Kırık linkler. Yetim kalmış sayfalar. Google’ın bir şekilde indeksleyip yıllardır unutmadan tuttuğu, 2019’dan kalma bir “test” sayfası… Bir web sitesi yönetiyorsan bu sancıyı çok iyi bilirsin.
İyi bir tarayıcı (crawler) bunların hepsini tek tek yakalar — üstüne bir de tüm siteni baştan sona haritalandırır ki gerçekten düzeltmeye nereden başlayacağını görebilesin. Ama işin komiği, çoğu kişi “web crawler” ile “web scraper” kavramlarını birbirine katıyor. Aynı şey değiller.
Ben de gerçek sitelerde 10 ücretsiz tarayıcıyı test ettim. Bazıları SEO denetimi tarafında efsane. Bazılarıysa web scraping ve veri çıkarma işlerinde daha kuvvetli. Hangisi iş görüyor, hangisi zaman kaybı; aşağıda açık açık anlattım.
Website Crawler Nedir? Temelleri Anlamak
Önce şu ayrımı netleştirelim: website crawler ile web scraper aynı şey değil. Evet, internette bu iki terim sürekli birbirine giriyor ama aslında bambaşka amaçlara hizmet ediyorlar. Bir tarayıcıyı sitenin “keşif ekibi” gibi düşün: her köşeye girer, her linki takip eder ve tüm sayfalarının haritasını çıkarır. Buradaki iş keşiftir: URL bulmak, site yapısını çözmek ve içeriği indekslemek. Google gibi arama motorlarının botları da böyle çalışır; SEO araçları da sitenin sağlığını kontrol etmek için aynı mantığı kullanır ().
Web scraper ise daha çok “veri avcısıdır”. Tüm haritayla ilgilenmez; onun derdi “değerli olanı” çekip çıkarmaktır: ürün fiyatları, şirket isimleri, yorumlar, e-postalar… ne arıyorsan. Scraper’lar, tarayıcıların bulduğu sayfalardan belirli alanları seçip alır ().
Bir benzetme yapalım:
- Crawler: Marketin tüm reyonlarını dolaşıp bütün ürünlerin envanterini çıkaran kişi.
- Scraper: Direkt kahve rafına gidip tüm organik kahvelerin fiyatını tek tek not eden kişi.
Bu ayrım neden önemli? Çünkü hedefin sitendeki tüm sayfaları bulmaksa (mesela bir SEO denetimi için), ihtiyacın olan şey crawler’dır. Rakibinin sitesinden tüm ürün fiyatlarını çekmek istiyorsan scraper gerekir — hatta en ideal senaryoda ikisini birden yapabilen bir web crawler aracı işini uçurur.
Neden Online Web Crawler Kullanılır? İşletmeler İçin Temel Faydalar
Peki niye bir web tarama aracına kafa yorasın? Çünkü web küçülmüyor; aksine her gün daha da şişiyor. Hatta ve bazı SEO araçları günde sayfayı tarıyor.
Tarayıcıların sana sağlayabilecekleri:
- SEO Denetimleri: Kırık linkler, eksik başlıklar, yinelenen içerik, yetim sayfalar ve daha fazlasını bulma ().
- Link Kontrolü & QA: Kullanıcı görmeden önce 404’leri ve yönlendirme döngülerini yakalama ().
- Site Haritası (Sitemap) Üretimi: Arama motorları ve planlama için otomatik XML sitemap oluşturma ().
- İçerik Envanteri: Tüm sayfaların listesini, hiyerarşisini ve metadatasını çıkarma.
- Uyumluluk & Erişilebilirlik: Her sayfayı WCAG, SEO ve yasal uyumluluk açısından kontrol etme ().
- Performans & Güvenlik: Yavaş sayfaları, aşırı büyük görselleri veya güvenlik sorunlarını işaretleme ().
- Yapay Zekâ & Analiz İçin Veri: Taranan veriyi analitik ya da AI araçlarına besleme ().
Aşağıdaki tablo, kullanım senaryolarını iş rolleriyle eşleştiriyor:
| Kullanım Senaryosu | Kimler İçin İdeal | Fayda / Sonuç |
|---|---|---|
| SEO & Site Denetimi | Pazarlama, SEO, Küçük İşletme Sahipleri | Teknik sorunları bulma, yapıyı optimize etme, sıralamaları iyileştirme |
| İçerik Envanteri & QA | İçerik Yöneticileri, Webmaster’lar | İçeriği denetleme/taşıma, kırık link/görsel yakalama |
| Lead Generation (Scraping) | Satış, İş Geliştirme | Prospecting’i otomatikleştirme, CRM’i güncel lead’lerle doldurma |
| Rekabet Analizi | E-ticaret, Ürün Yöneticileri | Rakip fiyatlarını, yeni ürünleri, stok değişimlerini izleme |
| Sitemap & Yapı Kopyalama | Geliştiriciler, DevOps, Danışmanlar | Yeniden tasarım/yedek için site yapısını klonlama |
| İçerik Toplama | Araştırmacılar, Medya, Analistler | Analiz veya trend takibi için çoklu siteden veri toplama |
| Pazar Araştırması | Analistler, AI Eğitim Ekipleri | Analiz veya AI model eğitimi için büyük veri setleri toplama |
()
En İyi Ücretsiz Website Crawler Araçlarını Nasıl Seçtik?
Birçok geceyi (ve söylemeye utanacağım kadar kahveyi) bu araçları kurcalayarak, dokümantasyon okuyarak ve test taramaları yaparak geçirdim. Şunlara özellikle baktım:
- Teknik Yetenek: Modern siteleri (JavaScript, giriş ekranları, dinamik içerik) kaldırabiliyor mu?
- Kullanım Kolaylığı: Teknik olmayan biri için anlaşılır mı, yoksa komut satırı büyücülüğü mü istiyor?
- Ücretsiz Plan Sınırları: Gerçekten ücretsiz mi, yoksa sadece “tadımlık” mı?
- Online Erişim: Bulut aracı mı, masaüstü uygulaması mı, yoksa kod kütüphanesi mi?
- Özgün Özellikler: AI ile çıkarım, görsel sitemap, olay tabanlı tarama gibi fark yaratan bir şey sunuyor mu?
Her aracı bizzat denedim, kullanıcı yorumlarını taradım ve özellikleri yan yana koyup kıyasladım. Bir araç beni “bilgisayarı camdan atacağım” noktaya getirdiyse, listeye girmedi.
Hızlı Karşılaştırma: 10 Ücretsiz Website Crawler Tek Bakışta
| Araç & Tür | Temel Özellikler | En İyi Kullanım | Teknik Gereksinim | Ücretsiz Plan Detayı |
|---|---|---|---|---|
| BrightData (Bulut/API) | Kurumsal tarama, proxy’ler, JS render, CAPTCHA çözme | Büyük ölçekli veri toplama | Biraz teknik bilgi faydalı | Ücretsiz deneme: 3 scraper, her biri 100 kayıt (toplam ~300 kayıt) |
| Crawlbase (Bulut/API) | API ile tarama, anti-bot, proxy, JS render | Backend tarama altyapısı isteyen geliştiriciler | API entegrasyonu | Ücretsiz: 7 gün ~5.000 API çağrısı, sonra aylık 1.000 |
| ScraperAPI (Bulut/API) | Proxy rotasyonu, JS render, async tarama, hazır endpoint’ler | Geliştiriciler, fiyat takibi, SEO verisi | Minimum kurulum | Ücretsiz: 7 gün 5.000 API çağrısı, sonra aylık 1.000 |
| Diffbot Crawlbot (Bulut) | AI ile tarama + çıkarım, bilgi grafiği, JS render | Ölçekli yapılandırılmış veri, AI/ML | API entegrasyonu | Ücretsiz: aylık 10.000 kredi (yaklaşık 10 bin sayfa) |
| Screaming Frog (Masaüstü) | SEO denetimi, link/meta analizi, sitemap, özel çıkarım | SEO denetimleri, site yöneticileri | Masaüstü uygulama, GUI | Ücretsiz: tarama başına 500 URL, temel özellikler |
| SiteOne Crawler (Masaüstü) | SEO, performans, erişilebilirlik, güvenlik, offline export, Markdown | Geliştiriciler, QA, taşıma, dokümantasyon | Masaüstü/CLI, GUI | Ücretsiz & açık kaynak, GUI raporunda varsayılan 1.000 URL (ayarlanabilir) |
| Crawljax (Java, Açık Kaynak) | JS yoğun siteler için olay tabanlı tarama, statik export | Dinamik web uygulamalarında dev/QA | Java, CLI/konfig | Ücretsiz & açık kaynak, limit yok |
| Apache Nutch (Java, Açık Kaynak) | Dağıtık tarama, eklenti mimarisi, Hadoop entegrasyonu, özel arama | Özel arama motoru, büyük ölçekli tarama | Java, komut satırı | Ücretsiz & açık kaynak, sadece altyapı maliyeti |
| YaCy (Java, Açık Kaynak) | P2P tarama & arama, gizlilik, web/intranet indeksleme | Özel arama, merkeziyetsizlik | Java, tarayıcı arayüzü | Ücretsiz & açık kaynak, limit yok |
| PowerMapper (Masaüstü/SaaS) | Görsel sitemap, erişilebilirlik, QA, tarayıcı uyumluluğu | Ajanslar, QA, görsel haritalama | GUI, kolay | Ücretsiz deneme: 30 gün, masaüstünde tarama başına 100 sayfa / online’da 10 sayfa |
BrightData: Kurumsal Seviyede Bulut Website Crawler

BrightData, web tarama dünyasının “ağır abisi”. Devasa bir proxy ağı var; JavaScript render yapabiliyor, CAPTCHA çözebiliyor ve özel taramalar için IDE sunan bir bulut platformu. Yüzlerce e-ticaret sitesinde fiyat izleme gibi büyük ölçekli veri toplama işlerinde altyapısı gerçekten sağlam ().
Güçlü Yanları:
- Anti-bot önlemleri olan zorlu sitelerde iyi iş çıkarır
- Kurumsal ölçekte büyümeye uygundur
- Popüler siteler için hazır şablonlar sunar
Sınırlamalar:
- Kalıcı ücretsiz plan yok (sadece deneme: 3 scraper, her biri 100 kayıt)
- Basit denetimler için fazla “ağır” kaçabilir
- Teknik olmayanlar için öğrenme eğrisi var
Web’i büyük ölçekte taraman gerekiyorsa BrightData, resmen Formula 1 kiralamak gibi. Sadece test sürüşünden sonra ücretsiz devam etmesini bekleme ().
Crawlbase: Geliştiriciler İçin API Odaklı Ücretsiz Web Crawler

Crawlbase (eski adıyla ProxyCrawl) tamamen programatik tarama mantığıyla çalışıyor. API’ye bir URL yolluyorsun; o da proxy, coğrafi hedefleme ve CAPTCHA gibi işleri arkada halledip HTML’i geri döndürüyor ().
Güçlü Yanları:
- Yüksek başarı oranı (%99+)
- JavaScript yoğun siteleri idare edebilir
- Kendi uygulamana/iş akışına entegre etmek için ideal
Sınırlamalar:
- API veya SDK entegrasyonu şart
- Ücretsiz plan: 7 gün ~5.000 API çağrısı, sonra aylık 1.000
Proxy ile uğraşmadan ölçekli web tarama (ve gerekiyorsa web scraping) yapmak isteyen geliştiriciler için Crawlbase gayet sağlam bir seçenek ().
ScraperAPI: Dinamik Web Taramayı Kolaylaştırma

ScraperAPI, “sen uğraşma ben getiririm” diyen bir API. URL’yi veriyorsun; proxy’leri, headless tarayıcıları ve anti-bot önlemlerini o yönetiyor, sana HTML’i (bazı sitelerde yapılandırılmış veriyi) teslim ediyor. Dinamik sayfalarda özellikle iyi ve ücretsiz katmanı da eli açık ().
Güçlü Yanları:
- Geliştiriciler için aşırı pratik (tek API çağrısı)
- CAPTCHA, IP ban, JavaScript gibi engelleri aşabilir
- Ücretsiz: 7 gün 5.000 API çağrısı, sonra aylık 1.000
Sınırlamalar:
- Görsel tarama raporu sunmaz
- Link takip ederek taramak istiyorsan tarama mantığını senin yazman gerekir
Dakikalar içinde kod tabanına web tarama eklemek istiyorsan ScraperAPI gayet mantıklı.
Diffbot Crawlbot: Otomatik Site Yapısı Keşfi

Diffbot Crawlbot işin “akıllı çocuk” tarafı. Sadece taramakla kalmıyor; AI ile sayfaları sınıflandırıyor (makale, ürün, etkinlik vb.) ve yapılandırılmış veriyi JSON olarak çıkarıyor. Okuduğunu anlayan bir robot stajyer gibi düşün ().
Güçlü Yanları:
- Sadece tarama değil, AI destekli veri çıkarımı da yapar
- JavaScript ve dinamik içeriği yönetebilir
- Ücretsiz: aylık 10.000 kredi (yaklaşık 10 bin sayfa)
Sınırlamalar:
- Geliştirici odaklı (API entegrasyonu gerekir)
- Görsel SEO aracı değil; daha çok veri projelerine uygun
Ölçekli yapılandırılmış veri gerekiyorsa (özellikle AI/analitik için) Diffbot gerçekten çok güçlü.
Screaming Frog: Ücretsiz Masaüstü SEO Tarayıcısı

Screaming Frog, SEO denetimi denince akla gelen klasik masaüstü tarayıcı. Ücretsiz sürümde tarama başına 500 URL’ye kadar gider; kırık linklerden meta etiketlere, yinelenen içerikten sitemap’e kadar her şeyi önüne serer ().
Güçlü Yanları:
- Hızlı, detaylı ve SEO dünyasında güvenilir
- Kod yok — URL’yi gir, başlat
- Tarama başına 500 URL’ye kadar ücretsiz
Sınırlamalar:
- Sadece masaüstü (bulut sürümü yok)
- Gelişmiş özellikler (JS render, zamanlama) ücretli lisans ister
SEO’yu ciddiye alıyorsan Screaming Frog neredeyse “olmazsa olmaz” — ama 10.000 sayfalık siteyi ücretsiz taramasını da bekleme.
SiteOne Crawler: Statik Site Dışa Aktarma ve Dokümantasyon

SiteOne Crawler, teknik denetim tarafında tam bir İsviçre çakısı. Açık kaynak, çok platformlu; tarama/denetim yapmasının yanında dokümantasyon ya da offline kullanım için siteni Markdown’a da aktarabiliyor ().
Güçlü Yanları:
- SEO, performans, erişilebilirlik, güvenlik kapsamı geniş
- Arşivleme veya taşıma için dışa aktarma seçenekleri
- Ücretsiz & açık kaynak, kullanım limiti yok
Sınırlamalar:
- Bazı GUI araçlarına göre daha teknik kalabilir
- GUI raporu varsayılan olarak 1.000 URL ile sınırlı (ayarlanabilir)
Geliştiriciysen, QA yapıyorsan ya da danışmansan ve “derin içgörü” istiyorsan (bir de açık kaynağı seviyorsan) SiteOne tam bir gizli cevher.
Crawljax: Dinamik Sayfalar İçin Açık Kaynak Java Web Crawler
Crawljax daha niş bir web crawler aracı: modern, JavaScript ağırlıklı web uygulamalarını kullanıcı etkileşimlerini (tıklama, form doldurma vb.) taklit ederek taramak için tasarlanmış. Olay tabanlı çalışır ve dinamik bir sitenin statik çıktısını bile üretebilir ().
Güçlü Yanları:
- SPA ve AJAX yoğun siteleri taramada çok güçlü
- Açık kaynak ve genişletilebilir
- Kullanım limiti yok
Sınırlamalar:
- Java ve biraz programlama/konfigürasyon ister
- Teknik olmayan kullanıcıya uygun değil
React ya da Angular uygulamasını gerçek kullanıcı gibi taraman gerekiyorsa Crawljax iyi bir yol arkadaşı.
Apache Nutch: Ölçeklenebilir Dağıtık Website Crawler

Apache Nutch, açık kaynak tarayıcıların “duayeni” sayılır. Devasa, dağıtık taramalar için tasarlanmıştır — kendi arama motorunu kurmak ya da milyonlarca sayfayı indekslemek gibi ().
Güçlü Yanları:
- Hadoop ile milyarlarca sayfaya kadar ölçeklenebilir
- Çok esnek ve genişletilebilir
- Ücretsiz & açık kaynak
Sınırlamalar:
- Öğrenmesi zor (Java, komut satırı, konfigürasyon)
- Küçük siteler veya “hemen halledeyim” işleri için uygun değil
Web’i büyük ölçekte web tarama ile gezmek istiyorsan ve komut satırından çekinmiyorsan Nutch tam sana göre.
YaCy: Peer-to-Peer Web Crawler ve Arama Motoru
YaCy, merkeziyetsiz bir tarayıcı ve arama motoru yaklaşımı getiriyor. Her kurulum siteleri tarayıp indeksliyor; istersen P2P ağa katılıp indeksleri başkalarıyla paylaşabiliyorsun ().
Güçlü Yanları:
- Gizlilik odaklı, merkezi sunucu yok
- Özel/intranet araması kurmak için iyi
- Ücretsiz & açık kaynak
Sınırlamalar:
- Sonuç kalitesi ağın kapsamasına bağlı
- Kurulum biraz uğraştırabilir (Java, tarayıcı arayüzü)
Merkeziyetsizlik fikri hoşuna gidiyorsa ya da kendi arama motorunu kurmak istiyorsan YaCy bayağı ilginç bir seçenek.
PowerMapper: UX ve QA İçin Görsel Sitemap Üretici

PowerMapper, site yapısını görselleştirme işine odaklanıyor. Siteni tarıyor, etkileşimli site haritaları çıkarıyor; ayrıca erişilebilirlik, tarayıcı uyumluluğu ve temel SEO kontrolleri de yapıyor ().
Güçlü Yanları:
- Görsel sitemap’ler ajanslar ve tasarımcılar için çok iyi
- Erişilebilirlik ve uyumluluk kontrolleri
- Kolay GUI, teknik bilgi gerekmez
Sınırlamalar:
- Sadece deneme sürümü (30 gün; masaüstünde tarama başına 100 sayfa / online’da 10 sayfa)
- Tam sürüm ücretli
Müşteriye site haritası sunman gerekiyorsa ya da uyumluluk kontrolü yapacaksan PowerMapper pratik bir çözüm.
İhtiyacınıza Uygun Ücretsiz Web Crawler’ı Seçmek
Bu kadar seçenek varken karar işi biraz “neye ihtiyacın var?” sorusuna bakıyor. Benim hızlı rehberim:
- SEO denetimleri için: Screaming Frog (küçük siteler), PowerMapper (görsel), SiteOne (derin denetimler)
- Dinamik web uygulamaları için: Crawljax
- Büyük ölçek / özel arama için: Apache Nutch, YaCy
- API erişimi isteyen geliştiriciler için: Crawlbase, ScraperAPI, Diffbot
- Dokümantasyon veya arşivleme için: SiteOne Crawler
- Kurumsal ölçekte (deneme ile) için: BrightData, Diffbot
Dikkate alınacak temel kriterler:
- Ölçek: Siten ya da tarama işin ne kadar büyük?
- Kullanım kolaylığı: Kodla aran nasıl; yoksa tıkla-çalıştır mı istiyorsun?
- Dışa aktarma: CSV/JSON gerekiyor mu, başka araçlarla entegrasyon şart mı?
- Destek: Takıldığında topluluk ya da doküman bulabiliyor musun?
Web Crawling ile Web Scraping Buluşunca: Neden Thunderbit Daha Akıllı Bir Seçim
Gerçekçi olalım: çoğu insan web sitelerini “güzel haritalar” çıkarmak için taramıyor. Asıl hedef genelde yapılandırılmış veri almak — ürün listeleri, iletişim bilgileri ya da içerik envanteri gibi. İşte burada devreye giriyor.
Thunderbit sadece tarayıcı değil, sadece scraper da değil — ikisini bir araya getiren, AI destekli bir Chrome eklentisi. Mantığı şöyle:
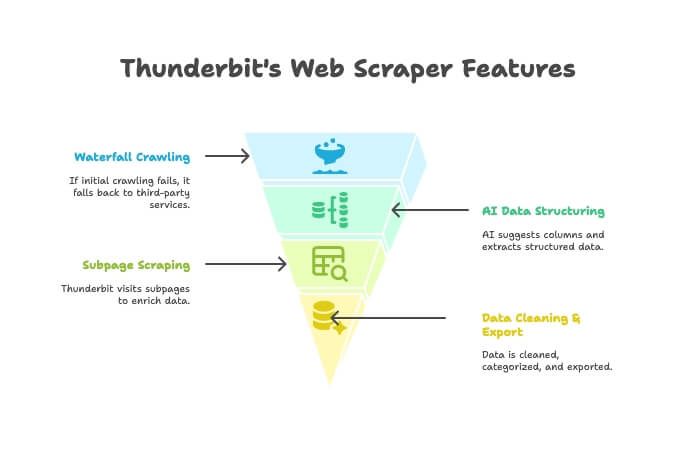
- AI Crawler: Thunderbit, bir crawler gibi siteyi keşfeder.
- Waterfall Crawling: Thunderbit’in kendi motoru sayfayı alamazsa (mesela sert bir anti-bot duvarı varsa), otomatik olarak üçüncü taraf tarama servislerine düşer — ekstra kurulumla uğraşmazsın.
- AI ile Veri Yapılandırma: HTML geldikten sonra Thunderbit’in AI’ı doğru sütunları önerir; tek bir selector yazmadan yapılandırılmış veriyi (isim, fiyat, e-posta vb.) çıkarır.
- Alt Sayfa (Subpage) Scraping: Her ürün sayfasındaki detayları mı istiyorsun? Thunderbit alt sayfaları otomatik dolaşıp tablonu zenginleştirir.
- Veri Temizleme & Dışa Aktarma: Veriyi özetleyebilir, kategorize edebilir, çevirebilir ve tek tıkla Excel, Google Sheets, Airtable veya Notion’a aktarabilirsin.
- No-Code Kolaylık: Tarayıcı kullanabiliyorsan Thunderbit’i de kullanırsın. Kod yok, proxy yok, baş ağrısı yok.
Klasik bir crawler yerine ne zaman Thunderbit kullanmalısın?
- Nihai hedefin URL listesi değil de temiz, kullanılabilir bir tablo/Excel ise.
- Tüm süreci (tara, çıkar, temizle, dışa aktar) tek yerde otomatikleştirmek istiyorsan.
- Zamanını ve enerjini korumak istiyorsan.
— neden bu kadar çok iş kullanıcısının geçiş yaptığını kendin gör.
Sonuç: Ücretsiz Website Crawler’lardan En İyi Verimi Almak
Website crawler dünyası ciddi şekilde olgunlaştı. İster pazarlamacı ol, ister geliştirici, ister sadece siteni “sapasağlam” tutmak isteyen biri — sana uygun ücretsiz (ya da en azından ücretsiz denemeli) bir seçenek mutlaka var. BrightData ve Diffbot gibi kurumsal platformlardan, SiteOne ve Crawljax gibi açık kaynak “cevherlere”, PowerMapper gibi görsel haritalama araçlarına kadar seçenekler hiç olmadığı kadar bol.
Ama “Bu veriye ihtiyacım var” noktasından “İşte tablom” noktasına daha akıllı ve entegre şekilde gitmek istiyorsan Thunderbit’i dene. Rapor değil, sonuç isteyen iş kullanıcıları için tasarlandı.
Hazır mısın? Bir araç indir, bir web tarama çalıştır ve neleri gözden kaçırdığını gör. İki tıkla taramadan aksiyon alınabilir veriye geçmek istiyorsan .
Daha fazla derin inceleme ve pratik rehber için sayfasına uğra.
SSS
Website crawler ile web scraper arasındaki fark nedir?
Crawler, bir sitedeki tüm sayfaları keşfeder ve haritalar (içindekiler tablosu çıkarır gibi). Scraper ise bu sayfalardan belirli veri alanlarını (fiyat, e-posta, yorum vb.) çekip çıkarır. Crawler bulur, scraper çıkarır ().
Teknik olmayan kullanıcılar için en iyi ücretsiz web crawler hangisi?
Küçük siteler ve SEO denetimleri için Screaming Frog kullanımı kolaydır. Görsel haritalama için PowerMapper (deneme süresince) iyi bir seçenektir. Hedefin yapılandırılmış veri almak ve kod yazmadan tarayıcı üzerinden ilerlemekse en kolay yol Thunderbit’tir.
Web crawler’ları engelleyen siteler var mı?
Evet. Bazı siteler robots.txt veya anti-bot önlemleri (CAPTCHA, IP engeli vb.) ile taramayı kısıtlar. ScraperAPI, Crawlbase ve Thunderbit (waterfall crawling ile) çoğu zaman bu engelleri aşabilir; yine de sorumlu tarayın ve site kurallarına uyun ().
Ücretsiz website crawler’larda sayfa/özellik limiti olur mu?
Genelde evet. Mesela Screaming Frog’un ücretsiz sürümü tarama başına 500 URL ile sınırlıdır; PowerMapper denemesi 100 sayfadır. API tabanlı araçlarda çoğunlukla aylık kredi limiti olur. SiteOne veya Crawljax gibi açık kaynak araçlarda sert limitler yoktur; ama bu sefer de donanımının kapasitesi sınır olur.
Web crawler kullanmak yasal mı, gizlilik açısından uygun mu?
Genel olarak herkese açık sayfaları taramak yasaldır; ama her zaman sitenin kullanım şartlarını ve robots.txt dosyasını kontrol et. İzin olmadan özel/şifre korumalı veriyi tarama; kişisel veri çıkarıyorsan gizlilik mevzuatına ekstra dikkat et ().