
Birkaç ay önce, satış ekibimizden bir arkadaşım bana defalarca duyduğum bir soruyu sordu: “Rakibin fiyatlarını herkese açık bir siteden scrape edersem, gerçekten başım derde girer mi?” Tedarikçi iletişim bilgilerini içeren bir dizin bulmuştu; fiyatlar düzgün satırlara dizilmişti ve onun istediği tek şey bir Excel tablosuydu. Tereddüt gerçekti — ve açıkçası, haklıydı.
Birleşik Krallık’ta tek bir “web scraping yasası” yok. Onun yerine, belirli bir scraping faaliyetinin hukuka uygun olup olmadığını dört farklı ama örtüşen hukuki çerçeve belirliyor. Bu yüzden cevap çoğu zaman “duruma bağlı” oluyor — ama bu, insanı felç etmesi gerektiği anlamına gelmiyor. Bu rehberde, yasaların gerçekten ne dediğini, bunların gerçek hayattaki senaryolara nasıl uygulandığını, cezaların nasıl göründüğünü ve nasıl uyumlu kalabileceğinizi anlatacağım.
Bu konuya Thunderbit’teki ekibimiz için ciddi zaman ayırdım. O yüzden beş farklı hukuk bürosu blogu ile bir Reddit başlığını didik didik etmek zorunda kalmadan öğrendiklerimi sizinle paylaşmak istiyorum.
Web Scraping Nedir (ve Birleşik Krallık’taki İşletmeler Neden Kullanır)
Web scraping, web sitelerinden verileri otomatik olarak toplamak için yazılım kullanmaktır — web sayfalarından bir tabloya tek tek kopyala-yapıştır yapmanın sıkıcı işini ortadan kaldırır.
Tekniğin kendisi nötrdür. Doğası gereği yasal da değildir, yasa dışı da değildir. Önemli olan neyi scrape ettiğiniz, nasıl scrape ettiğiniz ve sonrasında veriyi nasıl kullandığınızdır.
Birleşik Krallık’taki işletmeler scraping’i pek çok meşru amaç için kullanır:
- Fiyat karşılaştırması: Örneğin PriceSpy UK, otomatik web scraping kullanarak .
- Lead oluşturma: Satış ekipleri kamuya açık dizinlerden şirket adları, e-postalar ve telefon numaraları toplar.
- Pazar araştırması: Analistler emlak ilanlarını, iş panolarını veya rakip ürün yelpazelerini takip eder.
- Akademik araştırma: Office for National Statistics, 2014 ile 2015 arasında süpermarket sitelerinden topladı.
- AI model eğitimi: Hızla büyüyen — ve hukuken hâlâ netleşmemiş — bir kullanım alanı.
Eğilim oldukça net. tarafından yapılan ve Birleşik Krallık’tan 200 kişinin de dahil olduğu 500 karar vericiyi kapsayan bir araştırmaya göre, katılımcıların gibi büyük bir bölümü herkese açık web verisini küresel ekonomi için kritik ya da çok önemli görüyor; ise bu veriyi en az günlük bazda temin ediyor.
Buna rağmen , net bir düzenleme eksikliğinin kurumlarını endişelendirdiğini söyledi. Bu yazının varlık nedeni de tam olarak bu kaygı.
Birleşik Krallık’ta Web Scraping Yasal mı? Kısa Cevap
Birleşik Krallık yasaları web scraping’i tamamen yasaklamaz. Ancak bunu nasıl yapabileceğinizi birden fazla yasa düzenler ve herhangi bir projenin hukuka uygunluğu dört unsura bağlıdır:
- Hangi veriyi scrape ettiğiniz (kişisel veri mi, olgusal/kişisel olmayan veri mi)
- Nasıl eriştiğiniz (herkese açık sayfa mı, yoksa giriş duvarlarını ya da CAPTCHA’ları aşarak mı)
- Web sitesinin şartları ne diyor (otomatik erişimi yasaklıyor mu?)
- Veriyi sonrasında nasıl kullandığınız (iç analiz mi, ticari yeniden satış mı)
Bulduğum en iyi benzetme şu: web scraping, kamusal alanda fotoğraf çekmeye benzer. Kamuda fotoğraf çekmek otomatik olarak yasa dışı değildir — ama bazı konular, yerler, yöntemler ve kullanımlar hukuki risk doğurur. Scraping de buna benzer. Kamuya açık olması önemlidir, ama hikâyenin tamamı değildir.
ICO’nun yakın tarihli GenAI istişaresi, scrape edilmiş kişisel veriye dair en net resmi Birleşik Krallık açıklamalarından biridir. Buna göre, web scraping ile toplanan kişisel veriler kullanılarak üretken AI modelleri eğitilirken meşru menfaatler olmaya devam ediyor — ama yalnızca geliştirici sıkı üç aşamalı testi geçerse. Bu da eşik seviyesinin oldukça yüksek olduğunu ve Birleşik Krallık düzenleyicilerinin scrape edilmiş veriye ne kadar ciddi yaklaştığını gösteriyor.
Web Scraping’e Uygulanan Dört Birleşik Krallık Yasası
Dört farklı ama örtüşen mercek var — herhangi bir scraping projesi bunlardan birini, ikisini ya da dördünü birden tetikleyebilir.
UK GDPR ve Data Protection Act 2018
Kişisel veri — isimler, e-postalar, telefon numaraları, IP adresleri, sosyal medya profilleri — scrape ediyorsanız, UK GDPR devreye girer. “Herkese açık” olması, “istediğin gibi kullanabilirsin” anlamına gelmez.
Kamuya açık kişisel veri hâlâ kişisel veridir.
Ticari scraping için en ilgili hukuki dayanak meşru menfaatlerdir (Madde 6) — ama bunu gelişigüzel ileri süremezsiniz. Şunları yapmanız gerekir:
- Belirli ve meşru bir amaç tanımlamak
- İşlemenin bu amaç için gerekli olduğunu göstermek
- Kendi menfaatinizi, topladığınız kişilerin haklarıyla dengelemek
ICO’nun GenAI istişare yanıtı özellikle nettir: geliştiriciler geniş toplumsal faydanın tek başına yeterli olduğunu varsaymamalı, scraping yerine alternatiflerin neden uygun olmadığını kanıtlamalı ve kişilerin haklarını anlamasını ve kullanmasını sağlayan şeffaflık mekanizmaları kullanmalıdır. Kaynak: .
B2B lead oluşturma için de aynı mantık geçerlidir. Bir satış ekibi kamuya açık iş iletişim bilgilerini toplarken meşru menfaatlere dayanabilir; ancak yine de meşru menfaati belgelemeli, topladığı alanları en aza indirmeli, özel nitelikli veriden kaçınmalı, mümkün olan yerlerde gizlilik bilgisi sağlamalı ve opt-out taleplerine saygı göstermelidir.
Telif Hakkı, Veri Tabanı Hakları ve TDM İstisnası
Telif hakkı, web sitesindeki özgün içeriği korur: metin, görseller, ürün açıklamaları, makaleler. Fiyatlar gibi olgusal veri noktaları tek başına genellikle telif açısından daha az hassastır — ama korunan ifadeyi kopyalayıp yeniden yayımlarsanız, ihlal alanına girersiniz.
Veri tabanı hakları, çoğu kişinin fark ettiğinden daha önemlidir. Birleşik Krallık, Brexit sonrasında AB tarzı sui generis veri tabanı haklarını korudu ve korunan bir veri tabanının “esaslı bir kısmını” çıkarmak — özenle derlenmiş dizinler, ürün katalogları, pazar yeri ilanları — tek tek veri noktaları olgusal olsa bile ihlal oluşturabilir.
kapsamındaki Text and Data Mining (TDM) istisnası, yalnızca kullanıcı hukuka uygun erişime sahipse ve amaç ticari olmayan araştırmaysa metin ve veri analizi için kopyalara izin verir. Bu istisna dardır. Ticari scraping, ticari AI eğitimi ve ticari veri seti yeniden satışı bunun kapsamına girmez.
Birleşik Krallık hükümeti bu istisnayı AI eğitimi için genişletmeyi değerlendirdi; ancak itibarıyla, yaratıcılar, AI geliştiricileri ve Birleşik Krallık ekonomisi için hedefleri karşıladığından emin olana kadar reform yapmamaya karar verdi. Mevcut durumda, zaten bir istisna uygulanmıyorsa, AI eğitimi için korunan eserleri kopyalamak genellikle izin gerektirir.
Web Sitesi Kullanım Şartları ve Sözleşme Hukuku
Çoğu web sitesinde otomatik scraping’i yasaklayan veya sınırlayan Kullanım Şartları (ToS) bulunur. Siteye eriştiğinizde, özellikle bir kabul ekranını tıklayarak geçiyorsanız (clickwrap), bu şartları kabul ediyor olabilirsiniz. Footer bağlantısının arkasında duran browsewrap sözleşmeleri daha çok somut olguya bağlıdır; ancak Birleşik Krallık mahkemeleri, scraping’e ilişkin ToS kısıtlarını uygulamaya istekli olduğunu göstermiştir. uyuşmazlığında mahkeme, görünür site şartlarını screen-scraping bağlamında bağlayıcı kabul etti.
robots.txt bir yasa değildir. Site sahibinden gelen makine tarafından okunabilir bir sinyaldir. Tipik bir dosya şöyle görünür:
1User-agent: *
2Disallow: /account/
3Disallow: /checkout/
4Disallow: /private/
5Crawl-delay: 10robots.txt’yi yok saymak scraping’i otomatik olarak yasa dışı yapmaz; ancak mahkemeler ve ICO bunu site sahibinin niyetinin bir kanıtı olarak değerlendirir. Özellikle ToS ihlali veya agresif istek hacimleriyle birleşirse, bunu görmezden gelmek hukuki maruziyeti artırır.
Computer Misuse Act 1990
Bu yasa insanları geceleri uyutmayan türden — ve haklı bir nedenle. Çünkü cezai suçlar yaratır. Section 1, bilgisayar materyaline yetkisiz erişimi kapsar (azami ). Section 3, bilgisayar çalışmasını bozan yetkisiz eylemleri kapsar (azami ).
CMA riski, verinin gerçekten herkese açık olduğu ve scraper’ın teknik bariyerleri aşmadığı durumlarda en düşüktür. Risk şu durumlarda yükselir:
- Giriş duvarlarını, CAPTCHA’ları veya IP engellerini aşmak
- Çalıntı kimlik bilgileri kullanmak ya da sahte hesaplar açmak
- Hedef hizmetin işleyişini bozacak trafik hacimleri göndermek
Birleşik Krallık, ABD’deki “kamuya açık veri serbest av sahasıdır” tarzı net bir kural üretmedi. Bu da Birleşik Krallık tavsiyelerini daha temkinli hâle getiriyor: kamu erişimi CMA riskini ciddi biçimde düşürür, ancak web sitesi şartları, teknik kontroller ve scraper’ın kısıtlamaları bilip bilmemesi hâlâ önemli olabilir.
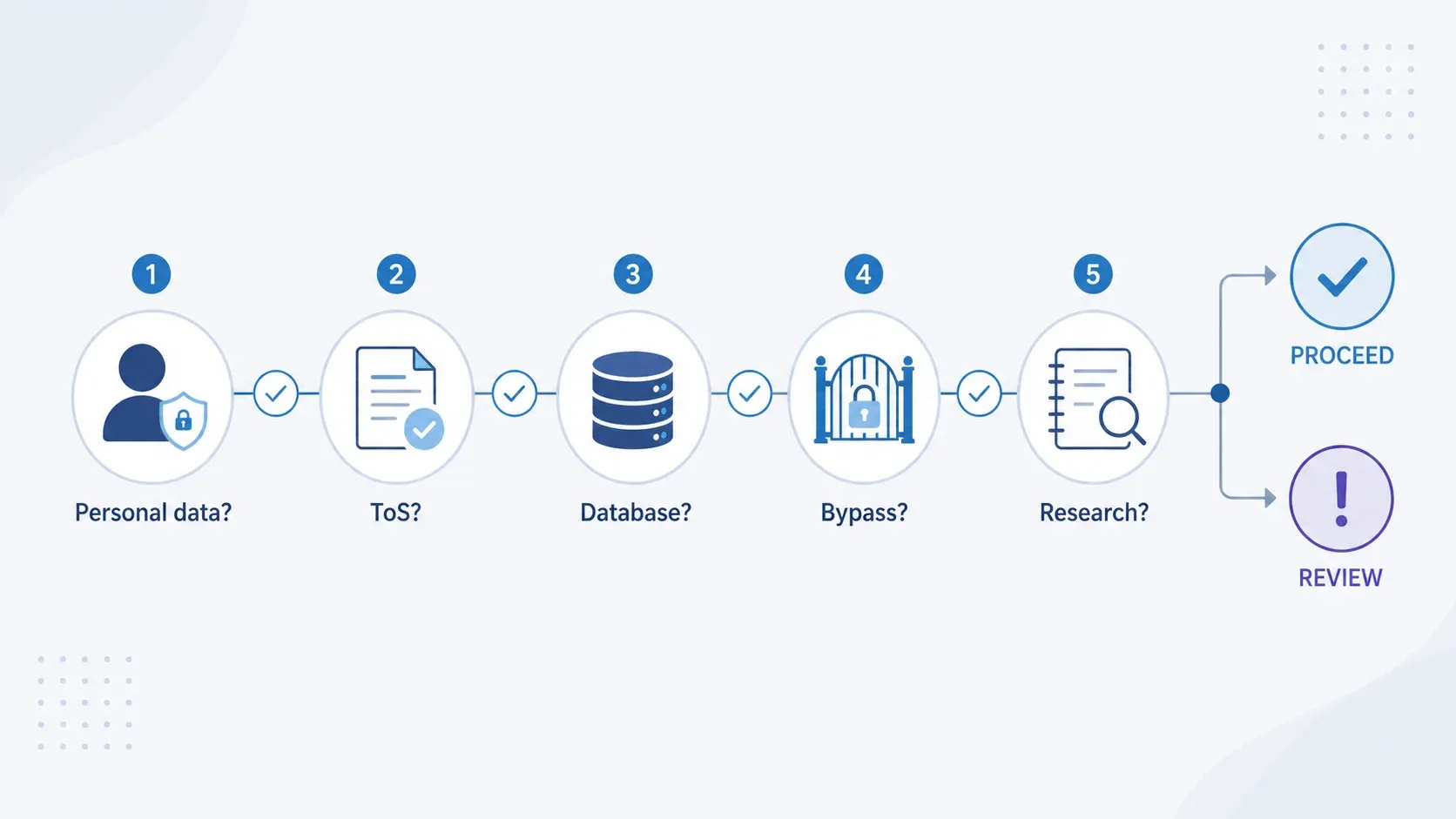
“Bunu Yasal Olarak Scrape Edebilir miyim?” — Hızlı Karar Akışı
Bir şeyi scrape etmeden önce şu beş karar noktasından geçin. Bu bir hukuki danışmanlık değil — sadece 60 saniyelik bir risk taraması.
| Karar Noktası | Cevap EVET ise | Cevap HAYIR ise |
|---|---|---|
| Veri kişisel veri mi (isimler, e-postalar vb.)? | UK GDPR uygulanır. Hukuki dayanağı belirleyin, LIA yapın, alanları en aza indirin, şeffaflığı planlayın. | GDPR katmanı uygulanmayabilir, ama diğer kontrolleri sürdürün. |
| Site ToS’u scraping’i açıkça yasaklıyor mu? | Sözleşme ihlali riski var. API, lisans ya da hukuki inceleme düşünün. | Sözleşmesel risk daha düşük, ama robots.txt’yi kontrol edin. |
| Bir veri tabanının esaslı bir kısmını mı çıkarıyorsunuz? | Sui generis veri tabanı hakkı ihlal edilmiş olabilir. Lisanslama veya daha dar kapsamlı çıkarım düşünün. | Telif hakkı yine de kopyalanan tekil içeriklere uygulanabilir. |
| Giriş, CAPTCHA veya erişim kontrollerini mi aşmaya çalışıyorsunuz? | CMA 1990 kapsamında potansiyel bir suç söz konusu olabilir. Durun ve hukuki inceleme alın. | Erişim gerçekten herkese açıksa CMA riski daha düşüktür. |
| Amaç ticari olmayan araştırma mı? | Hukuka uygun erişiminiz varsa Section 29A TDM istisnası uygulanabilir. | Ticari kullanım için geniş bir Birleşik Krallık TDM güvenli limanı yoktur. Tam IP ve sözleşme analizi gerekir. |
Keşke ekibimiz için scraping uyumluluğunu araştırmaya ilk başladığımda biri bunu bana verseydi. Hukuki karmaşıklığı, bir dakikadan kısa sürede çalıştırabileceğiniz yapılandırılmış bir öz-değerlendirmeye dönüştürüyor.
Gerçek Senaryolar: Sizin Belirli Scraping Faaliyeti Birleşik Krallık’ta Yasal mı?
Soyut hukuk bir şeydir. İnsanların gerçekten bilmek istediği şey şudur: “Benim özgü projem başımı derde sokar mı?”
Yerinde bir soru. İşte Birleşik Krallık’ta sık görülen beş scraping kullanım alanı ve her biri için kısa bir hukuki risk değerlendirmesi.
Karşılaştırma İçin Ürün Fiyatlarını Scrape Etmek
En yaygın ve çoğu zaman en düşük riskli iş kullanım alanlarından biri. Fiyatlar olgusal verilerdir ve PriceSpy gibi sitelerin çalışma biçimi de otomatik fiyat toplama üzerine kuruludur.
Yine de risk tamamen ortadan kalkmaz. Hedef sitenin ToS’u scraping’i yasaklıyorsa, ürün açıklamalarını veya görselleri kopyalıyorsanız ya da özenle derlenmiş bir ürün veri tabanının esaslı bir kısmını çıkarıyorsanız, sözleşme, telif ve veri tabanı hakkı sorunları doğabilir.
Risk seviyesi: DÜŞÜK ila ORTA
Temel uyum adımı: Yalnızca olgusal fiyat alanlarını toplayın, ürün açıklamalarını kelimesi kelimesine kopyalamayın, ToS ve robots.txt’ye uyun, rate limiting kullanın ve rakibin kataloğunun ham bir kopyasını yeniden yayımlamayın.
Veriyi Ticari Olarak Scrape Edip Yeniden Satmak
Açık ara en yüksek riskli ticari senaryo. Başkasının veri yatırımını satılacak bir ürüne dönüştürüyorsunuz — ve bu, dört hukuki ayağın hepsini aynı anda ilgilendirebilir.
Risk seviyesi: YÜKSEK
Temel uyum adımı: Hukuki inceleme şarttır. Veri sahipleriyle lisans anlaşmaları düşünün. Ürün kişisel veri içeriyorsa, bir veri koruma etki değerlendirmesi ekleyin.
Lead Oluşturma İçin İş İletişim Bilgileri Çıkarmak
Konuştuğum her satış ekibi bunun bir versiyonunu yapıyor: dizinlerden e-postalar, telefon numaraları ve şirket adları scrape etmek. Peki tuzak ne? İş iletişim verileri çoğu zaman kişisel veri içerir. Kamuya açık olsa bile, adı geçen bir çalışanın e-postası kişisel veridir.
Risk seviyesi: ORTA
Temel uyum adımı: Meşru Menfaat Değerlendirmesi yapın, mümkün olduğunda yalnızca iş amaçlı (özel hayata ilişkin olmayan) iletişim verisi toplayın, hukuki dayanağınızı belgeleyin ve bir opt-out yolu sağlayın. gibi araçlar burada erişim riskini azaltabilir; çünkü kullanıcının tarayıcısında çalışır — erişebildiği tek şey, kullanıcının zaten görebildiği içeriktir; erişim kontrollerini aşmaz.
Akademik veya Portföy Amaçlı Veri Analizi
Gerçekten ticari olmayan bir araştırma yapıyorsanız, en güçlü telif hakkı istisnası yoluna sahipsiniz: hukuka uygun erişiminiz olması şartıyla Section 29A CDPA.
Risk seviyesi: DÜŞÜK (gerçekten ticari değilse)
Temel uyum adımı: Ticari olmayan amacı belgeleyin, kaynakları belirtin, mümkünse anonimleştirin veya toplulaştırın ve telifli içerik ya da kişisel veriyi yeniden dağıtmayın.
AI Model Eğitimi İçin İçerik Scrape Etmek
2026’da herkesin sorduğu soru bu — ve cevap hâlâ tam tatmin edici değil. ICO, web scraping ile toplanan kişisel verinin eğitim için kullanılmasını yüksek riskli, görünmeyen işlem olarak değerlendiriyor. Birleşik Krallık hükümetinin 2026 raporu geniş bir ticari TDM istisnası getirmedi.
Risk seviyesi: ORTA ila YÜKSEK
Temel uyum adımı: Lisanslama, veri seti kökeni, telif analizi, kişisel veri filtreleme, hukuki dayanak belgeleri ve Birleşik Krallık politika değişikliklerini yakından izleme.
Senaryo Özeti Tablosu
| Senaryo | Tetiklenen Temel Yasalar | Risk Seviyesi | Temel Uyum Adımı |
|---|---|---|---|
| Ürün fiyat takibi | ToS, veri tabanı hakları, telif hakkı | Düşük–Orta | Olgusal alanları toplayın, site sinyallerine uyun |
| Ticari veri yeniden satışı | Dört ayağın hepsi | Yüksek | Hukuki inceleme ve lisanslama şart |
| B2B lead oluşturma | UK GDPR, ToS | Orta | LIA yapın, kişisel veriyi en aza indirin |
| Akademik araştırma | Telif (TDM istisnası), kişisel veri varsa GDPR | Düşük | Amacı ticari olmayan şekilde tutun, yeniden yayımlamayın |
| AI model eğitimi | UK GDPR, telif hakkı, veri tabanı hakları | Orta–Yüksek | Veriyi lisanslayın, hukuki dayanağı belgeleyin, politikayı izleyin |
Birleşik Krallık vs. ABD vs. AB: Web Scraping Hukuku Nasıl Farklılaşır
Yalnızca Birleşik Krallık’ta faaliyet gösteriyorsanız bu bölümü atlayabilirsiniz. Ama benim konuştuğum işletmelerin çoğu uluslararası scrape yapıyor — ya da en azından başka yargı bölgelerinde barındırılan siteleri scrape ediyor. Farklar düşündüğünüzden daha önemli.
| Hukuki Boyut | 🇬🇧 Birleşik Krallık | 🇺🇸 ABD | 🇪🇺 AB |
|---|---|---|---|
| Birincil veri koruma hukuku | UK GDPR + DPA 2018 | Federal düzeyde eşdeğer yok (eyalet yasaları değişir) | EU GDPR |
| Temel scraping emsal kararı | Clearview AI (ICO £7.5M ceza) | hiQ v LinkedIn (kamuya açık verinin scrape edilmesi OK, Ninth Circuit — ama hiQ kalıcı olarak men edildi ve nihai uzlaşma hükmü kapsamında $500K ödedi) | Ryanair v PR Aviation (CJEU, C-30/14, veri tabanı hakları) |
| Bilgisayar erişim hukuku | Computer Misuse Act 1990 | CFAA (Van Buren, 2021 ile daraltıldı) | Üye devlete göre değişir |
| Telif hakkı / TDM istisnası | Dar: yalnızca ticari olmayan araştırma (Section 29A) | Fair use doktrini (daha geniş, duruma göre) | DSM Direktifi Madde 3 & 4 (hak saklama ile daha geniş TDM hakları) |
| Veri tabanı hakları | Evet (AB Database Directive’den korundu) | Federal düzeyde eşdeğeri yok | Database Directive kapsamındaki sui generis hak |
| ToS’un uygulanabilirliği | Sözleşme hukuku uygulanır; browsewrap tartışmalı | Karışık: browsewrap çoğu zaman uygulanamaz | Değişir; Ryanair ToS konumunu güçlendirdi |
Pratik çıkarım şu: Birden fazla yargı alanında scrape yapıyorsanız, geçerli olan en sıkı yasaya uyun. ABD, hiQ kapsamında kamuya açık verilere erişim konusunda daha izin verici; ancak hiQ, herkese açık bir izin belgesi değildir (hiQ sonunda LinkedIn’i scrape etmekten men edildi ve $500K ödedi). AB, DSM Direktifi üzerinden daha geniş bir TDM mimarisine sahiptir. Birleşik Krallık ise ikisinin arasında bir yerde durur — geniş bir ticari TDM istisnası yok, güçlü veri tabanı hakları var ve aktif bir düzenleyici mevcut.
Cezalar ve Yaptırımlar: Yakalanırsanız Gerçekte Ne Olur?
“Ceza” ve “hukuki sorun” gibi muğlak uyarılar kimseye yardımcı olmaz. İşte gerçek rakamlar.
UK GDPR Cezaları
Azami ceza: , hangisi daha yüksekse.
Gerçek örnek: Clearview AI, Birleşik Krallık sosyal medyasından yüz görüntüleri scrape ettiği için 2022’de ICO tarafından para cezasına çarptırıldı. First-tier Tribunal bunu yargı yetkisi gerekçesiyle bozdu; ancak ICO’nun itirazını kabul edip dosyayı geri gönderdi. ICO, Aralık 2025 itibarıyla Clearview’in aldığını belirtti.
Computer Misuse Act Ceza Yaptırımları
- Section 1 (yetkisiz erişim): en fazla
- Section 3 (yetkisiz bozma): en fazla
Sıradan, herkese açık sayfa scraping’i için cezai kovuşturma son derece nadirdir.
Davranış hacking, kimlik bilgisi kötüye kullanımı, CAPTCHA atlatma veya hizmeti bozma gibi görünmeye başladığında risk profili dramatik biçimde değişir.
Telif Hakkı ve Veri Tabanı Hakları
Medeni tazminat ve ihtiyati tedbir. Kasten yapılan ticari ihlaller için cezai yaptırımlar mümkündür, ancak çoğu scraping anlaşmazlığı medeni dava olarak ilerler.
Sözleşme (ToS) İhlali
Medeni tazminat, hesap kapatma, IP engelleme. Bu genellikle en yaygın pratik yaptırım ve çoğu zaman ilk gerçekleşen şeydir.
Ceza Şiddeti Özeti
| Hukuki Çerçeve | Azami Ceza | Tipik İşletme Scraping’i İçin Olasılık | Gerçek Dünya Örneği |
|---|---|---|---|
| UK GDPR | £17.5m veya küresel cironun %4’ü | Kişisel veri büyük ölçekteyse orta; kişisel değilse düşük | Clearview AI £7.5M ceza |
| CMA Section 1 | 2 yıl hapis | Herkese açık sayfalarda düşük; kontroller aşılırsa daha yüksek | Yetkisiz erişim için CPS rehberi |
| CMA Section 3 | 10 yıl hapis | Trafik sistemleri bozmadıkça düşük | DDoS tarzı bozma örnekleri |
| Telif/veri tabanı hakları | Tazminat ve ihtiyati tedbir | Korunan içeriği veya derlenmiş veri tabanlarını kopyalarken orta | Ryanair ve BHB çizgisi davalar |
| ToS ihlali | Tazminat, hesap sonlandırma, engelleme | Pratik yaptırım yolu olarak yüksek | Ryanair screen-scraping uyuşmazlıkları |
Doğru Scraping Aracı Hukuki Riskinizi Nasıl Azaltır?
Seçtiğiniz araç, hukuka aykırı bir scraping’i hukuka uygun hâle getirmez. Ama önlenebilir riski azaltabilir.
Benim deneyimime göre, site sinyallerine saygı duyan bir araç ile her şeyi agresif biçimde aşan bir araç arasındaki fark, çoğu zaman sıradan bir veri projesi ile hukuki baş ağrısı arasındaki farktır.
robots.txt ve Site Sinyallerine Saygı
Sorumlu bir araç, scraping öncesinde robots.txt’yi kontrol etmeyi ve buna uymayı kolaylaştırmalıdır. Hukuken bağlayıcı olmasa da robots.txt’ye uyum, mahkemeler ve ICO tarafından iyi niyet kanıtı olarak değerlendirilir. Thunderbit’in , kullanıcılara herkese açık verileri scrape etmelerini ve robots.txt ile şartlara uymalarını tavsiye eder.
Tarayıcı Tabanlı Scraping vs. Bulut Tabanlı Scraping Seçenekleri
Bu ayrım hukuken önemlidir. Tarayıcı tabanlı scraping, kullanıcının kimliği doğrulanmış oturumunda görebildiği şeylere erişir — özünde el ile yaptığınız işi otomatikleştirir. Bulut tabanlı scraping ise sunuculardan istek gönderir; herkese açık siteler için daha hızlıdır ama sitenin gözünden “otomatik erişim” gibi görünebilir.
her iki modu da sunar. Tarayıcı tabanlı scraping, giriş gerektiren siteler için uygundur (CMA kapsamında “yetkisiz erişim” riskini azaltır); bulut tabanlı scraping ise hızın önemli olduğu herkese açık e-ticaret sayfalarında iyi çalışır. Bu ikili yaklaşım, kullanıcıların scraping yöntemini her sitenin hukuki risk profiline göre eşleştirmesini sağlar.
Erişim Kontrollerini Aşmama
Tarayıcı içinde çalışan ve CAPTCHA kırmayan ya da giriş duvarlarını dolaşmayan bir araç, Computer Misuse Act açısından doğası gereği daha düşük risklidir. Thunderbit’in Chrome uzantısı kullanıcının tarayıcı oturumu içinde çalışır — yalnızca kullanıcının zaten görebildiği içeriklere erişir.
Şeffaf Veri Dışa Aktarımı (GDPR Uyumunu Destekler)
Thunderbit verileri doğrudan Excel, Google Sheets, Airtable veya Notion’a aktarır. Verinin nereye gideceğine kullanıcı karar verir. Bu, GDPR şeffaflığını ve hukuki dayanak belgelendirmesini destekler: tam olarak hangi veriyi topladığınızı ve nereye gittiğini bilirsiniz. Araç içinde gizli bir işleme ya da veri saklama yoktur.
Rate Limiting ve Sorumlu Erişim
Aşırı istek hacimleri CMA Section 3’ü (yetkisiz bozma) tetikleyebilir. Rate limiting yalnızca teknik bir iyi uygulama değildir — aynı zamanda hukuki bir korumadır. Sorumlu araçlar sunucuları ezmez; bu da hem hukuki riski hem de IP’nizin engellenme ihtimalini azaltır.

Birleşik Krallık Web Scraping’i İçin Pratik Uyum Kontrol Listesi
Bir şeyi scrape etmeden önce bunu uygulayın:
- Hedef web sitesinin Kullanım Şartlarını ve Acceptable Use Policy’sini okuyun.
- robots.txt dosyasını kontrol edin ve ilgili yolların yasaklı olup olmadığını belgeleyin.
- Toplamak istediğiniz verinin kişisel veri olup olmadığını belirleyin. Öyleyse, UK GDPR kapsamındaki hukuki dayanağınızı saptayın.
- Bir veri tabanının “esaslı bir kısmını” mı çıkarıyorsunuz değerlendirin.
- Herhangi bir teknik erişim kontrolünü aşmadığınızdan emin olun (CAPTCHA’lar, girişler, rate limit’ler).
- Amacınız ticari olmayan araştırmaysa, TDM istisnasından yararlanmak için bunu belgeleyin.
- Rate limiting kullanın. Hedef sunucuyu bunaltmayın.
- Her şeyi belgeleyin: hukuki dayanağınız, ToS incelemeniz, toplanan veri alanları, dışa aktarma hedefleri, saklama süresi.
- Şüphedeyseniz, veri koruma ve IP alanında uzman bir avukattan hukuki danışmanlık alın.
Bu kontrol listesi bir avukat görüşünün yerini tutmaz — ama size sağlam bir başlangıç çerçevesi verir ve sorular gündeme gelirse iyi niyet gösterir.
Temel Çıkarımlar
- Web scraping Birleşik Krallık’ta yasa dışı değildir — ama UK GDPR, telif/veri tabanı hakları, sözleşme hukuku ve Computer Misuse Act olmak üzere dört örtüşen hukuki çerçeveyle düzenlenir.
- Her scraping işleminin hukuka uygunluğu; neyi scrape ettiğinize, buna nasıl eriştiğinize, web sitesinin şartlarının ne dediğine ve veriyi nasıl kullandığınıza bağlıdır.
- Kişisel veri scraping’i en yüksek uyum yükünü taşır. Meşru menfaatler genellikle tek uygulanabilir hukuki dayanak olur ve belgelendirilmiş bir denge testi gerektirir.
- Birleşik Krallık’ta geniş kapsamlı bir ticari TDM istisnası yoktur. Ticari AI eğitimi ve veri seti yeniden satışı, lisans olmadan yüksek risklidir.
- Başlamadan önce kendi durumunuzu değerlendirmek için yukarıdaki karar akışını ve senaryo tablosunu kullanın.
- Uyum en iyi uygulamalarıyla uyumlu araçlar seçin: tarayıcı tabanlı erişim, CAPTCHA aşmama, şeffaf veri dışa aktarma ve rate limiting. bu ilkeler düşünülerek tasarlanmıştır — ama uyum sorumluluğu her zaman kullanıcıdadır.
- Şüphedeyseniz, gerekçenizi belgeleyin ve bir avukatla konuşun. Hukuki görüşün maliyeti, çoğu zaman bir ICO soruşturmasının maliyetinden çok daha düşüktür.
SSS
Birleşik Krallık’ta herkese açık veriyi scrape etmek yasal mı?
Genellikle evet — herkese açık veriyi scrape etmek, giriş gerektiren veya özel veriyi scrape etmekten daha düşük risklidir. Ama “herkese açık” demek, “istediğin gibi kullanabilirsin” anlamına gelmez. UK GDPR herkese açık kişisel verilere yine uygulanabilir; telif hakkı kopyalanan ifadelere uygulanabilir; veri tabanı hakları özenle derlenmiş koleksiyonları koruyabilir; ToS ise otomatik erişimi sınırlayabilir.
Birleşik Krallık sitelerinden e-posta ve telefon numarası scrape edebilir miyim?
Veri kişisel veriyse (e-posta ve telefon numaraları genellikle öyledir), UK GDPR kapsamında hukuki dayanağa ihtiyacınız vardır. Meşru menfaatler, B2B lead oluşturma için en yaygın dayanak olsa da bir denge testi yapmalı, topladığınız veriyi en aza indirmeli ve bir opt-out yolu sağlamalısınız. Özel hayatla ilgili iletişim verilerini (cep numaraları, kişisel e-postalar) scrape etmek, iş dizinlerindeki listelemelere kıyasla çok daha risklidir.
Birleşik Krallık hukukunda web scraping ile web crawling arasındaki fark nedir?
Hukuken anlamlı bir fark yoktur — hukuk etiketlere değil davranışa bakar. Crawling genellikle sayfaları keşfetmek veya indekslemek; scraping ise genellikle yapılandırılmış veri çıkarmaktır. İkisi de web sitelerine otomatik erişimi içerir ve aynı hukuki çerçevelere tabidir.
robots.txt scraping’i yasa dışı yapar mı?
Hayır. robots.txt hukuken bağlayıcı değildir. Ancak onu yok saymak hukuki riskinizi artırır; çünkü mahkemeler ve ICO bunu site sahibinin niyetinin bir kanıtı olarak görür. robots.txt’yi yok sayıp bir de sitenin ToS’u scraping’i yasaklıyorsa, risk faktörlerini üst üste yığmış olursunuz — ve bu savunması çok daha zor bir konumdur.
Birleşik Krallık’ta web scraping nedeniyle cezai kovuşturmaya uğrayabilir miyim?
Yalnızca erişim kontrollerini (CAPTCHA’lar, girişler, IP blokları) aşarsanız veya kapsamında bir bilgisayar sistemine zarar verirseniz. Gerçekten herkese açık verinin, makul hacimlerde ve teknik kaçınma olmadan scrape edilmesi, cezai suçlamaya dönüşmesi son derece düşük olasılıktır. Davranış hacking’e ya da kasıtlı hizmet bozma davranışına benzediğinde risk profili dramatik biçimde değişir.
Daha Fazla Bilgi