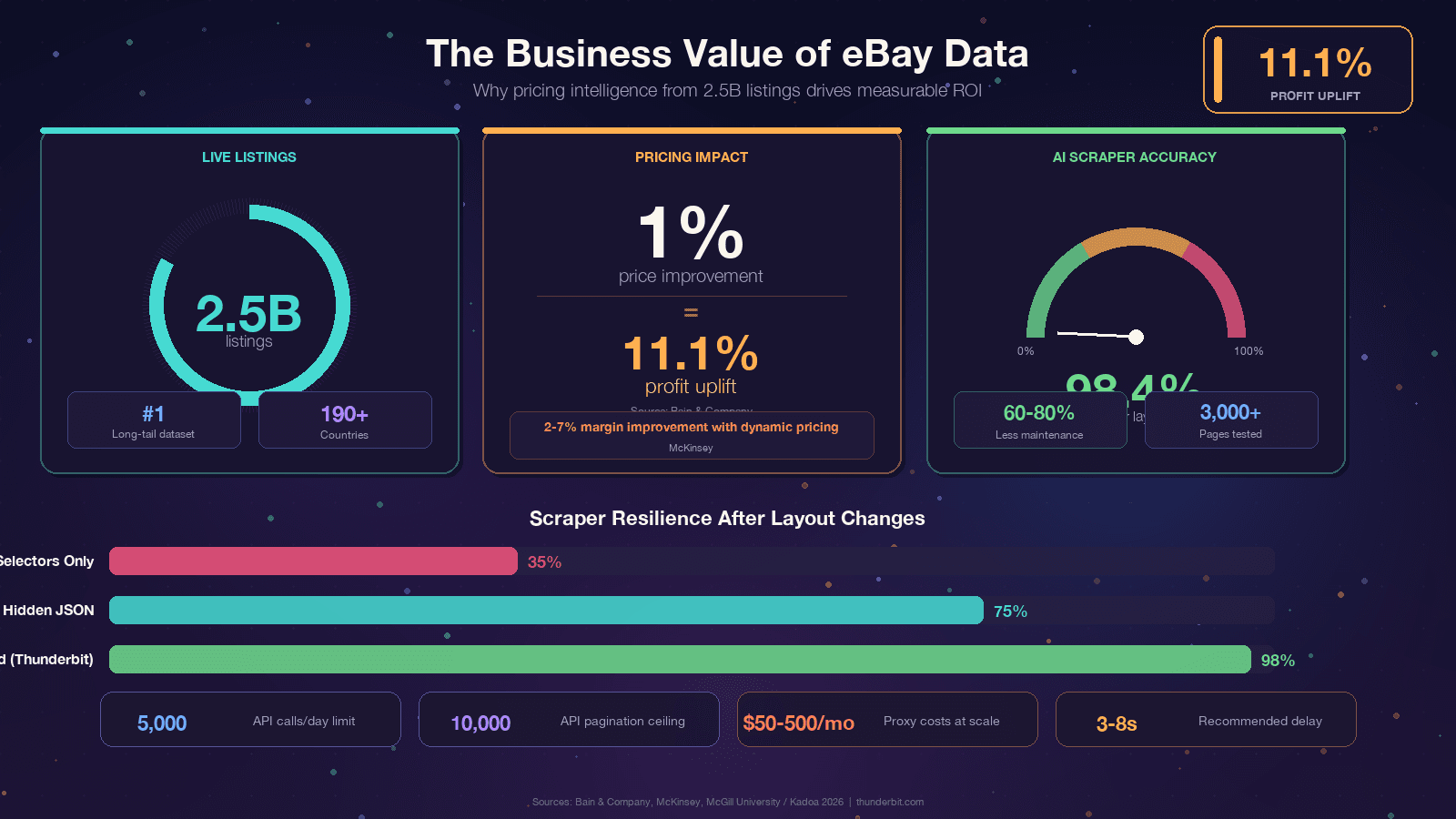
Ortak nokta şu: eBay’de veri var, ama web sayfalarının içine kilitlenmiş durumda.
Kazıma, bu veriyi rekabet avantajına dönüştürmenin yoludur.
eBay Resmi API’si mi, Python ile Web Kazıma mı? Hangisini Seçmelisiniz?
Keşke daha çok rehber bu soruyu dürüstçe cevap verseydi. eBay resmi API’ler sunuyor — başta olmak üzere — ve pek çok kullanıcı bunları mı yoksa doğrudan kazımayı mı kullanması gerektiğini merak ediyor. Cevap tamamen ihtiyacın olan veriye bağlı.
| Kriter | eBay Browse/Finding API | Python ile Web Kazıma |
|---|---|---|
| Satılmış/tamamlanmış ilanlar | Sınırlı — Marketplace Insights API var ama erişim çoğu zaman reddediliyor | LH_Sold=1&LH_Complete=1 URL parametreleriyle tam erişim |
| İstek limiti | Temel pakette günde 5.000 çağrı | Kullanıcı tarafından yönetilir (proxy’ye bağlı) |
| Veri alanları | Önceden tanımlı (başlık, fiyat, kategori, temel satıcı bilgileri) | Sayfada görünen her şey (yorumlar, tam teknik özellikler, varyant matrisi) |
| Kurulum zorluğu | OAuth 2.0, uygulama kaydı, API anahtarları | pip install + kod |
| Kararlılık | Kararlı uç noktalar | HTML değişince bozulur |
| Maliyet | Ücretsiz katman mevcut, hacimde ücretli | Kod ücretsiz, ama ölçekte proxy maliyeti var |
| Varyant/MSKU verisi | Kısmi — çoğu durumda yalnızca üst SKU | Tam (gizli JSON ayrıştırmasıyla) |
| Sayfalama derinliği | 10.000 öğelik sert üst sınır | Teorik olarak sınırsız |
Kısa bir not: eski Finding API (findCompletedItems içeren) . ebaysdk-python ya da Finding modülüne istek atan herhangi bir kütüphane kullanıyorsan, şu anda üretim ortamında çalışmıyor.
Benim önerim: Aktif ilanlarda kararlı, orta hacimli ve yapılandırılmış katalog sorguları için Browse API’yi kullanın. Satış fiyatları, yorumlar, varyant verileri veya API’nin sunmadığı herhangi bir alan gerektiğinde Python kazıma tercih edin. Birçok ekip ikisini birlikte kullanıyor.
eBay’i Python ile Kazımak İçin Gerekli Araçlar ve Kütüphaneler
Koda geçmeden önce araç setine bakalım. Çoğu eBay sayfası için headless browser’a ihtiyacın yok — veri sunucu tarafında üretilen HTML’in içine gömülü.
| Kütüphane | Amaç |
|---|---|
requests veya httpx | eBay sayfalarını indirmek için HTTP istemcisi |
curl_cffi | Gerçek tarayıcı TLS parmak izine sahip HTTP istemcisi (Akamai’yi aşmada kritik) |
beautifulsoup4 | CSS seçiciyle çıkarım yapmak için HTML ayrıştırıcı |
lxml | BeautifulSoup için hızlı ayrıştırma altyapısı |
jmespath | İç içe JSON bloklarını sorgulamak için dil |
pandas | Veri işleme ve CSV/Excel dışa aktarma |
gspread | Google Sheets entegrasyonu |
Hepsini tek satırda kurabilirsin:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadPython 3.11+ kullanın — pandas 3.0 için 3.10+ gerekiyor ve 3.11, I/O ağırlıklı işlerde %10–60 arası hız kazancı sağlar.
Bir kütüphane özellikle anılmayı hak ediyor: curl_cffi, 2026’da bir eBay kazıyıcısına yapılabilecek en etkili yükseltmedir. eBay kullanır ve Akamai’nin ana tespit yöntemi TLS parmak izidir. Düz requests, anında işaretlenen Python benzeri bir JA3 parmak izi üretir. curl_cffi ise gerçek bir Chrome tarayıcısının TLS el sıkışmasını taklit eder; bu da headless browser gerektirmeden Akamai korumalı hedeflerin yaklaşık %90’ında işe yarar.
Adım Adım: eBay Arama Sonuçları Python ile Nasıl Kazınır?
Bu bölüm temel rehberdir. Ürün ilanları için eBay arama sonuçları sayfalarını kazıyacağız.
- Zorluk: Başlangıç–Orta
- Gerekli Süre: İlk çalışan kazıma için yaklaşık 30 dakika
- Gerekenler: Python 3.11+, yukarıdaki kütüphaneler, bir terminal ve hedef bir eBay arama URL’si
1. Adım: Python Projenizi Kurun
Bir proje klasörü oluşturun ve bağımlılıkları yükleyin:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasscrape_ebay.py adında bir dosya oluşturun. Çalışma alanınız bu olacak.
2. Adım: eBay Arama URL’sini Oluşturun
eBay’in arama URL yapısı oldukça basittir. Temel parametre _nkw (anahtar kelime) parametresidir:
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # sayfa başına öğe: 60, 120 veya 240 (240 bot uyarısını tetikleyebilir)
7 "_pgn": "1", # sayfa numarası
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Diğer faydalı parametreler:
LH_BIN=1— yalnızca Hemen Satın Al_sacat=175673— belirli kategori_sop=12— en iyi eşleşmeye göre sırala (10 = en düşük ürün+kargo, 13 = yeni listelenenler)LH_Complete=1&LH_Sold=1— satılmış/tamamlanmış ilanlar (aşağıda ayrı bir bölümde ele alınıyor)
3. Adım: İstek Gönderin ve Yanıtı İşleyin
İşte curl_cffi burada devreye giriyor. Düz bir requests.get() çoğu zaman Akamai’den 403 döndürür. curl_cffi ile gerçek bir Chrome tarayıcısını taklit ediyoruz:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Durum {r.status_code}, {sleep_for:.1f}s sonra tekrar deneniyor...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" İstek hatası: {e}, tekrar deneniyor...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"{max_retries} denemeden sonra başarısız oldu: {url}")Üstel geri çekilme ve rastgele gecikme çok önemlidir — sabit bekleme aralıkları da bir bot parmak izidir.
4. Adım: Arama Sayfasından Ürün İlanlarını Ayrıştırın
eBay şu anda iki farklı arama sonuçları düzeni arasında geçiş yapıyor. Dayanıklı bir kazıyıcı her ikisini de işleyebilmelidir:
| Alan | Eski Düzen | Yeni Düzen |
|---|---|---|
| Kart kapsayıcısı | li.s-item | li.s-card veya div.su-card-container |
| Başlık | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Fiyat | span.s-item__price | .s-card__price |
Her iki düzeni de işleyen ayrıştırma kodu:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Başlık — iki düzeni de kontrol et
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Hayalet "Shop on eBay" yer tutucu kartı atla
11 if not title or "Shop on eBay" in title:
12 continue
13 # Fiyat
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Görsel
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Kargo
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsİlk karttaki hayalet öğe klasik bir tuzaktır. Birçok eBay arama sayfasındaki ilk li.s-item, içinde gerçek fiyat bulunmayan ve başlığı “Shop on eBay” olan gizli bir yer tutucudur. Bunu mutlaka filtreleyin.
5. Adım: Birden Fazla Sayfayı Kazımak İçin Sayfalama İşleyin
eBay, _pgn parametresiyle sayfalandırma yapar. Sonraki sayfa bağlantısı a.pagination__next ile gelir:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Sayfa {page_num} kazınıyor: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Sayfa {page_num} üzerinde sonuç yok, durduruluyor.")
12 break
13 all_results.extend(results)
14 print(f" {len(results)} ilan bulundu (toplam: {len(all_results)})")
15 # Nazik gecikme — rastgele 3 ila 8 saniye
16 time.sleep(random.uniform(3, 8))
17 return all_results3–8 saniyelik rastgele gecikme isteğe bağlı değildir.
eBay’in Akamai katmanı, tek bir IP’den saniyede 1 isteğin üzerindeki sürekli trafiği işaretler.
6. Adım: Kazıdığınız Veriyi CSV veya JSON Olarak Dışa Aktarın
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"{len(df)} ilan CSV ve JSON olarak dışa aktarıldı.")Artık eBay ilanlarından oluşan temiz bir tabloya sahip olmalısınız. Benim makinemde 3 sayfalık kazıma (360 ilan), gecikmeler dahil yaklaşık 45 saniye sürdü.
eBay Ürün Detay Sayfaları Python ile Nasıl Kazınır?
Arama sonuçları özet verir. Ürün detay sayfalarında ise asıl değerli bilgiler vardır: tam açıklamalar, satıcı geri bildirim puanları, ürün özellikleri, görsel galerileri ve varyant verileri.
Tek Bir Ürün İlanı Sayfasını Ayrıştırma
eBay ürün sayfaları /itm/<ITEM_ID> yolunda yer alır. En kararlı çıkarım yolu JSON-LD’dir — eBay, neredeyse tüm CSS değişimlerinden sağ çıkan bir Product şema bloğu yerleştirir:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — en kararlı çıkarım yolu
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. JSON-LD’de olmayan alanlar için CSS yedekleri
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Ürün özellikleri
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemBuradaki kalıp — önce JSON-LD, sonra CSS yedekleri — her çeyrekte bozulmayan kazıyıcılar kurmanın anahtarıdır. Birazdan daha ayrıntılı anlatacağım.
eBay Ürün Varyantlarını Kazımak (MSKU Verisi)
Bazı eBay ilanlarında birden fazla varyant bulunur — farklı renkler, bedenler, depolama kapasiteleri gibi. Görünen DOM, kullanıcı bir seçenek seçene kadar yalnızca “$899 ile $1,099” gibi bir fiyat aralığı gösterir. Her varyanta ait gerçek fiyatlandırma ise MSKU adı verilen gizli bir JavaScript nesnesinde saklanır.
Bu, eBay API’sinin yalnızca kısmi veri (üst SKU) sunduğu alanlardan biridir; bu yüzden kazıma çoğu zaman daha iyi bir çözüm olur.
1import re, json
2def extract_variants(html):
3 # Açgözlü olmayan eşleşme kritik — açgözlü .+ tüm sayfayı yutar
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusRegex’deki bu açgözlü olmayan (.+?) kısmı neredeyse her eBay kazıyıcısının tökezlediği nokta. Açgözlü .+, sayfadaki son "QUANTITY" ifadesine kadar her şeyi yutar ve bozuk JSON üretir. “Çalışıyor” denilen en az üç rehberde bu hatayı gördüm.
eBay Satılmış ve Tamamlanmış İlanlar Python ile Nasıl Kazınır?
API yerine kazımayı haklı çıkaran kullanım senaryosu budur. Gerçekten satılan ürün verisi — ne satıldı, hangi fiyata, hangi tarihte — pazar araştırması, ikinci el fiyatlama ve ekspertiz için altın standarttır. eBay Browse API bunu açıkça sunmaz. teknik olarak sunabilir, ancak erişim “Sınırlı Yayın” kapsamındadır ve .
İhtiyacın olan URL parametreleri LH_Complete=1 (tamamlanmış ilanlar) ve LH_Sold=1 (gerçekten satılanlarla sınırla) parametreleridir. İkisini birden göndermelisin. Yalnızca LH_Sold=1 kullanmak bazı kategorilerde sessizce aktif ilanlara döner — toplulukta en sık yapılan hatalardan biri budur.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Satılmış ilanlar için sayfa {page_num} kazınıyor...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Yalnızca gerçekten satılmış ürünleri dahil et (yeşil POSITIVE fiyatı)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Satılmamış tamamlanmış ilan — geç
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Satış tarihini ayrıştır
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldHTML’deki temel fark şudur: satılmış ürünler fiyatı yeşil renkte (.POSITIVE sarmalayıcısı içinde) gösterir; satılmamış tamamlanmış ilanlarda ise fiyat kırmızı üstü çizili görünür. Her zaman .POSITIVE sınıfına göre filtreleyin.
eBay Kazıyıcıları Neden Bozulur? (Ve Nasıl Dayanıklı Hale Getirilir?)
eBay kazıyıcın çalışmayı bıraktıysa, yalnız değilsin. Okuduğum her eBay kazıma forumunda bu en büyük sorun. Soru, kazıyıcının bozulup bozulmayacağı değil — ne zaman bozulacağıdır.
Neden olur:
- eBay, dağıtım anlarında değişen dinamik sınıf adlarıyla React tabanlı render kullanır
- A/B testleri farklı kullanıcılara farklı DOM yapıları gösterir (şu anda çift
s-item/s-carddüzeni bunun canlı örneği) - Periyodik site yenilemeleri, veri aynı kalsa bile HTML yuvalanmasını değiştirir
#itemTitleve#prcIsumgibi eski seçiciler yıllar önce kaldırıldı ama hâlâ bazı rehberlerde yer alıyor
ifadesiyle: “eBay web kazımasındaki gerçek zorluk, eBay’in CSS seçici değişimlerini yönetmektir. eBay ön yüzünü düzenli olarak günceller ve belirli sınıf adlarına güvenen kazıyıcıları bozar.”
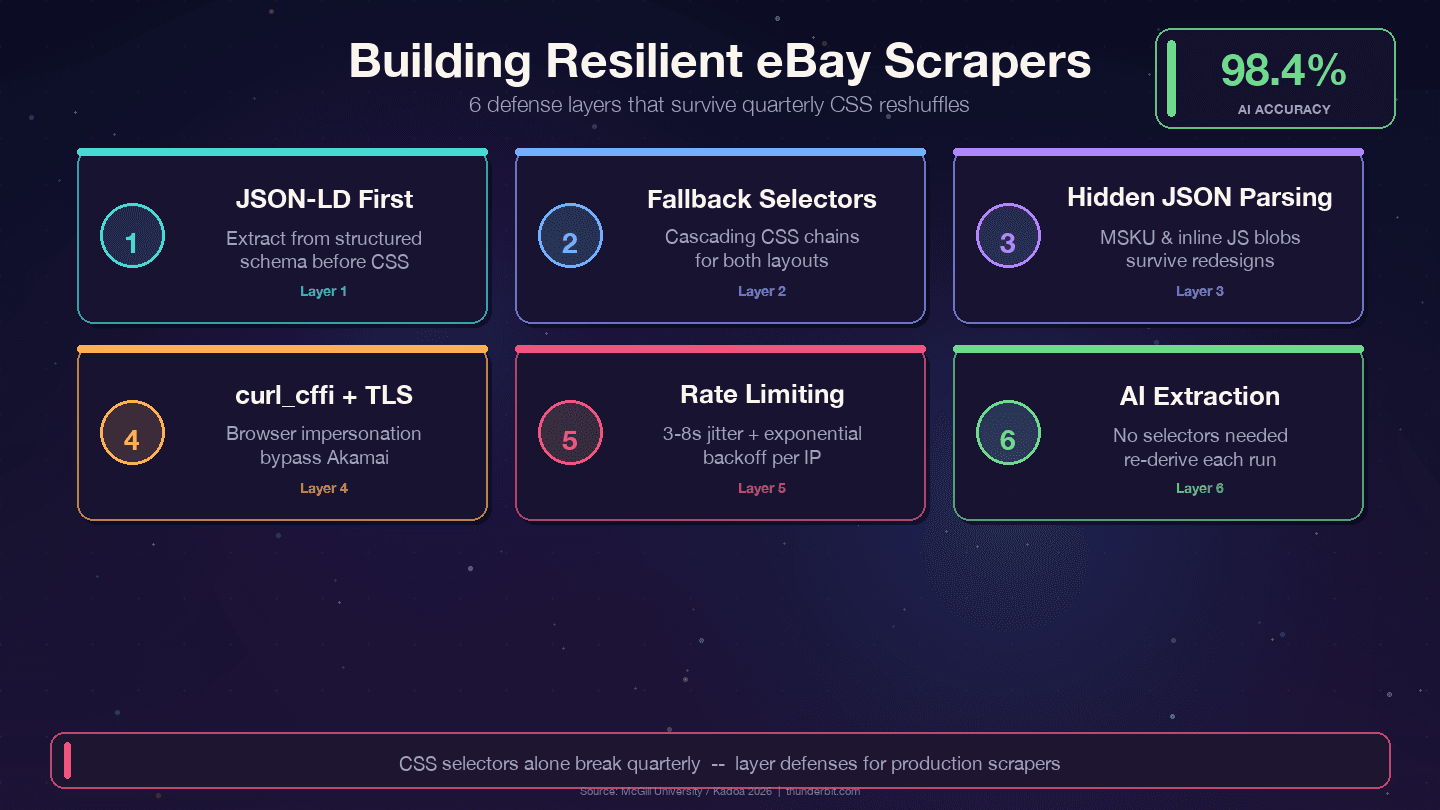
Uzun Ömürlü eBay Kazıyıcılar İçin Savunma Stratejileri
eBay’in üç aylık değişimlerine dayanabilen dört strateji:
1. CSS seçiciler yerine JSON-LD’yi önceliklendirin. eBay, her ürün sayfasına yapılandırılmış Product şema verisi yerleştirir. Veri katmanı, sunum katmanına göre çok daha az değişir — tasarımcılar CSS sınıflarını her çeyrek yeniden düzenler, ama price, name ve seller gibi arka uç alan adları iç API’lerle eşleşir ve nadiren değişir.
2. Kademeli yedek seçiciler kullanın. Tek bir CSS seçiciye asla güvenmeyin. Her zaman alternatifler sağlayın:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Gizli JSON bloklarını ayrıştırın. MSKU varyant nesnesi ve satır içi JavaScript verileri CSS değişikliklerinden etkilenmez çünkü sunucu tarafında üretilir. <script> etiketlerinden regex ile veri çekmek ilk başta biraz daha emek ister ama bakım yükünü ciddi biçimde azaltır.
4. Seçici hatalarını loglayın. Hangi anda bir seçicinin eşleşmeyi bıraktığını anlamak için izleme ekleyin; sadece verinin boş kaldığını fark etmek yeterli değildir:
1if title is None:
2 print(f"UYARI: title seçicisi başarısız oldu: {url}")5. Tarayıcı taklidiyle curl_cffi kullanın. Bu, headless browser gerektirmeden Akamai’nin TLS parmak izini aşmana yardımcı olur.
Yapay Zeka Destekli Alternatif: Seçici Bakımı Yok
Seçicileri birkaç ayda bir yamalamaktan yorulduysan, temelde farklı bir yaklaşım vardır. gibi araçlar sayfayı her seferinde yeniden okur ve çıkarım mantığını o an oluşturur. McGill Üniversitesi’nin yaptığı bir çalışma, 3.000 sayfa üzerinde AI ve seçici tabanlı kazıyıcıları karşılaştırdı ve gösterdi; sektör ölçümleri de olduğunu belirtiyor.
| Yaklaşım | eBay HTML değişince bozulur mu? | Bakım eforu |
|---|---|---|
| Sabit kodlanmış CSS seçiciler | Evet, üç ayda bir | Yüksek — sürekli düzeltme |
| Gizli JSON / JSON-LD çıkarımı | Nadiren | Düşük |
| AI tabanlı kazıma (Thunderbit) | Hayır — AI her çalıştırmada seçicileri yeniden türetir | Yok |
Thunderbit iş akışını ileride ayrıntılı anlatacağım. Şimdilik çıkarım şu: Aylarca çalıştırmayı planladığın bir kazıyıcı kuruyorsan, JSON öncelikli çıkarım ve yedek seçicilere yatırım yap. Seçicilerle hiç uğraşmak istemiyorsan, AI yaklaşımı kesinlikle değerlendirilmeye değer.
Tekrarlayan eBay Kazılarını Fiyat Takibi İçin Nasıl Otomatikleştirirsiniz?
Tek seferlik kazıma faydalıdır. Ancak fiyat takibi, stok izleme ve rakip analizi düzenli veri toplama gerektirir. İncelediğim neredeyse her rakip yazı fiyat takibini bir kullanım alanı olarak anıyor ama bunu gerçekten nasıl otomatikleştireceğini pek göstermiyor.
Seçenek 1: Cron Job’lar (Linux/macOS) veya Task Scheduler (Windows)
En basit yöntem budur. Python scriptini bir cron job içine alın. Her zaman sanal ortamındaki Python’ın tam yolunu kullanın — cron minimum bir ortamda çalışır:
1crontab -e
2# Her gün 08:15’te
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Windows’ta PowerShell kullanın:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TBu yöntem sürekli açık bir makine gerektirir ve proxy ile anti-bot önlemlerini kendin yönetirsin.
Seçenek 2: Bulut Fonksiyonları (Serverless)
AWS Lambda veya Google Cloud Functions, ayrı bir sunucu olmadan kazıyıcı çalıştırmana izin verir. Kurulum eforu daha yüksektir — bağımlılıkları paketlemen, zaman aşımı sınırlarını yönetmen (Lambda 15 dakika ile sınırlı) ve proxy’leri yine kontrol etmen gerekir. Ama sunucu bakımı yapmazsın.
Seçenek 3: Thunderbit ile Kodsuz Zamanlama
Scheduled Scraper özelliği, aralığı düz dille tanımlamana (“her gün sabah 8’de” gibi), eBay URL’lerini girip Zamanla’ya tıklamana izin verir. Dahili anti-bot desteğiyle bulutta çalışır.
| Yaklaşım | Kurulum Eforu | Sunucu Gerekir mi? | Anti-Bot Yönetir mi? |
|---|---|---|---|
| Cron + Python script | Orta | Evet (sürekli açık makine) | Proxy’leri siz yönetirsiniz |
| Bulut fonksiyonu (Lambda) | Yüksek | Hayır (serverless) | Proxy’leri siz yönetirsiniz |
| Thunderbit Scheduled Scraper | Düşük (metinle anlatılır) | Hayır (bulut tabanlı) | Dahili |
Tekrarlayan kazıma verisini saklamak için, yerel SQLite veritabanı fiyat geçmişi açısından doğru çözümdür. INSERT OR REPLACE yerine ([foreign key’leri bozar ve sütunları siler](https://www.sqlitetutorial.net/sqlite-upsert/)) ON CONFLICT ... DO UPDATE kullanın:
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Kod Yazmak İstemiyor musunuz? Thunderbit ile eBay’i 2 Dakikada Nasıl Kazırsınız
Şimdiye kadar Python koduna binlerce kelime ayırdım. Şimdi ise ne zaman buna ihtiyacın olmadığını dürüstçe söylemek istiyorum.
Tek seferlik pazar araştırması yapan bir iş kullanıcısıysan, benzer fiyat karşılaştırması yapan bir ikinci el satıcısıysan ya da bugün veriye ihtiyaç duyan bir e-ticaret ekibin varsa, Python çoğu zaman gereğinden fazladır. Kurulum, seçici bakımı, proxy yönetimi — “sadece bu 200 ilanı bir tabloya almak istiyorum” için çok fazla ek iş oluşturur.
Thunderbit eBay’i Nasıl Kazır? Adım Adım
- yükleyin — kredi kartı gerekmez.
- Chrome’da herhangi bir eBay arama sonucuna veya ürün sayfasına gidin.
- Thunderbit kenar çubuğunda “AI Suggest Fields” düğmesine tıklayın. AI sayfayı okur ve şu sütunları önerir: Başlık, Fiyat, Ürün Durumu, Kargo, Satıcı, Puan.
- “Scrape” düğmesine tıklayın. Eklenti sayfalama boyunca ilerler ve veri tablosunu doldurur. Özellikle eBay için Thunderbit’te tek tıkla çalışan vardır.
- Veriyi ücretsiz olarak Google Sheets, Airtable, Notion, CSV, JSON veya Excel formatına dışa aktarın.
Tüm işlem 2 dakikadan kısa sürer.
Bunu ölçtüm.
Alt Sayfa Zenginleştirme: Ek Kod Olmadan Detay Sayfası Verisi Alın
Bir arama sonuçları sayfasını kazıdıktan sonra Thunderbit, her ilanın detay sayfasına gidip ek alanları ekleyebilir — tam teknik özellikler, satıcı bilgisi, açıklama, tüm görseller. Bu, biraz önce yazdığımız 20+ satırlık Python alt sayfa kazıma kodunu tek bir tıklamayla değiştirir.
Python’u Hâlâ Ne Zaman Kullanmalısınız?
Python şu durumlarda kazanır:
- Büyük ölçekli kazıma (çalıştırma başına on binlerce sayfa)
- Derin özelleştirilmiş ayrıştırma mantığı veya veri dönüştürme
- Mevcut veri boru hatlarına entegrasyon (Airflow, dbt, Kafka)
- Gelişmiş anti-bot işler için ince ayarlı TLS/oturum kontrolü
- Birim ekonomi — milyonlarca satır seviyesinde, bakımı yapılmış bir yığın abonelik tabanlı SaaS’tan daha verimli olabilir
Çoğu tek seferlik veya orta ölçekli proje için Thunderbit daha hızlı ve kullanımı kolaydır. Ölçekli üretim boru hatları için Python sana tam kontrol sağlar.
Python ile eBay Kazırken Engellenmemek İçin İpuçları
eBay’in Akamai katmanı gerçektir. Pratikte işe yarayanlar şunlardır:
impersonate="chrome124"ilecurl_cffikullanın — bu, düzrequests’e göre en büyük tek iyileştirmedir- Kullanıcı Aracısı (User-Agent) dizelerini mevcut tarayıcı sürümlerinden oluşan bir listeden döndürün (Chrome 143, Firefox 124, Safari 26)
- İstekler arasında ekleyin — sabit aralıklar bir parmak izidir
- Birkaç düzine sayfayı aşan işler için residential veya rotating proxy kullanın. Datacenter IP’leri (AWS, GCP, DigitalOcean) Akamai tarafından hızlıca işaretlenir.
- robots.txt’ye saygı gösterin — filtrelenmiş çoğu browse URL’si açıkça Disallow edilir; ürün detay sayfaları (
/itm/<id>) ise edilmez - CAPTCHA’ları nazikçe yönetin — tespit edip farklı bir IP ile yeniden deneyin ya da CAPTCHA çözüm hizmeti kullanın
- Sunucuya yüklenmeyin. kararı, kazıma sunucuları gerçekten yavaşlattığında trespass to chattels ilkesinin uygulanabildiğini gösterir. IP başına saniyede 1 istekte kalmak seni bu sınırın oldukça altında tutar.
Yüksek hacimli ticari kullanım için, aktif ilanlarda Browse API’yi; yalnızca satılmış benzer fiyatlar ve API’nin sunmadığı veriler için hedefli kazımayı düşünün. Bu hibrit yaklaşım teknik ve hukuki açıdan daha temizdir.
Python ile eBay Kazımak Yasal mı?
Avukat değilim; bu blog yazısı da hukuki tavsiye değildir. O yüzden kısa tutacağım.
Hukuki ortam, kamuya açık verilerin kazınması lehine değişti. Temel emsaller:
- (9. Bölge, 2022): herkese açık verilerin kazınması CFAA’yı ihlal etmez
- Van Buren v. United States (ABD Yüksek Mahkemesi, 2021): CFAA’daki “yetkili erişimi aşma” hükmünü daralttı
- (N.D. California, 2024): oturum kapalıyken yapılan kazıma platformun kullanım şartlarını ihlal etmez, çünkü kazıyıcı bir “kullanıcı” değildir
Bununla birlikte, eBay’in açıkça “buy-for-me agent’ları, LLM destekli botlar veya insan incelemesi olmadan sipariş vermeye çalışan uçtan uca akışları” yasaklıyor. Çizgi net: kamuya açık sayfaların salt-okuma amaçlı kazınması sağlam bir zeminde; checkout sürecini otomatikleştirmek ise değil.
En iyi uygulamalar: yalnızca herkese açık verileri kazıyın. Sahte hesap oluşturmayın veya giriş duvarlarını aşmayın. Telifli ilan görsellerini topluca yeniden satmayın. Ve ticari ölçekli projeler için hukuki danışmanlık alın.
Sonuç ve Öne Çıkanlar
Python, eBay’i kazımanın en esnek yoludur; ancak sitenin HTML’si değiştikçe sürekli bakım gerektirir. Karar çerçevesi şöyle:
- Aktif ilanlarda kararlı, orta hacimli ve yapılandırılmış sorgular için eBay Browse API’yi kullanın
- Satılmış ilanlar, yorumlar, varyant verileri ve API’nin sunmadığı alanlar için Python kazımayı kullanın
- Kod yazmadan eBay verisi istiyorsanız kullanın
Bu rehberdeki kod, dayanıklılığı önceleyerek yazıldı: önce JSON-LD çıkarımı, sonra kademeli CSS yedekleri, varyantlar için gizli JSON ayrıştırması. Bu katmanlı yaklaşım sayesinde kazıyıcınız, eBay ön yüz ekibi bir tasarım yenilemesi yayınladığında hemen ölmez.
Kodsuz yolu denemek istersen, ile bunu hemen eBay sayfalarında test edebilirsin. nasıl çalıştığını görmek istersen, tek tık uzaktasın.
Web kazıma araçları hakkında daha fazla bilgi için , ve rehberlerimize göz atın. Ayrıca üzerindeki eğitim videolarını da izleyebilirsiniz.
SSS
1. Python ile eBay’i ücretsiz kazıyabilir miyim?
Evet. Tüm kütüphaneler (Requests, BeautifulSoup, curl_cffi, pandas) ücretsiz ve açık kaynaklıdır. Maliyet ölçek büyüdüğünde ortaya çıkar — yüksek hacimli kazıma için residential proxy’ler genellikle bant genişliğine bağlı olarak aylık 50–500 dolar arasında değişir. Küçük projelerde (birkaç yüz sayfa) dikkatli oran sınırlamasıyla ev IP’nizden kazıma yapabilirsiniz.
2. Python ile eBay’de satılmış ilanları ve tamamlanmış listeleri nasıl kazırım?
eBay arama URL’nize LH_Complete=1&LH_Sold=1 parametrelerini ekleyin. İkisini birlikte göndermelisiniz — bazı kategorilerde yalnızca LH_Sold=1 kullanmak sessizce aktif ilanlara döner. Sonuçları, gerçek satışı gösteren ve satılmamış süresi dolmuş bir liste yerine geçen fiyat öğesindeki .POSITIVE CSS sınıfını kontrol ederek filtreleyin.
3. eBay web kazımayı engelliyor mu?
eBay, başlıca TLS parmak izi ve davranış analizi üzerinden kazıyıcıları tespit eden Akamai Bot Manager kullanır. Düz requests çağrıları çoğu zaman 403 yanıtı döndürür. Tarayıcı taklidiyle curl_cffi kullanmak, User-Agent döndürmek ve istekler arasında 3–8 saniyelik rastgele gecikmeler eklemek çoğu engeli aşar. Ölçek büyüdüğünde residential proxy’ler yardımcı olur.
4. eBay API’sini mi yoksa web kazımayı mı kullanmalıyım?
Aktif ilanlarda kararlı, orta hacimli sorgular için Browse API’yi kullanın (günde 5.000 çağrıya kadar). Satış fiyatı geçmişi, tam varyant/MSKU verisi, yorumlar veya API’nin sunmadığı herhangi bir alan gerektiğinde kazıma kullanın. Marketplace Insights API teknik olarak satılmış verileri sağlar, ancak erişim kısıtlıdır ve .
5. Kodsuz olarak eBay’i kazımanın en kolay yolu nedir?
, eBay sayfalarını okuyup veri sütunları önerir ve ilanları tek tıkla çıkarır. Sayfalama, alt sayfa zenginleştirme ve Google Sheets, Excel, Airtable veya Notion’a dışa aktarma işlemlerini de yapar. Hazır , yaygın kullanım senaryolarında işi daha da hızlandırır.
Daha Fazla Bilgi