Låt mig säga så här: om jag fick en dollar varje gång någon skickade mig en PDF fullproppad med “viktig data” och förväntade sig att jag på magisk väg skulle förvandla den till ett kalkylark, skulle jag förmodligen ha råd med ett livstidslager av kaffe (och kanske några extra Chrome-tillägg). PDF-filer finns överallt — säljkontrakt, produktkataloger, forskningsartiklar, fakturor, you name it. Men när det faktiskt gäller att använda datan i de där filerna? Ja, då börjar det roliga (läs: huvudvärken).
Jag har varit nere i skyttegravarna — kopierat, klistrat in, formaterat om och ibland bara gett upp när formateringen spårade ur eller bilder och länkar försvann ut i tomma intet. Men här kommer de goda nyheterna: världen för PDF-utvinning har förändrats rejält, särskilt med framväxten av AI-drivna verktyg. Om du är trött på att lägga timmar på att mata in siffror för hand eller blir tokig av trasiga tabeller, är du på rätt plats. Låt oss dyka in i PDF-utvinningens värld, varför den spelar roll och hur verktyg som gör det hela (äntligen) smärtfritt.
Vad är PDF-utvinning? Förstå grunderna i datautvinning från PDF
Börja enkelt: PDF-utvinning är bara ett finare sätt att säga “få ut strukturerad data ur PDF-filer — automatiskt.” En PDF-utvinnare är ett verktyg (programvara, tillägg eller tjänst) som plockar ut det du bryr dig om — text, tabeller, bilder, länkar, you name it — och lägger det i ett format du faktiskt kan använda, som Excel, Google Sheets eller en databas.
Men här är haken: PDF-filer är inte som webbsidor eller Excel-filer. De är mer som digitala utskrifter, skapade för att se likadana ut överallt, inte för att enkelt kunna brytas ned av en dator. Vissa PDF:er har markerbar text, andra är bara inskannade bilder (vilket kräver OCR — optisk teckenigenkänning), och formateringen kan se helt olika ut. Så att utvinna data ur en PDF handlar inte bara om att kopiera text — det handlar om att tolka ett pussel av layouter, typsnitt och ibland även dold metadata.
Vad kan du extrahera ur en PDF?
- Vanlig text (stycken, rubriker osv.)
- Tabeller (tänk: ekonomi, produktspecifikationer, enkätdata)
- Bilder och grafik (diagram, logotyper, inskannade signaturer)
- Hyperlänkar och referenser (inbäddade URL:er, källhänvisningar)
- Formulärdata (fält i ifyllnadsbara formulär)
- Metadata (författare, titel, skapelsedatum, taggar)
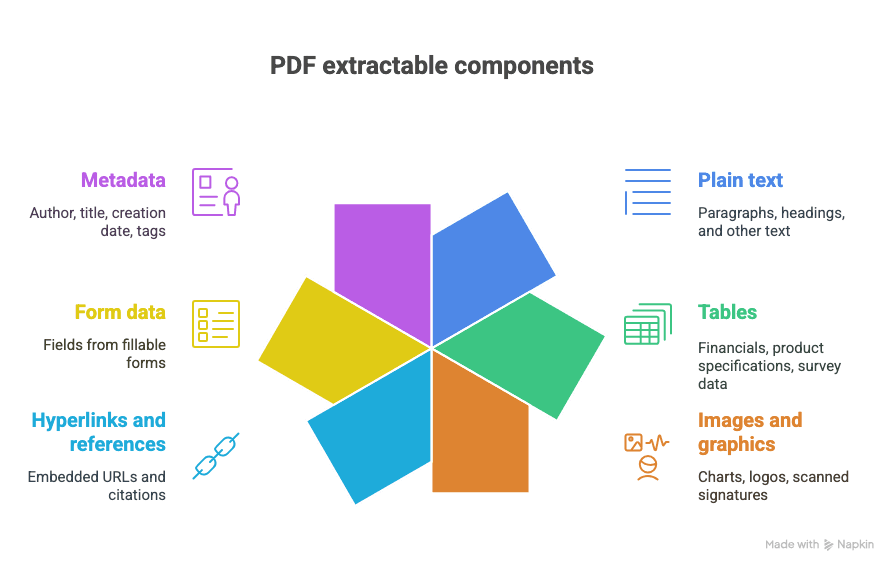
Och ja, ibland är allt detta blandat i ett och samma härligt kaotiska dokument.
Varför PDF-utvinning spelar roll: verkliga användningsfall och affärsnytta
Så varför ens bry sig om att utvinna data ur PDF:er? För att alla använder dem, och datan i dem är ofta affärskritisk. Det är här PDF-utvinning verkligen gör skillnad:
| Användningsfall | Manuellt arbete | Med PDF-utvinnare | Tids- och felbesparing |
|---|---|---|---|
| Extraktion av säljleads | Timmar på att kopiera kontakter från offerter eller event-PDF:er, risk att missa leads | Hämtar alla leads direkt till ett kalkylark | 80–90 % snabbare, färre misstag |
| Produktdata för e-handel | Dagar på att mata in produktspecifikationer från leverantörs-PDF:er, formateringskaos | Massutvinning till CSV eller Sheets | 95 %+ tidsbesparing, konsekvent data |
| Analys av forskningsdata | Veckor på att transkribera tabeller från akademiska artiklar, hög risk för stavfel | Extraherar tabeller, referenser och även inskannad text | 80 % tidsbesparing, högre noggrannhet |
Låt oss sätta siffror på det:
- skapas varje år.
- använder PDF som ett huvudformat för att dela information.
- Manuell digital administration (som datainmatning från PDF) tar upp .
- Automatiserade verktyg kan minska felfrekvensen från .
Om du jobbar inom sälj, e-handel eller forskning är automatisering av datautvinning från PDF inte bara en trevlig bonus — det är en konkurrensfördel.
Traditionella metoder för PDF-utvinning: utmaningar och begränsningar
Låt oss vara ärliga: de gamla sätten att få ut data ur PDF:er är… inte särskilt bra. Här är vad de flesta av oss har testat (och varför det är så frustrerande):

1. Manuell kopiera-klistra in
- Smärtpunkter: Formateringen blir förstörd, tabeller blir röriga, bilder och länkar försvinner, och du sitter kvar med migrän.
- Arbetskostnad: Hög. Om du har 5 000 PDF:er, och det tar 1 minut per fil, blir det 80+ timmar av ditt liv du aldrig får tillbaka.
- Felfrekvens: 5–10 %. Stavfel, missade rader, oavsiktliga borttagningar — been there, done that.
2. Konvertera till Word/Excel och städa sedan upp
- Smärtpunkter: Fungerar ibland för enkla dokument, men komplexa layouter eller tabeller blir sönderhackade. Du måste ändå städa upp röran.
- Bilder/länkar: Försvinner oftast i översättningen.
- Målinriktad extraktion: Glöm det — du får hela dokumentet, inte bara det du behöver.
3. Egna skript (Python osv.)
- Smärtpunkter: Du måste vara utvecklare (eller ha en på snabbuppringning). Varje nytt PDF-format innebär att skriptet behöver justeras. Skannade PDF:er? Lycka till.
- Underhåll: Högt. Varje gång en leverantör ändrar sin fakturamall går skriptet sönder.
- Skalbarhet: Inte för den lättskrämde (eller den icke-tekniska).
4. Onlinekonverterare
- Smärtpunkter: Enkla för engångsjobb, men du måste ladda upp känsliga dokument till en tredje parts server (hej, regelefterlevnadsproblem). Begränsad kontroll över vad som extraheras.
- Formatering: Träffar eller missar. Du kanske lägger mer tid på att städa upp än du sparade.
Kort sagt: Traditionella metoder är långsamma, felkänsliga och skalar dåligt. Det är därför så många team bara “lever med det” — men till ett enormt produktivitetstapp.
Moderna lösningar för PDF-utvinning: från kod till no-code-verktyg
Som tur är sitter vi inte fast i mörka medeltiden längre. Landskapet har exploderat med smartare, snabbare och mer användarvänliga alternativ för PDF-utvinning.
1. Kodbibliotek (för utvecklare)
- Exempel: , , .
- Styrkor: Superflexibla, kan automatiseras för stora batcher, gratis (öppen källkod).
- Svagheter: Hög uppsättningstid, kräver programmeringskunskaper, sköra (går sönder med nya format), begränsat stöd för OCR/bilder.
2. Onlinekonverterare för PDF
- Exempel: , , .
- Styrkor: Ingen installation, enkla för icke-tekniska användare, snabba för små jobb.
- Svagheter: Begränsad anpassning, integritetsfrågor, formateringsfel, filstorleks-/sidbegränsningar.
3. AI-drivna PDF-utvinnare
- Exempel: , Nanonets, Docparser.
- Styrkor: Ingen kod krävs, hanterar text/tabeller/bilder/länkar, AI föreslår vad som ska extraheras, stöd för batchjobb, integreras med Sheets/Notion/Airtable.
- Svagheter: Vissa har kredit-/sidgränser, kan kräva internetanslutning, viss inlärning för komplexa dokument.
Jämförelse av PDF-utvinningsverktyg: vilket tillvägagångssätt passar dina behov?
| Verktyg/metod | Installation | Bäst för | Extraherar | Kan anpassas? | Kostnad |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Medel (gränssnitt/kod) | Tabeller i PDF:er | Tabeller | Delvis | Gratis |
| PDFMiner | Kräver kod | Texttunga PDF:er | Text | Ja (kod) | Gratis |
| PyPDF2 | Kräver kod | Enkel text/metadata | Text, metadata | Ja (kod) | Gratis |
| Smallpdf/onlinekonverterare | Ingen (webbaserad) | Snabba konverteringar | Hela dokumentet (Word/Excel) | Nej | Freemium |
| Thunderbit | 2-klicksinstallation | Affärsanvändare, team | Text, tabeller, bilder, länkar | Ja (AI-promptar) | Freemium (16,5 USD/mån för Pro) |
Möt Thunderbit: Chrome-tillägget för AI-baserad PDF-utvinning
Nu ska vi prata om verktyget som har gjort mitt liv (och många affärsanvändares liv) så mycket enklare: .
Vad gör Thunderbit annorlunda?
- Extraktion med 2 klick: Öppna en PDF i Chrome, klicka på Thunderbit-tillägget och låt AI sköta resten.
- AI-drivna fältförslag: Thunderbits “AI Suggest Fields” läser din PDF och rekommenderar de kolumner du sannolikt vill ha (som “Namn”, “E-post”, “Pris” osv.).
- Hanterar bilder, länkar och tabeller: Inte bara vanlig text — Thunderbit kan plocka ut bilder, hyperlänkar och till och med köra OCR på skannade dokument.
- Anpassade promptar: Behöver du bara telefonnummer eller produktspecifikationer? Lägg till en anpassad instruktion så fokuserar Thunderbit på just det.
- Export överallt: Skicka datan direkt till Excel, Google Sheets, Airtable eller Notion. Inget mer CSV-trixande.
- Batch- och subsideutvinning: Har du en lista med PDF:er eller länkar? Thunderbit kan bearbeta dem alla på en gång.
- Driftsäkerhet i företagsklass: Utformat för noggrannhet, integritet och verkliga arbetsflöden.
Kort sagt är det som att ha en digital praktikant som faktiskt gillar datainmatning (och aldrig blir trött).
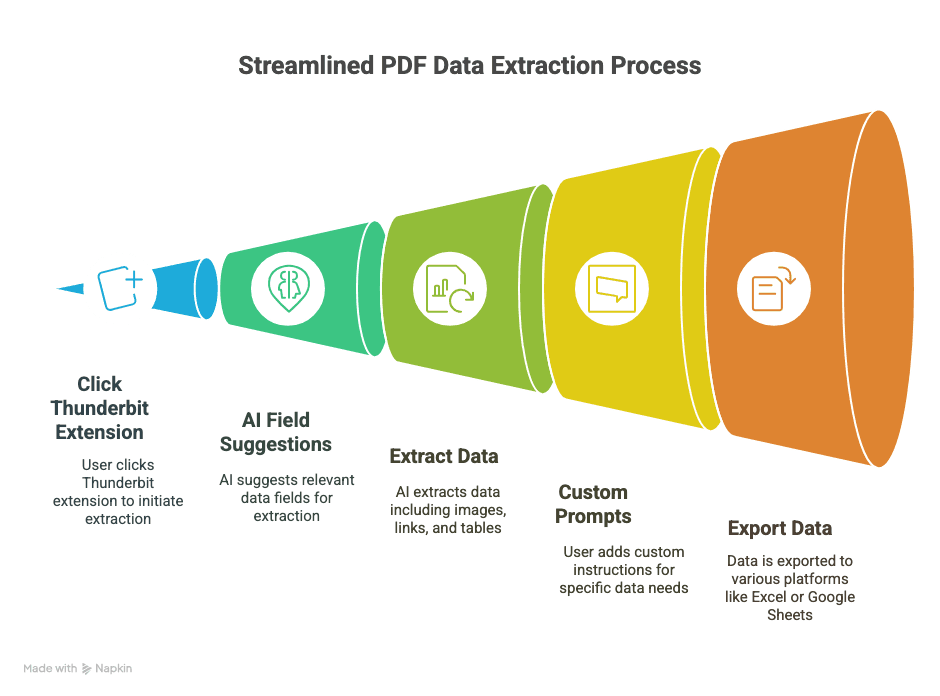
Så extraherar du data ur en PDF med Thunderbit: steg-för-steg-guide
Redo att se hur enkelt det kan vara? Så här använder jag Thunderbit för att förvandla PDF:er till strukturerad, användbar data:
1. Installera Thunderbit
- Hämta .
- Registrera dig (Google-konto eller e-post — tar några sekunder).
2. Öppna din PDF i Chrome
- Antingen öppnar du en PDF från en webblänk eller så drar du in en lokal PDF i en Chrome-flik.
3. Starta Thunderbit på PDF:en
- Klicka på Thunderbit-ikonen i webbläsarens verktygsfält.
- Välj “AI Web Scraper” — Thunderbit upptäcker PDF:en och gör sig redo att jobba.
4. Låt AI föreslå fält
- Klicka på “AI Suggest Columns.”
- Thunderbits AI skannar PDF:en och rekommenderar kolumner (som “Datum”, “Belopp”, “Kontaktnamn” osv.).
- Förhandsgranska den extraherade datan i en tabell direkt i tillägget.
5. Anpassa vid behov
- Byt namn på kolumner, ta bort extra fält eller lägg till egna (t.ex. “Garantitid” eller “Produkt-URL”).
- För knepig data kan du markera text i PDF:en för att träna AI:n på vad du vill ha.
6. Välj exportformat
- Välj mellan CSV, Google Sheets, Airtable eller Notion.
- Auktorisera Thunderbit att ansluta (engångsinstallation).
7. Extrahera och exportera
- Klicka på “Scrape” eller “Export.”
- Thunderbit bearbetar PDF:en och skickar datan dit du vill ha den — oftast på bara några sekunder.
Det var allt. Ingen kod, inget kopiera-klistra in, inget drama.
Tips för korrekt datautvinning ur PDF med Thunderbit
- Granska AI-föreslagna fält: AI:n är smart, men en snabb överblick säkerställer att du får exakt det du behöver.
- Hantera komplexa tabeller: För tabeller som sträcker sig över flera sidor eller har märklig formatering, använd förhandsgranskningen för att hitta problem och justera kolumnerna vid behov.
- Extrahera bilder/länkar: Se till att inkludera dessa fält om din PDF innehåller dem — Thunderbit kan hämta dem också.
- Skannade PDF:er: Thunderbits inbyggda OCR är bra, men ju renare skanningen är, desto bättre blir resultatet.
- Anpassade promptar: Vill du bara ha e-postadresser eller telefonnummer? Lägg till en prompt som “Extrahera alla e-postadresser” så fokuserar Thunderbit på dem.
Avancerad PDF-utvinning: extrahera bilder, länkar och anpassad data
Thunderbit handlar inte bara om vanlig text. Så här kan du få ut ännu mer av dina PDF:er:
- Bilder: Extrahera logotyper, diagram eller annan inbäddad grafik. Thunderbit kan till och med köra OCR på text inne i bilder.
- Hyperlänkar: Plocka ut alla URL:er eller referenser — perfekt för forskningsartiklar eller CV:n.
- Anpassade datatyper: Använd AI-promptar för att extrahera exakt det du behöver (t.ex. “Hitta alla produkt-SKU:er och deras priser”).
- Sammanfattningar och kategorisering: Lägg till en kolumn och be Thunderbit sammanfatta ett avsnitt eller kategorisera data i realtid.
Tolka data från PDF för specifika affärsbehov
- Sälj: Extrahera bara kontaktuppgifter från en batch offerter.
- E-handel: Hämta produktspecifikationer, priser och bilder från leverantörskataloger.
- Forskning: Plocka tabeller, referenser och till och med generera sammanfattningar från akademiska artiklar.
Och när du väl har datan kan du strukturera den för enkel analys i Excel, Google Sheets eller Notion — Thunderbit gör grovjobbet, du får bara ta del av resultatet.
Exportera och använda din PDF-data: från extraktion till handling
Att få ut datan är bara början. Så här får du den att faktiskt jobba för dig:
- Exportalternativ: CSV, Excel, Google Sheets, Airtable, Notion — välj det du gillar bäst.
- Formateringstips: Använd Thunderbits inställningar för kolumntyp (nummer, datum, text) för ren data som är redo för analys.
- Integrering i arbetsflöden: Koppla din exporterade data till CRM-system, lagersystem eller analysdashboards.
- Samarbete: Dela Google Sheets eller Airtable-baser med teamet — alla arbetar utifrån samma, uppdaterade data.
Det bästa? Inget mer mejlande av kalkylark fram och tillbaka eller funderande på om du missade en rad.
Vanliga fallgropar vid PDF-utvinning och hur du undviker dem
Även med de bästa verktygen kan några fallgropar dyka upp. Här är vad jag har lärt mig (ibland den hårda vägen):
- OCR-fel: Suddiga skanningar eller konstiga typsnitt kan ställa till det även för den bästa OCR:n. Försök använda så rena PDF:er som möjligt och kontrollera viktiga fält extra noggrant.
- Komplexa layouter: Tabeller med flera kolumner eller nästlade tabeller kan behöva lite manuell vägledning — använd Thunderbits manuella markering eller promptar.
- Datatyper: Siffror med kommatecken eller datum i udda format? Ställ in kolumntypen innan export, eller städa upp i Excel/Sheets.
- Filstorleks-/sidbegränsningar: Stora PDF:er? Dela upp dem i mindre delar, eller använd Thunderbits molnläge för batchjobb.
- AI-”hallucinationer”: Sällsynt, men ibland kan AI gissa ett kolumnnamn eller fylla i saknad data. Kontrollera alltid resultatet, särskilt när det gäller viktiga siffror.
- Manuell granskning: För affärskritisk data bör du göra en snabb validering — automatiska verktyg är noggranna, men ett mänskligt öga skadar aldrig.
Och om du kör fast finns Thunderbits support och community där för att hjälpa till.
Slutsats och viktigaste lärdomar: så får du PDF-utvinning att fungera i din verksamhet
Låt oss knyta ihop säcken. Att utvinna data ur PDF:er brukade vara en mardröm — långsamt, felkänsligt och bara allmänt tröttsamt. Men med moderna verktyg som är det nu snabbt, noggrant och (vågar jag säga det) nästan roligt.
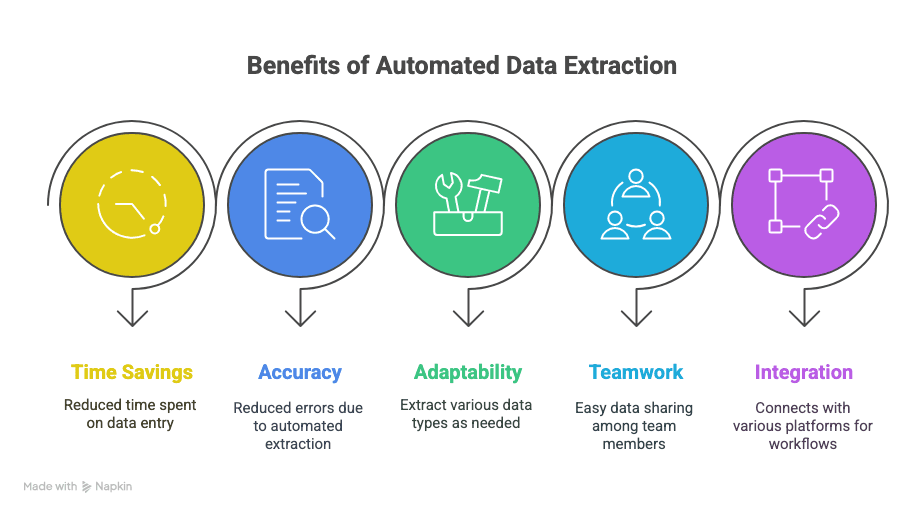
Det här får du:
- Mer tid tillbaka: Timmar (eller till och med veckor) sparade på manuell datainmatning.
- Färre misstag: Automatiserad extraktion betyder färre stavfel och missade rader.
- Flexibilitet: Extrahera exakt det du behöver — text, tabeller, bilder, länkar, you name it.
- Samarbete: Dela data direkt med teamet, oavsett var de befinner sig.
- Smartare arbetsflöden: Integrera med Sheets, Notion, Airtable med mera.
Redo att prova? Ladda ner , kör det på din nästa PDF och se hur mycket enklare livet kan bli. Ditt framtida jag (och din karpaltunnel) kommer att tacka dig.
För fler tips och guider, kolla in eller fördjupa dig i .
Låt oss förvandla PDF-huvudvärk till produktivitetsvinster — ett klick i taget.
Shuai Guan, medgrundare och VD, Thunderbit