

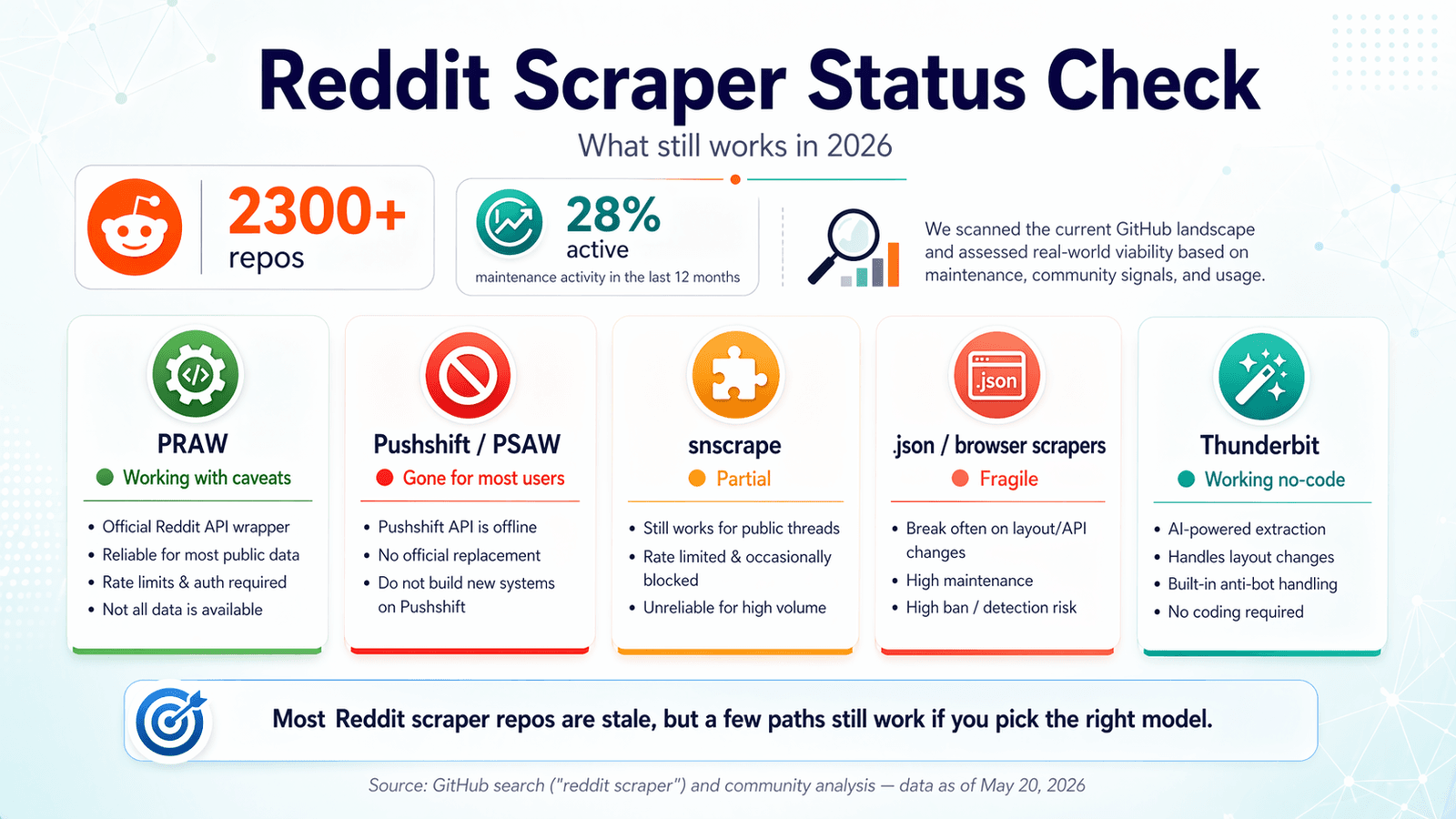
GitHub şu anda 2.300'den fazla Reddit scraper reposu gösteriyor. Kulağa açık büfe gibi geliyor. Ama işin aslı şu: bunların yalnızca yaklaşık %28’i son on iki ay içinde herhangi bir bakım faaliyeti göstermiş durumda. Son birkaç haftadır bu repoları inceleyerek, uç noktaları test ederek, issue kuyruklarını okuyarak ve Reddit’in kendi politika güncellemeleriyle çapraz kontrol yaparak geçirdim. Amacım, bir repo klonlayıp OAuth ile boğuşmaktan ve gece yarısı her şeyin 2024’te sessizce bozulduğunu fark etmekten sizi kurtarmak. 2026’da Reddit scraper GitHub manzarası, iyi niyet mezarlığı ile gerçekten çalışan birkaç aracın karışımından ibaret. Bu rehber; hangilerinin hâlâ çalıştığını, hangilerinin bozulduğunu, ne zaman kodu tamamen atlamak gerektiğini ve Reddit’in giderek sıkılaşan denetiminde nasıl doğru tarafta kalacağınızı kapsıyor. Kestirme bir yol arıyorsanız, Thunderbit tam da bu tür problemler için geliştirdiğimiz kodsuz seçenektir — ama kod tabanlı çözümlerin nerede hâlâ daha mantıklı olduğunu da dürüstçe anlatacağım.
Bir Reddit Scraper GitHub Reposu Nedir (Ve Neden Bu Kadar Çoğu Bozuk?)
Bir "reddit scraper github" reposu genellikle Reddit’ten gönderi, yorum, kullanıcı verisi veya medya çekmeyi otomatikleştiren açık kaynaklı bir Python (bazen de JavaScript) projesidir. Bunlar genelde dört gruba ayrılır:
- API sarmalayıcıları (PRAW gibi): Reddit’in resmî API’sini kullanır, OAuth ister ve Reddit’in kurallarına göre çalışır.
- Pushshift/PSAW tabanlı araçlar: tarihsel veri için Pushshift’in devasa Reddit arşivinden yararlanırdı.
- Herkese açık
.jsonuç nokta scraper’ları: Reddit URL’lerine.jsonekler veya kimlik doğrulaması olmadan herkese açık uç noktalara istek atar. - Tarayıcı tabanlı scraper’lar: Reddit sayfalarını yüklemek ve işlenmiş içeriği çıkarmak için Playwright, Selenium veya tarayıcı uzantıları kullanır.
Peki neden bu kadar çoğu bozuldu? Üç neden var.
- Reddit’in 2023 ortasındaki API fiyatlandırma değişikliği. Ücretsiz API sınırları, OAuth ile dakikada 100 sorguya ve OAuth olmadan yalnızca 10’a düştü. Daha yüksek ticari kullanım artık 1.000 API çağrısı başına 0,24 ABD doları tutuyor. Pek çok repo, API erişiminin neredeyse sınırsız olduğu bir dünyaya göre yazılmıştı — ve o dünya artık yok.
- Pushshift’in herkese açık erişimi kaldırıldı. Pushshift, tarihsel Reddit araştırmasının omurgasıydı. Reddit onu kısıtlayınca, "tarihsel scraper" repolarının büyük bir kısmı ana veri kaynağını kaybetti. Bazı README dosyaları bu araçları hâlâ çalışıyormuş gibi gösteriyor, ama sıradan kullanıcılar için alttaki bağımlılık artık yok.
- Reddit hem politikayı hem de uygulamayı sertleştirdi. 2024 robots.txt güncellemesi, 2025 Herkese Açık İçerik Politikası ve Mart 2026 Sorumlu Geliştirici Politikası, Reddit’in artık toplu scraping’i zararsız arka plan gürültüsü olarak görmediğini açıkça gösteriyor. Hatta izinsiz veri erişimi nedeniyle Anthropic ve SerpApi hakkında şikâyetlerde bulundular.
Özetle: "reddit scraper github" diye aradığınızda yüzlerce sonuç çıkar. Ama son commit tarihleri ve açık issue sayıları bambaşka bir hikâye anlatır.
2026 Reddit Scraper GitHub Durum Kontrolü: Hâlâ Ne Çalışıyor?
Rakip makalelerin çoğu 2023 veya 2024’te yazılmış ve bir daha güncellenmemiş. Forum kullanıcıları, bir yıl önce çalışan repolarda hata almaya devam ediyor — bir kullanıcının, "Reddit API limit hatasına takılıp duruyorum :\ Bunu nasıl aşabilirim?" diye yalvarması, aslında 2026 Reddit scraper deneyiminin özeti gibi.
Nisan 2026 itibarıyla bir güncellik denetimi yaptım. Bulduklarım şöyle.
PRAW: Resmî Python Sarmalayıcısı
Durum: ✅ Hâlâ çalışıyor, ama bazı kısıtlarla.
PRAW (Python Reddit API Wrapper), Reddit scraping için en güvenilir açık kaynak temel olmaya devam ediyor. Aktif olarak bakım görüyor — 4.099 yıldız, son push 20 Nisan 2026, yalnızca 6 açık issue ve PyPI’de praw 7.8.1 listeleniyor (Ekim 2024 sürümü).
Güçlü yönleri: Resmî, iyi belgelenmiş, Reddit API karmaşıklığının çoğunu soyutluyor.
2026 sınırlamaları:
- Daha sıkı OAuth gereksinimleri. Onaylanmış kullanım senaryosu açıklaması olan kayıtlı bir Reddit uygulamasına ihtiyacınız var.
- 2024’ten beri daha düşük oran sınırları (OAuth ile 100 sorgu/dk, OAuth olmadan 10).
- Sert yaklaşık 1.000 gönderilik listeleme sınırı hâlâ geçerli. r/redditdev ve Stack Overflow’daki topluluk başlıkları şunu doğruluyor: bir listeleme uç noktasından 1.000’den fazla gönderi almak mümkün değil.
API’nin sınırları içinde kalabiliyorsanız PRAW en güvenli seçenektir.
Sadece artık serbest biçimli bir toplu scraper değil.
Resmî API yolunu pratik şekilde görmek istiyorsanız, şu eğitim bu bölüme iyi uyar:
Pushshift / PSAW: Karanlığa Gömülen Arşiv
Durum: ❌ Herkese açık erişim yok.
PSAW, tarihsel Reddit verisine ulaşmanın en kolay yolu olan Pushshift için başvurulan Python sarmalayıcısıydı. 2026’da repo arşivlenmiş durumda, README dosyasında kelimenin tam anlamıyla "THIS REPOSITORY IS STALE" yazıyor ve son açık issue’lar arasında "Pushshift.io UNABLE to connect" ve "The code not working. Possibly due to pushshift api." gibi inciler var.
Akademik erişim belirli kanallar üzerinden hâlâ mevcut olabilir, ama bugün "reddit scraper github" arayan biri için Pushshift/PSAW geçerli bir seçenek değil. Derin tarihsel Reddit verisine ihtiyacınız varsa, onaylı akademik veri erişimine veya lisanslı yollara bakmanız gerekir.
snscrape (Reddit Modülü): Kısmi ve Güvenilmez
Durum: ⚠️ Kısmi — ara sıra bozuluyor, büyük ölçüde bakım görmüyor.
snscrape 5.337 yıldız almış, ama son push 15 Kasım 2023’te yapılmış. README hâlâ Reddit scraping’in "via Pushshift" desteklendiğini söylüyor. Açık Reddit sorunları arasında "Error reddit scraping" ve "Reddit scraper returns no submissions before 2022-11-03" var; son dönemde anlamlı bir onarım faaliyeti görünmüyor.
Bazı ortamlarda küçük, tek seferlik çekimler için işe yarayabilir, ama üretim ortamı veya tekrar eden scraping işleri için güvenilir değil. Onu eski nesil bir araç olarak düşünün.
Playwright ve .json Uç Nokta Scraper’ları: İşe Yarayabilen Geçici Çözüm
Durum: ✅ Çalışıyor, ama kırılgan.
Buradaki fikir basit: Reddit sayfalarını yüklemek ve işlenmiş içeriği kazımak için başsız bir tarayıcı (Playwright, Puppeteer) kullanmak ya da resmî API olmadan yapılandırılmış veri almak için Reddit URL’lerine .json eklemek.
Güçlü yönleri: API anahtarı gerekmez, 1k gönderi sınırını aşabilir, işlenmiş içeriğe erişebilir.
Zayıf yönleri: Reddit ön yüz düzenini veya JSON yapısını değiştirdiğinde bozulur, bot karşıtı önlemleri tetikleyebilir ve daha fazla teknik kurulum ister. Bu ay kendi testlerimde, herkese açık Reddit .json uç noktalarına doğrudan istekler 403 yanıtı döndürdü. Bu, her ortamın engelleneceği anlamına gelmez, ama .json kestirmesinin artık "sadece çalışır" diye varsayılacak bir şey olmadığını gösterir.
yars gibi repolar bu konuda şaşırtıcı derecede dürüst: README, kullanıcılara "Use with rotating proxies, or Reddit might gift you with an IP ban." uyarısını yapıyor. Nisan 2026 hikâyesi tek cümlede tam olarak bu.
Tarayıcı otomasyonuna dayalı geçici çözüm yolunu değerlendiriyorsanız, aşağıdaki bölüme iyi bir eşlikçi olan Playwright eğitimine göz atın:
Thunderbit: Yapay Zekâ Destekli Tarayıcı Scraping’i (Kod Yok, API Anahtarı Yok)
Durum: ✅ Çalışıyor — sayfa değişikliklerine otomatik uyum sağlar.
Thunderbit temelden farklı bir yaklaşım kullanır. Reddit sayfalarını okumak, veri alanları önermek (gönderi başlığı, yazar, upvote, zaman damgası, URL vb.) ve iki tıklamayla yapılandırılmış veri çıkarmak için AI kullanan bir Chrome Uzantısıdır. OAuth kurulumu yok, API anahtarı kaydı yok, Python ortamı yok, bağımlılık yönetimi yok. Yapay zekâ sayfayı her seferinde yeniden okur; böylece Reddit düzenini değiştirdiğinde Thunderbit sessizce bozulmak yerine otomatik uyum sağlar.
CSV, Google Sheets, Airtable veya Notion’a ücretsiz dışa aktarma. Sayfalama ve alt sayfa scraping’i destekler (örneğin bir subreddit listesini çekip sonra her gönderiyi ziyaret ederek yorumları alma). GitHub reposu bakımını üstlenmeden Reddit verisi isteyen kitle için bu, en az direnç gerektiren yoldur.
(Tam açıklama: Thunderbit’i biz geliştirdik, dolayısıyla biraz taraflıyım — ama bu makalenin ilerleyen kısımlarında kod tabanlı çözümlerin nerede hâlâ daha mantıklı olduğunu açıkça anlatacağım.)
Yan Yana Durum Özeti Tablosu
| Araç / Kategori | Hâlâ Çalışıyor mu (Nisan 2026)? | API Anahtarı Gerekli mi? | Notlar |
|---|---|---|---|
| PRAW | ✅ Evet, bazı kısıtlarla | Evet (OAuth) | En iyi bakım gören açık kaynak temel. Oran sınırları ve 1k gönderi limitiyle kısıtlı. |
| Pushshift / PSAW | ❌ Hayır (çoğu kullanıcı için) | Yok | Herkese açık erişim yok. Repo arşivlendi. |
| snscrape (Reddit modülü) | ⚠️ Kısmi / güvenilmez | Hayır | Reddit’i hâlâ "via Pushshift" olarak belgeliyor. Bakım 2023’ten beri durmuş durumda. |
| .json / herkese açık uç nokta scraper’ları | ⚠️ Kısmi | Hayır | Çalışabilir, ama doğrudan istekler giderek daha çok engelleniyor. Proxy’ye bağımlı. |
| Playwright / tarayıcı scraper’ları | ✅ Evet, ama kırılgan | Genelde hayır | API’siz DIY çözüm için en uygulanabilir seçenek. Sayfa değişiklikleri ve bot kontrolleri hâlâ önemli. |
| Thunderbit | ✅ Evet | Hayır | AI/tarayıcı iş akışı. OAuth yok, selector yok. Teknik bilgisi olmayanlar için en uygun seçenek. |
Oran Sınırları, 1k Gönderi Limiti ve Gerçekte Ne Yardımcı Oluyor?
Bu, bir reddit scraper github projesi kullanan herkes için en büyük acı noktası. Forum başlıkları şu tür yakınmalarla dolu: "oran sınırları yüzünden çalıştırmaların yarıda ölmesinden bıktım", "Neden yalnızca yaklaşık 1.000 öğe alabiliyorum?" Temel iki kısıt var: Reddit’in API oran sınırları (dakikadaki istek sayısı) ve yaklaşık 1.000 gönderilik listeleme limiti (API, bir listeleme uç noktasından yalnızca en güncel yaklaşık 1.000 gönderiyi döndürür).
Oran Sınırı Yönetimi İçin En İyi Uygulamalar
Reddit’in güncel herkese açık temeli: OAuth ile dakikada 100 sorgu, OAuth olmadan 10. Pratikte bunu şöyle yönetebilirsiniz:
- Üstel geri çekilme. Oran sınırı yanıtı alırsanız bekleyin ve her seferinde daha uzun gecikmeyle yeniden deneyin (1 sn, 2 sn, 4 sn, 8 sn…). Uç noktayı art arda zorlamayın.
X-Ratelimit-Remainingbaşlıklarını okuyun. Reddit API yanıtları, kaç isteğiniz kaldığını ve pencerenin ne zaman sıfırlanacağını gösteren başlıklar içerir. İsteklerinizi tahmine göre değil, bu değerlere göre hızlandırın.- Dönen user-agent’lar. Bazı repolar bunu tespitten kaçınmak için önerir. Yardımcı olabilir, ama etik kullanın — hak ettiğiniz yasaklardan kaçmak için kullanmayın.
- Her şeyi kaydedin. API yanıtları, oran sınırı başlıkları ve hatalar için loglama ekleyin. Scraper’ınız sabaha karşı 2’de öldüğünde loglar en iyi dostunuzdur.
1.000 Gönderi Tavanını Aşmak
API’nin yaklaşık 1.000 öğelik listeleme limiti için en güvenilir geçici çözüm zaman penceresi parçalamadır:
beforeveafterzaman damgası parametrelerini kullanarak bir zaman dilimini sorgulayın.- Pencereyi ileriye ya da geriye kaydırın.
- Tekrarlayın.
- Gönderi kimliğine göre tekrarları ayıklayın.
Bu şık değil, ama tek bir istek döngüsünün listeleme uç noktasından sınırsız geçmiş çekebileceği gibi davranmaktan daha dürüst. Gerçek tarihsel veri için onaylı akademik erişim veya lisanslı bir yol gerekir — Pushshift artık varsayılan cevap değil.
Tarayıcı tabanlı scraping (Playwright veya Thunderbit), sayfada işlenen içeriği kazıdığı için bu sınırı tamamen devre dışı bırakır; API’nin döndürdüğü şeyle sınırlı kalmaz. Thunderbit’in sayfalama özelliği, istediğiniz kadar sayfa arasında gezip veri toplamanıza izin verir.
Tekrarları Ayıklama ve Hata Kurtarma
Çoğu reddit scraper github reposu, tekrar ayıklama veya hata kurtarmayı kutudan çıktığı hâliyle sunmaz. Kullanıcılar açıkça "hiçbirinde deduping, hata sonrası oran sınırından kaçınma, dosyaların zaten indirilip indirilmediğini kontrol etme yoktu" diye şikâyet ediyor. Yapmanız gerekenler:
- Tekrar ayıklama: Her gönderinin kimliğini (veya kimlik + içerik) hash’leyin. Görülen hash’leri basit bir SQLite veritabanında veya düz bir dosyada saklayın. Eklemeden önce hash’in zaten olup olmadığını kontrol edin. Bu, özellikle zaman pencerelerini parçalıyorsanız veya başarısız işleri yeniden çalıştırıyorsanız çok önemlidir.
- Hata kurtarma: Her N kayıttan sonra ilerlemeyi bir checkpoint dosyasına kaydedin. İş başarısız olursa, baştan başlamak yerine son checkpoint’ten devam edin. Bu, 2. saatte ölen 3 saatlik bir işi 1 saatte devam ettirilebilir hâle getirir.
Farklı Yaklaşımlar Bu Kısıtları Nasıl Yönetiyor?

| Yaklaşım | Oran Sınırı Yönetimi | >1k Gönderi? | Otomatik Tekrar Ayıklama? | Hata Kurtarma? |
|---|---|---|---|---|
| PRAW (ham) | Manuel (bekle/tekrar dene) | ❌ (API limiti) | ❌ | ❌ |
| PRAW + zaman penceresi parçalama | Manuel | ✅ (geçici çözüm) | ❌ | ❌ (siz eklemezseniz) |
| Playwright .json scraping | Yok (API yok) | ✅ | ❌ | ❌ |
| Thunderbit (tarayıcı scraping) | Yerleşik (AI hız ayarı) | ✅ (sayfalama) | N/A (görsel inceleme) | Yerleşik |
Bir Reddit Scraper GitHub Reposu Cevap Değilse: Kodsuz Yol
Çoğu reddit scraper github makalesi Python bilgisi varsayar. Ama Reddit scraping çözümü arayanların çoğu pazarlamacılar, satış temsilcileri, araştırmacılar veya her gün Python yazmayan bağımsız kurucular. Bu kitle için bir GitHub reposu gizli maliyetler ekler:
- OAuth kimlik bilgilerini ve bir Reddit geliştirici uygulamasını kurmak
- Python sanal ortamlarını ve bağımlılık çakışmalarını yönetmek
- PRAW’ın iç yapısı değiştiğinde anlaşılmaz hata mesajlarını ayıklamak
- Reddit kullanım senaryonuzu onaylamazsa API anahtarı iptaliyle uğraşmak
- Reddit bir şeyi her değiştirdiğinde betiği bakımda tutmak
Bunlar varsayım değil. bulk-downloader-for-reddit 2.563 yıldız ve 107 açık issue’ya sahip. Son raporlar arasında "Struggling to install," "PRAW module error," ve "Exception not allowing to even authenticate." gibi sorunlar var.
Şu Durumlarda GitHub Reposu Kullanın...
- Özel scraping mantığına ihtiyacınız varsa (örneğin belirli yorum ağacı gezintisi, özel NLP boru hattı entegrasyonu).
- Mevcut bir Python veri hattına entegre etmek istiyorsanız.
- Özel depolama ile çok yüksek ölçekte scraping yapmanız gerekiyorsa (veritabanı, veri ambarı).
- Kodu sürdürmekten ve kırılma değişiklikleriyle uğraşmaktan rahatsanız.
Şu Durumlarda Kodsuz Araç Kullanın...
- Reddit verisine hızlıca, kurulum için saatler harcamadan ihtiyacınız varsa.
- API anahtarları, OAuth uygulamaları veya Python ortamları yönetmek istemiyorsanız.
- Hemen kullanım için doğrudan elektronik tablolara, Notion’a veya Airtable’a dışa aktarmak istiyorsanız.
- Reddit’in düzeni değiştiğinde aracın otomatik uyum sağlamasını istiyorsanız.
Thunderbit tam olarak kodsuz tarafta yer alır. Kullanıcılar AI’nın önerdiği alanlarla Reddit gönderilerini, yorumlarını ve kullanıcı verilerini 2 tıklamayla scrape edebilir, ücretsiz olarak CSV/Google Sheets/Airtable/Notion’a dışa aktarabilir ve kod yazmadan sayfalama işlemlerini yönetebilir. Tarayıcı tabanlı scraping, OAuth kurulumu ve API anahtarı kaydı gerektirmez.
Hızlı Uygulama: Thunderbit ile Reddit Scraping (Adım Adım)
- Thunderbit Chrome Uzantısını yükleyin.
- Kazımak istediğiniz Reddit sayfasına gidin (subreddit, arama sonuçları, kullanıcı profili).
- "AI Suggest Fields"e tıklayın. Thunderbit sayfayı okur ve sütunlar önerir — gönderi başlığı, yazar, upvote, zaman damgası, URL vb.
- Gerekiyorsa alanları düzenleyin, sonra "Scrape"e tıklayın.
- Veri tablosunu inceleyin. İsteğe bağlı olarak her gönderiyi ziyaret edip yorumları veya ek ayrıntıları çekmek için "Scrape Subpages"e tıklayın.
- Dışa aktarın istediğiniz hedefe: Google Sheets, Excel, Airtable, Notion, CSV veya JSON.
İki dakika. Sıfır satır kod. Nasıl çalıştığını görmek isterseniz, Thunderbit YouTube kanalına göz atın.
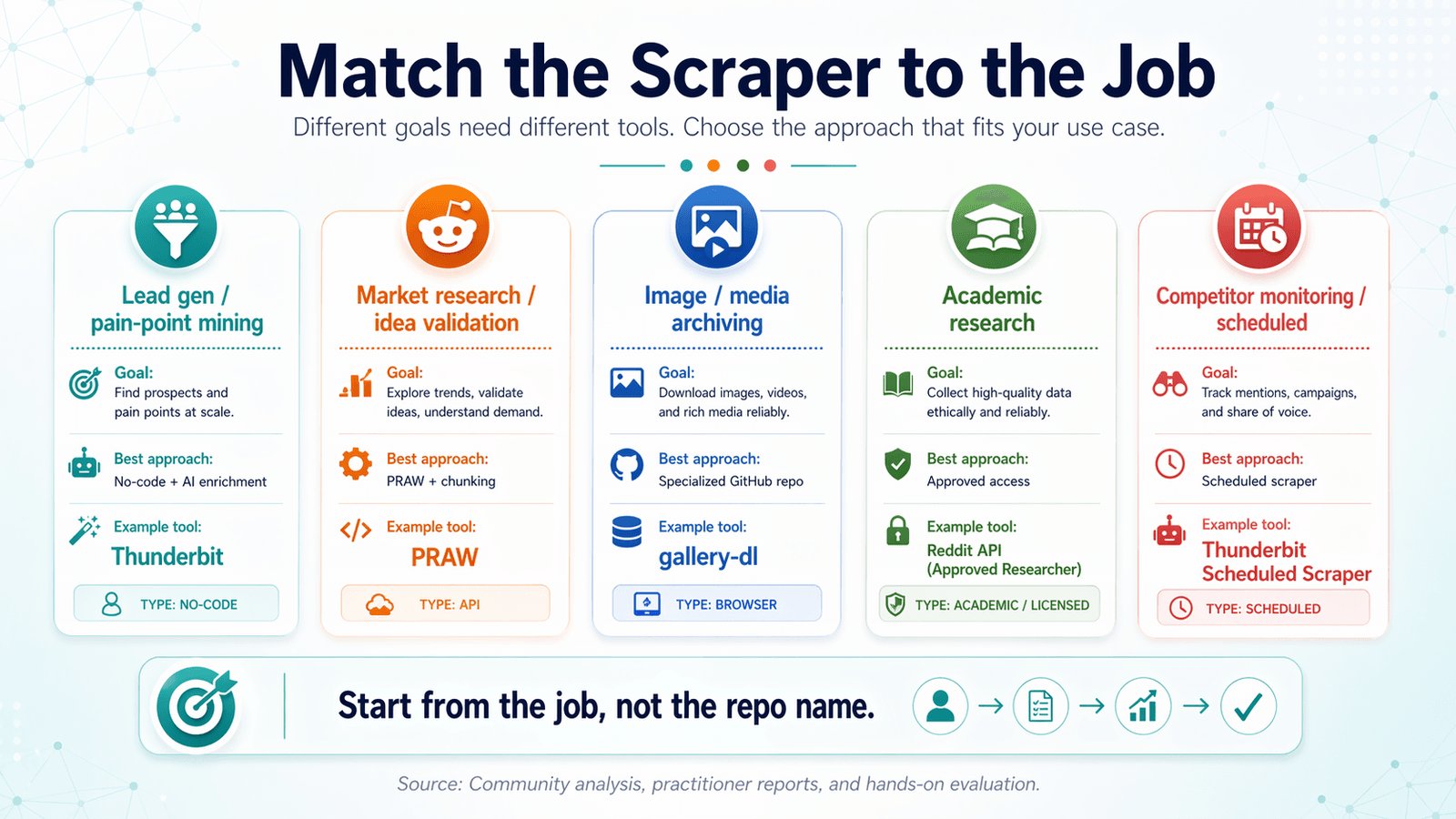
İşe Göre Doğru Reddit Scraper’ı Eşleştirin: Kullanım Senaryosu Karar Matrisi
Çoğu reddit scraper github makalesi araçlara göre düzenlenir. Bu yanlış yaklaşımdır.
Önce hedefinizden başlayın ve doğru aracı geriye doğru belirleyin.
Lead Oluşturma ve Acı Noktası Analizi
İhtiyacınız olan şey: Anahtar kelime filtreleme, AI etiketleme/sınıflandırma, CRM’e hazır formatlara dışa aktarma ile gönderiler + yorumlar.
En iyi yaklaşım: AI zenginleştirmeli kodsuz scraper.
Önerilen araç: Thunderbit (AI etiketleme + CRM içe aktarması için Google Sheets/Airtable’a dışa aktarma).
Örnek iş akışı: Belirli bir acı noktası hakkında konuşan gönderiler için bir subreddit’i scrape edin. Duyguyu sınıflandırmak veya konuları etiketlemek için Thunderbit’in Alan AI İstemini kullanın. Satış ekibinizin Airtable’ına veya Google Sheet’ine dışa aktarın.
Pazar Araştırması ve Fikir Doğrulama
İhtiyacınız olan şey: Yüksek hacimli gönderi başlıkları + puanlar, subreddit düzeyinde trend verisi.
En iyi yaklaşım: Hacim için zaman penceresi parçalama ile PRAW ya da hızlı çekimler için Thunderbit.
Örnek: Son 90 gündeki trend konular ve upvote desenleri için r/SaaS veya r/startups’ı scrape etmek.
Görsel ve Medya Arşivleme
İhtiyacınız olan şey: Medya URL’leri, tekrar ayıklama, zamanlanmış çalıştırmalar.
En iyi yaklaşım: Özel GitHub reposu (örneğin bulk-downloader-for-reddit) + cron işi.
Not: Burada tekrar ayıklama önemlidir — aynı görselin farklı subreddit’lerde paylaşılması yaygındır.
Akademik Araştırma ve Tarihsel Veri
İhtiyacınız olan şey: Tarihsel veri, tam yorum ağaçları, büyük veri kümeleri.
En iyi yaklaşım: Onaylı akademik erişim veya lisanslı veri yolu. Pushshift artık genel amaçlı cevap değil.
Gerçek durum: Pushshift kısıtlamaları ve Reddit’in sıkılaştırılmış veri politikaları nedeniyle 2026’da bu en zor kullanım senaryosudur.
Rakip İzleme ve Zamanlanmış Scraping
İhtiyacınız olan şey: Belirli aralıklarla tekrar eden scrape işlemleri, değişiklik tespiti.
En iyi yaklaşım: Thunderbit’in Scheduled Scraper özelliği (zaman aralığını düz İngilizceyle açıklayın, URL’leri girin, Schedule’a tıklayın) veya kod kullananlar için cron + betik.
Kullanım Senaryosu Karar Matrisi Tablosu
| Kullanım Senaryosu | İhtiyacınız Olan | En İyi Yaklaşım | Örnek Araç |
|---|---|---|---|
| Lead üretimi / acı noktası madenciliği | Gönderiler + yorumlar, anahtar kelime filtreleme, AI etiketleme | Kodsuz scraper + AI zenginleştirme | Thunderbit |
| Pazar araştırması / fikir doğrulama | Yüksek hacimli gönderi başlıkları + puanlar, subreddit düzeyi veri | PRAW + zaman penceresi parçalama veya Thunderbit | PRAW veya Thunderbit |
| Görsel/medya arşivleme | Medya URL’leri, tekrar ayıklama, zamanlanmış çalıştırmalar | Özel GitHub reposu + cron | bulk-downloader-for-reddit |
| Akademik araştırma | Tarihsel veri, tam yorum ağaçları | Onaylı akademik erişim veya Playwright | Pushshift akademik API (erişilebiliyorsa) |
| Rakip izleme / zamanlanmış | Tekrar eden scrape’ler, değişiklik tespiti | Zamanlanmış scraper | Thunderbit Scheduled Scraper veya cron + betik |
Bir Reddit Scraper GitHub Reposuna Bulaşmadan Önce Nasıl Değerlendirilir
Bir repoyu klonlayıp hata ayıklamaya başlamadan önce bu 5 dakikalık sağlık kontrolünü yapın. Saatler kazandırır.
5 Dakikalık Repo Sağlık Kontrolü
- Son commit tarihi. 6 aydan eskiyse dikkatli ilerleyin. Reddit API sık sık değişiyor.
- Açık issue / kapalı issue oranı. Cevaplanmamış issue’ların çokluğu kırmızı bayraktır. Son issue’larda kimlik doğrulama hataları, 403’ler veya Pushshift kesintileri geçiyor mu diye bakın.
- LICENSE dosyası. Var mı kontrol edin. Lisans yoksa hukuken belirsizdir (aşağıda daha fazlası var).
- Bağımlılıklar. Gerekli kütüphaneler güncel mi? Kullanım dışı kalmış paketler mi kullanıyor? 2022 sürümlerine sabitlenmiş bir
requirements.txtuyarı işaretidir. - README kalitesi. Kurulumu açıkça anlatıyor mu? Kullanım örnekleri var mı? Kötü dokümantasyon = sizin için daha fazla hata ayıklama süresi.
- Yıldızlar / fork’lar / son etkinlik. Yüksek yıldız ama düşük son etkinlik, projenin bir zamanlar popüler olup artık terk edildiği anlamına gelebilir. Yıldızları
pushed_attarihiyle karşılaştırın.
Kısa bir örnek: PSAW 364 yıldız almış — ilk bakışta güvenilir görünüyor. Ama repo arşivlenmiş ve README’de "THIS REPOSITORY IS STALE." yazıyor.
Yıldızlar tek başına hikâyeyi anlatmaz.
Reddit Scraper GitHub Kurulumunuzdan En Fazla Verimi Alma İpuçları
Kod yolunu seçerseniz, işte başınızı ağrıtmadan ilerlemenin yolları.
Her Zaman Sanal Ortam Kullanın
Sanal ortam, scraper’ınızın bağımlılıklarını izole eder; böylece başka Python projeleriyle çakışmaz. Tek komut: python -m venv venv ve bir şey kurmadan önce bunu etkinleştirin. Bu temel bir hijyen kuralı, ama "module not found" başlıklı yeterince GitHub issue gördüm ki bunu tekrar etmenin değerli olduğunu biliyorum.
Kimlik Bilgilerini Güvenli Saklayın
Reddit API client ID’nizi veya secret’ınızı asla betiğin içine gömmeyin. Ortam değişkenleri veya .env dosyası kullanın ve .env’yi .gitignore’a ekleyin. Kimlik bilgilerini yanlışlıkla GitHub’a gönderirseniz, bunları hemen değiştirin — botlar açıkta kalan API anahtarlarını tarar.
Her Şeyi Loglayın
API yanıtları, oran sınırı başlıkları ve hatalar için loglama ekleyin. Bir şey bozulduğunda loglar, "Ne olduğunu tam olarak biliyorum" ile "Neden durduğuna dair hiçbir fikrim yok" arasındaki farktır.
Akıllıca Zamanlayın ve Otomatikleştirin
Tekrarlayan scrape’ler çalıştırıyorsanız cron (Linux/Mac) veya Task Scheduler (Windows) kullanın — ama hataları izleyin. İki hafta boyunca sessizce başarısız olan bir cron işi, hiç otomasyon olmamasından bile kötüdür.
Alternatif: Thunderbit’in Scheduled Scraper özelliği, aralığı sade İngilizceyle anlatmanıza izin verir; cron sözdizimine gerek yoktur.
Reddit Scraping İçin Hukuki ve Etik En İyi Uygulamalar
Bu, sıradan bir feragatname değil. Reddit, 2023 API değişikliklerinden bu yana şartlarını agresif biçimde uyguladı ve kişisel veri scraping’i gerçek hukuki risk taşır.
Gerçekte önemli olanlar bunlar.
Reddit’in Hizmet Şartları: Aslında Ne Diyor?
Reddit’in Kullanıcı Sözleşmesi (31 Mart 2026’ya kadar revize edilmiş), şartlar veya ayrı bir anlaşma izin vermedikçe hizmetlere otomatik yollarla erişmeyi, arama yapmayı veya veri toplamayı açıkça yasaklıyor. Data API Terms ve Developer Terms daha fazla ayrıntı ekliyor: Reddit geliştirici kullanımını izleyebilir ve denetleyebilir, erişimi değiştirebilir veya durdurabilir, aşırı ya da kötüye kullanım durumunda erişimi kalıcı olarak engelleyebilir. Ticari kullanım genellikle açık onay gerektirir.
Mart 2026 Sorumlu Geliştirici Politikası daha da ileri gidiyor: API üzerinden Reddit verilerine erişmeden önce onay gerekiyor, onaylanmamış ticarileştirme ve AI/veri madenciliği kullanımları yasak, yaptırımlar arasında token’ların iptali, uygulama veya hesapların askıya alınması ve ilişkili botların veya alan adlarının durdurulması da olabilir.
robots.txt Uyumluluğu
Reddit’in güncel robots.txt dosyası alışılmadık derecede kısıtlayıcı:
User-agent: *
Disallow: /
Bu, tüm otomatik kullanıcı aracılar için genel bir engeldir. Ayrıca Herkese Açık İçerik Politikası’na da atıf yapar. Bu, birçok geliştiricinin eski web scraping normlarından hâlâ varsaydığı izin verici robots.txt kalıplarından çok daha serttir.
En iyi uygulama: aracınız bunu otomatik olarak zorlamasa bile scraping öncesi her zaman robots.txt’yi kontrol edin.
Kişisel Veri ve Gizlilik (GDPR/CCPA)
Kullanıcı adlarını, gönderi geçmişini veya herhangi bir kişisel tanımlayıcı bilgiyi scrape ediyorsanız, GDPR (AB) ve CCPA (Kaliforniya) geçerli olabilir. En iyi uygulama: kişisel verileri depolamadan önce anonimleştirin veya toplulaştırın. Hukuki bir dayanak olmadan bireysel kullanıcı profilleri oluşturmayın.
GitHub Repo Lisanslaması: İnşa Etmeden Önce Kontrol Edin
Birçok reddit scraper github reposu MIT veya Apache lisansı kullanır (esnektir), ama bazılarında hiç lisans dosyası yoktur — bu da hukuken "tüm hakları saklıdır" anlamına gelir. Fork yapmadan, değiştirmeden veya bir repo üzerine inşa etmeden önce her zaman LICENSE dosyasını kontrol edin. Yıldızı ne kadar çok olursa olsun, lisans yoksa hukuki durum belirsizdir.
2025–2026’da Uygulama Gerçekten Var
Reddit’in yaptırım hikâyesi 2023’te bitmedi. Reddit, 2025’te Anthropic’e karşı Reddit içeriğinin izinsiz scrape edilmesi/kullanılması iddiasıyla şikâyette bulundu ve ayrıca 2025 sonlarında Reddit v. SerpApi davasını sürdürdü. Bunlar, Reddit’in yalnızca teknik engelleme değil, hukuki yaptırım da uygulamaya hazır olduğunun işaretleri.
2026’da Doğru Reddit Scraper GitHub Yaklaşımını Seçmek
Reddit scraper GitHub manzarası 2023’ten bu yana dramatik biçimde değişti. Repoların çoğu güncel değil. Oran sınırları ve 1k gönderi limiti gerçek kısıtlar. Pushshift sıradan kullanıcılar için ortadan kalktı. Ve Reddit’in politika katmanı her zamankinden daha açık ve daha sıkı uygulanıyor.
Kısa versiyon:
- PRAW, Reddit’in API sınırlarını kabul edebiliyorsanız ve özel mantık geliştirmek istiyorsanız hâlâ en güvenilir açık kaynak temeldir.
- Pushshift/PSAW artık genel amaçlı cevap değildir.
- snscrape’in Reddit modülü eski ve güvenilmezdir.
- .json ve herkese açık uç nokta scraper’ları kırılgandır ve 2026’da çoğu zaman engellenir.
- Tarayıcı tabanlı araçlar — ister Playwright repoları ister Thunderbit gibi kodsuz seçenekler olsun — özellikle geliştirici olmayanlar için birçok kullanıcı adına en pratik yoldur.
Araçtan değil, kullanım senaryosundan başlayın. Herhangi bir GitHub projesine bağlanmadan önce 5 dakikalık repo sağlık kontrolünü uygulayın.
Ve kurulumla uğraşmadan birkaç dakika içinde Reddit scraping’e başlamak istiyorsanız, Thunderbit’i deneyin.
Reddit Scraping için Thunderbit’i Deneyin Get Started Free
SSS
2026’da GitHub’daki en iyi açık kaynak Reddit scraper’ları hangileri?
PRAW, aktif bakımı ve iyi dokümantasyonu sayesinde hâlâ en güvenilir API sarmalayıcısıdır. URS, PRAW üzerine kurulmuş, bakımı yapılan güvenilir bir CLI aracıdır. Playwright tabanlı scraper’lar API dışı scraping için çalışır, snscrape’in Reddit modülü ise kısmen işlevsel ama büyük ölçüde bakım görmüyor. Herhangi bir repo kullanmadan önce her zaman son commit tarihine ve açık issue’lara bakın — GitHub’daki 2.300+ Reddit scraper reposunun çoğu eski.
Reddit scraping yapmak yasal mı?
Herkese açık verileri scrape etmek hukuken gri alanda kalır, ancak Reddit’in kendi şartları kısıtlayıcıdır. Kullanıcı Sözleşmesi, Data API Terms, Herkese Açık İçerik Politikası, Sorumlu Geliştirici Politikası ve robots.txt, izinsiz toplu scraping’e karşı duruyor. Scrape edilmiş verinin ticari yeniden dağıtımı Reddit’in açık iznini gerektirebilir. Kişisel veri scrape ediyorsanız GDPR ve CCPA da geçerli olabilir.
Reddit’in API oran sınırlarını nasıl aşarım?
Üstel geri çekilme kullanın, X-Ratelimit-Remaining başlıklarını izleyin ve sınırlar içinde kalmak için zaman penceresi parçalamayı düşünün. Tarayıcı tabanlı scraping (Playwright veya Thunderbit) işlenen sayfaları kazıdığı için API oran sınırlarını aşar, ancak kendi konuları vardır (sayfa yükleme hızı, bot karşıtı önlemler). Oran sınırlarını tamamen kaldırmak için sihirli bir hile yoktur — bunlar sunucu tarafında uygulanır.
API anahtarı olmadan Reddit scrape edebilir miyim?
Evet. Playwright tabanlı scraper’lar ve .json URL hilesi API anahtarı gerektirmez. Thunderbit da tarayıcı üzerinden scraping yaptığı için API anahtarı istemez. Takaslar şunlardır: .json uç noktaları giderek daha sık engelleniyor (Nisan 2026 itibarıyla birçok ortamda 403 döndürüyor) ve tarayıcı tabanlı scraping, API çağrılarına göre daha yavaş ve daha kaynak yoğundur.
Reddit scraping için Pushshift’e ne oldu?
Pushshift’in herkese açık API erişimi, Reddit’in 2023’te başlayan veri lisanslama değişikliklerinin ardından kaldırıldı. PSAW sarmalayıcısı arşivlendi ve eski durumda. Sınırlı akademik erişim belirli onaylı kanallar üzerinden mevcut olabilir, ama bugün "reddit scraper github" arayan çoğu kullanıcı için Pushshift artık geçerli bir seçenek değil. Derin tarihsel Reddit verisine ihtiyacınız varsa, Reddit’in onaylı akademik veya lisanslı veri yollarına bakın.
Daha Fazla Bilgi




