

Om du någonsin har försökt bygga en riktad säljlista, utforska nya marknader eller jämföra konkurrenter vet du vilken guldgruva Google Maps är. Men här är det viktiga: med över 1,5 miljarder sökningar med ”i närheten av mig” varje månad och 76 % av lokala sökare som besöker ett företag inom 24 timmar (thinkwithgoogle.com), har efterfrågan på aktuell, platsbaserad företagsdata aldrig varit högre.
Oavsett om du jobbar med försäljning, marknadsföring eller drift kan strukturerad data från Google Maps vara avgörande för om ett lead blir ett kallt samtal eller en varm, högkonverterande kontakt.
Jag har jobbat i SaaS och automation i flera år, och jag har sett på nära håll hur team använder Python (och numera AI-drivna verktyg som Thunderbit) för att göra Google Maps till en strategisk tillgång.
I den här guiden går jag igenom exakt hur du extraherar Google Maps-data med Python år 2026 — steg för steg, med kod, tips för regelefterlevnad och en jämförelse med no-code-lösningar. Oavsett om du är Python-proffs eller bara vill ha den snabbaste vägen till användbar data är du på rätt plats.
Vad betyder det att extrahera Google Maps med Python?
Låt oss börja med grunderna: att extrahera Google Maps med Python betyder att programmatiskt hämta företagsinformation — som namn, adresser, betyg, recensioner, telefonnummer och koordinater — från Google Maps, så att du kan analysera, filtrera och exportera den för affärsbruk.

Det finns två huvudsakliga sätt att göra detta:
- Google Maps Places API: Det officiella, licensierade sättet. Du använder en API-nyckel för att fråga Googles servrar och få tillbaka strukturerad JSON-data. Det är stabilt, förutsägbart och (för det mesta) förenligt med reglerna, men det kommer med kvoter och kostnader.
- Webbscraping av HTML: Du automatiserar en webbläsare (med verktyg som Playwright eller Selenium) för att ladda Google Maps, göra sökningar och tolka den renderade sidan. Det är mer flexibelt men också skörare — Google ändrar ofta webbplatsens struktur, och att scrapa HTML kan bryta mot Googles villkor.
Vanliga datafält du kan extrahera:
- Företagsnamn
- Kategori/typ
- Fullständig adress (plus stad, delstat, postnummer, land)
- Latitud och longitud
- Telefonnummer
- Webbplats-URL
- Betyg och antal recensioner
- Prisnivå
- Företagsstatus (öppet/stängt)
- Öppettider
- Place ID (Googles unika identifierare)
- Google Maps-URL
Varför spelar detta roll? För de här fälten används till allt från leadgenerering och territorieplanering till konkurrentanalys och marknadsundersökningar. Nyckeln är att rikta in sig på rätt data för dina affärsmål — scrapa inte bara blint.
Varför sälj- och marknadsteam extraherar data från Google Maps med Python
Låt oss bli praktiska. Varför är så många sälj- och marknadsteam besatta av Google Maps-data år 2026?
- Leadgenerering: Bygg hyperriktade listor över lokala företag, kompletta med kontaktuppgifter och betyg, för outreach-kampanjer.
- Territorieplanering: Kartlägg säljdistrikt, leveransområden eller serviceområden utifrån verklig företagsdensitet och företagskategorier.
- Konkurrentbevakning: Följ konkurrenters platser, betyg och recensioner över tid för att upptäcka trender och möjligheter.
- Marknadsundersökning: Analysera företagskategorier, öppettider och känslan i recensioner för att informera go-to-market-strategier.
- Val av plats: För fastighet och detaljhandel, utvärdera möjliga platser utifrån närliggande bekvämligheter, fottrafik och konkurrens.
Effekt i verkligheten: Enligt HubSpot 2025 State of Sales planerar 92 % av säljorganisationerna att öka investeringarna i AI/data, och team som använder riktad, lokal data ser konverteringsgrader upp till 8× högre än de som förlitar sig på generiska kalla listor (martal.ca). En studie om leadgenerering för franchisetagare visade 15 dollar i ny intäkt för varje 1 dollar som spenderades på Google Maps-baserade leadlistor.
Koppla affärsmål till Google Maps-fält:
| Affärsmål | Nödvändiga Google Maps-fält |
|---|---|
| Lokal leadlista | namn, adress, telefon, webbplats, kategori |
| Territorieplanering | namn, lat/lng, business_status, opening_hours |
| Konkurrentjämförelse | namn, betyg, userRatingCount, priceLevel, reviews |
| Val av plats | kategori, lat/lng, recensionsdensitet, openingDate |
| Sentiment-/menyintelligens | reviews, editorialSummary, photos, types |
| Uppsökande via e-post/telefon | nationalPhoneNumber, websiteUri (berika sedan vid behov) |
Så sätter du upp din Python Google Maps-scraper: verktyg och krav
Innan du börjar scrapa behöver du ställa in din Python-miljö och samla rätt verktyg. Här är vad du behöver 2026:
1. Installera Python och nödvändiga bibliotek
Rekommenderad Python-version: 3.10 eller senare.
Installera de viktigaste biblioteken:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
Vad de gör:
requests,httpx: HTTP-förfrågningar (API-anrop)beautifulsoup4,lxml: HTML-tolkning (för webbscraping)pandas: datarensning, analys, exportselenium,playwright: webbläsarautomation (för HTML-scraping)googlemaps,google-maps-places: klienter för Google Maps APIschedule,APScheduler: schemaläggning av uppgifterpython-dotenv: läs in API-nycklar säkert från.env-filertenacity: återförsökslogik för felhantering
2. Skaffa en Google Maps API-nyckel (för API-baserad scraping)
- Gå till Google Cloud Console.
- Skapa eller välj ett projekt.
- Aktivera fakturering (krävs, även för gratisnivån).
- Aktivera “Places API (New)” under APIs & Services > Library.
- Gå till Credentials > Create Credentials > API Key.
- Begränsa nyckeln till specifika API:er och IP-adresser av säkerhetsskäl.
- Lagra API-nyckeln i en
.env-fil (checka aldrig in den i koden):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
Obs: Från och med mars 2025 erbjuder Google inte längre någon universell gratis kredit på 200 dollar per månad. I stället får du fria månadströsklar per API-nivå (se officiell prissättning).
Så extraherar du data från Google Maps med Python: steg-för-steg-guide
Låt oss gå igenom båda huvudmetoderna — API-baserad och HTML-scraping — så att du kan välja det som passar dina behov bäst.
Metod 1: Använd Google Maps Places API (rekommenderat)
Steg 1: Installera och importera nödvändiga bibliotek
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
Steg 2: Läs in din API-nyckel på ett säkert sätt
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
Steg 3: Bygg din sökfråga
Du använder Text Search-ändpunkten för att hitta företag som matchar dina kriterier.
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
Steg 4: Skicka API-anropet
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # server-side filter
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # Always set this!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
Steg 5: Hantera paginering och samla resultat
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
Steg 6: Exportera data med Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
Proffstips:
- Ange alltid headern
X-Goog-FieldMaskför att kontrollera kostnaderna. Om du begär recensioner eller bilder kan priset per 1 000 anrop hoppa från 5 dollar till 25 dollar (prisinformation). - Använd server-side-filter (som
minRating,includedType,locationBias) för att undvika att slösa krediter på irrelevanta resultat. - Cacha
place_id-värden för deduplicering och framtida uppdateringar.
Metod 2: Scrapa Google Maps HTML (för utbildning eller enstaka användning)
Varning: Google Maps är en single-page app. Du måste använda webbläsarautomation (Playwright eller Selenium), och att scrapa HTML kan bryta mot Googles villkor. Använd detta för research, inte i produktion.
Steg 1: Installera Playwright och starta en webbläsare
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
Tips:
- Google slumpmässiggör CSS-klasser varannan vecka, så koden kan behöva uppdateras regelbundet.
- Använd mänskliga fördröjningar och undvik att scrapa för snabbt för att minska risken att blockeras.
- Försök aldrig kringgå CAPTCHAs eller Googles SearchGuard-system — det kan utsätta dig för juridiska risker.
Undvik blinda scrapes: så riktar du in dig exakt på datan du behöver
Att scrapa allt är ett recept på slöseri med tid och uppsvällda datamängder. Så här riktar du bara in dig på den data som faktiskt spelar roll:
- Skapa riktade URL-listor: Använd Googles egna sökfilter i Maps (kategori, plats, betyg, öppet nu) för att snäva in resultaten innan du scrapar.
- Använd frasmatchning: Sök efter exakta företagstyper eller nyckelord (t.ex. ”veganskt bageri i Austin”).
- Platsfilter: Ange stad, område eller till och med koordinater och radie för exakt träffsäkerhet.
- Server-side-filtrering (API): Använd
minRating,includedTypeochlocationBiasi din API-begäran. - Client-side-filtrering (Python): Efter scraping kan du använda pandas för att filtrera företag med betyg över 4,0, fler än 50 recensioner eller specifika kategorier.
Exempel: Filtrera bara restauranger på Manhattan med betyg över 4,0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
Använd Python-bibliotek för att strukturera och exportera Google Maps-data
När du väl har scrapat din data är det dags att rensa, analysera och exportera den för ditt team.
Rensa och strukturera data med Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
Analysera och sammanfatta data
Exempel: genomsnittligt betyg per område
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
Exportera till Excel eller CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
Stora datamängder? Använd Parquet-format för snabbhet och effektiv filstorlek:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: AI-driven alternativ till Python Google Maps-scraper
Om du nu tänker: ”Det här är mycket att sätta upp för en enkel leadlista”, är du inte ensam. Det är precis därför vi byggde Thunderbit — en AI-driven, no-code web scraper som gör det lika enkelt att extrahera data från Google Maps (och mycket mer) som att klicka några gånger.
Varför Thunderbit?
- Ingen kod eller API-nycklar krävs: Öppna bara Thunderbit Chrome Extension, gå till Google Maps och klicka på “AI Suggest Fields”.
- AI-fältdetektering: Thunderbits AI läser sidan och föreslår rätt kolumner — namn, adress, betyg, telefon, webbplats och mer.
- Scraping av undersidor: Vill du berika tabellen med data från varje företags webbplats? Thunderbit kan besöka varje undersida och hämta in extra information automatiskt.
- Export till Excel, Google Sheets, Airtable eller Notion: Inget mer pandas-trixande — klicka bara på “Export” så är datan redo för teamet.
- Schemalagd scraping: Sätt upp återkommande jobb för att bevaka konkurrenter eller uppdatera din leadlista automatiskt.
- Inget underhåll: Thunderbits AI anpassar sig till webbplatsförändringar, så du slipper hela tiden laga trasiga skript.
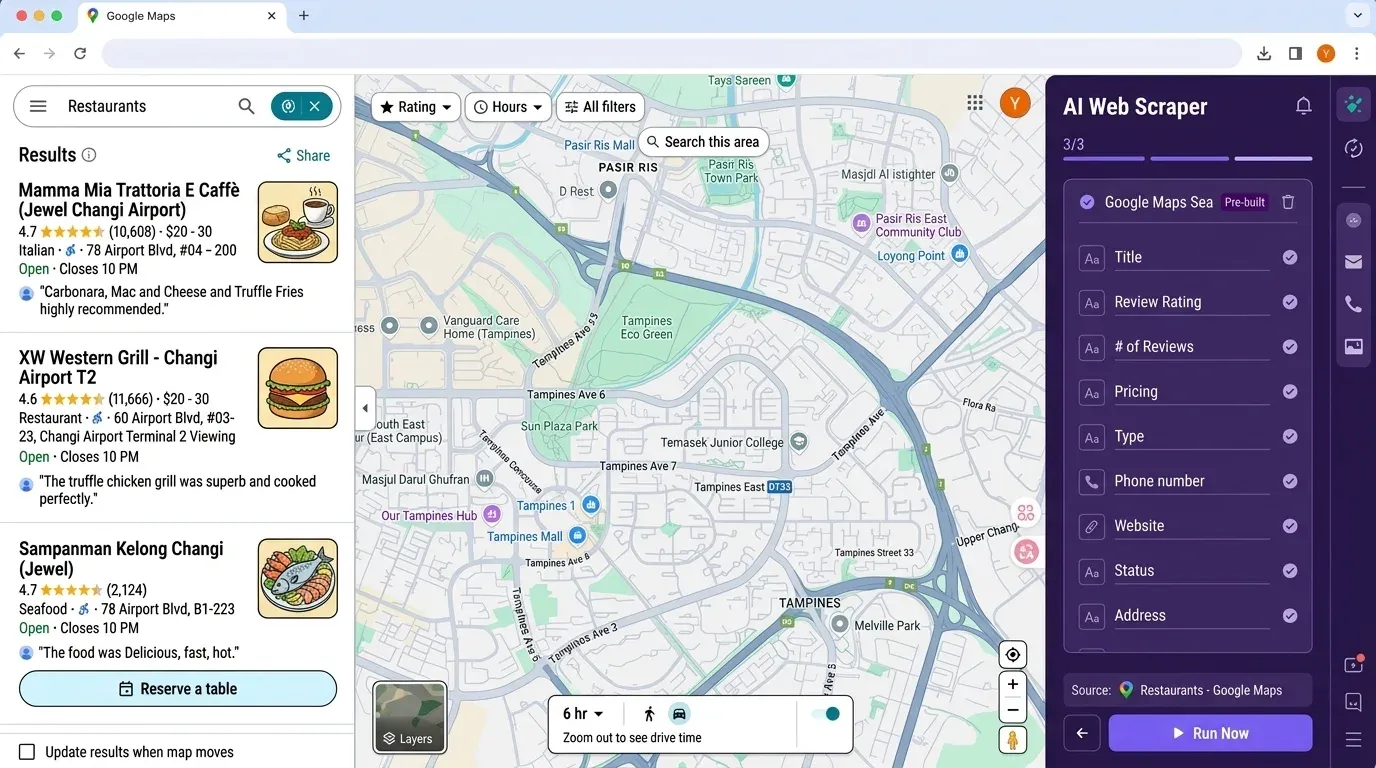
Thunderbit kontra Python-arbetsflöde:
| Steg | Python-scraper | Thunderbit |
|---|---|---|
| Installera verktyg | 30–60 min (Python, pip, bibliotek) | 2 min (Chrome Extension) |
| API-nyckelsetup | 10–30 min (Cloud Console) | Ingen behövs |
| Fältval | Manuell kod, field masks | AI Suggest Fields (1 klick) |
| Datautvinning | Skriv/kör skript, hantera fel | Klicka på “Scrape” |
| Export | pandas till CSV/Excel | Exportera till Excel/Sheets/Notion |
| Underhåll | Manuella uppdateringar vid webbplatsändringar | AI anpassar sig automatiskt |
Bonus: Thunderbit används av över 30 000 användare världen över, och gratisnivån låter dig scrapa upp till 6 sidor (eller 10 med en provboost) utan kostnad.
Följ reglerna: Googles användarvillkor för Maps och etik kring scraping
Det här är delen där de flesta Python-guider blir farligt föråldrade. Här är vad du behöver veta 2026:
- Google Maps Platform ToS §3.2.3 förbjuder strikt scraping, cachning eller export av data utanför de officiella API:erna (cloud.google.com). Det enda undantaget: latitud-/longitudvärden får cachas i upp till 30 dagar; Place IDs kan lagras på obestämd tid.
- API-användare är avtalsbundet bundna: Om du använder en API-nyckel har du godkänt Googles villkor — även om du bara samlar in offentlig data.
- Att kringgå tekniska spärrar (CAPTCHAs, SearchGuard) kan numera innebära en möjlig DMCA §1201-överträdelse, vilket kan leda till straffrättsliga påföljder (ppc.land).
- GDPR och integritetsskydd: Om du samlar in personuppgifter (e-post, telefonnummer, granskarnas namn) från Google Maps måste du ha en rättslig grund och respektera raderingsbegäran. Franska CNIL bötfällde KASPR med 200 000 euro 2024 för scraping av LinkedIn-kontakter (edpb.europa.eu).
- Bästa praxis:
- Använd i första hand Places API när det går.
- Begränsa anropsfrekvensen (≤10 QPS för API, 1–2 förfrågningar/s för HTML-scraping).
- Försök aldrig kringgå CAPTCHAs eller tekniska blockeringar.
- Vidarebefordra inte scrappad persondata.
- Respektera opt-out- och raderingsbegäran.
- Granska alltid lokala lagar — GDPR, CCPA och andra tillämpas aktivt.
Kort sagt: Om regelefterlevnad är en fråga, håll dig till API:t och minimera datan du samlar in. För de flesta företagsanvändare minskar ett no-code-verktyg som Thunderbit riskytan (ingen API-nyckel, ingen vidaredistribution).
Schemalägg och automatisera din Google Maps-scraping med Python
Om du behöver hålla datan färsk — säg för veckovis konkurrentbevakning eller månatliga uppdateringar av leadlistor — är automation din vän.
Enkel schemaläggning med schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
Produktionsklar schemaläggning med APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 3:15 AM ± 10 min
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
Tips för säker automation
- Lägg in slumpmässig jitter i schemat för att undvika förutsägbara mönster.
- För HTML-scraping, kör aldrig mer än 1–2 förfrågningar per sekund.
- För API-användning, övervaka kvoten och sätt upp faktureringsvarningar.
- Logga alltid fel och ha en ”dead-letter”-fil för misslyckade förfrågningar.
Thunderbit-bonus: Med Thunderbit kan du schemalägga återkommande scraping direkt i gränssnittet — ingen kod, inga cron-jobb, ingen serveruppsättning.
Viktiga lärdomar: effektiv, riktad och regelrätt extrahering av Google Maps-data
Låt oss sammanfatta det viktigaste:
- Google Maps är den främsta källan till platsdata för företag, och driver allt från leadgenerering till marknadsundersökningar.
- Python-scraping ger flexibilitet och kontroll, men innebär samtidigt arbete med installation, underhåll och regelefterlevnad — särskilt i takt med att Googles anti-bot-skydd och rättsliga åtgärder skärps.
- API-baserad extrahering är det säkraste och mest skalbara alternativet för de flesta team. Använd alltid field masks och server-side-filter för att kontrollera kostnaderna.
- HTML-scraping är skört och riskfyllt — använd det bara för engångsresearch och kringgå aldrig tekniska spärrar.
- Rikta in dig på rätt data: Använd frasmatchning, platsfilter och pandas-arbetsflöden för att extrahera bara det du behöver.
- Thunderbit är den snabbaste vägen för dig som inte kodar: AI-driven, ingen setup, direkt export och inbyggd schemaläggning.
- Regelefterlevnad spelar roll: Respektera Googles villkor, integritetslagar och anropsgränser för att undvika juridiskt krångel.
För fler guider och tips, kolla in Thunderbit Blog och vår YouTube-kanal.
Vanliga frågor
1. Är det lagligt att scrapa Google Maps-data med Python år 2026?
Scraping av Google Maps via det officiella API:t är tillåtet inom Googles villkor, så länge du respekterar kvoter och inte vidarebefordrar begränsad data. HTML-scraping av Google Maps är uttryckligen förbjudet av Googles användarvillkor och innebär juridisk risk, särskilt om du kringgår tekniska spärrar eller samlar in personuppgifter utan samtycke. Kontrollera alltid lokala lagar (GDPR, CCPA osv.) och följ bästa praxis för regelefterlevnad.
2. Vad är skillnaden mellan att använda Google Maps API och att webbscrapa HTML?
API:t är stabilt, licensierat och utformat för dataextrahering, men kräver en API-nyckel och omfattas av kvoter och kostnader. HTML-scraping använder webbläsarautomation för att extrahera data från den renderade sidan, men är skört (webbplatsen ändras ofta), kan bryta mot villkoren och är juridiskt riskablare. För de flesta affärsbehov är API:t det rekommenderade alternativet.
3. Hur mycket kostar det att extrahera data från Google Maps med Python år 2026?
Google Places API-prissättning är per 1 000 anrop och ligger mellan 5 dollar (Essentials) och 25 dollar (Enterprise+Atmosphere), beroende på vilka fält du begär. Det finns fria månadströsklar (10 000 för Essentials, 5 000 för Pro, 1 000 för Enterprise), men scraping i stor skala kan snabbt bli dyrt. Använd alltid field masks och server-side-filter för att kontrollera kostnaderna.
4. Hur står sig Thunderbit jämfört med Python-baserade Google Maps-scrapers?
Thunderbit är en no-code, AI-driven web scraper som låter dig extrahera Google Maps-data (och mycket mer) utan programmering, API-nycklar eller underhåll. Det är perfekt för sälj- och marknadsteam som vill ha snabba, pålitliga exporter till Excel, Google Sheets, Airtable eller Notion. För tekniska användare som behöver anpassad logik erbjuder Python mer flexibilitet, men kräver också mer uppsättning och hantering av regelefterlevnad.
5. Hur kan jag automatisera återkommande extrahering av Google Maps-data?
Med Python kan du använda schemaläggningsbibliotek som schedule eller APScheduler för att köra din scraper med bestämda intervall (dagligen, veckovis osv.). Lägg till slumpmässig jitter för att undvika upptäckt och övervaka din API-kvot. Med Thunderbit kan du schemalägga återkommande scraping direkt i gränssnittet — ingen kod eller serveruppsättning behövs.
Redo att göra Google Maps till din superkraft för försäljning och marknadsföring? Oavsett om du är en Python-entusiast eller vill ha den snabbaste no-code-lösningen finns verktygen här 2026. Testa Thunderbit för omedelbar, AI-driven scraping — eller kavla upp ärmarna och dyka ner i API:t. Hur som helst hoppas jag att dina leadlistor är färska, dina exporter rena och dina kampanjer fulla av högkonverterande lokala prospekt. Lycka till med scrapingen!
Läs mer




