

Dürüst olalım — Amazon, internetin tamamı için adeta bir AVM, bir süpermarket ve bir elektronik mağazası. Satış, e-ticaret ya da operasyon tarafındaysanız, Amazon’da olanın Amazon’da kalmadığını zaten biliyorsunuz; fiyatlandırmanızı, stoklarınızı, hatta bir sonraki büyük ürün lansmanınızı bile etkiliyor. Ama işin püf noktası şu: O harika ürün detayları, fiyatlar, puanlar ve yorumlar, veri aç ekipler için değil, alışveriş yapanlar için tasarlanmış bir web arayüzünün arkasında kilitli. Peki bu veriyi, sanki 1999’daymışız gibi hafta sonlarınızı kopyala-yapıştır yaparak harcamadan nasıl alırsınız?
İşte burada web kazıma devreye giriyor. Bu rehberde size Amazon ürün verisini çıkarmanın iki yolunu göstereceğim: klasik “kolları sıvayıp Python ile kod yazma” yaklaşımı ve no-code bir web kazıyıcı olan Thunderbit ile AI’ın ağır işi üstlendiği modern yöntem. Gerçek Python kodunu, tüm takılma noktaları ve geçici çözümleriyle birlikte adım adım anlatacağım; ardından Thunderbit’in size aynı veriyi sadece birkaç tıkla, kod yazmadan nasıl sunduğunu göstereceğim. İster geliştirici olun, ister iş analisti, ister manuel veri girişinden bıkmış biri — aradığınızı burada bulacaksınız.
Neden Amazon Ürün Verisi Çıkarmalısınız? (amazon scraper python, web scraping with python)
Amazon sadece dünyanın en büyük online perakendecisi değil; aynı zamanda rekabet istihbaratı için dünyanın en büyük açık hava pazarı. 600 milyondan fazla ürün listesi ve yaklaşık 2 milyon aktif satıcı ile Amazon, şunları yapmak isteyen herkes için gerçek bir altın madeni:

- Fiyatları izlemek (ve kendi fiyatınızı anlık ayarlamak)
- Rakipleri analiz etmek (yeni lansmanlarını, puanlarını ve yorumlarını takip etmek)
- Lead üretmek (satıcılar, tedarikçiler, hatta potansiyel iş ortakları bulmak)
- Talebi tahmin etmek (stok seviyelerini ve satış sıralarını izleyerek)
- Pazar trendlerini yakalamak (yorumlar ve arama sonuçlarından içgörü çıkararak)
Ve bu sadece teori değil — gerçek işletmeler gerçek ROI görüyor. Örneğin bir elektronik perakendecisi, Amazon fiyatlandırma verisini kazıyarak kâr marjlarını %15 artırdı; başka bir marka ise rakip fiyat takibini otomatikleştirerek satışlarda %4 artış ve analist zamanında %30 azalma elde etti.
İşte kullanım senaryoları ve bekleyebileceğiniz faydaları gösteren kısa bir tablo:
| Kullanım Senaryosu | Kim Kullanır | Tipik ROI / Faydası |
|---|---|---|
| Fiyat Takibi | E-ticaret, Operasyon | %15+ kâr marjı artışı, %4 satış artışı, %30 daha az analist zamanı |
| Rakip Analizi | Satış, Ürün, Operasyon | Daha hızlı fiyat ayarlamaları, daha güçlü rekabetçilik |
| Pazar Araştırması (Yorumlar) | Ürün, Pazarlama | Daha hızlı ürün iterasyonu, daha iyi reklam metinleri, SEO içgörüleri |
| Lead Üretimi | Satış | Ayda 3.000+ lead, temsilci başına haftada 8+ saat tasarruf |
| Stok ve Talep Tahmini | Operasyon, Tedarik Zinciri | %20 daha az fazla stok, daha az stok tükenmesi |
| Trend Yakalama | Pazarlama, Yöneticiler | Sıcak ürün ve kategorileri erken tespit etme |
İşin asıl çarpıcı kısmı şu: kuruluşların %90’ından fazlası artık veri analitiğinden ölçülebilir değer elde ettiğini bildiriyor. Amazon verisini kazımıyorsanız, içgörüleri de parayı da masada bırakıyorsunuz demektir.
Genel Bakış: Amazon Scraper Python vs. No Code Web Scraper Araçları
Amazon verisini tarayıcıdan çıkarıp elektronik tablolarınıza ya da panolarınıza aktarmanın iki ana yolu var:
-
Amazon Scraper Python (web scraping with python):
Requests ve BeautifulSoup gibi Python kütüphaneleriyle kendi script’inizi yazarsınız. Bu size tam kontrol sağlar; ancak kod yazmayı, anti-bot önlemlerini aşmayı ve Amazon sitesi değiştikçe script’inizi güncel tutmayı bilmeniz gerekir.
-
No Code Web Scraper Araçları (Thunderbit gibi):
Veri almak için işaretle, tıkla ve çıkar mantığıyla çalışan bir araç kullanırsınız — programlama gerekmez. Thunderbit gibi modern araçlar, hangi verinin çekileceğini anlamak, alt sayfaları ve sayfalama yapısını yönetmek, veriyi doğrudan Excel veya Google Sheets’e aktarmak için AI’dan yararlanır.
Karşılaştırma şöyle:
| Kriter | Python Scraper | No Code (Thunderbit) |
|---|---|---|
| Kurulum Süresi | Yüksek (kurulum, kod, hata ayıklama) | Düşük (eklenti kurulur) |
| Gerekli Beceri | Kodlama gerekir | Yok (işaretle ve tıkla) |
| Esneklik | Sınırsız | Yaygın kullanım alanlarında yüksek |
| Bakım | Kodu siz düzeltirsiniz | Araç kendini günceller |
| Anti-bot Yönetimi | Proxy ve header’ları siz yönetirsiniz | Yerleşik, sizin yerinize halledilir |
| Ölçeklenebilirlik | Manuel (thread, proxy) | Bulut kazıma, paralel çalışma |
| Veri Aktarımı | Özel (CSV, Excel, DB) | Tek tıkla Excel, Sheets |
| Maliyet | Ücretsiz (zamanınız + proxy’ler) | Freemium, ölçek için ücretli |
Sonraki bölümlerde her iki yaklaşımı da adım adım anlatacağım — önce gerçek kodla Python’da bir Amazon kazıyıcısı nasıl yapılır, ardından Thunderbit’in AI web kazıyıcısıyla aynı iş nasıl yapılır.
Amazon Scraper Python ile Başlarken: Ön Koşullar ve Kurulum
Koda geçmeden önce ortamınızı hazırlayalım.
İhtiyacınız olacaklar:
- Python 3.x (python.org üzerinden indirebilirsiniz)
- Bir kod editörü (ben VS Code’u seviyorum ama herhangi biri olur)
- Şu kütüphaneler:
requests(HTTP istekleri için)beautifulsoup4(HTML ayrıştırma için)lxml(hızlı HTML ayrıştırıcı)pandas(veri tabloları/aktarım için)re(yerleşik regex desteği)
Kütüphaneleri kurun:
pip install requests beautifulsoup4 lxml pandas
Proje kurulumu:
- Projeniz için yeni bir klasör oluşturun.
- Editörünüzü açın, yeni bir Python dosyası oluşturun (ör.
amazon_scraper.py). - Hazırsınız!
Adım Adım: Amazon Ürün Verisi için Python ile Web Kazıma
Tek bir Amazon ürün sayfasını kazımaya bakalım. (Merak etmeyin, birazdan birden fazla ürün ve sayfa kazımaya da geleceğiz.)
1. İstek Gönderme ve HTML Alma
Önce bir ürün sayfasının HTML’ini çekelim. (URL’yi herhangi bir Amazon ürünüyle değiştirebilirsiniz.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Dikkat: Bu basit istek büyük olasılıkla Amazon tarafından engellenecektir. Ürün sayfası yerine 503 hatası ya da CAPTCHA görebilirsiniz. Neden? Çünkü Amazon sizin gerçek bir tarayıcı olmadığınızı anlıyor.
Amazon’un Anti-Bot Önlemleriyle Baş Etmek
Amazon botlardan pek hoşlanmaz. Engellenmemek için şunları yapmanız gerekir:
- User-Agent başlığı ayarlamak (Chrome veya Firefox gibi davranmak)
- User-Agent’ları döndürmek (her seferinde aynı olanı kullanmamak)
- İstekleri yavaşlatmak (rastgele gecikmeler eklemek)
- Proxy kullanmak (büyük ölçekli kazıma için)
Başlıkları şöyle ayarlayabilirsiniz:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Biraz daha ileri gitmek ister misiniz? Bir User-Agent listesi kullanın ve her istekte döndürün. Büyük işler için bir proxy hizmeti kullanmak isteyeceksiniz (piyasada bolca var), ama küçük ölçekli kazıma için genelde başlıklar ve gecikmeler yeterlidir.
Temel Ürün Alanlarını Çıkarmak
HTML elinizde olduğunda, sıra BeautifulSoup ile ayrıştırmaya gelir.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Şimdi güzel kısımları çekelim:
Ürün Başlığı
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Fiyat
Amazon’un fiyatı birkaç farklı yerde olabilir. Şunları deneyin:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Puan ve Yorum Sayısı
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # örn. "1,554 ratings"
Ana Görsel URL’si
Amazon bazen yüksek çözünürlüklü görselleri HTML içinde JSON’a gizler. İşte hızlı bir regex yaklaşımı:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Ya da ana görsel etiketini alın:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Ürün Detayları
Marka, ağırlık ve boyut gibi teknik bilgiler genellikle bir tabloda yer alır:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Ya da Amazon “detailBullets” formatını kullanıyorsa:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Sonuçları yazdırın:
print("Başlık:", product_title)
print("Fiyat:", price)
print("Puan:", rating, "dayalı", reviews_count, "yorum")
print("Ana görsel URL’si:", main_image_url)
print("Detaylar:", details)
Birden Fazla Ürün Kazıma ve Sayfalama Yönetimi
Tek ürün güzel, ama muhtemelen bir liste istiyorsunuz. İşte arama sonuçlarını ve birden fazla sayfayı nasıl kazıyacağınız.
Arama Sayfasından Ürün Bağlantılarını Alma
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Sayfalama Yönetimi
Amazon’un arama URL’leri &page=2, &page=3 şeklinde ilerler.
for page in range(1, 6): # ilk 5 sayfayı kazı
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... yukarıdaki gibi ürün bağlantılarını çıkar ...
Ürün Sayfalarında Dönüp CSV’ye Aktarma
Ürün verinizi bir sözlük listesi olarak toplayın, sonra pandas kullanın:
import pandas as pd
df = pd.DataFrame(product_data_list) # sözlük listesi
df.to_csv("amazon_products.csv", index=False)
Ya da Excel’e:
df.to_excel("amazon_products.xlsx", index=False)
Amazon Scraper Python Projeleri için En İyi Uygulamalar
Gerçekçi olalım — Amazon sürekli sitesini değiştiriyor ve kazıyıcılara karşı savaşıyor. Projenizi ayakta tutmak için şunları yapın:
- Başlıkları ve User-Agent’ları döndürün (
fake-useragentgibi bir kütüphane kullanın) - Büyük ölçekli kazıma için proxy kullanın
- İstekleri yavaşlatın (istekler arasında rastgele
time.sleep()) - Hataları zarif şekilde yönetin (503’te yeniden deneyin, engellenirseniz geri çekilin)
- Esnek ayrıştırma mantığı yazın (her alan için birden fazla seçici deneyin)
- HTML değişikliklerini izleyin (script’iniz bir anda her şeyi
Nonedöndürüyorsa sayfayı kontrol edin) - robots.txt’ye saygı gösterin (Amazon birçok bölümü kazımayı yasaklar — sorumlu davranın)
- Veriyi ilerledikçe temizleyin (para birimi sembolleri, virgüller, boşlukları kaldırın)
- Toplulukla bağlantıda kalın (forumlar, Stack Overflow, Reddit’in r/webscraping topluluğu)
Kazıyıcınızı korumak için kontrol listesi:
- User-Agent ve başlıkları döndür
- Ölçekli kazıyorsan proxy kullan
- Rastgele gecikmeler ekle
- Kolay güncelleme için kodu modüllere ayır
- Ban veya CAPTCHA’ları izle
- Veriyi düzenli olarak dışa aktar
- Seçicileri ve mantığı dokümante et
Daha derin bir inceleme için Python ile web kazıma rehberime göz atın.
No Code Alternatifi: Thunderbit AI Web Scraper ile Amazon Kazıma
Amazon Ürün Verisini AI ile Kazıyın Get Started Free
Tamam, Python yöntemini gördünüz. Peki kod yazmak istemiyorsanız — ya da sadece iki tıkla veriyi alıp hayatınıza devam etmek istiyorsanız? İşte Thunderbit burada devreye giriyor.
Thunderbit, Amazon ürün verisini (ve hemen hemen herhangi bir web sitesindeki veriyi) sıfır kodla çıkarmanızı sağlayan bir AI web scraper Chrome uzantısıdır. Neden sevdiğimi söyleyeyim:
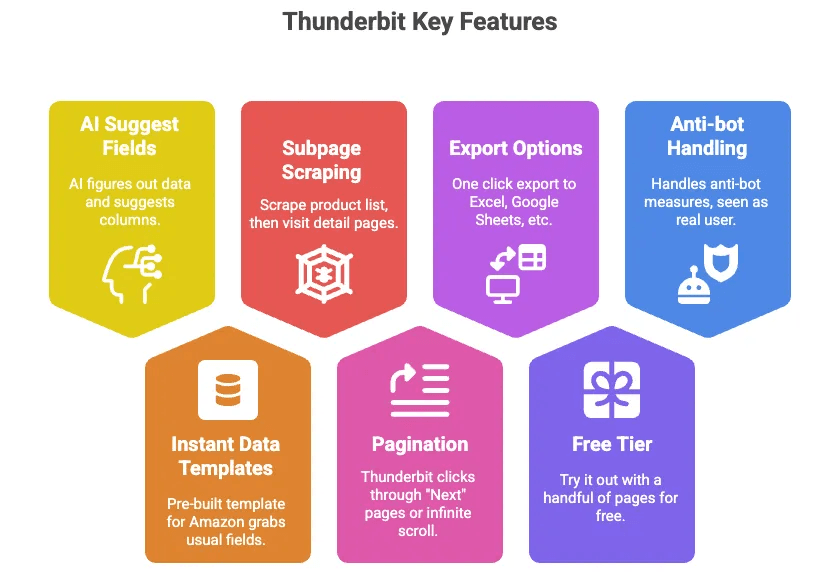
- AI Alan Önerisi: Sadece bir düğmeye tıklayın; Thunderbit’in AI’ı sayfadaki veriyi çözer ve sütunları önerir (Başlık, Fiyat, Puan vb.).
- Anında Veri Şablonları: Amazon için önceden hazırlanmış bir şablon vardır; tüm yaygın alanları toplar — kurulum gerekmez.
- Alt Sayfa Kazıma: Ürün listesini kazıyın, ardından Thunderbit’in her ürünün detay sayfasını ziyaret edip ek bilgileri otomatik çekmesine izin verin.
- Sayfalama: Thunderbit, sizin için “Sonraki” sayfalarına tıklayabilir veya sonsuz kaydırmayı yönetebilir.
- Excel, Google Sheets, Airtable, Notion’a Aktarma: Tek tıkla veriniz kullanıma hazırdır.
- Ücretsiz Plan: Birkaç sayfa ile ücretsiz deneyebilirsiniz.
- Anti-bot işlerini sizin yerinize halleder: Tarayıcınızda (veya bulutta) çalıştığı için Amazon onu gerçek kullanıcı gibi görür.
Adım Adım: Thunderbit ile Amazon Ürün Verisi Kazıma
Ne kadar kolay olduğuna bakın:
-
Thunderbit’i kurun:
Thunderbit Chrome Uzantısı uygulamasını indirin ve giriş yapın.
-
Amazon’u açın:
Kazımak istediğiniz Amazon sayfasına gidin (arama sonuçları, ürün detay sayfası, her neyse).
-
“AI Alan Önerisi”ne tıklayın veya bir şablon kullanın:
Thunderbit çıkarılacak sütunları önerir (ya da Amazon Ürün şablonunu seçebilirsiniz).
-
Sütunları gözden geçirin:
İsterseniz sütunları düzenleyin (alan ekleyin/çıkarın, yeniden adlandırın vb.).
-
“Kazı”ya tıklayın:
Thunderbit veriyi sayfadan çeker ve bir tabloda gösterir.
-
Alt sayfaları ve sayfalamayı yönetin:
Bir liste kazıdıysanız, her ürünün detay sayfasına gidip daha fazla bilgi almak için “Alt Sayfaları Kazı”ya tıklayın. Thunderbit ayrıca “Sonraki” sayfalarına otomatik tıklayabilir.
-
Verinizi dışa aktarın:
“Excel’e Aktar” veya “Google Sheets’e Aktar” butonuna tıklayın. Bitti.
-
(İsteğe bağlı) Zamanlama yapın:
Bu veriye her gün mü ihtiyacınız var? Thunderbit’in zamanlayıcısıyla otomatikleştirin.
Hepsi bu. Kod yok, hata ayıklama yok, proxy yok, baş ağrısı yok. Görsel bir anlatım için Thunderbit YouTube Kanalı veya Amazon Ürün Kazıyıcı şablon sayfasına göz atın.
Amazon Ürün Kazıyıcı Şablonunu Deneyin
Amazon Scraper Python vs. No Code Web Scraper: Yan Yana Karşılaştırma
Her şeyi bir araya getirelim:
| Kriter | Python Scraper | Thunderbit (No Code) |
|---|---|---|
| Kurulum Süresi | Yüksek (kurulum, kod, hata ayıklama) | Düşük (eklenti kurulur) |
| Gerekli Beceri | Kodlama gerekir | Yok (işaretle ve tıkla) |
| Esneklik | Sınırsız | Yaygın kullanım alanlarında yüksek |
| Bakım | Kodu siz düzeltirsiniz | Araç kendini günceller |
| Anti-bot Yönetimi | Proxy ve header’ları siz yönetirsiniz | Yerleşik, sizin yerinize halledilir |
| Ölçeklenebilirlik | Manuel (thread, proxy) | Bulut kazıma, paralel çalışma |
| Veri Aktarımı | Özel (CSV, Excel, DB) | Tek tıkla Excel, Sheets |
| Maliyet | Ücretsiz (zamanınız + proxy’ler) | Freemium, ölçek için ücretli |
| En Uygun Olduğu Kişiler | Geliştiriciler, özel ihtiyaçlar | İş kullanıcıları, hızlı sonuçlar |
Kurcalamayı seven ve tamamen size özel bir şeye ihtiyaç duyan bir geliştiriciyseniz, Python tam size göre. Hız, sadelik ve sıfır kod istiyorsanız, Thunderbit doğru yol.
Amazon Verisi İçin Python, No Code veya AI Web Scraper Ne Zaman Seçilmeli?
Python seçin, eğer:
- Özel mantığa ihtiyacınız varsa ya da kazımayı arka uç sistemlerinize entegre etmek istiyorsanız
- Çok büyük ölçekte kazıma yapıyorsanız (on binlerce ürün)
- Kazımanın perde arkasında nasıl çalıştığını öğrenmek istiyorsanız
Thunderbit (no code, AI web scraper) seçin, eğer:
- Kod yazmadan hızlı veri istiyorsanız
- İş kullanıcısı, analist veya pazarlamacıysanız
- Ekibinizin veriyi kendi başına almasını istiyorsanız
- Proxy, anti-bot önlemleri ve bakım derdiyle uğraşmak istemiyorsanız
İkisini birlikte kullanın, eğer:
- Thunderbit ile hızlıca prototip çıkarıp ardından üretim için özel bir Python çözümü kurmak istiyorsanız
- Veri toplama için Thunderbit’i, veri temizleme/analiz için Python’u kullanmak istiyorsanız
Çoğu iş kullanıcısı için Thunderbit, Amazon kazıma ihtiyaçlarının %90’ını çok daha kısa sürede karşılar. Geriye kalan %10’luk kısım — son derece özel, büyük ölçekli veya derin entegrasyonlu işler — için ise Python hâlâ kral.
Sonuç ve Öne Çıkanlar
2025’te AI Kullanarak Amazon Ürünleri ve Yorumları Nasıl Kazınır Get Started Free
Amazon ürün verisini kazımak, satış, e-ticaret veya operasyon ekipleri için gerçek bir süper güçtür. İster fiyat takibi yapın, ister rakipleri analiz edin, ister ekibinizi bitmek bilmeyen kopyala-yapıştır işinden kurtarmaya çalışın — sizin için bir çözüm var.
- Python ile kazıma size tam kontrol sağlar; ancak öğrenme eğrisi ve sürekli bakım gerektirir.
- Thunderbit gibi no code web kazıyıcılar, Amazon verisini herkes için erişilebilir hale getirir — kod yok, baş ağrısı yok, sadece sonuç.
- En iyi yaklaşım mı? Beceri seviyenize, zaman planınıza ve iş hedeflerinize uyan aracı kullanın.
Merak ediyorsanız Thunderbit’i deneyin — başlamak ücretsizdir ve ihtiyacınız olan veriyi ne kadar hızlı alabildiğinize şaşıracaksınız. Geliştiriciyseniz de araçları karıştırıp eşleştirmekten çekinmeyin: Bazen en hızlı geliştirme yolu, sıkıcı işleri AI’a bırakmaktır.
Thunderbit Chrome Uzantısını Alın
SSS
1. Bir işletme neden Amazon ürün verisini kazımak ister?
Amazon kazıma, işletmelerin fiyatları izlemesine, rakipleri analiz etmesine, ürün araştırması için yorum toplamasına, talebi tahmin etmesine ve satış lead’leri üretmesine olanak tanır. Amazon’da 600 milyondan fazla ürün ve yaklaşık 2 milyon satıcı olması, onu zengin bir rekabet istihbaratı kaynağı haline getirir.
2. Amazon’u kazımak için Python ile Thunderbit gibi no-code araçlar arasındaki temel farklar nelerdir?
Python kazıyıcılar maksimum esneklik sunar; ancak kodlama becerisi, kurulum süresi ve sürekli bakım gerekir. No-code bir AI web kazıyıcı olan Thunderbit ise kullanıcıların Amazon verisini bir Chrome uzantısıyla anında çıkarmasına izin verir — kod gerekmez, yerleşik anti-bot yönetimi ve Excel/Sheets’e aktarım seçenekleri vardır.
3. Amazon’dan veri kazımak yasal mı?
Amazon’un kullanım şartları genel olarak kazımayı yasaklar ve aktif anti-bot önlemleri uygular. Ancak birçok işletme, oran sınırlamalarına uymak ve aşırı istek göndermemek gibi sorumlu yöntemlerle kamuya açık verileri yine de kazımaktadır.
4. Web kazıma araçlarıyla Amazon’dan ne tür veriler çıkarabilirim?
Yaygın veri alanları arasında ürün başlıkları, fiyatlar, puanlar, yorum sayıları, görseller, ürün teknik özellikleri, stok durumu ve hatta satıcı bilgileri bulunur. Thunderbit ayrıca alt sayfa kazıma ve sayfalama desteğiyle birden fazla liste ve sayfadan veri toplar.
5. Ne zaman Python kazıma, ne zaman Thunderbit gibi bir araç seçmeliyim?
Tam kontrol, özel mantık veya kazımayı arka uç sistemlere entegre etmeyi planlıyorsanız Python kullanın. Kod yazmadan hızlı sonuç almak, kolayca ölçeklemek veya düşük bakım gerektiren bir çözüm arayan bir iş kullanıcısıysanız Thunderbit’i kullanın.
Daha derine inmek ister misiniz? Şu kaynaklara göz atın:
- Thunderbit Blog
- Veri Kazıma Nedir ve 2025’te Nasıl Yapılır
- 2025’te AI Kullanarak Amazon Ürünleri ve Yorumları Nasıl Kazınır
- Python ile Web Kazıma Rehberi
Keyifli kazımalar — ve elektronik tablolarınız hep güncel kalsın.
Amazon için Thunderbit AI Web Scraper’ı Deneyin Get Started Free




