Tempot i digitala nyheter i dag är, ärligt talat, helt galet. Varje minut publiceras, uppdateras eller smygredigeras tusentals rubriker – från stora redaktioner till nischbloggar och sociala flöden. Som jämförelse tar in över 4 miljoner nyhetsartiklar varje dag, medan följer nyheter på 100+ språk och uppdaterar sitt globala flöde var 15:e minut. För dig som jobbar med media, forskning eller business intelligence kan manuell bevakning kännas som att försöka ösa en sjunkande båt med en kaffekopp.
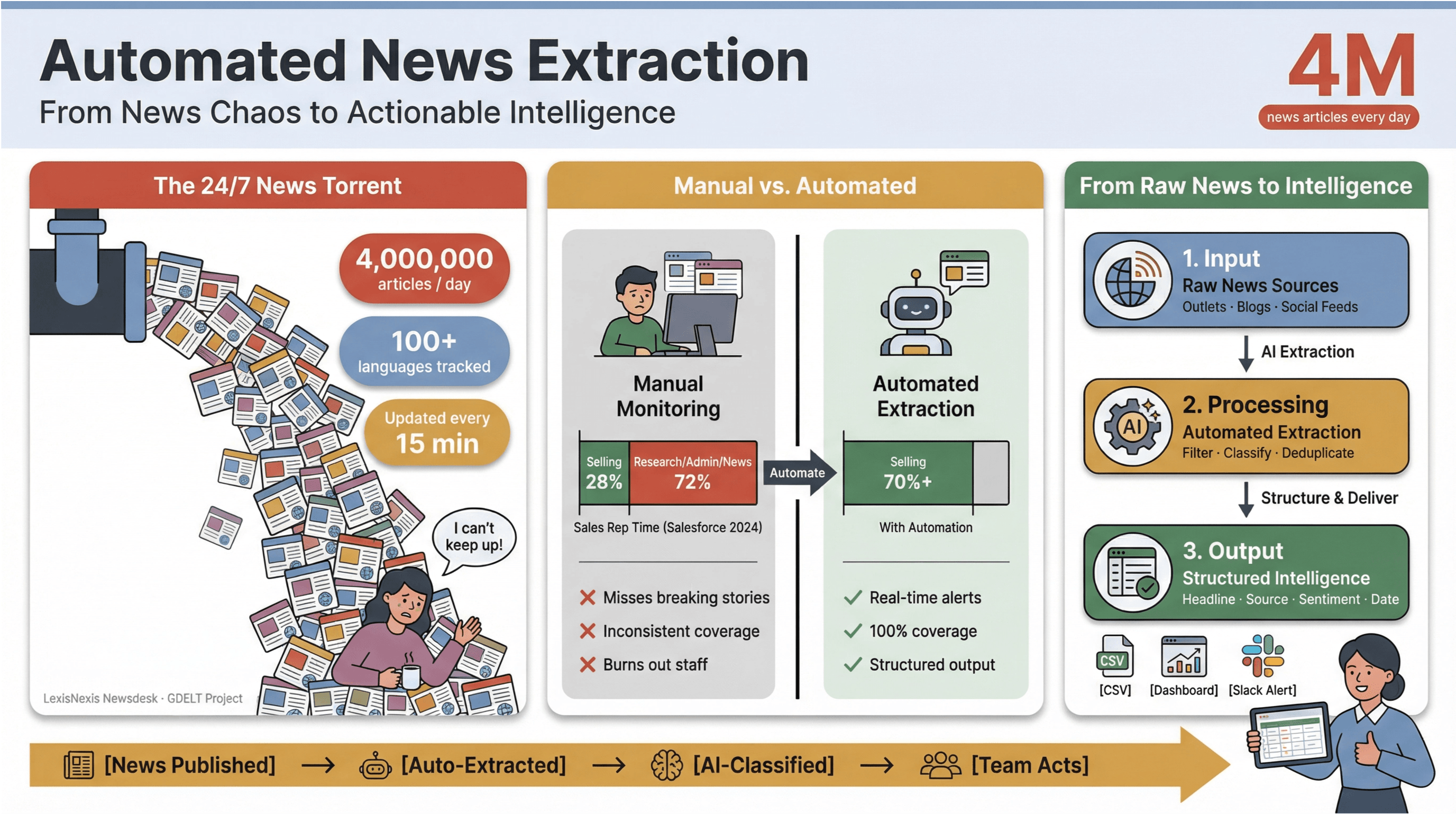
Jag har själv sett hur manuell nyhetsbevakning äter upp tid och suger musten ur team. Säljteam lägger mindre än en tredjedel av veckan på att faktiskt sälja – – och resten försvinner i research, admin och, ja, oändligt flik-hoppande mellan nyhetssajter. Därför har automatiserad nyhetsextraktion blivit ett riktigt ess i rockärmen för moderna team: det är i praktiken enda sättet att göra ett 24/7-nyhetsflöde till strukturerad, handlingsbar information – utan att bränna ut folk eller missa det som faktiskt spelar roll.
Vi går igenom vad automatiserad nyhetsextraktion egentligen är, varför det är kritiskt för alla som behöver nyhetsdata i realtid, och hur du bygger ett stabilt, “på riktigt”-arbetsflöde med rätt verktyg (inklusive hur gör det förvånansvärt enkelt – även för icke-tekniska användare som min mamma).
Automatiserad nyhetsextraktion: varför det är avgörande för moderna redaktioner
Automatiserad nyhetsextraktion är exakt vad det låter som: att använda programvara för att samla in nyhetsinnehåll automatiskt och göra om det till strukturerad, sökbar data – tänk rader och kolumner i stället för stökiga webbsidor eller PDF:er. I praktiken betyder det att du kan bevaka hundratals (eller tusentals) källor, plocka ut nyckelfält som rubrik, tidsstämpel, författare och brödtext, och mata in datan i dashboards, larm eller vidare analys – utan att behöva leva på Ctrl+C/Ctrl+V.
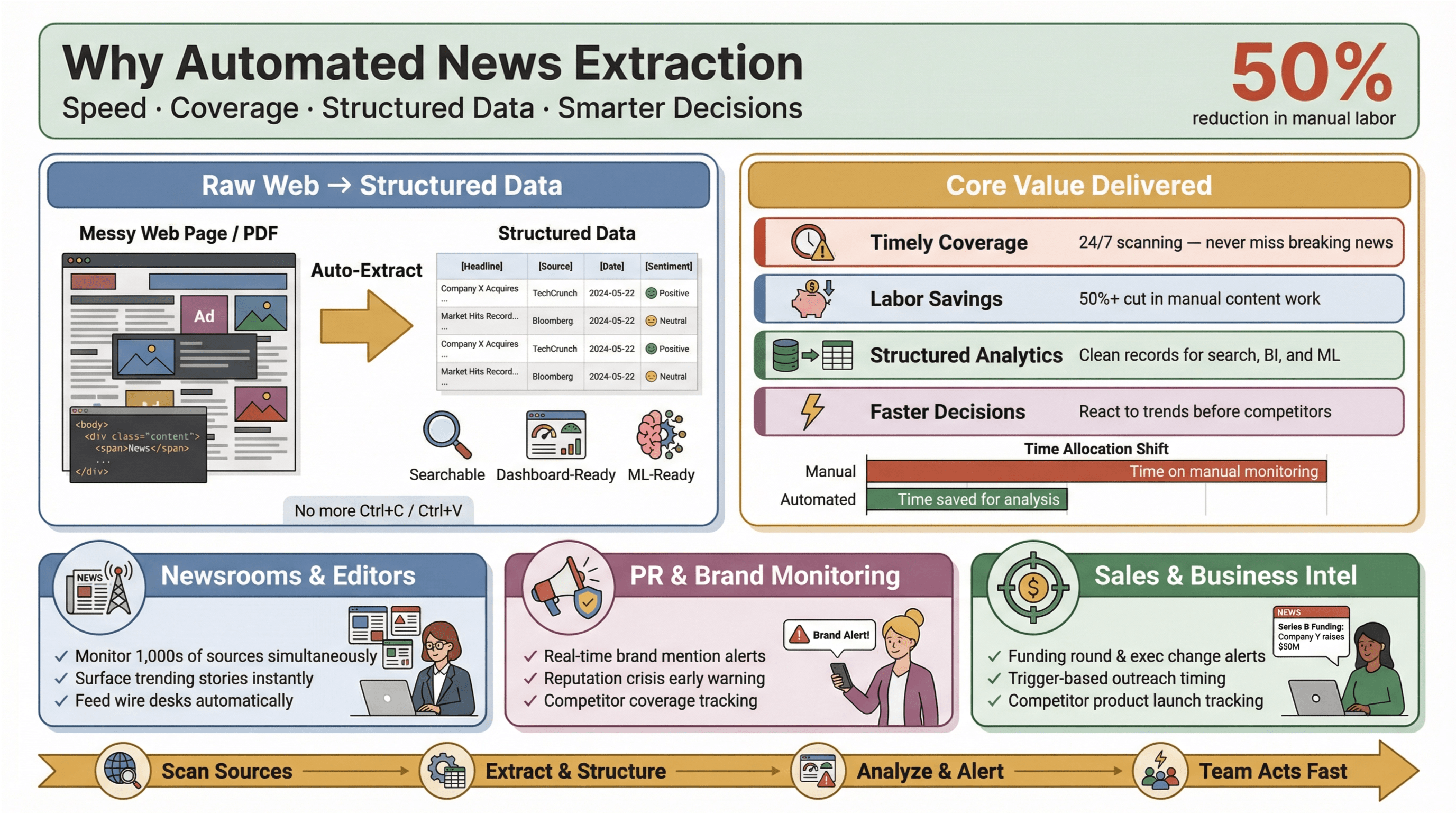 Varför är det här viktigt? För i dagens nyhetslandskap är hastighet allt. Oavsett om du är redaktör, PR-ansvarig som håller koll på varumärkesomnämnanden eller analytiker som följer konkurrenters drag, kan förstahandsinfo vara skillnaden mellan att fånga en möjlighet och att hamna på efterkälken. Automatiserad extraktion gör att även små team kan leverera långt över sin viktklass – samla nyhetsdata i realtid från hela webben, kapa manuellt slit och lyfta fram det som är mest relevant.
Varför är det här viktigt? För i dagens nyhetslandskap är hastighet allt. Oavsett om du är redaktör, PR-ansvarig som håller koll på varumärkesomnämnanden eller analytiker som följer konkurrenters drag, kan förstahandsinfo vara skillnaden mellan att fånga en möjlighet och att hamna på efterkälken. Automatiserad extraktion gör att även små team kan leverera långt över sin viktklass – samla nyhetsdata i realtid från hela webben, kapa manuellt slit och lyfta fram det som är mest relevant.
Och effekten är tydlig: studier visar att automatisering kan minska manuellt arbete för innehållsuppdateringar med minst 50 %, vilket frigör tid för analys och beslut.
Kärnnyttan med automatiserad nyhetsextraktion i nyhetsbranschen
Låt oss snacka konkret. Vad ger automatiserad nyhetsextraktion i praktiken för redaktioner och affärsteam?
- Aktuell och heltäckande bevakning: Inga fler missade nyheter för att någon glömde kolla ett flöde. Automatiska verktyg skannar källor dygnet runt.
- Mindre arbete och lägre kostnader: Små och medelstora team kan bevaka lika många källor som de stora – utan att behöva anställa en hel armé av praktikanter.
- Strukturerad data för analys: I stället för att gräva i ostrukturerade artiklar får du rena poster som är redo för sök, dashboards och maskininlärning.
- Snabbare och smartare beslut: Nyhetsdata i realtid gör att du kan agera på marknadsrörelser, PR-kriser eller trender före konkurrenterna.
Inom PR och kommunikation lyfter plattformar som och fram realtidsbevakning som avgörande för att skydda varumärket och kunna agera snabbt vid negativ rapportering. I försäljning blir nyhetslarm till “kontextkort” för prospektering – till exempel finansieringsrundor, ledningsförändringar eller produktlanseringar som triggar kontakt vid helt rätt tillfälle.
Välja rätt verktyg för nyhetsscraping i olika scenarier
Alla verktyg för nyhetsscraping är inte skapade lika. Rätt val beror på dina mål, din tekniska nivå och vilka typer av nyheter du behöver. Här är en enkel modell för att landa rätt:
Utvärdera användarvänlighet och tillgänglighet
För de flesta affärsanvändare och journalister är användarvänlighet inte förhandlingsbart. Du vill ha ett verktyg som funkar direkt, utan kod och utan krångliga inställningar. No-code- och low-code-plattformar som , och låter dig bygga scrapers visuellt – peka, klicka, extrahera.
Thunderbit sticker särskilt ut med sin tvåstegsprocess: beskriv vad du vill ha, låt AI:n föreslå fält och tryck på “Scrape”. Även icke-tekniska användare kan få upp en pipeline för nyhetsdata på minuter, inte timmar.
Säkerhet och dataskydd
Mer data innebär också mer ansvar. Verktyg för nyhetsscraping kan komma åt känsligt innehåll, så säkerhet och regelefterlevnad måste ligga högt på listan. Leta efter:
- Kryptering (under överföring och i vila)
- Tydliga integritetspolicys (Thunderbit säger till exempel att de inte säljer användardata och bara kommer åt innehåll du själv väljer att extrahera)
- Detaljerade behörigheter (särskilt för webbläsartillägg – kolla alltid vilken data verktyget kan läsa)
- Efterlevnad av lokala lagar (GDPR, CCPA och för EU-användare )
För extra trygghet: välj etablerade leverantörer, granska tilläggsbehörigheter och begränsa åtkomst till det som faktiskt behövs.
Matcha verktyg mot nyhetstyper och branschbehov
Vissa verktyg är extra vassa inom specifika nyhetsområden:
- Finans: API:er som och erbjuder klustring, sentiment och händelsedetektering för finansnyheter.
- Tech & startups: Anpassad scraping med Thunderbit eller Octoparse gör att du kan sikta in dig på nischbloggar, pressmeddelanden eller eventlistor.
- Politik & policy: Licensierade databaser som och ger tillgång till premiumkällor och arkiv.
Om du behöver bevaka en mix av stora medier, nischkällor och internationella sajter – inklusive sådana utan API:er – är flexibla AI-drivna scrapers som Thunderbit ofta det mest rimliga valet.
Thunderbits unika fördelar för extraktion av nyhetsdata i realtid
Nu till det som gör till ett starkt val för automatiserad nyhetsextraktion – särskilt om du vill ha nyhetsdata i realtid utan tekniskt strul.
Thunderbit är ett AI-drivet web scraper Chrome-tillägg byggt för affärsanvändare, journalister och analytiker som behöver uppdaterat, strukturerat nyhetsinnehåll från vilken webbplats som helst. Därför är det mitt förstaval:
- AI Suggest Fields: Thunderbit läser nyhetssidan och föreslår automatiskt de bästa kolumnerna att extrahera – rubrik, tidsstämpel, författare, sammanfattning med mera. Du slipper mecka med selektorer eller mallar.
- Subpage Scraping: Behöver du hela artikeln, inte bara rubriken? Thunderbit kan gå in på varje nyhetslänk, hämta brödtext, entiteter och taggar och slå ihop allt i en strukturerad tabell.
- Mass-export och snabba uppdateringar: Exportera direkt till Excel, Google Sheets, Airtable eller Notion med ett klick. Inga copy-paste-maraton eller CSV-strul.
- Scheduled Scraping: Skapa återkommande körningar (varje timme, dagligen eller egna intervall) för att hålla flödet fräscht – perfekt för breaking news, marknadsbevakning eller löpande research.
- Anpassningsförmåga: Thunderbits AI klarar layoutändringar och “long-tail”-nyhetssajter, så du lägger mindre tid på att laga trasiga scrapers och mer tid på analys.
Med över och 4,8 i betyg används det av team världen över – från PR-bevakning till konkurrensanalys.
AI-driven fältidentifiering och Subpage Scraping
En av Thunderbits mest imponerande funktioner är AI-driven fältidentifiering. Klicka på “AI Suggest Fields” så skannar verktyget nyhetssidan och plockar upp nyckelfält som titel, datum, författare och sammanfattning. Du kan finjustera eller lägga till egna fält (till exempel “tagga artikeln som ‘rapport’ om den nämner kvartalsresultat”), och Thunderbits AI tar hand om resten.
Subpage Scraping är en riktig game changer för nyheter: hämta rubriker från en startsida eller sektionslista och låt sedan Thunderbit besöka varje artikel-URL för att extrahera hela texten, entiteter och till och med bilder. Resultatet blir kompletta och berikade nyhetsposter – redo för sök, dashboards eller vidare AI-analys.
Mass-export och snabba uppdateringar
Thunderbit gör exporten löjligt smidig. Med ett klick skickar du ditt strukturerade nyhetsflöde till Google Sheets, Airtable, Notion eller laddar ner som CSV/Excel. För team som lever i kalkylark eller BI-verktyg är det en brutal tidsbesparing.
Och eftersom Thunderbit stödjer Scheduled Scraping kan du köra varje timme, varje dag eller enligt eget schema – så att nyhetsdatan alltid är uppdaterad. Du slipper sitta och vänta på att Google Alerts ska indexera artiklar flera dagar för sent.
Hantera operativa utmaningar i lösningar för nyhetsdata i realtid
Även med bra verktyg finns det utmaningar med nyhetsextraktion i realtid. Så här tar du hand om de vanligaste:
Hantera latens och datans aktualitet
- Schemalägg scraping efter nyhetstempo: För snabba nyheter, kör var 15–30:e minut (i linje med ). För långsammare områden räcker timvis eller dagligen.
- Följ upp skillnaden mellan publicering och hämtning: Mät tiden mellan när artikeln publiceras och när ditt system hämtar den. Om fördröjningen ökar kan det bero på blockeringar eller prestanda.
- Skrapa om för “tysta redigeringar”: Artiklar uppdateras ofta efter publicering. Lägg in en andra körning 24 timmar senare för att fånga rättelser eller diskreta ändringar ().
Hantera API-begränsningar och variation mellan källor
- Respektera API-kvoter: Om du använder nyhets-API:er, håll koll på rate limits – sprid anrop över tid och cache:a resultat när det går ().
- Avduplicera och kanonisera: Nyheter kan dyka upp på flera URL:er eller uppdateras. Spara kanoniska URL:er och använd hash (t.ex. titel + datum) för att undvika dubbletter ().
- Hantera dynamiskt innehåll: För sajter med oändlig scroll eller lazy loading, använd verktyg som klarar dynamisk rendering och håll koll på layoutändringar ().
Smart analys av nyhetsdata: AI och maskininlärning
Att extrahera nyheter är bara första steget. Det riktiga värdet kommer när du analyserar och agerar på datan – och där är AI och maskininlärning riktigt kraftfullt.
- Entitetsextraktion: Använd NLP för att plocka ut personer, organisationer och platser som nämns i artikeln ().
- Ämnesklassificering: Tagga artiklar automatiskt efter ämne, sentiment eller brådska – för smartare dashboards och larm ().
- Händelseklustring: Gruppera dubbletter eller relaterade artiklar mellan olika medier så att du ser helheten (inte bara en flod av nästan identiska rubriker).
- Personalisering och målgruppsstyrning: Använd nyhetsdata i realtid för segmentering, bättre annonsinriktning eller innehållsrekommendationer – vilket kan öka engagemang och ROI.
Till exempel använder PR-team realtidsanalys för att upptäcka kriser innan de smäller, medan säljteam berikar prospektlistor med “trigger events” som finansieringsrundor eller nyrekryteringar i ledningen.
Checklista: bästa praxis för automatiserad nyhetsextraktion
Här är en snabb checklista för att hålla din pipeline stabil:
| Bästa praxis | Varför det är viktigt | Så gör du |
|---|---|---|
| Schemalägg täta körningar | Minska fördröjning, fånga breaking news | Anpassa frekvens efter nyhetstempo (t.ex. var 15:e minut för snabba flöden) |
| Använd AI-driven extraktion | Tål layoutändringar, snabbare uppstart | Verktyg som Thunderbit, Diffbot, Zyte API |
| Avduplicera och kanonisera | Undvik dubbla larm, håll datan ren | Spara kanoniska URL:er, använd hash för avduplicering |
| Övervaka extraktionskvalitet | Fånga saknade fält, drift eller fel | Följ andel kompletta poster, latens och felgrad |
| Respektera juridik/efterlevnad | Minska juridisk risk, behåll förtroende | Föredra officiella API:er/flöden, granska villkor, minimera persondata |
| Exportera till strukturerade format | Möjliggör vidare analys | CSV, Excel, Sheets, Notion, Airtable |
| Schemalägg omkörningar för redigeringar | Fånga ändringar efter publicering | Besök artiklar igen efter 24 h/1 v (GDELT-modellen) |
| Säkra din pipeline | Skydda känslig data | Kryptering, åtkomstkontroller, pålitliga verktyg |
Bygg ett robust arbetsflöde för automatiserad nyhetsextraktion
Vill du bygga din egen “svarta låda” för nyhetsdata? Här är ett steg-för-steg-upplägg:
- Identifiera dina källor: Lista nyhetssajter, bloggar eller API:er du vill bevaka.
- Sätt upp extraktion: Använd Thunderbit eller valfritt verktyg för att definiera fält (AI Suggest Fields gör det enkelt).
- Schemalägg körningar: Välj frekvens efter nyhetstempo – timvis för snabba nyheter, dagligen för långsammare.
- Berika via undersidor: För varje rubrik, hämta hela artikeln (brödtext, entiteter, taggar).
- Avduplicera och normalisera: Spara kanoniska URL:er, hasha poster och standardisera fält.
- Exportera och integrera: Skicka strukturerad data till Excel, Google Sheets, Airtable eller Notion.
- Övervaka och anpassa: Följ kvalitet, håll koll på layoutändringar och justera vid behov.
- Håll dig compliant: Läs villkor, respektera robots.txt och minimera persondata.
Som en visuell kedja:
Källor → Extraktion (AI-fält) → Berikning via undersidor → Avduplicering → Export → Analys/Larm → Övervakning
Slutsats och viktigaste insikterna
Automatiserad nyhetsextraktion är inte längre “nice to have” – det är ett måste för alla som vill ligga steget före i en värld där nyheter både bryter och förändras minut för minut. Med rätt bästa praxis och rätt verktyg kan du förvandla den digitala nyhetsbrandposten till ett stabilt flöde av strukturerad, handlingsbar information.
Viktigaste takeaways:
- Skalan och hastigheten i online-nyheter kräver automatisering – manuell bevakning räcker inte.
- Verktyg för automatiserad nyhetsextraktion sparar tid, sänker kostnader och gör att små team kan matcha betydligt större organisationers bevakning.
- Rätt verktyg handlar om balans mellan användarvänlighet, säkerhet och anpassningsförmåga – Thunderbit utmärker sig med AI-driven enkelhet och export i realtid.
- Bygg arbetsflödet kring aktualitet, avduplicering, efterlevnad och kvalitetsövervakning för att få pålitlig och användbar nyhetsdata.
- AI och maskininlärning skapar ännu mer värde – smartare målgruppsstyrning, personalisering och beslutsstöd.
Om du fortfarande copy-pastar rubriker eller väntar på att Google Alerts ska hinna ikapp är det dags att växla upp. och se hur enkelt automatiserad nyhetsextraktion kan vara. För fler tips, arbetsflöden och fördjupningar, besök .
Vanliga frågor (FAQ)
1. Vad är automatiserad nyhetsextraktion och hur fungerar det?
Automatiserad nyhetsextraktion innebär att programvara samlar in nyhetsartiklar och gör om dem till strukturerad data (t.ex. tabeller eller JSON) för analys, sök eller larm. Verktyg som Thunderbit använder AI för att identifiera viktiga fält (rubrik, tidsstämpel, författare, brödtext) och extrahera dem automatiskt från webbsidor eller API:er.
2. Varför är nyhetsdata i realtid så viktigt för företag?
Nyhetsdata i realtid gör att företag kan reagera snabbt på marknadshändelser, PR-kriser eller konkurrenters drag. Oavsett om du jobbar med försäljning, PR eller research ger uppdaterade nyheter bättre och snabbare beslut – och ett försprång.
3. Hur gör Thunderbit nyhetsscraping enklare för icke-tekniska användare?
Thunderbit har en enkel tvåstegsprocess: beskriv vilken data du vill ha och låt AI:n föreslå fält. Med funktioner som Subpage Scraping och direkt export till Excel eller Google Sheets kan även icke-tekniska användare bygga stabila pipelines på några minuter.
4. Vilka juridiska och compliance-aspekter bör man tänka på vid nyhetsscraping?
Granska alltid användarvillkoren för de sajter du vill hämta från, använd helst officiella API:er eller flöden när de finns och respektera robots.txt. Undvik att skrapa inloggningskrävt eller betalväggat innehåll utan tillstånd och minimera insamling av personuppgifter för att följa integritetslagar.
5. Hur säkerställer jag att mitt arbetsflöde för nyhetsextraktion är stabilt över tid?
Schemalägg regelbundna körningar, övervaka extraktionskvalitet och använd verktyg som klarar layoutändringar (som Thunderbits AI-drivna extraktion). Avduplicera poster, följ fördröjningen mellan publicering och extraktion och sätt upp larm vid fel eller saknade fält för att hålla pipelinen frisk och uppdaterad.
Läs mer