
En crawl-baserad studie av hur webbplatser med hög trafik publicerar maskinläsbara riktlinjer för stora språkmodeller, hur tidiga implementationer ser ut och varför mätning av användning kräver mer än att räkna HTTP 200-svar.
- Dataset:
data/llms_probe_results_top_10000.csv - Tranco-lista nedladdad: 6 maj 2026
- Omfattning: root-nivåns
/llms.txtoch/llms-full.txt
Viktiga mätetal
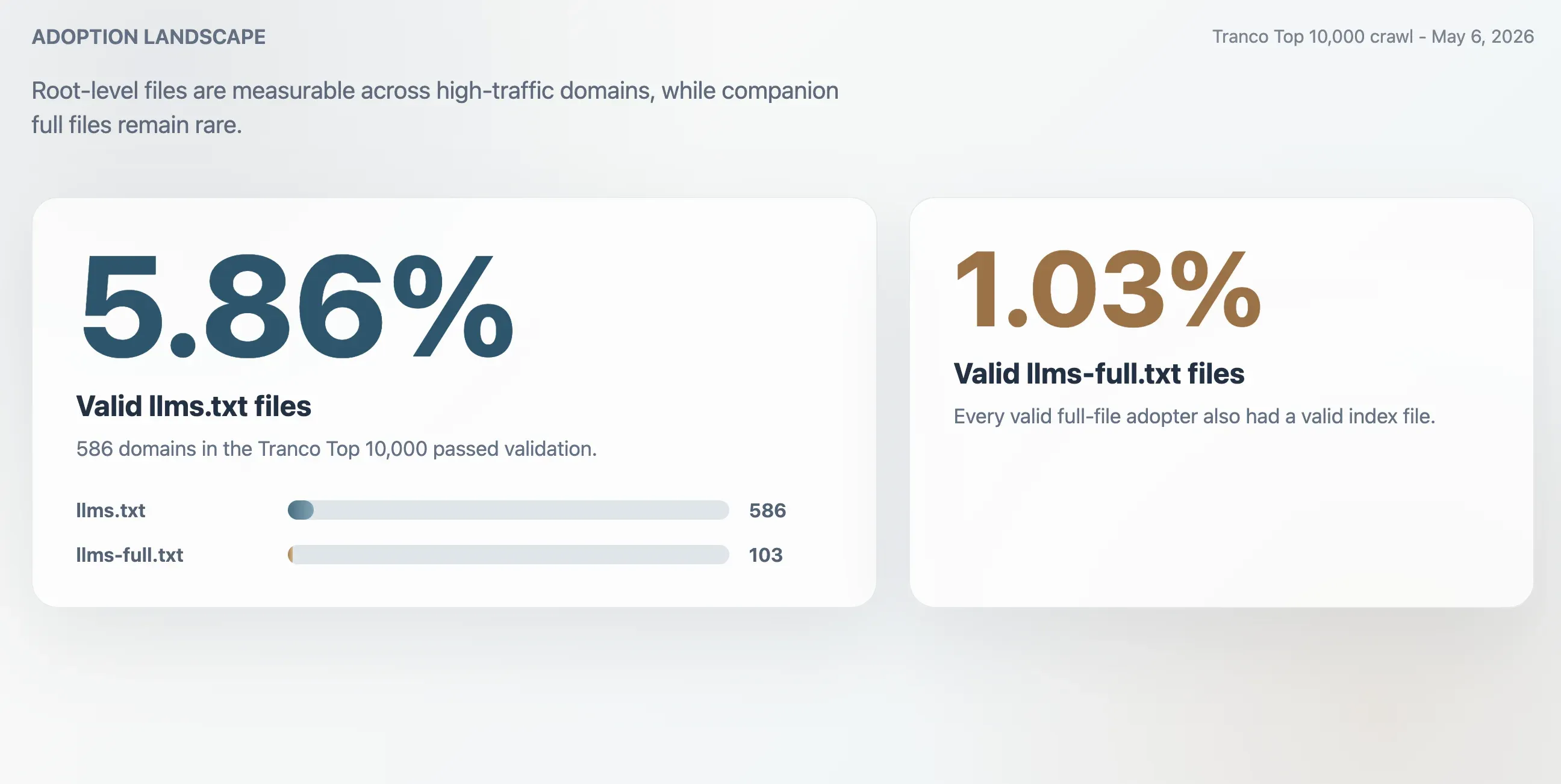
- 5,86 %: Giltig användning av
llms.txti Tranco Top 10 000, motsvarande 586 domäner. - 1,03 %: Giltig användning av
llms-full.txt, motsvarande 103 domäner. Varje giltig fullfilsanvändare hade också en giltig indexfil. - 63,51 %: Andel HTTP 200-svar för
/llms.txtsom inte klarade valideringen. - 2,74x: Ungefärlig överskattning om användning mättes enbart genom råa HTTP 200-svar.
Sammanfattning
llms.txt är fortfarande en tidig webbstandard, men det är inte längre bara ett marginellt experiment. I en crawl av Tranco Top 10 000-domäner den 6 maj 2026 hittade denna studie 586 giltiga llms.txt-filer, vilket ger en observerad användningsgrad på 5,86 %. Den kompletterande filen llms-full.txt var betydligt ovanligare: 103 domäner hade en giltig fullfil, vilket motsvarar 1,03 %.
Det viktigaste metodologiska fyndet är att statuskoder är en dålig proxy för användning. Crawlern registrerade 1 606 HTTP 200-svar för /llms.txt, men bara 586 klarade valideringen. De återstående 1 020 bestod främst av omdirigeringar till fel mål, generiska HTML-sidor, tomma svar eller andra ogiltiga responser. En naiv crawler som räknar varje 200-svar som användning skulle överskatta den verkliga användningen med omkring 2,74 gånger.
Bland de giltiga användarna är implementeringskvaliteten högre än vad en ren platshållarbild skulle antyda. Medianstorleken för en giltig fil var cirka 7,1 KB, 61,77 % av de giltiga filerna var större än 5 KB, 70,82 % innehöll sex eller fler Markdown-sektioner och 77,47 % innehöll 11 eller fler Markdown-länkar. Bland de tidiga användarna finns Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog och Cloudinary.
llms.txtbör bäst förstås som en förklarande och navigerande signal för AI-system, inte som en ersättning förrobots.txt. Dess värde ligger inte bara i att filen finns, utan i om den hjälper maskiner att hitta auktoritativ, kompakt och aktuell information.
Kontext: webben lägger till AI-riktade signaler
Webbplatser har länge använt robots.txt för att uttrycka crawler-preferenser, sitemap.xml för att förbättra upptäckten av URL:er och strukturerad data för att hjälpa sök- och plattformssystem att tolka sidor. Generativ AI introducerar ett annat problem. Innehåll kan användas för träning, retrieval, sammanfattning, agentisk surfning, kodassistans, kundsupport och svarsgenerering. Det skapar två samtidiga behov: publicister vill ha mer kontroll över automatiserad användning, men de vill också att AI-system hittar rätt kanonisk information när systemen faktiskt interagerar med deras webbplatser.
Det ursprungliga förslaget för llms.txt, som introducerades av Jeremy Howard 2024, beskriver filen som ett Markdown-dokument placerat i webbplatsens rot för att ge LLM-vänlig information vid inferenstidpunkt. Förslaget hävdar att HTML-sidor ofta innehåller navigering, annonsering, skript och annat brus som gör dem svårare för språkmodeller att bearbeta. En kortfattad Markdown-fil kan leda modellerna till de viktigaste sidorna, dokumentationen, API:erna, exemplen, policyerna och produktinformationen.
Extern webbforskning ger en bredare bakgrund. Data Provenance Initiative's “Consent in Crisis” beskriver en snabb ökning av AI-relaterade begränsningar i robots.txt och användarvillkor, och hävdar att befintliga samtyckesmekanismer på webben inte var utformade för AI-återanvändning av data i stor skala. Cloudflare Radar AI Insights har också gjort AI-crawler- och robots.txt-mönster synliga på nivån för topp 10 000 domäner. I det sammanhanget hamnar llms.txt på den konstruktiva sidan av AI-signaler: inte ”crawla inte detta”, utan ”om du behöver förstå den här webbplatsen, börja här”.
Extern evidens och debatten om användning
Den offentliga debatten kring llms.txt är splittrad mellan två påståenden. Det optimistiska påståendet är att filen ger AI-system en renare och effektivare väg till auktoritativt innehåll. Det skeptiska påståendet är att ingen större LLM-leverantör offentligt har förbundit sig att använda den som signal för rankning, crawlning eller citering, så publicister bör inte förvänta sig trafikvinster enbart från filen. De tre externa källor som granskats för denna uppdatering stödjer en mer nyanserad slutsats: llms.txt är användbar infrastruktur, men evidensen för direkt trafikpåverkan är fortfarande begränsad och kontextberoende.
Externa riktmärken för användning förändras snabbt
Rankabilitys användningsspårare rapporterade en användningsgrad på 0,3 % bland de 1 000 största webbplatserna per den 22 juni 2025, eller 3 av 1 000 sajter. Den beskriver månatlig automatiserad genomsökning av domain.com/llms.txt, med validering som utesluter omdirigeringar och HTML-svar. Den metoden ligger riktningenligt nära denna studies försiktiga valideringsansats.
Skillnaden i resultat är stor: denna studie fann 75 giltiga llms.txt-filer i Tranco Top 1 000 den 6 maj 2026, eller 7,50 %. De två siffrorna ska inte behandlas som en strikt tidsserie eftersom rankingkällan, implementeringsdetaljerna, valideringslogiken och crawl-tidpunkten kan skilja sig åt. Ändå antyder kontrasten att användningen förändrades märkbart mellan mitten av 2025 och maj 2026, särskilt bland utvecklar-, SaaS-, moln-, säkerhets- och dokumentationstunga sajter.
| Källa | Snapshot | Urval | Rapporterad giltig användning | Tolkning |
|---|---|---|---|---|
| Rankability | 22 juni 2025 | Topp 1 000 webbplatser | 0,3 % | Tidigt offentligt riktmärke som visade minimal användning i mitten av 2025. |
| Denna studie | 6 maj 2026 | Tranco Top 1 000 | 7,50 % | Senare crawl som visade tydlig användning bland webbplatser med hög trafik. |
| Denna studie | 6 maj 2026 | Tranco Top 10 000 | 5,86 % | Större urval som visar att användningen är mätbar men inte mainstream. |
Trafikexperimenten ger blandade resultat
Search Engine Land publicerade en analys av 10 sajter i januari 2026 som följde sajter i 90 dagar före och 90 dagar efter implementering. Artikeln rapporterade att två sajter såg ökningar i AI-trafik på 12,5 % och 25 %, åtta såg ingen mätbar förbättring och en sjönk med 19,7 %. Den viktigaste tolkningen var kausal försiktighet: de två till synes framgångsrika fallen lanserade också nya mallar, byggde om resurscenter, lade till extraherbara jämförelsetabeller, fick pressbevakning, åtgärdade tekniska problem eller publicerade nytt FAQ-liknande innehåll. I den ramen dokumenterade llms.txt starkare innehålls- och teknikarbete; det verkade inte orsaka tillväxten på egen hand.
Renat Alimbekovs personliga bloggexperiment drog en mer positiv slutsats från en mindre observation på sajtnivå. Det jämförde två fyramånadersperioder i Yandex.Metrica efter att både llms.txt och llms-full.txt hade lagts till. LLM-hänvisningssessioner ökade från 75 till 92, en ökning med 23 %, medan användare ökade från 51 till 64. Perplexity-sessioner ökade från 29 till 55, medan ChatGPT-sessioner sjönk från 31 till 26. Samma inlägg noterar också att den totala hänvisningstrafiken växte snabbare, från 160 till 290 sessioner, så LLM-andelen av sessionerna föll från 47 % till 32 %.
| Typ av evidens | Observerat resultat | Huvudreservation | Hur det påverkar denna rapport |
|---|---|---|---|
| Search Engine Lands före/efter-studie på 10 sajter | Två sajter ökade, åtta hade ingen mätbar förändring, en sjönk. | De positiva fallen hade samtidigt innehålls-, PR- och tekniska förändringar. | Stödjer att llms.txt ses som infrastruktur, inte som en ensam tillväxtspak. |
| Alimbekovs observation före/efter på personlig blogg | LLM-hänvisningssessioner ökade 23 % under perioden efter. | Ingen kontrollgrupp; total hänvisningstrafik ökade 81 % och LLM-andelen sjönk. | Tyder på möjlig uppsida för tekniska bloggar, särskilt via Perplexity, men kausaliteten är inte isolerad. |
| Denna crawl-baserade användningsstudie | 586 giltiga filer och många strukturerade implementationer. | Mäter förekomst och struktur, inte nedströms trafikpåverkan. | Visar användning och implementeringsmognad, men inte ROI i sig. |
Vad debatten klargör
Den externa evidensen skärper tolkningen av detta dataset. En välstrukturerad llms.txt-fil kan minska friktionen för maskinell tolkning, särskilt för utvecklardokumentation, API-referenser och kunskapsbasinnehåll. Men de starkaste trafikfallen verkar fortfarande bero på innehåll som är användbart, extraherbart, auktoritativt och upptäckbart även utanför filen. Därför är den praktiska frågan inte isolerat ”spelar llms.txt roll?”. Den är i stället om filen ingår i ett bredare AI-läsbart innehållssystem.
Uppdaterad tolkning:
llms.txtbör implementeras som billig AI-riktad infrastruktur. Den bör inte positioneras som en ersättning för bättre dokumentation, strukturerat innehåll, teknisk tillgänglighet, källhänvisningar, länkar eller varumärkesauktoritet.
Testa Thunderbit för AI-webbskrapning
Metod
Den här studien använde Tranco Top 10 000-domäner som urval. Tranco är en forskningsinriktad toppliste-ranking som är utformad för att vara stabilare och mer motståndskraftig mot manipulation än många traditionella topplistor. Tranco-källfilen laddades ner den 6 maj 2026, med en Last-Modified-tidsstämpel från källan den 5 maj 2026 kl. 22:17:59 GMT.
Crawlern testade två sökvägar på rotnivå för varje domän:
https://example.com/llms.txt, med HTTP-fallback vid behov.https://example.com/llms-full.txt, med HTTP-fallback vid behov.
För varje test registrerade crawlern statuskod, slutlig URL, hämtningsmetod, svarsstorlek i byte, content type, felmeddelande, förfluten tid och valideringsresultat. Lyckade svarsbody sparades under raw_llms_txt/ för granskning och sekundär analys.
Valideringsregler
Ett svar räknades som en giltig fil endast om det returnerade en lyckad body och inte såg ut som en generisk webb-fallback. Den slutliga URL-sökvägen måste förbli /llms.txt eller /llms-full.txt. Tomma bodies avvisades. Uppenbara HTML-dokument och app shells avvisades. Content type användes som stödjande bevis snarare än som enda regel, eftersom ett litet antal giltiga textliknande filer serverades med ovanliga content types.
Användningslandskapet
Crawlningen fann 586 giltiga llms.txt-filer i Tranco Top 10 000. Det ger en giltig användningsgrad på 5,86 %. Den mindre kompletterande filen llms-full.txt fanns och var giltig på 103 domäner, eller 1,03 % av urvalet.
| Mått | Antal | Andel av Top 10 000 |
|---|---|---|
| Domäner crawled | 10 000 | 100,00 % |
| Giltiga llms.txt-filer | 586 | 5,86 % |
| Giltiga llms-full.txt-filer | 103 | 1,03 % |
| HTTP 200-svar för /llms.txt | 1 606 | 16,06 % |
| HTTP 200-svar som avvisades som ogiltiga | 1 020 | 10,20 % |
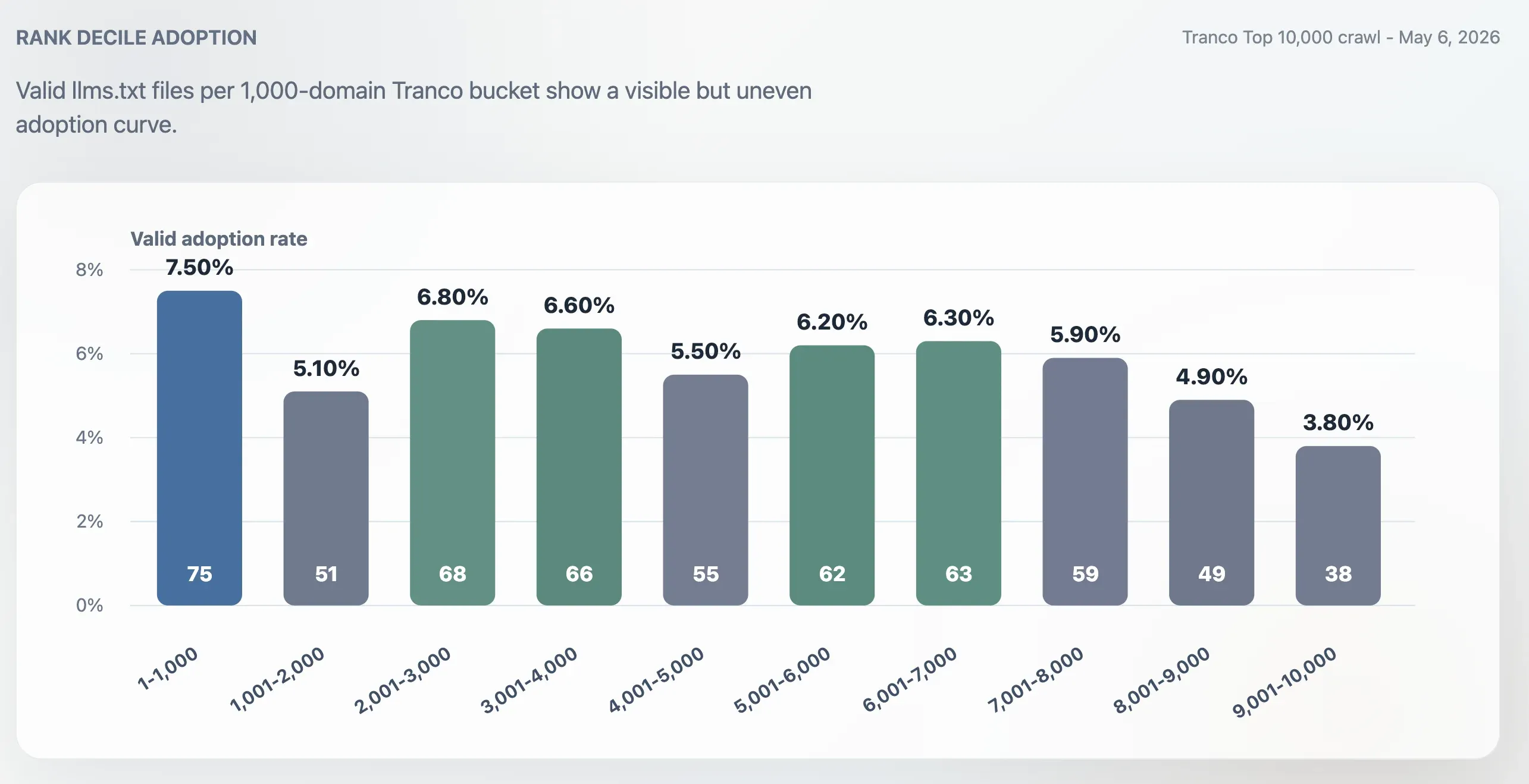
Användningen är inte bara topp-tung
Användningen var högre i Top 1 000 än i hela Top 10 000, men den var inte begränsad till de allra största sajterna. Användningsgraden i Top 1 000 var 7,50 %. Den sista gruppen om 1 000 domäner, placering 9 001–10 000, sjönk till 3,80 %. Mitten av rankningen förblev aktiv: intervallen 2 001–3 000, 3 001–4 000, 5 001–6 000 och 6 001–7 000 landade alla runt 6 %.
Tidiga användare
Den högst rankade giltiga användaren var Cloudflare på Tranco-rank 4. Andra högt rankade användare inkluderade Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink och OneSignal.
Dessa användare är inte slumpmässiga. De tenderar att ha stora dokumentationsytor, produktlinjer som behöver förklaras, API:er eller utvecklarekosystem, supportinnehåll, prissidor, säkerhets- och integritetsmaterial samt tillräcklig varumärkesauktoritet för att bry sig om hur AI-system tolkar deras webbplatser.
| Rank | Domän | Filstorlek | Observerat mönster |
|---|---|---|---|
| 4 | cloudflare.com | 4 225 B | Kompakt index för produkt, utvecklare, företag och prissättning. |
| 26 | azure.com | 47 037 B | Utvecklarverktyg, AI, beräkning, lagring, säkerhet, övervakning och valfria resurser. |
| 28 | github.com | 27 108 B | Programmatisk åtkomst, Copilot, MCP, REST API, Actions, repositories och CLI-länkar. |
| 248 | stripe.com | 64 229 B | Betalningar, Connect, Checkout, Billing, Tax, Atlas, Radar och utvecklardokumentation. |
| 265 | salesforce.com | 1,02 MB | Massivt produkt- och Agentforce-länkarkiv, utan Markdown-rubriker för sektioner. |
Kategorier bland användare i Top 1 000
Denna studie klassificerade de 75 giltiga användarna i Tranco Top 1 000 med hjälp av domänkontext, första rubriker, rå filstruktur och innehållsnyckelord. Den största gruppen var marknadsföring, media och adtech med 22,67 %. Sajter inom moln, utveckling och infrastruktur stod för 20,00 %. SaaS, produktivitet och kunddrift stod för 17,33 %. Säkerhet, identitet och integritet stod för 12,00 %.
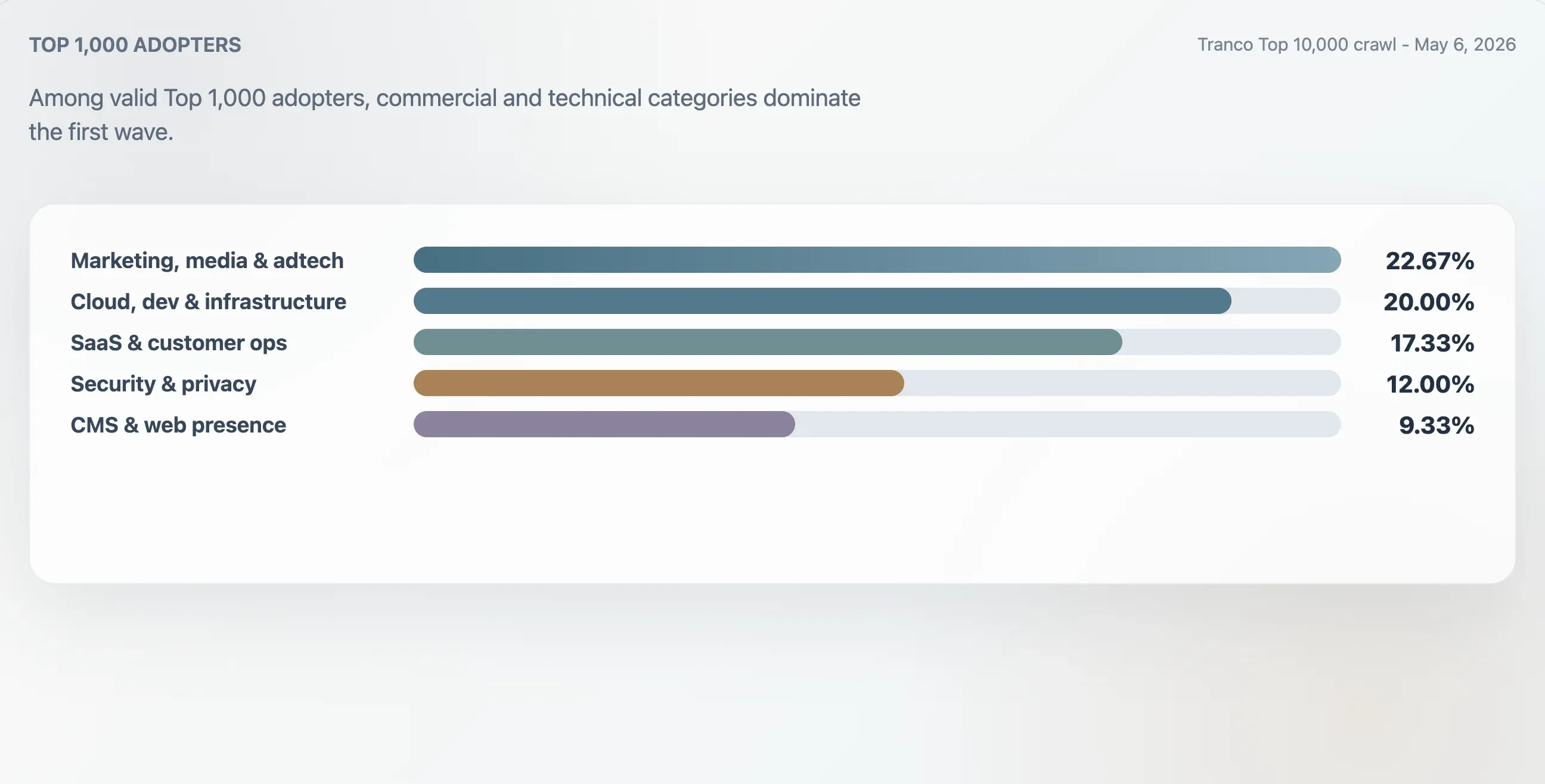
| Kategori | Domäner | Andel av användarna i Top 1 000 | Medianpoäng för kvalitet | Medianantal länkar |
|---|---|---|---|---|
| Marknadsföring, media & adtech | 17 | 22,67 % | 94 | 25 |
| Moln, utveckling & infrastruktur | 15 | 20,00 % | 94 | 62 |
| SaaS, produktivitet & kunddrift | 13 | 17,33 % | 94 | 46 |
| Säkerhet, identitet & integritet | 9 | 12,00 % | 98 | 78 |
| CMS, hosting & webb-närvaro | 7 | 9,33 % | 100 | 24 |
TLD-mönster
Toppdomäner är inte branschetiketter, men de är användbara riktningstecken. Bland TLD:er med minst 50 domäner i urvalet hade .io högst giltig användningsgrad med 14,44 %. .com följde på 8,19 %. Lägre användning bland .gov, .edu och .net antyder att den tidiga användarbasen är mer kommersiell och teknisk än institutionell.
Implementeringskvalitet
Giltig användning betyder inte enhetlig implementeringskvalitet. Vissa filer är kortfattade, välstrukturerade index. Vissa är mestadels löptext. Vissa är råa länkarkiv. Vissa är nästan tomma platshållare. Vissa är innehållsdumpar på flera megabyte som kan vara kompletta men kostsamma att hämta och tolka.
Bland giltiga llms.txt-filer var 362 större än 5 KB, eller 61,77 % av de giltiga användarna. Medianfilstorleken var cirka 7,1 KB. P90-storleken var 156 KB, P95 var 356 KB, P99 var 2,54 MB och den största observerade filen var 7,97 MB.
Vanliga innehållssignaler
En nyckelordsgenomsökning av giltiga filer visade att många sajter inte bara publicerar en deklaration; de pekar modeller mot operativt användbart material. Termer för support eller hjälp förekom i 70,31 % av de giltiga filerna. Blogg-, guide- eller handledningstermer förekom i 67,92 %. Säkerhet, integritet, regelefterlevnad eller villkor förekom i 61,43 %. Prissättning förekom i 53,92 %, dokumentation i 52,22 %, API-termer i 33,96 % och signaler för changelog eller release i 27,30 %.
Kvalitetspoäng och arketyper
För att gå från förekomst till mognad skapade denna studie en lättviktig implementeringspoäng. Poängen beaktar innehållstyp, filstorlek, Markdown-struktur, antal länkar, ämnestäckning och varningssignaler som saknade rubriker, inga Markdown-länkar, ovanliga content types, små filer, mycket stora filer och beteende som länkdump. Detta är ingen formell standard. Det är en forskningsmodell för att jämföra observerade implementationer.
Med denna modell klassificerades 416 giltiga filer som starka strukturerade index, 107 som användbara index, 24 som tunna eller oregelbundna och 39 som symboliska eller med låg nytta. En separat arketypanalys fann 296 strukturerade index, 113 sektionerade textfiler, 63 länkarkiv, 52 tunna index, 50 symboliska eller platshållarfiler och 12 massiva innehållsdumpar.
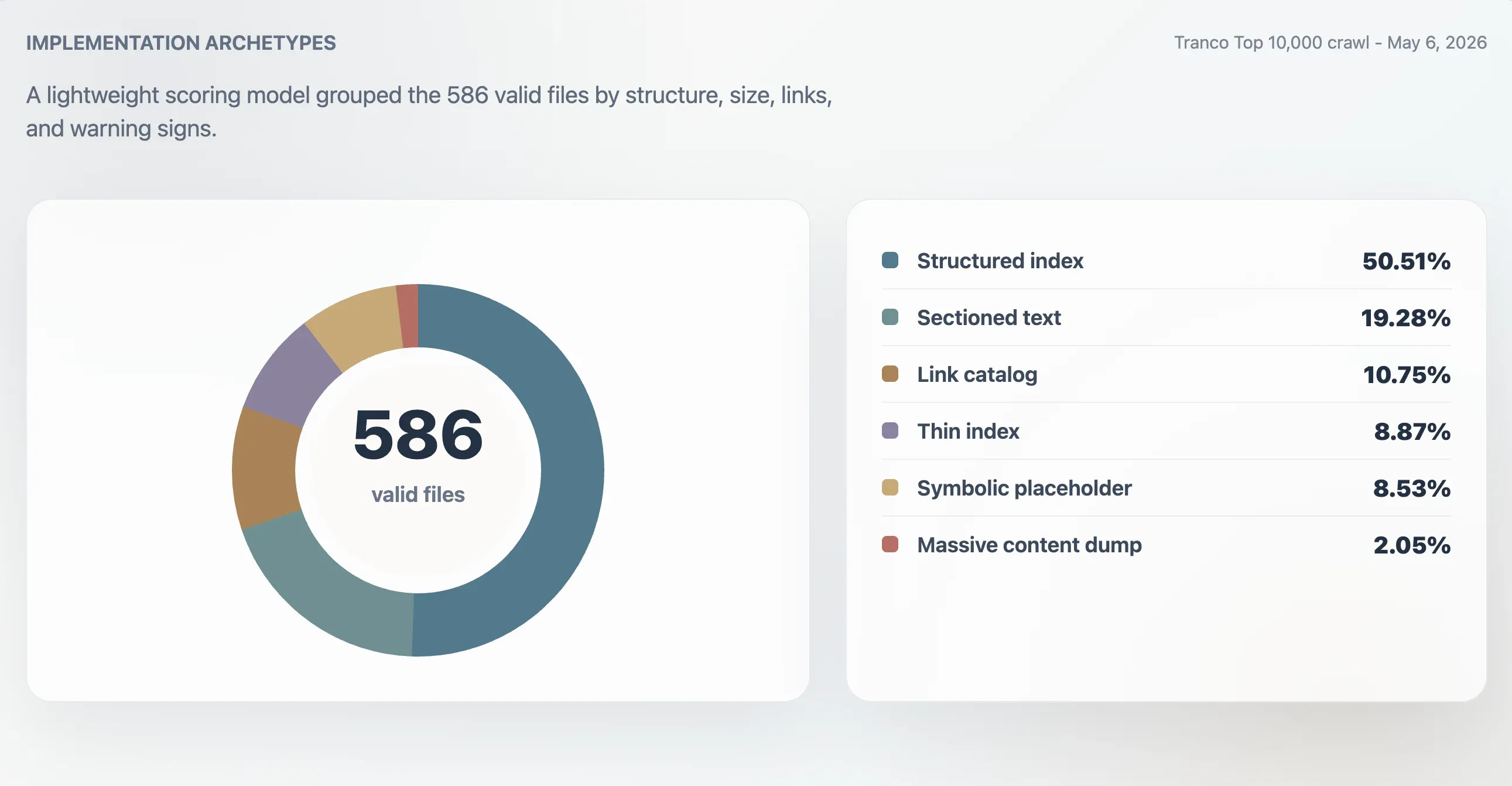
| Arketyp | Domäner | Andel av giltiga filer | Medianpoäng | Medianfilstorlek | Medianantal länkar |
|---|---|---|---|---|---|
| Strukturerat index | 296 | 50,51 % | 98 | 11 241 B | 61,5 |
| Sektionerad text | 113 | 19,28 % | 78 | 4 718 B | 0 |
| Länkarkiv | 63 | 10,75 % | 86 | 4 160 B | 23 |
| Tunt index | 52 | 8,87 % | 66 | 2 814 B | 0 |
| Symbolisk eller platshållare | 50 | 8,53 % | 27 | 15 B | 0 |
| Massiv innehållsdump | 12 | 2,05 % | 74 | 2,84 MB | 7 259,5 |
De största användarna har tätare implementationer
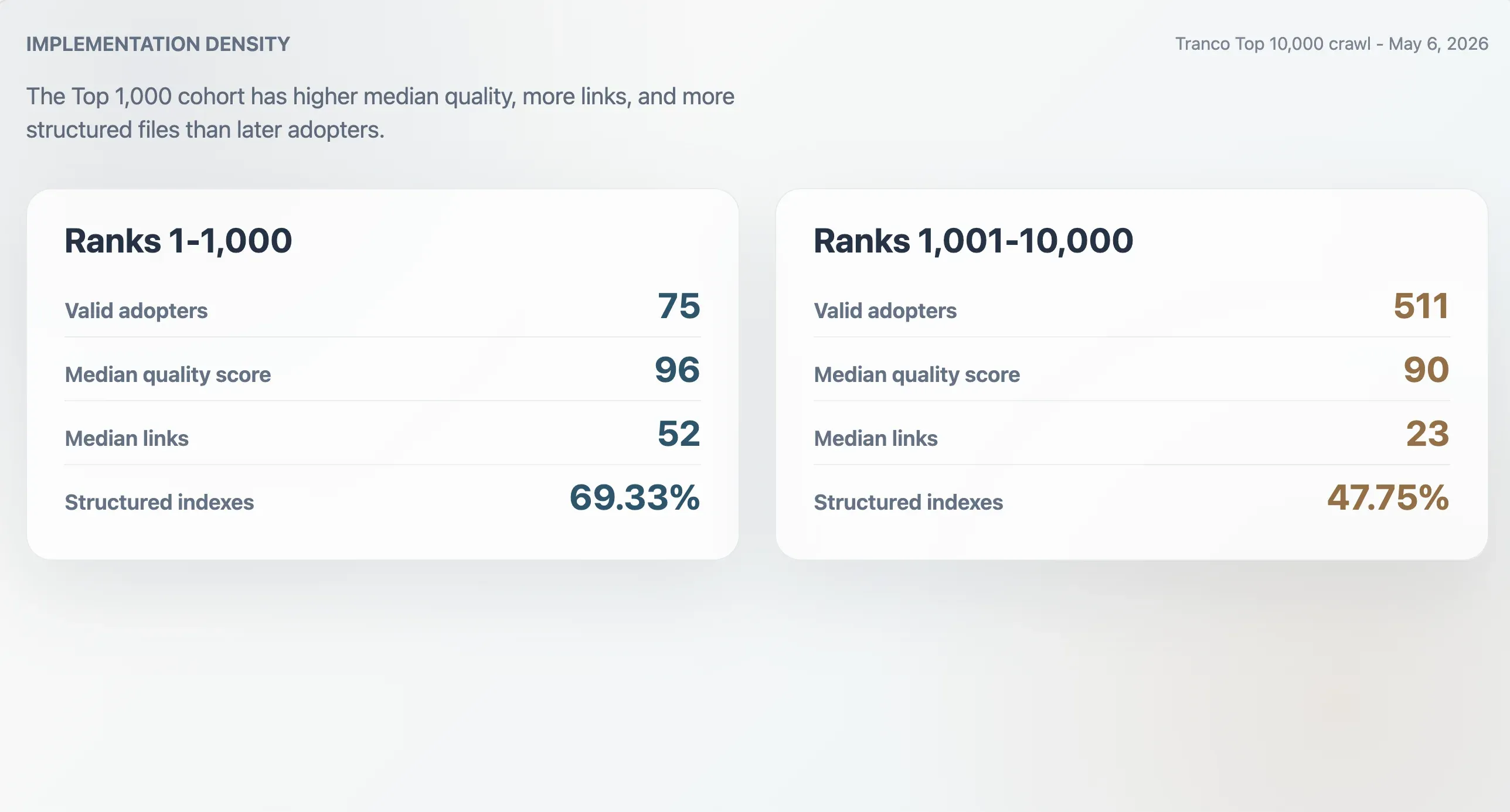
De 75 giltiga användarna i Tranco Top 1 000 hade en medianpoäng för kvalitet på 96, medianfilstorlek på 9 068 byte, medianantal Markdown-länkar på 52 och medianantal sektioner på 11. De 511 användarna rankade 1 001–10 000 hade lägre medianer: poäng 90, filstorlek 6 506 byte, 23 Markdown-länkar och 9 sektioner. Användarna i Top 1 000 var också oftare strukturerade index: 69,33 % jämfört med 47,75 % i den senare kohorten.
Problemet med falska positiva resultat

Den största mätarisken är falska positiva resultat. Av de 1 606 domäner som returnerade HTTP 200 för /llms.txt underkände 1 020 valideringen. Den vanligaste ogiltiga orsaken var omdirigering till fel mål, med 618 fall. Ytterligare 367 svar var generiska HTML-dokument. Tjugonio returnerade en tom body, och sex var andra eller okategoriserade ogiltiga svar.
Detta spelar roll eftersom många stora sajter styr okända sökvägar till inloggningssidor, startsidor, app shells, regionala sidor, samtyckesytor eller marknadsförings-fallbacks. Dessa svar kan se friska ut för en statuskodcrawler men innehåller ingen giltig llms.txt-signal.
llms-full.txt: mer sällsynt och mer ojämnt
Den kompletterande filen llms-full.txt var betydligt ovanligare än llms.txt. Crawlningen fann 103 giltiga fullfiler, vilket motsvarar 17,58 % av de giltiga llms.txt-användarna och 1,03 % av hela Top 10 000-urvalet.
Fullfilsimplementationerna var ojämna. Bland de 103 användare med båda filerna hade 57 en llms-full.txt-fil som var större än indexfilen, men 46 hade antingen en fullfil som inte var större än indexfilen eller en fullfil under 100 byte. Medianförhållandet mellan fullfil och indexfil var 1,43, men extrema fall var mycket större. Supabases fullfil var ungefär 7 139 gånger större än indexfilen. Made-in-China.com hade en fullfil på 89,89 MB.
| Domän | llms.txt | llms-full.txt | Förhållande |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7 139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Rekommendation: publicera
llms-full.txtendast när sajten redan har en stabil dokumentationspipeline, versionsdisciplin och en tydlig anledning att exponera stora mängder innehåll i en enda maskinläsbar fil.
llms.txt, robots.txt och sitemap.xml
llms.txt bör inte behandlas som en ny robots.txt. De är båda maskinläsbara filer på rotnivå, men de kommunicerar olika saker. robots.txt är en signal om crawler-preferenser och åtkomstkontroll. sitemap.xml är en signal för URL-upptäckt. llms.txt är en förklarande och navigerande signal.
| Signal | Huvudroll | Typisk läsare | Tolkning i denna studie |
|---|---|---|---|
robots.txt | Ange crawler-preferenser och begränsningar på sökvägsnivå. | Sökcrawlers, AI-crawlers, arkivcrawlers, generiska bottar. | Styrnings- och åtkomstsignal. |
sitemap.xml | Lista upptäckbara URL:er för indexeringssystem. | Sökmotorer och indexeringspipelines. | Upptäcktsignal. |
llms.txt | Ge kompakt webbplatskontext, viktiga länkar, dokumentation, API:er, exempel och policyreferenser. | LLM-applikationer, AI-agenter, utvecklarverktyg, retrieval-system. | Förklarings- och navigeringssignal. |
Rekommendationer
För sajter som överväger llms.txt antyder de starkaste implementationerna i detta dataset och den externa trafikevidensen ett pragmatiskt mönster:
- Publicera
/llms.txti roten och håll den tillgänglig utan inloggning, JavaScript-körning, samtyckesväggar eller omdirigeringar utanför sökvägen. - Servera den som
text/plainellertext/markdownnär det går. - Börja med en kort beskrivning av sajten och gruppera sedan länkar efter produkt, dokumentation, API, prissättning, changelog, exempel, support, policyer och företagsresurser.
- Föredra kanoniska länkar framför uttömmande URL-listor.
- Undvik tomma symboliska filer; de räknas högst som en svag signal.
- Undvik massiva odifferentierade dumpningar om det inte finns ett starkt maskinkonsumtionsbehov och en tillförlitlig genereringspipeline.
- Validera slutlig URL, svarsbody, content type, Markdown-struktur, antal länkar och filstorlek efter publicering.
Team bör också sätta förväntningarna noggrant. De tillgängliga offentliga experimenten bevisar inte att llms.txt i sig ökar AI-hänvisningstrafik. Om ett team vill testa affärseffekten bör det spåra LLM-hänvisningar, citerade sidor, botförfrågningar, indexets färskhet och innehållsförändringar tillsammans. Ett användbart experiment skulle jämföra matchade sidgrupper, hålla innehållsuppdateringar konstanta där det går och separera plattformsspecifik trafik som Perplexity, ChatGPT, Gemini, Claude och Bing/Copilot.
Begränsningar
Detta är ett crawl-baserat ögonblicksfoto, inte en permanent sanning. Webbplatser kan när som helst lägga till, ta bort eller ändra llms.txt-filer. Vissa domäner kan blockera automatiska förfrågningar eller bete sig olika beroende på geografi, TLS-konfiguration, omdirigeringslogik, user agent eller bot-skydd. Studien testade endast filer på rotnivå och sökte inte i subdomäner eller icke-standardiserade sökvägar.
Kvalitetspoängen och arketyperna är forskningsverktyg, inte officiella efterlevnadsetiketter. Ämnesanalysen är nyckelordsbaserad och bör läsas som vägledande. Studien bevisar inte att någon specifik AI-plattform i dag läser, respekterar eller använder llms.txt i produktion.
Den externa trafikevidensen som granskats i denna version har också begränsningar. Search Engine Lands analys är starkare som en försiktig observation över flera sajter än som ett randomiserat experiment. Alimbekovs resultat är användbart som en transparent fallstudie på sajtnivå, men det saknar kontrollgrupp och omfattar en period då den totala hänvisningstrafiken ökade markant. Dessa referenser hjälper till att rama in debatten, men de gör inte denna crawl till en kausal trafikstudie.
Filer och reproducerbarhet
| Fil | Syfte |
|---|---|
crawl_llms_txt.py | Crawler för /llms.txt och /llms-full.txt. |
analyze_llms_txt.py | Huvudanalys av användning och diagramgenerering. |
deep_analyze_llms_txt.py | Sekundär analys för rankdeciler, TLD:er, ämnessignaler, kvalitetspoäng, arketyper och beteende med två filer. |
deep_dive_early_quality.py | Klassificering av tidiga användare och fördjupad analys av implementeringskvalitet. |
data/llms_probe_results_top_10000.csv | Huvuddataset för crawl-resultat. |
data/deep_analysis_top_10000.json | Sammanfattning av sekundäranalys. |
data/deep_early_quality_analysis.json | Kategorier för tidiga användare, jämförelse av kvalitet mellan kohorter, arketypdetaljer och fallstudier. |
Källor
- The /llms.txt file, Jeremy Howard, 2024.
- HTTP Archive Web Almanac 2024 Methodology.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation.
- Does llms.txt matter?, Search Engine Land, januari 2026.
- The State of llms.txt Adoption, Rankability, juni 2025.
- How LLMS.txt Increased AI Chat Traffic by 23%, Renat Alimbekov.
Metodkorrigeringar, datasetproblem och uppföljande analyser välkomnas på support@thunderbit.com. Den här rapporten publiceras oberoende av någon kommersiell position som Thunderbit har. Uppgifterna i rapporten står på egna ben. — Thunderbit Research Team, maj 2026.
Testa Thunderbit för att skrapa och analysera webdata Get Started Free




