
Thunderbits PubMed Scraper hjälper dig att förvandla PubMed-sidor till rena, strukturerade dataset med hjälp av AI. Du kan hämta trendande medicinsk forskning, evidens från kliniska prövningar, abstrakt, författare, affiliationer, publiceringsdatum, PMID och artikellänkar – och sedan exportera till Excel, Google Sheets, Airtable eller Notion. Öppna bara PubMed i Chrome, låt AI föreslå de bästa kolumnerna och skrapa.
🧬 Vad är PubMed Scraper
PubMed Scraper är en AI Web Scraper byggd för . Med (ett AI-webscraper-tillägg för Chrome) kan du gå till valfri resultatsida på PubMed, klicka på AI Suggest Columns och därefter Scrape för att extrahera strukturerad data – helt utan kod.
🔎 Vad kan du skrapa från PubMed
PubMed är fullt av värdefull biomedicinsk metadata, men den är inte alltid redo för analys direkt. Thunderbits AI Web Scraper (https://thunderbit.com/) hjälper dig att samla in och strukturera listningar från PubMed och komplettera dem med detaljer på artikelnivå via Subpage Scraping (öppna varje artikelsida och lägg till fält som abstrakt, affiliationer, DOI med mera).
Nedan är två vanliga arbetsflöden som du kan köra på bara några minuter.
📈 Skrapa trendande medicinsk forskning på PubMed
Använd detta upplägg för att bevaka vad som trendar inom medicinsk forskning på PubMeds trendsida. Det passar för att hålla sig uppdaterad, skapa interna sammanfattningar, följa konkurrenters publikationer eller mata en pipeline för litteraturbevakning.
Exempel på destinationssida:
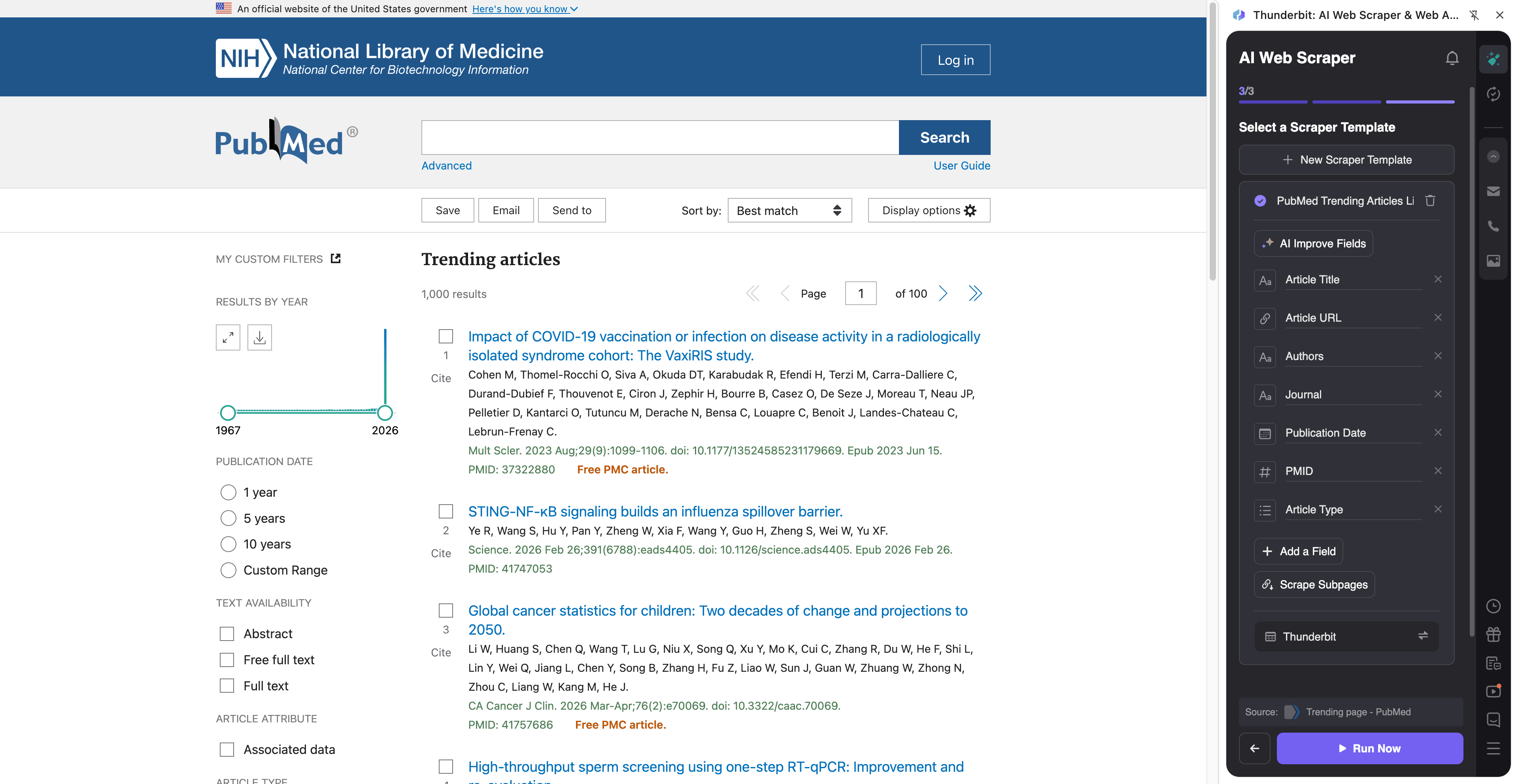
Steg:
- Ladda ner och registrera ett konto.
- Gå till destinationssidan, till exempel: .
- Klicka på AI Suggest Columns så föreslår AI lämpliga kolumnnamn och datatyper.
- Klicka på Scrape för att hämta datan och exportera till Excel, Google Sheets, Airtable eller Notion.
Kolumnnamn
| Kolumn | Beskrivning |
|---|---|
| 🧾 Artikelrubrik | Titeln på den trendande PubMed-artikeln. |
| 🔗 Artikel-URL | Direktlänk till PubMed-postens sida. |
| 🆔 PMID | PubMeds identifierare för posten (bra som stabil nyckel). |
| 🏛️ Tidskrift | Namnet på tidskriften där artikeln publicerats. |
| 📅 Publiceringsdatum | Datumet som visas i listningen. |
| ✍️ Författare | Författarsträngen som visas på resultatkortet. |
| 🧪 Artikeltyp | Publikationstyp när den finns (t.ex. Review, Clinical Trial). |
| 🏷️ Nyckelord / Ämnen | Synliga ämnestaggar eller nyckelord i listningen (om de finns). |
| 📝 Utdrag / Sammanfattning | Kort utdragstext som visas i listningen (om den finns). |
| 🧷 DOI | DOI när den finns (fångas ofta bäst via subpage scraping). |
| 🧑🔬 Affiliationer | Författarnas affiliationer (hämtas vanligtvis via subpage scraping). |
| 📄 Abstrakt | Abstrakttext (hämtas vanligtvis via subpage scraping). |
🧫 Skrapa PubMed för evidens från kliniska prövningar
Använd detta arbetsflöde för att hämta prövningsrelaterad evidens från PubMeds sökresultat och sedan berika varje rad genom att besöka artikelsidan för att fånga abstrakt, prövningssignaler och den metadata du behöver för granskning.
Exempel på destinationssida:
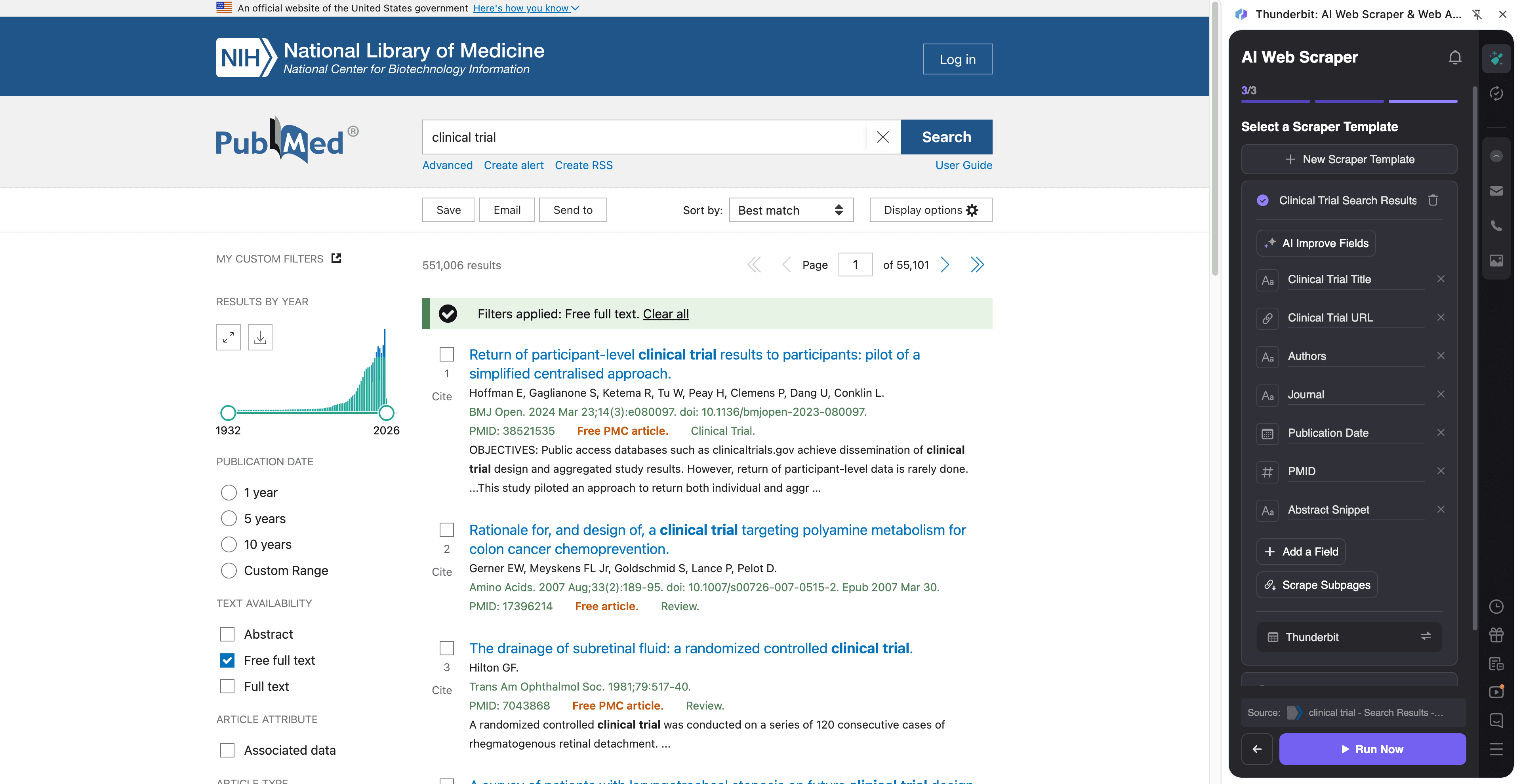
Steg:
- Ladda ner och registrera ett konto.
- Gå till destinationssidan, till exempel: .
- Klicka på AI Suggest Columns för att skapa rekommenderade fält (du kan byta namn eller lägga till egna).
- Klicka på Scrape för att samla resultaten och använd sedan Scrape Subpages för att berika varje rad med abstrakt, affiliationer, DOI med mera.
Kolumnnamn
| Kolumn | Beskrivning |
|---|---|
| 🧾 Titel | Artikelns titel från sökresultaten. |
| 🔗 PubMed-URL | Länk till PubMed-artikelsidan för berikning via subpages. |
| 🆔 PMID | PubMed-ID för avduplicering och referenser. |
| 🧑⚕️ Författare | Författare som listas i resultatets utdrag. |
| 🏛️ Tidskrift | Tidskriftsnamn och citeringsinfo som visas i resultaten. |
| 📅 Datum | Publiceringsdatum (eller ePub-datum) som visas i listningen. |
| 🧪 Publikationstyp | Indikationer som Clinical Trial, Randomized Controlled Trial, Meta-Analysis (ofta tydligare på artikelsidan). |
| 🧾 Abstrakt | Full abstrakttext (bäst via subpage scraping). |
| 🧬 MeSH-termer | Medical Subject Headings när de finns (ofta på artikelsidan). |
| 🧷 DOI | DOI för länkning till förlagssidor och referenshanterare. |
| 🏥 Affiliationer | Författarnas affiliationer för institutionsanalys (subpage scraping). |
| 🌍 Land / Institution | Tolkas från affiliationer med Field AI Prompts (valfritt). |
| 🔍 Nyckelord för klinisk prövning | AI-märkta flaggor som “randomized”, “double-blind”, “placebo” (valfritt via Field AI Prompt). |
| 📎 Fulltextlänkar | Utgående länkar till förlag eller fri fulltext när de finns. |
🎯 Varför använda PubMed-verktyget
Att skrapa PubMed handlar om hastighet, konsekvens och att göra forskningsdata användbar i hela arbetsflödet. I stället för att kopiera citeringar en och en kan du bygga ett strukturerat dataset som går att filtrera, tagga och dela.
Vanliga skäl till att team skrapar PubMed:
- Medical affairs- och pharmateam: Följa nya publikationer inom ett terapiområde, bevaka konkurrenters prövningar och bygga evidenstabeller för interna granskningar.
- Biotech & klinisk verksamhet: Samla prövningsrelaterade publikationer, kartlägga institutioner och prövare samt hålla en levande bibliografi.
- Healthcare marketing- och contentteam: Identifiera trendande ämnen, tidskrifter med hög impact och nya nyckelord för innehållsplanering.
- Akademiska forskare & bibliotekarier: Skapa dataset för litteraturöversikter, avduplicera via PMID och exportera till kalkylark för screening.
- Datateam: Skapa strukturerade underlag för analys, dashboards eller interna kunskapsbaser.
Thunderbit är extra användbart när du behöver mer än bara listningssidan. Med Subpage Scraping kan du hämta abstrakt, affiliationer, DOI, MeSH-termer och fulltextlänkar i stor skala.
🧩 Så använder du PubMed Chrome-tillägget
- Installera Thunderbit Chrome Extension: Hämta den från och skapa ditt konto.
- Gå till en PubMed-sida: Öppna , en trendsida som eller en sökning som .
- Aktivera AI-baserad skrapning: Klicka på AI Suggest Columns för att generera fält, justera datatyper (text/datum/url) och lägg till valfria Field AI Prompts (för märkning, formatering eller för att extrahera prövningssignaler).
- Skrapa och exportera: Klicka på Scrape. Om du behöver abstrakt/affiliationer/MeSH, kör Scrape Subpages för att berika varje rad och exportera sedan till Excel, Google Sheets, Airtable eller Notion.
Lästips om du vill bygga ett återanvändbart arbetsflöde:
💳 Priser för PubMed
Thunderbit använder ett enkelt kreditsystem:
- 1 kredit = 1 utdatarad i din resultattabell (till exempel en PubMed-post).
- Dataexport är gratis: ladda ner CSV/JSON eller skicka till Excel, Google Sheets, Airtable eller Notion.
Du kan börja med:
- Gratisnivå: skrapa 6 sidor per månad (sidbaserad kvot på Free).
- Gratis provperiod: skrapa 10 sidor gratis, vilket är perfekt för att testa PubMed-trender och några sidor med kliniska prövningsresultat.
Om du skrapar regelbundet (veckovis bevakning, evidensuppdateringar eller stora sökningar) ger betalplaner fler krediter. Årsplanen är oftast mer prisvärd eftersom den inkluderar rabatt jämfört med att betala månad för månad.
Du kan se alternativen på .
❓ Vanliga frågor
-
Vad är den AI-drivna PubMed Scraper?
Den AI-drivna PubMed Scraper är ett arbetsflöde i Thunderbit som hämtar strukturerad data från PubMeds sökresultat och artikelsidor. Du kan låta AI föreslå kolumner, skrapa listningar och berika varje rad genom att besöka artikelns undersidor för abstrakt, affiliationer, DOI med mera. -
Vad är Thunderbit?
är ett AI-webscraper-tillägg för Chrome, framtaget för affärs- och forskningsflöden där du behöver strukturerad data från webbplatser. Det hjälper dig att extrahera, märka och exportera data snabbt – utan att bygga eller underhålla skrapningsskript. -
Kan man skrapa PubMeds trendsidor och vanliga sökresultat?
Ja. Du kan skrapa , vanliga nyckelordssökningar och filtrerade resultatsidor (till exempel prövningsfokuserade frågor). Thunderbits AI anpassar sig till olika layouter genom att läsa sidan och föreslå fält. -
Kan Thunderbit hämta abstrakt, affiliationer och MeSH-termer?
Ja – och det är här Subpage Scraping gör störst skillnad. Du skrapar först resultatlistan och låter sedan Thunderbit öppna varje PubMed-post för att hämta abstrakttext, affiliationer, MeSH-termer, DOI och annan metadata till samma tabell. -
Hur fungerar paginering och oändlig scroll på PubMed?
Thunderbit stödjer skrapning med paginering, inklusive navigering av typen “nästa sida”. Om PubMed ändrar hur resultaten laddas är AI-baserad extraktion ofta mer robust än stela selektorer, eftersom den läser om sidstrukturen vid varje körning. -
Vilka format kan jag exportera PubMed-data till?
Du kan exportera till CSV eller JSON, eller skicka datasetet till Excel, Google Sheets, Airtable eller Notion. Det är praktiskt för screeningflöden, evidenstabeller, dashboards och delning med samarbetspartners. -
Hur många PubMed-poster kan jag skrapa gratis?
På Free-nivån kan du skrapa 6 sidor per månad, vilket ofta räcker för mindre bevakningsuppgifter. Med gratis provperiod kan du skrapa 10 sidor utan kostnad för att validera kolumnupplägg och strategi för berikning via subpages. -
Kan jag anpassa kolumner för specifika behov vid evidensextraktion?
Ja. Du kan byta namn på kolumner, välja datatyper (text/datum/url) och lägga till Field AI Prompts för att extrahera eller märka information som nyckelord för studiedesign, population, intervention, comparator, utfall eller land från affiliationer. Det gör att du kan gå från rå skrapning till strukturerad evidensförberedelse. -
Är det okej att skrapa PubMed?
PubMed är en offentlig resurs och många team samlar bibliografisk metadata för forskning och analys. Du bör ändå följa tillämpliga lagar, respektera webbplatsens villkor och använda ansvarsfulla skrapningsmetoder – särskilt vid stora och frekventa körningar.
📚 Läs mer
- Hämta tillägget:
- Utforska guider på
- Lär dig grunderna:
- Bygg listflöden:
- Exportera till kalkylark:
- Om du även skrapar PDF:er i research ops: