
Förra veckan lade jag en hel eftermiddag på att få en AI-agent att fylla i ett leverantörsformulär i en portal bakom inloggning. Efter tre timmar stirrade jag på felet "Connection Refused", min VPS hade slut på minne och jag var allvarligt frestad att bara göra allt manuellt.
Den upplevelsen är i princip hela OpenClaw-browser automation i ett nötskal. Verktyget kan navigera på sidor, hämta data, fylla i formulär och kedja ihop komplexa arbetsflöden med instruktioner i vanlig engelska — riktigt imponerande grejer. Men glappet mellan "det här låter fantastiskt" och "det här funkar faktiskt på min dator" är där de flesta fastnar.
Jag har spenderat mycket tid på båda sidor av det glappet, både med att bygga automationsverktyg på och med att testa vad ekosystemet med öppen källkod har att erbjuda. Den här guiden är den jag själv hade velat ha: en riktig genomgång från installation till drift, valet av webbläsarläge som ställer till det för nästan alla, en Windows-väg som faktiskt fungerar nativt (för WSL ska inte vara ett krav), en överlevnadsguide mot bot-skydd, exempel på faktisk output, vanliga fel med riktiga lösningar och en ärlig bild av när OpenClaw är rätt verktyg — och när det är överkurs.
Vad är OpenClaw-webbautomatisering?
OpenClaw är en gratis AI-agentplattform med öppen källkod (MIT-licens) som kan styra en webbläsare åt dig. I stället för att skriva Selenium-skript eller Puppeteer-kod beskriver du vad du vill få gjort i vanlig engelska — "Gå till den här sidan och extrahera alla produktnamn och priser" — och AI:n tar reda på hur det ska göras. Den använder ett numrerat snapshot-system där agenten identifierar sidans element, tilldelar referensnummer och interagerar med dem steg för steg.
Arkitekturen består av tre delar — vilket är anledningen till att installationen är mer än bara att lägga till ett tillägg:
- Gateway (VPS/server): "Hjärnan" som bearbetar dina instruktioner och kopplar mot LLM:er. Körs som standard på port 18789.
- Node Host (lokal dator): En brygga som låter Gateway skicka webbläsarinstruktioner till din lokala Chrome. Ansluts via en säker tunnel som Tailscale.
- Chrome Extension (Browser Relay): Ger agenten direkt kontroll över webbläsarflikar i din riktiga webbläsare.
Ytterligare portar inkluderar Control Service (18791), CDP Relay (18792) och hanterad webbläsar-CDP (, med stöd för upp till 100 parallella profiler).
Ja, det är många delar att hålla reda på. Men när du väl förstår vad varje del gör blir installationen logisk. Tänk på det som en radiostyrd bil: Gateway är kontrollen, Node Host är radiosignalen och Chrome Extension är själva bilen.

Varför OpenClaw-webbautomatisering spelar roll för företagsteam
Kunskapsarbetare lägger upp till i stället för värdeskapande arbete, inklusive 1,8 timmar per dag bara på att söka och samla information. Smartsheet fann att lägger minst en fjärdedel av sin veckoarbetstid på manuella, repetitiva uppgifter. Bara manuell datainmatning kostar amerikanska företag uppskattningsvis .
Det är det problemet OpenClaw-webbautomatisering är byggt för att lösa. I praktiken passar det in i konkreta affärsflöden:
| Användningsfall | Vad OpenClaw gör | Affärsnytta | |---|---|---| | Leadgenerering | Hämtar kontaktuppgifter från kataloger och företagssidor | Fyller säljpipen snabbare | | Prisbevakning av konkurrenter | Besöker produktsidor dagligen och extraherar priser | Uppdaterad konkurrensinsikt i realtid | | Formulärifyllning / datainmatning | Fyller repetitiva webbformulär (CRM, portaler, ansökningar) | Sparar timmar varje vecka | | Innehållsbevakning | Kollar konkurrenters bloggar, platsannonser och pressmeddelanden | Tidiga signaler om vad som händer på marknaden | | QA / testning | Kör igenom webbflöden för att verifiera att de fungerar | Färre trasiga användarupplevelser |
Marknaden för AI-agenter har nått , nästan en fördubbling från $3,7 miljarder 2023, och använder nu AI-automation i minst en funktion. Det här är alltså inte längre någon nisch.
Sandbox Chromium vs. Browser Relay vs. Chrome Remote Debugging: välj rätt läge
Att välja fel webbläsläge är, enligt min erfarenhet, den största källan till frustration för nya OpenClaw-användare. Jag har sett folk lägga timmar på att felsöka anslutningsproblem som hade kunnat undvikas om de valt ett annat läge från början. OpenClaw erbjuder tre sätt att ansluta, och alla har tydliga kompromisser:
- Sandbox Chromium (hanterad profil): OpenClaw startar sin egen headless-webbläsare på servern. Inga inloggade sessioner, snabbt, lite att konfigurera — men lättare att upptäcka av bot-skydd.
- Browser Relay (befintlig session): En node host på din lokala dator vidarebefordrar instruktioner från VPS:n till din riktiga Chrome. Stöd för inloggningar och cookies, och den använder din riktiga webbläsarprofil.
- Chrome Remote Debugging (Remote CDP): Ansluter till fjärrwebbläsare via WebSocket-URL. Full åtkomst till sessionen, men högst installationsnivå. Fungerar med molnleverantörer som Browserless eller Browserbase.

Jämförelsetabell: alla tre webbläsarlägen
| Faktor | Sandbox Chromium | Browser Relay | Remote CDP | |---|---|---|---| | Stöd för inloggning | ❌ Nej (ny profil) | ✅ Ja (riktiga sessioner) | ✅ Ja (förinloggad) | | Risk för bot-detektion | ⚠️ Medelhög–hög | ✅ Låg (riktig profil) | ✅ Låg (hanteras av leverantör) | | Hastighet | ✅ Snabb | ⚠️ Långsammare (nätverksbrygga) | ⚠️ Varierar | | Installationssvårighet | Låg | Medel | Hög | | Fullt funktionsstöd | ✅ Ja (alla funktioner) | ⚠️ Begränsat (ingen batch, ingen avlyssning av nedladdningar) | Beror på leverantör | | Bäst för | Offentliga sidor, snabba extraktioner | Sidor bakom inloggning, formulärifyllning | Molninfrastruktur, alltid på-övervakning |
Beslutsflöde: vilket läge ska du välja?
Gå igenom frågorna i den här ordningen:
- "Behöver du vara inloggad?" — Nej → Sandbox Chromium. Ja → nästa fråga.
- "Har sajten kraftigt bot-skydd?" — Ja → Browser Relay (din riktiga webbläsarprofil minskar risken att bli upptäckt). Nej → antingen Browser Relay eller Remote CDP.
- "Behöver du en uthållig session som alltid är igång (t.ex. övervakning av en dashboard dygnet runt)?" — Ja → Remote CDP med en molnleverantör. Nej → Browser Relay.
Exempel på hur valet mappar mot verkligheten:
- Scrapa offentliga Amazon-listningar → Sandbox Chromium
- Fylla i ett CRM-formulär bakom inloggning → Browser Relay
- Övervaka en intern analytics-dashboard dygnet runt → Remote CDP med Browserless/Browserbase
Gör du rätt val här sparar du timmar av felsökning. Verkligen.
Innan du börjar
- Svårighetsgrad: Medel (du behöver vara bekväm med CLI)
- Tidsåtgång: 45–75 minuter för full installation; 10–15 minuter per steg
- Det du behöver: En VPS (minst 2 GB RAM, helst 4 GB), Node.js v22.12.0+, ett Tailscale-konto (gratis), Chrome-webbläsare och tålamod
Steg 1: få OpenClaw igång på en VPS (eller lokalt)
VPS:en är där OpenClaws "hjärna" bor. Det finns två vägar dit:
Alternativ A: VPS-hosting med ett klick
Flera leverantörer erbjuder förkonfigurerade OpenClaw-images:
| Leverantör | Startpris | Kommentar | |---|---|---| | Hostinger | Från $6.99/mån | Förkonfigurerad image | | Tencent Cloud Lighthouse | Från ca $0.08/år (kampanj) | 2 kärnor/4 GB rekommenderas | | Hetzner | Från $4.09/mån (CX22) | Mest prisvärd; manuell installation | | DigitalOcean | Från $4/mån | Manuell installation | | Vultr | Från $3.50/mån | Manuell installation |
Alternativ B: manuell CLI-installation
1# Installera via npm (kräver Node.js v22.12.0+)
2npm install -g openclaw
3# Kör introduktionsguiden
4openclaw onboard
5# Skapa gateway-token (spara den här — du behöver den för node host)
6openclaw doctor --generate-gateway-token
7# Verifiera konfigurationen
8openclaw doctor --fixMinimikrav: 2 GB RAM (kraschar vid 1 GB), 4 GB rekommenderas. Varje headless webbläsarinstans använder 400–800 MB i vila. Om du kör Docker, sätt shm_size: '2gb' — det är avgörande för stabilitet.
Efter det här steget ska OpenClaw vara igång och du ska ha sparat en Gateway-token på ett säkert ställe. (Jag lägger min i en lösenordshanterare. Tappa den inte.)
Steg 2: ställ in Tailscale för att koppla ihop VPS och lokal dator
Tailscale skapar en privat, krypterad tunnel mellan din VPS och din lokala enhet så att webbläsarinstruktioner inte exponeras mot det öppna internet. Med tanke på att OpenClaw enligt uppgift hade i början av 2026 är det här inte ett steg du vill hoppa över.
1# På VPS
2curl -fsSL https://tailscale.com/install.sh | sh
3sudo tailscale up --ssh=true
4# Notera VPS:ens Tailscale-IP (100.x.x.x)
5# Konfigurera Gateway så att den lyssnar på Tailscale-nätverket
6openclaw config set gateway.listen "100.x.x.x:18789"Installera Tailscale på din lokala dator från . Båda enheterna måste använda samma Tailscale-konto.
Alternativ om Tailscale inte passar dig:
| Faktor | Tailscale | Cloudflare Tunnel | WireGuard | |---|---|---|---| | Installationstid | 5 min | 10–15 min | 20–30 min | | Kostnad | Gratis (privat) | Gratis | Gratis | | NAT-traversering | Automatiskt | Automatiskt | Manuellt |
Nu ska du kunna pinga VPS:ens Tailscale-IP från din lokala dator. Om inte, kontrollera att båda enheterna är inloggade på samma Tailscale-konto.
Steg 3: installera Node Host på din lokala enhet
Node Host vidarebefordrar webbläsarinstruktioner från VPS-Gatewayn till din lokala Chrome — översättaren mellan server och webbläsare.
1# Installera node host-paketet
2npm install -g @openclaw/node-host
3# Ange gateway-token från steg 1
4export OPENCLAW_GATEWAY_TOKEN="your-token-here"
5# Starta node host och peka mot VPS:ens Tailscale-IP
6openclaw node install --host 100.x.x.x --port 18789
7# Godkänn anslutningen från VPS-sidan
8openclaw node approve <node-id>Du bör se en bekräftelse på att noden är ansluten och godkänd. Om godkännandestegen hänger sig, starta om Gateway-processen på VPS:en.
Steg 4: installera OpenClaw Chrome-tillägget
Tillägget ger agenten direkt kontroll över webbläsarflikar. Du kan också hämta det från Chrome Web Store genom att söka efter "OpenClaw Browser Relay."
1# Installera tilläggsfilerna
2openclaw browser extension install
3# Eller manuellt:
4# 1. Öppna chrome://extensions
5# 2. Aktivera "Developer mode" (växeln uppe till höger)
6# 3. Klicka på "Load unpacked" → välj tilläggsmappen
7# 4. Fäst det i verktygsfältet
8# 5. Kontrollera att märket visar "ON"Om märket visar "ON" är du i mål. Om det står "OFF", hoppa ner till felsökningsdelen längre ner.
Steg 5: kör din första OpenClaw-automation i webbläsaren
Öppna en målsida och testa sedan något enkelt från OpenClaw-chattgränssnittet:
1Gå till https://books.toscrape.com och extrahera titel och pris för varje bok på sidanFörväntat flöde: Instruktionen skickas → agenten tar ett snapshot (identifierar sidans element med numrerade referenser) → agenten extraherar data → strukturerad output returneras som JSON eller CSV.
Ett tips från erfarenhet: börja med väldigt enkla prompts. Om du beskriver för mycket kan du faktiskt förvirra AI:n — lägg bara till mer detaljer om agenten missförstår din första instruktion.
För 20 böcker på första sidan, räkna med cirka 30–60 sekunder. Får du tillbaka strukturerad data? Då fungerar din OpenClaw-installation.
OpenClaw-webbautomatisering på Windows: den nativa vägen
De flesta guider för OpenClaw utgår från macOS eller Linux. Om du kör Windows har du redan märkt det. En användare på forumet sammanfattade det bra: "många lösningar verkade rimliga i teorin, men ingen var byggd för Windows nativt."
Här är det som faktiskt fungerar.
Alternativ A: Chrome Remote Debugging på Windows (rekommenderad nativ väg)
Det mest pålitliga alternativet för Windows. Öppna PowerShell och starta Chrome med fjärrfelsökning aktiverad:
1& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222Om Chrome inte ligger där, prova:
1# Kolla alternativa platser
2Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
3# Eller kontrollera AppData
4& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222Konfigurera sedan OpenClaw att ansluta via Remote CDP genom att sätta cdpUrl till ws://localhost:9222 i din openclaw.json.
Alternativ B: Docker Desktop som fallback på Windows
Om den nativa vägen krånglar kan Docker Desktop på Windows köra en headless Chromium-container:
1docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
2# Peka OpenClaw mot: cdpUrl: "ws://localhost:9222"Det lägger till ännu ett lager komplexitet, men är stabilare för vissa användare. Det fungerar, men är inte elegant.
Windows-specifik fellogg
| Fel | Orsak | Åtgärd (PowerShell) |
|---|---|---|
| Port 9222 används redan | En annan DevTools-session är öppen | Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force |
| Chrome-binären hittas inte | Fel sökväg | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale-anslutning nekades | Windows-brandväggen blockerar | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm-behörighetsfel | Körs inte som administratör | Kör PowerShell som Administratör, eller använd nvm-windows |
Alla kommandon ovan är PowerShell, inte bash. Kopiera och klistra in direkt.
Överlevnadsguide mot bot-skydd för OpenClaw-webbautomatisering
Bot-detektion är den största frustrationen för användare av OpenClaw-webbautomatisering. OpenClaws standard-Chromium har — sajter upptäcker det via WebDriver-flaggan, skärmstorlek, fontfingeravtryck och IP-rykte. Jag har sett agenter blockeras inom några sekunder på vissa sajter.
Men det finns en stegvis metod. Börja med den enklaste lösningen och gå vidare bara om det behövs.
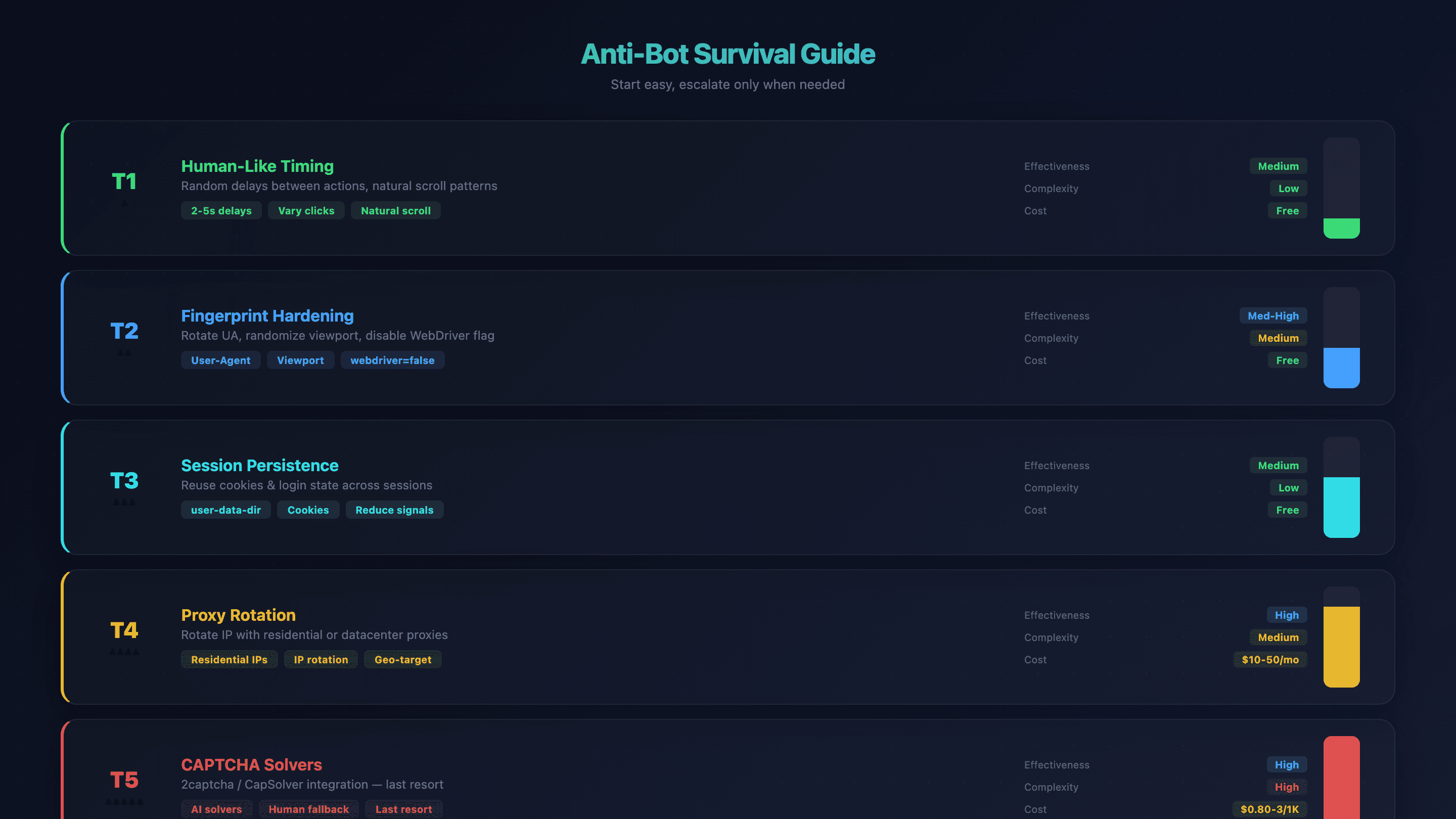
Nivå 1: mänsklig timing och beteende
Lägg in slumpmässiga fördröjningar mellan åtgärderna i dina prompts. I stället för att låta agenten klicka i maskinhastighet, instruera den: "vänta 2–5 sekunder mellan varje klick." AI:n varierar redan tidsmönstret lite grann, men tydliga instruktioner hjälper.
Effektivitet: Medel | Komplexitet: Låg | Kostnad: Gratis
Nivå 2: förstärk webbläsarens fingeravtryck
Rotera user-agent-strängar, slumpa viewport-storlek och låt OpenClaw automatiskt stänga av flaggan navigator.webdriver (via --disable-blink-features=AutomationControlled).
1# Ange egna headers
2openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
3# Slumpa viewport
4openclaw browser set viewport 1366 768
5# Ställ in tidszon och språk
6openclaw browser set timezone America/New_York
7openclaw browser set locale en-USFör djupare anti-detektion rekommenderar communityn Camoufox (en Firefox-baserad anti-detect-webbläsare med C++-baserad fingeravtrycksspoofing på motornivå).
Effektivitet: Medel–hög | Komplexitet: Medel | Kostnad: Gratis
Nivå 3: spara sessioner
Använd user-data-dir för att behålla cookies och inloggningsstatus mellan sessioner. Det minskar signaler om "ny webbläsare" som triggar bot-skydd.
1openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
2openclaw config set browser.profiles.persistent.cdpPort 18802Effektivitet: Medel | Komplexitet: Låg | Kostnad: Gratis
Nivå 4: rotera proxy
När timing och fingeravtryck inte räcker behöver du byta IP-adress. Residential proxies är svårare att upptäcka; datacenter-proxies är snabbare och billigare.
1export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"Observera: proxykonfiguration på webbläsarnivå är fortfarande ett önskemål i funktionlistan (GitHub Issue #8079). Just nu måste proxies ställas in på OS-nivå eller i miljövariabler.
| Leverantör | Residential | Datacenter | Bäst för | |---|---|---|---| | Bright Data | $4–8.40/GB | $0.43–0.60/GB | Företag, högsta kvalitet | | Oxylabs | $6–8/GB | $0.48–5/GB | Extraktion i stor skala | | Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | Medelbudget | | IPRoyal | $5–7/GB | -- | Budgetvänligt | | DataImpulse | $1/GB | -- | Lägsta kostnad |
Effektivitet: Hög | Komplexitet: Medel | Kostnad: $10–50/mån
Nivå 5: CAPTCHA-lösare
Sista utvägen. Integrera tjänster som 2captcha eller CapSolver.
| Tjänst | reCAPTCHA v2 | Cloudflare Turnstile | Latens | |---|---|---|---| | 2Captcha | $2.99/1K | $2.99/1K | 15–45 s (mänskliga lösare) | | CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10 s (AI) |
FlareSolverr (öppen källkod för att kringgå Cloudflare) bedöms som opålitligt under 2025–2026 på grund av Cloudflares allt starkare försvar.
Effektivitet: Hög | Komplexitet: Hög | Kostnad: $0.80–3/1K lösningar
Sammanfattning av anti-bot-metoder
| Teknik | Effektivitet | Komplexitet | Kostnad | |---|---|---|---| | Mänsklig timing | Medel | Låg | Gratis | | Fingerprint-förstärkning | Medel–hög | Medel | Gratis | | Session persistence | Medel | Låg | Gratis | | Proxyrotation | Hög | Medel | $10–50/mån | | CAPTCHA-lösare | Hög | Hög | $0.80–3/1K lösningar |
För användare som gång på gång stöter på bot-väggar och bara behöver datan: s molnbaserade scraping hanterar bot-skydd direkt för offentliga webbplatser — ingen proxykonfiguration, ingen tuning av fingerprint. Det är ett fundamentalt annat upplägg (AI läser sidan varje gång via hanterad molninfrastruktur) som helt kringgår bot-racet för vanliga extraheringsuppgifter.
Vad OpenClaw-webbautomatisering faktiskt producerar i praktiken
Innan du lägger 45–75 minuter på installation vill du nog se hur slutresultatet ser ut. Rimligt nog — här är tre exempel på arbetsflöden med faktisk output.
Exempel 1: webbscraping — extrahera produktdata
Prompt: "Gå till https://books.toscrape.com och extrahera titel och pris för varje bok på sidan"
Output (första 5 raderna):
| Titel | Pris | |---|---| | A Light in the Attic | £51.77 | | Tipping the Velvet | £53.74 | | Soumission | £50.10 | | Sharp Objects | £47.82 | | Sapiens: A Brief History of Humankind | £54.23 |
Tidsåtgång: cirka 45 sekunder för 20 rader (en sida). Sidnumrering krävde en uppföljande instruktion: "Klicka på Next-knappen och upprepa för 5 sidor." Totalt: ungefär 100 rader på cirka 3 minuter.
Exempel 2: formulärautomatisering — fylla i ett webbformulär med flera fält
Scenario: Fyll i ett förfrågningsformulär för leverantörer med företagsnamn, kontaktuppgifter och produktintresse.
Agenten tar ett snapshot av formuläret, identifierar varje fält med referensnummer och fyller dem i sekventiellt. Före: tomma fält. Efter: alla fält ifyllda, bekräftelse visas. Eventuella dropdown-menyer eller kryssrutor hanteras av snapshot-systemet — agenten "ser" alternativen och väljer rätt.
Tidsåtgång: cirka 30 sekunder för ett formulär med 6 fält.
Exempel 3: paginering — extrahera över flera sidor
Första resultat: 20 rader från sida 1. Efter instruktionen "klicka på Next och upprepa för alla sidor": 1 000 rader över 50 sidor på books.toscrape.com. Agenten upptäcker "Next"-knappen via snapshot och klickar sig igenom den i en loop.
Tidsåtgång: cirka 12 minuter för hela datasetet på 1 000 rader.
Sida vid sida: samma scrapinguppgift i Thunderbit
För samma exempel med books.toscrape.com ser flödet ut så här i :
- Installera (~30 sekunder)
- Gå till sidan
- Klicka på "AI Suggest Fields" → AI identifierar Title, Price, Availability, Rating
- Klicka på "Scrape" → 20 rader extraheras
- Använd sidnumreringskontrollerna → alla sidor skrapas
- Exportera till Google Sheets (gratis)
Total tid: cirka 3 minuter från tom start till exporterad data, utan VPS, utan CLI och utan konfiguration.
Poängen är inte att ett verktyg är "bättre". Rätt verktyg beror på vad du faktiskt försöker göra.
När OpenClaw-webbautomatisering är överkurs (och vad du ska använda i stället)
OpenClaw är utmärkt för komplex, flerstegs, agentstyrd automatisering — arbetsflöden bakom inloggning, kedjning av webbläsaråtgärder med shell-kommandon, drift dygnet runt på en VPS. Men om målet är "extrahera produktdata från en listingsida" eller "plocka ut mejladresser från en katalog" är hela stacken med VPS + Tailscale + node host sannolikt onödigt tung.
Jag har sett folk lägga över 60 minuter på installation för en uppgift som tar 2 minuter med ett enklare verktyg. Ingen bra affär.

Rätt verktyg för jobbet: jämförelsetabell
| Faktor | OpenClaw Browser Automation | Thunderbit | |---|---|---| | Installationstid | 45–75 min (VPS + Tailscale + node host) | ~2 min (installera Chrome-tillägg) | | Kräver kod | CLI + prompts i naturligt språk | Nej — klicka "AI Suggest Fields" → "Scrape" | | Hantering av bot-skydd | Manuell (proxy, fingerprint-konfiguration) | Inbyggd molnscraping | | Navigering bakom inloggning | ✅ Browser Relay / remote debug | ✅ Browser scraping-läge | | Berikning av undersidor | Egen kod per arbetsflöde | Skrapa undersidor med ett klick | | Schemalagda / 24×7-körningar | VPS-baserat, alltid igång | Inbyggd | | Månadskostnad | $8–14 (hobby) till $110–280 (tung användning) | $0 (gratisnivå) till $15/mån | | Underhållsbehov | Högt (uppdateringar, VPS, felsökning) | Nästan obefintligt — AI anpassar sig till layoutändringar | | Bäst för | Komplexa agentflöden, egna pipelines | Dataextraktion, formulärifyllning, leadgenerering, prisbevakning |
Användningsfallsstyrning
- Du behöver flerstegs-agentflöden som kedjar ihop webbläsaråtgärder med shell-kommandon, meddelandeappar och databaser → OpenClaw är rätt val.
- Du behöver skrapa data från webbplatser, fylla i formulär eller bevaka priser utan att röra terminalen → tar dig dit snabbare. Du kan också kika på för snabba demoexempel.
- Du behöver ett lätt skript för ett specifikt API-endpoint → Ett enkelt Python-skript med requests kan räcka.
Det här är faktiskt samma ramverk jag använder när någon i mitt team frågar: "vilket verktyg ska jag använda för det här?"
Vanliga fel vid OpenClaw-webbautomatisering och hur du fixar dem
Bokmärk det här avsnittet. Det är uppdelat efter symptom så att du kan använda Ctrl+F och hitta lösningen snabbt.
"Connection Refused" eller Node Host ansluter inte
Troliga orsaker (kolla i den här ordningen):
- Tailscale körs inte på båda enheterna → kör
tailscale statuspå båda - Gateway är inte inställd att lyssna på Tailscale-nätverket (fortfarande på localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - Fel IP-adress → dubbelkolla med
tailscale ip -4 - Brandväggen blockerar port 18789 →
sudo ufw allow 18789/tcp(Linux) eller lägg till en Windows-brandväggsregel
Tilläggsikonen står kvar på "OFF" eller fliken upptäcks inte
- Tillägget är inte laddat i Developer mode →
chrome://extensions→ aktivera Developer mode → ladda om - Node Host körs inte → starta om med
openclaw node start - Konflikt med Chrome-instans → stäng alla Chrome-fönster, starta om och ladda om tillägget
Agenten returnerar tom eller felaktig data
- Sidan har inte laddat klart: Instruera agenten att "vänta 3 sekunder efter navigering innan du extraherar." Många SPA:er behöver tid för att rendera.
- Bot-skydd blockerar: Kontrollera om du får en CAPTCHA-sida i stället för riktigt innehåll. Byt från Sandbox Chromium till Browser Relay.
- Gammalt snapshot: Be agenten att "ta ett nytt snapshot" — referensnummer blir inaktuella efter navigering.
"Port 9222 Already in Use"
Vanligt när Chrome DevTools eller ett annat automationsverktyg redan använder porten.
1# macOS/Linux
2lsof -i :9222 | grep LISTEN
3kill -9 <PID>
4# Windows PowerShell
5Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -ForceVPS:n får slut på minne
Varje headless webbläsarinstans använder 400–800 MB RAM. Om flera körs samtidigt kan en liten VPS krascha.
Lösningar:
- Stäng av inladdning av bilder/CSS/fonter:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Begränsa antalet samtidiga instanser till vad din RAM klarar
- Sätt
shm_size: '2gb'i Docker-konfigurationer - Aktivera session-hibernation:
OPENCLAW_HIBERNATE_AFTER=300 - Uppgradera till en VPS med 4 GB+ RAM om du behöver mer marginal
Tips för att hålla din OpenClaw-webbautomatisering stabil
Några bästa arbetssätt jag plockat upp när jag kört sådana här setup:er över tid:
- Stäng av bilder, stylesheets och fonter för uppgifter som bara handlar om data. Det minskar resursanvändningen rejält och gör allt snabbare.
- Återanvänd webbläsarinstanser i stället för att starta en ny för varje uppgift. Nya instanser kostar mycket RAM och triggar fler bot-signaler.
- Börja med enkla prompts. Lägg till mer detaljer först om agenten missförstår. För mycket beskrivning kan förvirra AI:n mer än det hjälper.
- Övervaka VPS:ens resursanvändning (CPU, RAM) och skala upp innan du når gränserna. En kraschad VPS klockan 02:00 är inget man vill felsöka.
- Håll OpenClaw och Chrome-tillägget uppdaterade — men testa uppdateringar i en stagingmiljö först. OpenClaw släpper ungefär , och alla är inte helt smärtfria.
- För återkommande uppgifter (dagliga prischeckar, veckovisa lead-uttag) låter Thunderbits dig sätta intervaller i vanlig text och slippa tänka på VPS-underhåll helt.
Etiska och juridiska aspekter
Kort men viktigt. Respektera robots.txt (formellt standardiserad av IETF i ), begränsa takten på dina förfrågningar, granska målwebbplatsens användarvillkor och hantera personuppgifter enligt GDPR och dataskyddslagstiftning. Prejudikatet (2022) slog fast att scraping av offentligt tillgänglig data inte bryter mot CFAA, men det betyder inte att allt är fritt fram. Ansvarsfull automatisering skyddar både dig och ditt företag. Läs gärna också vår guide om .
Avslutning
OpenClaw-webbautomatisering är ett kraftfullt alternativ för komplexa webbflöden i flera steg, styrda med naturligt språk. Det viktigaste att ta med sig:
- Välj rätt webbläsarläge direkt (Sandbox, Relay, Remote CDP) — det enda valet sparar timmar av felsökning.
- Windows-användare har en fungerande väg, men du måste följa Windows-specifika kommandon och hålla utkik efter brandväggs- och sökvägsproblem.
- Hantering av bot-skydd är en riktig utmaning — börja med de enklaste metoderna (timing, fingerprinting) och eskalera bara vid behov.
- Se resultatet innan du bestämmer dig. Om du bara behöver strukturerad data från en listingsida får du det snabbare med ett no-code-verktyg som på några minuter, utan löpande underhåll.
- Räkna med underhåll. OpenClaw släpper ungefär 13 versioner per månad, VPS-kostnaderna tickar på och felsökning ingår i paketet.
Om du vill prova den enkla vägen först erbjuder — installera tillägget, skrapa en sida och se om det täcker ditt behov innan du investerar i en full VPS-installation. Om du ändå väljer OpenClaw-vägen, bokmärk den här guiden. Du kommer förr eller senare behöva fellistan — och må dina webbläsarinstanser alltid ha tillräckligt med RAM.
Vanliga frågor
Vad är skillnaden mellan OpenClaw Sandbox Chromium och Browser Relay?
Sandbox Chromium kör en headless-webbläsare på servern — det går snabbt och kräver lite installation, men skapar en ny profil varje gång (inga inloggade sessioner) och är lättare för bot-skydd att upptäcka. Browser Relay skickar instruktioner till din riktiga Chrome på din lokala dator, vilket betyder att den stödjer inloggningar, använder din riktiga webbläsarprofil och är svårare för sajter att se som automatiserad. Nackdelen är att Browser Relay är långsammare på grund av nätverksbryggan och har vissa begränsningar i funktionaliteten (inga batchåtgärder, ingen avlyssning av nedladdningar).
Kan jag köra OpenClaw-webbautomatisering på Windows utan WSL?
Ja, men med vissa förbehåll. Den mest pålitliga nativa vägen på Windows är Chrome Remote Debugging via PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop är en fallback om det visar sig opålitligt. Fullt nativt stöd för Node Host på Windows kan fortfarande ha skavanker — kolla aktuell dokumentation och var beredd på Windows-specifika problem som brandväggsblockeringar och skillnader i binärsökvägar. Alla kommandon i Windows-delen av den här guiden är PowerShell, inte bash.
Hur hanterar jag CAPTCHA i OpenClaw-webbautomatisering?
Börja med att minska upptäcktsrisken: lägg in mänsklig timing, stärk webbläsarens fingerprint och använd sessionspersistens så att du inte ser ut som en ny browser varje gång. Om CAPTCHA ändå dyker upp, integrera en lösningstjänst som 2captcha ($2.99/1K lösningar) eller CapSolver ($0.80–1.50/1K, AI-driven). För offentliga webbplatser där du bara behöver datan hanterar Thunderbits molnscraping bot-skydd automatiskt utan proxy- eller CAPTCHA-konfiguration.
Är OpenClaw-webbautomatisering gratis att använda?
OpenClaw i sig är öppen källkod (MIT-licens) och gratis. Men att köra det kräver infrastruktur — en VPS för $4–15/mån, plus valfria tjänster som proxyrotation ($10–50/mån) eller CAPTCHA-lösare (betalning per lösning). Den totala månadskostnaden ligger någonstans mellan $8–14 för hobbybruk och $110–280 för tung automationsbelastning. Som jämförelse täcker grundläggande scraping utan infrastrukturkostnader.
Vad ska jag göra om min OpenClaw-agent hela tiden returnerar tomma resultat?
Tre saker att kolla, i ordning: För det första kanske sidan inte har laddat klart — instruera agenten att "vänta 3 sekunder efter navigering innan du extraherar." För det andra kan du träffa en bot-vägg — om agenten "ser" en CAPTCHA-sida i stället för riktigt innehåll, byt från Sandbox Chromium till Browser Relay. För det tredje kan snapshot-referenserna vara gamla — be agenten att "ta ett nytt snapshot" efter varje navigering. Om inget av detta hjälper, kontrollera VPS:ens minnesanvändning — en kraschad webbläsarinstans ger ofta tomma resultat utan tydliga fel.