Mitt första försök med webbläsarautomatisering: sen kväll, kallt kaffe och ett kalkylark fullt av produktlänkar som jag fasade för att kopiera och klistra in. Det måste ha funnits ett bättre sätt.
Det finns det. Webbläsarautomatisering har gått från ett nischat utvecklartrick till ett viktigt affärsverktyg. Men webben blir hela tiden knepigare — sajter laddar innehåll dynamiskt, gömmer data bakom knappar och kastar upp popup-fönster hela tiden.
Här är 15 verktyg för webbläsarautomatisering som jag har testat — inklusive AI-webbscrapers som — anpassade för olika kunskapsnivåer och användningsområden.
Vad är webbläsarautomatisering? Lås upp kraften i webbautomatisering och webbscraping
Låt oss reda ut det: webbläsarautomatisering är helt enkelt programvara som efterliknar det du skulle göra i webbläsaren — klicka på länkar, fylla i formulär, scrolla, ladda ner filer — utan att du behöver lyfta ett finger. Tänk på det som din digitala assistent som outtröttligt upprepar de där webbarbetsuppgifterna du helst slipper göra själv ().
Webbscraping är en särskild form av webbläsarautomatisering, med fokus på att extrahera data från webbplatser och göra om den till något strukturerat — som ett kalkylark eller en databas — så att du faktiskt kan använda den. Inget mer copy-paste. Webbautomatisering är det bredare begreppet som omfattar båda: det handlar om att automatisera all interaktion med webbappar, från datauttag till formulärinlämning eller till och med hela arbetsflöden ().
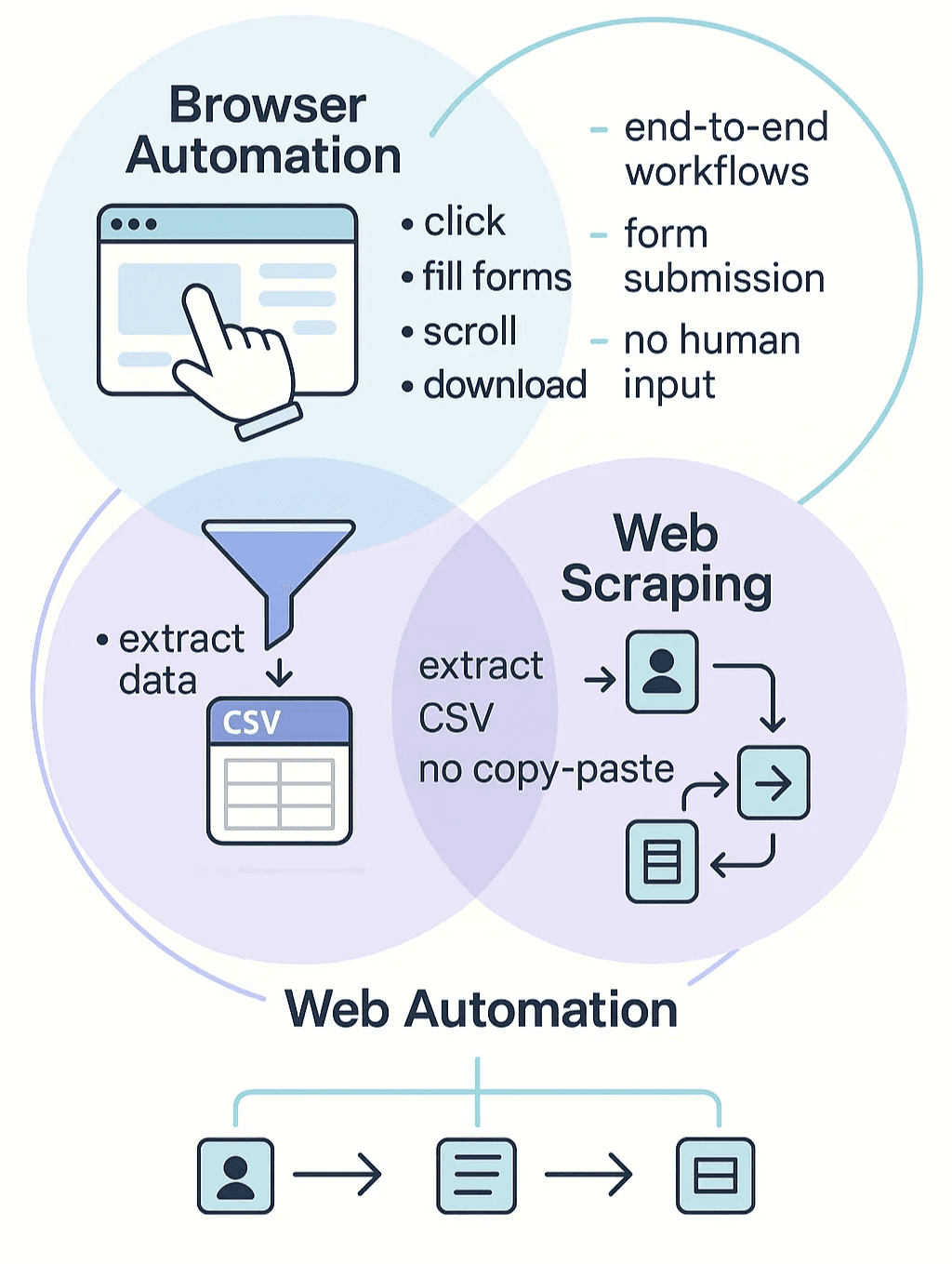
Varför är webbläsarautomatisering så viktigt just nu? Moderna webbplatser är dynamiska och tungt beroende av JavaScript. Innehåll laddas medan du scrollar, knappar visar dold information, och ibland måste du logga in eller klicka runt för att komma åt datan. Gamla scrapers som bara hämtar statisk HTML räcker inte till. Verktyg för webbläsarautomatisering styr en riktig webbläsare (ibland headless — utan gränssnitt), så de kan hantera allt detta dynamiska innehåll och simulera verkliga användaråtgärder ().
Kort sagt: webbläsarautomatisering är nyckeln till att extrahera data från och interagera med den moderna webben, särskilt när saker blir röriga.
Varför webbläsarautomatisering är viktigt för moderna företag
Låt oss prata affärsvärde. Webbläsarautomatisering och webbscraping är inte bara för tekniknördar — de är numera affärskritiska för sälj, e-handel, drift och i princip alla team som är beroende av webbaserad data.
Här är varför:
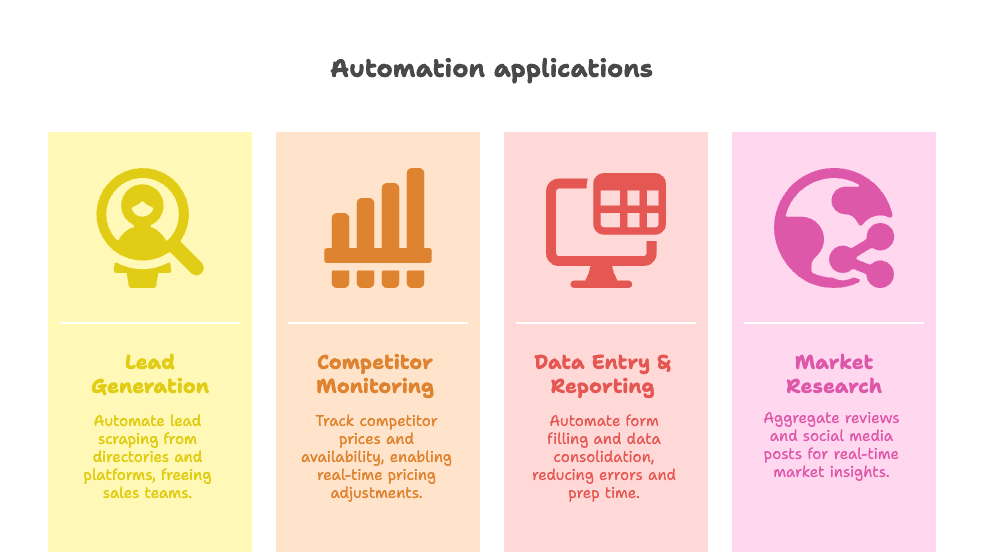
- Leadgenerering: Scrapa företagsregister, LinkedIn eller Google Maps efter nya leads medan du sover. Säljteam som använder automatisering rapporterar att de lägger 82 % mer tid på att faktiskt sälja, inte på att jaga kontaktuppgifter ().
- Övervakning av konkurrenter och prisuppföljning: E-handelsteam använder botar för att dagligen bevaka konkurrenters priser och produkttillgänglighet och justerar sina egna priser nästan i realtid ().
- Datainmatning och rapportering: Automatisera formulärifyllning, samla data från flera källor och eliminera mänskliga fel. Ett vårdföretag minskade manuell datainmatning med 60 % och kortade rapportförberedelserna med 40 % ().
- Marknadsundersökningar: Samla recensioner, listningar eller inlägg i sociala medier för realtidsinsikter som vore omöjliga att samla in manuellt.
Och siffrorna bekräftar det:
- Nästan utgörs nu av botar — mycket av det är automatisering och scraping.
- använder webbscraping för att driva AI- och analysprojekt.
- under det första året är vanligt för investeringar i digital automatisering.
Här är en snabb tabell över vanliga affärsscenarier och fördelarna med webbläsarautomatisering:
| Affärsscenario | Fördel med automatisering |
|---|---|
| Leadgenerering | Bygger snabbt leadlistor och frigör säljare till att stänga affärer |
| Prisuppföljning | Marknadsöverblick i realtid, dynamisk prissättning, snabb reaktion på konkurrentförändringar |
| Datainmatning och rapportering | Eliminerar tråkig copy-paste, minskar fel och håller data uppdaterad |
| Marknadsundersökningar och konkurrensanalys | Samlar stora datamängder för insikter och stödjer datadriven strategi |
Kort sagt: webbläsarautomatisering är hur moderna företag håller sig snabba, korrekta och konkurrenskraftiga.
Kategorier av verktyg för webbläsarautomatisering: från AI-webbscraper till kodfria lösningar
Alla verktyg för webbläsarautomatisering är inte skapade lika. Beroende på din bakgrund och dina behov vill du välja mellan fyra huvudkategorier:
- Utvecklarverktyg: För dig som älskar att koda (tänk Selenium, Puppeteer, Playwright, Cypress). Maximal flexibilitet, men du behöver programmeringskunskaper.
- Kodfria/lågkodsplattformar: Visuella byggare och inspelare (som Browserflow, Axiom.ai, UI Vision) som låter icke-tekniska användare automatisera uppgifter genom att klicka runt eller dra block.
- RPA-sviter för företag: Tunga plattformar (UiPath, Automation Anywhere, Microsoft Power Automate) som är byggda för storskalig, end-to-end affärsprocessautomatisering.
- AI-drivna lösningar: De nya spelarna på plan — verktyg som som använder AI för att “läsa” webbsidor, anpassa sig till förändringar och låter dig automatisera med bara ett par klick eller vanliga svenska instruktioner.
Varje kategori har sina styrkor. Utvecklare får full kontroll, affärsanvändare får snabbhet och enkelhet, och AI-drivna verktyg bygger bron däremellan — så att kraftfull automatisering blir tillgänglig för alla.
Thunderbit: AI-webbscraper för alla
Jag ska vara ärlig: jag är partisk, men av goda skäl. är verktyget jag önskar att jag hade haft för flera år sedan. Det är ett AI-drivet Chrome-tillägg som låter vem som helst — ja, även om du inte kan ett skvatt kod — extrahera strukturerad data från vilken webbplats som helst på bara två klick.
Därför utmärker sig Thunderbit:
- AI Suggest Fields: Klicka bara på “AI Suggest Fields” så läser Thunderbit sidan, rekommenderar de bästa kolumnerna och sätter upp scrapern åt dig.
- Scraping av undersidor: Behöver du mer information? Thunderbit kan automatiskt besöka varje undersida (som produkt- eller profilsidor) och berika din datatabell.
- Schemalagd scraping: Ställ in det och glöm det. Schemalägg körningar med intervall — perfekt för prisövervakning, lagerkontroller eller återkommande leaduttag.
- Omedelbara mallar för dataextrahering: För populära sajter som Amazon, Zillow eller Instagram väljer du bara en mall och exporterar data med ett klick.
- Gratis dataexport: Ladda ner resultaten som CSV, Excel eller skicka dem direkt till Google Sheets, Airtable eller Notion — ingen betalvägg för export.
- AI-baserad datatransformering: Sammanfatta, kategorisera, översätt eller omforma data medan du scraper — AI gör grovjobbet ().
Vem passar det för? Säljteam, e-handelsansvariga, mäklare, marknadsförare — i princip alla som behöver webbaserad data men inte vill brottas med kod eller sköra gamla scrapers.
Det jag gillar: Thunderbit anpassar sig efter webbplatsändringar (inga fler trasiga skript), klarar sidor med mycket JavaScript och gör scraping lika enkelt som att beställa takeout. Dessutom är det gratis att prova, och betalplanerna börjar på bara 9 dollar i månaden (). Om du vill se det i praktiken, kolla in eller läs fler tips på .
Selenium: det klassiska ramverket för webbläsarautomatisering
Selenium är webbläsarautomatiseringens urfader — tänk på det som den schweiziska armékniven för utvecklare och QA-ingenjörer. Det är open source, stöder alla större webbläsare och låter dig skriva skript i Java, Python, C#, JavaScript och mer.

Styrkor:
- Fungerar i flera webbläsare och på flera plattformar: Fungerar överallt, integreras med CI/CD och är ryggraden i många automatiserade testsviter.
- Moget ekosystem: Massor av plugins, molnbaserade grid-leverantörer och stöd från communityn.
- Gratis och open source: Inga licenskostnader.
Begränsningar: Kräver programmeringskunskaper, kan vara knepigt att underhålla (särskilt när webbplatser ändras) och är inte det snabbaste valet för riktigt stora scrapingjobb. Men om du är utvecklare eller QA-proffs är Selenium fortfarande ett verktyg du bör känna till.
Puppeteer: headless webbläsarautomatisering för webbscraping
Puppeteer, från Google, är ett Node.js-bibliotek som styr Chrome eller Chromium — headless som standard. Det är en favorit bland utvecklare som vill automatisera Chrome, scrapa dynamiskt innehåll eller generera PDF:er och skärmdumpar.
Styrkor:
- Modernt JavaScript-API: Enkelt att skriva komplexa webbläsaruppgifter.
- Headless-läge: Snabbt och resurssnålt för scraping eller testning.
- Bra för dynamiska sajter: Hanterar sidor med mycket JavaScript utan problem.
Begränsningar: Främst för JavaScript/Node.js-användare och fokuserar på Chrome/Chromium (stöd för Firefox förbättras). Om du behöver Safari eller Edge, titta på Playwright.
Playwright: automatisering över flera webbläsare för moderna webbappar
Playwright, från Microsoft, är den nya stjärnan med ordentlig kraft under huven. Det stöder Chromium, Firefox och WebKit (Safaris motor) med ett enda API och fungerar i JavaScript, Python, Java och .NET.

Styrkor:
- Äkta automatisering över flera webbläsare: Ett skript, alla webbläsare.
- Auto-wait och hög tillförlitlighet: Minskar instabila tester och scrapingfel.
- Bra felsökningsverktyg: Inspector, trace viewer och codegen.
Begränsningar: Lite yngre ekosystem än Selenium, men tar snabbt igen avståndet. Om du startar ett nytt projekt är Playwright ett fantastiskt val.
Cypress: strömlinjeformad webbautomatisering och testning
Cypress är ett utvecklarvänligt end-to-end-testverktyg byggt för moderna webbappar. Det kör tester i webbläsaren, erbjuder felsökning i realtid och är älskat av front-end-team.
Styrkor:
- Allt-i-ett testkörning: Visuellt, interaktivt och snabbt.
- Automatiska väntetider: Färre instabila tester, mindre manuellt timingkodande.
- Bra för SPA:er: Hanterar asynkt beteende smidigt.
Begränsningar: Har historiskt varit Chrome-fokuserat (stöder nu Firefox/WebKit), och är inte byggt för scraping eller arbetsflöden med flera flikar. Bäst för att testa dina egna appar, inte för att scrapa tredjepartssajter.
Kodfria och lågkodade verktyg för webbläsarautomatisering
Browserflow
Browserflow är ett Chrome-tillägg som låter dig bygga automatiseringsflöden visuellt — ingen kod krävs. Klicka runt, spela in dina handlingar, justera steg och automatisera uppgifter som scraping, formulärifyllning eller datainmatning.
Höjdpunkter:
- Visuell flödesbyggare: Dra och släpp steg, lägg till loopar eller villkor.
- Integration med Google Sheets: Exportera data direkt till Sheets.
- Molnschemaläggning: Kör flöden enligt schema (betalplaner).
Perfekt för icke-tekniska användare som vill automatisera repetitiva webbuppgifter utan att behöva störa IT.
Axiom.ai
Axiom.ai är ett annat kodfritt Chrome-tillägg med fokus på automatisering av affärsprocesser (). Bygg botar steg för steg, integrera med Google Sheets, API:er och till och med Zapier.
Höjdpunkter:
- Gränssnitt för att bygga botar: Sätt ihop åtgärder visuellt.
- Förbyggda mallar: Kom igång snabbt med vanliga arbetsflöden.
- Molnschemaläggning och integrationer: Automatisera över webbappar.
Perfekt för driftteam eller alla som vill automatisera dataöverföringar och webbuppgifter utan att skriva kod.
UI Vision, Browser Automation Studio, TagUI
- UI Vision: Open source-webbläsartillägg med kommandon i Selenium IDE-stil och visuell automatisering (bildigenkänning, OCR). Gratis, plattformsoberoende och kan till och med automatisera skrivbordsappar.
- Browser Automation Studio: Windows-app med ett visuellt skript-IDE, multitrådning och möjlighet att kompilera fristående botar. Kraftfullt, men med en brantare inlärningskurva.
- TagUI: Open source-verktyg för RPA via kommandorad som låter dig skriva automatiseringsskript på enkel engelska (eller andra språk). Bra för teknikvana användare som vill ha en gratis och flexibel lösning.
RPA-verktyg i företagsklass
UiPath
UiPath är en tung RPA-plattform för att automatisera allt från webbläsaruppgifter till skrivbordsappar. Visuell arbetsflödesdesigner, AI-datorseende och robust orkestrering gör den till en favorit bland stora organisationer.
Styrkor: Företagsskala, stark community, stöder både övervakad och oövervakad automatisering.
Begränsningar: Dyrt och med en inlärningskurva för avancerade funktioner. Bäst för företag med stora automatiseringsambitioner.
Automation Anywhere
En annan toppmodern RPA-svit, Automation Anywhere erbjuder moln-först-automatisering, en visuell botbyggare och stark integration med affärsappar ().
Styrkor: Användarvänlig, molnbaserad, bra för både front-office- och back-office-automatisering.
Begränsningar: Liknande kostnad och komplexitet som UiPath, men ett stabilt val för företag.
Microsoft Power Automate
Om du redan finns i Microsofts ekosystem ger Power Automate webbläsar- och skrivbordsautomatisering till användare av Office 365 ().
Styrkor: Tät integration med Microsofts appar, prisvärt för befintliga kunder och lätt för affärsanvändare.
Begränsningar: Windows-centrerat, mindre moget för avancerade RPA-funktioner, men förbättras snabbt.
BrowserStack Automate
BrowserStack Automate är inte en skriptbyggare — det är en molnplattform för att köra dina Selenium-, Playwright- eller Cypress-skript på tusentals kombinationer av webbläsare och enheter ().
Styrkor: Enorm täckning, parallell testkörning, ingen infrastruktur att underhålla.
Begränsningar: Inte för att bygga automatiseringar, men avgörande för testning över flera webbläsare i stor skala.
Så väljer du det bästa verktyget för webbläsarautomatisering för dina behov
Att välja rätt verktyg kan kännas som att välja ny telefon — alla har en åsikt, och det beror på vad du faktiskt behöver. Så här brukar jag gå till väga steg för steg:
- Definiera målet: Ska du scrapa data, automatisera affärsprocesser eller testa webbappar?
- Bedöm teamets kompetens: Utvecklare? Välj kodbaserade verktyg. Affärsanvändare? Välj kodfria eller AI-drivna verktyg som Thunderbit.
- Tänk på komplexitet: Enkel scraping? Testa Thunderbit eller Browserflow. Komplexa arbetsflöden mellan flera appar? Titta på UiPath eller Power Automate.
- Kontrollera webbläsarkompatibilitet: Behöver du stöd för flera webbläsare? Playwright eller Selenium. Räcker Chrome? Puppeteer, Cypress eller de flesta kodfria verktyg.
- Tänk på skala: För riktigt stora jobb skalar kodbaserade verktyg eller företags-RPA bäst. För medelstora behov räcker webbläsartillägg gott.
- Budget: Open source-verktyg är gratis men kräver mer uppsättning. Kodfria och AI-verktyg är prisvärda för små och medelstora företag. RPA-sviter är en investering.
Här är en snabb jämförelse:
| Verktygskategori | Användarvänlighet | Funktioner och kraft | Ideala användare |
|---|---|---|---|
| Kodbaserade ramverk | Brant inlärning | Maximal flexibilitet | Utvecklare, QA-ingenjörer |
| Kodfria verktyg | Väldigt enkla | Måttlig komplexitet | Affärsanvändare, analytiker |
| Företags-RPA | Medel (utbildning krävs) | End-to-end-automatisering | Stora organisationer, RPA-team |
| AI-drivna verktyg | Enklast | Smart, anpassningsbar scraping | Sälj, drift, icke-tekniska användare |
Framtida trender inom webbläsarautomatisering, webbscraping och AI-webbscraperteknik
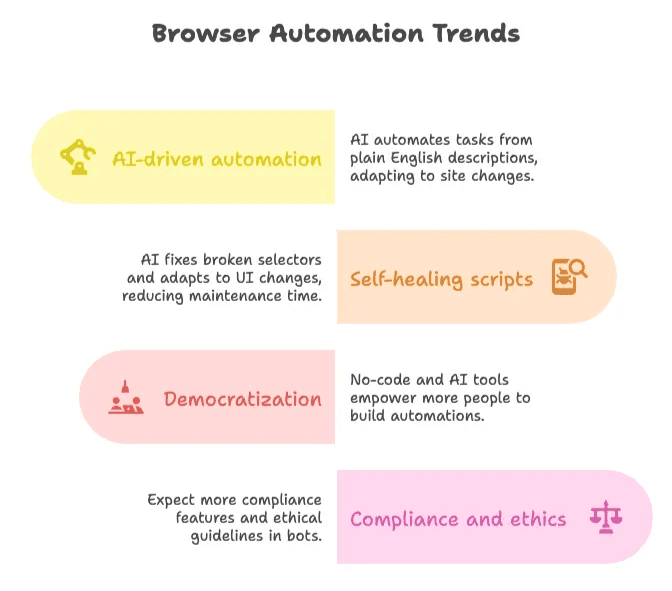
- AI-driven automatisering: Verktyg som Thunderbit leder vägen genom att låta användare beskriva uppgifter på vanligt språk och automatiskt anpassa sig till webbplatsförändringar ().
- Självläkande skript: AI kan nu laga trasiga selectors och anpassa sig till gränssnittsförändringar, vilket kan minska underhållstiden med upp till 50 % ().
- Demokratisering: Fler “citizen developers” bygger sina egna automatiseringar tack vare kodfria och AI-drivna verktyg ().
- Efterlevnad och etik: När botar blir vanligare kan du förvänta dig fler inbyggda funktioner för efterlevnad och tydligare etiska riktlinjer ().
Kort sagt: webbläsarautomatisering blir bara kraftfullare och mer användarvänlig. Om du inte automatiserar än så lämnar du tid och pengar på bordet.
Slutsats: växla upp verksamheten med rätt verktyg för webbläsarautomatisering
Webbläsarautomatisering är inte bara en tekniktrend — det är ryggraden i moderna, datadrivna företag. Oavsett om du driver ensamföretag eller ingår i ett Fortune 500-bolag kan rätt verktyg spara timmar, öka noggrannheten och låsa upp insikter du aldrig trodde var möjliga.
Mitt råd? Börja smått. Välj ett verktyg från den här listan — om du vill ha den enklaste och mest träffsäkra webbscraping utan kod är en fantastisk plats att börja på. Testa det på en riktig uppgift, se avkastningen själv och skala sedan upp i takt med att du växer.
Och kom ihåg: framtiden tillhör dem som automatiserar. Så plocka upp din digitala assistent, säg farväl till tråkigt webbjobb och låt oss återgå till det roliga.
Vanliga frågor
-
Vad är skillnaden mellan webbläsarautomatisering, webbscraping och webbautomatisering?
Webbläsarautomatisering efterliknar mänskliga handlingar i en webbläsare — klicka, scrolla och fylla i formulär. Webbscraping fokuserar på att extrahera strukturerad data (som tabeller) från webbplatser. Webbautomatisering är den bredare kategorin som omfattar båda och täcker alla uppgifter som automatiseras via en webbläsare — till exempel formulärinlämning, datainsamling eller hela arbetsflöden.
-
Varför investerar företag i webbläsarautomatisering?
För att det sparar tid, minskar fel och förbättrar resultaten. Säljteam scrapar leads, e-handel följer priser och drift automatiserar datainmatning. Studier visar 30–200 % ROI under första året, och 65 % av företagen använder webbaserad data för att driva AI- och analysprojekt.
-
Jag är inte utvecklare — kan jag ändå scrapa webbplatser?
Ja! Verktyg som är byggda för dig som inte kodar. Installera bara Chrome-tillägget, klicka på “AI Suggest Fields” så scrapar Thunderbit strukturerad data åt dig — även från dynamiska sidor. Det går snabbt, är träffsäkert och gratis att prova. Perfekt för sälj-, e-handels- och researchteam.
Läs mer: