

Det finns något tidlöst i att öppna en terminal, skriva in ett enda kommando och se rå webbdata rulla in som om du just öppnat Matrix. För utvecklare och tekniskt avancerade användare är cURL just det där magiska verktyget — ett anspråkslöst kommandoradsverktyg som i tysthet körs på miljarder enheter, från molnservrar till din smarta kyl. Och även 2026, med alla glansiga no-code- och AI-verktyg för skrapning som finns där ute, är webbskrapning med cURL fortfarande ett självklart val för alla som vill ha fart, kontroll och möjlighet att automatisera med skript.
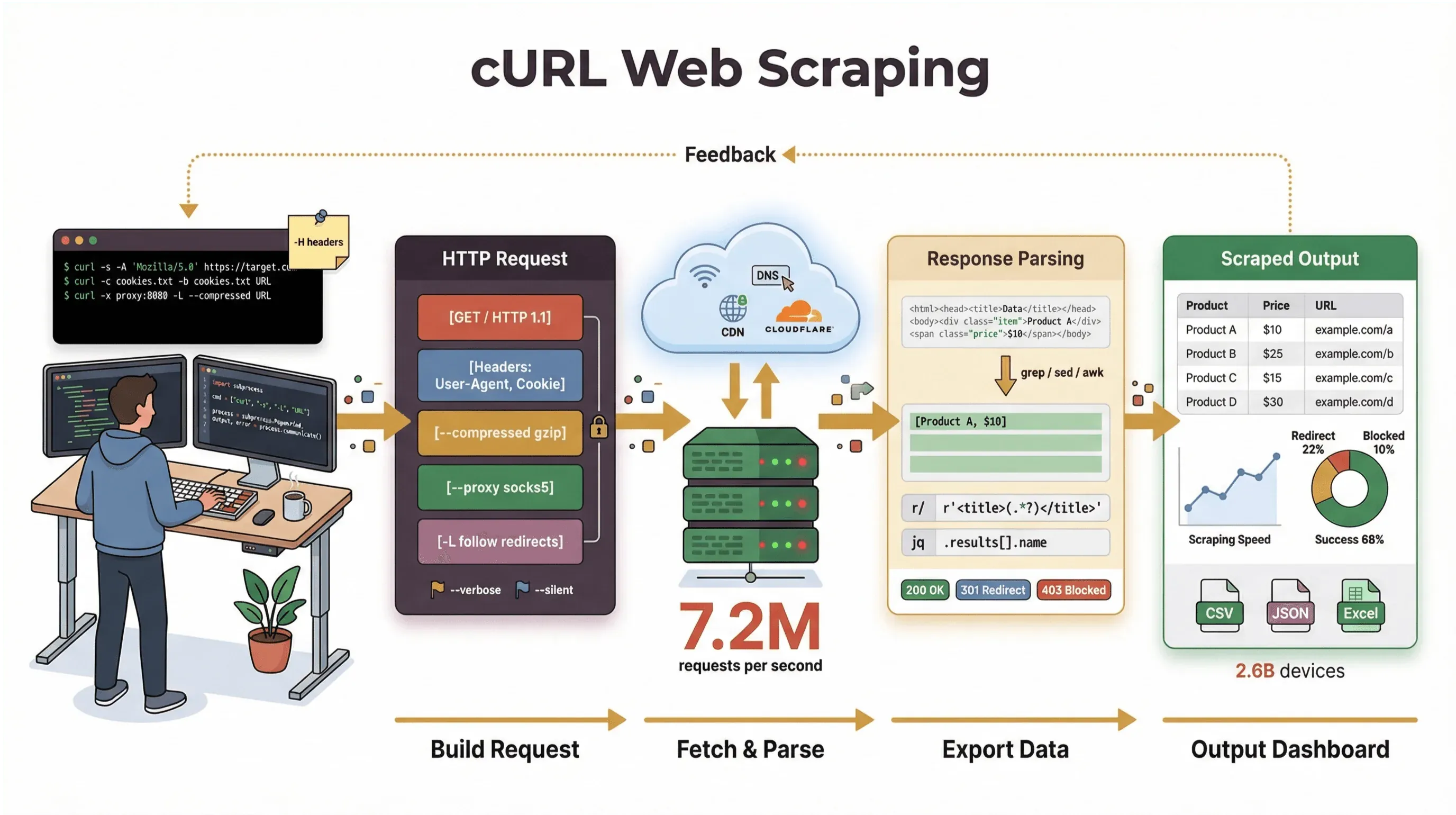 Jag har ägnat år åt att bygga automationsverktyg och hjälpa team att hantera webbdata, och jag använder fortfarande cURL när jag behöver hämta en sida, felsöka ett API eller prototypa ett arbetsflöde för skrapning. I den här guiden går jag igenom en cURL-webbskrapningsguide som täcker både grunderna och proffstricken — med riktiga kommandon, praktiska tips och en ärlig bild av var cURL glänser (och var det tar stopp). Och om du hellre är en affärsanvändare som inte vill röra kommandoraden alls, visar jag hur Thunderbit, vår AI-drivna webbskrapare, kan ta dig från ”jag behöver den här datan” till ”här är mitt kalkylblad” på två klick — helt utan kod.
Jag har ägnat år åt att bygga automationsverktyg och hjälpa team att hantera webbdata, och jag använder fortfarande cURL när jag behöver hämta en sida, felsöka ett API eller prototypa ett arbetsflöde för skrapning. I den här guiden går jag igenom en cURL-webbskrapningsguide som täcker både grunderna och proffstricken — med riktiga kommandon, praktiska tips och en ärlig bild av var cURL glänser (och var det tar stopp). Och om du hellre är en affärsanvändare som inte vill röra kommandoraden alls, visar jag hur Thunderbit, vår AI-drivna webbskrapare, kan ta dig från ”jag behöver den här datan” till ”här är mitt kalkylblad” på två klick — helt utan kod.
Låt oss dyka in och se varför cURL fortfarande är relevant för webbskrapning 2026, hur du använder det effektivt och när det är dags att ta fram något ännu kraftfullare.
Vad är cURL? Grunden i webbskrapning med cURL
I grunden är cURL ett kommandoradsverktyg och ett bibliotek för att överföra data med URL:er. Det har funnits i nästan 30 år (ja, verkligen) och finns överallt — inbyggt i operativsystem, som drivkraft i skript och tyst hanterande av dataöverföringar i mer än tjugo miljarder installationer. Om du någon gång har kört ett snabbt kommando för att hämta en webbsida, testa ett API eller ladda ner en fil, finns det god chans att du har använt cURL.
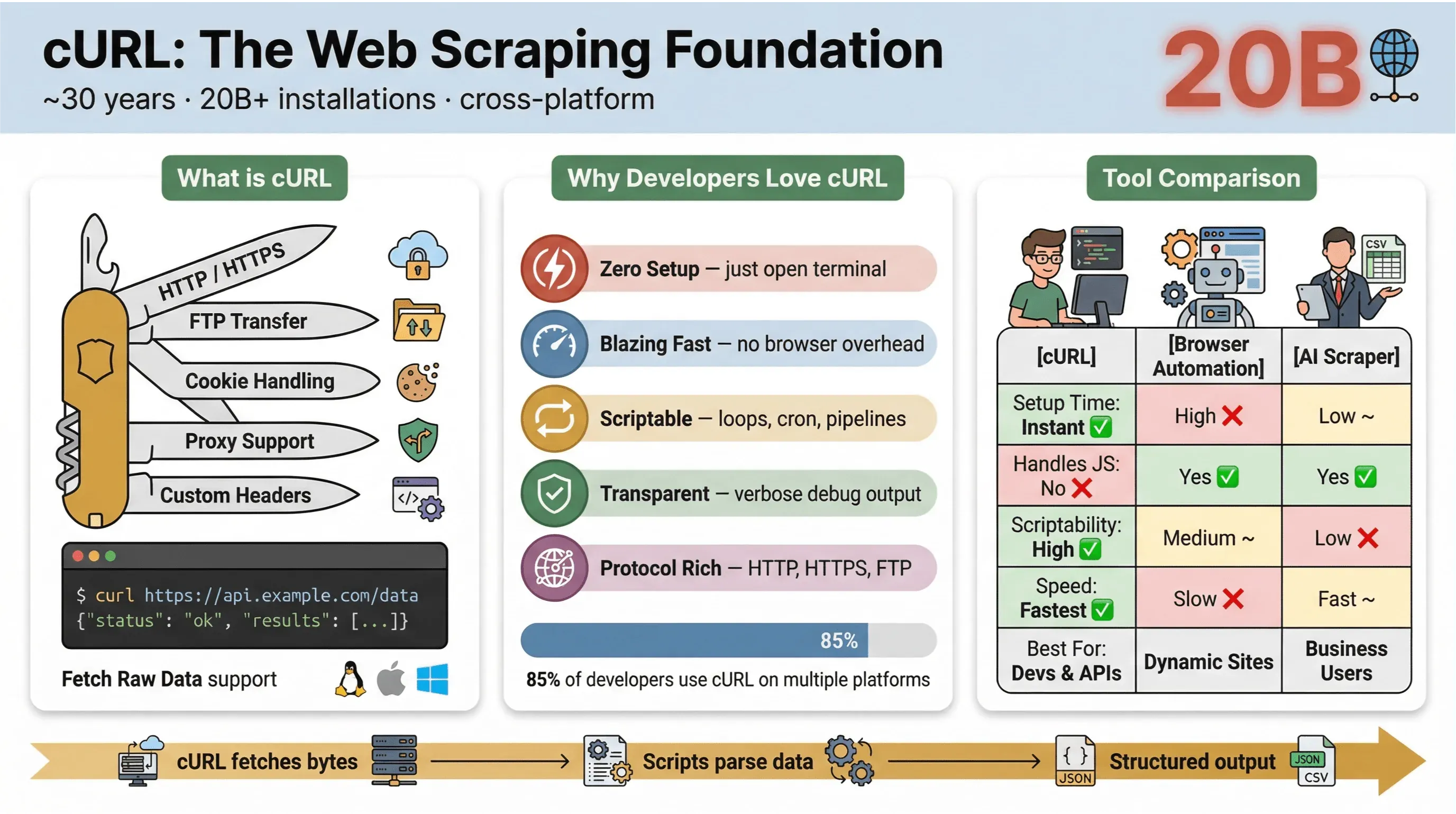 Det här är det som gör cURL så populärt för webbskrapning:
Det här är det som gör cURL så populärt för webbskrapning:
- Lättviktigt och plattformsoberoende: Körs på Linux, macOS, Windows och till och med inbyggda enheter.
- Stöd för protokoll: Hanterar HTTP, HTTPS, FTP med mera.
- Går att skripta: Perfekt för automatisering, cron-jobb och limkod.
- Ingen användarinteraktion krävs: Utformat för icke-interaktiv användning — utmärkt för batchjobb och pipelines.
Men låt oss vara tydliga: cURL:s huvuduppgift är att hämta rådata — HTML, JSON, bilder, vad du vill. Det parsar, renderar eller strukturerar inte datan åt dig. Se cURL som ”första milen” i webbskrapning: det ger dig bytesen, men du behöver andra verktyg (som Python-skript, grep/sed/awk eller en AI-webbskrapare) för att omvandla det till strukturerad information.
Om du vill se den officiella dokumentationen kan du läsa cURL:s guide för HTTP-skriptning.
Varför använda cURL för webbskrapning? (cURL-webbskrapningsguide)
Så varför återkommer utvecklare och tekniska användare till cURL för webbskrapning, trots alla nya verktyg? Här är det som får cURL att sticka ut:
- Minimal installation: Inga installationer, inga beroenden — bara öppna terminalen och kör.
- Hastighet: Hämta data direkt utan att vänta på att en webbläsare ska ladda.
- Går att skripta: Loopa enkelt över URL:er, automatisera begäranden och kedja kommandon.
- Stöd för protokoll och funktioner: Hantera cookies, proxyservrar, omdirigeringar, anpassade headers och mer.
- Transparens: Se exakt vad som händer med utförlig felsökningsutmatning.
I cURL:s användarundersökning 2025 svarade 85,7 % att de använder cURL:s kommandoradsverktyg, och 96,2 % uppgav att de använder det på Linux — fortfarande den klart största plattformen för cURL.
--- Det är fortfarande den schweiziska armékniven för HTTP-begäranden, snabba datainsamlingar och felsökning.
Här är en snabb jämförelse mellan cURL och andra metoder för skrapning:
| Funktion | cURL | Webbläsarautomatisering (t.ex. Selenium) | AI-webbskrapare (t.ex. Thunderbit) |
|---|---|---|---|
| Installationstid | Omedelbar | Hög | Låg |
| Går att skripta | Hög | Medel | Låg (ingen kod behövs) |
| Hanterar JavaScript | Nej | Ja | Ja (Thunderbit: via webbläsare) |
| Stöd för cookies/sessioner | Manuellt | Automatiskt | Automatiskt |
| Datastrukturering | Manuellt (parsas senare) | Manuellt (parsas senare) | AI-/mallbaserat |
| Bäst för | Utvecklare, snabba hämtningar | Komplexa, dynamiska webbplatser | Affärsanvändare, strukturerad export |
Kort sagt: cURL är oslagbart för snabba, skriptbara datainhämtningar — särskilt för statiska sidor, API:er eller när du vill automatisera enkla arbetsflöden. Men så snart du behöver tolka komplex HTML, hantera JavaScript eller exportera strukturerad data, vill du ha något mer specialiserat.
Kom igång: Exempel på grundläggande cURL-kommandon för webbskrapning
Nu kör vi praktiskt. Så här använder du cURL för grundläggande webbskrapning, steg för steg.
Hämta rå HTML med cURL
Det enklaste användningsfallet: hämta HTML-koden från en webbsida.
curl https://books.toscrape.com/
Det här kommandot hämtar startsidan för Books to Scrape, en publik demosajt för webbskrapning. Du ser rå HTML-utdata i terminalen — leta efter taggar som <title> eller snuttar som ”In stock”.
Spara utdata till en fil
Vill du spara HTML-koden för senare tolkning? Använd flaggan -o:
curl -o page.html https://books.toscrape.com/
Nu har du en fil page.html med hela HTML-innehållet. Perfekt för vidare analys eller parsning med andra verktyg.
Skicka POST-begäranden med cURL
Behöver du skicka in ett formulär eller prata med ett API? Använd flaggan -d för POST-begäranden. Här är ett exempel med httpbin, en sajt byggd för HTTP-testning:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Du får ett JSON-svar som speglar de data du skickade in — perfekt för test och prototypande.
Inspektera headers och felsöka
Ibland vill du se svarshuvuden eller felsöka begäran:
-
Endast headers (HEAD-begäran):
curl -I https://books.toscrape.com/ -
Inkludera headers tillsammans med body:
curl -i https://httpbin.org/get -
Utförlig/felsökningsutmatning:
curl -v https://books.toscrape.com/
De här flaggorna hjälper dig att förstå vad som händer under huven — avgörande när du felsöker.
Här är en snabb referenstabell för dessa kommandon:
| Uppgift | Exempel på kommando | Kommentarer |
|---|---|---|
| Hämta HTML | curl URL | Skriver ut HTML till terminalen |
| Spara till fil | curl -o file.html URL | Skriver utdata till en fil |
| Inspektera headers | curl -I URL eller curl -i URL | -I för endast HEAD, -i inkluderar headers med body |
| Skicka formulärdata | curl -d "a=1&b=2" URL | Skickar formaterad formulärdata |
| Felsök begäran/svar | curl -v URL | Visar detaljerad information om begäran/svar |
För fler exempel kan du läsa cURL:s officiella dokumentation för skriptning.
Ta det vidare: Avancerad webbskrapning med cURL (webbskrapning med cURL)
När du väl behärskar grunderna öppnar cURL upp en värld av avancerade funktioner för mer komplexa skrapningsuppgifter.
Hantera cookies och sessioner
Många webbplatser kräver cookies för att hålla inloggningssessioner aktiva eller spåra användare. Med cURL kan du spara och återanvända cookies mellan olika begäranden:
# Spara cookies efter inloggning
curl -c cookies.txt https://example.com/login
# Använd cookies för efterföljande begäranden
curl -b cookies.txt https://example.com/account
Det här låter dig efterlikna webbläsarsessioner och nå sidor bakom inloggningsväggar (så länge det inte finns någon JavaScript-utmaning).
Förfalska User-Agent och anpassade headers
Vissa webbplatser visar olika innehåll beroende på din User-Agent eller dina headers. Som standard identifierar sig cURL som ”curl/VERSION”, vilket kan utlösa blockeringar eller annat innehåll. För att efterlikna en webbläsare:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Du kan också ange anpassade headers, till exempel språkpreferenser:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Det här hjälper dig att få samma innehåll som en riktig webbläsare skulle se.
Använda proxyservrar för webbskrapning
Behöver du routa dina begäranden via en proxy (för geografiska tester eller för att undvika IP-blockeringar)? Använd flaggan -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Se bara till att du använder proxyservrar ansvarsfullt och inom webbplatsens användarvillkor.
Automatisera skrapning av flera sidor
Vill du skrapa flera sidor — till exempel en paginerad produktlista? Använd en enkel shell-loop:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Det här hämtar sidorna 2 till 5 i Books to Scrape-katalogen och sparar varje sida i en separat fil. (Sida 1 är startsidan.)
Begränsningar med webbskrapning med cURL: Det här behöver du känna till
Hur mycket jag än gillar cURL är det inte någon silverkula. Här är var det kommer till korta:
- Ingen JavaScript-körning: cURL kan inte hantera sidor som kräver JavaScript för att rendera innehåll eller lösa anti-bot-utmaningar (developers.cloudflare.com).
- Manuell parsning krävs: Du får rå HTML eller JSON, men du måste tolka den själv — ofta med extra skript eller verktyg.
- Begränsad sessionshantering: Att hantera komplexa inloggningar, tokens eller flerstegsformulär kan snabbt bli rörigt.
- Ingen inbyggd datastrukturering: cURL gör inte om webbsidor till rader, tabeller eller kalkylblad.
- Sårbart för anti-bot-detektering: Många webbplatser använder numera avancerat botskydd (JavaScript, fingerprinting, CAPTCHAs) som cURL helt enkelt inte kan kringgå (datadome.co).
Här är en snabb jämförelsetabell:
| Begränsning | Endast cURL | Moderna skrapverktyg (t.ex. Thunderbit) |
|---|---|---|
| Stöd för JavaScript | Nej | Ja |
| Datastrukturering | Manuell | Automatisk (AI/mall) |
| Sessionshantering | Manuell | Automatisk |
| Bypass av anti-bot | Begränsad | Avancerad (webbläsarbaserad/AI) |
| Användarvänlighet | Tekniskt | Icke-tekniskt |
För statiska sidor och API:er är cURL fantastiskt. För allt som är mer dynamiskt eller skyddat vill du gå vidare i verktygskedjan.
Thunderbit jämfört med cURL: Det bästa tillvägagångssättet för icke-tekniska användare
Låt oss nu prata om Thunderbit, vår AI-drivna Chrome-tillägg för webbskrapning. Om du är säljare, marknadsförare eller arbetar med drift och bara vill få data från en webbplats in i Excel, Google Sheets eller Notion — utan att röra kommandoraden — då är Thunderbit byggt för dig.
Så här står sig Thunderbit jämfört med cURL:
| Funktion | cURL | Thunderbit |
|---|---|---|
| Gränssnitt | Kommandorad | Klicka och peka (Chrome-tillägg) |
| AI-förslag på fält | Nej | Ja (AI läser sidan och föreslår kolumner) |
| Hanterar paginering/delsidor | Manuell skriptning | Automatiskt (AI upptäcker och skrapar) |
| Dataexport | Manuellt (parsa + spara) | Direkt till Excel, Google Sheets, Notion, Airtable |
| JavaScript/skyddade sidor | Nej | Ja (webbläsarbaserad skrapning) |
| Kräver ingen kod | Nej (kräver skript) | Ja (alla kan använda det) |
| Gratisnivå | Alltid gratis | Gratis för upp till 6 sidor (10 med provboost) |
Med Thunderbit öppnar du bara tillägget, klickar på ”AI föreslå fält” och låter AI:n räkna ut vilken data som ska extraheras. Du kan skrapa tabeller, listor, produktdetaljer och till och med besöka delsidor automatiskt. Sedan exporterar du datan direkt till dina favoritverktyg — utan parsning, utan huvudvärk.
Thunderbit används av över 100 000 användare världen över, och är särskilt populärt bland sälj-, e-handels- och fastighetsteam som behöver strukturerad data snabbt.
Prova Thunderbits Chrome-tillägg för webbskrapning
Vill du testa? Ladda ner Chrome-tillägget här.
Kombinera cURL och Thunderbit: Flexibla strategier för webbskrapning
Om du är teknisk användare finns det ingen anledning att välja bara ett verktyg. Faktum är att många team använder cURL och Thunderbit tillsammans för maximal flexibilitet:
- Prototypa med cURL: Använd cURL för att snabbt testa endpoints, inspektera headers och förstå hur en webbplats svarar.
- Skala upp med Thunderbit: När du behöver strukturerad data, skrapning av flera sidor eller ett repeterbart arbetsflöde, byt till Thunderbit för klickbaserad extraktion och direkt export.
Här är ett exempel på arbetsflöde för marknadsundersökningar:
- Använd cURL för att hämta några sidor och inspektera HTML-strukturen.
- Identifiera de datamfält du vill ha (t.ex. produktnamn, priser, recensioner).
- Öppna Thunderbit, klicka på ”AI föreslå fält” och låt AI:n sätta upp skraparen.
- Skrapa alla sidor (inklusive delsidor eller paginerade listor) och exportera till Google Sheets.
- Analysera, dela och agera på datan — utan manuell parsning.
Här är en snabb beslutstabell:
| Scenario | Använd cURL | Använd Thunderbit | Använd båda |
|---|---|---|---|
| Snabb hämtning av API eller statisk sida | ✅ | ||
| Behöver strukturerad data i ett kalkylblad | ✅ | ||
| Felsökning av headers/cookies | ✅ | ||
| Skrapning av dynamiska/JS-tunga sidor | ✅ | ||
| Bygga ett repeterbart, no-code-arbetsflöde | ✅ | ||
| Prototypa och sedan skala upp | ✅ | ✅ | Hybridarbetsflöde |
Vanliga utmaningar och fallgropar vid webbskrapning med cURL
Innan du går loss med cURL, låt oss prata om de verkliga utmaningarna du kommer att möta:
- Anti-bot-system: Många webbplatser använder nu avancerat skydd (JavaScript-utmaningar, CAPTCHAs, fingerprinting) som cURL inte kan kringgå (developers.cloudflare.com).
- Problem med datakvalitet: Ändringar i HTML, saknade fält eller inkonsekventa layouter kan bryta dina skript.
- Underhållsarbete: Varje gång en webbplats ändras måste du uppdatera din parslogik.
- Juridiska och regelmässiga risker: Kontrollera alltid webbplatsens användarvillkor, robots.txt och relevanta lagar innan du skrapar. Bara för att data är offentlig betyder det inte att den är fri att använda (calawyers.org, polsinelli.com).
- Begränsningar i skala: cURL är utmärkt för små jobb, men för skrapning i stor skala behöver du hantera proxyservrar, hastighetsgränser och felhantering.
Tips för felsökning och efterlevnad:
- Börja alltid med tillåtna eller demobaserade sajter (som Books to Scrape).
- Respektera hastighetsgränser — överbelasta inte endpoints.
- Undvik att skrapa personuppgifter om du inte har laglig grund.
- Om du stöter på JavaScript- eller CAPTCHA-väggar, överväg att byta till ett webbläsarbaserat verktyg som Thunderbit.
Steg-för-steg-sammanfattning: Så skrapar du webbplatser med cURL
Här är din snabbguide för webbskrapning med cURL:
- Identifiera din/dina mål-URL:er: Börja med en statisk sida eller ett API-endpoint.
- Hämta sidan:
curl URL - Spara utdata till en fil:
curl -o file.html URL - Inspektera headers/felsök:
curl -I URL,curl -v URL - Skicka POST-data:
curl -d "a=1&b=2" URL - Hantera cookies/sessioner:
curl -c cookies.txt ...,curl -b cookies.txt ... - Ange anpassade headers/User-Agent:
curl -A "..." -H "..." URL - Följ omdirigeringar:
curl -L URL - Använd proxyservrar (vid behov):
curl -x proxy:port URL - Automatisera skrapning av flera sidor: Använd shell-loopar eller skript.
- Parsa och strukturera datan: Använd fler verktyg eller skript vid behov.
- Byt till Thunderbit för strukturerad, kodfri skrapning eller dynamiska sidor.
Slutsats och viktigaste lärdomar: Att välja rätt verktyg för webbskrapning
Skrapa data från vilken webbplats som helst med AI Get Started Free
Webbskrapning med cURL är fortfarande en kraftfull färdighet för tekniska användare 2026 — särskilt för snabba datainhämtningar, prototypande och automatisering. cURL:s hastighet, skriptbarhet och allestädesnärvaro gör det till en självklar del av varje utvecklares verktygslåda. Men i takt med att webben blir mer dynamisk och mer skyddad, och när affärsanvändare kräver strukturerad data utan kod, omdefinierar verktyg som Thunderbit vad som är möjligt.
Viktigaste lärdomarna:
- Använd cURL för statiska sidor, API:er och snabb prototypning — särskilt när du vill ha full kontroll.
- Byt till Thunderbit (eller liknande AI-webbskrapare) när du behöver strukturerad data, ska hantera dynamiska/JavaScript-tunga sidor eller vill ha ett no-code-flöde som passar affärsbruk.
- Kombinera båda för maximal flexibilitet: prototypa med cURL, skala upp och strukturera med Thunderbit.
- Skrapa alltid ansvarsfullt — respektera webbplatsens villkor, hastighetsgränser och juridiska ramar.
Nyfiken på hur enkelt webbskrapning kan vara? Prova Thunderbits gratis Chrome-tillägg och upplev AI-driven dataextraktion själv. Och om du vill fördjupa dig mer, kolla in Thunderbit-bloggen för fler guider, tips och branschinsikter. Du kanske också gillar:
- Så skrapar du vilken webbplats som helst med AI
- Så skrapar du webbplatsdata till Excel med AI
- Vad är dataskrapning och hur gör man det 2025
Lycka till med skrapningen — och må din data alltid vara ren, strukturerad och bara ett kommando (eller klick) bort.
Utforska Thunderbits abonnemang för skalbar webbskrapning
Vanliga frågor
1. Kan cURL hantera webbsidor som renderas med JavaScript?
Nej, cURL kan inte köra JavaScript. Det hämtar rå HTML som den levereras av servern. Om en sida kräver JavaScript för att rendera innehåll eller lösa anti-bot-utmaningar kommer cURL inte kunna komma åt datan. I sådana fall använder du webbläsarbaserade verktyg som Thunderbit.
2. Hur sparar jag cURL-utdata direkt till en fil?
Använd flaggan -o: curl -o filename.html URL. Det skriver svarstexten till en fil i stället för att visa den i terminalen.
3. Vad är skillnaden mellan cURL och Thunderbit för webbskrapning?
cURL är ett kommandoradsverktyg för att hämta rå webbdata — utmärkt för tekniska användare och automatisering. Thunderbit är en AI-driven Chrome-tillägg som är byggt för affärsanvändare som vill extrahera strukturerad data från vilken webbplats som helst, hantera dynamiska sidor och exportera direkt till verktyg som Excel eller Google Sheets — utan kod.
4. Är det lagligt att skrapa webbplatser med cURL?
Att skrapa offentlig data är i allmänhet lagligt i USA efter senare domstolsavgöranden, men kontrollera alltid webbplatsens användarvillkor, robots.txt och relevanta lagar. Undvik att skrapa personliga eller skyddade uppgifter utan tillstånd, och respektera hastighetsgränser och etiska riktlinjer (calawyers.org, polsinelli.com).
5. När bör jag byta från cURL till ett mer avancerat verktyg som Thunderbit?
Om du behöver skrapa dynamiska/JavaScript-tunga sidor, vill ha strukturerad data i ett kalkylblad eller föredrar ett no-code-arbetsflöde, är Thunderbit det bättre valet. Använd cURL för snabba, tekniska uppgifter; använd Thunderbit för affärsvänlig, repeterbar dataextraktion.
För fler tips och guider om webbskrapning, besök Thunderbit-bloggen eller kolla in vår YouTube-kanal.
Prova Thunderbit AI-webbskrapare Get Started Free




