
2015’te web’den veri çekmek demek, bir geliştiriciden Python script’i istemek ya da XPath öğrenmek için hafta sonunu gözden çıkarmaktı. 2026’ya geldiğimizde ise “tüm ürün adlarını ve fiyatlarını al” diye yazıyorsun; gerisini AI hallediyor. Kısacası web tarama bambaşka bir seviyeye geçti.
Bu dönüşüm gerçekten jet hızıyla yaşandı. Bugün web scraping’e yaslanıyor. Pazar geçti ve 2030’a kadar ikiye katlanması bekleniyor.
Peki bu büyümeyi asıl ateşleyen ne? AI web crawler’lar. Sayfanın düzeni değişince afallamıyorlar; uyum sağlayabiliyorlar. Sadece HTML etiketlerini okumuyor, sayfanın “ne anlatmak istediğini” de kavrıyorlar. Üstelik hayatında kod yazmamış biri için bile çalışacak kadar erişilebilirler.
Ben de aylarımı 15 aracı kurcalayıp test ederek geçirdim. Sonuçlar burada — Thunderbit’in (evet, kurucu ortaklarından biri olduğum şirket) neden listenin tepesine oturduğu da dahil.
Yapay Zekâ Web Sayfası Scraping’i Nasıl Dönüştürüyor: Web Scraper Araçlarında Yeni Dönem
Gerçekçi olalım: klasik web scraping, “ortalama iş kullanıcısı” düşünülerek tasarlanmadı. Kod, selector’lar, XPath’ler… Bir de üstüne “site tasarımı değişmesin de script patlamasın” diye içten içe dua etmek. AI ve LLM’ler bu düzeni kökten değiştirdi.
Nasıl mı?
- Doğal Dil ile Talimat: Kodla boğuşmak yerine ne istediğini söylüyorsun. gibi araçlar günlük dilde yazdığın talimatı anlayıp veri çıkarma kurulumunu senin yerine yapıyor ().
- Uyarlanabilir Öğrenme: AI web scraper’lar, web sitelerindeki ; bakım yükünü ciddi şekilde hafifletiyor.
- Dinamik İçerik Yakalama: Modern siteler JavaScript’i ve sonsuz kaydırmayı seviyor. AI destekli araçlar bu öğelerle etkileşime girip, eski tip scraper’ların kaçıracağı verileri de toplayabiliyor.
- AI Ayrıştırma ile Yapılandırılmış Çıktı: LLM tabanlı scraper’lar sayfa içeriğini gerçekten ve temiz, düzenli veri üretiyor.
- Otomatik Anti-Bot Aşma: AI web scraper’lar ; proxy/headless tarayıcılarla IP engellerinden sıyrılabiliyor.
- Entegre Veri Akışları: En iyi araçlar sadece veriyi çekmekle kalmıyor; tek tıkla Google Sheets, Airtable, Notion ve daha fazlasına aktararak iş akışına “hazır teslim” ediyor ().
Sonuç: Web scraping artık “tıkla-çek” (hatta sohbet eder gibi) bir deneyime dönüştü. Böylece web verisini doğrudan kullanmak; sadece geliştiricilerin değil, satış, pazarlama ve operasyon ekiplerinin de rahatça erişebileceği bir yetenek haline geldi.
2026’da Dikkate Değer 15 AI Web Crawler
Şimdi 15 AI web crawler’ı, Thunderbit’ten başlayarak tek tek masaya yatıralım. Her araç için temel özellikleri, hedef kullanıcıyı, fiyatlandırmayı ve onu öne çıkaran noktaları paylaşacağım. Ayrıca nerede parladığını (ve nerede zorlanabileceğini) açık açık söyleyeceğim.
1. Thunderbit: Herkes İçin AI Web Scraper
Burada biraz taraflı olduğum doğru; ama Thunderbit, yıllar önce elimde olmasını isteyeceğim türden bir AI web scraper. Bu listede #1 olmasının sebepleri:
- Doğal Dil ile Veri Çıkarma: Thunderbit ile resmen “sohbet ediyorsun”. İstediğin veriyi tarif et — “bu sayfadaki tüm ürün adlarını ve fiyatlarını çek” — gerisini AI yapar (). Kod yok, selector yok, baş ağrısı yok.
- Alt Sayfa ve Çok Katmanlı Tarama: Thunderbit, bağlantıları . Mesela ürün listesini çekip, her ürün sayfasına girerek detayları tek seferde toplarsın.
- Anında Yapılandırılmış Çıktı: AI, veriyi anlık olarak ; ilgili alanları önerir, formatları normalize eder, hatta metni özetleyip kategorize edebilir.
- Geniş Kaynak Desteği: Thunderbit sadece HTML için değil; yerleşik OCR ve görsel AI ile PDF ve görsellerden de veri çıkarabilir ().
- İş Entegrasyonları: Google Sheets, Airtable, Notion veya Excel’e tek tıkla aktarım (). Scrape işlemlerini zamanlayın ve veriyi doğrudan ekibinizin iş akışına akıtın.
- Hazır Şablonlar: Amazon, LinkedIn, Zillow gibi siteler için Thunderbit, tek tıkla veri çekmeye yarayan hazır “tarifler” sunar ().
- Kullanıcı Dostu ve Erişilebilir: Arayüz tıkla-çalıştır mantığında; asistanı sezgisel. Kullanıcılar dakikalar içinde kullanmaya başladıklarını söylüyor.

Thunderbit, dünya genelinde tarafından tercih ediliyor; Accenture, Grammarly ve Puma ekipleri de buna dahil. Satış ekipleri çıkarmak için kullanıyor; emlakçılar ilanları toparlıyor; pazarlamacılar rakipleri izliyor — tek satır kod yazmadan.
Fiyatlandırma: var (ayda 100 adıma kadar). Ücretli planlar 14,99$/ay’dan başlıyor. Pro planlar bile bireyler ve küçük ekipler için ulaşılabilir.
Thunderbit, “web’i bir veritabanına dönüştürme” fikrine gördüğüm en yakın şey — ve sadece mühendisler için değil, herkes için tasarlandı.
2. Crawl4AI
Kimler için: Özel veri hatları (pipeline) kuran geliştiriciler ve teknik ekipler.
Crawl4AI, hız ve büyük ölçekli tarama için optimize edilmiş, açık kaynaklı Python tabanlı bir framework; ayrıca tasarlanmış. Çok hızlıdır, dinamik içerik için headless tarayıcıları destekler ve çekilen veriyi AI iş akışlarına beslemek için yapılandırabilir.
- En iyi olduğu alan: Güçlü ve özelleştirilebilir bir tarama motoru isteyen geliştiriciler.
- Fiyatlandırma: Ücretsiz (MIT lisansı). Barındırma ve çalıştırma size ait.
3. ScrapeGraphAI
Kimler için: AI ajanları veya karmaşık veri hatları kuran geliştiriciler ve analistler.
ScrapeGraphAI, LLM’lerle web sitelerini yapılandırılmış veri “grafikleri”ne dönüştüren, prompt odaklı açık kaynak bir Python kütüphanesi. “İlk 5 sayfadaki tüm ürün adlarını, fiyatları ve puanları çıkar” gibi prompt’lar yazarsınız; araç sizin için scraping iş akışını kurar ().
- En iyi olduğu alan: Esnek, prompt tabanlı scraping isteyen teknik kullanıcılar.
- Fiyatlandırma: Açık kaynak kütüphane ücretsiz; bulut API 20$/ay’dan başlar.
4. Firecrawl
Kimler için: AI ajanları veya büyük ölçekli veri hatları geliştiren geliştiriciler.
Firecrawl, tüm web sitelerini “LLM’e hazır” veriye dönüştüren AI odaklı bir tarama platformu ve API’dir (). Markdown veya JSON çıktı verir, dinamik içeriği yönetir ve LangChain ile LlamaIndex gibi framework’lerle entegre olur.
- En iyi olduğu alan: Canlı web verisini AI modellerine beslemek isteyen geliştiriciler.
- Fiyatlandırma: Açık kaynak çekirdek ücretsiz; bulut planları 19$/ay’dan başlar.
5. Browse AI
Kimler için: İş kullanıcıları, growth hacker’lar ve analistler.
Browse AI, olan no-code bir platform. İstediğiniz veriye tıklayarak bir “robotu” eğitirsiniz; AI bu deseni genelleyip sonraki çekimlerde uygular. Giriş (login), sonsuz kaydırma gibi senaryoları yönetir ve değişiklikleri izleyebilir.
- En iyi olduğu alan: Veri toplama ve izlemeyi otomatikleştirmek isteyen teknik olmayan kullanıcılar.
- Fiyatlandırma: Ücretsiz plan (ayda 50 kredi); ücretli planlar 19$/ay’dan başlar.
6. LLM Scraper
Kimler için: Ayrıştırma işini AI’ya bırakmak isteyen geliştiriciler.
LLM Scraper, bir LLM’in herhangi bir web sayfasından bu şemaya göre veri çıkarmasını sağlayan açık kaynak JavaScript/TypeScript kütüphanesidir. Playwright üzerine kuruludur, birden fazla LLM sağlayıcısını destekler ve yeniden kullanılabilir kod bile üretebilir.
- En iyi olduğu alan: LLM’lerle herhangi bir sayfayı yapılandırılmış veriye dönüştürmek isteyen geliştiriciler.
- Fiyatlandırma: Ücretsiz (MIT lisansı).
7. Reader (Jina Reader)
Kimler için: LLM uygulamaları, chatbot’lar veya özetleme sistemleri geliştiren geliştiriciler.
Jina Reader, web sayfalarından (hatta PDF/görsellerden) bir API’dir; LLM’e hazır Markdown veya JSON döndürür. Özel bir AI modeliyle çalışır ve görsellere açıklama (caption) ekleyebilir.
- En iyi olduğu alan: LLM’ler veya Soru-Cevap sistemleri için okunabilir, temiz içerik çekmek.
- Fiyatlandırma: Ücretsiz API (temel kullanım için anahtar gerekmez).
8. Bright Data
Kimler için: Ölçek, uyumluluk ve güvenilirlik isteyen kurumsal/profesyonel kullanıcılar.
Bright Data, devasa proxy ağı ve web veri dünyasının ağır toplarından. Hazır scraper’lar, genel bir Web Scraper API ve “LLM’e hazır” veri akışları sunar.
- En iyi olduğu alan: Büyük ölçekte güvenilir web verisi ihtiyacı.
- Fiyatlandırma: Kullanıma göre, premium. Ücretsiz deneme mevcut.
9. Octoparse
Kimler için: Teknik olmayanlardan yarı teknik kullanıcılara.
Octoparse, ve AI destekli otomatik algılama sunan, köklü bir no-code araçtır. Login, sonsuz kaydırma gibi durumları yönetir ve farklı formatlarda dışa aktarım yapabilir.
- En iyi olduğu alan: Analistler, küçük işletme sahipleri veya araştırmacılar.
- Fiyatlandırma: Ücretsiz plan var; ücretli planlar 119$/ay’dan başlar.
10. Apify
Kimler için: Özel scraping/otomasyon ihtiyacı olan geliştiriciler ve teknik ekipler.
Apify, scraping script’lerini (“actor”) bulutta çalıştırmaya yarayan bir platformdur ve sunar. Ölçeklenebilir, AI ile entegre olur ve proxy yönetimini destekler.
- En iyi olduğu alan: Bulutta özel script çalıştırmak isteyen geliştiriciler.
- Fiyatlandırma: Ücretsiz plan; kullanıma dayalı ücretli planlar 49$/ay’dan başlar.
11. Zyte (Scrapy Cloud)
Kimler için: Kurumsal seviyede scraping ihtiyacı olan geliştiriciler ve şirketler.
Zyte, Scrapy’nin arkasındaki şirkettir; bulut platformu ve sunar. Zamanlama, proxy ve büyük ölçekli projeleri yönetir.
- En iyi olduğu alan: Uzun soluklu scraping projeleri yürüten geliştirme ekipleri.
- Fiyatlandırma: Ücretsiz denemeden özel kurumsal planlara.
12. Webscraper.io
Kimler için: Yeni başlayanlar, gazeteciler ve araştırmacılar.
, olarak tıkla-seç veri çıkarma sağlar. Yerelde kullanım için basit ve ücretsizdir; daha büyük işler için bulut servisi de vardır.
- En iyi olduğu alan: Hızlı, tek seferlik scraping işleri.
- Fiyatlandırma: Eklenti ücretsiz; bulut planları ~50$/ay’dan başlar.
13. ParseHub
Kimler için: Temel araçlardan daha güçlü bir şeye ihtiyaç duyan teknik olmayan kullanıcılar.
ParseHub, haritalar ve formlar dahil dinamik içerik çekmek için görsel iş akışı sunan bir masaüstü uygulamasıdır. Projeleri bulutta çalıştırabilir ve API sağlar.
- En iyi olduğu alan: Dijital pazarlamacılar, analistler ve gazeteciler.
- Fiyatlandırma: Ücretsiz plan (çalıştırma başına 200 sayfa); ücretli planlar 189$/ay’dan başlar.
14. Diffbot
Kimler için: Büyük ölçekte yapılandırılmış web verisine ihtiyaç duyan kurumlar ve AI şirketleri.
Diffbot, bilgisayarlı görü ve NLP kullanarak herhangi bir web sayfasından ; makaleler, ürünler için API’ler ve dev bir bilgi grafiği sunar.
- En iyi olduğu alan: Pazar zekâsı, finans ve AI eğitim verisi.
- Fiyatlandırma: Premium; ~299$/ay’dan başlar.
15. DataMiner
Kimler için: Özellikle satış, pazarlama ve gazetecilikte teknik olmayan kullanıcılar.
DataMiner, hızlı tıkla-seç veri çıkarma için bir . Hazır “recipe” kütüphanesi vardır ve Google Sheets’e doğrudan aktarım yapabilir.
- En iyi olduğu alan: Tablo/listeyi hızlıca spreadsheet’e aktarma gibi pratik işler.
- Fiyatlandırma: Ücretsiz plan (günde 500 sayfa); Pro ~19$/ay’dan başlar.
En İyi AI Web Scraper Araçlarını Karşılaştırma: Hangisi Size Uyar?
Size uygun aracı bulmanız için üst düzey bir karşılaştırma:
| Araç | AI/LLM Kullanımı | Kullanım Kolaylığı | Çıktı/Entegrasyon | Kimler İçin İdeal | Fiyatlandırma |
|---|---|---|---|---|---|
| Thunderbit | Doğal dil arayüzü; AI alan önerir | En kolay (no-code sohbet) | Sheets, Airtable, Notion dışa aktarım | Teknik olmayan ekipler | Ücretsiz plan; Pro ~30$/ay |
| Crawl4AI | AI’ye hazır tarama; LLM entegrasyonu | Zor (Python kod) | Kütüphane/CLI; kodla entegrasyon | Hızlı AI veri hatları kuran dev’ler | Ücretsiz |
| ScrapeGraphAI | Scraping için LLM prompt hatları | Orta (biraz kod veya API) | API/SDK; JSON çıktı | AI ajanları geliştiren dev/analistler | Ücretsiz OSS; API 20$+/ay |
| Firecrawl | LLM’e hazır Markdown/JSON üretir | Orta (API/SDK kullanımı) | SDK’lar (Py, Node vb.); LangChain entegrasyonu | Canlı web verisini AI’ya bağlayan dev’ler | Ücretsiz + ücretli bulut |
| Browse AI | AI destekli tıkla-seç | Kolay (no-code) | 7000+ uygulama entegrasyonu (Zapier) | Web izlemeyi otomatikleştiren teknik olmayanlar | Ücretsiz 50 çalıştırma; Ücretli 19$+/ay |
| LLM Scraper | LLM ile sayfayı şemaya göre ayrıştırır | Zor (TS/JS kod) | Kod kütüphanesi; JSON çıktı | Ayrıştırmayı AI’ya yaptırmak isteyen dev’ler | Ücretsiz (kendi LLM API’nizi kullanırsınız) |
| Reader (Jina) | AI modeli metin/JSON çıkarır | Kolay (basit API çağrısı) | REST API Markdown/JSON döndürür | LLM’lere web arama/içerik ekleyen dev’ler | Ücretsiz API |
| Bright Data | AI güçlendirmeli scraping API’leri; büyük proxy ağı | Zor (API, teknik) | API/SDK; veri akışları veya dataset’ler | Kurumsal ölçek | Kullanıma göre |
| Octoparse | AI liste algılama | Orta (no-code uygulama) | CSV/Excel, sonuçlar için API | Yarı teknik kullanıcılar | Ücretsiz sınırlı; 59–166$/ay |
| Apify | Bazı AI özellikleri (Actors, AI içerikleri) | Zor (script kod) | Kapsamlı API; LangChain entegrasyonu | Bulutta özel scraping isteyen dev’ler | Ücretsiz plan; kullandıkça öde |
| Zyte (Scrapy) | ML tabanlı otomatik çıkarım; Scrapy framework | Zor (Python kod) | API, Scrapy Cloud arayüzü; JSON/CSV | Dev ekipleri, uzun vadeli projeler | Özel fiyat |
| Webscraper.io | AI yok (manuel şablonlar) | Kolay (tarayıcı eklentisi) | CSV indirme, Cloud API | Yeni başlayanlar, hızlı tek seferlik işler | Ücretsiz eklenti; Bulut ~50$/ay |
| ParseHub | Belirgin LLM yok; görsel oluşturucu | Orta (no-code uygulama) | JSON/CSV; bulut çalıştırmalar için API | Karmaşık siteleri çeken non-dev’ler | Ücretsiz 200 sayfa; Ücretli 189$+/ay |
| Diffbot | Her sayfa için AI görsel/NLP; bilgi grafiği | Kolay (API çağrıları) | API’ler (Article/Prod/...) + Knowledge Graph sorgusu | Kurumsal, yapılandırılmış web verisi | ~299$/ay’dan başlar |
| DataMiner | LLM yok; topluluk recipe’leri | En kolay (tarayıcı arayüzü) | Excel/CSV dışa aktarım; Google Sheets | Spreadsheet’e veri çeken teknik olmayanlar | Ücretsiz sınırlı; Pro ~19$/ay |
Araç Kategorileri: Geliştirici Odaklı Güç Araçlarından İş Dostu Web Scraper’lara
Listeyi daha anlaşılır kılmak için araçları birkaç kategoriye ayıralım:
1. Geliştirici ve Açık Kaynak “Güç Araçları”
- Örnekler: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Güçlü yanlar: Yüksek esneklik, ölçek ve özelleştirme. Özel pipeline kurmak veya AI modelleriyle entegre etmek için ideal.
- Dezavantajlar: Kodlama bilgisi ve daha fazla yapılandırma gerektirir.
- Kullanım senaryoları: Özel veri hattı kurma, karmaşık siteleri çekme, iç sistemlerle entegrasyon.
2. AI Entegre Scraping Ajanları
- Örnekler: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Güçlü yanlar: Veri çekme ile veriyi anlama arasındaki boşluğu kapatır. Doğal dil arayüzleri erişilebilirliği artırır.
- Dezavantajlar: Bazıları hâlâ gelişim aşamasında; çok ince ayar kontrolü sunmayabilir.
- Kullanım senaryoları: Hızlı yanıt/dataset üretimi, otonom ajanlar, canlı veriyi LLM’lere besleme.
3. No-Code/Low-Code İş Dostu Scraper’lar
- Örnekler: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Güçlü yanlar: Kullanımı kolay, az ya da hiç kod gerektirmez; düzenli iş ihtiyaçları için uygun.
- Dezavantajlar: Çok karmaşık sitelerde veya devasa ölçekte zorlanabilir.
- Kullanım senaryoları: Lead üretimi, rakip takibi, araştırma projeleri, tek seferlik veri çekimleri.
4. Kurumsal Veri Platformları ve Hizmetler
- Örnekler: Bright Data, Diffbot, Zyte
- Güçlü yanlar: Uçtan uca çözümler, yönetilen hizmetler, uyumluluk ve büyük ölçekte güvenilirlik.
- Dezavantajlar: Daha yüksek maliyet, daha fazla onboarding.
- Kullanım senaryoları: Büyük ölçekli sürekli veri hatları, pazar zekâsı, AI eğitim verisi.
Web Sayfası Scraping İhtiyacınız İçin Doğru AI Web Crawler’ı Nasıl Seçersiniz?
Doğru aracı seçmek göz korkutucu olabilir; o yüzden adım adım gidelim:
- Hedefinizi ve Veri İhtiyacınızı Netleştirin: Hangi sitelerden hangi veriler? Ne sıklıkla? Ne kadar hacim? Veriyi ne amaçla kullanacaksınız?
- Teknik Seviyenizi Değerlendirin: Kod yoksa Thunderbit, Browse AI veya Octoparse. Biraz script yazabiliyorsanız LLM Scraper veya DataMiner. Güçlü geliştirme becerileri varsa Crawl4AI, Apify veya Zyte.
- Sıklık ve Ölçeği Düşünün: Tek seferlik işlerde ücretsiz araçlar yeterli olabilir. Düzenli çekimlerde zamanlama (schedule) özelliklerine bakın. Büyük ölçekte kurumsal araçlar veya ölçekli açık kaynak.
- Bütçe ve Fiyat Modeli: Ücretsiz planlar denemek için ideal. Abonelik mi, kullanıma göre mi; ihtiyacınıza göre değişir.
- Deneme ve PoC: Araçları kendi gerçek veriniz üzerinde test edin. Çoğunda ücretsiz katman var.
- Bakım ve Destek: Site değişince kim düzeltecek? AI’lı no-code araçlar küçük değişiklikleri otomatik toparlayabilir; açık kaynakta sorumluluk sizde/toplulukta.
- Senaryoya Göre Eşleştirin: Satış ekibi lead çekiyorsa Thunderbit veya Browse AI. Araştırmacı tweet topluyorsa DataMiner veya . AI modeli haber makalesi istiyorsa Jina Reader veya Zyte. Karşılaştırma sitesi kuruyorsanız Apify veya Zyte.
- Yedek Plan Yapın: Bazı sitelerde tek bir araç yetmeyebilir. Alternatifiniz olsun.
“Doğru” araç; ihtiyacınız olan veriyi, en az sürtünmeyle ve bütçeniz içinde size ulaştıran araçtır. Bazen en iyi çözüm bir kombinasyondur.
Thunderbit ve Klasik Web Scraper Araçları: Onu Öne Çıkaran Ne?
Thunderbit’in farkını daha net görelim:
- Doğal Dil Arayüzü: Kod yok, tıkla-seç akrobasisine gerek yok. Ne istediğini anlat ().
- Sıfır Konfigürasyon ve Şablon Önerileri: Thunderbit sayfalama, alt sayfalar gibi yapıları otomatik algılar; yaygın siteler için şablon da önerir ().
- AI ile Veri Temizleme ve Zenginleştirme: Scrape ederken özetleme, kategorize etme, çeviri ve veri zenginleştirme yapın ().
- Daha Az Bakım Derdi: Thunderbit’in AI’sı küçük site değişikliklerine daha dayanıklıdır; kırılmaları azaltır.
- İş Araçlarıyla Entegrasyon: Google Sheets, Airtable, Notion’a doğrudan aktarım — CSV ile uğraşmaya son ().
- Hızlı Değer Üretimi: Fikirden veriye günler değil, dakikalar içinde.
- Öğrenme Eğrisi: Web’de gezinebiliyor ve ihtiyacını tarif edebiliyorsan Thunderbit’i kullanabilirsin.
- Uyarlanabilirlik: Web siteleri, PDF’ler, görseller ve daha fazlası — tek araçla.
Thunderbit sadece bir scraper değil; satış, pazarlama, e-ticaret veya gayrimenkul gibi alanlarda iş akışına uyum sağlayan bir veri asistanı.
AI Web Scraper Araçlarıyla Web Sayfası Scraping İçin En İyi Uygulamalar
AI web scraper’lardan maksimum verim almak için önerilerim:
- Veri İhtiyacınızı Net Tanımlayın: Hangi alanlar, kaç sayfa, hangi format?
- AI Önerilerinden Yararlanın: Alan algılama ve AI önerileriyle kaçırabileceğiniz kritik verileri yakalayın ().
- Küçük Başlayın ve Doğrulayın: Küçük bir örnekle test edin, çıktıyı kontrol edin, gerekirse ayarlayın.
- Dinamik İçeriği Yönetin: Aracınızın sayfalama, sonsuz kaydırma gibi etkileşimleri desteklediğinden emin olun.
- Site Politikalarına Saygı Gösterin: robots.txt’i kontrol edin, hassas verileri çekmeyin, hız limitlerine uyun.
- Otomasyon İçin Entegre Edin: Dışa aktarma ve webhook’larla veriyi doğrudan iş akışınıza bağlayın.
- Veri Kalitesini Koruyun: Mantık kontrolü yapın, post-processing uygulayın, hataları izleyin.
- Prompt’larda Net ve Kısa Olun: AI odaklı araçlarda açık ve spesifik talimatlar daha iyi sonuç verir.
- Topluluktan Öğrenin: Forumlar ve topluluklar ipuçları ve sorun çözme için çok faydalı.
- Güncel Kalın: AI araçları çok hızlı gelişiyor; yeni özellikleri takip edin.
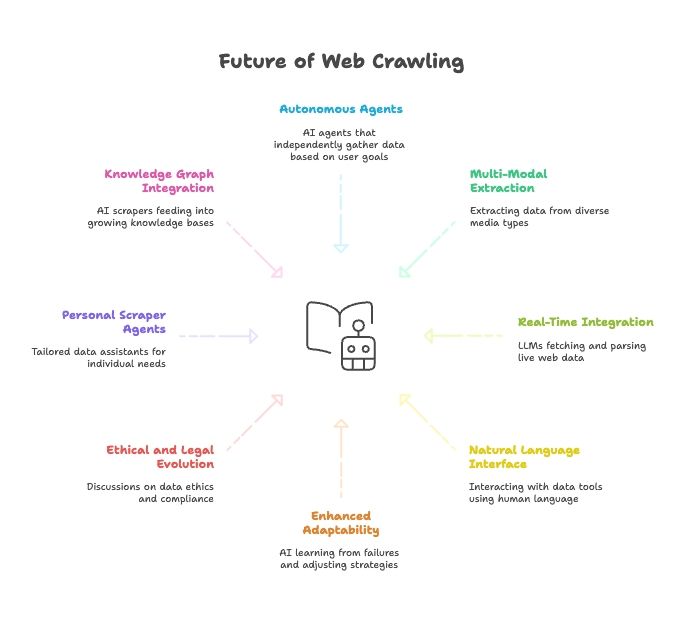
Web Scraping’in Geleceği: AI, LLM’ler ve Doğal Dil ile Çalışan Web Scraper Ajanlarının Yükselişi
İleriye baktığımızda, AI ile web scraping’in birleşimi daha da hızlanıyor:
- Tam Otonom Scraper Ajanları: Yakında bir AI ajanına sadece nihai hedefini söyleyeceksin; veriyi nasıl alacağını kendi çözecek.
- Çok Modlu Veri Çıkarma: Scraper’lar metin, görsel, PDF hatta videodan veri çekebilecek.
- AI Modelleriyle Gerçek Zamanlı Entegrasyon: LLM’lerde canlı web verisini çekip ayrıştıran yerleşik modüller olacak.
- Her Şey Doğal Dil: Veri araçlarıyla insanla konuşur gibi konuşacağız; veri toplama ve dönüştürme herkes için erişilebilir olacak.
- Daha Güçlü Uyarlanabilirlik: AI web scraper’lar hatalardan öğrenip stratejilerini otomatik uyarlayacak.
- Etik ve Hukuki Evrim: Veri etiği, uyumluluk ve adil kullanım daha çok tartışılacak.
- Kişisel Scraper Ajanları: İhtiyacına göre haber, iş ilanı vb. toplayan kişisel veri asistanlarını düşün.
- Bilgi Grafikleriyle Entegrasyon: AI web scraper’lar büyüyen bilgi tabanlarını sürekli besleyerek daha akıllı AI’ları güçlendirecek.
Özetle: Web scraping’in geleceği, AI’ın geleceğiyle iç içe. Araçlar her gün daha akıllı, daha otonom ve daha erişilebilir hale geliyor.
Sonuç: Doğru AI Web Crawler ile İş Değerini Açığa Çıkarmak
AI sayesinde web scraping, niş bir teknik beceriden temel bir iş yetkinliğine dönüştü. Burada ele aldığım 15 araç, 2026’da mümkün olanın en iyi örneklerini temsil ediyor: geliştirici odaklı güç araçlarından iş dostu asistanlara kadar.
Asıl mesele şu: Doğru aracı seçmek, web verisinden elde edeceğin değeri dramatik biçimde artırabilir. Teknik olmayan ekipler için Thunderbit, web’i yapılandırılmış ve analize hazır bir veritabanına dönüştürmenin en kolay yolu — kod yok, uğraş yok, sadece sonuç.
Lead topluyor, rakip izliyor ya da yeni nesil AI modelini besliyor ol; ihtiyaçlarını tart, birkaç aracı dene ve sana en uygun olanı seç. Web scraping’in geleceğini bugün deneyimlemek istersen, . İhtiyacın olan içgörü, bir prompt kadar yakın.
Daha fazlasını merak ediyorsan, derinlemesine içerikler, eğitimler ve AI destekli veri çıkarımındaki yenilikler için ’a göz atın.
İleri Okuma:
SSS
1. AI web crawler nedir ve geleneksel web scraper’lardan farkı ne?
AI web crawler; doğal dil işleme ve makine öğrenmesiyle web verisini anlar, çıkarır ve yapılandırır. XPath seçicileri ve manuel kodlama gerektiren geleneksel scraper’ların aksine; dinamik içeriği yönetebilir, sayfa düzeni değişikliklerine uyum sağlayabilir ve kullanıcı talimatlarını günlük dilden yorumlayabilir.
2. Thunderbit gibi AI web scraping araçlarını kimler kullanmalı?
Thunderbit hem teknik olmayan hem de teknik kullanıcılar için tasarlandı. Satış, pazarlama, operasyon, araştırma ve e-ticaret profesyonelleri için idealdir; web siteleri, PDF’ler veya görsellerden yapılandırılmış veri çıkarmayı kod yazmadan mümkün kılar.
3. Thunderbit’i diğer AI web crawler’lardan ayıran özellikler neler?
Thunderbit; doğal dil arayüzü, çok katmanlı tarama, otomatik veri yapılandırma, OCR desteği ve Google Sheets/Airtable gibi platformlara sorunsuz aktarım sunar. Ayrıca AI destekli alan önerileri ve popüler siteler için hazır şablonlar içerir.
4. 2026’da AI web scraping için ücretsiz seçenekler var mı?
Evet. Thunderbit, Browse AI ve DataMiner gibi birçok araç sınırlı kullanımlı ücretsiz planlar sunuyor. Geliştiriciler için Crawl4AI ve ScrapeGraphAI gibi açık kaynak seçenekler de ücretsiz; ancak teknik kurulum gerektirir.
5. İhtiyacıma uygun AI web crawler’ı nasıl seçerim?
Önce veri hedeflerini, teknik seviyeni, bütçeni ve ölçek ihtiyacını belirle. No-code ve kolay bir çözüm istiyorsan Thunderbit veya Browse AI iyi seçeneklerdir. Büyük ölçek veya özelleştirme gerekiyorsa Apify ya da Bright Data daha uygun olabilir.