
Vissa samlar på frimärken. Andra samlar sneakers. Men om du jobbar med sälj, marknadsföring, e-handel eller drift 2025 är chansen stor att du samlar på något lite mer… digitalt: webbdata. Och det är inte småpotatis heller—företag lägger i snitt 5 miljoner dollar per år på att samla in webbdata, och web scraping har blivit ett självklart standardverktyg i allt från strategi till kundservice ().
När efterfrågan bara fortsätter att explodera dyker två namn upp i nästan varje Python-guide och i massor av dataprojekt: playwright och selenium. Båda började som verktyg för webbläsarautomatisering inom testning, men har i praktiken blivit förstahandsvalet för den som vill göra webben till strukturerad, användbar data. Men här är grejen: valet mellan dem är inte bara tekniskt—det handlar om att välja rätt verktyg för dina faktiska behov. Och om du inte är utvecklare, eller bara vill ha resultat snabbt, finns det en ännu enklare väg (ledtråd: den kräver inte en enda rad Python). Nu kör vi.
Från testverktyg till web scraping-motorer: Playwright och Selenium förklarade
Vi tar det från början. selenium har funnits sedan 2004 och är den beprövade klassikern inom webbläsarautomatisering. Det byggdes från start för QA-testare och låter dig styra webbläsare som Chrome, Firefox och till och med Internet Explorer (för den som gillar att leva lite farligt). playwright klev in 2020, med Microsoft i ryggen, och tog ett mer modernt grepp—tänk Seleniums yngre, snabbare syskon.
Båda verktygen låter dig skriva skript (ofta i Python) som öppnar en webbläsare, går till en webbplats, klickar på knappar, fyller i formulär och—viktigast för oss—hämtar ut data. Trots att de har sina rötter i automatiserad testning har de blivit ryggraden i web scraping för allt från prisbevakning till leadgenerering (). Och det är inte bara utvecklare som använder dem: allt fler affärsanvändare försöker bygga egna python scraper-lösningar, eller åtminstone komma igång.
Men när du skrapar data skiftar prioriteringarna. Du bryr dig mindre om testtäckning och mer om att få ut data stabilt, undvika blockeringar och slippa lägga helgen på att felsöka Python-fel. Det är här de verkliga skillnaderna mellan playwright och selenium blir tydliga.
Viktigaste skillnaderna: Playwright vs. Selenium för web scraping

Rakt på sak: både playwright och selenium kan skrapa webbplatser, men de glänser i olika lägen.
- selenium är veteranen. Det funkar med nästan alla webbläsare och språk, har en enorm community och passar bra för äldre, mer statiska webbplatser med förutsägbara layouter.
- playwright är den moderna uppstickaren. Det är byggt för dagens dynamiska, JavaScript-tunga sajter, med inbyggt stöd för inloggningar, popups, oändlig scroll och mer. Dessutom är det snabbare och ofta enklare att komma igång med, särskilt för Python-användare.
Men vi nöjer oss inte med snack—vi tar det punkt för punkt.
Jämförelsetabell: Playwright vs. Selenium
| Funktion | Selenium | Playwright |
|---|---|---|
| Språkstöd | Python, Java, C#, JS, Ruby, fler | Python, JS/TS, Java, C# |
| Webbläsarstöd | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Komplexitet vid installation | Kräver webbläsardriver, manuell konfiguration | Ett kommando installerar allt |
| Hastighet/prestanda | Långsammare, mer resurskrävande | 40–50% snabbare, async/parallellt som standard |
| Hantering av dynamiskt innehåll | Manuella väntetider, mer kod behövs | Auto-väntar, klarar JS-tunga sajter enkelt |
| Anti-bot/undvika upptäckt | Lättare att upptäcka, kräver tillägg | Inbyggd stealth, bättre på att efterlikna användare |
| Felsökningsverktyg | Grundläggande (Selenium IDE, skärmdumpar) | Inspector, videoinspelning, codegen |
| Community & stöd | Enormt, moget, massor av guider | Växer snabbt, modern dokumentation, aktivt utvecklat |
| Arbetsflöde för Python Scraper | Mer setup, mer boilerplate | Smidigare, mindre kod, enklare för nybörjare |
Välj rätt verktyg: När ska du använda Playwright eller Selenium för web scraping?
Så vilket ska du välja till nästa projekt? Här är min take, efter år av att bygga automationslösningar och hjälpa team att få ut data från webbens vilda västern.
- selenium passar dig om:
- Sajten du skrapar är ”old school”—statisk HTML, lite JavaScript och inga avancerade popups.
- Du måste stödja udda webbläsare (hej, Internet Explorer) eller integrera med äldre system.
- Du vill luta dig mot en gigantisk community och oändligt med StackOverflow-svar.
- Du redan kan selenium från testprojekt.
- playwright är rätt val om:
- Sajten är modern, dynamisk och full av JavaScript (tänk e-handel, sociala medier eller allt som får datorfläkten att gå igång).
- Du behöver logga in, klicka mellan flikar, hantera oändlig scroll eller popups.
- Du vill komma igång snabbt, med mindre konfiguration och mindre kod.
- Du är trött på att skriva
time.sleep(5)överallt och vill att verktyget sköter tajmingen.
En enkel tumregel: om ditt första försök med selenium mest består av ”varför laddar inte det här?”, då är det ofta dags att testa playwright.
Selenium för web scraping: Styrkor och begränsningar
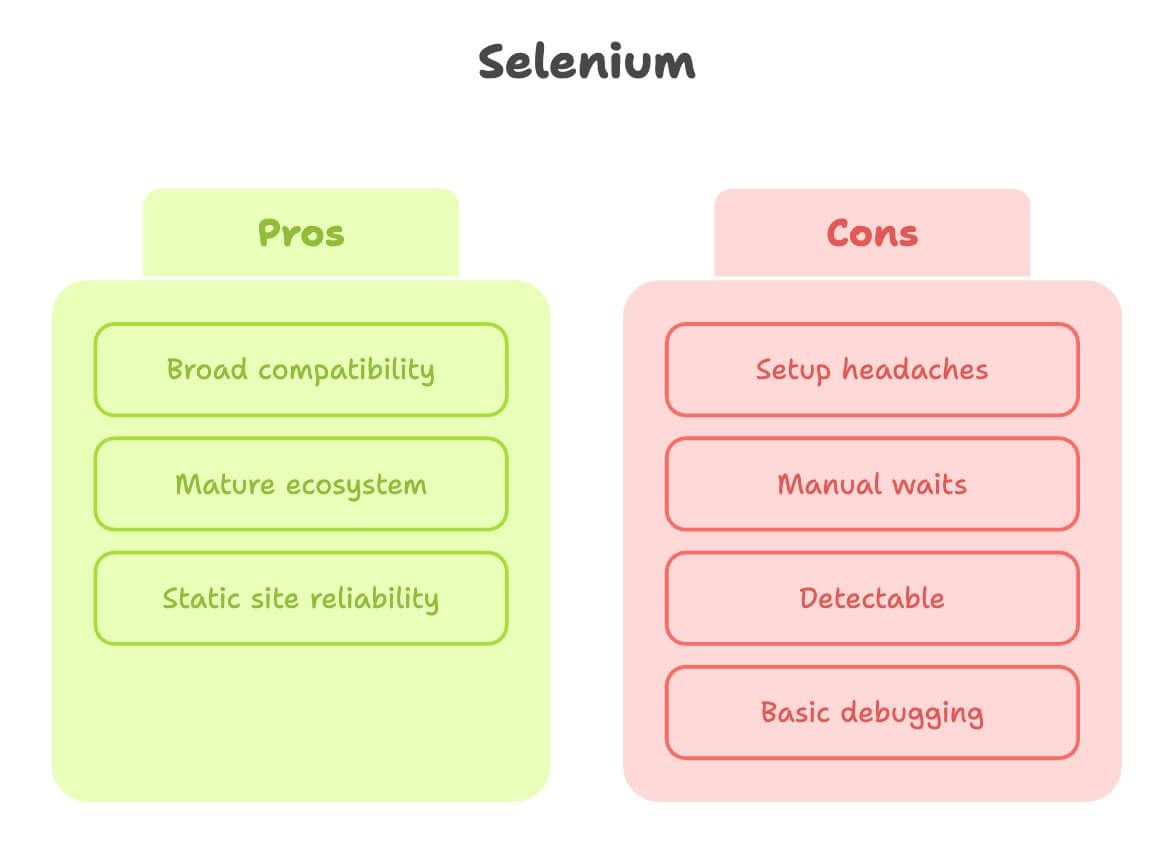
selenium förtjänar sin plats. Det är urfadern till webbläsarautomatisering och för många skrapjobb funkar det riktigt bra.
Styrkor:
- Bred kompatibilitet: Funkar med nästan alla webbläsare och språk.
- Moget ekosystem: Massor av guider, Q&A och plugins.
- Starkt för statiska sajter: Om sidan inte förändras så mycket är selenium stabilt.
Begränsningar:
- Strulig setup: Du måste ladda ner och konfigurera en webbläsardriver (som ChromeDriver) och hålla den uppdaterad. Nybörjare fastnar ofta här ().
- Manuella väntetider: Dynamiskt innehåll? Då blir det många explicita waits eller, ännu värre, slumpmässiga sleep-rader.
- Lättare att upptäcka: Många sajter kan känna igen selenium-styrda webbläsare och blockera dem, särskilt i molnmiljö.
- Enkel felsökning: Ingen inbyggd videoinspelning eller interaktiv inspector.
Kort sagt: selenium är perfekt för enkla, stabila sajter—men kan kännas som att rulla en sten uppför en backe på moderna, interaktiva sidor.
Playwright för web scraping: Styrkor och begränsningar
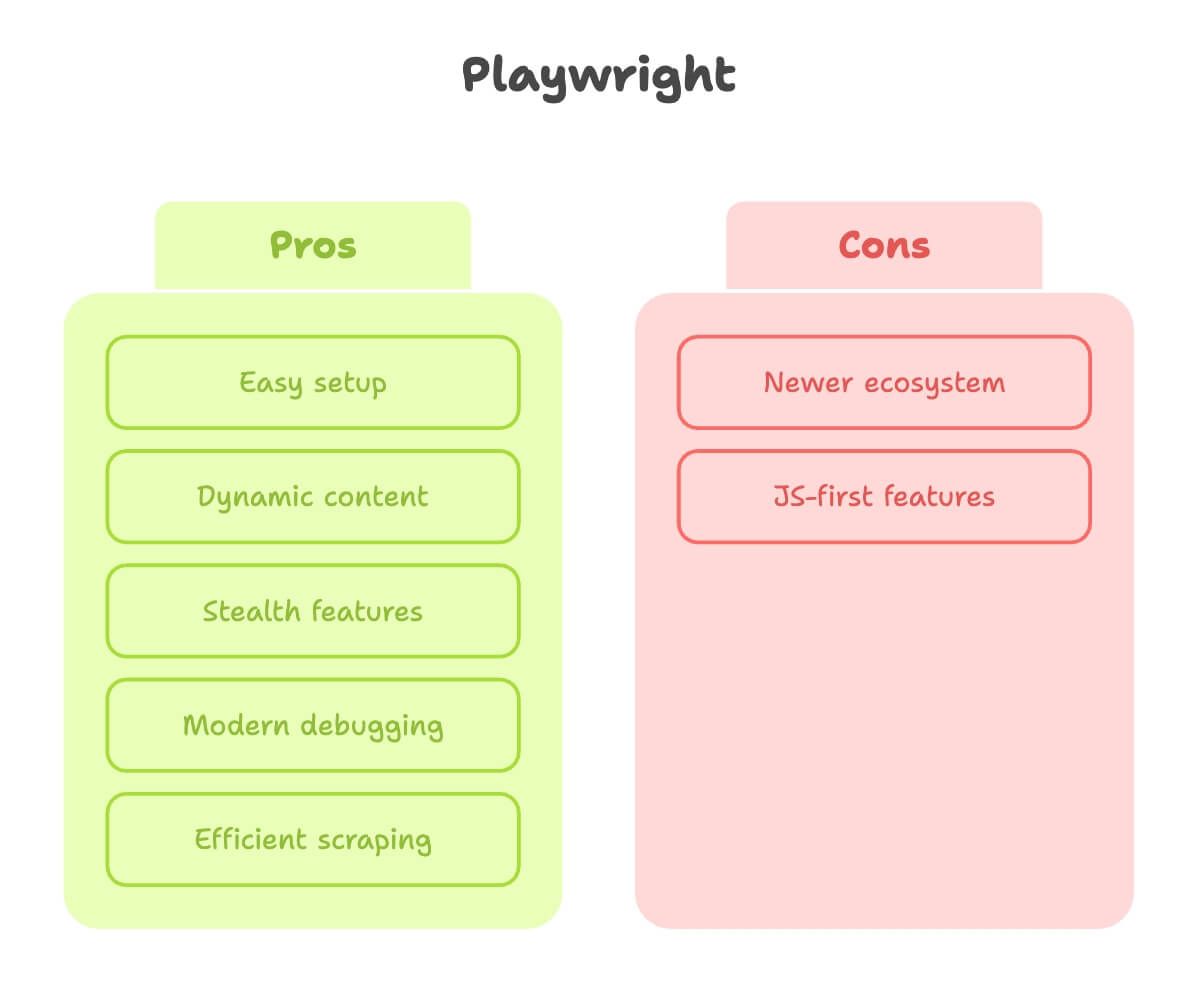
playwright då? Efter att ha jobbat mycket med båda kan jag säga att playwright känns som att det är byggt av personer som faktiskt har lidit av web scraping i praktiken.
Styrkor:
- Enkel installation: En pip-installation, ett kommando, och du är igång. Inget driver-krångel.
- Klarar dynamiskt innehåll: Auto-väntar på element, så du slipper gissa när sidan är redo ().
- Stealth-funktioner: Efterliknar riktiga användare bättre, med inbyggt stealth-läge och stöd för flera contexts (bra om du vill skrapa som flera ”användare” samtidigt).
- Modern felsökning: Inspector, videoinspelning och till och med kodgenerering från dina manuella klick.
- Snabbare och effektivare: Särskilt när du skrapar många sidor eller kör parallellt.
Begränsningar:
- Nyare ekosystem: Något färre guider, även om gapet minskar snabbt.
- Vissa funktioner är JS-först: Det mesta funkar i Python, men ibland är dokumentationen tydligare i JS.
Slutsats: playwright är mitt förstaval för allt som är ens lite dynamiskt, eller när jag vill få resultat snabbt utan att bråka med installationen.
Anti-bot och blockeringar: Vilken Python Scraper klarar moderna sajter bäst?
Vi tar elefanten i rummet: att bli blockerad. Vid web scraping är det svåraste ofta inte koden—utan att se till att sajten inte stänger dörren.
- selenium: Direkt ur lådan är det lättare att upptäcka. Sajter kan se
webdriver-flaggan, headless user agents och andra tydliga signaler. Det finns lösningar (som undetected-chromedriver), men de kräver extra setup och ligger ständigt steget efter anti-bot-teknik (). - playwright: Har inbyggda stealth-funktioner, som att dölja automationsfingeravtryck, stödja flera webbläsarkontexter och vänta in mer användarlika interaktioner. Det är ingen magi, men du blir ofta blockerad mer sällan i första försöket.
Men sanningen är: inget av verktygen är helt immunt. För scraping med höga insatser (t.ex. sneaker-releaser eller biljettsajter) behöver du fortfarande proxies, IP-rotation och kanske även CAPTCHA-lösningar. playwright gör det bara lite mindre smärtsamt.
Utvecklarupplevelse: Installation, inlärningskurva och felsökning
Så hur känns det att komma igång—särskilt om du är nybörjare eller bara vill få jobbet gjort utan en doktorsexamen i Python?
- selenium:
- Installation: Installera Python, installera selenium, ladda ner rätt driver, lägg den i PATH, och hoppas att versionerna matchar. (Fler fastnar på driver-steget än på själva skrapningen.)
- Inlärningskurva: Massor av resurser, men också mycket legacy-kod och gamla tutorials.
- Felsökning: Ofta print-satser och skärmdumpar. Selenium IDE finns, men är ganska basic.
- playwright:
- Installation:
pip install playwright, sedanplaywright install. Klart. - Inlärningskurva: Modern dokumentation, många exempel och ett API som känns mer ”mänskligt”—du kan välja element via text, roll eller placeholder.
- Felsökning: Inspector låter dig stega igenom skriptet, se webbläsaren och även spela in video från dina körningar ().
- Installation:
Om du vill se resultat snabbt och lägga mindre tid på installation och strul, vinner playwright tydligt. selenium är toppen om du redan kan dess egenheter eller behöver den breda kompatibiliteten.
Steg för steg: Bygg din första Python Web Scraper med Playwright eller Selenium
Så här ser det ut i praktiken att bygga en scraper med respektive verktyg—utan kod, bara stegen.
Playwright (Python):
- Installera Playwright och webbläsare:
pip install playwright+playwright install - Starta webbläsaren: Öppna Chromium, Firefox eller WebKit (headless eller synlig).
- Gå till sidan: Använd
page.goto("<https://example.com>") - Vänta på innehåll: Playwright auto-väntar på att element ska laddas.
- Extrahera data: Använd lättlästa selektorer (som
get_by_text,locator("span.price")). - Hantera paginering eller undersidor: Loopa sidor eller klicka länkar—Playwright gör det enkelt att köra flera sidor parallellt.
- Exportera data: Spara till CSV, Excel eller databas.
- Felsök: Använd Inspector eller videoinspelning om något går snett.
Selenium (Python):
- Installera Selenium:
pip install selenium - Ladda ner webbläsardriver: (t.ex. ChromeDriver för Chrome) och lägg den i PATH.
- Starta webbläsaren: Öppna Chrome, Firefox eller annan webbläsare.
- Gå till sidan:
driver.get("<https://example.com>") - Vänta på innehåll: Lägg till explicita waits (
WebDriverWait) eller, om du chansar,time.sleep. - Extrahera data: Använd
find_elementellerfind_elements(CSS/XPath-selektorer). - Hantera paginering eller undersidor: Loopa URL:er eller klicka knappar, men du måste själv hantera timing och navigation.
- Exportera data: Spara till CSV, Excel eller databas.
- Felsök: Mest manuellt—titta i webbläsaren, printa HTML eller ta skärmdumpar.
Ser du skillnaden? playwright är lite mer ”plug and play” för moderna sajter.
Utan kod: No-code web scraping med Thunderbit AI Web Scraper
Låt oss vara ärliga: alla vill inte bli Python-experter bara för att få en tabell med produktpriser eller en lista med leads. Kanske jobbar du med sälj, marknadsföring, fastigheter eller operations och vill bara ha datan—nu. Det är här kommer in.
Som medgrundare av Thunderbit har jag sett hur många affärsanvändare helst vill hoppa över kodandet och gå direkt på resultat. Därför byggde vi ett som låter dig skrapa vilken webbplats som helst med två klick—ingen Python, inga drivers, ingen felsökning.
Så fungerar Thunderbit
- Gå till webbplatsen du vill skrapa.
- Klicka på “AI Suggest Fields.” Thunderbits AI skannar sidan och föreslår datafält (som produktnamn, pris, bild, betyg).
- Klicka på “Scrape.” Direkt får du en strukturerad datatabell.
- Exportera till Excel, Google Sheets, Airtable, Notion, CSV eller JSON. Klart.
Inget pill med selektorer, ingen trial-and-error, ingen kod. Det är ungefär lika enkelt som att beställa hämtmat (och ärligt talat ofta snabbare än att vänta på leveransen).
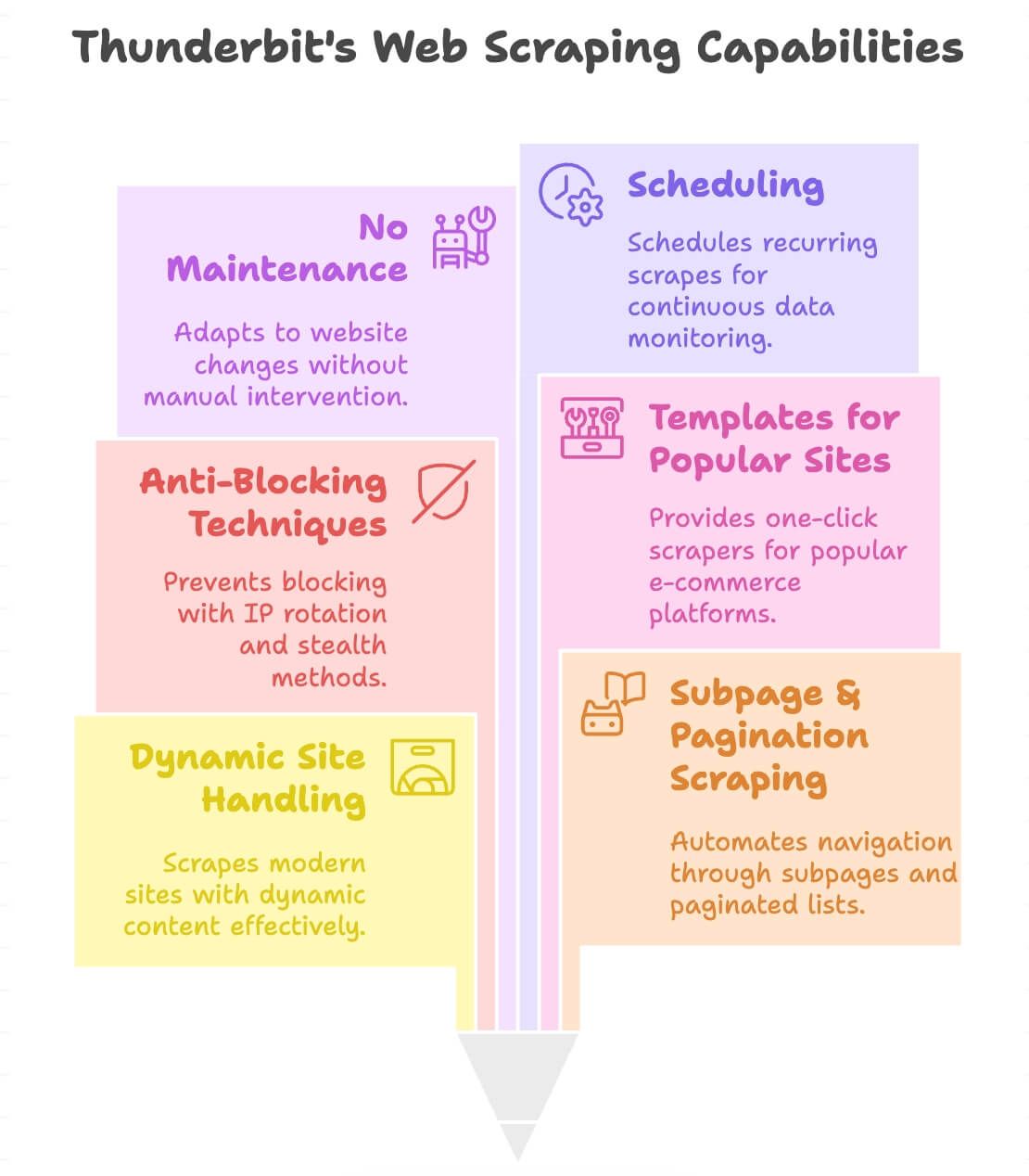
Vad gör Thunderbit annorlunda?
- Klarar dynamiska sajter: Skrapar modern e-handel, kataloger och även sidor med oändlig scroll eller popups.
- Skrapning av undersidor och paginering: Klickar automatiskt igenom produktsidor eller paginerade listor för att hämta allt du behöver.
- Inbyggt skydd mot blockering: Använder IP-rotation i backend och stealth-tekniker, så du blir blockerad mer sällan.
- Mallar för populära sajter: One-click scrapers för Amazon, eBay, Shopify, Zillow med flera ().
- Ingen löpande maintenance: Om en webbplats ändras anpassar sig Thunderbits AI—du slipper skriva om din scraper.
- Schemaläggning: Sätt upp återkommande skrapningar för löpande bevakning (t.ex. dagliga prischeckar).
- Stöd för 34 språk: Skrapa och översätt data från nästan var som helst.
Och det bästa? Du behöver inte kunna något om HTML, CSS eller Python. Kan du använda en webbläsare kan du använda Thunderbit.
Vilken web scraping-lösning passar dig?
Vi rundar av med en snabb guide:
| Din situation | Bästa verktyget |
|---|---|
| Skrapar en statisk, enkel webbplats; setup är okej | Selenium |
| Skrapar en modern, dynamisk sajt; vill ha snabba resultat | Playwright |
| Behöver stöd för äldre webbläsare eller språk | Selenium |
| Vill ha enkel installation, modern felsökning och mindre kod | Playwright |
| Inte utvecklare; vill ha data direkt, utan kod och setup | Thunderbit |
| Behöver skrapa många sidor, undersidor eller schemalägga jobb | Thunderbit |
| Vill exportera direkt till Excel, Sheets, Notion, Airtable | Thunderbit |
| Hatar att felsöka Python-fel | Thunderbit |
Om du är utvecklare, eller gillar att pilla med kod, är både playwright och selenium kraftfulla alternativ. Men om målet är att få in data i ett kalkylark så snabbt som möjligt, kan Thunderbit spara timmar—kanske till och med dagar.
Slutsats: Snabb och pålitlig web scraping—på ditt sätt
web scraping har blivit mainstream, och det finns en bra anledning: företag behöver data för att konkurrera, och de behöver den nu. playwright och selenium har utvecklats från enkla testverktyg till centrala ramverk för scraping, med olika styrkor. selenium är den trygga klassikern för statiska sajter och äldre miljöer; playwright är det moderna, snabba valet för dynamiska och interaktiva sidor.
Men här är mitt ärliga råd efter år inom SaaS, automation och AI: om du inte gör det här för kodandets skull—slösa inte tid på drivers, selektorer och anti-bot-tricks. Med kan du gå från ”jag behöver den här datan” till ”här är min Excel-fil” på minuter—inte dagar.
Oavsett om du är Python-proffs eller affärsanvändare som bara vill ha resultat finns det en lösning som matchar dina behov—och din tålamodsnivå. Testa, se vad som passar ditt arbetsflöde, och kom ihåg: den bästa python scraper är den som ger dig datan du behöver, med minsta möjliga krångel.
Och om du någon gång sitter och felsöker ett selenium driver-fel klockan 02:00—kom ihåg att Thunderbit fortfarande finns här, redo att skrapa med två klick.
Vill du lära dig mer om no-code scraping, AI-driven dataextraktion och hur Thunderbit kan hjälpa ditt team? Kika in vår , eller kom igång med redan idag.
P.S. Om du fortfarande är osäker på vilket verktyg du ska välja, eller vill se Thunderbit i praktiken, titta förbi vår för demos, tips och någon enstaka web scraping-vits. (Ja, vi har såna.)
Vidare läsning: