

Webben svämmar över av värdefull data – oavsett om du jobbar med försäljning, e-handel eller marknadsundersökningar är web scraping ett hemligt vapen för leadgenerering, prisbevakning och konkurrensanalys. Men här kommer kruxet: ju fler företag som använder scraping, desto hårdare slår webbplatserna tillbaka. Förändringen är verklig: en analys från ppc.land 2024 visade att mer än en tredjedel av de 1 000 största sajterna redan blockerar enbart OpenAI:s crawler — och den bredare verktygslådan med IP-blockeringar, CAPTCHA och browser fingerprinting är nu snarare norm än undantag.
Om du någon gång har sett ditt Python-script köra på fint i 20 minuter — för att sedan plötsligt köra rakt in i en vägg av 403-fel — vet du att frustrationen är högst verklig.
Jag har tillbringat år i SaaS och automatisering, och jag har sett med egna ögon hur scraping-projekt kan gå från ”wow, det här är enkelt” till ”varför är jag blockerad överallt?” på ett ögonblick. Så låt oss bli praktiska: jag går igenom hur du gör web scraping utan att bli blockerad i Python, delar de bästa teknikerna och kodsnutten, och visar när det är dags att överväga AI-drivna alternativ som Thunderbit. Oavsett om du är ett Python-proffs eller bara försöker få det att fungera (ordvits avsedd), kommer du härifrån med en verktygslåda för pålitlig, blockfri dataextraktion.
Vad innebär web scraping utan att bli blockerad i Python?
I grunden betyder web scraping utan att bli blockerad att extrahera data från webbplatser på ett sätt som inte triggar deras anti-bot-försvar. I Python-världen handlar det om mer än att bara skriva en requests.get()-loop — det handlar om att smälta in, efterlikna riktiga användare och ligga steget före detekteringssystemen.
Varför Python? Python är det mest populära språket för web scraping — tack vare sin enkla syntax, enorma ekosystem (tänk: requests, BeautifulSoup, Scrapy, Selenium) och flexibilitet för allt från snabba skript till distribuerade crawlers. Men popularitet har ett pris: många anti-bot-system är nu finjusterade för att upptäcka scraping-mönster från Python.
Så om du vill skrapa på ett tillförlitligt sätt behöver du gå längre än grunderna. Det innebär att förstå hur sajter upptäcker bottar, och hur du kan överlista dem — utan att korsa några etiska eller juridiska gränser.
Varför det är viktigt att undvika blockeringar i Python-projekt för web scraping
Att bli blockerad är inte bara ett tekniskt störmoment — det kan rasera hela affärsflöden. Låt oss bryta ner det:
| Användningsområde | Konsekvens av att bli blockerad |
|---|---|
| Leadgenerering | Ofullständiga eller föråldrade prospektlistor, förlorad försäljning |
| Prisbevakning | Missade prisändringar hos konkurrenter, dåliga prisbeslut |
| Innehållsaggregering | Luckor i nyheter, recensioner eller forskningsdata |
| Marknadsintelligens | Blindfläckar i bevakningen av konkurrenter eller branschen |
| Bostadsannonser | Felaktiga eller inaktuella fastighetsdata, missade möjligheter |
När en scraper blir blockerad förlorar du inte bara data — du slösar resurser, riskerar efterlevnadsproblem och kan fatta dåliga affärsbeslut baserat på ofullständig information. I en värld där 79 % av företag förlitar sig på web scraping för leadgenerering är tillförlitlighet allt.
Hur webbplatser upptäcker och blockerar Python-webbscrapers
Webbplatser har blivit riktigt skickliga på att upptäcka bottar. Här är de vanligaste anti-scraping-försvaren du kommer att stöta på (Medium, Bright Data):
- Svartlistning av IP-adresser: För många förfrågningar från samma IP? Blockerad.
- Kontroller av User-Agent och headers: Förfrågningar med saknade eller generiska headers (som Pythons standard
python-requests/2.25.1) sticker ut. - Hastighetsbegränsning: För många förfrågningar på kort tid utlöser strypning eller avstängning.
- CAPTCHA: ”Bevisa att du är mänsklig”-pussel som bottar inte kan lösa (åtminstone inte enkelt).
- Beteendeanalys: Sajter letar efter robotliknande mönster — till exempel att klicka på samma knapp med samma intervall.
- Honeypots: Dolda länkar eller fält som bara bottar kommer att interagera med.
- Browser fingerprinting: Insamling av detaljer om din webbläsare och enhet för att avslöja automatiseringsverktyg.
- Spårning av cookies och sessioner: Bottar som inte hanterar cookies eller sessioner korrekt flaggas.
Tänk på det som flygplatskontroll: om du ser ut, beter dig och rör dig som alla andra går du igenom utan problem. Om du dyker upp i trenchcoat och solglasögon, räkna med extra frågor.
Viktiga Python-tekniker för web scraping utan att bli blockerad
Nu till det viktiga: hur du faktiskt undviker blockeringar när du scrapar med Python. Här är de grundläggande strategierna som varje scraper bör känna till:

Växlande proxies och IP-adresser
Varför det spelar roll: Om alla dina förfrågningar kommer från samma IP är du ett enkelt mål för IP-blockering. Växlande proxies låter dig sprida förfrågningarna över många IP-adresser, vilket gör dig mycket svårare att blockera.
Så gör du i Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...fler proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# bearbeta svaret
Du kan använda betalda proxytjänster (som residential proxies eller roterande proxies) för högre tillförlitlighet (ScrapingBee).
Ställ in User-Agent och anpassade headers
Varför det spelar roll: Pythons standardheaders skriker ”bot”. Efterlikna riktiga webbläsare genom att ställa in user-agent och andra headers.
Exempelkod:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Växla user-agents för extra diskretion (ZenRows).
Slumpa timing och mönster för förfrågningar
Varför det spelar roll: Bottar är snabba och förutsägbara; människor är långsammare och mer slumpmässiga. Lägg in fördröjningar och variera hur du navigerar.
Python-tips:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Vänta 2–7 sekunder
Du kan också slumpa klickvägar och scrollmönster om du använder Selenium.
Hantera cookies och sessioner
Varför det spelar roll: Många sajter kräver cookies eller sessions-tokens för att ge åtkomst till innehåll. Bottar som ignorerar detta blir blockerade.
Så hanterar du det i Python:
import requests
session = requests.Session()
response = session.get(url)
# sessionen hanterar cookies automatiskt
För mer komplexa flöden kan du använda Selenium för att fånga upp och återanvända cookies.
Simulera mänskligt beteende med headless browsers
Varför det spelar roll: Vissa sajter använder JavaScript, musrörelser eller scrollning som signaler för att identifiera riktiga användare. Headless browsers som Selenium eller Playwright kan efterlikna dessa handlingar.
Exempel med Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Det här hjälper dig att kringgå beteendeanalys och dynamiskt innehåll (ScrapingBee).
Avancerade strategier: kringgå CAPTCHA och honeypots i Python
CAPTCHA är utformade för att stoppa bottar direkt. Även om vissa Python-bibliotek kan lösa enkla CAPTCHA förlitar sig de flesta seriösa scrapers på tredjepartstjänster (som 2Captcha eller Anti-Captcha) för att lösa dem mot en avgift (Medium).
Exempel på integration:
# Pseudokod för att använda 2Captcha API
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Vänta på lösningen och skicka sedan in den med din förfrågan
Honeypots är dolda fält eller länkar som bara bottar kommer att interagera med. Undvik att klicka på eller skicka något som inte är synligt i en riktig webbläsare (ZenRows).
Bygg robusta request-headers med Python-bibliotek
Utöver user-agent kan du växla och slumpa andra headers (som Referer, Accept, Origin och så vidare) för att smälta in ännu bättre.
Med Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Fler headers
}
}
Med Selenium: Använd webbläsarprofiler eller tillägg för att ställa in headers, eller injicera dem via JavaScript.
Håll din header-lista uppdaterad — kopiera riktiga webbläsarförfrågningar via webbläsarens DevTools som inspiration.
När traditionell Python scraping inte räcker: framväxten av anti-bot-teknik
Så här ser verkligheten ut: i takt med att scraping blir mer populärt, blir även anti-bot-uppgraderingarna det. Stora sajter blockerar nu inte bara uppenbara bottar, utan även avancerade headless browsers och roterande proxies. AI-driven detektion, dynamiska trösklar för förfrågningar och browser fingerprinting gör det svårare än någonsin för även avancerade Python-skript att förbli oupptäckta (Medium).
Ibland spelar det ingen roll hur smart din kod är — du kör ändå fast. Då är det dags att överväga ett annat angreppssätt.
Thunderbit: ett AI-webbscraper-alternativ till Python scraping
När Python når sin gräns kliver Thunderbit in som en kodfri, AI-driven web scraper byggd för företagsanvändare — inte bara utvecklare. I stället för att brottas med proxies, headers och CAPTCHA läser Thunderbits AI-agent av webbplatsen, föreslår de bästa fälten att extrahera och hanterar allt från navigering på undersidor till dataexport.
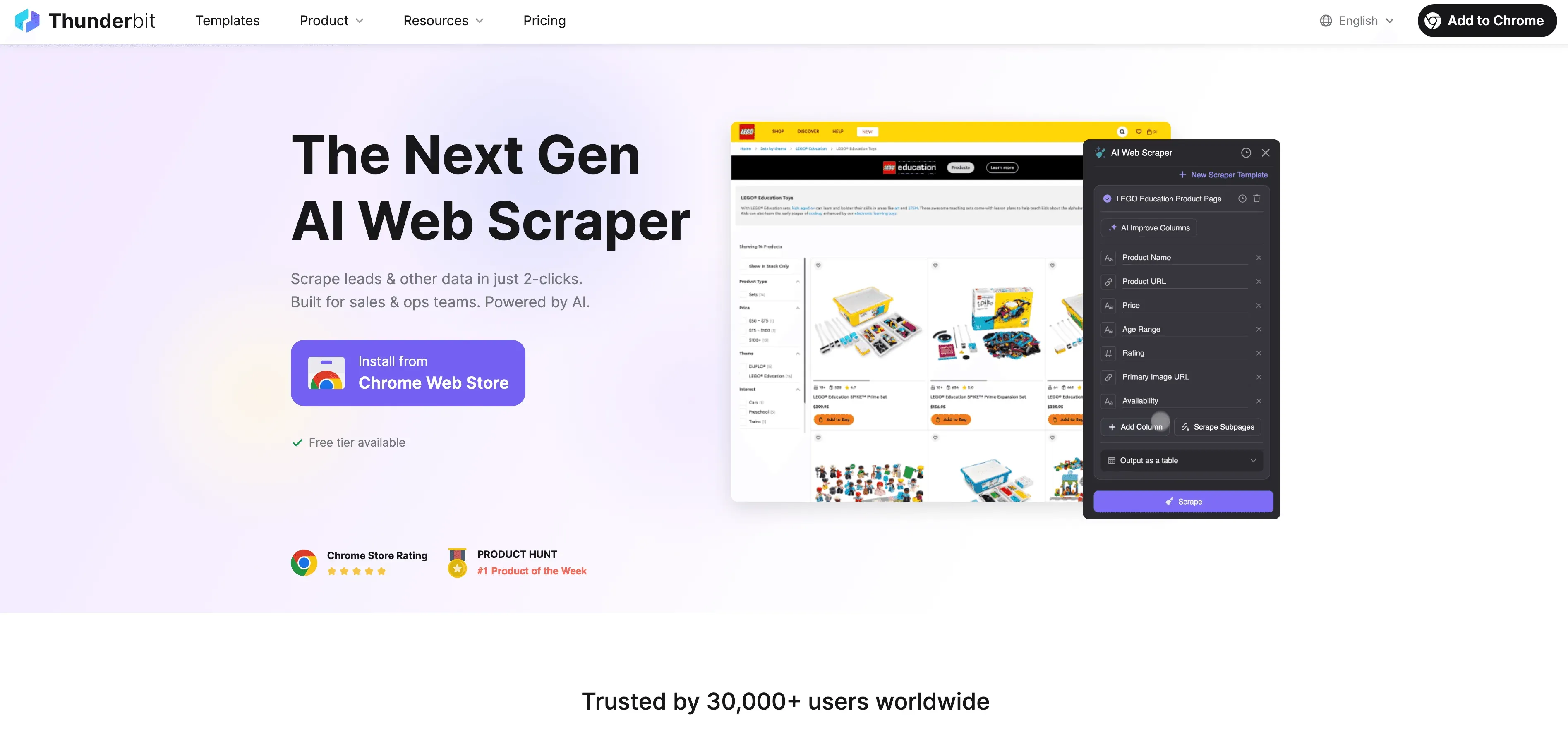
Vad gör Thunderbit annorlunda?
- AI-förslag för fält: Klicka på ”AI Suggest Fields” så skannar Thunderbit sidan, rekommenderar kolumner och genererar till och med extraktionsinstruktioner.
- Scraping av undersidor: Thunderbit kan besöka varje undersida (som produktdetaljer eller LinkedIn-profiler) och berika din tabell automatiskt.
- Scraping i molnet eller i webbläsaren: Välj det snabbaste alternativet — moln för publika sajter, webbläsare för sidor bakom inloggning.
- Schemalagd scraping: Ställ in och glöm bort — Thunderbit kan köra scraping enligt schema, så att din data alltid är färsk.
- Direktmallar: För populära sajter (Amazon, Zillow, Shopify osv.) erbjuder Thunderbit mallar med ett klick — ingen konfiguration behövs.
- Gratis dataexport: Exportera till Excel, Google Sheets, Airtable eller Notion — utan extra avgifter.
Thunderbit används och litas på av över 100 000 användare världen över, och du behöver inte skriva en enda kodrad.
Skrapa data från vilken webbplats som helst med AI Get Started Free
Hur Thunderbit hjälper användare att undvika blockeringar och automatisera dataextraktion
Thunderbits AI imiterar inte bara mänskligt beteende — den anpassar sig till varje sajt i realtid, vilket minskar risken att bli blockerad. Så här fungerar det:
- AI anpassar sig till layoutändringar: Mindre omarbete när en sajt uppdaterar sin design — du behöver inte gå tillbaka och justera selektorer varje vecka.
- Hantering av undersidor och paginering: Thunderbit följer länkar och paginerade listor åt dig, ungefär som en person som klickar sig igenom dem.
- Molnscraping i batcher: Kör jobb från Thunderbits moln i stället för från din laptop, med batchstorlekar som sätts per plan (se prissidan för aktuella gränser).
- Mindre kod att underhålla: Det är inte du som jagar trasiga selektorer mitt i natten när en sajt ändras; AI:n läser av sidan på nytt.
För en djupare genomgång, kolla in Hur du scrapar vilken webbplats som helst med AI.
Jämförelse mellan Python scraping och Thunderbit: vilket ska du välja?
Låt oss ställa dem bredvid varandra:
| Funktion | Python scraping | Thunderbit |
|---|---|---|
| Konfigurationstid | Medel–hög (skript, proxies osv.) | Låg (2 klick, AI gör resten) |
| Tekniska kunskaper | Kodning krävs | Ingen kodning behövs |
| Tillförlitlighet | Varierar (lätt att bryta) | Hög (AI anpassar sig till ändringar) |
| Risk för blockering | Medel–hög | Låg (AI efterliknar användare, anpassar sig) |
| Skalbarhet | Kräver egen kod/molnkonfiguration | Inbyggd scraping i moln/batcher |
| Underhåll | Frekvent (ändringar på sajten, blockeringar) | Minimalt (AI justerar automatiskt) |
| Exportalternativ | Manuellt (CSV, databas) | Direkt till Sheets, Notion, Airtable, CSV |
| Kostnad | Gratis (men tidskrävande) | Gratis nivå, betalda planer för större volymer |
När du ska använda Python:
- Du behöver full kontroll, anpassad logik eller integration med andra Python-flöden.
- Du scrapar sajter med minimala anti-bot-försvar.
När du ska använda Thunderbit:
- Du vill ha hastighet, tillförlitlighet och noll konfiguration.
- Du scrapar komplexa eller ofta föränderliga sajter.
- Du vill slippa proxies, CAPTCHA och kod.
Prova Thunderbit AI Web Scraper gratis
Steg-för-steg-guide: sätt upp web scraping utan att bli blockerad i Python
Låt oss gå igenom ett praktiskt exempel: att scrapa produktdata från en testsajt, samtidigt som vi tillämpar bästa praxis för att undvika blockering.
1. Installera nödvändiga bibliotek
pip install requests beautifulsoup4 fake-useragent
2. Förbered ditt skript
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Ersätt med dina URL:er
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Extrahera data här
print(soup.title.text)
else:
print(f"Blockerad eller fel på {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Slumpmässig fördröjning
3. Lägg till proxyrotation (valfritt)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Fler proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...resten av koden
4. Hantera cookies och sessioner
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...resten av koden
5. Felsökningstips
- Om du ser många 403/429-fel, sakta ner dina förfrågningar eller prova nya proxies.
- Om du stöter på CAPTCHA, överväg att använda Selenium eller en tjänst för CAPTCHA-lösning.
- Kontrollera alltid sajtens
robots.txtoch användarvillkor.
Slutsats och viktiga lärdomar
Web scraping i Python är kraftfullt — men att bli blockerad är en ständig risk i takt med att anti-bot-tekniken utvecklas. Det bästa sättet att undvika blockeringar? Kombinera tekniska bästa praxis för web scraping (växlande proxies, smarta headers, slumpmässiga fördröjningar, sessionshantering och headless browsers) med respekt för sajtregler och etik.
Men ibland räcker inte ens de bästa Python-tricken. Det är där AI-verktyg som Thunderbit kommer in — kodfria, byggda för att hantera layoutändringar och paginering som ställer till det för stela skript, och riktade till företagsanvändare som helst slipper vakta ett Selenium-jobb på kvällstid.
Vill du se hur enkelt scraping kan vara? Ladda ner Thunderbits Chrome-tillägg och prova själv — eller kolla in vår blogg för fler tips och guider om scraping.
Skrapa data utan att bli blockerad
Vanliga frågor
1. Varför blockerar webbplatser Python-webbscrapers?
Webbplatser blockerar scrapers för att skydda sin data, förhindra överbelastning av servrar och stoppa automatiserade bottar från att missbruka deras tjänster. Python-skript är lätta att upptäcka om de använder standardheaders, inte hanterar cookies eller skickar för många förfrågningar för snabbt.
2. Vilka är de mest effektiva sätten att undvika att bli blockerad när man scrapar med Python?
Använd roterande proxies, ställ in realistiska user-agents och headers, slumpa tidpunkten för förfrågningar, hantera cookies/sessioner och simulera mänskligt beteende med verktyg som Selenium eller Playwright.
3. Hur hjälper Thunderbit till att undvika blockeringar jämfört med Python-skript?
Thunderbit använder AI för att anpassa sig till sajtens layout, efterlikna mänsklig surfning och hantera undersidor och paginering automatiskt. Det minskar risken för blockeringar genom att smälta in och uppdatera sitt arbetssätt i realtid — ingen kod eller proxies behövs.
4. När ska jag använda Python scraping jämfört med ett AI-verktyg som Thunderbit?
Använd Python när du behöver anpassad logik, integration med annan Python-kod eller scrapar enkla sajter. Använd Thunderbit för snabb, tillförlitlig och skalbar scraping — särskilt när sajter är komplexa, förändras ofta eller blockerar skript aggressivt.
5. Är web scraping lagligt?
Web scraping är lagligt för offentligt tillgänglig data, men du måste följa varje sajts användarvillkor, integritetspolicy och relevanta lagar. Scrapa aldrig känslig eller privat data, och använd alltid scraping etiskt och ansvarsfullt.
Redo att scrapa smartare, inte hårdare? Prova Thunderbit och lämna blockeringarna bakom dig.
Läs mer:
- Google News Scraping med Python: En steg-för-steg-guide
- Bygg ett prisbevakningsverktyg för Best Buy med Python
- 14 sätt att göra web scraping utan att bli blockerad
- 10 bästa tipsen för hur du inte blir blockerad vid web scraping
Prova AI Web Scraper Get Started Free




