Google lade ned sitt Flights API redan 2018, men flygpriserna fortsätter att svänga — för en enda inrikeslinje. Om du vill ha programmatisk åtkomst till den datan är scraping i praktiken det enda realistiska alternativet.
Jag har lagt mycket tid på att testa olika sätt att hämta flygdata från Google, och läget har förändrats rejält — särskilt efter att Google lanserade SearchGuard i januari 2025. I den här guiden går jag igenom hur du bygger en fungerande Python-scraper för Google Flights med Playwright, visar hur du hanterar antibot-skydden som ställer till det för de flesta, och bygger vidare till en automatiserad prisbevakare med aviseringar. Om du helst vill slippa koda helt tar jag också upp ett no-code-alternativ med som ger samma resultat på ungefär två minuter.
Varför skrapa Google Flights med Python?
Google Flights dominerar flygsök. I USA:s mobila synlighet och gick förbi alla stora OTA:er. Marknaden för resesökmotorer bakom tjänsten värderas till och växer med 30,2% CAGR. Men sedan QPX Express API:et finns inget officiellt sätt att komma åt den här datan programmässigt.
Samtidigt kan flygpriser för samma resplan, med en genomsnittlig skillnad på ungefär 20 dollar mellan lägsta och högsta pris. Flygbolag som Delta använder 77 prisnivåer för dynamisk prissättning. Genomsnittspriset för en tur-och-retur i USA i början av 2026 ligger på 408 dollar, och flygbiljetter är .
Dominerande plattform, inget API, svängiga priser. Därför har scraping av Google Flights med Python blivit ett av de mest populära projekten på GitHub och i reseforum.
Här är vem som tjänar på det och hur:
| Användartyp | Användningsområde | Viktig nytta |
|---|---|---|
| Enskilda resenärer | Bevaka priser för specifika rutter över tid | Spara i snitt $50 per flygning |
| Resebyråer | Konkurrensanalys av priser | Övervakning av prisparitet i realtid |
| Team för affärsresor | Kostnadsoptimering över olika rutter | 10–30% besparing på affärsresor |
| Utvecklare | Bygga appar för prisjämförelser | Programmatisk åtkomst till prisdata |
| Forskare | Analys av prisvolatilitet hos flygbolag | Akademisk och kommersiell forskning |
Användare på forum är tydliga med varför de gått över till scraping: "Google Flights API was discontinued and I should use web scraping instead" är ett omdöme som dyker upp om och om igen. Och nyttan är verklig — efter att ha analyserat över 5 miljarder prisuppgifter per dag, medan Expedias data för 2026 visar att bokning 8–15 dagar i förväg sparar ungefär .
Vilken data kan du skrapa från Google Flights?
En resultatsida i Google Flights innehåller förvånansvärt mycket information. Här är det som vanligtvis går att få ut:
- Flygbolagets namn (och logotyp)
- Avgångstid och flygplatskod
- Ankomsttid och flygplatskod
- Total restid
- Antal mellanlandningar och detaljer om uppehåll (flygplats, längd, om det är övernattning)
- Biljettpris (beroende på valuta)
- CO2-utsläpp (kg CO2e, med procentuell skillnad mot typiska flyg)
- Reseklass, flightnummer, flygplansmodell
- Utrymme för benen
- Tilläggstjänster (Wi‑Fi, eluttag, streaming)
- Prisnivåindikator (låg/normal/hög)
- Förseningsvarningar ("Ofta försenad mer än 30 min")
Tillgängligheten varierar beroende på rutt, datum och biljettyp (enkelresa eller tur-och-retur). Så här kan en enskild skrapad flygpost se ut som JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Så ställer du in din Python-miljö
Innan vi skriver någon scrapingkod behöver du några saker på plats.
Förkunskaper:
- Svårighetsgrad: Medel
- Tidsåtgång: ~1–2 timmar för hela guiden
- Du behöver: Python 3.7+, grundläggande Python-kunskaper, en Chromium-baserad webbläsare
Installera de bibliotek som behövs
Vi använder Playwright för webbläsarautomation (Google Flights är till 100% renderat med JavaScript — vanliga HTTP-anrop ger inget användbart), plus några hjälpbibliotek:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automatiserar en riktig webbläsare, hanterar JavaScript-rendering och inbyggda väntemekanismer
- playwright-stealth — döljer vanliga signaler som avslöjar botar
- pandas — för analys av data och export till CSV senare
Varför Playwright i stället för Selenium eller requests
Google Flights fungerar inte med bara requests + BeautifulSoup — sidinnehållet renderas helt av JavaScript. Du behöver en riktig webbläsare.
| Funktion | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS-rendering | Fullt stöd | Fullt stöd | Inget |
| Hastighet | 42% snabbare totalt | Baslinje | Ej relevant här |
| Asynkront stöd | Inbyggt | Endast sekventiellt | Ej relevant |
| Minnesanvändning | 30% lägre | Högre | Minimal |
| Undvikande av botdetektion | Bra (med stealth) | Lättare att upptäcka | Ej relevant |
Playwright är snabbare, modernare och har bättre stöd för async. För Google Flights är det det självklara valet.
Steg för steg: Så skrapar du Google Flights med Python
Det här är kärnan i guiden. Vi bygger scrapen bit för bit.
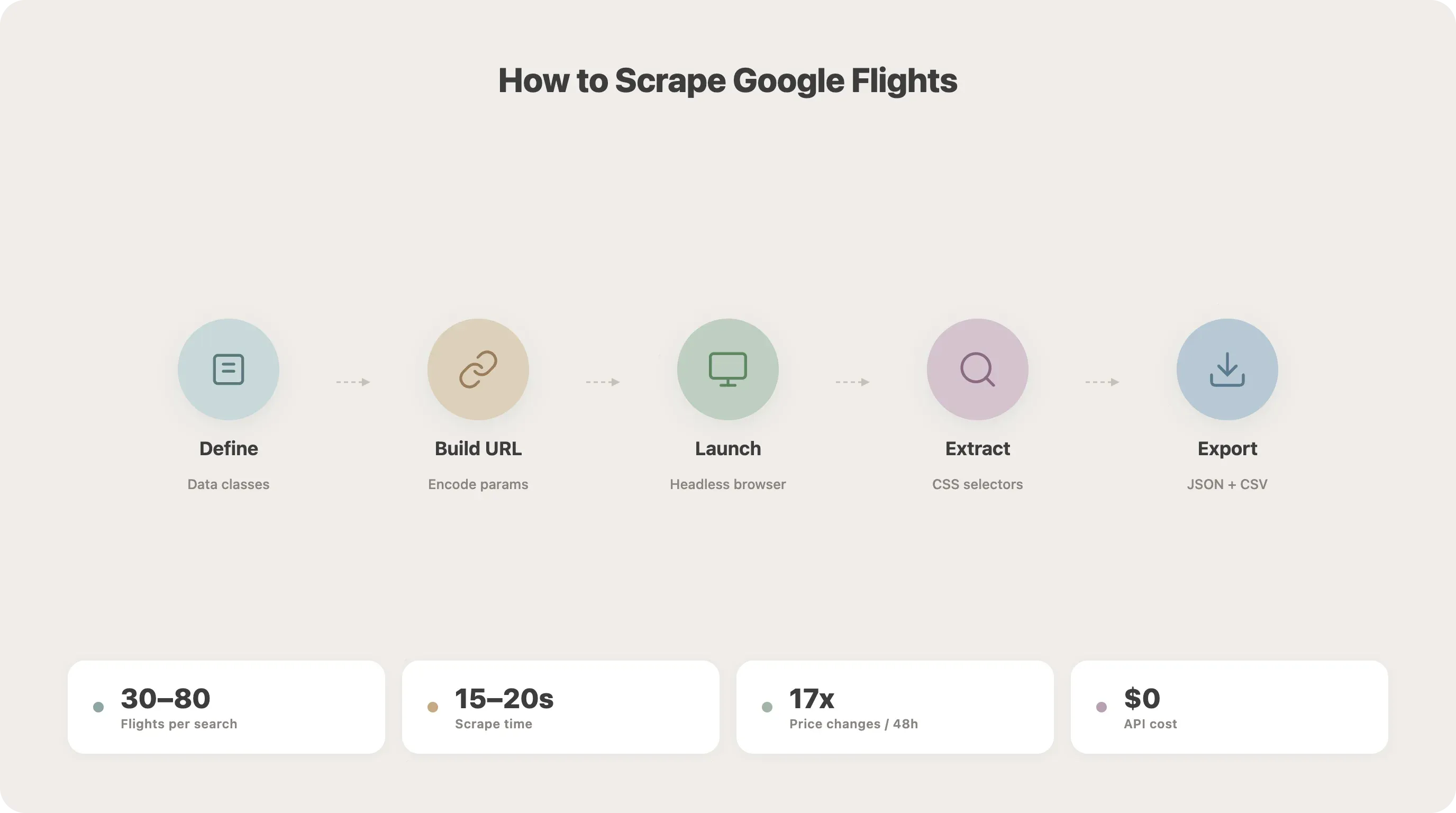
Steg 1: Definiera dina dataklasser
Börja med att strukturera dina sökparametrar och flygdata med Python-dataklasser. Då hålls koden ren och blir lättare att bygga vidare på senare.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # t.ex. "SFO"
6 destination: str # t.ex. "JFK"
7 departure_date: str # t.ex. "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" eller "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Varje fält mappar direkt till det vi ska plocka ut från sidan. Med den här strukturen från början slipper du skicka runt röriga ordböcker senare.
Steg 2: Förstå URL-strukturen i Google Flights
Google Flights kodar sökparametrar med Base64-enkodad Protobuf i URL-parametern tfs. Du kan antingen reverse-engineera den kodningen eller ta den enklare vägen: skapa en naturlig sök-URL.
Det enklaste sättet är att använda sökformatet:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDOm du vill ha mer kontroll kan du bygga URL:er programmatiskt:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"Det andra alternativet — att reverse-engineera Protobuf-kodningen — ger mer exakt kontroll men slutar fungera när Google ändrar sitt interna format. Bibliotek som på GitHub använder Protobuf-avkodning för att slippa HTML-parsning helt, men det är en mer avancerad metod.
Steg 3: Starta webbläsaren och gå till Google Flights
Här är Playwright-installationen. Vi använder playwright-stealth för att minska risken att bli upptäckt redan från start.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Förinställ cookie-samtycke för att hoppa över popupen
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Vi kör headless i produktion (byt till headless=False vid felsökning), sätter en realistisk vy och user-agent, och förinställer SOCS-cookien för att hoppa över samtyckesrutan — mer om det i avsnittet om antibot-skydd.
Steg 4: Gå till sökresultaten
Ladda den byggda URL:en och vänta på att flygresultaten visas:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Vänta på att flygresultaten laddas
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Om du får timeout här betyder det oftast antingen att samtyckesrutan blockerade sidan (se cookie-lösningen i steg 3) eller att Google visar en CAPTCHA. Vi tar båda scenarierna i avsnittet om antibot-skydd.
Steg 5: Ladda alla flygresultat
Google Flights döljer fler resultat bakom knappen "Show more flights". Du behöver klicka på den upprepade gånger tills alla flyg är synliga:
1 # Klicka på "Show more flights" tills alla resultat är laddade
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakLoopen klickar på knappen, väntar 2 sekunder så att nya resultat hinner renderas, och avbryter när knappen inte längre syns. I mina tester har de flesta rutter 1–3 sidor med resultat.
Steg 6: Extrahera flygdata med CSS-selectors
Nu parsar vi den faktiska flygdatat från den laddade sidan. Här är selectors (verifierade i april 2026 — se underhållsavsnittet nedan för varför det datumet spelar roll):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Flygbolagets namn
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Avgångstid
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Ankomsttid
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Restid
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Mellanlandningar
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Pris
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2-utsläpp
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsVarning: klassnamn som pIav2d, sSHqwe och FpEdX genereras av Googles Closure Compiler och kan ändras när som helst. aria-label-selectors är betydligt stabilare. Jag går igenom en fullständig underhållsstrategi längre ner.
Steg 7: Spara resultaten till JSON eller CSV
Till sist sparar du den skrapade datan med en tidsstämpel (viktigt för prisbevakning senare):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Spara även som CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Skrapade {len(flights)} flyg")
25asyncio.run(main())Kör detta så får du en flights.json och flights.csv med resultaten. I mina tester brukar en SFO-JFK-sökning ge 30–80 flygalternativ och ta ungefär 15–20 sekunder att slutföra.
Överlevnadsguiden mot antibot-skydd i Google Flights
De flesta guider slutar här. Det är också här de flesta scrapers kraschar. Google lanserade , vilket slog ut nästan alla SERP-scrapers över en natt. Google beskriver det som "resultatet av tiotusentals arbetstimmar och investeringar på miljontals dollar." Google Flights bedöms som att skrapa.
Ingen konkurrentartikel går igenom detta på djupet, trots att det är den främsta orsaken till att scrapers slutar fungera. Här är vad du möter och hur du hanterar det.

Slumpmässiga pauser mellan anrop
Det enklaste försvaret mot rate limiting. Två rader kod, medelhög effekt:
1import time
2import random
3time.sleep(random.uniform(3, 7))Lägg detta mellan sidnavigeringar. Fasta intervaller (som exakt 5 sekunder varje gång) är en tydlig signal — slumpa tiden.
Rotation av User-Agent
Att skicka samma user-agent-sträng vid varje anrop är lätt att upptäcka. Rotera från en lista:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Bypass av headless-detektion
Google kontrollerar navigator.webdriver och andra automatiseringssignaler. Biblioteket playwright-stealth hanterar det mesta av detta, men du bör också använda startargumenten från steg 3. Viktiga flaggor:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Det här tar dig förbi grundläggande detektion. SearchGuard går djupare — den bevakar musrörelser, tangentbordsintervall och scrollmönster — men för scraping i måttlig volym räcker ofta stealth-läge tillsammans med realistiska pauser.
Proxyrotation: datacenter kontra residential
För allt mer än ett fåtal sökningar behöver du proxies. Skillnaden spelar stor roll:
Residential proxies är ungefär när du skrapar skyddade sajter. Leverantörspriser 2026: Smartproxy från 7 USD/GB, Bright Data 8,40 USD/GB, Oxylabs 8 USD/GB.
Lägg till en proxy i Playwright så här:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Hantering av popupen för cookie-samtycke
Användare nämner konsekvent popupen "I agree to terms" som ett hinder: "first google will show you the 'I agree to terms and conditions' popup." Den renaste lösningen är att förinställa SOCS-cookien (som visas i steg 3). Om det inte fungerar kan du klicka dig vidare:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # Ingen popup synligObservera: knapptexten varierar beroende på språk — "Alle akzeptieren" på tyska, "Tout accepter" på franska.
Snabbguide för antibot-skydd
| Teknik | Svårighetsgrad | Effekt | Kräver kod? |
|---|---|---|---|
| Slumpmässiga pauser (2–7 s) | Låg | Medel | 2 rader |
| Rotation av user-agent | Låg | Medel | 5 rader |
| Bypass av headless-detektion | Medel | Hög | Playwright startargument |
| playwright-stealth-plugin | Medel | 60–80% på enkla sajter | pip install |
| Proxyrotation (datacenter) | Medel | Medel | Konfiguration |
| Proxyrotation (residential) | Medel | 85–95% träffsäkerhet | Konfiguration |
| Förinställd cookie-samtycke (SOCS) | Låg | Krävs | 1 rad |
För rekommenderade säkra nivåer: håll 10–20 sekunders paus mellan anrop med IP-rotation. Googles trösklar ligger ungefär på 100 anrop per minut per IP innan du får en 429, och ihållande volymer över 1 000 anrop per dag och IP kan leda till tillfälliga blockeringar.
Varför dina Google Flights-selectors hela tiden går sönder (och hur du fixar det)
Det här är utan jämförelse den största huvudvärken. Forumtrådar är fulla av varianter av "allt jag får tillbaka är 14 tomma listor." Varje guide ger dig selectors. Ingen förklarar varför de slutar fungera.
Varför Google Flights-selectors ändras
Det beror på tre saker:
-
Obfuskering via Closure Compiler. Google använder för att generera klassnamn som
BVAVmfochYMlIzviagoog.setCssNameMapping(). De ändras vid varje build — ibland varje vecka. -
A/B-testning. Olika användare ser olika HTML-strukturer samtidigt. Din scraper kan fungera hos dig men misslyckas för någon i en annan region.
-
Språkliga skillnader. EU-användare ser andra termer, layouter och ibland även andra datafält än användare i USA.
Skriv robusta selectors
Föredra selectors som bygger på betydelse snarare än utseende:
1# Skör — går sönder vid varje build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# Mer robust — kopplad till tillgänglighetslabel
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Också robust — textbaserad matchning
6more_btn = page.locator('button:has-text("Show more flights")')Hierarki för selector-stabilitet (mest till minst stabil):
aria-label-attribut — kopplade till tillgänglighet, ändras sällandata-*-attribut — läggs till med avsikt för funktionalitetrole-attribut — ARIA-roller är semantiska- Textbaserade selectors — matchar synligt innehåll
- Delsträngsmatchning av klasser — t.ex.
[class*="price"] - Hela obfuskade klassnamn — undvik dessa om möjligt
Lägg till en valideringsfunktion
Låt inte trasiga selectors tyst ge tom data. Fånga det tidigt:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Saknar '{field_name}' — selectors kan behöva uppdateras"
11 )
12 valid = False
13 return validKör detta på varje skrapat flyg. Om du börjar se varningar är det dags att inspektera sidan och uppdatera dina selectors.
Strategi för selector-underhåll
- Kontrollera selectors varje månad, eller direkt när datakvaliteten sjunker
- Lägg selectors i en separat konfigurationsdictionary för enkla uppdateringar
- Selectors i den här artikeln verifierades senast: april 2026
- Överväg som ett alternativ — det använder Protobuf-avkodning i stället för CSS-selectors och kringgår problemet helt (även om det också kan bli bräckligt när Google ändrar interna dataformat)
Från engångsscraping till automatiserad prisbevakare för Google Flights
De flesta guider slutar vid "spara till JSON." Men rubriken för den här artikeln säger "Prisaviseringar." Dags att leverera.
![]()
Schemalägg din scraper så att den körs automatiskt
Alternativ 1: Python-biblioteket schedule (enklast, fungerar på alla plattformar):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Alternativ 2: cron-jobb (Linux/Mac):
1# Kör kl. 06 och 18 varje dag
20 6,18 * * * cd /path/to/scraper && python scraper.pyAlternativ 3: Windows Aktivitetsschema — skapa en enkel uppgift som kör python scraper.py enligt ditt önskade schema.
Nackdelen: alla dessa kräver en maskin som alltid är igång. Om du kör detta på en laptop som går i vila missar du körningar.
Spara historisk prisdata
Byt från att skriva över en JSON-fil till att lägga till rader i en SQLite-databas:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Efter en vecka med skrapning två gånger per dag har du tillräckligt med data för att börja se trender.
Analysera prisutvecklingen och sätt upp aviseringar
Hitta det billigaste alternativet i din historiska data:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Billigast: ${cheapest['price_usd']:.0f} den "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Trigga en e-postavisering när priset går under din gräns:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Prisfall! {route}: ${price:.0f} "
6 f"(under din gräns på ${threshold:.0f})"
7 )
8 msg["Subject"] = f"Flygdeal: {route} för ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# Efter varje skrapning, kontrollera om det finns deal
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Rekommenderad skrapfrekvens: två gånger om dagen räcker för privat prisbevakning (slumpmässig timing minskar upptäcktsrisken). Var 4–6 timme om du bevakar för ett företag. En gång i timmen bara under intensiva kampanjperioder, och bara tillfälligt.
Den enkla vägen: Thunderbits Scheduled Scraper
Om cron-jobb, en alltid igång-maskin och proxy-konfigurationer känns som mer infrastruktur än du vill underhålla, klarar Scheduled Scraper samma användningsfall utan allt det där. Du beskriver intervallet på vanlig svenska, anger dina Google Flights-URL:er, och scrapen körs automatiskt i Thunderbits molninfrastruktur — med inbyggd antibot-hantering och export direkt till . Det ersätter inte den fulla Python-lösningen (du tappar viss anpassning), men för just användningsfallet "jag vill ha ett kalkylblad för prisbevakning" är det snabbaste vägen. Du kan testa det i .
När Python är överkurs: No-code sätt att skrapa Google Flights
Efter att ha byggt allt ovan ska jag vara ärlig: det är ganska många rörliga delar. Alla behöver inte den här nivån av kontroll. Selectors går sönder, proxies måste roteras och cron-jobb måste övervakas. Om ditt mål är "få flygpriser in i ett kalkylblad regelbundet" finns snabbare alternativ.
Jämförelse: egen Python, API-tjänster eller Thunderbit
| Metod | Starttid | Kod krävs | Hanterar antibot | Schemaläggning | Kostnad |
|---|---|---|---|---|---|
| DIY Playwright (den här guiden) | 1–2 timmar | Python (medel) | Manuell konfiguration | Manuell (cron) | Gratis + proxykostnader |
| SerpApi Google Flights endpoint | 15 min | Endast API-anrop | Hanteras | Via API | ~50 USD+/mån |
| Thunderbit Chrome Extension | 2 min | Nej | Moln-scraping | Inbyggd schemaläggning | Gratis nivå finns |
En notis om SerpApi: Google och menade att deras förfrågningar ökade 25 000% på två år. Den juridiska osäkerheten är värd att ha i åtanke om du utvärderar API-leverantörer.
Så skrapar Thunderbit Google Flights
Öppna dina Google Flights-resultat i Chrome, klicka på Thunderbits knapp "AI Suggest Fields" — AI:n läser sidan och föreslår kolumner som flygbolag, pris, avgångstid och mellanlandningar — granska de föreslagna fälten och klicka på "Scrape." Resultaten visas i en tabell som du kan exportera till Excel, Google Sheets, Airtable eller Notion — allt i .
För just prisbevakning ersätter Thunderbits Scheduled Scraper och (som kan hantera 50 sidor samtidigt) hela infrastrukturen med cron + proxy + server.
Python ger dig full kontroll och obegränsad anpassning. Thunderbit ger dig snabbhet och minimalt underhåll. Välj utifrån vad du faktiskt vill uppnå. Om du vill lära dig mer om no-code-scraping, kolla in vår guide till .

Är det lagligt att skrapa Google Flights? Det här behöver du veta
Forumanvändare tar ofta upp detta: "scraping Google Flights directly violates the TOS that Google has." En rimlig oro — särskilt eftersom API:et har lagts ned och det inte finns något sanktionerat alternativ.
TOS-brott kontra juridiskt ansvar
Googles användarvillkor (uppdaterade 22 maj 2024) säger att användare inte får "access or use the Services or any content through the use of any automated means (such as robots, spiders or scrapers)." Att bryta mot villkoren är ett avtalsbrott (civilrättsligt) — det är inte samma sak som att bryta mot lagen.
Det viktiga rättsfallet: hiQ v. LinkedIn (Ninth Circuit, 2022) slog fast att scraping av offentligt tillgänglig data inte bryter mot Computer Fraud and Abuse Act (CFAA). Men målet slutade i förlikning, och Googles december 2025-stämning mot SerpApi bygger på en annan juridisk grund — DMCA Section 1201 (kringgående av tekniska skyddsåtgärder) — vilket potentiellt är allvarligare.
Bästa praxis för ansvarsfull scraping
- Begränsa takten — 10–20 sekunders paus med IP-rotation
- Skrapa inte personuppgifter — flygpriser är offentligt visad aggregerad data
- Kringgå inte CAPTCHA:er programmatiskt (det är här DMCA-risken ligger)
- Använd datan för egen research, inte för att bygga en konkurrerande kommersiell produkt utan rätt licens
- Överväg officiella API:er där sådana finns
Alternativa datakällor
Om scraping känns för riskabelt för ditt användningsfall finns legitima API-alternativ:
| Leverantör | Kostnad | Gratisnivå | Kommentar |
|---|---|---|---|
| SerpApi | 75–3 750 USD+/mån | 250 sökningar/mån | Direkt Google Flights-JSON (under juridisk granskning) |
| Kiwi Tequila | Gratis (affiliate-modell) | Obegränsat | Bra för startups och testning |
| Amadeus | Betala per användning | 2 000 anrop/mån | Över 400 flygbolag, bokningsstöd |
| Skyscanner | Anpassat | Kräver godkännande | 52 marknader, 30 språk |
Vi har skrivit en djupare genomgång av om du vill ha hela bilden.
Slutsats och viktigaste insikter
Det här var mycket. Här är det som spelar roll:
- Python + Playwright är det mest flexibla sättet att skrapa Google Flights, men det kräver löpande underhåll
- Antibot-skydd (pauser, rotation av user-agent, residential proxies) är inte valfritt — det är avgörande för driftsäkerhet, särskilt efter SearchGuard
- Selectors går ofta sönder — använd
aria-labeloch textbaserade selectors där det går, validera resultatet och ha ett underhållsschema - Automatisera med
scheduleeller cron för att göra en engångsscrape till en riktig prisbevakare med historik och e-postaviseringar - erbjuder ett no-code-alternativ med inbyggd schemaläggning, molnscraping och antibot-hantering — perfekt om målet är ett prisbevakningskalkylblad snarare än ett kodprojekt
- Respektera juridiska gränser — begränsa takten, skrapa bara offentliga data och överväg API-alternativ för kommersiell användning
Hämta koden från den här guiden, eller installera för snabbspåret. Oavsett vilket kommer du att bevaka flygpriser i stället för att manuellt uppdatera Google Flights.
För fler tekniker inom Python-scraping, kolla våra guider om och .
Vanliga frågor
1. Kan jag skrapa Google Flights utan Python?
Ja. API-tjänster som SerpApi och Kiwi Tequila ger strukturerad flygdata via API-anrop (ingen webbläsarautomation behövs). För en helt no-code-lösning kan skrapa Google Flights-resultat direkt från din webbläsare med AI-föreslagna fält och export med ett klick.
2. Blockerar Google flygskrapning?
Google använder botdetektion (SearchGuard), CAPTCHA:er och rate limiting. Med rätt antibot-åtgärder — slumpmässiga pauser, rotation av user-agent, residential proxies och stealth-inställningar i webbläsaren — kan du få tillförlitlig scraping i måttlig skala. Se avsnittet om antibot ovan för specifika tekniker och trösklar.
3. Hur ofta bör jag skrapa Google Flights för prisbevakning?
Två gånger per dag (vid slumpmässiga tider) räcker för privat bevakning och håller upptäcktsrisken låg. För affärsövervakning: var 4–6 timme med proxyrotation. Undvik scraping varje timme utom under korta kampanjperioder — det ökar risken markant att bli blockerad.
4. Finns det ett gratis Google Flights API?
Det officiella Google QPX Express API:et . Det finns ingen gratis officiell ersättare. Det närmaste gratisalternativet är (affiliate-modell, obegränsade sökningar). SerpApi erbjuder 250 gratis sökningar per månad. För de flesta användare är scraping eller ett no-code-verktyg som Thunderbit den praktiska vägen.
5. Varför ger mina CSS-selectors i Google Flights hela tiden tom data?
Google använder Closure Compiler för att generera obfuskade klassnamn som ändras vid varje build. A/B-testning och språkliga skillnader gör också att HTML-strukturen varierar mellan användare. Lösningen: använd aria-label-attribut och textbaserade selectors i stället för klassnamn, lägg till en valideringsfunktion som fångar problem tidigt och kontrollera dina selectors varje månad. Se avsnittet om selector-underhåll för en detaljerad strategi.
Läs mer