

De flesta guider om att scrapa eBay har ungefär tre månaders hållbarhet. Det vet jag, eftersom vårt team på Thunderbit har sett utvecklare fastna i trasiga kodsnuttar, gamla CSS-selektorer och ”fungerande” GitHub-repos som i tysthet slutade fungera för två eBay-omdesigner sedan.
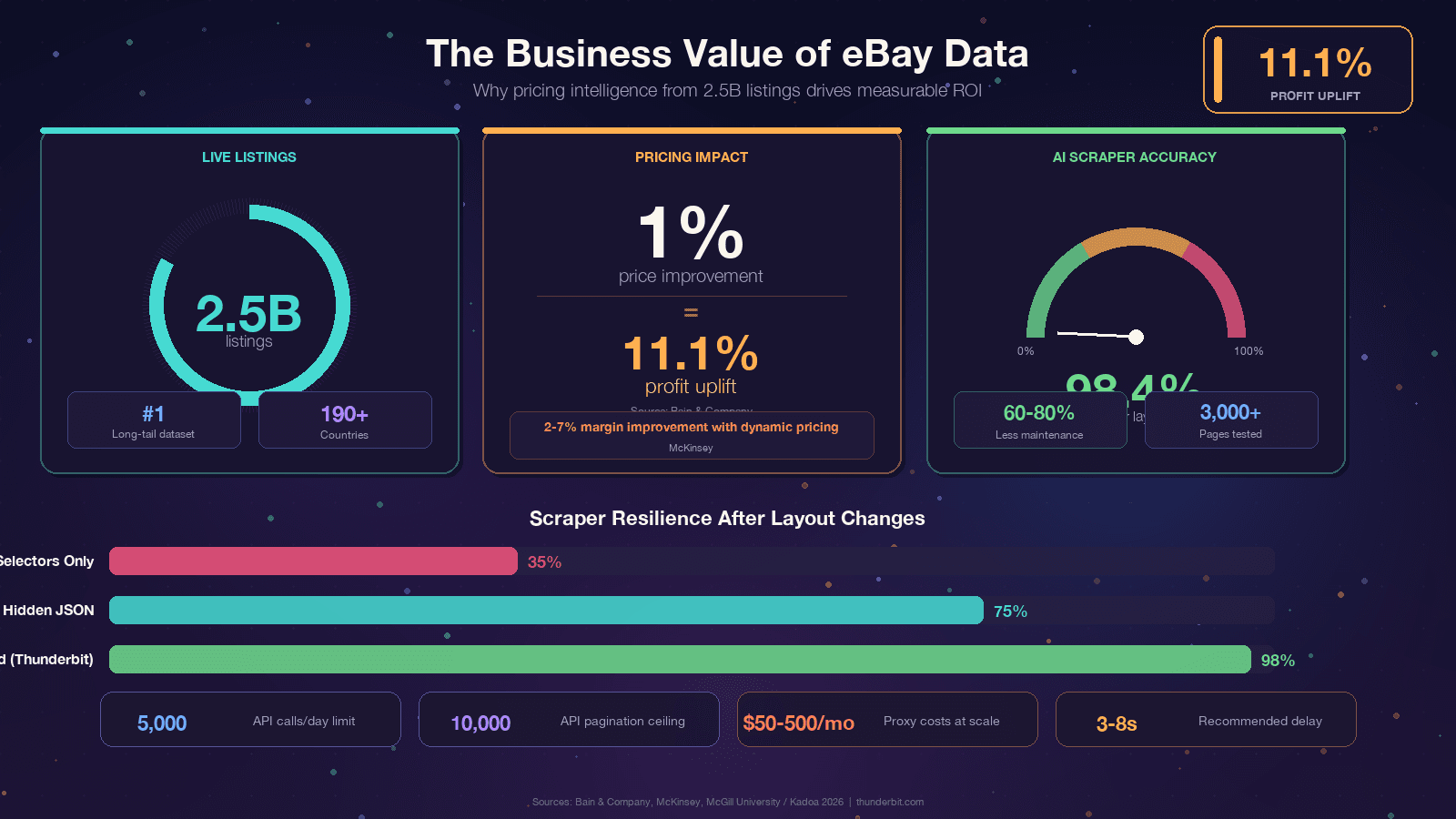
eBay sitter på cirka 2,5 miljarder aktiva annonser — den största datamängden för long-tail-prissättning på det öppna webben efter Amazon. Den datan driver allt från prisstrategi för återförsäljare till konkurrensanalys. Men att komma åt den programmatiskt är ett rörligt mål: eBays React-baserade frontend byter ut CSS-klassnamn, A/B-tester visar olika DOM-strukturer för olika användare, och Akamai Bot Manager står mellan dig och HTML-koden. Den här guiden ger dig Python-kod som fungerar idag, förklarar varför scrapers går sönder så att du kan bygga robustare lösningar, går ärligt igenom beslutet eBay API vs. scraping, och visar en no-code-lösning när Python inte är värt uppstarten.
Vad betyder det att scrapa eBay med Python?
Att webbscrapa eBay med Python innebär att skriva skript som programmatiskt laddar ner eBays webbsidor, tolkar HTML-koden (eller dold JSON) och plockar ut strukturerad data — titlar, priser, säljarinfo, försäljningsdatum, variantdetaljer — till ett format du faktiskt kan använda, som CSV, kalkylblad eller databas.
Du kan scrapa flera typer av eBay-sidor:
- Sökresultat (t.ex. alla annonser för ”AirPods Pro”)
- Enskilda produktsidor (fulla specifikationer, bilder, säljarinfo)
- Sålda/slutförda annonser (faktiska transaktionspriser och datum)
- Säljarprofiler och omdömen
Python är det självklara valet för det här arbetet. Ekosystemet — Requests, BeautifulSoup, lxml, pandas — gör det enkelt att hämta sidor, tolka HTML och bearbeta data. Det är dock skillnad på att scrapa webbplatsens HTML och att använda eBays officiella API — det tar vi upp härnäst.
Varför scrapa eBay? Verkliga användningsfall för affärsteam
Om du läser det här har du förmodligen redan ett syfte. Men det är ändå värt att förankra diskussionen i konkret affärsnytta, eftersom ROI:n från eBay-data verkligen är stark. Bain fann att en 1 % förbättring i realiserat pris motsvarar en vinstökning på 11,1 % över tusentals företag. McKinsey tillskriver upp till 5 % högre försäljning och 2–7 % bättre marginal till dynamisk prissättning inom retail.
De vanligaste användningsfallen jag ser:
| Användningsfall | Data som behövs | Affärseffekt |
|---|---|---|
| Prisbevakning & omprissättning | Aktiva annonspriser, frakt, skick | Konkurrenskraftig prissättning, skyddad marginal |
| Konkurrentanalys | Produktsortiment, kampanjer, fraktvillkor | Strategisk positionering, identifiering av sortimentsluckor |
| Marknadsanalys & trendspaning | Annonsvolym, kategoritrender, efterfrågemönster | Identifiering av nya produkter, prognoser för efterfrågan |
| Prisbedömning för återförsäljare | Sålda priser, försäljningsdatum, skick | Rätt marknadsvärde, köp-/budbeslut |
| Sentimentanalys | Recensioner, betyg, returpolicy | Insikter om produktkvalitet, kundnöjdhet |
| Leadgenerering | Säljarprofiler, butiksinfo, kontaktuppgifter | B2B-uppsök mot säljare med hög omsättning |
Det gemensamma temat: eBay har datan, men den är låst i webbsidor.
Scraping är hur du förvandlar den till en konkurrensfördel.
eBays officiella API vs. Python-webbscraping: Vad ska du välja?
Det här är frågan jag önskar att fler guider svarade ärligt på. eBay erbjuder officiella API:er — främst Browse API — och många undrar om de ska använda dem eller scrapa direkt. Svaret beror helt på vilken data du behöver.
| Kriterium | eBays Browse/Finding API | Python-webbscraping |
|---|---|---|
| Sålda/slutförda annonser | Begränsat — Marketplace Insights API finns, men åtkomst avslås ofta | Full åtkomst via URL-parametrar LH_Sold=1&LH_Complete=1 |
| Hastighetsgränser | 5 000 anrop/dag på basnivån | Hanteras själv (beroende på proxy) |
| Datafält | Fördefinierade (titel, pris, kategori, grundläggande säljarinfo) | Allt som syns på sidan (recensioner, fullständiga specifikationer, variantmatris) |
| Uppstartskomplexitet | OAuth 2.0, appregistrering, API-nycklar | pip install + kod |
| Stabilitet | Stabila endpoints | Går sönder när HTML ändras |
| Kostnad | Gratisnivå finns, betalt för större volymer | Gratis kod, men proxykostnader i skala |
| Variant-/MSKU-data | Delvis — ofta bara huvud-SKU | Fullt stöd (via parsing av dold JSON) |
| Sidnumreringens djup | Hårdtak på 10 000 artiklar | I teorin obegränsat |
En snabb notis: det gamla Finding API:t (som hade findCompletedItems) avvecklades helt i februari 2025. Om du använder ebaysdk-python eller något bibliotek som träffar Finding-modulen, så är det trasigt i produktion just nu.
Min rekommendation: Använd Browse API för stabila, måttliga och strukturerade katalogfrågor på aktiva annonser. Använd Python-scraping när du behöver sålda priser, recensioner, variantdata eller något fält som API:t inte exponerar. Många team använder båda.
Verktyg och bibliotek du behöver för att scrapa eBay med Python
Innan vi skriver kod, här är verktygslådan. Du behöver ingen headless browser för de flesta eBay-sidor — datan ligger inbäddad i den serverrenderade HTML-koden.
| Bibliotek | Syfte |
|---|---|
requests eller httpx | HTTP-klient för att ladda ner eBays sidor |
curl_cffi | HTTP-klient med riktig TLS-fingerprinting från webbläsare (avgörande för att kringgå Akamai) |
beautifulsoup4 | HTML-parser för extrahering via CSS-selektorer |
lxml | Snabb parser-backend för BeautifulSoup |
jmespath | Frågespråk för att tolka nästlad JSON |
pandas | Databearbetning och export till CSV/Excel |
gspread | Integration med Google Sheets |
Installera allt med ett enda kommando:
pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread
Använd Python 3.11+ — pandas 3.0 kräver 3.10+, och 3.11 ger 10–60 % snabbare prestanda i I/O-tunga arbetsflöden.
Ett bibliotek förtjänar särskild uppmärksamhet: curl_cffi är den enskilt största förbättringen en eBay-scraper kan få 2026. eBay använder Akamai Bot Manager, och Akamais främsta sätt att upptäcka bottar är TLS-fingerprinting. Vanliga requests skickar en Python-lik JA3-fingerprint som flaggas direkt. curl_cffi imiterar en riktig Chrome-webbläsares TLS-handshake, vilket klarar ungefär 90 % av Akamai-skyddade mål utan att du behöver en headless browser.
Testa Thunderbit för vilken webbplats som helst
Steg för steg: Så scrapar du eBay-sökresultat med Python
Det här är kärnguiden. Vi ska scrapa eBays sökresultatsidor för produktannonser.
- Svårighetsgrad: Nybörjare–Medel
- Tidsåtgång: Cirka 30 minuter för första fungerande scrape
- Det du behöver: Python 3.11+, biblioteken ovan, en terminal och en eBay-sök-URL
Steg 1: Skapa ditt Python-projekt
Skapa en projektmapp och installera beroenden:
mkdir ebay-scraper && cd ebay-scraper
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests curl_cffi beautifulsoup4 lxml pandas
Skapa en fil som heter scrape_ebay.py. Det är din arbetsyta.
Steg 2: Bygg eBays sök-URL
eBays sök-URL-struktur är enkel. Den viktigaste parametern är _nkw (keyword):
import urllib.parse
keyword = "airpods pro"
base_url = "https://www.ebay.com/sch/i.html"
params = {
"_nkw": keyword,
"_ipg": "120", # antal objekt per sida: 60, 120 eller 240 (240 kan trigga bot-flaggor)
"_pgn": "1", # sidnummer
}
url = f"{base_url}?{urllib.parse.urlencode(params)}"
print(url)
# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1
Andra användbara parametrar:
LH_BIN=1— endast Köp nu_sacat=175673— specifik kategori_sop=12— sortera efter bästa träff (10 = lägsta pris + frakt, 13 = nyligen upplagd)LH_Complete=1&LH_Sold=1— sålda/slutförda annonser (tas upp i ett särskilt avsnitt längre ner)
Steg 3: Skicka en förfrågan och hantera svaret
Det är här curl_cffi gör sitt jobb. En vanlig requests.get() ger ofta 403 från Akamai. Med curl_cffi låtsas vi vara en riktig Chrome-webbläsare:
from curl_cffi import requests as cffi_requests
import random, time
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
]
HEADERS = {
"User-Agent": random.choice(USER_AGENTS),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def fetch_page(url, max_retries=5):
delay = 2
for attempt in range(max_retries):
try:
r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
if r.status_code == 200:
return r.text
if r.status_code in (403, 429, 503):
retry_after = r.headers.get("Retry-After")
sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
print(f" Status {r.status_code}, försöker igen om {sleep_for:.1f}s...")
time.sleep(sleep_for)
delay *= 2
continue
r.raise_for_status()
except Exception as e:
print(f" Begäran misslyckades: {e}, försöker igen...")
time.sleep(delay)
delay *= 2
raise RuntimeError(f"Misslyckades efter {max_retries} försök: {url}")
Exponentiell backoff med jitter är viktig — fasta väntetider är i sig en bot-signatur.
Steg 4: Tolka produktannonserna från söksidan
eBay är just nu mitt i en migrering mellan två olika sökresultatslayouter. En robust scraper måste hantera båda:
| Fält | Gammal layout | Ny layout |
|---|---|---|
| Kortcontainer | li.s-item | li.s-card eller div.su-card-container |
| Titel | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Pris | span.s-item__price | .s-card__price |
Här är kod som klarar båda layouterna:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item, li.s-card, div.su-card-container")
results = []
for card in cards:
# Titel — prova båda layouterna
title_el = card.select_one(".s-item__title, .s-card__title")
title = title_el.get_text(strip=True) if title_el else None
# Hoppa över den tomma platshållarkortet "Shop on eBay"
if not title or "Shop on eBay" in title:
continue
# Pris
price_el = card.select_one("span.s-item__price, .s-card__price")
price = price_el.get_text(strip=True) if price_el else None
# URL
link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
url = link_el["href"].split("?")[0] if link_el else None
# Bild
img_el = card.select_one("img.s-item__image-img, .s-card__image img")
image = None
if img_el:
image = img_el.get("src") or img_el.get("data-src")
# Frakt
ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
shipping = ship_el.get_text(strip=True) if ship_el else None
results.append({
"title": title,
"price": price,
"url": url,
"image": image,
"shipping": shipping,
})
return results
Den där falska första kort-fällan är en klassisk miss. Det första li.s-item på många eBay-sökningar är en dold platshållare med titeln ”Shop on eBay” och inget riktigt pris. Filtrera alltid bort den.
Steg 5: Hantera sidnumrering för att scrapa flera sidor
eBay använder _pgn för sidnumrering. Länken till nästa sida använder a.pagination__next:
import urllib.parse
def scrape_ebay_search(keyword, max_pages=5):
all_results = []
for page_num in range(1, max_pages + 1):
params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scrapar sida {page_num}: {url}")
html = fetch_page(url)
results = parse_search_results(html)
if not results:
print(f" Inga resultat på sida {page_num}, stoppar.")
break
all_results.extend(results)
print(f" Hittade {len(results)} annonser (totalt: {len(all_results)})")
# Hänsynsfull paus — 3 till 8 sekunder med slump
time.sleep(random.uniform(3, 8))
return all_results
Den slumpmässiga pausen på 3–8 sekunder är inte valfri.
eBays Akamai-lager flaggar ihållande trafik över 1 begäran/sekund från en enda IP.
Steg 6: Exportera din data till CSV eller JSON
import pandas as pd
results = scrape_ebay_search("airpods pro", max_pages=3)
df = pd.DataFrame(results)
df.to_csv("ebay_airpods.csv", index=False)
df.to_json("ebay_airpods.json", orient="records", indent=2)
print(f"Exporterade {len(df)} annonser till CSV och JSON.")
Nu bör du ha ett rent kalkylblad med eBay-annonser. På min dator tog det cirka 45 sekunder att scrapa 3 sidor (360 annonser), inklusive pauser.
Så scrapar du eBays produktsidor med Python
Sökresultat ger dig en sammanfattning. Produktsidorna innehåller det viktiga: fullständiga beskrivningar, säljarens feedbackpoäng, objektspecifikationer, bildkaruseller och variantdata.
Tolka en enskild produktsida
eBays objektsidor ligger på /itm/<ITEM_ID>. Den mest stabila extraktionsvägen är JSON-LD — eBay bäddar in ett Product-schema som överlever nästan alla CSS-ändringar:
import json
def parse_item_page(html):
soup = BeautifulSoup(html, "lxml")
item = {}
# 1. JSON-LD — den mest stabila extraktionsvägen
for tag in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(tag.string or "")
except (json.JSONDecodeError, TypeError):
continue
if isinstance(data, dict) and data.get("@type") == "Product":
item["title"] = data.get("name")
item["brand"] = (data.get("brand") or {}).get("name")
item["images"] = data.get("image")
offers = data.get("offers") or {}
item["price"] = offers.get("price")
item["currency"] = offers.get("priceCurrency")
break
# 2. CSS-fallbacks för fält som inte finns i JSON-LD
def first_text(selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
item.setdefault("title", first_text([
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
]))
item["condition"] = first_text([
".x-item-condition-text .ux-textspans",
])
item["seller"] = first_text([
".x-sellercard-atf__info__about-seller a .ux-textspans",
])
item["shipping"] = first_text([
"div.ux-labels-values--shipping .ux-textspans--BOLD",
])
# 3. Objektspecifikationer
specifics = {}
for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
if k and v:
specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
item["specifics"] = specifics
return item
Mönstret här — JSON-LD först, CSS-fallbacks sedan — är nyckeln till att bygga scrapers som inte går sönder varje kvartal. Mer om det längre ner.
Scrapa eBays produktvarianter (MSKU-data)
Vissa eBay-annonser har flera varianter — olika färger, storlekar eller lagringskapacitet. Den synliga DOM:en visar bara ett prisintervall som ”899 till 1 099 dollar” tills användaren klickar på ett alternativ. Det faktiska priset per variant ligger i ett dolt JavaScript-objekt som kallas MSKU.
Det här är ett område där eBays API bara ger delvis data (parent SKU), vilket gör scraping till det bättre alternativet.
import re, json
def extract_variants(html):
# Icke-girig matchning är avgörande — girig .+ slukar hela sidan
m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
if not m:
return []
try:
msku = json.loads(m.group(1))
except json.JSONDecodeError:
return []
item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
skus = []
for combo_key, variation_id in msku.get("variationCombinations", {}).items():
option_ids = combo_key.split("_")
options = [item_labels.get(oid, oid) for oid in option_ids]
var = msku.get("variationsMap", {}).get(str(variation_id), {})
bin_model = var.get("binModel", {})
price_spans = bin_model.get("price", {}).get("textSpans", [{}])
price = price_spans[0].get("text") if price_spans else None
qty = var.get("quantity")
skus.append({
"options": options,
"price": price,
"quantity_available": qty,
"variation_id": variation_id,
})
return skus
Den där icke-giriga (.+?) i regexen är där varje eBay-scraper brukar falla. Girig .+ sväljer allt fram till sista "QUANTITY" på sidan, vilket ger trasig JSON. Jag har sett det här felet i minst tre ”fungerande” guider.
Så scrapar du eBays sålda och slutförda annonser med Python
Det här är användningsfallet som motiverar scraping framför API:t. Data om sålda varor — vad som faktiskt såldes, till vilket pris och på vilket datum — är guldstandarden för marknadsanalys, prisbedömning och återförsäljarstrategi. eBays Browse API ger uttryckligen inte detta. Marketplace Insights API gör det tekniskt sett, men åtkomsten är en ”Limited Release” som ofta avslås.
De URL-parametrar du behöver är LH_Complete=1 (slutförda annonser) och LH_Sold=1 (begränsa till faktiskt sålda). Du måste ange båda. Bara LH_Sold=1 faller i vissa kategorier tyst tillbaka till aktiva annonser — det här är den vanligaste fallgropen i communityn.
def scrape_sold_listings(keyword, max_pages=3):
all_sold = []
for page_num in range(1, max_pages + 1):
params = {
"_nkw": keyword,
"_ipg": "120",
"_pgn": str(page_num),
"LH_Complete": "1",
"LH_Sold": "1",
}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scrapar såld sida {page_num}...")
html = fetch_page(url)
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item")
for card in cards:
title_el = card.select_one(".s-item__title")
title = title_el.get_text(strip=True) if title_el else None
if not title or "Shop on eBay" in title:
continue
# Inkludera bara faktiskt sålda objekt (grön POSITIVE-markering)
sold_tag = card.select_one(
".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
)
if sold_tag is None:
continue # Slutförd men osåld annons — hoppa över
price_el = card.select_one("span.s-item__price")
price = price_el.get_text(strip=True) if price_el else None
# Tolka försäljningsdatum
sold_date = None
import re, datetime as dt
card_text = card.get_text()
m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
if m:
sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
link_el = card.select_one("a.s-item__link[href]")
url = link_el["href"].split("?")[0] if link_el else None
all_sold.append({
"title": title,
"sold_price": price,
"sold_date": sold_date,
"url": url,
})
if not cards:
break
time.sleep(random.uniform(3, 8))
return all_sold
Den viktiga skillnaden i HTML: sålda objekt visar priset i grönt (inne i en .POSITIVE-wrapper), medan osålda slutförda annonser visar priset i rött med överstrykning. Filtrera alltid på .POSITIVE-klassen.
Varför eBay-scrapers går sönder (och hur du bygger robusta sådana)
Om din eBay-scraper slutade fungera är du i gott sällskap. Det här är problem nummer ett i varje eBay-scrapingtråd jag har läst. Frågan är inte om din scraper går sönder — utan när.
Varför det händer:
- eBay använder React-baserad rendering med dynamiskt genererade klassnamn som ändras vid deployment
- A/B-tester serverar olika DOM-strukturer till olika användare (den dubbla
s-item/s-card-layouten är ett levande exempel just nu) - Periodiska omdesigns ändrar HTML-strukturen även när datan är densamma
- Gamla selektorer som
#itemTitleoch#prcIsumtogs bort för flera år sedan men dyker fortfarande upp i guider
Som Scrapflys 2026-guide uttrycker det: ”Den verkliga utmaningen med eBay-webbscraping är att hantera eBays ändringar i CSS-selektorer. eBay uppdaterar sin frontend regelbundet, vilket bryter scrapers som förlitar sig på specifika klassnamn.”
Strategier för långlivade eBay-scrapers
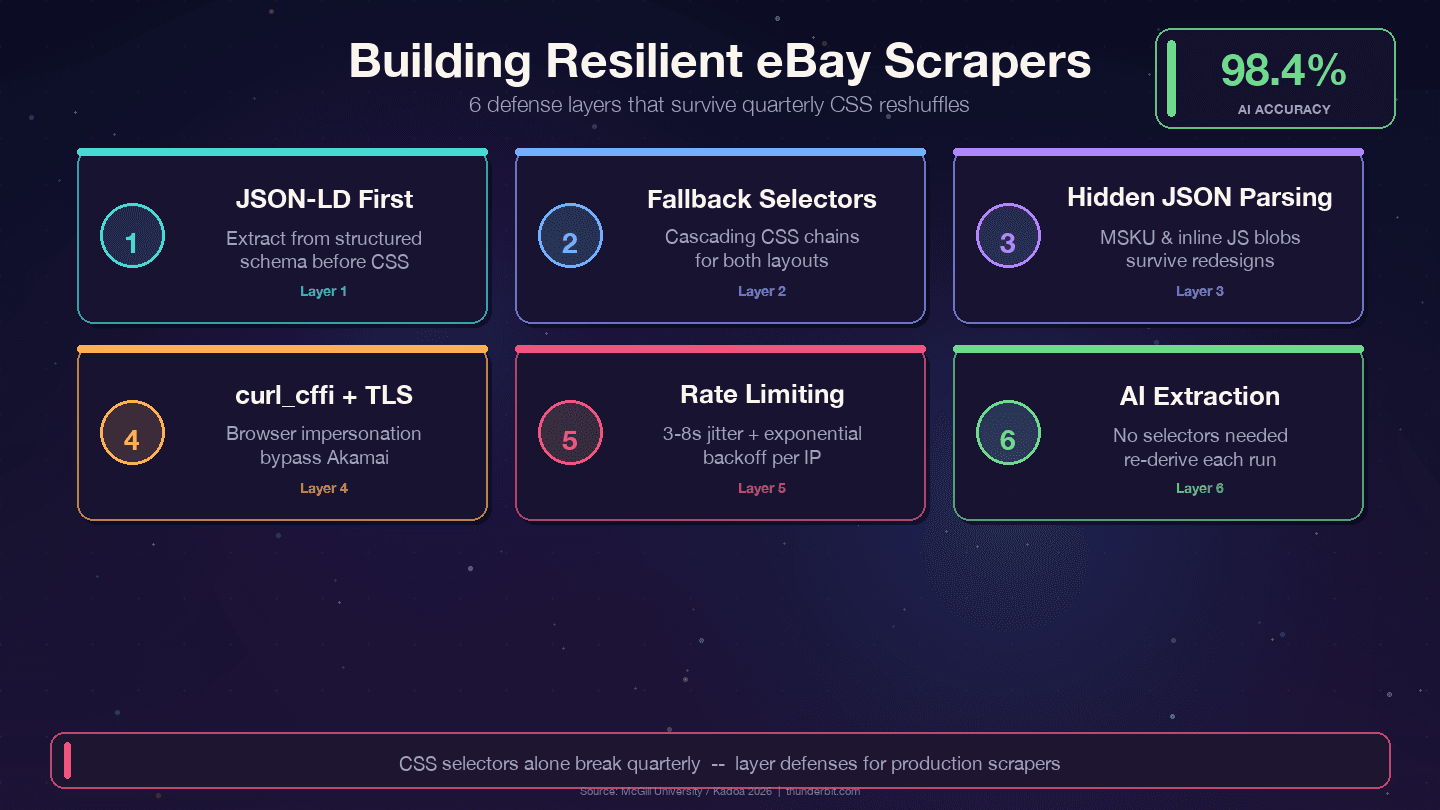
Fyra strategier som överlever eBays kvartalsvisa ommöbleringar:
1. Prioritera JSON-LD framför CSS-selektorer. eBay bäddar in strukturerad Product-schema-data på varje objektsida. Datalagret förändras mycket mindre än presentationslagret — designers refaktorerar CSS-klasser varje kvartal, men backendfält som price, name och seller mappas till interna API:er och byter sällan namn.
2. Använd flera fallback-selektorer. Lita aldrig på bara en CSS-selektor. Ha alltid alternativ:
def first_text(soup, selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
title = first_text(soup, [
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
"[data-testid='x-item-title'] h1",
])
3. Tolka dolda JSON-block. MSKU-objektet för varianter och inbäddad JavaScript-data överlever CSS-ändringar eftersom de genereras på serversidan. Regex-extraktion från <script>-taggar kräver mer arbete i början men minskar underhållet kraftigt.
4. Logga när selektorer misslyckas. Lägg in övervakning så att du vet när en selektor slutar matcha, inte bara att datan blev tom:
if title is None:
print(f"VARNING: titel-selektorn misslyckades för {url}")
5. Använd curl_cffi med webbläsarimpersonation. Det hanterar Akamais TLS-fingerprinting utan att du behöver en headless browser.
AI-drivet alternativ: inget selektorunderhåll
Om du tröttnat på att lappa selektorer varannan månad finns det ett fundamentalt annat angreppssätt. Verktyg som Thunderbit använder AI för att läsa sidan på nytt varje gång och härleda extraktionslogiken dynamiskt. En studie från McGill University testade AI mot selektorbaserade scrapers över 3 000 sidor och fann att AI-metoder höll 98,4 % noggrannhet även efter layoutändringar, med branschjämförelser som pekar på 60–80 % lägre underhållsbehov.
| Metod | Går sönder när eBay ändrar HTML? | Underhållsarbete |
|---|---|---|
| Hårdkodade CSS-selektorer | Ja, varje kvartal | Högt — löpande patchning |
| Dold JSON / JSON-LD-extraktion | Sällan | Lågt |
| AI-baserad scraping (Thunderbit) | Nej — AI:n härleder selektorer varje körning | Inget |
Scrapa eBay-data med AI Get Started Free
Jag går igenom Thunderbit-flödet mer detaljerat längre fram. För stunden: om du bygger en scraper som ska köras i månader bör du satsa på JSON-först-extraktion och fallback-selektorer. Om du inte vill underhålla selektorer alls är AI-vägen väl värd att titta på.
Automatisera återkommande eBay-scrapes för prisbevakning
En engångsscrape är användbar. Men prisbevakning, lageruppföljning och konkurrentanalys kräver återkommande datainsamling. Varje konkurrentartikel jag har läst nämner prisbevakning som ett användningsfall, men nästan ingen visar hur man faktiskt automatiserar det.
Alternativ 1: Cron-jobb (Linux/macOS) eller Aktivitetsschemaläggaren (Windows)
Det enklaste sättet. Lägg ditt Python-skript i ett cron-jobb. Använd alltid den absoluta sökvägen till din venv:s Python — cron kör med en minimal miljö:
crontab -e
# Dagligen kl 08:15
15 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1
På Windows använder du PowerShell:
$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
$T = New-ScheduledTaskTrigger -Daily -At 8:15am
Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T
Det här kräver en dator som alltid är igång, och du hanterar proxies och anti-bot-skydd själv.
Alternativ 2: Cloud Functions (serverless)
AWS Lambda eller Google Cloud Functions låter dig köra scrapers utan en dedikerad server. Högre uppstartskrav — du måste paketera beroenden, hantera timeouts (Lambda stoppar vid 15 minuter) och fortfarande sköta proxies. Men ingen serverdrift.
Alternativ 3: No-code-schemaläggning med Thunderbit
Thunderbits funktion Scheduled Scraper låter dig beskriva intervallet med vanlig text (t.ex. ”varje dag kl. 8”), mata in eBay-URL:er och klicka på Schema. Den kör i molnet med inbyggt anti-bot-skydd.
| Metod | Uppstartsstorlek | Behöver server? | Hantera anti-bot? |
|---|---|---|---|
| Cron + Python-skript | Medel | Ja (alltid på) | Du sköter proxies |
| Cloud function (Lambda) | Hög | Nej (serverless) | Du sköter proxies |
| Thunderbit Scheduled Scraper | Låg (beskriv med ord) | Nej (molnbaserat) | Inbyggt |
För att lagra återkommande scrape-data är en lokal SQLite-databas rätt val för prishistorik. Använd ON CONFLICT ... DO UPDATE (inte INSERT OR REPLACE, som förstör foreign keys och rensar kolumner):
CREATE TABLE IF NOT EXISTS listings (
item_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
last_price REAL,
first_seen_at TEXT DEFAULT (datetime('now')),
last_seen_at TEXT DEFAULT (datetime('now'))
);
CREATE TABLE IF NOT EXISTS price_history (
item_id TEXT NOT NULL,
observed_at TEXT NOT NULL DEFAULT (datetime('now')),
price REAL NOT NULL,
PRIMARY KEY (item_id, observed_at)
);
Testa Thunderbits Scheduled Scraper
Vill du inte koda? Så scrapar du eBay på 2 minuter med Thunderbit
Jag har ägnat 2 000 ord åt Python-kod. Nu vill jag vara ärlig med när du inte behöver den.
Om du är en affärsanvändare som gör engångsmarknadsresearch, en återförsäljare som jämför comps, eller ett ecommerce-team som behöver data idag utan ett utvecklingssprint, är Python överkurs. Uppstarten, underhållet av selektorer, proxyhanteringen — det är mycket overhead för ”jag behöver bara de här 200 annonserna i ett kalkylblad”.
Så scrapar Thunderbit eBay (steg för steg)
- Installera Thunderbit Chrome Extension — inget kreditkort krävs.
- Öppna valfri eBay-sökresultatsida eller produktsida i Chrome.
- Klicka på ”AI Suggest Fields” i Thunderbit-sidopanelen. AI:n läser sidan och föreslår kolumner: Titel, Pris, Skick, Frakt, Säljare, Betyg.
- Klicka på ”Scrape.” Tillägget går igenom pagineringen och fyller datatabellen. För eBay finns dessutom färdiga instant scraper-mallar som fungerar med ett klick.
- Exportera till Google Sheets, Airtable, Notion, CSV, JSON eller Excel — gratis.
Hela processen tar under 2 minuter.
Jag mätte det.
Berikning av undersidor: få data från detaljsidor utan extra kod
Efter att ha scrapat en sökresultatsida kan Thunderbit besöka varje annons detaljsida och lägga till fler fält — fullständiga specifikationer, säljarinfo, beskrivning, alla bilder. Det ersätter de 20+ rader Python-kod för att scrapa undersidor som vi skrev tidigare med ett enda klick.
När Python fortfarande är rätt val
Python vinner när du behöver:
- Scraping i stor skala (tiotusentals sidor per körning)
- Djupt anpassad parserlogik eller datatransformation
- Integration i befintliga datapipelines (Airflow, dbt, Kafka)
- Finmaskig kontroll över TLS/sessioner för avancerat anti-bot-arbete
- Enhetskostnad — i miljontals rader vinner en underhållen stack över kreditbaserad SaaS
För de flesta engångs- eller mellanstora projekt är Thunderbit snabbare och enklare. För produktionspipelines i stor skala ger Python dig full kontroll.
Tips för att undvika att bli blockerad när du scrapar eBay med Python
eBays Akamai-lager är på riktigt. Det som faktiskt fungerar i praktiken:
- Använd
curl_cffimedimpersonate="chrome124"— den största förbättringen jämfört med vanligarequests - Rotera User-Agent-strängar från en lista med aktuella webbläsarversioner (Chrome 143, Firefox 124, Safari 26)
- Lägg in slumpmässiga fördröjningar på 3–8 sekunder mellan förfrågningar — fasta intervaller är en fingerprint
- Använd residential- eller roterande proxies för allt över några dussin sidor. Datacenter-IP:er (AWS, GCP, DigitalOcean) flaggas snabbt av Akamai.
- Respektera
robots.txt— de flesta filtrerade browse-URL:er är uttryckligen förbjudna; objektsidor (/itm/<id>) är det inte - Hantera CAPTCHA på ett smidigt sätt — upptäck dem och försök igen med en annan IP, eller använd en CAPTCHA-lösningstjänst
- Belasta inte servern för hårt. Prejudikatet eBay v. Bidder's Edge säger att trespass to chattels kan tillämpas när scraping faktiskt försämrar servrar. Håller du dig runt 1 begäran/sekund per IP ligger du långt under den gränsen.
För kommersiell användning i hög volym: överväg att använda Browse API för aktiva annonser och bara scrapa riktat för sålda comps och data som API:t inte exponerar. Den hybriden är renare både tekniskt och juridiskt.
Är det lagligt att scrapa eBay med Python?
Jag är inte jurist, och det här blogginlägget är inte juridisk rådgivning. Så jag håller det kort.
Den juridiska utvecklingen har rört sig i riktning mot scraping av offentligt tillgänglig data. De viktigaste prejudikaten:
- hiQ v. LinkedIn (9:e kretsen, 2022): scraping av offentligt tillgänglig data bryter inte mot CFAA
- Van Buren v. United States (US Supreme Court, 2021): snävade in CFAA:s ”exceeds authorized access”-bestämmelse
- Meta v. Bright Data (N.D. Cal., 2024): scraping utloggat bryter inte mot plattformens användarvillkor eftersom scrapen inte är en ”användare”
Med det sagt förbjuder eBays uppdatering av användaravtalet i februari 2026 uttryckligen ”buy-for-me-agents, LLM-drivna bottar eller något end-to-end-flöde som försöker lägga beställningar utan mänsklig granskning.” Gränsen är tydlig: read-only-scraping av offentliga sidor står starkt; att automatisera checkout gör det inte.
Bästa praxis: scrapa bara offentligt synlig data. Skapa inte fejkade konton och kringgå inte inloggningsväggar. Återförsälj inte upphovsrättsskyddade annonsbilder i bulk. Och rådfråga jurist vid kommersiella projekt i större skala.
Slutsats och viktigaste lärdomar
Python är det mest flexibla sättet att scrapa eBay, men det kräver löpande underhåll när webbplatsens HTML ändras. Beslutsramen är:
- Använd eBays Browse API för stabila, måttliga och strukturerade frågor om aktiva annonser
- Använd Python-scraping för sålda annonser, recensioner, variantdata och allt API:t inte exponerar
- Använd Thunderbit om du vill ha eBay-data utan att skriva eller underhålla kod
Koden i den här guiden prioriterar robusthet: JSON-LD först, flera CSS-fallbacks sedan, dold JSON-parsing för varianter. Det lager-på-lager-upplägget gör att din scraper inte dör nästa gång eBays frontend-team släpper en omdesign.
Om du vill testa no-code-vägen kan Thunderbits gratisnivå låta dig prova direkt på eBay-sidor. Och om du vill se hur eBay-scraper-mallen fungerar är det bara ett klick bort.
För mer om verktyg för webbscraping, kolla in våra guider om bästa automatiserade verktyg för webbscraping, scrapa data från webbplatser till Excel och bästa Python-verktygen för webbscraping. Du kan också se tutorials på Thunderbits YouTube-kanal.
Testa Thunderbit för eBay-scraping Get Started Free
Vanliga frågor
1. Kan jag scrapa eBay gratis med Python?
Ja. Alla bibliotek (Requests, BeautifulSoup, curl_cffi, pandas) är gratis och öppen källkod. Kostnaderna kommer i skala — residential proxies för scraping i hög volym kostar normalt 50–500 USD/månad beroende på bandbredd. För små projekt (några hundra sidor) kan du scrapa från din hem-IP med försiktig rate limiting.
2. Hur scrapar jag eBays sålda objekt och slutförda annonser med Python?
Lägg till LH_Complete=1&LH_Sold=1 i sök-URL:ens parametrar. Du måste ange båda — LH_Sold=1 ensam faller i vissa kategorier tyst tillbaka till aktiva annonser. Filtrera resultaten genom att kontrollera .POSITIVE-klassen på pris-elementet, vilket visar att det faktiskt är en försäljning och inte en osåld utgången annons.
3. Blockerar eBay webbscraping?
eBay använder Akamai Bot Manager, som främst upptäcker scrapers genom TLS-fingerprinting och beteendeanalys. Vanliga requests-anrop får ofta 403-svar. Med curl_cffi och webbläsarimpersonation, roterande User-Agents och 3–8 sekunders slumpmässiga pauser mellan begärningar klarar du de flesta blockeringar. Residential proxies hjälper i större skala.
4. Ska jag använda eBays API eller webbscraping?
Använd Browse API för stabila frågor i måttlig volym om aktiva annonser (upp till 5 000 anrop/dag). Använd scraping när du behöver historik över sålda priser, fullständig variant-/MSKU-data, recensioner eller något fält som API:t inte exponerar. Marketplace Insights API ger tekniskt sett såld data, men åtkomsten är begränsad och avslås ofta.
5. Vad är det enklaste sättet att scrapa eBay utan kod?
Thunderbit Chrome Extension använder AI för att läsa eBay-sidor, föreslå datakolumner och extrahera annonser med ett klick. Den hanterar paginering, berikning av undersidor och export till Google Sheets, Excel, Airtable eller Notion. Färdiga eBay-scraper-mallar gör det ännu snabbare för vanliga behov.
Läs mer




