
Vad är en Amazon Web Scraper
En Amazon Web Scraper är ett smidigt verktyg eller program som automatiskt hämtar data från Amazon.com. Det kan till exempel samla in produktinformation, priser, recensioner, lagerstatus och mycket mer. Syftet är oftast att få fram stora mängder data för marknadsundersökningar, prisjämförelser eller konkurrensanalys. Du kan också samla in användarrecensioner för sökordsanalys och få bättre koll på produkternas styrkor och svagheter.
Viktiga funktioner i en Amazon Web Scraper
- Automatisk datainsamling: Slipp det tidskrävande arbetet med att kopiera och klistra in information manuellt. En web scraper kan hämta den data du behöver direkt från webbsidor.
- Anpassningsbar scraping: Du kan ställa in skräpverktyget så att det samlar in exakt de datataggar du behöver, vilket gör analysen mer träffsäker.
- Dataexport: Exportera enkelt den insamlade datan till vanliga format som Excel, CSV eller JSON för vidare analys i andra verktyg.
- Regelbundna uppdateringar: Schemalägg insamling med jämna mellanrum så att din Amazon-databas hålls uppdaterad och aktuell.
- Recensionsinsamling: Ofta behöver du även plocka ut för- och nackdelar ur recensionerna för konkurrensanalys.

Varför använda en Amazon Web Scraper
Amazon är en av de stora aktörerna inom global e-handel, känd för sitt enorma produktsortiment, konkurrenskraftiga priser och en smidig köpupplevelse. Plattformen ger företag möjlighet att nå kunder över hela världen och därmed expandera sin marknad. Konsumenter litar på Amazon som en av de främsta platserna för näthandel, vilket skapar en stabil försäljningsmiljö för handlare. Dessutom gör Amazons logistiknätverk det möjligt för företag att erbjuda snabb och effektiv leverans, vilket i sin tur stärker kundnöjdheten. Amazon erbjuder också flera marknadsföringsverktyg för att öka synligheten och försäljningen, till exempel sponsrade produktannonser och varumärkeskampanjer.
För e-handelsföretag är det avgörande att analysera försäljningsdata på Amazon. Med hjälp av en Amazon Web Scraper kan företag samla in data för att få insikter om marknadstrender och kundbeteende, samt optimera produktstrategier och lagerhantering. Det hjälper företag att växa effektivt på Amazon, öka försäljningen och stärka varumärkeskännedomen för långsiktig tillväxt. Så här kan du använda en Amazon Web Scraper för analys:
Marknadsundersökning
-
Val av SKU
Att välja rätt SKU (Stock Keeping Unit) är avgörande för e-handelns framgång och påverkar produktsortiment, effektivitet i leveranskedjan och lagerhantering. Med en Amazon Web Scraper kan du hämta detaljerad data från miljontals produkter för att analysera försäljningstrender och kundpreferenser. Om du till exempel skrapar Amazons produktsidor kan du enkelt få fram viktig information som produktpriser, antal recensioner och säljarbetyg för en djupare marknadsanalys. Den här datan hjälper dig att avgöra om en SKU har potential på marknaden och visar vilka produkter som presterar bäst. Genom att jämföra produkter inom samma kategori kan företag optimera sitt sortiment, öka lagret av populära SKU:er och minska lagret av långsamt säljande artiklar, vilket förbättrar lageromsättningen.
-
Identifiera kundtrender
Genom att samla in stora mängder produktrecensioner, betyg och kundfeedback kan en web scraper hjälpa dig att snabbt upptäcka förändringar i efterfrågan. Genom att analysera recensionsdata kan du till exempel se vilka egenskaper kunderna värdesätter mest, som "prisvärdhet" eller "hållbarhet". Den här informationen är viktig för produktutveckling, prissättning och marknadsföring. Du kan också analysera köpfrekvens och försäljningstrender över tid för att förutse säsongsvariationer och planera lager och marknadsinsatser i förväg.

Konkurrensanalys
-
Prisövervakning
I en konkurrensutsatt marknad är prisövervakning avgörande för e-handelsföretag. En Amazon Web Scraper kan hjälpa dig att samla in produktdata i realtid och följa konkurrenternas prisförändringar, så att dina priser förblir konkurrenskraftiga. Den här funktionen är särskilt värdefull för dynamisk prissättning. Genom att samla in prisinformation om liknande produkter kan företag skapa flexibla prismodeller som automatiskt justerar priserna utifrån efterfrågan, lagernivåer och konkurrenternas prissättning för att maximera vinsten.
-
Insamling av recensioner
Kundrecensioner påverkar inte bara försäljningen utan speglar också förändringar i marknadens efterfrågan. En Amazon Web Scraper kan hjälpa företag att samla in stora mängder kundfeedback. AI-baserade web scrapers kan dessutom sammanfatta innehållet och göra sentimentanalys för att ge insikter om användarnas åsikter om både dina egna och konkurrenternas produkter, så att du snabbt kan justera produktdesign eller marknadsföring.
Kostnadsjämförelse
Med hjälp av en Amazon Web Scraper kan företag samla in data om priser, fraktkostnader och kampanjer för liknande produkter för en mer heltäckande kostnadsjämförelse. Analysen hjälper företag att optimera kostnadsstrukturen, undvika onödiga utgifter och öka vinstmarginalerna. För företag som letar efter leverantörer på Amazon ger det också insikter om olika leverantörers fraktavgifter och försäljningspriser, vilket minskar kostnaderna och hjälper till att säkerställa konkurrenskraftig prissättning på marknaden och i slutändan förbättra bruttomarginalen.
Testa AI för web scraping
Test it! You can click, explore, and run the workflow as you watch.
Varför använda AI för att skrapa Amazon-produktdata
Med AI:s snabba utveckling leder AI-drivna Amazon Web Scraper-verktyg en ny era av datainsamling och gör traditionell scraping betydligt smidigare. AI gör inte bara insamlingen snabbare och mer träffsäker, utan sänker också tröskeln tekniskt och öppnar upp för mer innovativa möjligheter för e-handelsföretag.
Lätt att använda även för icke-tekniska användare
För användare utan teknisk bakgrund innebär AI-stödda Amazon Web Scraper-verktyg stora fördelar. Till skillnad från traditionella scrapers som kräver manuell kodning och API-anrop behöver användaren bara ange vad som ska samlas in och välja önskade kolumnnamn. AI genererar automatiskt lämpliga skräpplaner och förslag, vilket tar bort krånglet med programmering och komplicerade inställningar. Den här användarvänliga funktionen hjälper e-handelsteam att få fram data effektivt utan specialiserad teknisk personal, ökar produktiviteten och gör det enkelt även för icke-tekniska medarbetare att använda avancerade verktyg för datainsamling.
Snabbt och effektivt
Skrapa data från vilken webbplats som helst med AI Get Started Free
AI Web Scraper automatiserar datainsamlingen och gör scraping betydligt snabbare och mer effektiv. Verktygen kan snabbt hantera komplexa webbplatsstrukturer och dynamiskt innehåll, fånga rätt data med hög precision, minska manuellt arbete och förbättra den övergripande träffsäkerheten. Dessutom kan AI Web Scraper sänka driftkostnaderna avsevärt och optimera arbetsflöden, så att företag kan få högkvalitativ data till lägre kostnad och därmed fatta bättre beslut.
Intelligent analys och förslag
Jämfört med traditionella web scrapers erbjuder AI web scraper fördelen av intelligent automatisering av arbetsflöden. AI-verktyg kan automatiskt kategorisera data, sammanfatta innehåll och ge insikter från datan. Företag kan till exempel använda AI för att automatiskt sortera olika produkter i fördefinierade kategorier eller analysera stora mängder recensionsdata för att extrahera nyckelord och sentimenttrender, vilket hjälper dem att förstå kundfeedback bättre och optimera produkter. AI kan också skapa anpassade rapporter utifrån den insamlade datan och automatiskt generera marknadsanalyser som hjälper företag att snabbt identifiera populära produktegenskaper och möjliga marknadsmöjligheter.
Smart utmatning och exportalternativ
Med en AI-baserad Amazon web scraper blir datautmatningen mer flexibel och smart. Traditionella kodlösningar ger ofta bara CSV-filer, medan AI-verktyg stödjer CSV-format och dessutom kan exportera insamlad data direkt till samarbetsplattformar som Google Sheets och Notion, vilket förenklar analys och delning av data avsevärt. Du kan till exempel importera data direkt till Google Sheets för analys i realtid eller koppla den till teamets samarbetsverktyg, så att informationen flödar smidigt mellan avdelningar. Det här smarta exportsättet gör att team kan fatta beslut snabbare och ökar verksamhetens flexibilitet och responsförmåga.
Skrapa med Thunderbit: AI Web Scraper
Thunderbit är ett nylanserat, kraftfullt och heltäckande AI-drivet web scraping-verktyg som är utvecklat för att möta dina databehov. Med Thunderbit kan användare enkelt samla in data från Amazon, oavsett om det gäller produktdetaljer, prisutveckling eller kundrecensioner, och snabbt omvandla det till värdefulla affärsinsikter. Så här kan Thunderbit hjälpa e-handelsföretag att stärka sin konkurrenskraft.
Först går du till Thunderbits webbplats och lägger till Thunderbits web scraper-tillägg i din Chrome-webbläsare. Logga in med ditt Google-konto eller en annan e-postadress.
 Därefter kan du använda Thunderbits inbyggda färdiga web scraper eller AI web scraper för att skrapa Amazon-produkter och recensioner. Så här gör du:
Därefter kan du använda Thunderbits inbyggda färdiga web scraper eller AI web scraper för att skrapa Amazon-produkter och recensioner. Så här gör du:
Alternativ 1: Använd Thunderbits förbyggda web scraper
Thunderbit har tagit fram och optimerat olika färdiga web scraping-verktyg utifrån användarnas behov, inklusive en särskild scraper-modul för Amazon. Dessa verktyg har fördefinierade mallar för Amazons komplexa datastruktur och är utformade för att samla in stora mängder data utan att du själv behöver bygga upp logiken, vilket gör insamlingen snabbare och mer effektiv.
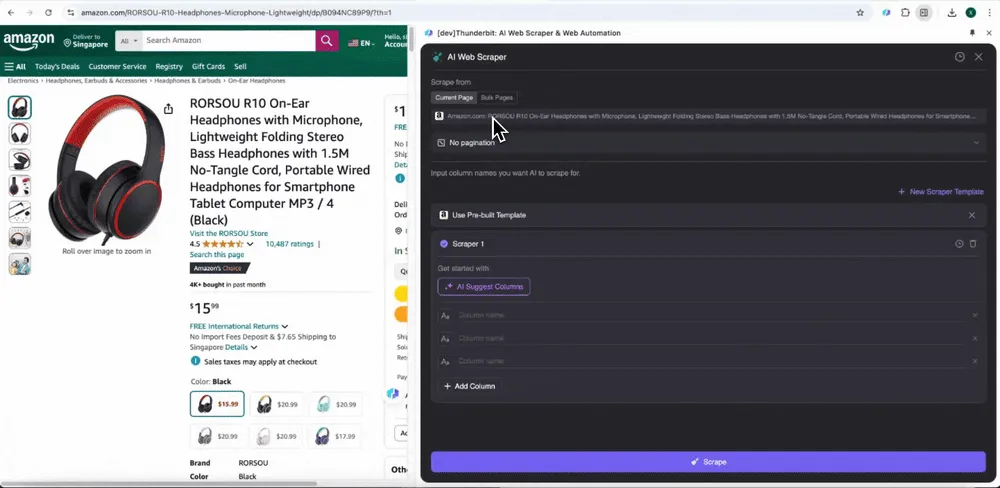
När du öppnar en sida på Amazon öppnar du Thunderbits web scraper i tillägget. Där ser du två färdiga scrapers med många kolumnnamn. Markera bara de kolumner du vill hämta, så sköter Thunderbit resten.
-
Amazon Collect SKU Reviews
Det här verktyget innehåller förbyggda kolumnnamn som produktnamn, produkt-URL, total betygspoäng, detaljerad betygsfördelning, antal recensioner, recensionsrubrik, författarnamn, recensionsinnehåll, recensionsland och nyckelord. Markera de kolumner du vill hämta, klicka på scrape och få snabbt den recensionsdata du behöver för produktanalys.
-
Amazon Collect SKU Details
Det här verktyget erbjuder förbyggda kolumnnamn som produktnamn, produkt-URL, varumärke, tillverkare, ursprungspris, slutpris, beskrivning, betyg, kategorier, leveransalternativ och säljar-URL. Markera de kolumner du vill hämta, klicka på scrape och få snabbt den produktdetaljdata du behöver. Oavsett om du jämför leverantörer, tillverkare och leveransalternativ, gör marknadsundersökningar, bedömer prisnivån för din SKU eller vill förstå de senaste försäljningstrenderna, kan den här datan hjälpa dig i analysen.
Alternativ 2: Använd Thunderbits AI Web Scraper
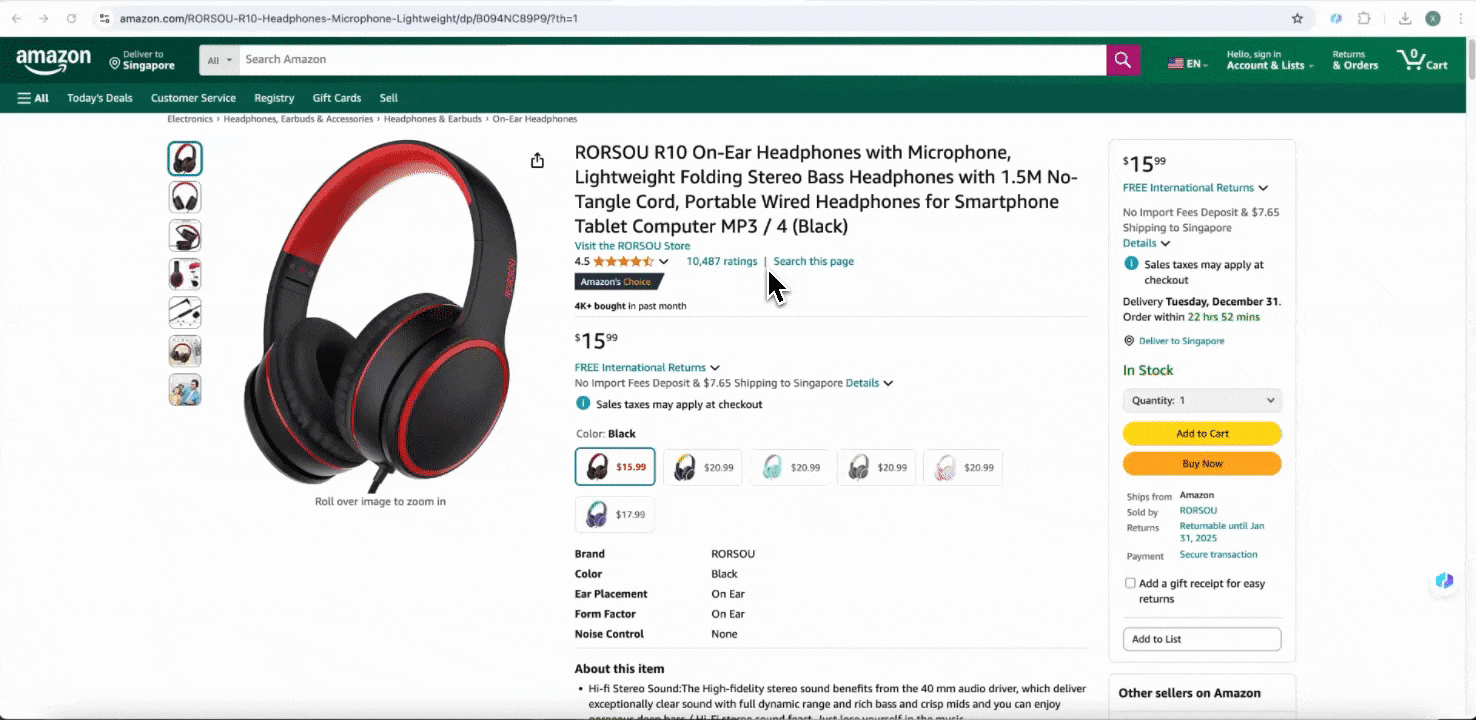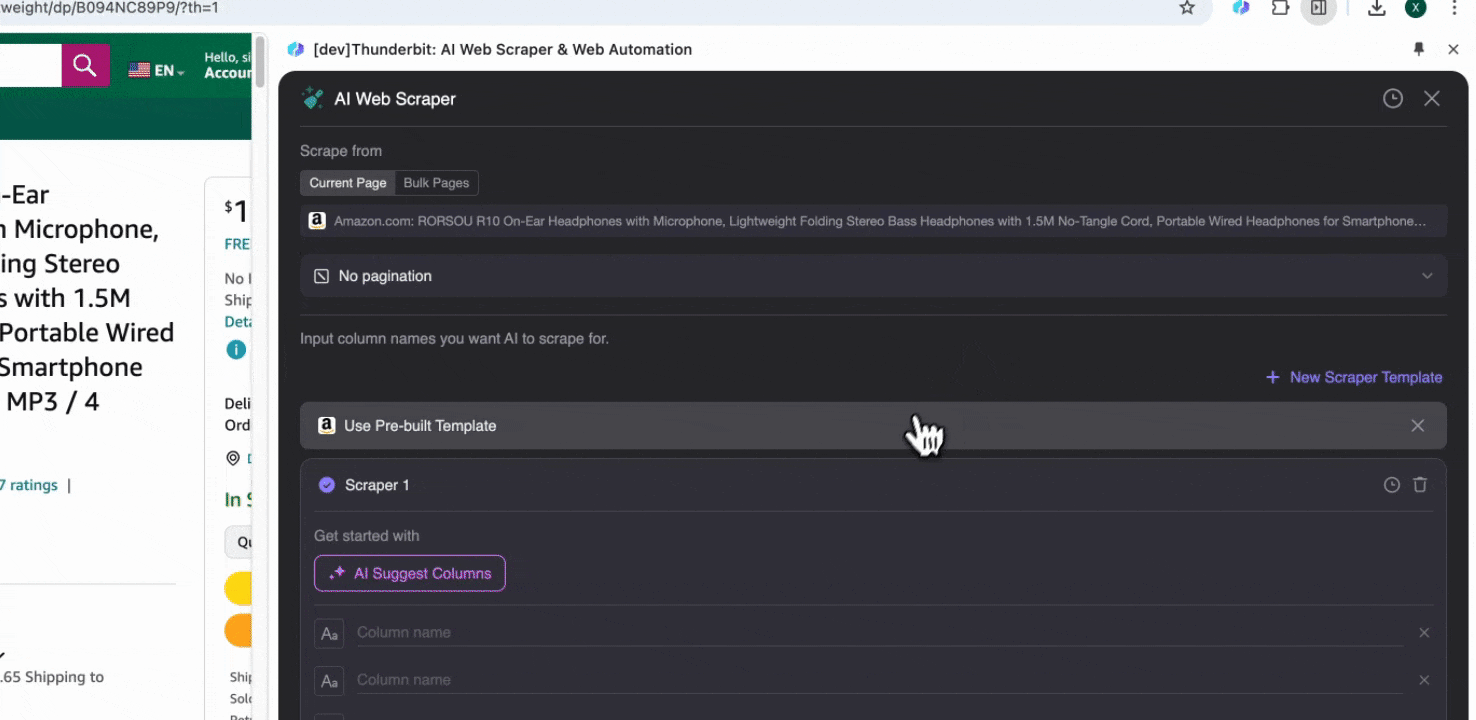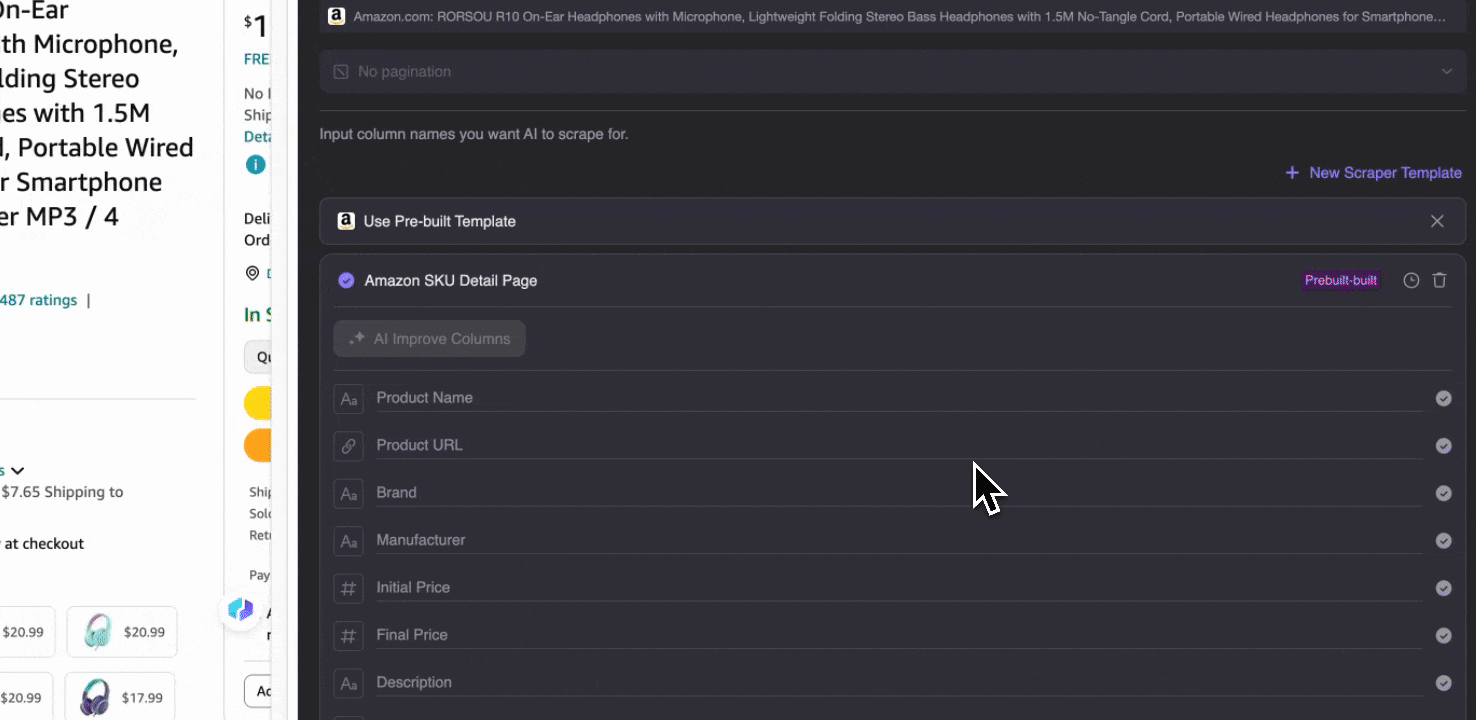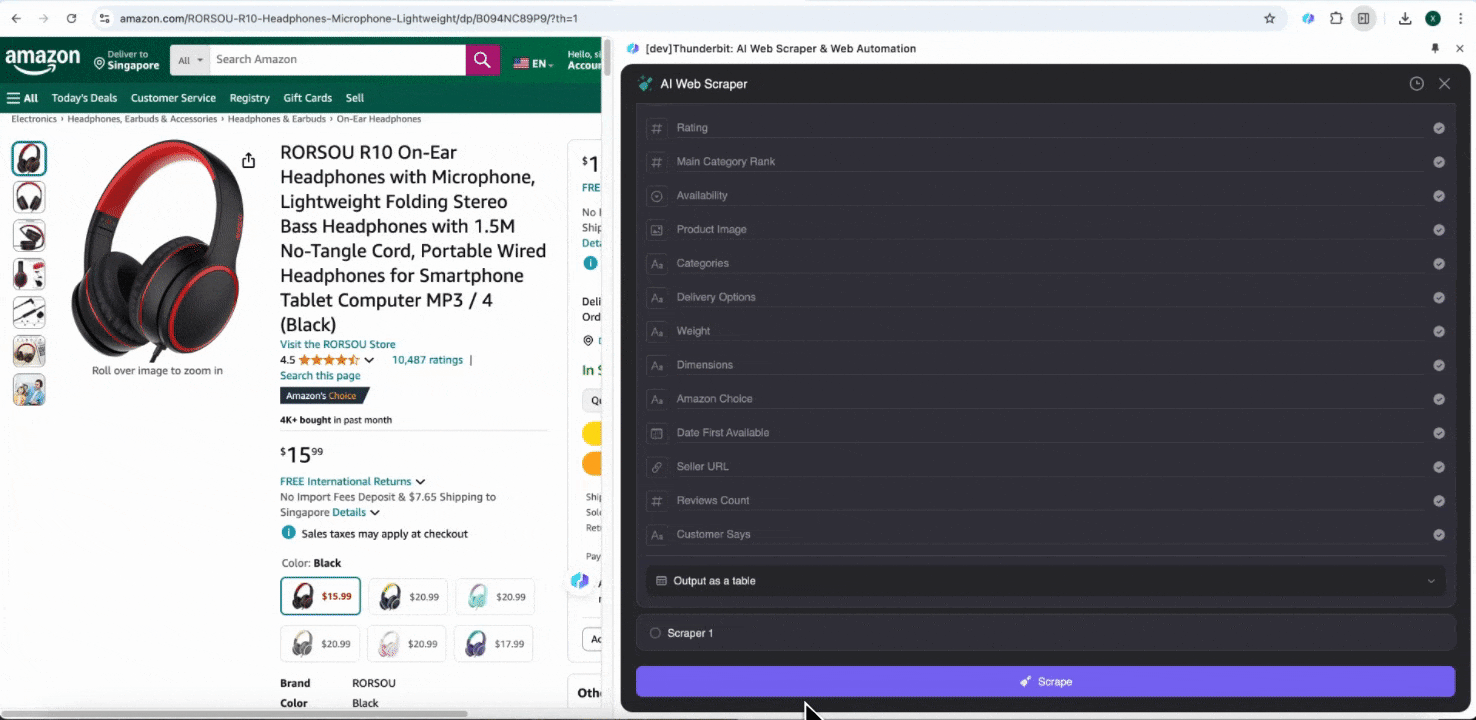
Steg 1: Öppna Amazon.com och klicka på “AI Web Scraper” i sidofältet
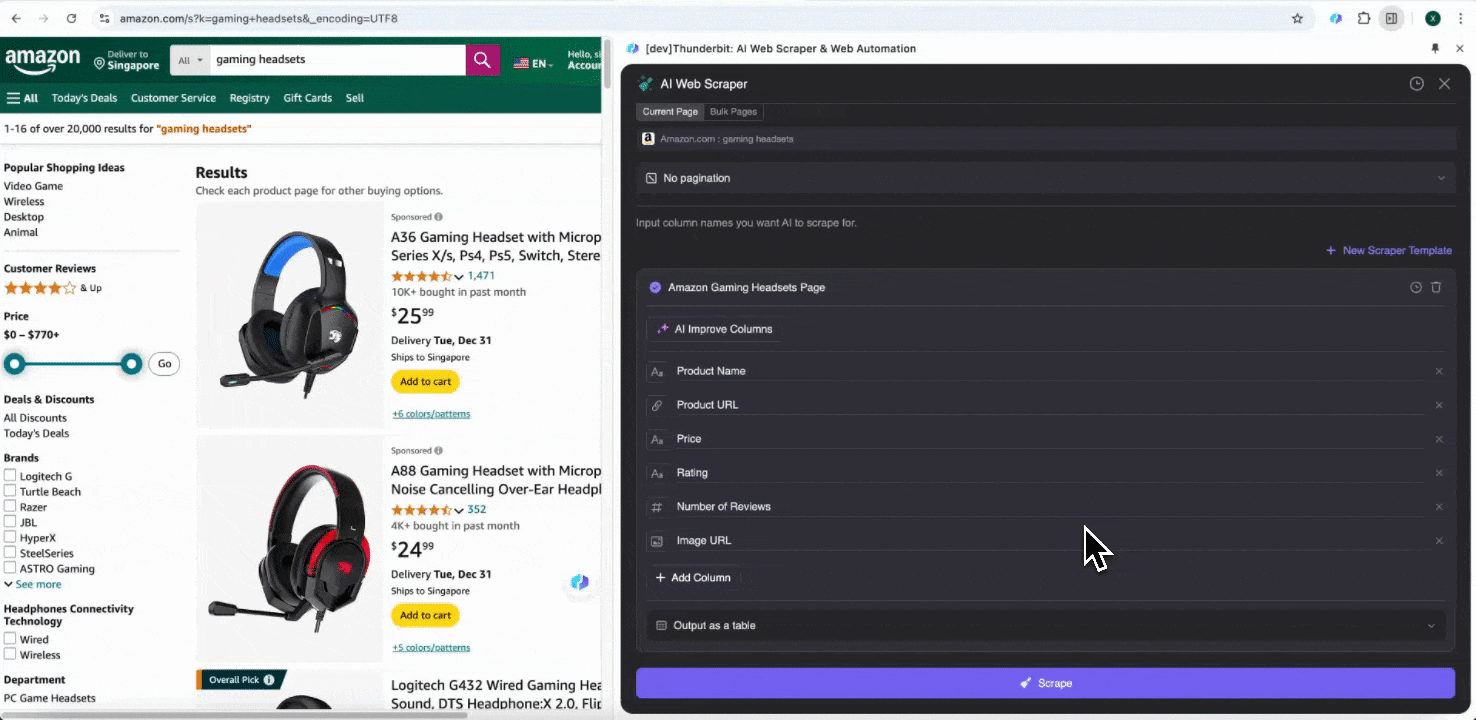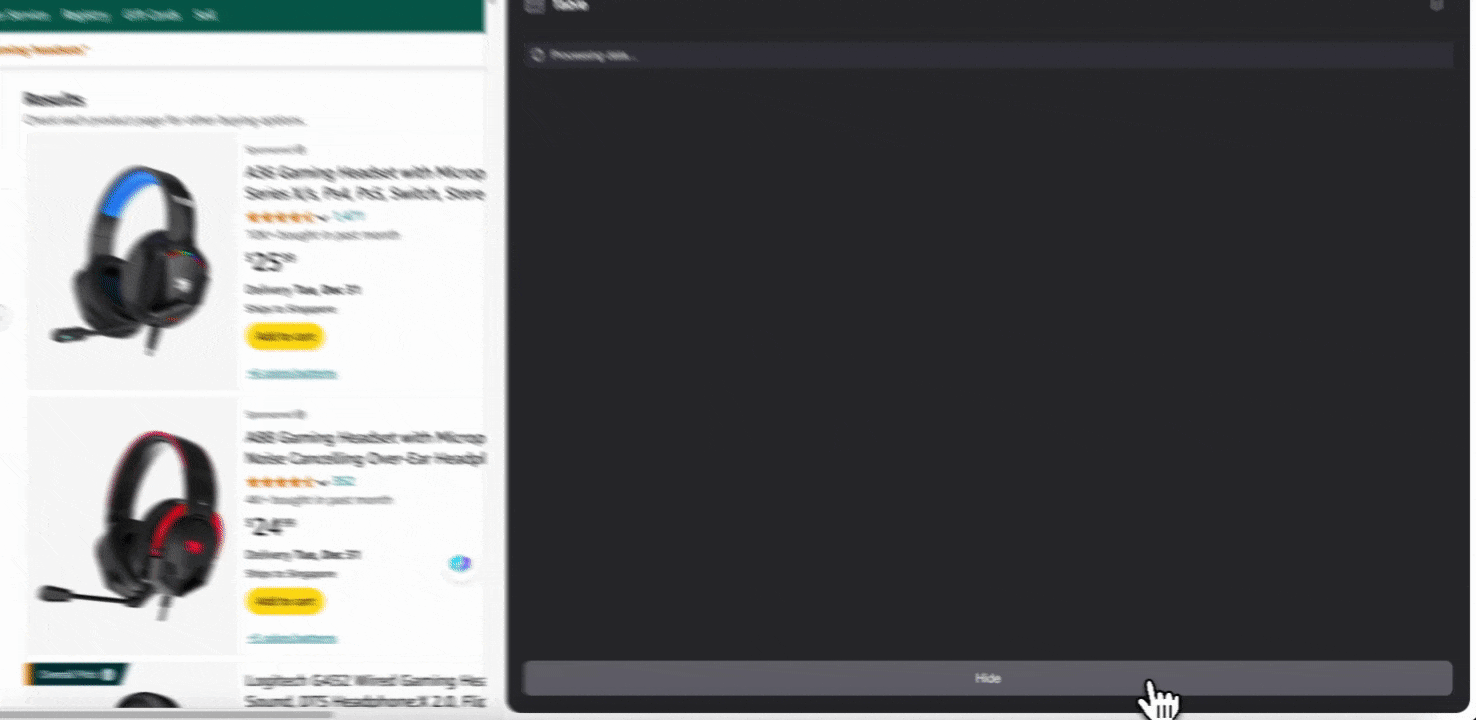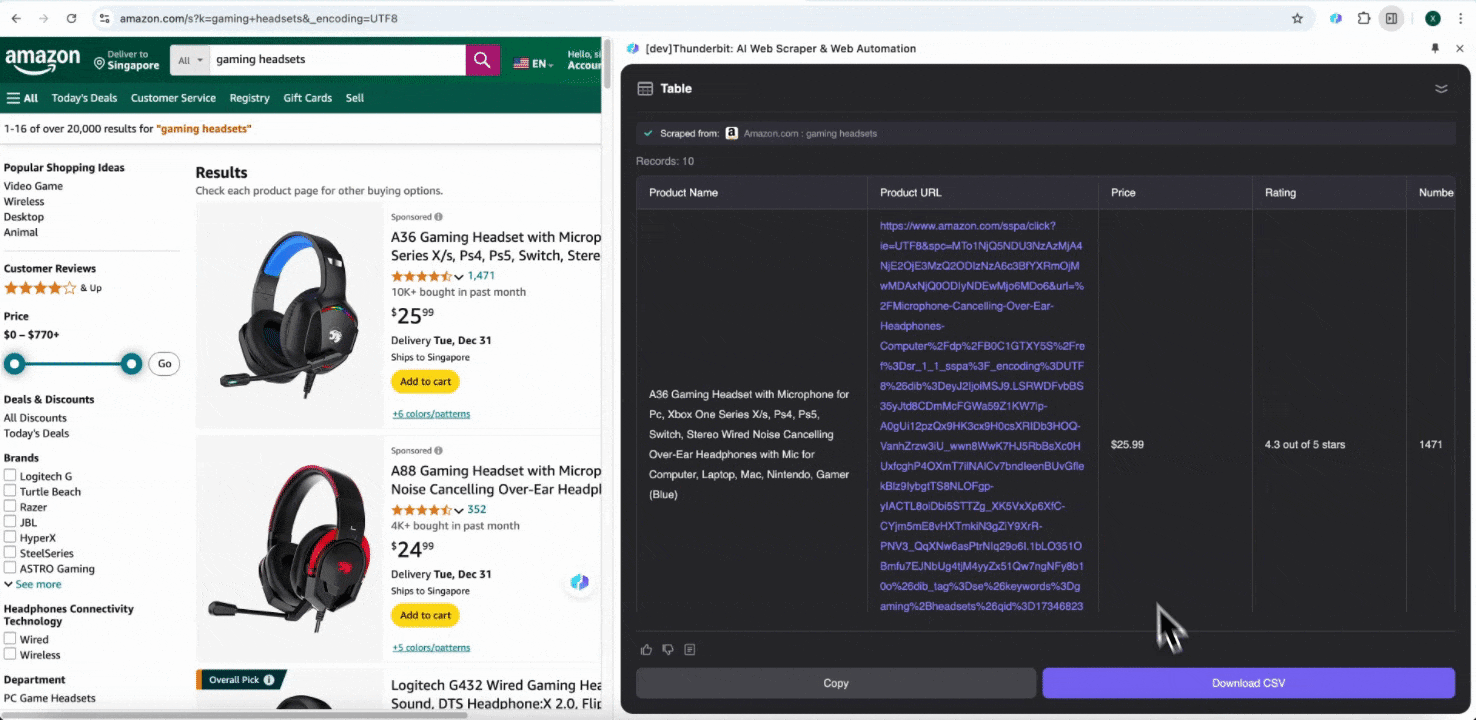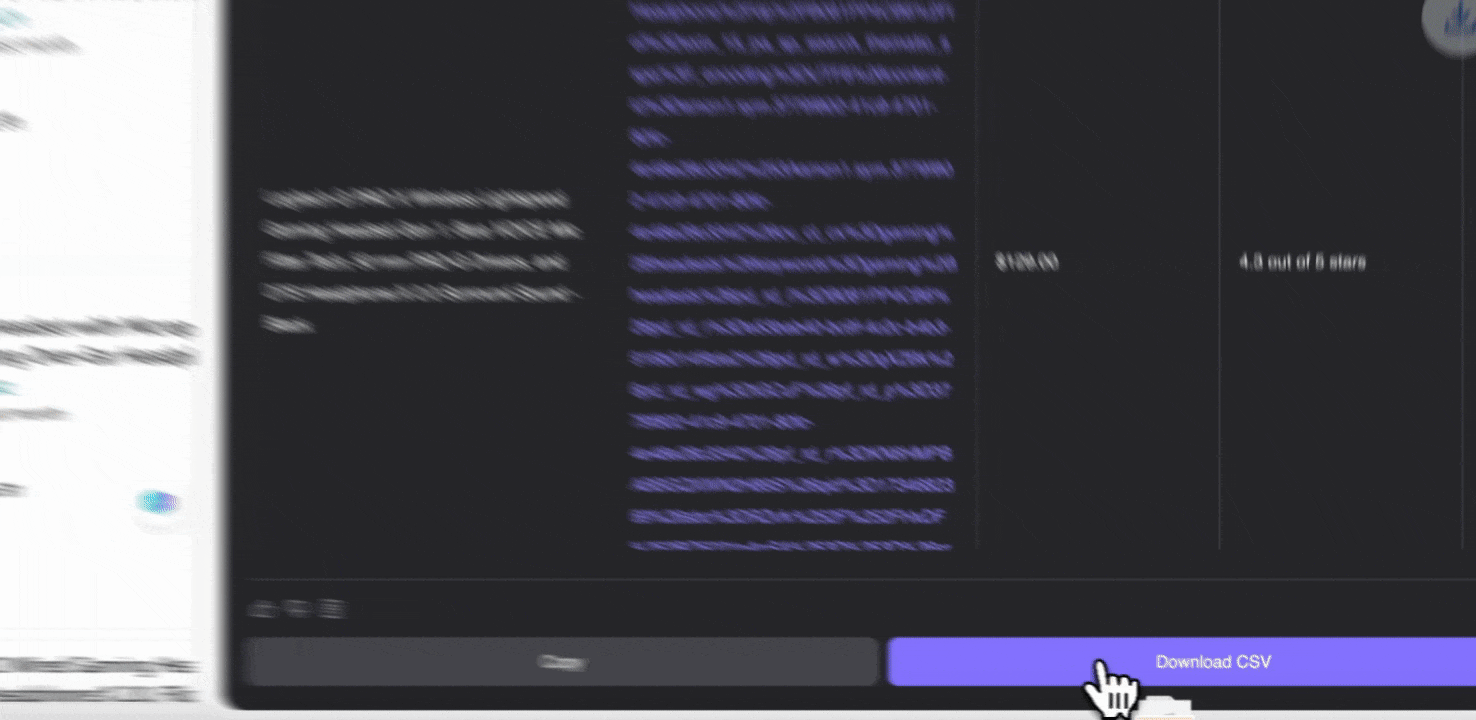
Öppna Amazons webbplats i din Chrome-webbläsare, sök eller navigera fram till sidan du vill hämta data från, klicka sedan på Thunderbit-ikonen uppe till höger i Chrome för att öppna tillägget och välj "AI Web Scraper."
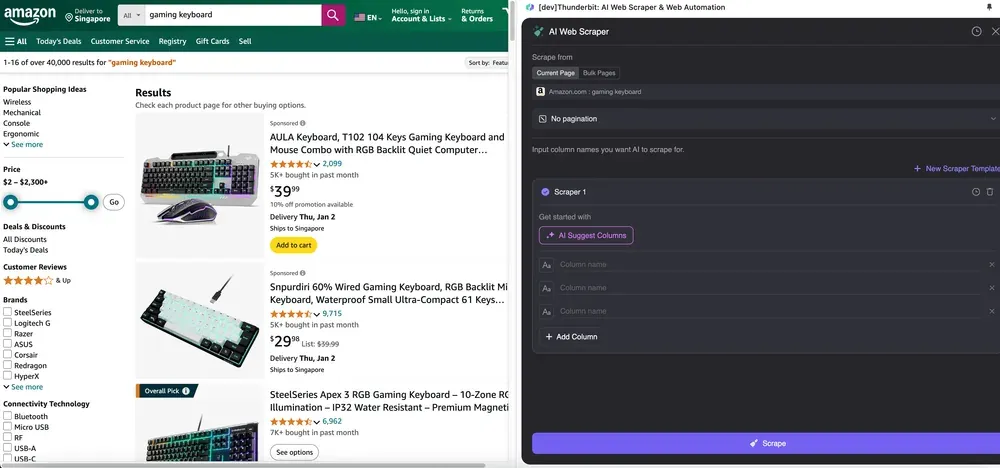
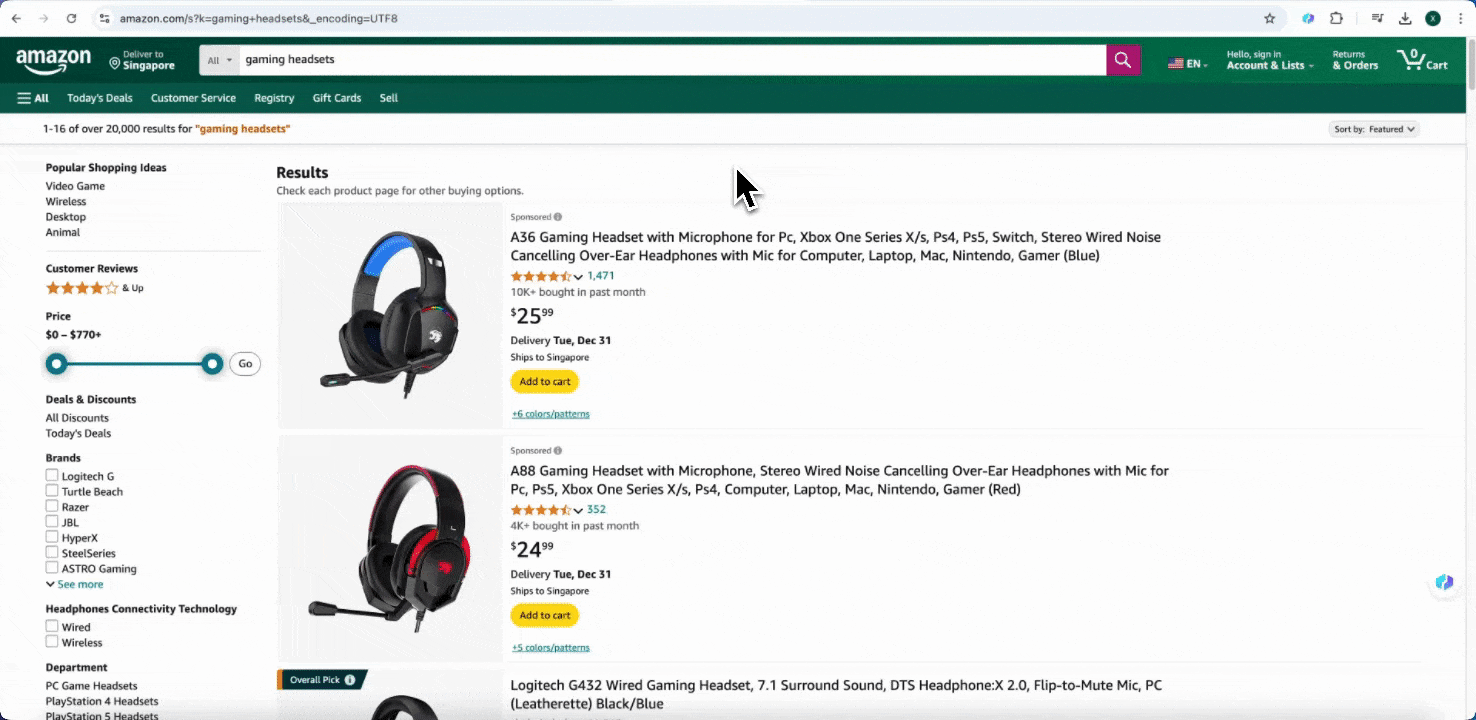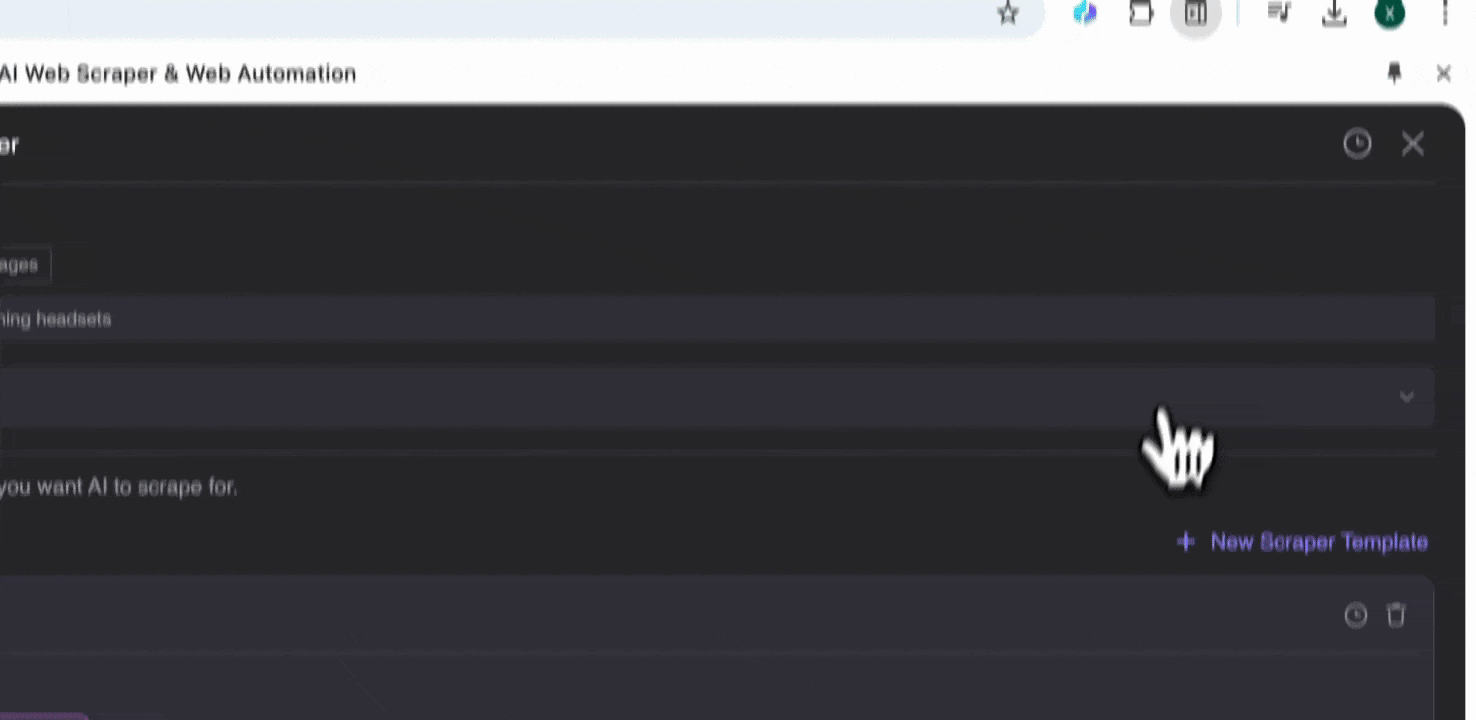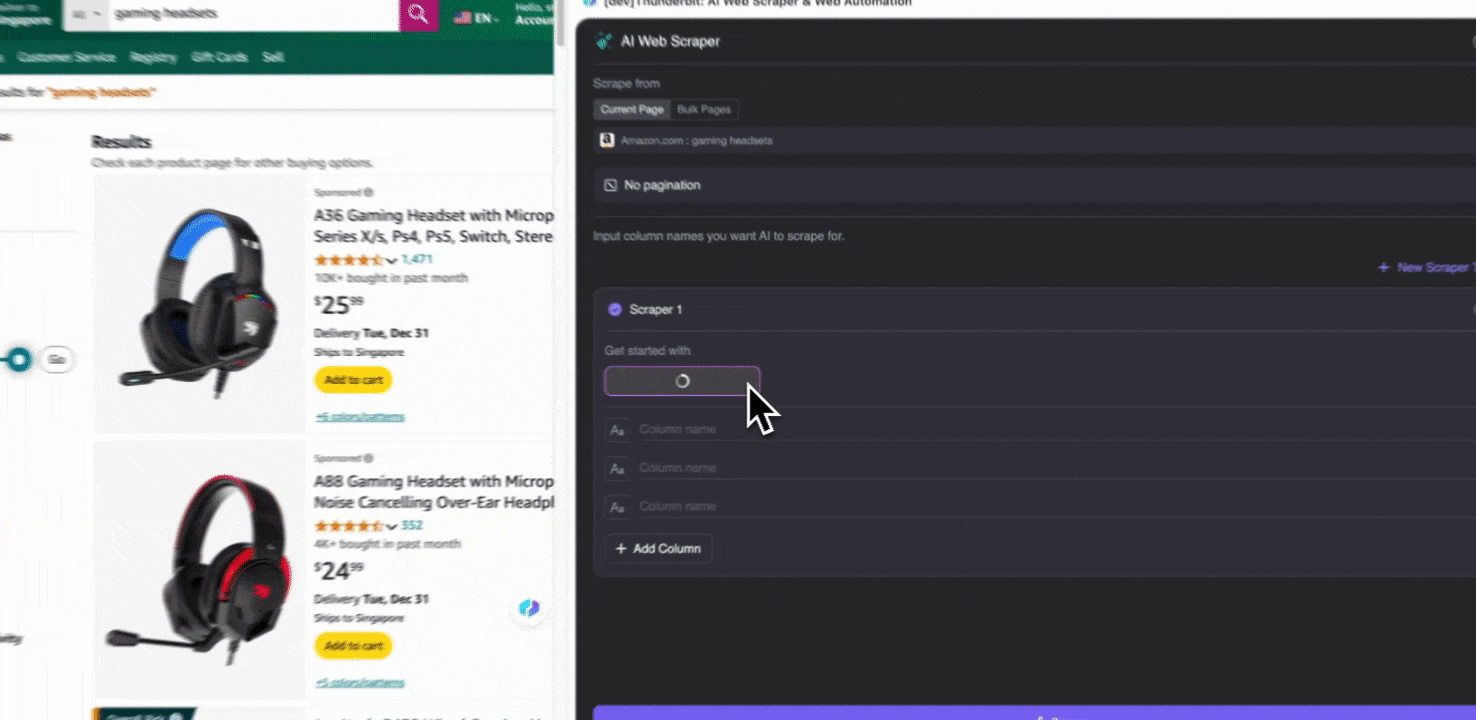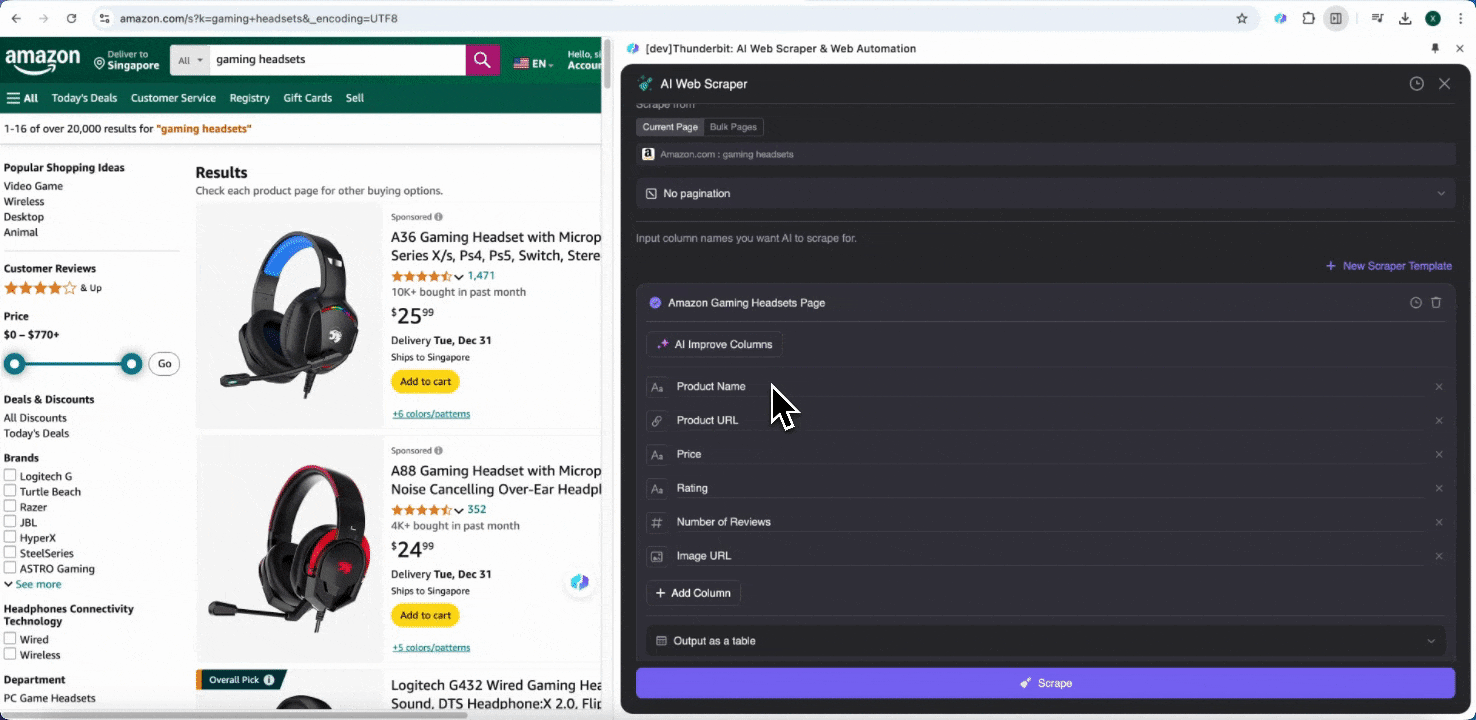
Steg 2: Anpassa de datafält du vill hämta
Om du inte är säker på vilka datataggar du behöver kan du klicka på AI Suggest Columns så låter du Thunderbits AI automatiskt skapa lämpliga kolumnnamn. Du kan också beskriva önskade datamärkningar med naturligt språk och fylla i dem i kolumnnamnsfältet. Välj ikoner för att byta datatyp, oavsett om det är bild, URL, text, tal eller annan typ, och hämta motsvarande data.
När du fyllt i de första kolumnnamnen kan du välja AI Improve Columns för att låta AI optimera dina kolumner ytterligare. Du kan också lägga till detaljerade instruktioner per kolumn för att anpassa exakt efter dina behov. Du kan till exempel be att produkttyp-kolumnen sorterar produkter i herr, dam, barn och andra kategorier. Thunderbit kommer då att kategorisera varje datapost i kolumnen enligt de fyra kategorierna du har definierat. Du kan också be Thunderbit att omvandla alla priser i priskolumnen till din önskade valuta med hjälp av aktuell växelkurs, så att du enkelt får de värden du behöver för analys utan att behöva oroa dig för valutaskillnader.
Slutligen kan du anpassa hur mycket data du vill samla in. För Amazons produktsidor kan du välja paginering med klick och ange hur många sidor du vill skrapa. Thunderbit bläddrar då automatiskt vidare och hämtar all data från varje sida.
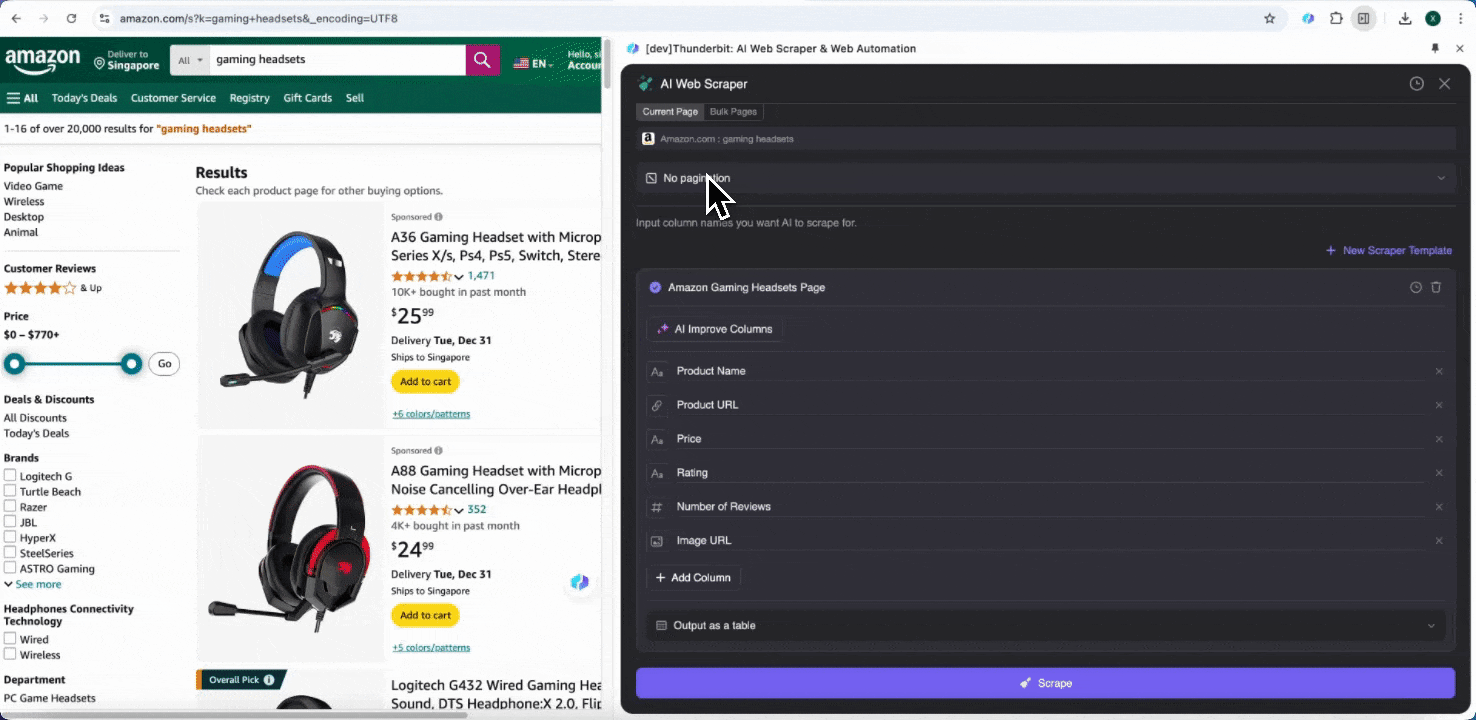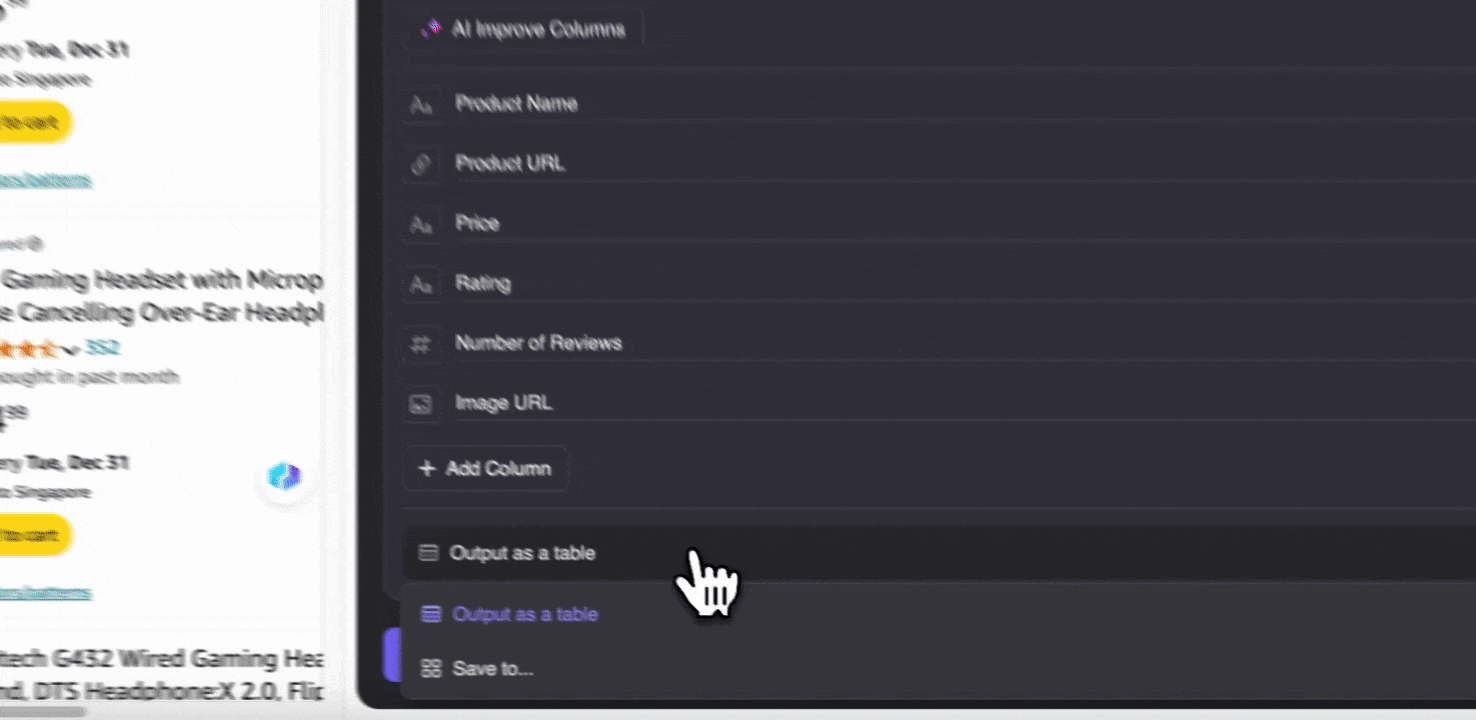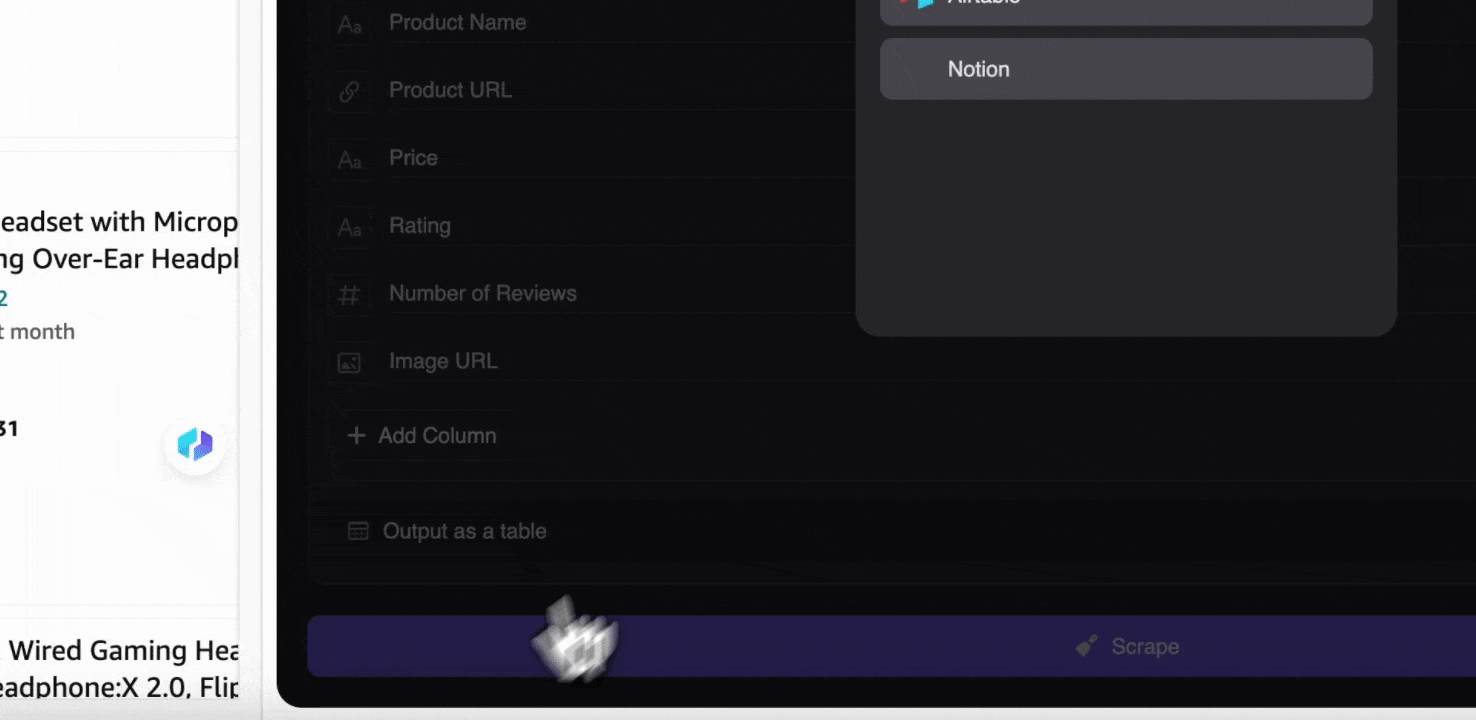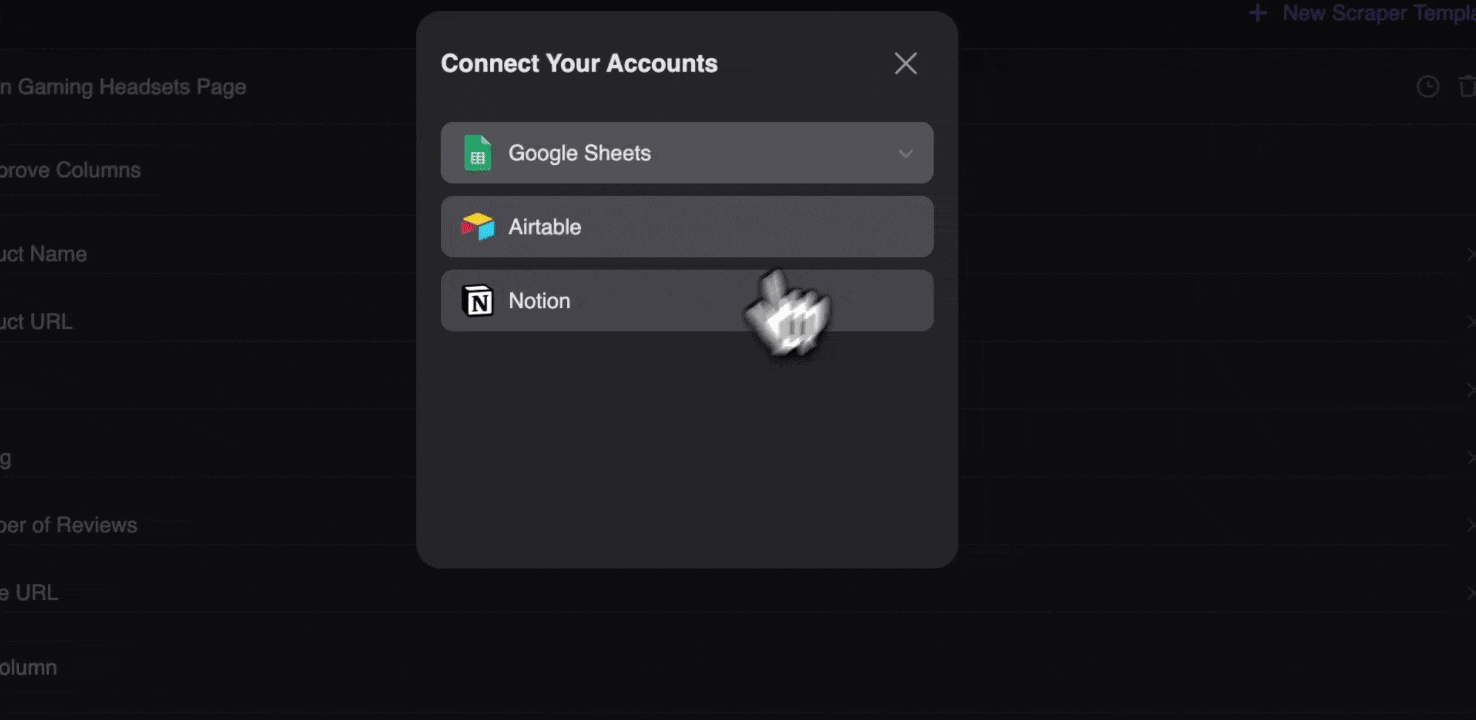
Steg 3: Ladda ner den insamlade datan eller exportera som tabell
Med Thunderbit-web scraper-tillägget kan du exportera insamlad data på flera sätt. Välj att visa resultatet som en tabell och ladda sedan ner CSV-filen lokalt, eller välj spara till Google Sheets, Notion eller Airtable. Logga in på ditt konto och exportera direkt till dessa molnbaserade samarbetsplattformar.
Skrapa Amazon-SKU-data med AI på 2 klick
Scraping med traditionella web scraper-verktyg
Förutom de senaste AI-verktygen kan du också använda traditionella web scraper-verktyg med lätt kod och API:er för att samla in produktdata från Amazon.
ScraperAPI: Hämta Amazon-produkdata i JSON-format via API
ScraperAPI erbjuder ett effektivt API för datainsamling från Amazon som hjälper dig att hämta produktdetaljer, recensioner, sökresultat och prisinformation från Amazon och returnerar det i ett strukturerat JSON-format. Så här använder du API:et för scraping.
Steg 1: Ställ in Python-miljön
Först bör du se till att du har Python 3.8 eller senare installerat. Installera sedan vanliga analysbibliotek som Pandas och webbskrapningsbibliotek som requests och BeautifulSoup. Dessa bibliotek hjälper dig att enkelt extrahera data från webbsidor.
Steg 2: Skapa ett ScraperAPI-konto
Gå till ScraperAPI:s webbplats för att skapa ett gratiskonto och få din API-nyckel. Du kan använda nyckeln för att komma åt ScraperAPI i din kod.
Steg 3: Förbered koden
Skapa en egen lokal mapp och skriv ett Python-skript för att implementera datainsamlingen. Här är ett enkelt arbetsflöde:
- Hämta Amazon-sök-URL: Sök efter produkten du vill hitta på Amazon och kopiera URL:en till sökresultatsidan.
- Bygg förfrågningar: ScraperAPI loopar automatiskt genom de första fem sidorna med sökresultat. URL:en för varje sida skapas genom att lägga till &page= och motsvarande sidnummer till bas-URL:en.
- Skicka förfrågningar och tolka data: Använd metoden get() för att skicka förfrågningar till ScraperAPI. Om begäran lyckas (statuskod 200) kan du tolka sidinnehållet för att extrahera önskat ASIN (Amazon Standard Identification Number).
- Hämta detaljerad produktdata: Genom att anropa slutpunkten för strukturerad data kan du få detaljerad produktinformation för varje ASIN för vidare analys.
Steg 4: Se fler guider
För mer detaljerade användarguider kan du läsa ScraperAPI:s officiella bloggtutorial för ytterligare information.
ScrapFly: Undvik blockering och skala upp scraping
När du samlar in data från Amazon är anti-scraping-tekniker som IP-blockering, CAPTCHAs och dynamisk inläsning av innehåll ofta utmaningar för utvecklare. ScrapFly tillhandahåller ett kraftfullt API som hjälper dig att kringgå dessa mekanismer och säkerställer en smidig datainsamling.
ScrapFlys viktigaste funktioner är:
- Rotating Residential Proxies: Växlar automatiskt IP-adresser för att undvika IP-blockering.
- JavaScript Rendering: Hanterar dynamiskt innehåll och skrapar webbsidor som renderas med JavaScript.
- Full Browser Automation: Styr webbläsare för att scrolla, skriva in och klicka på element.
- Format Conversion: Skrapa som HTML, JSON, Text eller Markdown.
Med bara några rader kod kan du använda ScrapFly för att skrapa Amazon-data. Här är ett enkelt exempel:
import scrapfly_sdk
# Skapa en klient
client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
# Skicka en begäran
response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
# Hämta den returnerade datan
print(response.json())
Genom att använda ScrapFly kan din scraper hantera Amazons olika anti-scraping-mekanismer, vilket ökar träffsäkerheten i datainsamlingen. Oavsett om det gäller enkel produktinformation eller avancerad recensionsanalys är ScrapFly ett mycket praktiskt verktyg. För mer detaljerade guider, se ScrapFlys officiella handledning.
Scraping med Python: Traditionella kodmetoder
För dig som kan kod kan du också prova att skriva Python-kod för att samla in produktdata från Amazon. Här är ett enkelt exempel som referens.
Steg 1: Förbered det du behöver
Skapa först en egen mapp för projektet.
mkdir amazonscraper
Installera sedan de nödvändiga biblioteken i den här mappen.
pip install beautifulsoup4
pip install requests
Skapa nu en Python-fil med valfritt namn. Det blir huvudfilen där vi lägger vår kod. Jag döper den till amazon.py.
Steg 2: Gör en GET-begäran till målsidan
Nu gör vi en GET-begäran till vår målsida med biblioteket requests.
import requests
from bs4 import BeautifulSoup
target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
headers = {
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
}
response = requests.get(target_url, headers=headers)
Steg 3: Skrapa Amazon-produktdata
Nu behöver vi bestämma vad vi ska hämta från målsidan.
# Kontrollera om begäran lyckades
if response.status_code == 200:
# Tolka sidinnehållet
soup = BeautifulSoup(response.content, 'html.parser')
# Hitta alla produktlistningar
products = soup.find_all('div', {'data-component-type': 's-search-result'})
# Gå igenom varje produkt och hämta detaljer
for product in products:
# Hämta produktnamn
title = product.h2.text.strip()
# Hämta produktpris
price = product.find('span', 'a-price')
if price:
price = price.find('span', 'a-offscreen').text.strip()
else:
price = "Pris ej tillgängligt"
# Hämta produktbetyg
rating = product.find('span', 'a-icon-alt')
if rating:
rating = rating.text.strip()
else:
rating = "Betyg ej tillgängligt"
# Skriv ut produktinformationen
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")
print("-" * 40)
else:
print(f"Det gick inte att hämta sidan. Statuskod: {response.status_code}")
Vanliga frågor
1. Är det lagligt att skrapa amazon.com?
Ja, det är lagligt att skrapa Amazons offentliga data! Precis som många andra webbplatser gör Amazon sina produktlistningar och annan offentlig information tillgänglig för alla som vill titta på den. Du kan skrapa och samla in fritt tillgänglig data utan att bryta mot Amazons användarvillkor.
2. Kan jag testa Thunderbit gratis?
Ja, Thunderbit erbjuder gratis sidextraktion och datainsamling. Vissa avancerade funktioner kan kräva betalning, men de grundläggande funktionerna för datainsamling är ofta gratis.
3. Vilken data kan jag skrapa från Amazon?
Du kan samla in en mängd olika uppgifter från Amazon, inklusive produktnamn, priser, beskrivningar, recensioner, betyg och säljarinformation. Den datan kan vara värdefull för marknadsundersökningar, prisövervakning och konkurrensanalys.
4. Hur ofta bör jag skrapa Amazon-data?
Frekvensen beror på vilken typ av data du är ute efter. Om du bevakar priser eller konkurrentaktivitet kan det vara lämpligt att skrapa dagligen eller veckovis. För mer statisk information som produktdetaljer kan månadsvis insamling räcka.
Läs mer
- Hur du skrapar webbplatsdata till Excel med AI
- 6 bästa Twitter (x.com)-scrapers 2025
- Hur du skrapar data från PDF med AI
Testa AI Web Scraper Get Started Free




