

Web scraping için hangi programlama dilini seçmelisin? Cevap tamamen projenin karakterine bağlı — ve sırf yanlış dili seçtiği için “tamam ya, ben bu işi bırakıyorum” noktasına gelen geliştiriciler gördüm.
Web scraping yazılım pazarı 2024’te $1,01 milyar dolara ulaştı ve 2032’ye kadar iki katından fazla büyümesi bekleniyor. Doğru dil; daha hızlı çıktı, daha az bakım demek. Yanlış dil ise sürekli patlayan scraper’lar ve çöpe giden hafta sonları.
Yıllardır otomasyon araçları geliştiriyorum. Aşağıda scraping için en sık başvurduğum yedi dili; kod örnekleri, net artı-eksi’ler ve bazen de kodu tamamen kenara bırakıp Thunderbit kullanmanın daha mantıklı olduğu senaryolarla birlikte anlatıyorum.
Web Scraping için En İyi Dili Nasıl Seçtik?
Web scraping işinde her dil aynı ligde oynamıyor. Birkaç kritik kriter var; doğru seçim projeyi uçurur, yanlış seçim yere çakar:
- Kullanım Kolaylığı: Ne kadar çabuk ayağa kalkıyorsun? Söz dizimi akıcı mı, yoksa “Hello World” için bile bilgisayar bilimi doktorası mı lazım?
- Kütüphane Desteği: HTTP istekleri, HTML ayrıştırma ve dinamik içerik yönetimi için sağlam kütüphaneler var mı? Yoksa her şeyi sıfırdan mı örüyorsun?
- Performans: Milyonlarca sayfayı kaldırır mı, yoksa birkaç yüz sayfada nefesi mi kesilir?
- Dinamik İçerikle Başa Çıkma: Modern siteler JavaScript’e bayılıyor. Seçtiğin dil buna yetişebiliyor mu?
- Topluluk ve Destek: Duvara tosladığında (toslayacaksın), el uzatacak bir topluluk var mı?
Bu kriterlere — ve gecenin bir yarısı yapılan bolca deneme-yanılmaya — dayanarak ele alacağım yedi dil şunlar:
- Python: Hem yeni başlayanların hem profesyonellerin gözdesi.
- JavaScript & Node.js: Dinamik içerikte en rahat seçeneklerden.
- Ruby: Tertemiz söz dizimi, hızlı script’ler.
- PHP: Sunucu tarafında pratik ve erişilebilir.
- C++: Ham hız gerektiğinde.
- Java: Kurumsal ölçekte sağlam ve ölçeklenebilir.
- Go (Golang): Hızlı ve concurrency konusunda çok güçlü.
Ve eğer “Shuai, ben hiç kod yazmak istemiyorum” diyorsan, en sonda Thunderbit kısmını sakın atlama.
Python ile Web Scraping: Yeni Başlayan Dostu Güç Merkezi
Herkesin favorisiyle açalım: Python. Veriyle uğraşan bir odaya “web scraping için en iyi programlama dili hangisi?” diye sorsan, Taylor Swift konserindeki tezahürat gibi Python sesi yükselir.
Neden Python?
- Yeni başlayan dostu söz dizimi: Python kodunu sesli okuyunca neredeyse İngilizce gibi akar.
- Rakipsiz kütüphane ekosistemi: HTML ayrıştırma için BeautifulSoup, büyük ölçekli crawling için Scrapy, HTTP için Requests ve tarayıcı otomasyonu için Selenium — hepsi elinin altında.
- Devasa topluluk: Sadece web scraping tarafında bile Stack Overflow’da 33.000+ soru var.
Python Örnek Kod: Sayfa Başlığını Çekme
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Page title: {title}")
Güçlü Yanları:
- Hızlı geliştirme ve prototipleme.
- Tonla eğitim içeriği ve soru-cevap kaynağı.
- Veri analiziyle müthiş uyum: Python ile scrape et, pandas ile analiz et, matplotlib ile görselleştir.
Sınırlamaları:
- Çok büyük işlerde derlenen dillere göre daha yavaş kalabilir.
- Aşırı dinamik sitelerde süreç ağırlaşabilir (Selenium ve Playwright burada imdada yetişir).
- Milyonlarca sayfayı “ışık hızında” çekmek için en ideal seçenek değildir.
Özet:
Scraping’e yeni giriyorsan ya da hızlıca sonuç almak istiyorsan, web scraping için en iyi dil Python’dur — net. Python’un web scraping’de neden baskın olduğuna dair daha fazlası.
JavaScript & Node.js: Dinamik Siteleri Rahatça Scrape Etmek
Python bir İsviçre çakısıysa, JavaScript (ve Node.js) özellikle JavaScript’le şişirilmiş modern sitelerde tam bir matkap gibi çalışır.
Neden JavaScript/Node.js?
- Dinamik içerikte doğal avantaj: Tarayıcı dili olduğu için kullanıcı ne görüyorsa onu yakalar — sayfa React, Angular veya Vue ile kurulmuş olsa bile.
- Varsayılan olarak async: Node.js aynı anda yüzlerce isteği çevirebilir.
- Web geliştiricilere tanıdık: Web geliştirdiysen zaten JavaScript’e aşinasındır.
Öne Çıkan Kütüphaneler:
- Puppeteer: Headless Chrome otomasyonu.
- Playwright: Çoklu tarayıcı otomasyonu.
- Cheerio: Node için jQuery tadında HTML ayrıştırma.
Node.js Örnek Kod: Puppeteer ile Sayfa Başlığını Çekme
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Page title: ${title}`);
await browser.close();
})();
Güçlü Yanları:
- JavaScript ile render edilen içeriği doğal şekilde yakalar.
- Sonsuz kaydırma, pop-up ve etkileşimli sayfalarda çok başarılıdır.
- Büyük ölçekte eşzamanlı scraping için verimlidir.
Sınırlamaları:
- Async mantığı yeni başlayanları biraz zorlayabilir.
- Headless tarayıcılar paralel çalışınca RAM’i hızlıca sömürebilir.
- Python’a kıyasla veri analizi tarafındaki araçlar daha sınırlıdır.
JavaScript/Node.js ne zaman web scraping için en iyi seçim olur?
Hedef siten dinamikse veya tarayıcı aksiyonlarını otomatikleştirmen gerekiyorsa. Node.js ile dinamik içerik scraping hakkında daha fazlası.
Ruby: Hızlı Web Scraping Script’leri için Temiz Söz Dizimi
Ruby sadece Rails ve “şık kod şiiri” değil. Web scraping için de gayet sağlam bir seçenek — özellikle kodun haiku gibi akmasını seviyorsan.
Neden Ruby?
- Okunabilir ve ifade gücü yüksek söz dizimi: Ruby ile yazdığın bir scraper, alışveriş listesi gibi okunur.
- Prototipleme için ideal: Yazması hızlı, değiştirmesi kolay.
- Önemli kütüphaneler: Ayrıştırma için Nokogiri, gezinmeyi otomatikleştirmek için Mechanize.
Ruby Örnek Kod: Sayfa Başlığını Çekme
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Page title: #{title}"
Güçlü Yanları:
- Çok okunabilir ve kısa.
- Küçük projeler, tek seferlik script’ler veya zaten Ruby kullanıyorsan harika.
Sınırlamaları:
- Büyük işlerde Python veya Node.js kadar hızlı değildir.
- Scraping tarafında daha az kütüphane ve daha küçük topluluk.
- JavaScript ağırlıklı siteler için ideal değil (Watir veya Selenium ile çözülür).
En uygun senaryo:
Ruby kullanıyorsan veya hızlı bir script çıkarmak istiyorsan Ruby keyiflidir. Devasa ve dinamik scraping için başka seçeneklere bakmak daha doğru olur.
PHP: Web Verisi Çıkarmada Sunucu Tarafı Pratikliği
PHP kulağa “eski internet” gibi gelebilir ama hâlâ sahnede — özellikle veriyi doğrudan sunucunda çekmek istiyorsan.
Neden PHP?
- Her yerde çalışır: Çoğu web sunucusunda PHP zaten hazır gelir.
- Web uygulamalarına kolay entegrasyon: Veriyi çekip aynı akışta sitende gösterebilirsin.
- Önemli kütüphaneler: HTTP için cURL, istekler için Guzzle, headless tarayıcı otomasyonu için Symfony Panther.
PHP Örnek Kod: Sayfa Başlığını Çekme
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Page title: $title\n";
?>
Güçlü Yanları:
- Web sunucularında dağıtımı kolay.
- Web iş akışının bir parçası olarak scraping için uygun.
- Basit sunucu tarafı scraping işlerinde hızlıdır.
Sınırlamaları:
- İleri seviye scraping için kütüphane desteği daha sınırlı.
- Yüksek eşzamanlılık veya dev ölçek için tasarlanmamıştır.
- JavaScript ağırlıklı siteler zorlayabilir (Panther burada yardımcı olur).
En uygun senaryo:
Teknoloji yığınında zaten PHP varsa veya veriyi çekip sitende göstermek istiyorsan, PHP gayet mantıklı bir tercihtir. Scraping için PHP vs Python hakkında daha fazlası.
C++: Büyük Ölçekli Projeler için Yüksek Performanslı Web Scraping
C++ programlama dillerinin kaslı spor arabasıdır. Ham hız ve kontrol istiyorsan ve biraz “el emeği” gözünü korkutmuyorsa, C++ seni bayağı ileri taşır.
Neden C++?
- Çok hızlı: CPU ağırlıklı işlerde çoğu dili geride bırakır.
- İnce ayar kontrolü: Bellek, thread’ler ve performans optimizasyonlarında tam kontrol.
- Önemli kütüphaneler: HTTP için libcurl, ayrıştırma için htmlcxx.
C++ Örnek Kod: Sayfa Başlığını Çekme
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Page title: " << title << std::endl;
} else {
std::cout << "Title tag not found" << std::endl;
}
return 0;
}
Güçlü Yanları:
- Devasa scraping işlerinde çok yüksek hız.
- Scraping’i yüksek performanslı sistemlere entegre etmek için ideal.
Sınırlamaları:
- Öğrenme eğrisi dik (kahveyi hazır et).
- Manuel bellek yönetimi.
- Üst seviye kütüphaneler sınırlı; dinamik içerik için uygun değil.
En uygun senaryo:
Milyonlarca sayfayı çekmen gerekiyorsa veya performans “olmazsa olmaz” ise. Yoksa scraping’den çok debug’a gömülme ihtimalin var.
Java: Kurumsal Seviyede Web Scraping Çözümleri
Java, kurumsal dünyanın yük beygiri. Uzun süre çalışacak, çok veri kaldıracak ve kıyamet kopsa bile ayakta kalacak bir şey kuruyorsan Java iyi bir yol arkadaşıdır.
Neden Java?
- Sağlam ve ölçeklenebilir: Büyük ve uzun soluklu scraping projeleri için biçilmiş kaftan.
- Güçlü tip sistemi ve hata yönetimi: Prod ortamında daha az sürpriz.
- Önemli kütüphaneler: Ayrıştırma için Jsoup, tarayıcı otomasyonu için Selenium WebDriver, HTTP için Apache HttpClient.
Java Örnek Kod: Sayfa Başlığını Çekme
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Page title: " + title);
}
}
Güçlü Yanları:
- Yüksek performans ve eşzamanlılık.
- Büyük ve sürdürülebilir kod tabanları için çok uygun.
- Dinamik içerik için iyi destek (Selenium veya HtmlUnit ile).
Sınırlamaları:
- Söz dizimi daha “uzun”; script dillerine göre daha fazla kurulum ister.
- Küçük, tek seferlik işler için fazla ağır kalabilir.
En uygun senaryo:
Kurumsal ölçekte scraping veya uzun vadede güvenilirlik ve ölçeklenebilirlik gerektiğinde.
Go (Golang): Hızlı ve Eşzamanlı Web Scraping
Go nispeten yeni sayılır ama özellikle yüksek hızlı ve eşzamanlı scraping tarafında hızlıca öne çıktı.
Neden Go?
- Derlenen dil hızı: C++’a yakın performans.
- Yerleşik concurrency: Goroutine’ler paralel scraping’i ciddi anlamda kolaylaştırır.
- Önemli kütüphaneler: Scraping için Colly, ayrıştırma için Goquery.
Go Örnek Kod: Sayfa Başlığını Çekme
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page title:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Error:", err)
}
}
Güçlü Yanları:
- Büyük ölçekli scraping’de çok hızlı ve verimli.
- Dağıtımı kolay (tek binary).
- Eşzamanlı crawling için çok uygun.
Sınırlamaları:
- Python veya Node.js kadar büyük bir topluluğu yok.
- Üst seviye scraping kütüphaneleri daha az.
- JavaScript ağırlıklı siteler için ekstra kurulum gerekir (Chromedp veya Selenium).
En uygun senaryo:
Ölçekli scraping gerektiğinde veya Python yeterince hızlı gelmediğinde. Scraping’de Go vs Python: performans karşılaştırması.
Web Scraping için En İyi Programlama Dillerinin Karşılaştırması
Hepsini tek tabloda toparlayalım. 2026’da web scraping için en doğru dili seçmene yardımcı olacak yan yana bir karşılaştırma:
| Dil/Araç | Kullanım Kolaylığı | Performans | Kütüphane Desteği | Dinamik İçerik Yönetimi | En İyi Kullanım Senaryosu |
|---|---|---|---|---|---|
| Python | Çok Yüksek | Orta | Mükemmel | İyi (Selenium/Playwright) | Genel amaç, yeni başlayanlar, veri analizi |
| JavaScript/Node.js | Orta | Yüksek | Güçlü | Mükemmel (doğal) | Dinamik siteler, async scraping, web geliştiriciler |
| Ruby | Yüksek | Orta | İyi | Sınırlı (Watir) | Hızlı script’ler, prototipleme |
| PHP | Orta | Orta | Orta | Sınırlı (Panther) | Sunucu tarafı, web uygulaması entegrasyonu |
| C++ | Düşük | Çok Yüksek | Sınırlı | Çok Sınırlı | Performans kritik, devasa ölçek |
| Java | Orta | Yüksek | İyi | İyi (Selenium/HtmlUnit) | Kurumsal, uzun süre çalışan servisler |
| Go (Golang) | Orta | Çok Yüksek | Gelişiyor | Orta (Chromedp) | Yüksek hızlı, eşzamanlı scraping |
Ne Zaman Kod Yazmamalı: No-Code Web Scraping Çözümü Olarak Thunderbit
Thunderbit AI Web Scraper’ı Deneyin İş kullanıcıları, pazarlamacılar ve satış ekipleri için no-code, yapay zekâ destekli web scraping. Get Started Free
Dürüst olalım: Bazen tek istediğin şey veridir — kod yazmadan, debug’a girmeden, “bu selector niye yine bozuldu?” stresini yaşamadan. İşte tam bu noktada Thunderbit devreye giriyor.
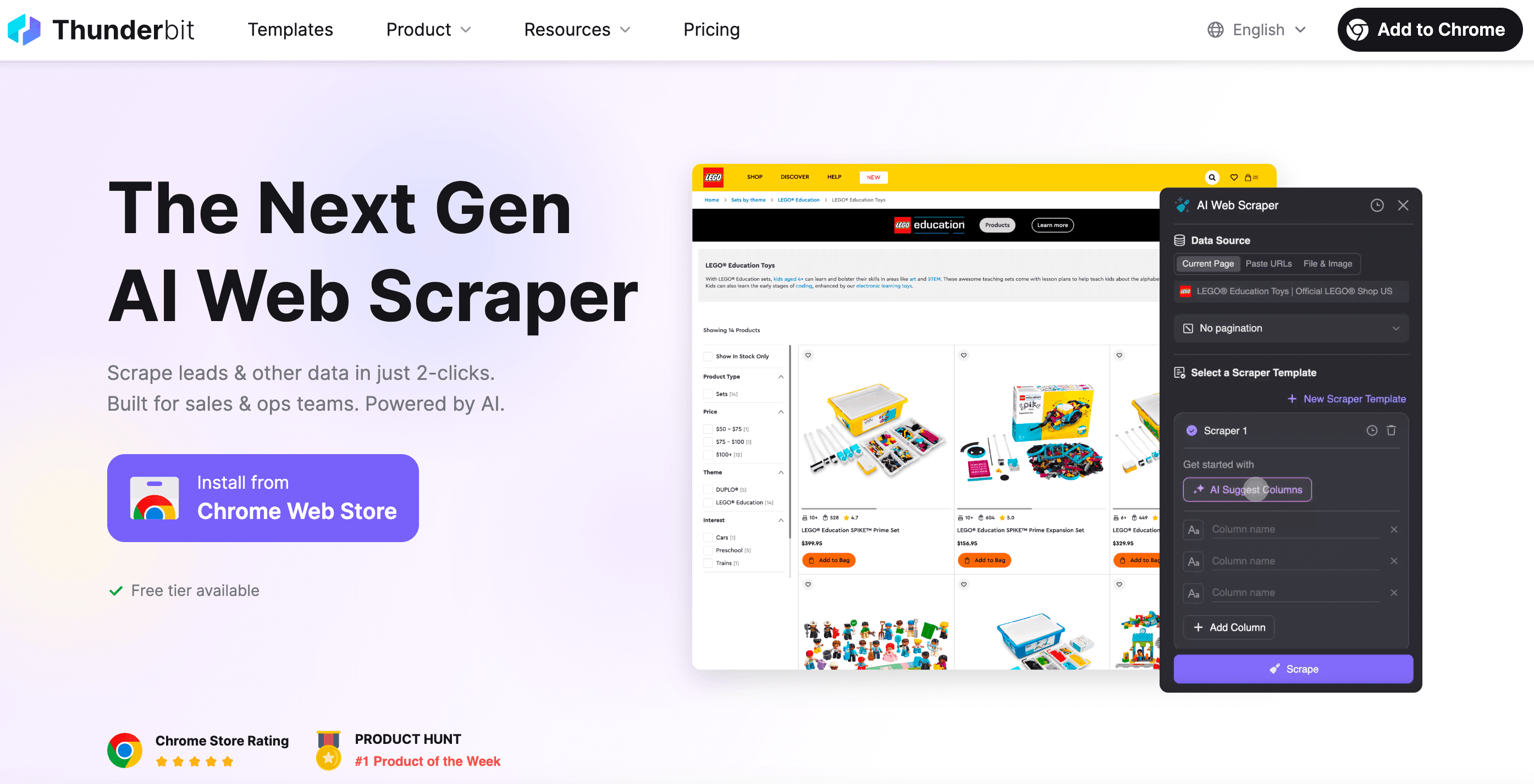
Thunderbit’in kurucu ortağı olarak, web scraping’i yemek siparişi vermek kadar kolay hale getiren bir araç yapmak istedim. Thunderbit’i farklı kılan şeyler:
- 2 Tıkla Kurulum: “AI Suggest Fields” ve ardından “Scrape”e bas. HTTP istekleri, proxy’ler, anti-bot taktikleriyle uğraşmak yok.
- Akıllı Şablonlar: Tek bir scraper template, farklı sayfa düzenlerine uyum sağlayabilir. Site değiştikçe scraper’ı baştan yazman gerekmez.
- Tarayıcı & Bulut Scraping: Tarayıcıda scraping (giriş yapılmış siteler için süper) veya bulutta scraping (herkese açık veride çok hızlı) arasında seçim yap.
- Dinamik İçeriği Yönetir: Thunderbit’in yapay zekâsı gerçek bir tarayıcıyı kontrol eder; sonsuz kaydırma, pop-up, giriş ekranları ve daha fazlasını halleder.
- Her Yere Aktarın: Excel’e indir, Google Sheets, Airtable, Notion’a gönder veya panoya kopyala.
- Bakım Derdi Yok: Site değişirse AI önerisini yeniden çalıştır. Gece yarısı debug seanslarına son.
- Zamanlama & Otomasyon: Scraper’ları belirli aralıklarla çalışacak şekilde planla — cron job yok, sunucu kurulum derdi yok.
- Özel Extractor’lar: E-posta, telefon numarası veya görsel mi lazım? Thunderbit’te bunlar için tek tıkla extractor’lar var.
En güzel tarafı: Tek satır kod bilmen gerekmiyor. Thunderbit; iş kullanıcıları, pazarlamacılar, satış ekipleri, emlak profesyonelleri — kısacası hızlı ve düzenli veriye ihtiyaç duyan herkes için.
Thunderbit’i canlı görmek ister misin? Chrome eklentisini indirin veya demolar için YouTube kanalımıza uğra.
Thunderbit AI Web Scraper’ı Ücretsiz Deneyin
Sonuç: 2026’da Web Scraping için En İyi Dili Seçmek
Veri Scraping Nedir ve Nasıl Yapılır Get Started Free
2026’da web scraping her zamankinden daha ulaşılabilir — ve daha güçlü. Otomasyonun içinde yıllar geçirdikten sonra bende kalan net çıkarımlar şunlar:
- Python, hızlı başlamak ve bol kaynağa yaslanmak isteyenler için hâlâ en iyi seçenek.
- JavaScript/Node.js, dinamik ve JavaScript ağırlıklı sitelerde rakipsiz.
- Ruby ve PHP, özellikle zaten kullanıyorsan hızlı script’ler ve web entegrasyonu için çok iyi.
- C++ ve Go, hız ve ölçek gerektiğinde en yakın arkadaşın.
- Java, kurumsal ve uzun vadeli projelerde güvenilir bir tercih.
- Ve hiç kod yazmak istemiyorsan? Gizli silahın: Thunderbit.
Başlamadan önce kendine şunları sor:
- Projem ne kadar büyük?
- Dinamik içerikle uğraşmam gerekiyor mu?
- Teknik konfor seviyem ne?
- Bir şey inşa etmek mi istiyorum, yoksa sadece veriyi almak mı?
Yukarıdaki kod örneklerinden birini dene ya da bir sonraki işinde Thunderbit’i kullan. Daha derine inmek istersen, daha fazla rehber, ipucu ve gerçek hayattan scraping hikâyeleri için Thunderbit Blog sayfamıza göz at.
Keyifli scraping’ler — verin hep temiz, düzenli ve tek tık uzağında olsun.
Not: Eğer kendini gece 2’de web scraping tavşan deliğinde kaybolmuş bulursan, şunu unutma: Her zaman Thunderbit vardır. Ya da kahve. Ya da ikisi birden.
Thunderbit AI Web Scraper’ı Şimdi Deneyin Get Started Free
SSS
1. 2026’da web scraping için en iyi programlama dili hangisi?
Python; okunabilir söz dizimi, güçlü kütüphaneleri (BeautifulSoup, Scrapy, Selenium gibi) ve geniş topluluğu sayesinde hâlâ ilk sırada. Scraping’i veri analiziyle birleştirmek isteyen yeni başlayanlar ve profesyoneller için çok uygun.
2. JavaScript ağırlıklı web sitelerini scrape etmek için en iyi dil hangisi?
Dinamik sitelerde en iyi tercih JavaScript (Node.js). Puppeteer ve Playwright gibi araçlar tam tarayıcı kontrolü sağlar; React, Vue veya Angular ile yüklenen içerikle etkileşime girebilirsin.
3. Web scraping için no-code bir seçenek var mı?
Evet — Thunderbit dinamik içerikten zamanlamaya kadar her şeyi yöneten, no-code bir AI Web Scraper çözümüdür. “AI Suggest Fields”e tıklarsın ve scraping’e başlarsın. Hızlıca yapılandırılmış veriye ihtiyaç duyan satış, pazarlama veya operasyon ekipleri için idealdir.
Daha Fazlası:




