Tumblr-krämare
Används av proffs på ledande företag














Lås upp Tumblr-data med Thunderbit
Extrahera enkelt Tumblr-data som inläggsinnehåll och like counts.
Få hela Tumblr-historien
Tumblrs listningssidor visar ofta bara utdrag. För att få hela bilden behöver du hela inläggstexten, författaruppgifter och all tillhörande data. Thunderbit besöker automatiskt varje länkad undersida, extraherar detaljerna och lägger till dem som nya kolumner, så att du enkelt kan hämta post_id, post_date och mer utan att klicka manuellt.
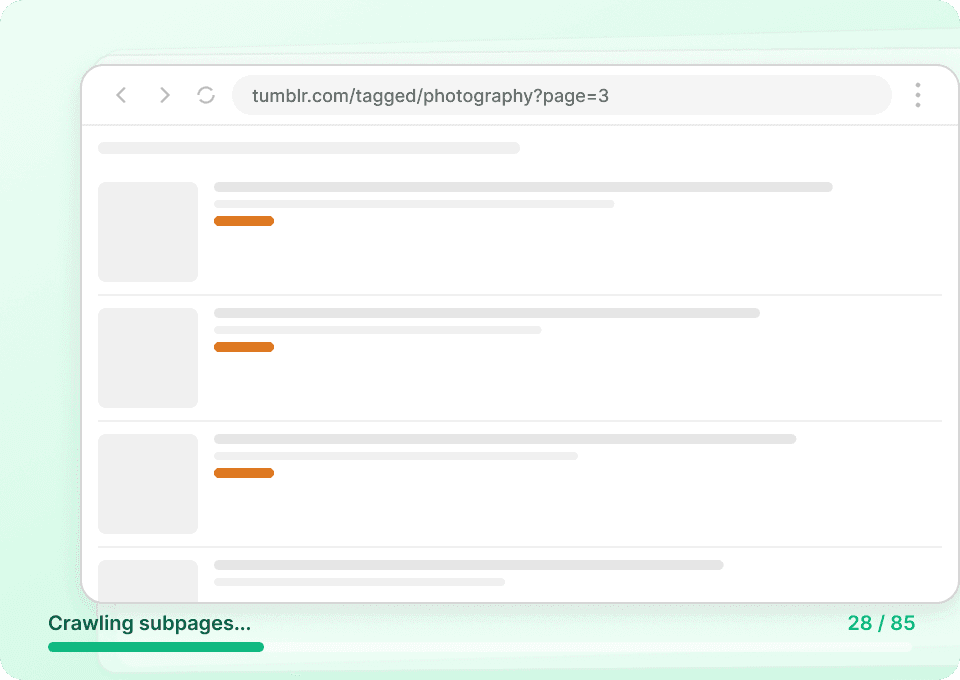
Automatisera din insamling av Tumblr-data
Tumblr-data förändras hela tiden. Att manuellt samla in samma bloggar om och om igen är tidskrävande. Med Thunderbits schemalagda scraping kan du ställa in återkommande uppgifter på autopilot. Få färsk data som like_count och post_content levererad direkt till Google Sheets utan att lyfta ett finger.
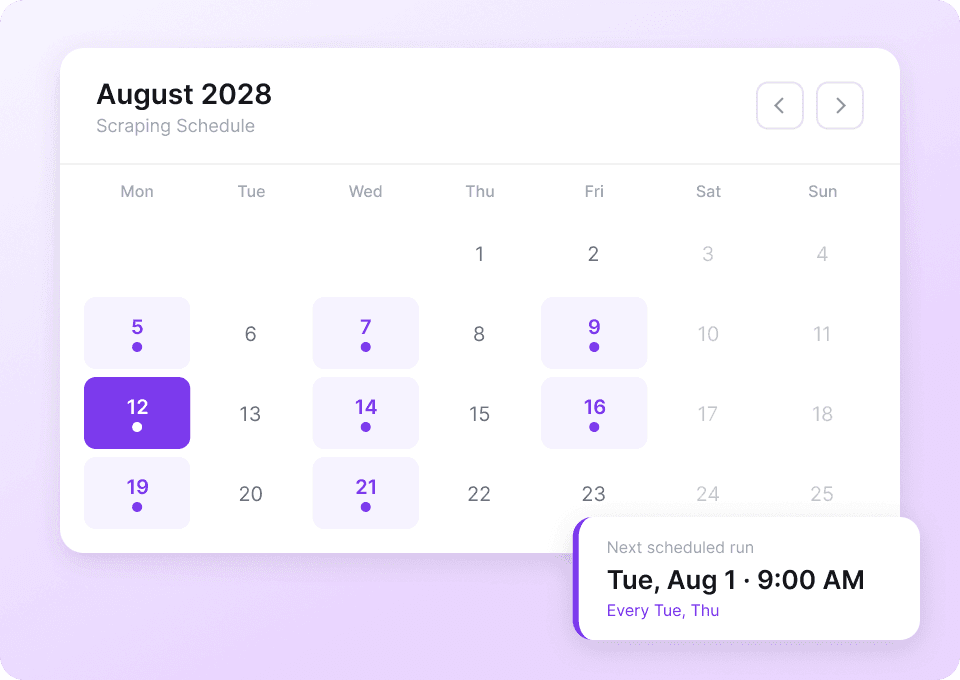
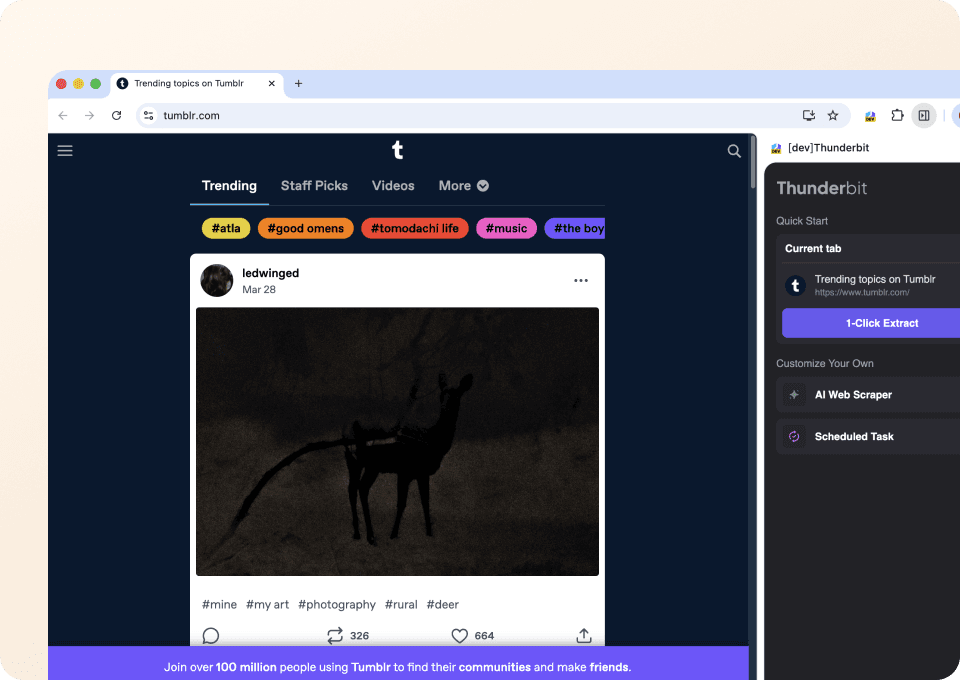
Samla in Tumblr-inlägg på två klick
Glöm komplicerad kod och CSS-selektorer. Thunderbit låter dig extrahera Tumblr-data på bara två klick. Peka bara på datan du vill ha, så identifierar Thunderbits semantiska AI relevanta fält (som post_type och post_author) och hämtar dem. Ingen kod behövs för att få fram datan du behöver från Tumblr.
Varför skiljer sig Thunderbit från traditionella Tumblr scrapers?
Extrahera Tumblr-data utan ansträngning, även när layouter skiftar eller ändras oväntat.
Traditionella scrapers
Det gamla sättet att göra sakerThunderbit AI
Det smartare arbetssättetTa inte bara vårt ord för det
Se vad våra användare säger om Thunderbit.




Vanliga frågor
Relaterat användningsområden
Utforska fler användningsområden för Thunderbits webbscraper.

UNIQLO Scraper
Samla in produktdata från UNIQLO, som namn, priser och tillgängliga storlekar, med bara 2 klick tack vare Thunderbits Chrome-tillägg.
Läs mer ->
Craigslist-skrapa telefonnummer
Thunderbits Craigslist-skrapa för telefonnummer hjälper dig att med AI hämta telefonnummer och annonsdetaljer från Craigslists sökresultat. Skrapa annonser, låt verktyget öppna varje inlägg för att få kontaktuppgifter och fler fält, och exportera sedan till Excel, Google Sheets, Airtable, Notion, CSV eller JSON.
Läs mer ->
United Airlines Scraper
Peka och klicka för att samla in flygdata från United Airlines, som flygnummer, ankomsttid och avgångsflygplats — Thunderbits AI sköter resten.
Läs mer ->
Trivago-skrapare
Skrapa hotellnamn, priser och betyg från Trivago med bara några klick — ingen kod eller installation behövs.
Läs mer ->PeopleWhiz-scraper
Thunderbit PeopleWhiz-scrapern låter dig extrahera data från PeopleWhiz sökresultat och profiler med AI-drivna fältförslag. Samla namn, kontaktuppgifter, platser och mer för research, marknadsföring eller leadgenerering. Omvandla PeopleWhiz-data till strukturerade dataset snabbt och effektivt.
Läs mer ->Substack-scraper
Få Substack-prenumerantantal, artikelrubriker och publikationbeskrivningar i ett rent kalkylblad — ingen kod, AI:n sköter struktureringen.
Läs mer ->Redo att lyfta din datautvinning till nästa nivå?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Den kostnadsfria testperioden ger obegränsade krediter för 8 webbsidor.