Facebook-scraping är fortfarande värt att göra 2026, men bara om du väljer rätt insamlingsmodell. Pew Research Center rapporterade den 20 november 2025 att , och Meta sa den 29 april 2026 att deras i mars 2026. Den skalan gör Facebook användbart för bevakning av Marketplace, research på offentliga sidor, leadgenerering och konkurrentbevakning. Det svåra är inte att hitta användningsfall. Det svåra är att få ren data utan att fastna i inloggningsväggar, dynamisk laddning, tillfälliga blockeringar eller sköra scraping-upplägg.
Den här årliga shortlistan är byggd för snabbare beslut. Jag kontrollerade igen de officiella produktsidorna, dokumentationen och prissignalerna den 8 maj 2026 och höll sedan listan fokuserad på verktyg som fortfarande är relevanta för verkliga företagsanvändare. Om ditt arbetsflöde mest handlar om att ”hämta datan på den här sidan och skicka den till ett kalkylark”, börja med Thunderbit. Om du behöver infrastruktur i API-skala ligger Bright Data, Apify och Nimble by Nimbleway högt upp på listan. Om ditt jobb omfattar molnautomation eller uppföljande åtgärder efter insamling, förtjänar PhantomBuster en närmare titt.
Snabba val efter behov
- Behöver du den snabbaste no-code-exporten från Facebook eller Marketplace? Börja med .
- Behöver du API-skala för företag och hanterad upplåsning? Kortlista .
- Behöver du flexibla scraping-flöden i molnet? Titta närmare på .
- Behöver du API-först-insamling av offentliga webbsidor med mindre underhåll av scrapern? Överväg .
- Behöver du ett budgetvänligt API för mindre jobb? är fortfarande relevant.
- Behöver du scraping plus arbetsflödesautomation? är det bättre valet.
- Behöver du en visuell dra-och-släpp-byggare med schemaläggning? är fortfarande ett stabilt no-code-alternativ.
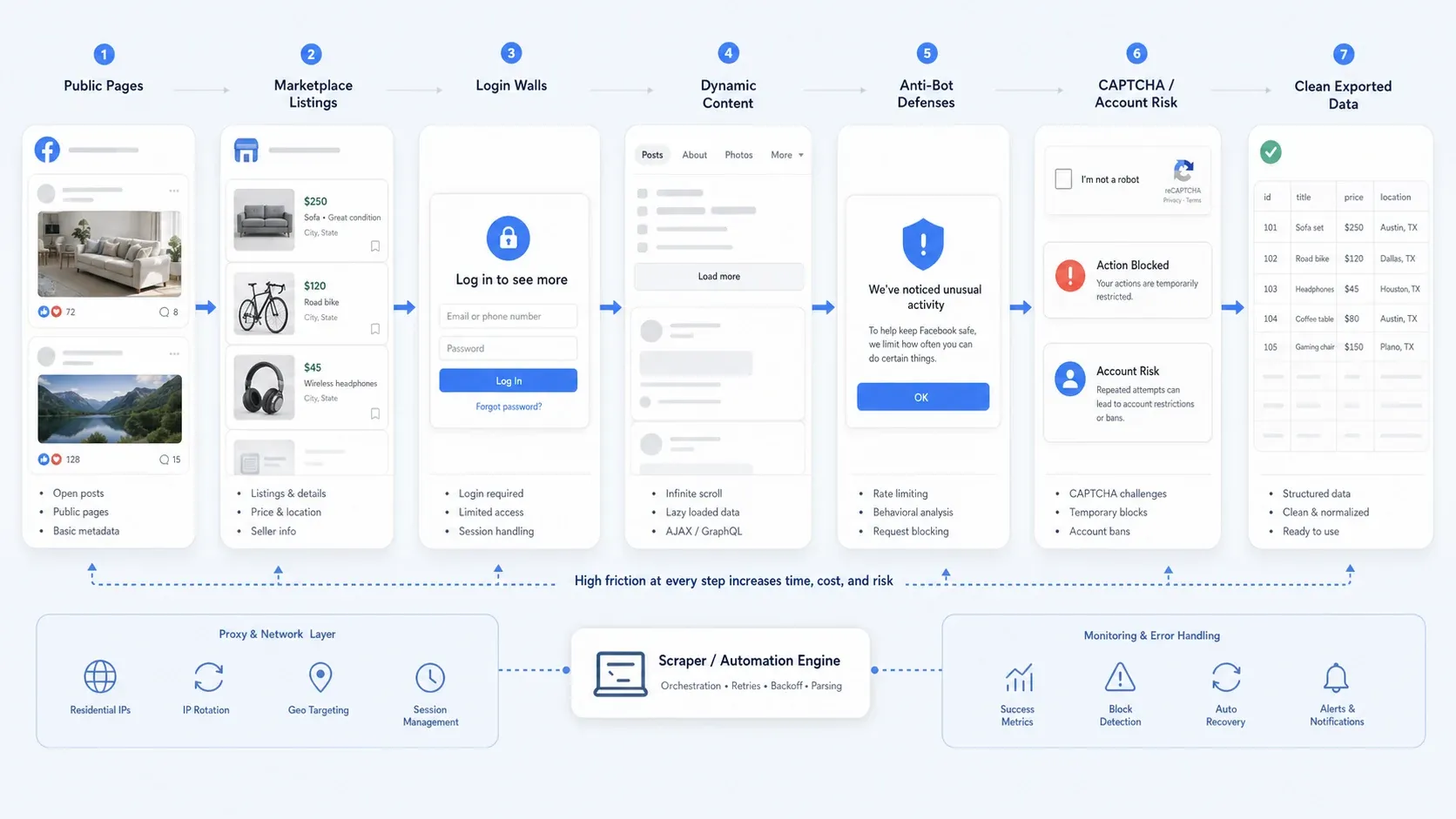
Varför Facebook-scraping fortfarande är svårt 2026
Insamling av Facebook-data handlar sällan bara om att hitta rätt selector längre. I praktiken stöter de flesta team på ett eller flera av de här problemen:
- Delvis offentlig åtkomst: Vissa sidor förblir offentliga, medan andra flöden styr dig mot inloggning för att se mer information.
- Dynamiskt innehåll: Marketplace-vyer, långa kommentarstrådar och sidinnehåll laddas ofta stegvis.
- Skydd mot botar: Hastighetsbegränsningar, beteendekontroller, CAPTCHA och tillfälliga åtgärdsblockeringar slår sönder naiv automation.
- Operativ risk: Insamling bakom inloggning är mycket mer riskfylld än scraping av offentliga sidor, särskilt om du bryr dig om kontosäkerhet och reproducerbarhet.
Så utvärderade jag verktygen
Jag optimerade den här sidan för att bygga en shortlist, inte för att fylla på med funktioner. Verktygen här jämfördes utifrån:
- Passform för arbetsflöden: Passar produkten faktiskt de Facebook- och Marketplace-insamlingsjobb som riktiga team gör?
- Användarvänlighet: Kan icke-utvecklare eller små team snabbt få fram användbart resultat?
- Skala och tillförlitlighet: Håller verktyget fortfarande måttet när du går från ett engångsscrape till återkommande körningar?
- Hantering av anti-bot och sessioner: Hur mycket infrastrukturkrångel tar produkten bort?
- Output-kvalitet: Kan du få strukturerad data till CSV, Sheets eller vidare system utan mycket städning?
- Prissignaler: Är produkten rimlig att utvärdera, eller kräver den en tung enterprise-säljprocess?
- Efterlevnadsinställning: Är verktyget tydligt inriktat på insamling av offentliga data och ansvarsfull användning?
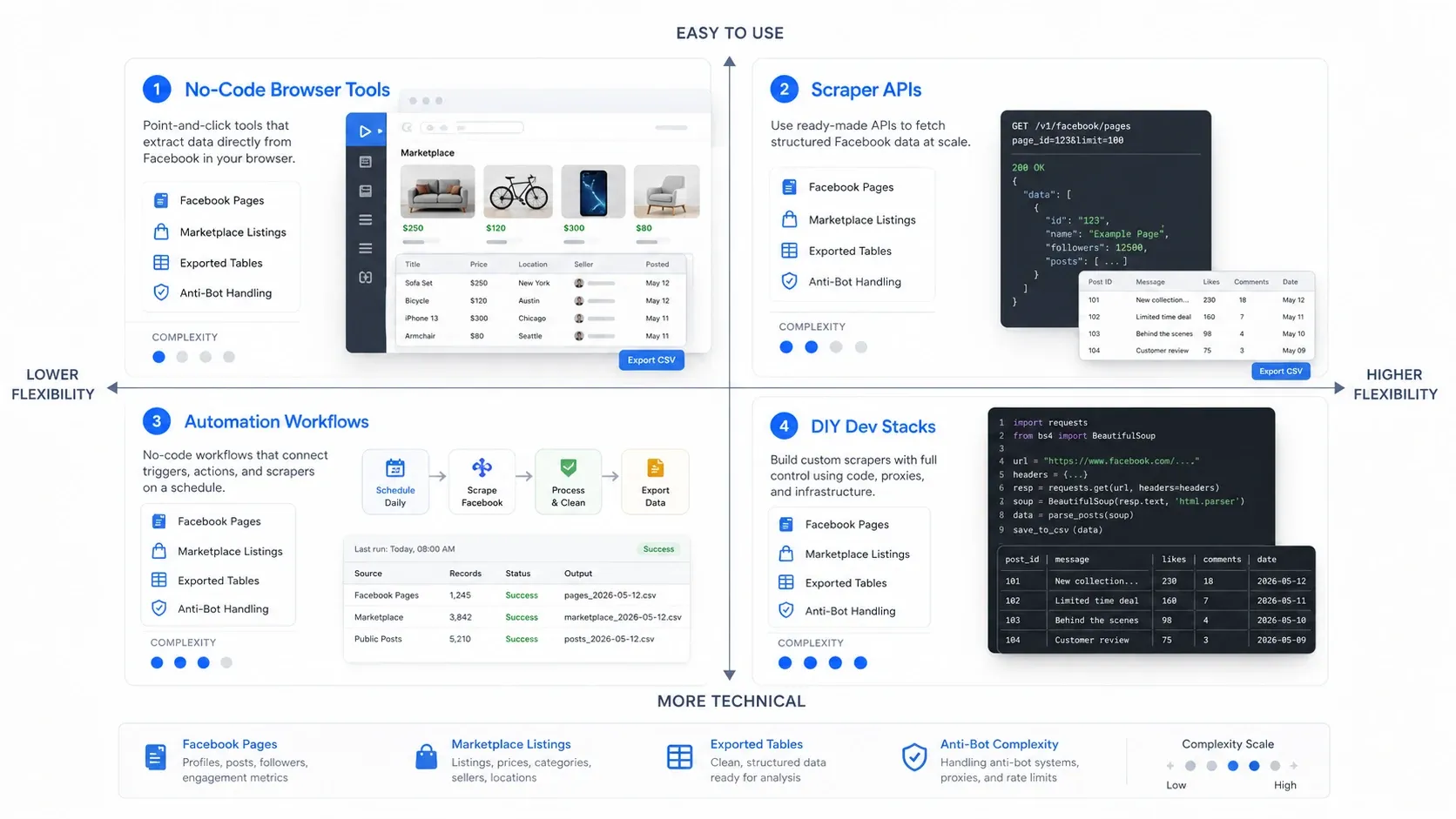
Vilken typ av Facebook-scraper behöver du?
Det snabbaste sättet att välja rätt är att först välja rätt kategori. Verktyg för Facebook-scraping brukar falla in i fyra driftmodeller:
- No-code-webbläsarverktyg: Bäst när du vill extrahera snabbt från sidan som redan är öppen framför dig.
- Scraper-API:er: Bäst när du behöver tillförlitlig, upprepad insamling i högre volym.
- Automationsflöden: Bäst när scraping bara är ett steg i en bredare go-to-market-process.
- Egenutvecklade dev-stackar: Bäst när ditt team vill ha maximal kontroll och är berett att äga underhållsbördan.
Jämförelsetabell
| Verktyg | Bäst för | Varför det kom med på listan | Prissignal |
|---|---|---|---|
| Thunderbit | Icke-tekniska team och snabba ad hoc-jobb | AI-baserad fältidentifiering, dynamisk sidhantering direkt i webbläsaren, snabba exporter | Gratis provperiod; kreditbaserade betalplaner |
| Bright Data | Storskaliga pipelines för offentliga sociala data | Dedikerade scraper-API:er för sociala medier, hanterad upplåsning, stark skala | Konsumtionsbaserad och enterprise-prissättning |
| Apify | Flexibla scraping-flöden i molnet | Färdiga Facebook-actors, schemaläggning, API-åtkomst, utrymme för anpassning | Betalda plattformspaket plus mätförbrukning |
| Nimble by Nimbleway | API-först-insamling av offentliga webbsidor | URL-först-API-flöde och mindre underhåll av scrapern | Säljstyrd prissättning |
| ScrapingBot | Mindre jobb med offentliga data och prototyper | Enkelt API, stöd för rendering, lägre ingångspris | Gratis nivå; betalplaner från cirka 22 USD/månad |
| PhantomBuster | GTM-automationsflöden | Molnautomationer, webbläsarbaserade arbetsflöden, bra för leadgenerering | Gratis provperiod; betalplaner från cirka 56 USD/månad |
| Octoparse | Visuell schemalagd no-code-scraping | Byggare med peka-och-klicka, molnextraktion, återkommande flöden | Gratis plan; betalplaner från cirka 119 USD/månad |
1. Thunderbit
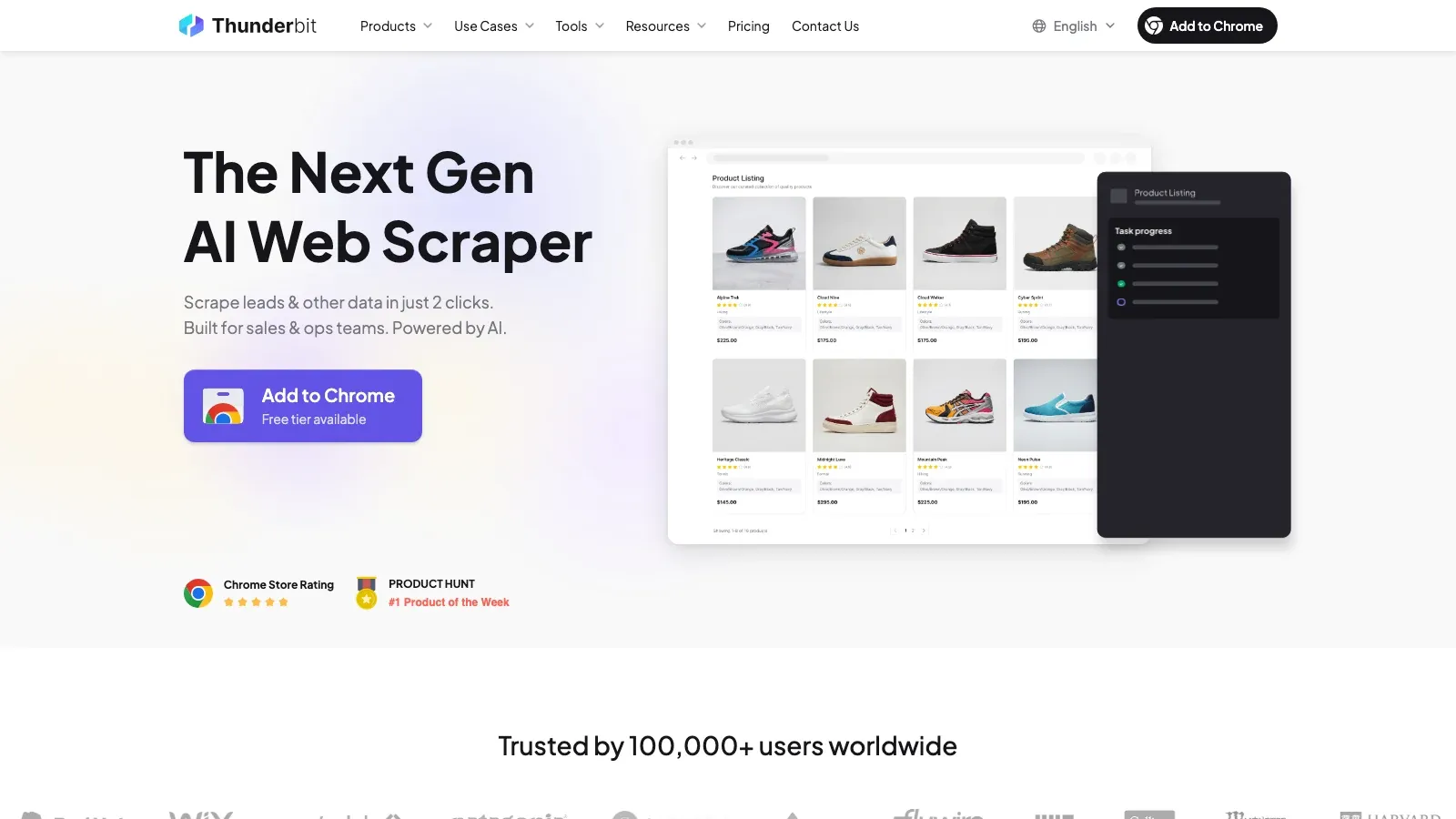
är det starkaste valet här om målet är att snabbt omvandla en Facebook-sida eller en Marketplace-resultatlista till strukturerad data utan att bygga eller underhålla en scraper. Den främsta fördelen är semantisk extraktion: den läser sidan, föreslår användbara fält och låter dig exportera resultatet utan att du behöver hantera selectors, proxies eller kod.
Det som gör att den sticker ut:
- AI Suggest Fields: Thunderbit identifierar sannolika fält som titel, pris, säljare, plats, kontaktuppgifter och URL:er.
- Hantering direkt i webbläsaren: Eftersom den kör där sidan renderas fungerar den bra på dynamiska sidor med mycket scrollning.
- Berikning av undersidor: Du kan först samla in listdata och sedan öppna varje annons eller sida för mer detaljerad information.
- Användbara exporter: Excel, Google Sheets, Airtable och Notion är alla naturliga mål.
Om du vill se ett videoexempel innan du själv testar ett webbläsarbaserat arbetsflöde är den här praktiska genomgången av Thunderbit den bästa utgångspunkten, eftersom den visar det faktiska extraktionsflödet i stället för att bara prata om funktioner:
Bäst för: icke-tekniska användare, säljteam, operatörer och forskare som vill ha snabba resultat.
Prissignal: Gratis provperiod finns; betalplanerna är kreditbaserade. Se .
2. Bright Data
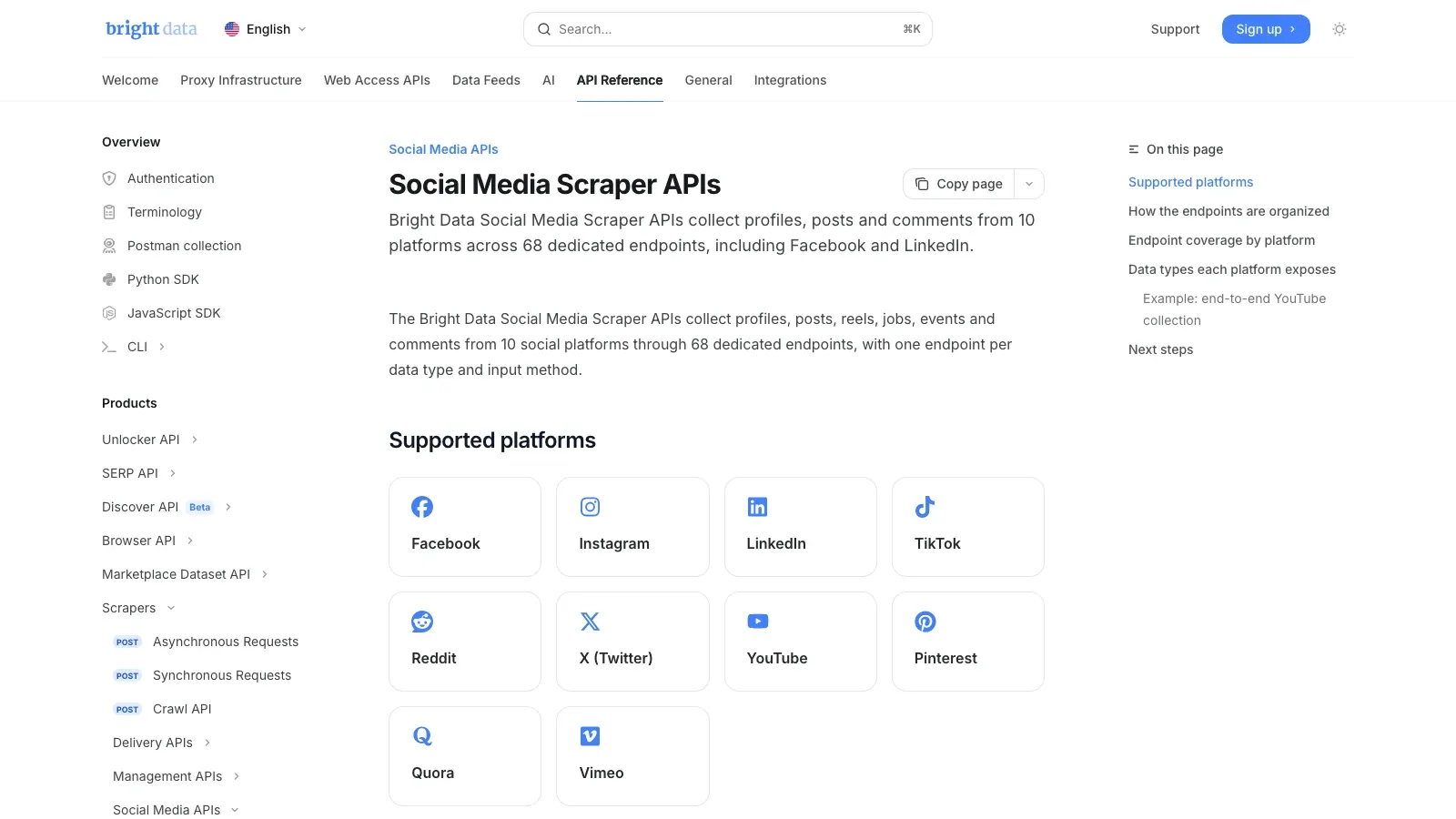
är det infrastrukturförst-alternativet. Bright Datas egen dokumentation säger att deras täcker 10 plattformar och 68 dedikerade endpoints, inklusive Facebook. Om jobbet handlar om storskalig insamling av offentliga data är den här typen av hanterad API-stack vanligtvis mer realistisk än att försöka skala ett webbläsartillägg eller en hemmabyggd scraper.
Varför den platsar på shortlistan:
- Dedikerade scraping-endpoints för sociala medier
- Hanterad upplåsning och extraktion
- Strukturerad leverans av output för datapipelines
- Bättre passform för tillförlitlig övervakning och analysjobb
Bäst för: analytiker, datateam, stora bevakningsprojekt och offentliga sociala datamängder i skala.
Prissignal: Priset varierar beroende på produkt och volym. Kontrollera .
3. Apify
är fortfarande relevant eftersom det ger en bra mellanväg mellan färdiga mallar och full anpassning. Deras Facebook Pages Scraper-actor är en användbar startpunkt, medan den bredare Apify-plattformen ger dig molnkörningar, schemaläggning, API:er och utrymme att bygga vidare om behoven blir mer komplexa.
Därför kom den med på listan:
- Färdiga Facebook-actors
- Molnkörning och återkommande scheman
- Flexibla exporter och API-åtkomst
- Enklare att bygga ut än ett rent no-code-webbläsarflöde
Bäst för: tekniska marknadsförare, byråer, ops-team och återkommande insamlingsjobb över flera webbplatser.
Prissignal: Plattformspaketen är betalda och actor-användning debiteras separat. Se .
4. Nimble by Nimbleway
är API-först-alternativet för team som vill skicka in en URL och låta plattformen hantera åtkomst, rendering och leverans. Nimble positionerar sin som en komplett lösning för insamling av offentliga webbdata, vilket gör den användbar när Facebook-scraping bara är en del av en större datastack.
Varför den är värd att utvärdera:
- URL-först-API-flöde
- Mindre underhållsbörda för scrapern för utvecklingsteam
- Bra för robust extraktion av offentliga webbsidor
- Användbar när den insamlade datan matar interna produkter eller dashboards
Bäst för: utvecklingsdrivna team, datapipelines för produktdata och organisationer som vill ha infrastrukturabstraktion i stället för punktverktyg.
Prissignal: Nimble lyfter inte fram tydlig offentlig självbokningsprissättning på sina centrala API-sidor, så räkna med säljstyrd prissättning och verifiera direkt med .
5. ScrapingBot
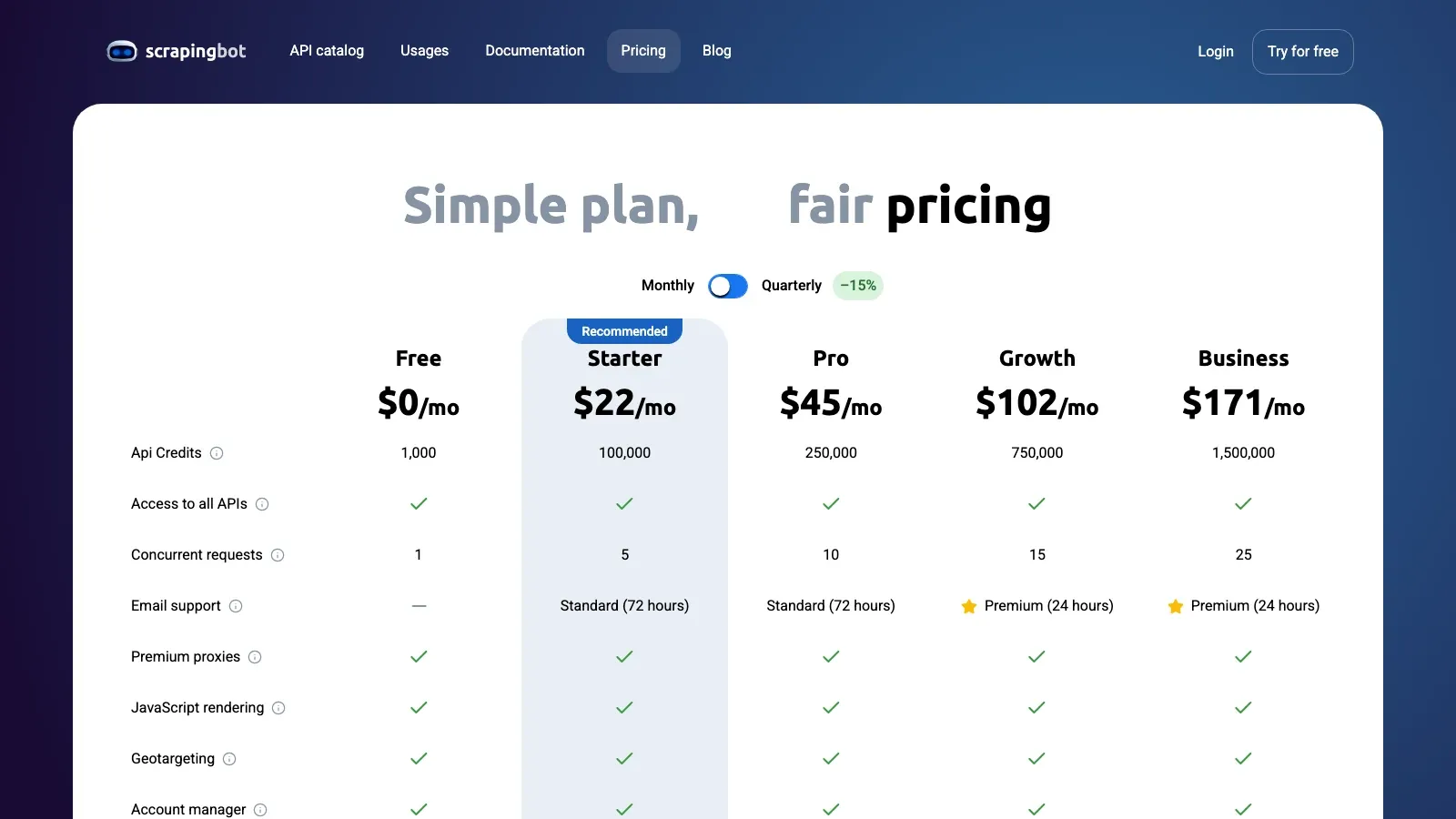
är det budgetmedvetna API-alternativet i den här listan. Det är inte den djupaste Facebook-specialiserade plattformen här, men det är ändå vettigt för mindre jobb med offentliga data där du vill ha ett API, stöd för rendering och en lägre kostnadsnivå än enterprise-infrastruktur för scraping.
Där passar den in:
- Enkelt API-drivet scraping av offentliga sidor
- Lägre ingångspris
- Rendering och proxyhantering ingår
- Bättre för prototyper och lätta återkommande hämtningar än för stora analysprogram
Bäst för: startups, småföretag och utvecklare som testar lättare användningsfall för insamling från offentliga sidor.
Prissignal: Gratis nivå finns; den aktuella offentliga prissidan startar betalda planer från cirka .
6. PhantomBuster
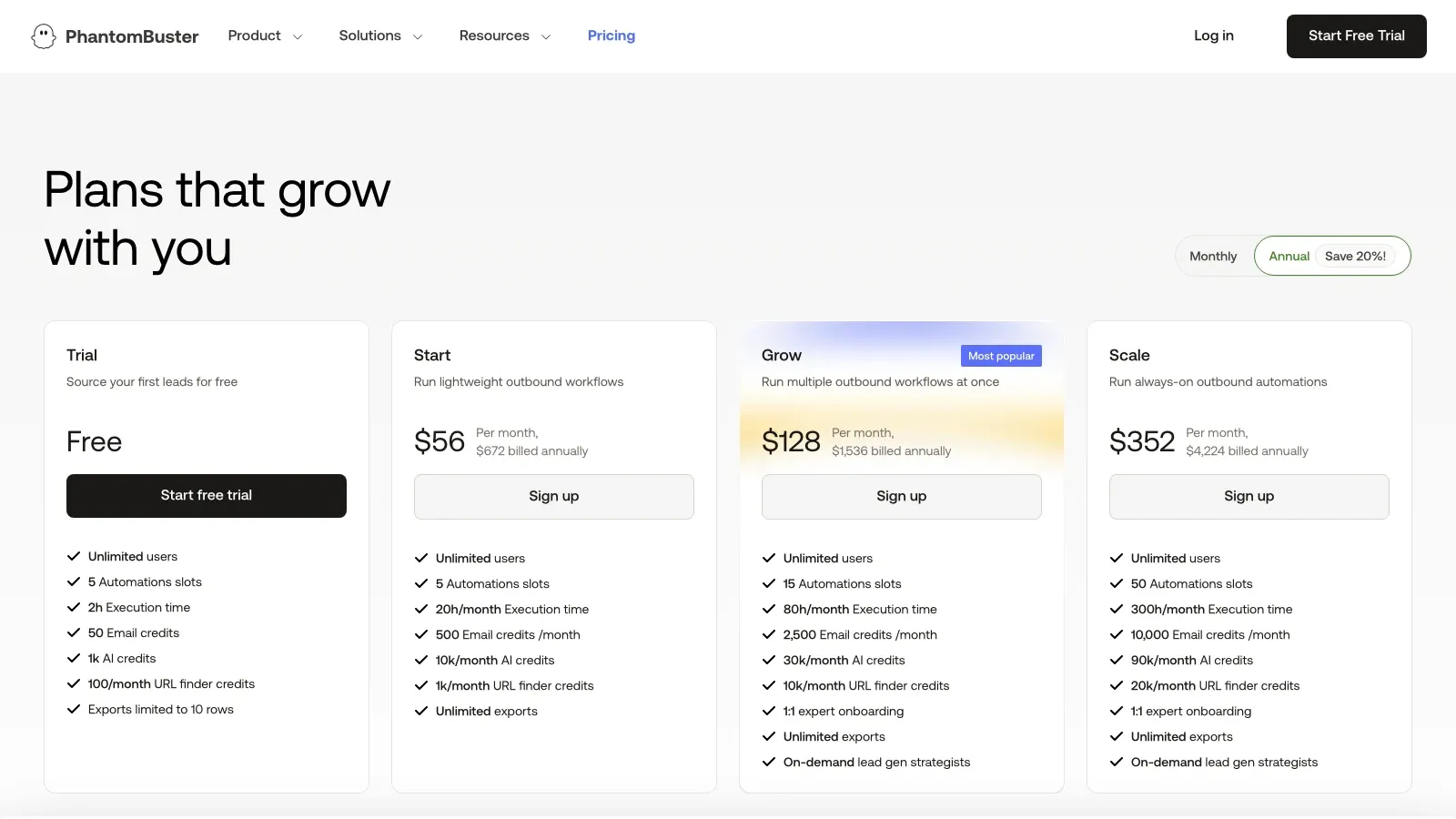
handlar mindre om ren scraping-infrastruktur och mer om vad som händer efter insamlingen. Om ditt användningsfall är ”samla in datan och trigga sedan outreach, berikning eller uppföljande åtgärder” är PhantomBuster ofta mer användbart än en vanlig extractor eftersom det är byggt runt molnautomation och webbläsarbaserade arbetsflöden.
Därför fortsätter team att kortlista det:
- Molnbaserade automationsflöden
- Användbart för leadgenerering och GTM-arbete
- Bättre passform när scraping bara är ett steg i en bredare process
- Praktiskt för operatörer som bryr sig om åtgärder, inte bara exporter
Bäst för: GTM-team, growth-team, rekryterare och operatörer som kedjar ihop insamling med efterföljande åtgärder.
Prissignal: Gratis provperiod finns; betalda planer på den aktuella prissidan startar från cirka .
7. Octoparse
är fortfarande ett av de bättre visuella no-code-verktygen för scraping för användare som vill ha återkommande arbetsflöden och schemalagda molnkörningar. Det är inte lika lättviktigt som Thunderbit för snabba Facebook-jobb på en gång, men det ger icke-utvecklare mer uttrycklig kontroll över hur extraktionslogiken byggs och upprepas.
Varför det fortfarande är relevant:
- Visuell byggare med dra-och-släpp
- Molnextraktion och schemaläggning
- Bra för strukturerade, återkommande uppgifter
- Bättre lämpat för analytiker som vill ha reproducerbarhet utan kod
Bäst för: icke-tekniska analytiker, SMB-ops-team och återkommande insamlingsuppgifter med mer uttrycklig arbetsflödeslogik.
Prissignal: Octoparses offentliga prissida listar betalplaner från cirka .
Shortlista efter team
Om du redan vet vilket team som ska äga arbetsflödet, börja här:
- Ensam operatör eller småföretag: Thunderbit, ScrapingBot eller Octoparse
- Sälj- / GTM-team: Thunderbit eller PhantomBuster
- Ops-analytiker: Thunderbit, Apify eller Octoparse
- Growth-automationsteam: PhantomBuster eller Apify
- Datateam inom engineering: Bright Data, Nimble eller Apify

Så väljer du rätt Facebook-scraper
- Välj Thunderbit om snabbhet och enkelhet är viktigare än maximal skala.
- Välj Bright Data om du behöver skala för offentliga data och hanterad tillförlitlighet.
- Välj Apify om du vill ha plattformsflexibilitet och actor-baserade arbetsflöden.
- Välj Nimble om du vill ha ett API-först-abstraktionslager med mindre underhåll av scrapern.
- Välj PhantomBuster om scraping bara är ett steg i ett bredare GTM-automationsflöde.
- Välj Octoparse om du vill ha visuell reproducerbarhet utan kod.
- Välj ScrapingBot om budgeten spelar stor roll och jobbet är relativt enkelt.
Slutsats
Marknadsuppdelningen är tydligare 2026 än den var för ett år sedan. Du väljer egentligen inte en enda universell ”bästa Facebook-scraper”. Du väljer en insamlingsmodell: snabb no-code-extraktion, hanterad API-skala, molnautomation eller praktisk visuell kontroll av arbetsflöden. Börja där, så blir shortlistningen mycket enklare.
Om ditt team vill ha den snabbaste vägen från en Facebook-sida eller en Marketplace-annons till användbar strukturerad data, är Thunderbit fortfarande den enklaste platsen att börja på. Om din volym eller dina teknikkrav är betydligt tyngre ger Bright Data, Apify och Nimble mer mening. Om ditt arbetsflöde börjar med scraping men slutar i uppföljande åtgärder är PhantomBuster det smartare valet för shortlistan.
Vanliga frågor
1. Vilket är det enklaste verktyget för Facebook-scraping för icke-tekniska användare?
Thunderbit är den enklaste utgångspunkten för de flesta icke-tekniska användare eftersom det fungerar i webbläsaren, föreslår fält automatiskt och exporterar data snabbt utan kod.
2. Vilket Facebook-scrapingverktyg är bäst för storskalig insamling av offentliga data?
Bright Data är det starkaste infrastrukturvalet i den här listan när jobbet gäller storskalig insamling av offentliga sociala data och tillförlitlighet är viktigare än användarvänlighet.
3. Vad händer om jag behöver scraping plus uppföljande automation?
PhantomBuster är bättre lämpat när datainsamling bara är ett steg i ett bredare arbetsflöde för leadgenerering eller GTM.
4. Är Facebook-scraping fortfarande svårt 2026?
Ja. Dynamiskt innehåll, inloggningsväggar, hastighetsgränser, anti-bot-system och kontorisker gör fortfarande Facebook svårare än att skrapa enklare offentliga webbplatser.
5. Hur bör team tänka kring efterlevnad?
Håll fokus på offentliga data, använd rimliga hastigheter, undvik missbruk av inloggningsuppgifter och granska plattformens villkor och tillämpliga integritetsregler innan du skalar ett arbetsflöde.
Vidare läsning: