Size söyleyeyim: Bana “önemli verilerle” dolu bir PDF gönderilip bunu sihirli bir şekilde bir elektronik tabloya dönüştürmem beklense, muhtemelen ömür boyu yetecek kadar kahve alacak parayı ve belki birkaç ekstra Chrome uzantısını da toplamış olurdum. PDF’ler her yerde: satış sözleşmeleri, ürün katalogları, araştırma makaleleri, faturalar, daha neler neler. Peki asıl mesele, bu dosyaların içindeki veriyi gerçekten kullanmak olduğunda ne oluyor? İşte eğlencenin değil, baş ağrısının başladığı yer tam orası.
Bu işi bizzat yaşadım: kopyaladım, yapıştırdım, yeniden biçimlendirdim; bazen de biçimlendirme tamamen dağıldığında ya da görseller ve bağlantılar bir anda yok olduğunda düpedüz pes ettim. Ama iyi haber şu: Özellikle yapay zekâ destekli araçların yükselişiyle PDF ayıklama dünyası büyük ölçüde değişti. Sayıları yeniden tek tek girmekten yorulduysanız ya da bozulmuş tablolar yüzünden aklınızı kaçırma noktasına geldiyseniz, doğru yerdesiniz. Gelin PDF ayıklama dünyasına, bunun neden önemli olduğuna ve gibi araçların bunu nasıl nihayet zahmetsiz hâle getirdiğine bakalım.
PDF Ayıklama Nedir? PDF Veri Çıkarma Temellerini Anlamak
Basit başlayalım: PDF ayıklama, “PDF dosyalarından yapılandırılmış veriyi otomatik olarak çekmek” demenin havalı bir yolu. Bir PDF ayıklayıcı, ilgilendiğiniz şeyleri — metin, tablolar, görseller, bağlantılar, aklınıza ne gelirse — çıkarıp bunları Excel, Google E-Tablolar ya da bir veritabanı gibi gerçekten kullanabileceğiniz bir formata yerleştiren bir araçtır (yazılım, uzantı ya da hizmet).
Ama burada bir püf noktası var: PDF’ler web sayfaları ya da Excel dosyaları gibi değildir. Onlar daha çok dijital çıktılar gibidir; her yerde aynı görünmeleri için tasarlanmıştır, bilgisayarın kolayca parçalara ayırması için değil. Bazı PDF’lerde seçilebilir metin bulunur, bazıları ise taranmış görsellerden ibarettir (bu durumda OCR — optik karakter tanıma — gerekir) ve biçimlendirme her yerde başka türlü olabilir. Yani PDF ayıklamak sadece metni kopyalamak değildir; yerleşimlerin, yazı tiplerinin ve bazen gizli meta verilerin oluşturduğu bir yapbozu çözmektir.
Bir PDF’den neleri çıkarabilirsiniz?
- Düz metin (paragraflar, başlıklar vb.)
- Tablolar (finansal veriler, ürün özellikleri, anket verileri gibi)
- Görseller ve grafikler (grafikler, logolar, taranmış imzalar)
- Köprüler ve referanslar (gömülü URL’ler, atıflar)
- Form verileri (doldurulabilir formlardaki alanlar)
- Meta veriler (yazar, başlık, oluşturulma tarihi, etiketler)
Evet, bazen bunların hepsi tek bir görkemli ve kaotik belgede birbirine karışmış olur.
PDF Ayıklama Neden Önemli? Gerçek Kullanım Senaryoları ve İş Faydaları
Peki neden PDF ayıklama ile uğraşasınız? Çünkü onları herkes kullanıyor ve içlerindeki veri çoğu zaman iş açısından kritik oluyor. PDF ayıklamanın öne çıktığı yerler şunlar:
| Kullanım Senaryosu | Manuel Efor | PDF Ayıklayıcı ile | Zaman ve Hata Tasarrufu |
|---|---|---|---|
| Satış Adayı Çıkarma | Tekliflerden veya etkinlik PDF’lerinden saatlerce kişi bilgisi kopyalama, potansiyel müşteri kaçırma riski | Tüm adayları anında bir elektronik tabloya aktarır | %80–90 daha hızlı, daha az hata |
| E-ticaret Ürün Verisi | Tedarikçi PDF’lerinden ürün özelliklerini günlerce girme, biçimlendirme kabusu | CSV veya E-Tablolar’a toplu çıkarım | %95+ zaman tasarrufu, tutarlı veri |
| Araştırma Verisi Analizi | Akademik makalelerdeki tabloları haftalarca elle aktarma, yüksek yazım hatası riski | Tabloları, referansları ve taranmış metni bile çıkarır | %80 zaman tasarrufu, daha yüksek doğruluk |
Bunu biraz sayılara dökelim:
- Her yıl oluşturuluyor.
- Kuruluşların bilgi paylaşımında birincil format olarak PDF kullanıyor.
- PDF veri girişi gibi manuel dijital işler, çalışma saatlerinin yiyor.
- Otomatik araçlar hata oranlarını indirebiliyor.
Satışta, e-ticarette ya da araştırmada çalışıyorsanız, PDF veri çıkarımını otomatikleştirmek “iyi olsa güzel olur” seviyesinde değil; doğrudan rekabet avantajı demek.
Geleneksel PDF Ayıklama Yöntemleri: Zorluklar ve Sınırlamalar
Dürüst olalım: PDF’lerden veri almanın eski yöntemleri pek iyi değil. Çoğumuzun denediği şeyler ve neden bu kadar sinir bozucu oldukları şöyle:

1. Elle Kopyala-Yapıştır
- Can sıkıcı noktalar: Biçimlendirme bozulur, tablolar birbirine girer, görseller ve bağlantılar kaybolur, geriye bir de baş ağrısı kalır.
- İşçilik maliyeti: Yüksek. 5.000 PDF’niz varsa, her biri sadece 1 dakika sürse bile bu, hayatınızdan geri alamayacağınız 80+ saat demek.
- Hata oranı: %5–10. Yazım hataları, kaçırılan satırlar, yanlışlıkla silinen içerikler — hepsini yaşadık.
2. Word/Excel’e Dönüştür, Sonra Temizle
- Can sıkıcı noktalar: Basit belgelerde bazen işe yarar, ama karmaşık yerleşimler veya tablolar altüst olur. Sonra yine karmaşayı temizlemek zorunda kalırsınız.
- Görseller/bağlantılar: Çoğu zaman yolda kaybolur.
- Hedefli çıkarım: Unutun gitsin — bütün belge gelir, ama sizin ihtiyacınız olan kısım değil.
3. Özel Betikler (Python vb.)
- Can sıkıcı noktalar: Kod yazmayı bilmeniz gerekir (ya da bir kodcuya hızlı erişiminiz olmalı). Her yeni PDF formatı, betiği ayarlamanızı gerektirir. Taranmış PDF’ler mi? Kolay gelsin.
- Bakım: Yüksek. Bir tedarikçi fatura şablonunu değiştirdiği anda betiğiniz kırılır.
- Ölçeklenebilirlik: Teknik olmayanlar ya da sabırsız olanlar için değil.
4. Çevrimiçi Dönüştürücüler
- Can sıkıcı noktalar: Tek seferlik işler için kolaydır, ama hassas belgeleri üçüncü taraf bir sunucuya yüklemeniz gerekir (merhaba, uyumluluk sorunları). Nelerin çıkarılacağı üzerinde kontrol sınırlıdır.
- Biçimlendirme: Bazen olur, bazen olmaz. Temizlemeye harcadığınız süre, kazandığınız zamandan fazla olabilir.
Kısa cevap: Geleneksel yöntemler yavaş, hataya açık ve ölçeklenebilir değil. Bu yüzden birçok ekip durumu olduğu gibi kabulleniyor — ama bunun verimlilikteki bedeli çok yüksek.
PDF Ayıklama İçin Modern Çözümler: Koddan Kodsuz Araçlara
Neyse ki artık taş devrinde yaşamıyoruz. Daha akıllı, daha hızlı ve daha kullanıcı dostu PDF ayıklama seçenekleri hızla çoğaldı.
1. Kod Kütüphaneleri (Geliştiriciler İçin)
- Örnekler: , , .
- Güçlü yönler: Son derece esnek, büyük toplu işler için otomatikleştirilebilir, ücretsiz (açık kaynak).
- Zayıf yönler: Kurulum süresi yüksek, programlama bilgisi gerekir, kırılgandır (yeni formatlarda bozulur), OCR/görsel desteği sınırlıdır.
2. Çevrimiçi PDF Dönüştürücüler
- Örnekler: , , .
- Güçlü yönler: Kurulum yok, teknik olmayanlar için kolay, küçük işler için hızlı.
- Zayıf yönler: Sınırlı özelleştirme, gizlilik kaygıları, biçim hataları, dosya boyutu/sayfa sınırları.
3. Yapay Zekâ Destekli PDF Ayıklayıcılar
- Örnekler: , Nanonets, Docparser.
- Güçlü yönler: Kod gerekmez, metin/tablo/görsel/bağlantı desteği sunar, AI neyin çıkarılacağını önerebilir, toplu işler desteklenir, Sheets/Notion/Airtable ile entegre olur.
- Zayıf yönler: Bazılarında kredi/sayfa sınırları olabilir, internet bağlantısı gerekebilir, karmaşık belgelerde ara sıra öğrenme eğrisi olur.
PDF Ayıklama Araçlarını Karşılaştırma: Hangi Yaklaşım Size Uygun?
| Araç/Yöntem | Kurulum | En İyi Olduğu Alan | Neleri Çıkarır | Özelleştirilebilir mi? | Maliyet |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Orta (arayüz/kodlama) | PDF’lerdeki tablolar | Tablolar | Kısmen | Ücretsiz |
| PDFMiner | Kod gerekir | Metin ağırlıklı PDF’ler | Metin | Evet (kodla) | Ücretsiz |
| PyPDF2 | Kod gerekir | Basit metin/meta veri | Metin, meta veri | Evet (kodla) | Ücretsiz |
| Smallpdf/Çevrimiçi Dönüştürücü | Yok (web tabanlı) | Hızlı dönüşümler | Tüm belge (Word/Excel) | Hayır | Freemium |
| Thunderbit | 2 tıkla kurulum | İş kullanıcıları, ekipler | Metin, tablolar, görseller, bağlantılar | Evet (AI istemleri) | Freemium (Pro için ayda 16,5 $) |
Thunderbit ile Tanışın: AI PDF Ayıklayıcı Chrome Uzantısı
Şimdi, hem benim hem de birçok iş kullanıcısının hayatını çok daha kolay hâle getiren araçtan bahsedelim: .
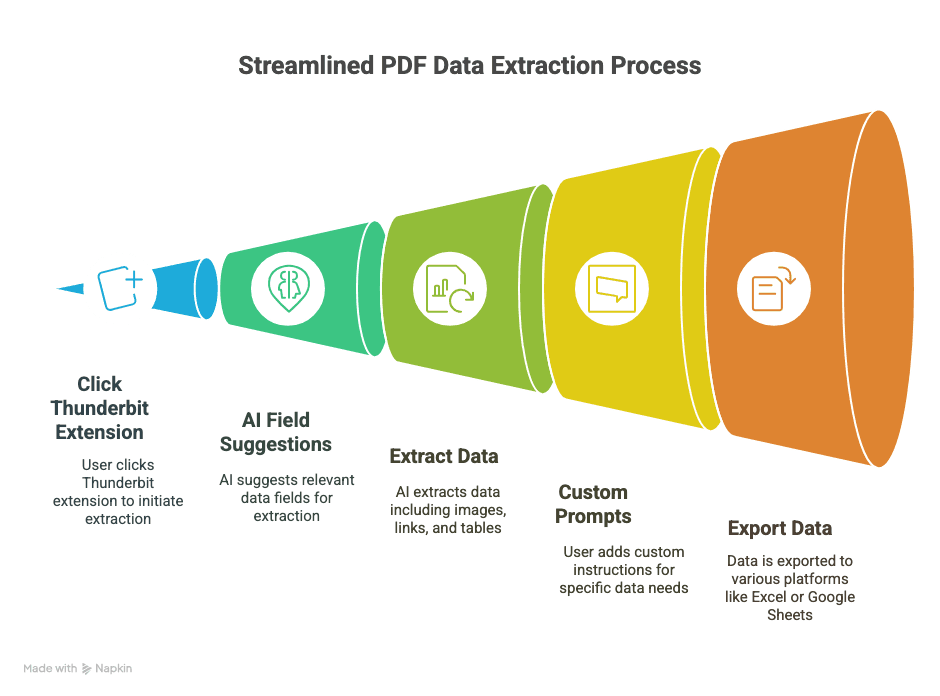
Thunderbit’i farklı kılan nedir?
- 2 tıkla çıkarım: Bir PDF’yi Chrome’da açın, Thunderbit uzantısına tıklayın ve gerisini AI’ya bırakın.
- AI destekli alan önerileri: Thunderbit’in “AI Suggest Fields” özelliği PDF’nizi okur ve muhtemelen istediğiniz sütunları önerir (“Ad”, “E-posta”, “Fiyat” gibi).
- Görselleri, bağlantıları ve tabloları işler: Sadece düz metin değil — Thunderbit görselleri, köprüleri çıkarabilir ve taranmış belgelerde OCR çalıştırabilir.
- Özel istemler: Sadece telefon numaraları ya da ürün özellikleri mi lazım? Özel bir talimat ekleyin, Thunderbit yalnızca ona odaklansın.
- Her yere dışa aktarır: Verinizi doğrudan Excel, Google E-Tablolar, Airtable veya Notion’a gönderin. CSV çevrimi yapmaya gerek kalmaz.
- Toplu ve alt sayfa ayıklama: Bir PDF ya da bağlantı listesi mi var? Thunderbit hepsini tek seferde işleyebilir.
- İş düzeyinde güvenilirlik: Doğruluk, gizlilik ve gerçek iş akışları için tasarlanmıştır.
Kısacası, bu araç sanki veri girişi yapmayı gerçekten seven ve hiç yorulmayan dijital bir stajyer gibi.
Thunderbit Kullanarak Bir PDF’den Veri Nasıl Çıkarılır: Adım Adım Kılavuz
Bunun ne kadar kolay olabileceğini görmeye hazır mısınız? Ben PDF’leri yapılandırılmış ve kullanılabilir verilere dönüştürmek için Thunderbit’i şöyle kullanıyorum:
1. Thunderbit’i Kurun
- sayfasından indirin.
- Kayıt olun (Google hesabı veya e-posta ile — saniyeler sürer).
2. PDF’nizi Chrome’da Açın
- PDF’yi ya bir web bağlantısından açın ya da yerel bir PDF’yi Chrome sekmesine sürükleyin.
3. PDF Üzerinde Thunderbit’i Çalıştırın
- Tarayıcınızdaki araç çubuğunda Thunderbit simgesine tıklayın.
- “AI Web Scraper”ı seçin — Thunderbit PDF’yi algılar ve çalışmaya hazır hâle gelir.
4. AI’nın Alan Önermesine İzin Verin
- “AI Suggest Columns”a tıklayın.
- Thunderbit’in AI’sı PDF’yi tarar ve sütunları önerir (“Tarih”, “Tutar”, “İletişim Adı” gibi).
- Çıkarılan veriyi uzantının içinde tablo halinde önizleyin.
5. Gerekirse Özelleştirin
- Sütunları yeniden adlandırın, gereksizleri silin ya da kendi alanlarınızı ekleyin (örneğin “Garanti Süresi” veya “Ürün URL’si”).
- Zor veriler için, AI’yı ne istediğinize göre eğitmek amacıyla PDF içindeki metni seçin.
6. Dışa Aktarım Formatınızı Seçin
- CSV, Google E-Tablolar, Airtable veya Notion seçeneklerinden birini seçin.
- Thunderbit’in bağlanmasına izin verin (bir defalık kurulum).
7. Ayıklayın ve Dışa Aktarın
- “Scrape” ya da “Export”a basın.
- Thunderbit PDF’yi işler ve veriyi istediğiniz yere gönderir — genelde saniyeler içinde.
Hepsi bu. Kod yok, kopyala-yapıştır yok, drama yok.
Thunderbit ile Doğru PDF Veri Çıkarma İçin İpuçları
- AI’nın önerdiği alanları inceleyin: AI akıllıdır, ama hızlı bir kontrol tam olarak ihtiyacınızı aldığınızdan emin olmanızı sağlar.
- Karmaşık tablolarla başa çıkın: Çok sayfalı veya garip biçimlendirilmiş tablolar için önizlemeyi kullanarak sorunları görün ve sütunları gerektiği gibi ayarlayın.
- Görselleri/bağlantıları çıkarın: PDF’nizde varsa bu alanları dahil ettiğinizden emin olun — Thunderbit bunları da alabilir.
- Taranmış PDF’ler: Thunderbit’in yerleşik OCR’ı oldukça iyidir, ama tarama ne kadar temizse sonuçlar da o kadar iyi olur.
- Özel istemler: Sadece e-posta ya da telefon numarası mı istiyorsunuz? “Tüm e-posta adreslerini çıkar” gibi bir istem ekleyin; Thunderbit ona odaklanır.
Gelişmiş PDF Ayıklama: Görselleri, Bağlantıları ve Özel Verileri Çıkarmak
Thunderbit sadece düz metinle ilgili değildir. PDF’lerinizden daha fazlasını nasıl çıkarabileceğinize bakalım:
- Görseller: Logoları, grafikleri veya gömülü tüm görselleri çıkarın. Thunderbit görsellerin içindeki metni bile OCR ile okuyabilir.
- Köprüler: Tüm URL’leri veya referansları çıkarın — araştırma makaleleri veya özgeçmişler için harikadır.
- Özel veri türleri: İhtiyacınız olanı tam olarak çıkarmak için AI istemleri kullanın (örneğin, “Tüm ürün SKU’larını ve fiyatlarını bul”).
- Özetler ve sınıflandırma: Bir sütun ekleyin ve Thunderbit’ten bir bölümü özetlemesini veya veriyi anında kategorize etmesini isteyin.
Özel İş İhtiyaçları İçin PDF’den Veri Ayrıştırma
- Satış: Birden fazla tekliften yalnızca iletişim bilgilerini çıkarın.
- E-ticaret: Tedarikçi kataloglarından ürün özelliklerini, fiyatları ve görselleri alın.
- Araştırma: Akademik makalelerden tabloları, referansları ve hatta özetleri çıkarın.
Veriyi aldıktan sonra onu Excel, Google E-Tablolar veya Notion’da kolay analiz edilecek şekilde düzenleyin — ağır işi Thunderbit yapar, siz de sonucu kullanırsınız.
PDF Verinizi Dışa Aktarmak ve Kullanmak: Çıkarmadan Eyleme
Veriyi dışarı almak sadece başlangıç. Bunu sizin için işe yarar hâle getirmenin yolu şu:
- Dışa aktarma seçenekleri: CSV, Excel, Google E-Tablolar, Airtable, Notion — hangisini isterseniz.
- Biçimlendirme ipuçları: Temiz ve analiz edilmeye hazır veri için Thunderbit’in sütun türü ayarlarını kullanın (sayı, tarih, metin).
- İş akışı entegrasyonu: Dışa aktardığınız veriyi CRM’lere, stok sistemlerine veya analiz panolarına bağlayın.
- İş birliği: Google E-Tablolar ya da Airtable tabanlarınızı ekibinizle paylaşın — herkes aynı ve güncel veriyle çalışır.
En güzel kısmı ne mi? Artık elektronik tabloları birbirine e-posta ile göndermek zorunda değilsiniz; ya da bir satırı kaçırıp kaçırmadığınızı düşünmezsiniz.
PDF Ayıklamada Yaygın Tuzaklar ve Bunlardan Kaçınma Yolları
En iyi araçlarla bile birkaç pürüz çıkabilir. İşte bazen zor yoldan öğrendiklerim:
- OCR hataları: Bulanık taramalar veya garip yazı tipleri en iyi OCR araçlarını bile zorlayabilir. Mümkün olan en temiz PDF’leri kullanmaya çalışın ve kritik alanları iki kez kontrol edin.
- Karmaşık yerleşimler: Çok sütunlu veya iç içe tablolar biraz manuel yönlendirme isteyebilir — Thunderbit’in manuel seçimini ya da istemlerini kullanın.
- Veri türleri: Virgüllü sayılar ya da tuhaf biçimli tarihler mi var? Dışa aktarmadan önce sütun türünü ayarlayın ya da Excel/E-Tablolar’da temizleyin.
- Dosya boyutu/sayfa sınırları: Dev PDF’ler mi? Onları daha küçük parçalara bölün ya da toplu işler için Thunderbit’in bulut modunu kullanın.
- AI “uydurması”: Nadiren olur, ama bazen AI bir sütun adını tahmin edebilir ya da eksik veriyi doldurabilir. Özellikle önemli rakamlar için çıktıyı mutlaka gözden geçirin.
- Manuel kontrol: Kritik veriler için hızlı bir doğrulama yapın — otomatik araçlar doğrudur, ama insan gözü her zaman faydalıdır.
Ve bir noktada duvara toslarsanız, Thunderbit’in destek ekibi ve topluluğu yardım etmeye hazır.
Sonuç ve Temel Çıkarımlar: PDF Ayıklamayı İşiniz İçin Çalışır Hâle Getirmek
Toparlayalım. PDF’lerden veri ayıklamak eskiden bir kabustu — yavaştı, hataya açıktı ve düpedüz sıkıcıydı. Ama gibi modern araçlarla artık hızlı, doğru ve (bunu söylemeye cesaret ediyorum) neredeyse keyifli.
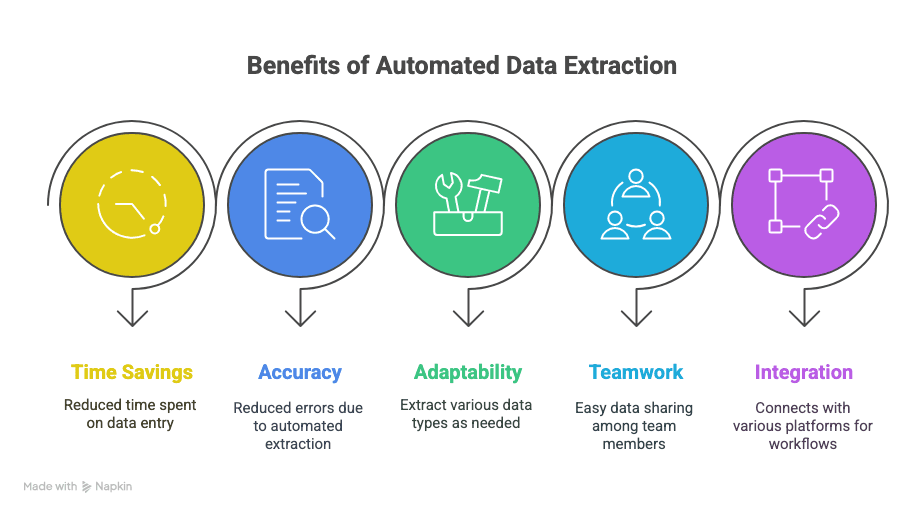
Elde ettikleriniz:
- Zaman kazanımı: Manuel veri girişinde saatler, hatta haftalar geri kazanırsınız.
- Daha az hata: Otomatik çıkarım daha az yazım hatası ve kaçırılmış satır demektir.
- Esneklik: Tam olarak neye ihtiyacınız varsa onu çıkarın — metin, tablolar, görseller, bağlantılar, aklınıza ne gelirse.
- İş birliği: Veriyi ekip arkadaşlarınızla, nerede olurlarsa olsunlar anında paylaşın.
- Daha akıllı iş akışları: Sheets, Notion, Airtable ve daha fazlasıyla entegre edin.
Denemeye hazır mısınız? nı indirin, bir sonraki PDF’nizde çalıştırın ve hayatın ne kadar kolaylaşabileceğini görün. Gelecekteki siz (ve karpal tüneliniz) size teşekkür edecek.
Daha fazla ipucu ve rehber için sayfasına göz atın ya da içeriğine daha derinlemesine dalın.
Gelin, o PDF baş ağrılarını tek tıkla verimlilik kazancına dönüştürelim.
Shuai Guan, Kurucu Ortak ve CEO, Thunderbit