

“Du kan ha data utan information, men du kan inte ha information utan data.” — Daniel Keys Moran*
Nya uppskattningar visar att det finns över 1,5 miljarder webbplatser på internet, med omkring 2 miljoner nya inlägg som publiceras varje dag. Det här enorma datamängden rymmer värdefulla insikter som kan hjälpa dig att fatta bättre beslut, men det finns en hake: ungefär 80 % av allt är ostrukturerat, vilket betyder att det måste bearbetas innan det faktiskt går att använda. Det är här webbskrapningsverktyg kommer in i bilden och blir oumbärliga för alla som vill ta vara på online-data.
Om du är ny inom webbskrapning kan termer som webbkomponenter och HTML kännas lite avskräckande. Men i AI-eran är de här utmaningarna mycket enklare att ta sig an. Dagens AI-drivna skrapverktyg kan hjälpa dig att komma igång utan djupa tekniska kunskaper. De gör det möjligt att samla in och bearbeta data snabbt, utan att du behöver kunna koda.
De bästa webbskrapningsverktygen och programvarorna
- Thunderbit för en lättanvänd AI-webbskrapare med bästa resultat
- Browse AI för övervakning i realtid och massutvinning av data
- Bardeen AI för no-code-automation med omfattande appintegrationer
- Web Scraper för mer professionell visuell webbskrapning
- Octoparse för kraftfull no-code-skrapning som undviker IP-blockering och bottillämpad upptäckt
- Diffbot för avancerat AI-drivet API för datautvinning och kunskapsgrafer
Testa att använda AI för webbskrapning
Testa själv! Du kan klicka, utforska och köra arbetsflödet medan du tittar.
Hur fungerar webbskrapning?
Webbskrapning handlar helt enkelt om att hämta data från webbplatser. Du ger ett verktyg en uppsättning instruktioner, och sedan hämtar det text, bilder eller vad du nu behöver till en tabell från en webbsida. Det kan vara praktiskt för allt från att följa priser på e-handelswebbplatser till att samla in forskningsdata eller bara bygga upp ett bra Excel-ark eller Google Sheets.
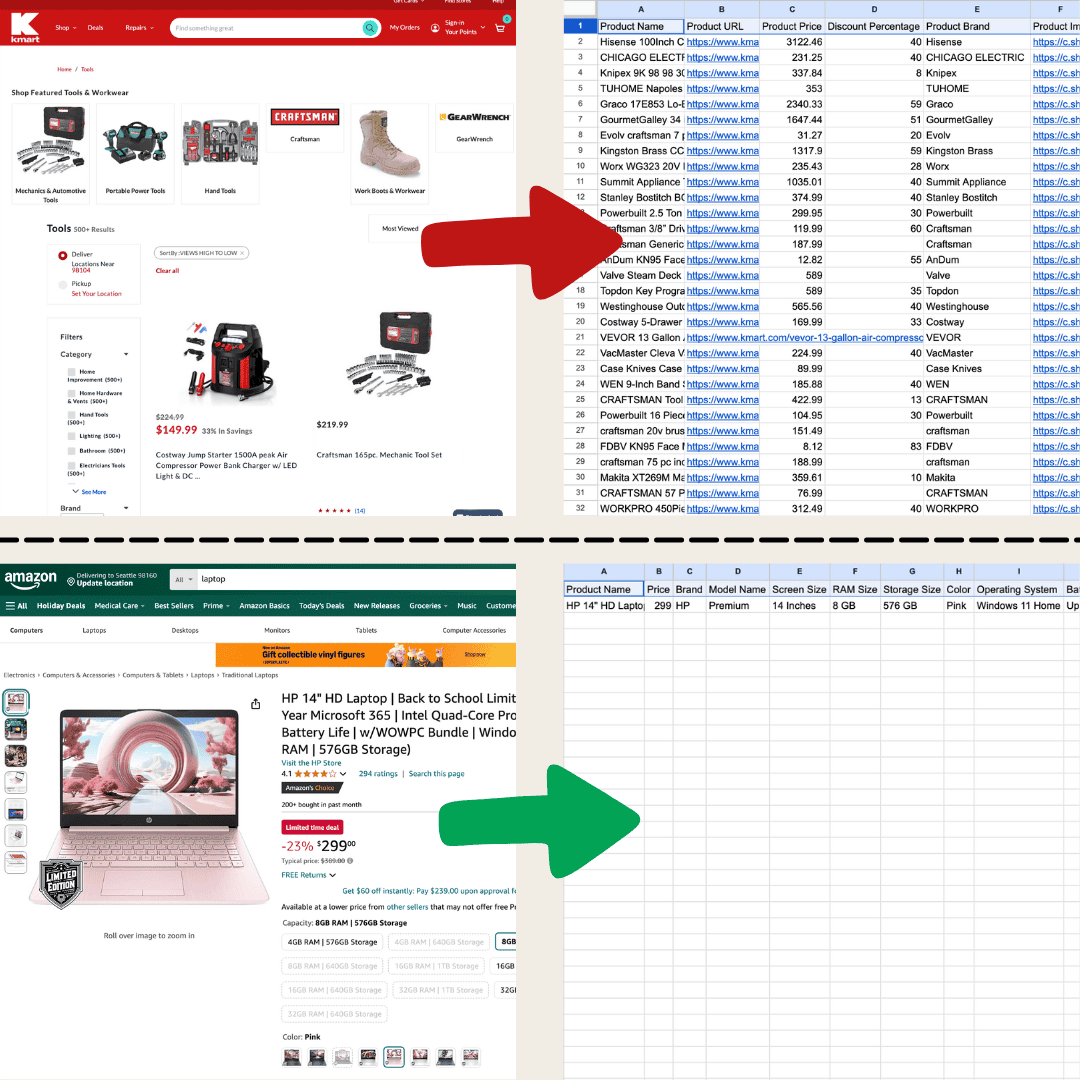 Jag gjorde detta med Thunderbit med hjälp av AI Web Scraper.
Jag gjorde detta med Thunderbit med hjälp av AI Web Scraper.
Det finns några olika sätt att göra det på. På den enklaste nivån skulle du kunna kopiera och klistra in allt själv, men det blir snabbt väldigt mycket jobb om det handlar om stora mängder data. Därför använder de flesta en av tre metoder: traditionella webbskrapare, AI-webbskrapare eller egen kod.
Traditionella webbskrapare fungerar genom att man sätter upp specifika regler för vilken data som ska hämtas, baserat på sidans struktur. Du kan till exempel ställa in den så att den hämtar produktnamn eller priser från vissa HTML-taggar. De fungerar bäst på webbplatser som inte ändras särskilt ofta, eftersom minsta layoutjustering innebär att du måste gå in och justera din skrapare.
 Att använda en traditionell skrapare tar tid att lära sig, och det kommer sannolikt att ta dig dussintals klick att slutföra installationen.
Att använda en traditionell skrapare tar tid att lära sig, och det kommer sannolikt att ta dig dussintals klick att slutföra installationen.
Skrapa data från vilken webbplats som helst med AI Get Started Free
AI-webbskrapare betyder i princip att ChatGPT läser igenom hela webbplatsen och sedan extraherar innehållet utifrån det du behöver. Den kan hantera datautvinning, översättning och sammanfattning samtidigt. Den använder naturlig språkbehandling för att analysera och förstå webbplatsens upplägg, vilket gör att den kan hantera ändringar på webbplatsen smidigare. Om webbplatsen till exempel flyttar runt sina sektioner lite grand kan en AI-webbskrapare kanske anpassa sig utan att du behöver skriva om något. Därför är de bra för mer underhållskrävande sajter eller sajter med mer komplex struktur.
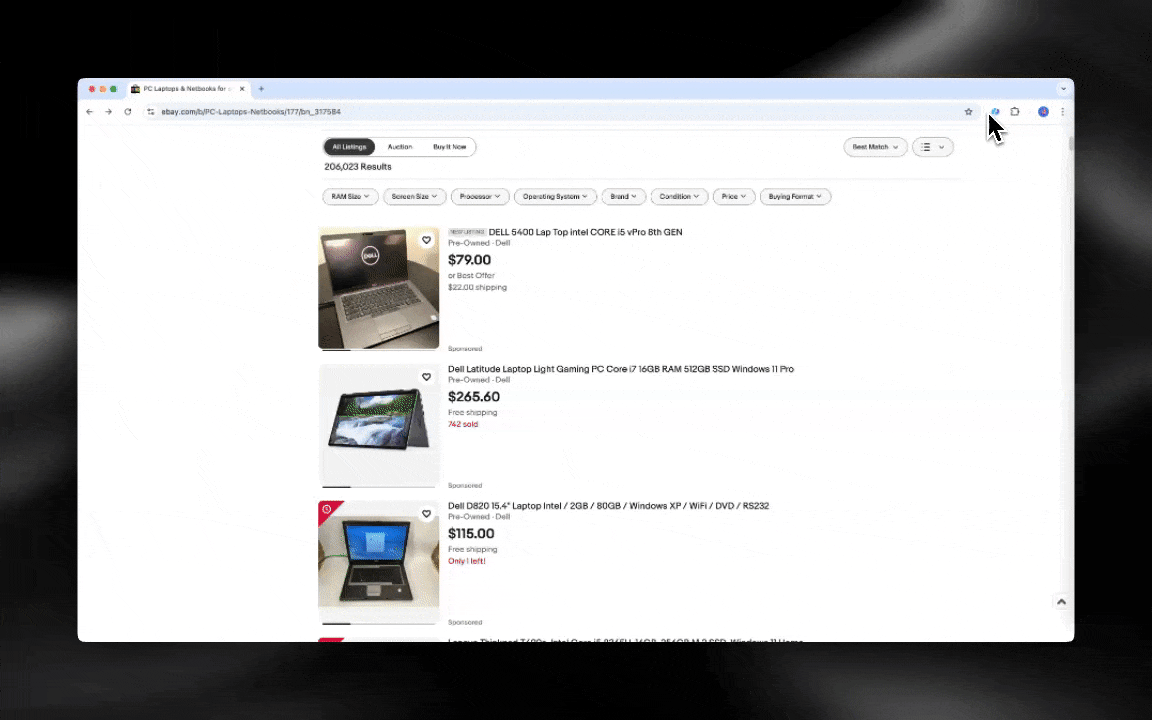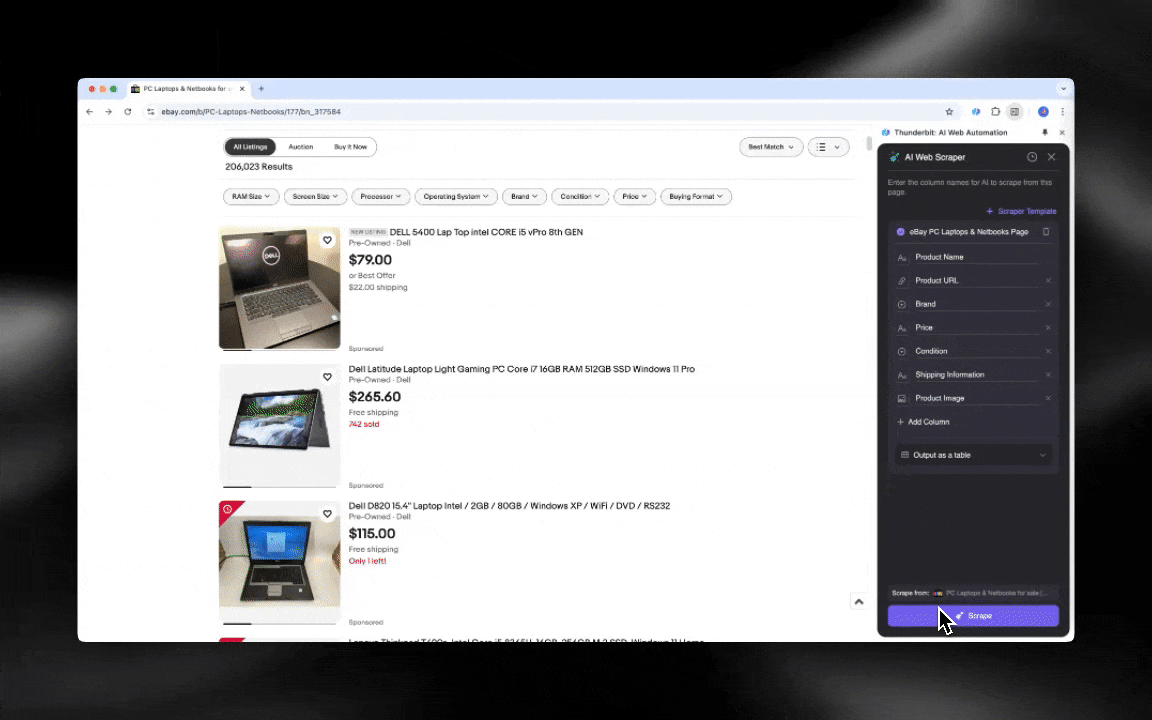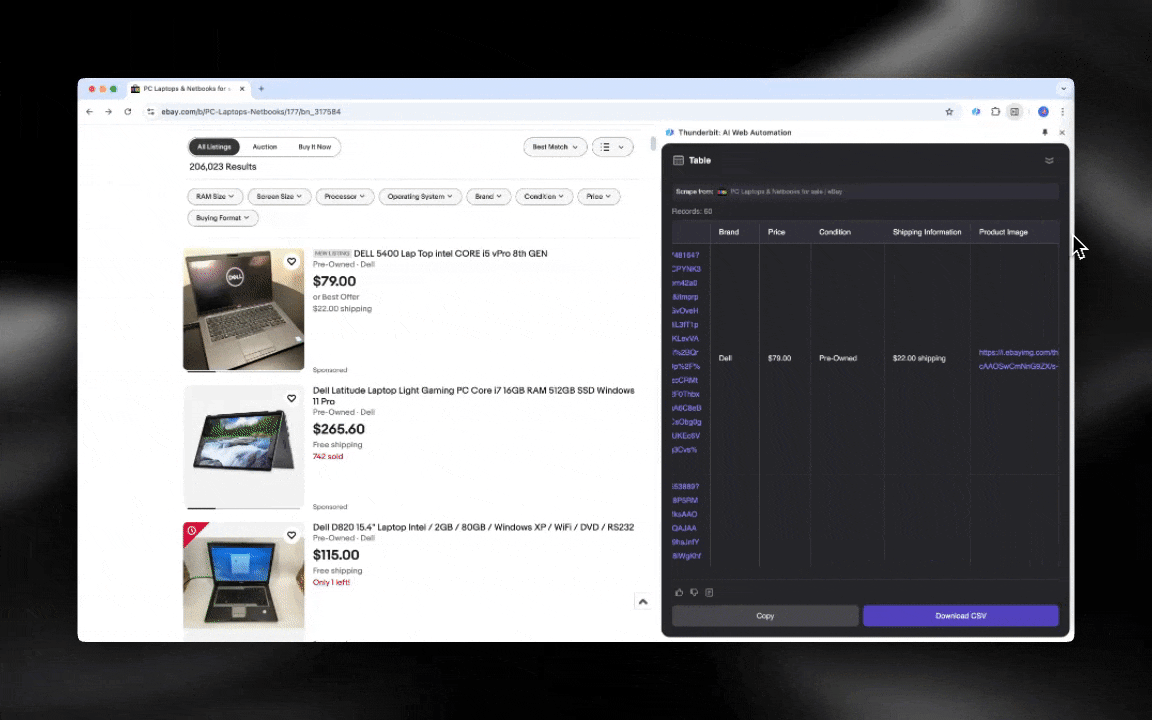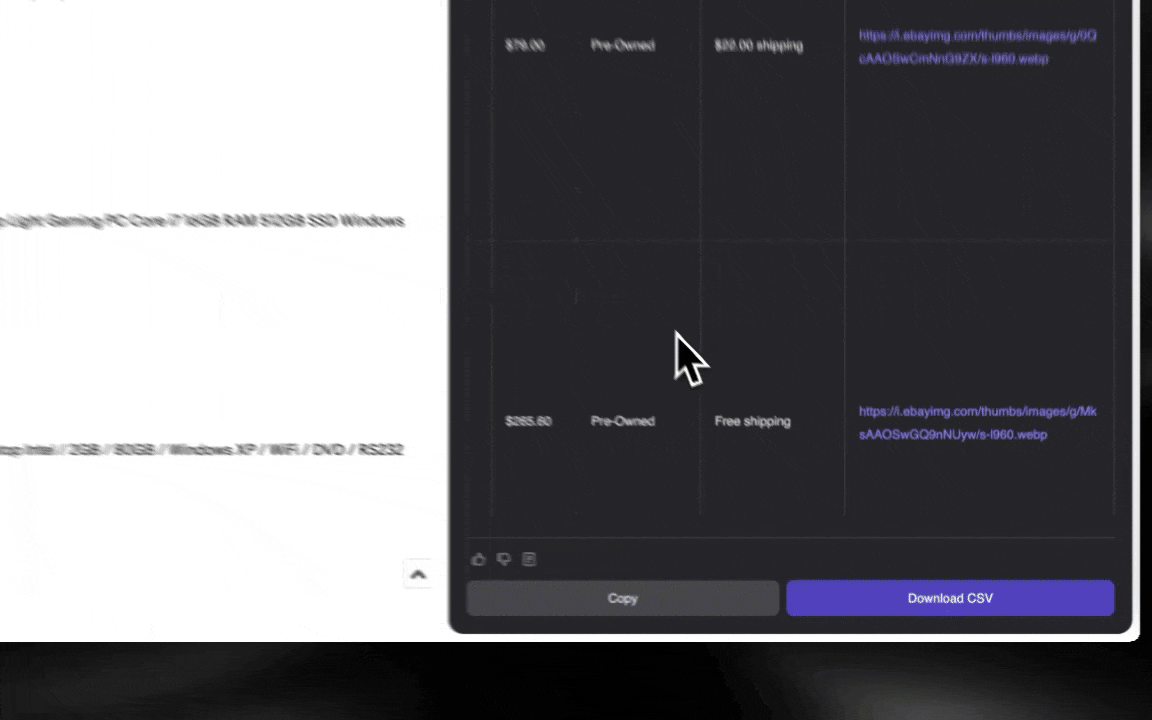 AI-webbskraparen är enkel att komma igång med och ger dig detaljerad data på bara några klick!
AI-webbskraparen är enkel att komma igång med och ger dig detaljerad data på bara några klick!
Vilken ska du välja? Det beror på. Om du är bekväm med att pilla med kod eller behöver samla in stora mängder data från en populär webbplats kan traditionella skrapare vara mycket effektiva. Men om du är ny inom webbskrapning eller vill ha något som hänger med när webbplatsen uppdateras är AI-webbskrapare oftast det bättre valet. Kolla tabellen nedan för mer detaljerade scenarier!
| Scenario | Bästa val |
|---|---|
| Lätt skrapning på sidor som kataloger, shoppingwebbplatser eller vilken webbplats som helst med en lista | AI Web Scraper |
| Sidan innehåller färre än 200 rader data, och att bygga en skrapare med en traditionell webbskrapare tar för lång tid | AI Web Scraper |
| Data du behöver skrapa måste ha ett visst format för att laddas upp någon annanstans. Till exempel: skrapa kontaktuppgifter för att ladda upp till HubSpot. | AI Web Scraper |
| Webbplatser som används i stor skala, till exempel tiotusentals Amazon-produktsidor eller Zillow-objektlistningar. | Traditionell Web Scraper |
De bästa webbskrapningsverktygen och programvarorna i korthet
| Verktyg | Prissättning | Nyckelfunktioner | Fördelar | Nackdelar |
|---|---|---|---|---|
| Thunderbit | Från 9 USD/månad, gratisnivå finns | AI-webbskrapare, identifierar och formaterar data automatiskt, stöd för flera format, export med ett klick, användarvänligt gränssnitt. | Kodfritt, AI-stöd, integrationer med appar som Google Sheets | Storskalig skrapning kan vara långsam, avancerade funktioner kan kosta mer |
| Browse AI | Från 48,75 USD/månad, gratisnivå finns | No-code-gränssnitt, övervakning i realtid, massutvinning av data, arbetsflödesintegration. | Användarvänligt, integrerar med Google Sheets och Zapier | Komplexa sidor kräver extra installation, massskrapning kan orsaka timeouts |
| Bardeen AI | Från 60 USD/månad, gratisnivå finns | No-code-automation, integreras med 130+ appar, MagicBox omvandlar uppgifter till arbetsflöden. | Omfattande integrationer, skalbart för företag | Brant inlärningskurva för nya användare, tidskrävande installation |
| Web Scraper | Gratis för lokal användning, 50 USD/månad för moln | Visuell skapandeprocess, stöd för dynamiska sajter (AJAX/JavaScript), molnskrapning. | Fungerar bra för dynamiska sajter | Kräver teknisk kunskap för bästa installation |
| Octoparse | Från 119 USD/månad, gratisnivå finns | No-code-skrapning, automatisk identifiering av sidkomponenter, molnskrapning med schemalagda uppgifter, mallbibliotek för vanliga webbplatser. | Kraftfulla funktioner för dynamiska sajter, hanterar begränsningar | Komplexa sajter kräver inlärning |
| Diffbot | Från 299 USD/månad | API för datautvinning, regel-fritt API, NLP för ostrukturerad text, omfattande kunskapsgraf. | Stark AI-utvinning, omfattande API-integration, storskalig skrapning | Inlärningskurva för icke-tekniska användare, uppsättning tar tid |
Den bästa webbskraparen i AI-eran
Thunderbit
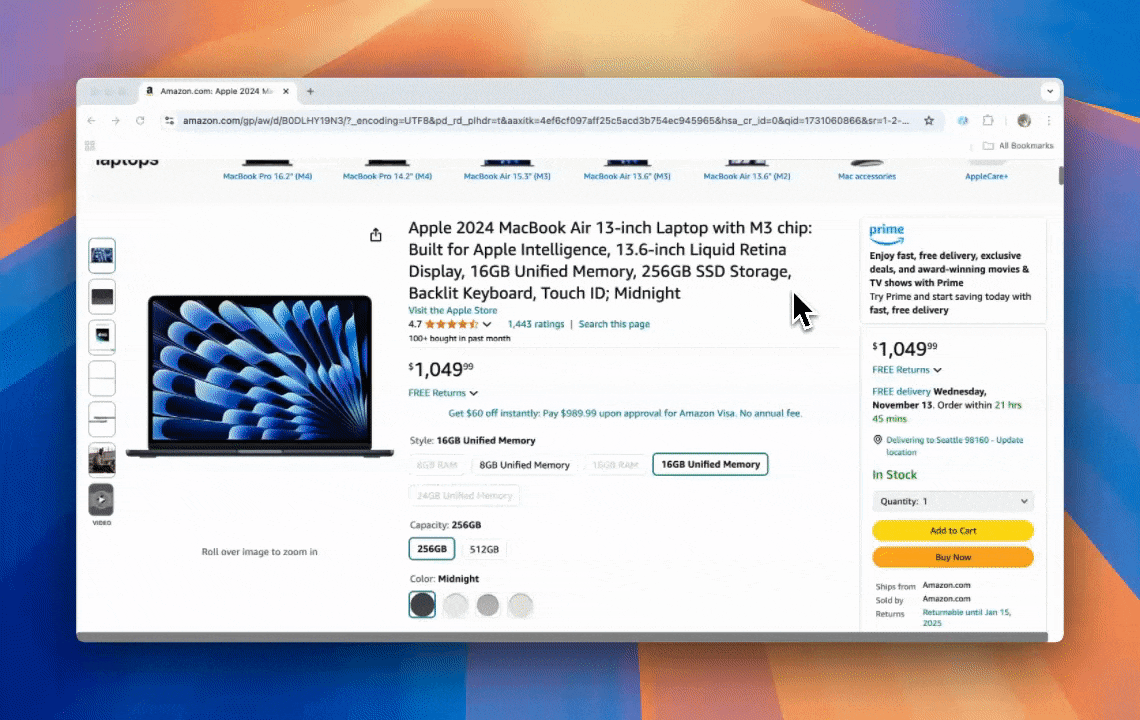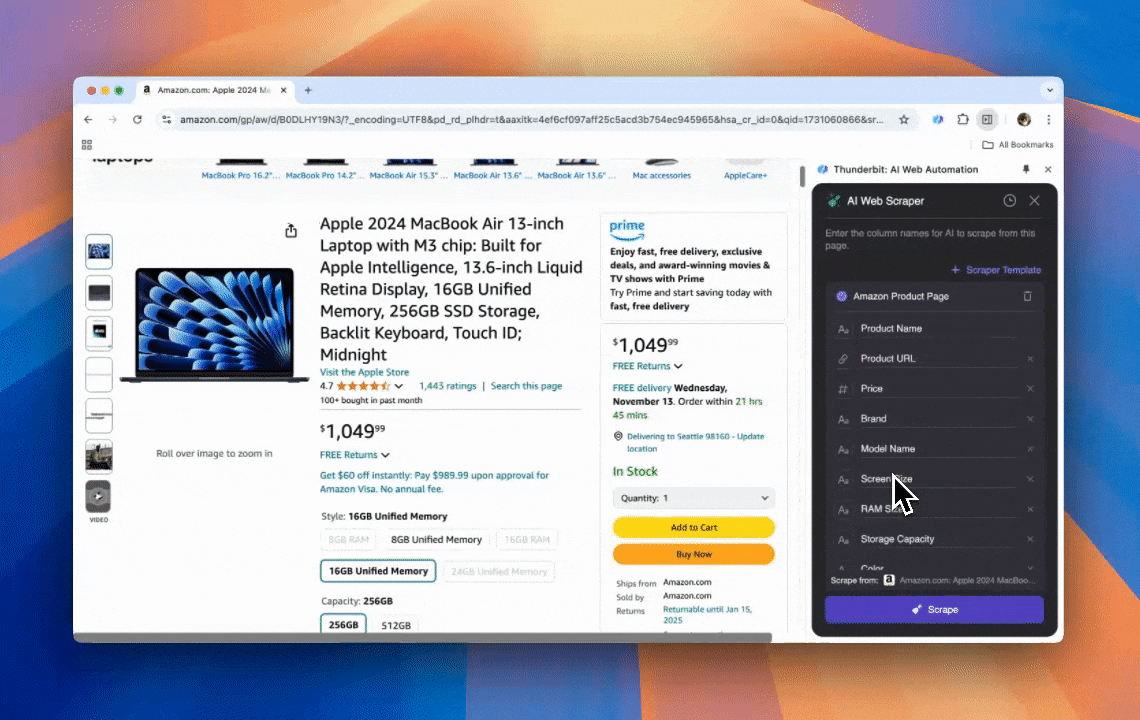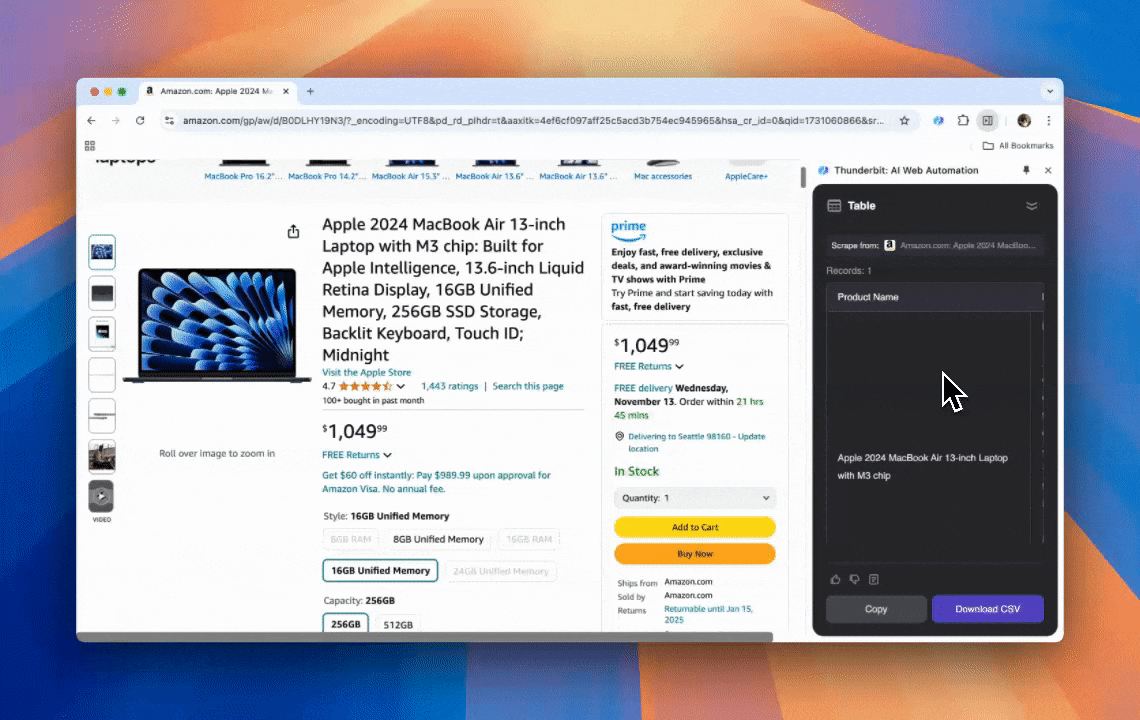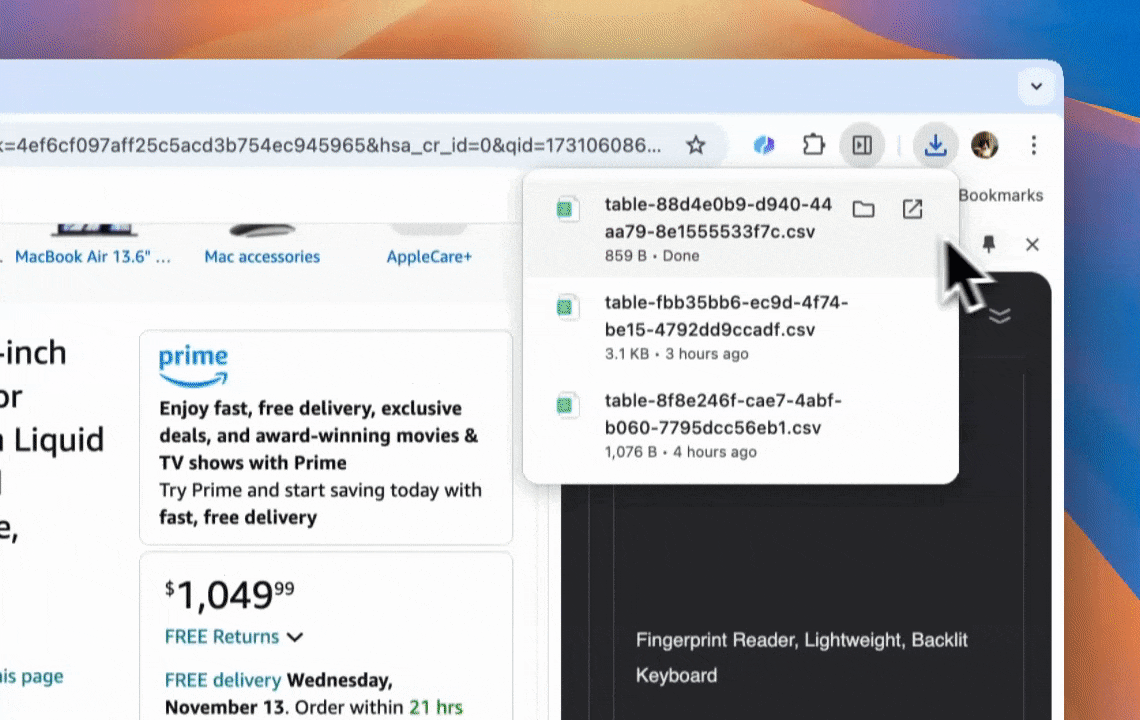
Thunderbit är ett kraftfullt och användarvänligt AI-verktyg för webbautomation som gör det enkelt för användare utan kodningskunskaper att extrahera och organisera data. Med sitt Chrome-tillägg förenklar Thunderbits AI Web Scraper dataskrapning — användare kan snabbt hämta webdata utan att manuellt interagera med webbelement eller sätta upp enskilda skrapare för olika sidlayouter.
Nyckelfunktioner
- AI-driven flexibilitet: Thunderbits AI Web Scraper identifierar och formaterar webdata automatiskt, vilket gör CSS-selectorer överflödiga.
- Enklaste möjliga skrapningsupplevelse: Allt du behöver göra är att klicka på “AI föreslå kolumn” och sedan klicka på “Skrapa” på sidan du vill extrahera från. Det är allt.
- Stöd för olika dataformat: Thunderbit kan skrapa URL:er, bilder och visa insamlad data i flera format.
- Automatiserad databehandling: Thunderbits AI kan omforma data direkt, inklusive att sammanfatta, kategorisera och översätta den till önskat format.
- Enkel dataexport: Exportera data till Google Sheets, Airtable eller Notion med ett klick, vilket förenklar databehandlingen.
- Användarvänligt gränssnitt: Ett intuitivt gränssnitt gör det tillgängligt för användare på alla nivåer.
Prissättning
Thunderbit erbjuder nivåindelade abonnemang, från 9 USD per månad för 5 000 krediter. Det går hela vägen upp till 199 USD för 240 000 krediter. För årsplanen får du dessutom alla krediter direkt på en gång.
Fördelar:
- Stark AI-support förenklar datautvinning och bearbetning.
- Kodfritt, tillgängligt för användare på alla kunskapsnivåer.
- Perfekt för lättare skrapning, till exempel kataloger, shoppingwebbplatser med mera.
- Hög integrationsförmåga för direkt export till populära appar.
Nackdelar:
- Storskalig dataskrapning kan ta lite tid för att säkerställa noggrannhet.
- Vissa avancerade funktioner kan kräva en betalprenumeration.
Vill du ha mer information? Börja med att installera Thunderbit, eller upptäck hur du enkelt skrapar webbplatser med Thunderbit.
Bästa webbskraparen för dataövervakning och massutvinning
Browse AI
Browse AI är ett robust no-code-verktyg för dataskrapning som är utformat för att hjälpa användare att extrahera och övervaka data utan att skriva någon kod. Browse AI har vissa AI-funktioner, men det är inte riktigt på nivån av renodlad AI-skrapning. Med det sagt gör det ändå starten enklare för användare.
Nyckelfunktioner
- No-code-gränssnitt: Gör det möjligt för användare att skapa anpassade arbetsflöden med enkla klick.
- Övervakning i realtid: Använder botar för att följa ändringar på webbsidor och leverera uppdaterad information.
- Massutvinning av data: Kan hantera upp till 50 000 dataposter på en gång.
- Arbetsflödesintegration: Kopplar ihop flera botar för mer komplex databehandling.
Prissättning
Från 48,75 USD per månad, inklusive 2 000 krediter. En gratisnivå finns med 50 krediter per månad för att prova de grundläggande funktionerna.
Fördelar:
- Erbjuder integrationer med Google Sheets och Zapier.
- Förbyggda botar förenklar vanliga uppgifter för datautvinning.
Nackdelar:
- Kan kräva extra konfiguration för komplexa sidor.
- Hastigheten vid massskrapning kan variera, vilket ibland leder till timeouts.
Bästa webbskraparen för arbetsflödesintegration
Bardeen AI
Bardeen AI är ett no-code-automationsverktyg som är utformat för att effektivisera arbetsflöden genom att koppla ihop olika appar. Även om det använder AI för att skapa anpassad automation saknar det den anpassningsförmåga som ett fullt AI-skrapverktyg har.
Nyckelfunktioner
- No-code-automation: Låter användare sätta upp arbetsflöden med klick.
- MagicBox: Beskriver uppgifter på vanligt språk, som Bardeen AI omvandlar till arbetsflöden.
- Breda integrationsmöjligheter: Integreras med över 130 appar, inklusive Google Sheets, Slack och LinkedIn.
Prissättning
Från 60 USD per månad, med 1 500 krediter (ungefär 1 500 rader data). En gratisnivå erbjuder 100 krediter per månad för att prova grundfunktionerna.
Fördelar:
- Omfattande integrationsmöjligheter stödjer många olika affärsbehov.
- Flexibelt och skalbart för företag i alla storlekar.
Nackdelar:
- Nya användare kan behöva tid för att lära sig hela plattformen.
- Den inledande installationen kan vara tidskrävande.
Bästa visuella webbskraparen för dig med erfarenhet
Web Scraper
Ja, du hörde rätt: verktyget heter "Web Scraper". Web Scraper är ett populärt webbläsartillägg för Chrome och Firefox som låter användare extrahera data utan kodning och erbjuder ett visuellt sätt att skapa skrapuppgifter. Du kan dock behöva lägga några dagar på att titta på och lära dig av handledningarna ovan för att verkligen behärska verktyget. Om du vill göra skrapning lätt för hjärnan, välj AI Web Scraper.
Nyckelfunktioner
- Visuell skapelse: Låt användare ställa in skrapuppgifter genom att klicka på webbelement.
- Stöd för dynamiska webbplatser: Kan hantera AJAX-begäranden och JavaScript för dynamiska sajter.
- Molnskrapning: Schemalägg uppgifter via Web Scraper Cloud för periodisk skrapning.
Prissättning
Gratis för lokal användning; betalda planer börjar på 50 USD/månad för molnfunktioner.
Fördelar:
- Fungerar bra för dynamiska sajter.
- Gratis för lokal användning.
Nackdelar:
- Kräver teknisk kunskap för optimal installation.
- Komplex testning krävs vid ändringar.
Bästa webbskraparen för att undvika IP-blockering och bottillämpad upptäckt
Octoparse
Octoparse är en mångsidig programvara för mer tekniska användare som vill samla in och övervaka specifik webdata utan kod, idealisk för stora databehov. Octoparse förlitar sig inte på användarens webbläsare för att fungera, utan använder molnservrar för dataskrapning. Därför kan den erbjuda olika metoder för att kringgå IP-blockering och viss bottäckning på webbplatser.
Nyckelfunktioner
- No-code-användning: Användare kan skapa skrapuppgifter utan att skriva kod, vilket gör verktyget tillgängligt för användare med olika teknisk nivå.
- Smart autodetektering: Identifierar automatiskt siddata, hittar snabbt element som kan skrapas och förenklar installationen.
- Molnskrapning: Stöd för molnbaserad dataskrapning dygnet runt med schemalagda skrapuppgifter för flexibel datainsamling.
- Omfattande mallbibliotek: Erbjuder hundratals förinställda mallar, så att användare snabbt kan hämta data från populära webbplatser utan komplicerad installation.
Prissättning
Octoparses prisplan börjar på 119 USD per månad och inkluderar 100 uppgifter. En gratisnivå med 10 uppgifter per månad finns också för att testa grundfunktionerna.
Fördelar:
- Kraftfulla funktioner stödjer skrapning av dynamiska sajter med hög anpassningsförmåga.
- Erbjuder lösningar för att hantera skrapningsbegränsningar och problem med dynamiskt innehåll.
Nackdelar:
- Komplexa webbplatsstrukturer kan kräva mer tid att sätta upp.
- Nya användare kan behöva tid för att lära sig använda verktyget.
Bästa webbskraparen för avancerat AI-drivet API för datautvinning
Diffbot
Diffbot är ett avancerat verktyg för webdatautvinning som använder AI för att omvandla ostrukturerat webb-innehåll till strukturerad data. Med kraftfulla API:er och en kunskapsgraf hjälper Diffbot användare att extrahera, analysera och hantera information från webben, lämpligt för olika branscher och användningsområden.
Nyckelfunktioner
- API för datautvinning: Diffbot erbjuder ett regel-fritt API för datautvinning, vilket gör att användare bara behöver ange en URL för automatisk datainsamling, utan att sätta upp egna regler för varje webbplats.
- API för naturlig språkbehandling: Extraherar strukturerade entiteter, relationer och sentiment från ostrukturerad text, vilket hjälper användare att bygga sina egna kunskapsgrafer.
- Kunskapsgraf: Diffbot har en av de största kunskapsgraferna och kopplar samman omfattande entitetsdata, inklusive uppgifter om individer och organisationer.
Prissättning
Diffbots prisplan börjar på 299 USD per månad och inkluderar 250 000 krediter (motsvarande ungefär 250 000 webbsidextraktioner via API).
Fördelar:
- Stark förmåga till regel-fri datautvinning med hög anpassningsförmåga.
- Omfattande API-integrationer för enkel anslutning till befintliga system.
- Stöd för storskalig dataskrapning, lämpligt för företagsanvändning.
Nackdelar:
- Den första installationen kan kräva viss inlärning för icke-tekniska användare.
- Användaren måste skriva ett program för att anropa API:t för att använda det.
Vad kan du använda skrapare till?
Om du är ny inom webbskrapning finns här några populära användningsområden som hjälper dig att komma igång. Många använder skrapare för att hämta Amazon-produktsidor, dra realtidsdata om fastigheter från Zillow eller samla in företagsuppgifter från Google Maps. Men det är bara början — du kan använda Thunderbits AI Web Scraper för att samla in data från nästan vilken webbplats som helst, effektivisera uppgifter och spara tid i ditt dagliga arbetsflöde. Oavsett om det gäller research, prisbevakning eller att bygga databaser öppnar webbskrapning upp mängder av sätt att få internetdata att arbeta för dig.
FAQ
-
Är webbskrapning lagligt?
Webbskrapning är vanligtvis laglig, men du måste följa webbplatsens användarvillkor och ta hänsyn till vilken typ av data som hämtas. Läs alltid igenom relevanta policyer och följ juridiska riktlinjer.
-
Behöver jag programmeringskunskaper för att använda webbskrapningsverktyg?
De flesta verktyg som tas upp här kräver inte programmeringskunskaper, men verktyg som Octoparse och Web Scraper kan fungera bättre om användaren har grundläggande förståelse för webbstrukturer och ett programmeringsmässigt tänk.
-
Finns det gratis webbskrapningsverktyg?
Ja, gratisverktyg som BeautifulSoup, Scrapy och Web Scraper finns tillgängliga, och vissa verktyg erbjuder också gratisplaner med begränsade funktioner.
-
Vilka är de vanligaste utmaningarna inom webbskrapning?
Vanliga utmaningar är att hantera dynamiskt innehåll, CAPTCHA, IP-blockering och komplexa HTML-strukturer. Avancerade verktyg och tekniker kan effektivt lösa dessa problem.
Läs mer:
Använd AI för att arbeta utan ansträngning. Get Started Free




