Mitt OpenRouter-instrumentpanel visade 47 dollar redan innan lunch en tisdag. Jag hade kanske kört ett dussin koduppgifter — inget extremt, bara lite refaktorering och några buggfixar. Då insåg jag att OpenClaws standardinställningar i tysthet skickade varje enda interaktion, inklusive bakgrundens heartbeat-pingar, via Claude Opus till över 15 dollar per miljon tokens.
Om du har varit med om liknande överraskningar — och om forumen ska man tro är det många som har det ("Jag har redan spenderat 40 dollar och använder det knappt ens", skrev en användare) — så går den här guiden igenom hela arbetssättet jag använde för att granska och optimera kostnaden och få ner min månadskostnad med ungefär 90 %. Inte bara "byt till en billigare modell", utan en systematisk genomgång av vart openclaw tokenförbrukning faktiskt tar vägen, hur du övervakar den, vilka budgetmodeller som faktiskt håller för riktigt agentiskt arbete, och tre färdiga konfigurationer du kan klistra in direkt. Hela processen tog en eftermiddag.
Vad är OpenClaw tokenförbrukning (och varför är den så hög som standard)?
Tokens är debiteringsenheten för varje AI-interaktion i OpenClaw. Tänk på dem som små textbitar — ungefär 4 engelska tecken per token. Varje meddelande du skickar, varje svar du får, varje bakgrundsprocess som körs: allt faktureras i tokens.
Problemet är att OpenClaws standardvärden är optimerade för maximal kapacitet, inte minimal kostnad. Direkt ur lådan är huvudmodellen inställd på anthropic/claude-opus-4-5 — det dyraste alternativet som finns. Heartbeat-pingar? De körs också på Opus. Delagenter som startas för sidouppgifter? Också Opus. Att använda Opus för en heartbeat-ping är som att anlita en neurokirurg för att sätta på ett plåster. Tekniskt möjligt, men katastrofalt dyrt.
De flesta användare inser inte att de betalar premiumpris för triviala bakgrundsuppgifter. Standardkonfigurationen utgår i praktiken från att du vill ha bästa möjliga modell för allt, hela tiden — och debiterar därefter.
Varför lägre OpenClaw tokenförbrukning sparar mer än bara pengar
Den uppenbara vinsten är lägre kostnad. Men det finns också indirekta fördelar som växer över tid.
Billigare modeller är ofta snabbare. Gemini 2.5 Flash-Lite ligger på ungefär jämfört med Opus på runt 51 — alltså cirka 4 gånger snabbare i varje interaktion. GPT-OSS-120B på Cerebras når , vilket är ungefär 35 gånger snabbare än Opus. I en agentisk loop med 50+ verktygskallningssteg betyder den skillnaden att arbetet blir klart på minuter i stället för att du sitter och väntar på Opus långsamma 13,6 sekunder till första token vid varje rundgång.
Du får också mer marginal innan du når rate limits, färre strypta sessioner och större utrymme att skala användningen utan att skala upp oron för fakturan.
Beräknade besparingar för olika användningsnivåer:
| Användarprofil | Uppskattad månadskostnad (standard) | Efter full optimering | Månatlig besparing |
|---|---|---|---|
| Lätt (~10 frågor/dag) | ~$100 | ~$12 | ~88% |
| Medel (~50 frågor/dag) | ~$500 | ~$90 | ~82% |
| Tung (~200+ frågor/dag) | ~$1,750 | ~$220 | ~87% |
Det här är inte hypotetiskt. En utvecklare dokumenterade hur han gick från — en verklig sänkning på 90 % — genom att kombinera modellrouting med de dolda kostnadsdräneringar som tas upp senare i guiden.
OpenClaws tokenanvändning i praktiken: var varje token faktiskt tar vägen
Det här är delen de flesta optimeringsguider hoppar över, och det är också den viktigaste. Du kan inte fixa det du inte kan se.
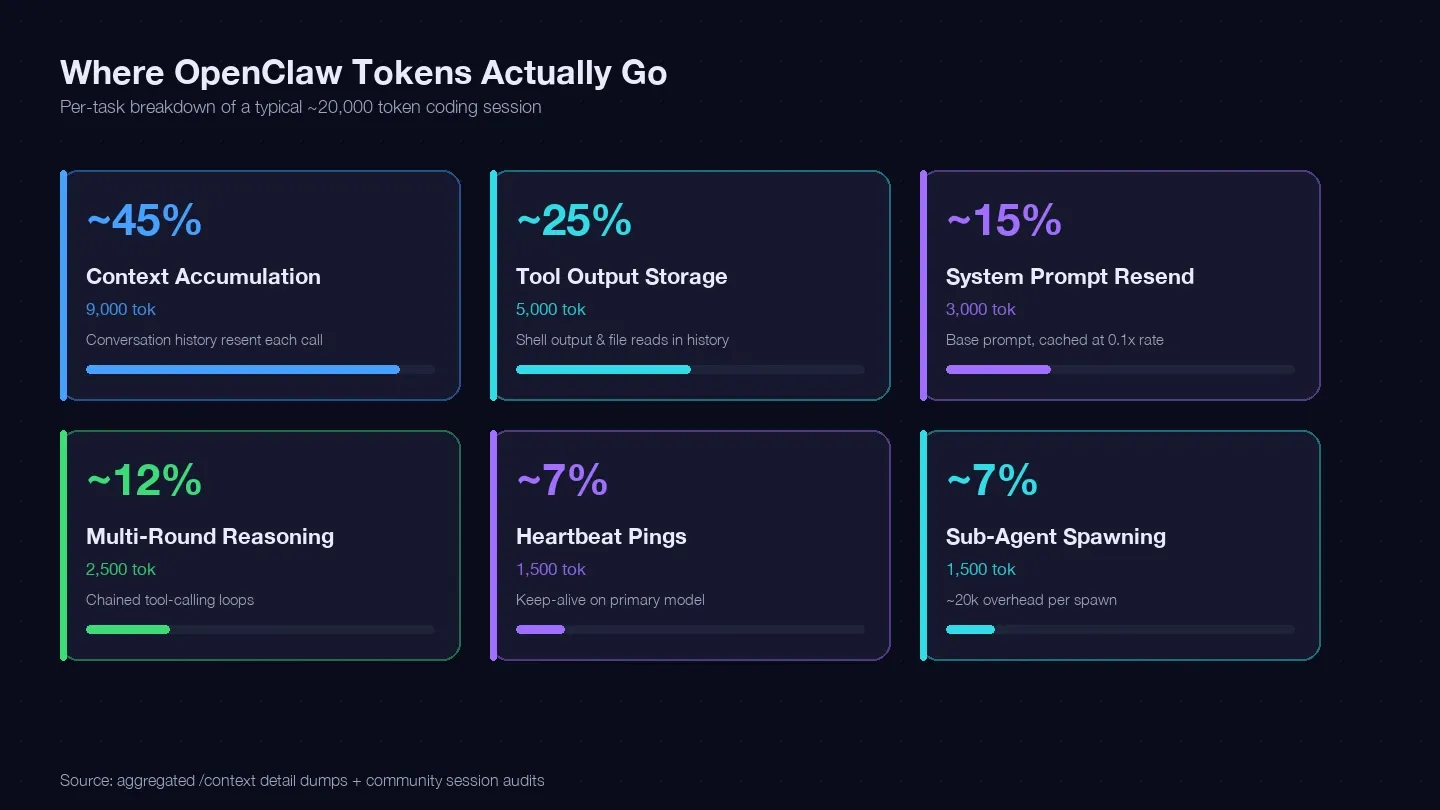
Jag granskade flera sessioner och jämförde med samt community-dumpar av /context för att bygga ett tokenbokslut för en typisk koduppgift. Här gick ungefär 20 000 tokens faktiskt åt:
| Tokentyp | Typisk andel av totalen | Exempel (1 koduppgift) | Kan du styra det? |
|---|---|---|---|
| Kontextackumulering (samtalshistorik skickas om vid varje anrop) | ~40–50% | ~9 000 tokens | Ja — /clear, /compact, kortare sessioner |
| Lagring av verktygsoutput (shell-output, filinläsningar sparas i historiken) | ~20–30% | ~5 000 tokens | Ja — mindre läsningar, snävare verktygsomfång |
| Omförsändning av systemprompt (~15K bas) | ~10–15% | ~3 000 tokens | Delvis — cacheade läsningar till 0,1x pris |
| Resonemang i flera rundor (kedjade verktygskallningsloopar) | ~10–15% | ~2 500 tokens | Modellval + bättre prompts |
| Heartbeat-/keep-alive-pingar | ~5–10% | ~1 500 tokens | Ja — ändra konfiguration |
| Delagetanrop | ~5–10% | ~1 500 tokens | Ja — modellrouting |
Den största posten — kontextackumulering — är att din konversationshistorik skickas på nytt vid varje API-anrop. En visade 185 400 tokens bara i Messages-facket, innan modellen ens hade svarat. Systemprompten och verktygen lade dessutom till ytterligare cirka 35 800 tokens i fast overhead.
Slutsatsen: om du inte rensar sessioner mellan orelaterade uppgifter betalar du för att sända om hela din konversationshistorik vid varje enskild vändning.
Så övervakar du OpenClaw tokenförbrukning (du kan inte kapa det du inte ser)
Innan du ändrar något behöver du få insyn i vart dina tokens tar vägen. Att gå direkt till "använd en billigare modell" utan övervakning är som att försöka gå ner i vikt utan att någonsin ställa sig på vågen.
Kolla din OpenRouter-dashboard
Om du routar via OpenRouter är den enklaste dashboarden utan uppsättning. Du kan filtrera per modell, leverantör, API-nyckel och tidsperiod. Vyn Usage Accounting visar prompt-, completion-, reasoning- och cacheade tokens för varje förfrågan. Det finns också en Export-knapp (CSV eller PDF) för längre analyser.
Det du ska leta efter: vilken modell som konsumerade flest tokens, och om heartbeat- eller delagetanrop dyker upp som oväntat stora poster.
Granska dina lokala API-loggar
OpenClaw sparar sessionsdata i ~/.openclaw/agents.main/sessions/sessions.json, där totalTokens finns per session. Du kan också köra openclaw logs --follow --json för loggning per förfrågan i realtid.
En viktig brasklapp: , så dashboarden kan visa gamla värden före komprimering. Lita mer på /status och /context detail än på de sparade totalsummorna.
Använd tredjepartsverktyg för spårning (för medelstora till tunga användare)
LiteLLM proxy ger dig en OpenAI-kompatibel endpoint framför 100+ leverantörer och . Den riktigt starka funktionen: hårda budgetar per nyckel som överlever /clear — en skenande delagent kan alltså inte spränga en gräns du satt.
Helicone är ännu enklare — ett som ger dig en Sessions-vy där relaterade förfrågningar grupperas. En enda prompt som "fixa den här buggen" och som förgrenar sig till 8+ delagetanrop visas som en rad i sessionen med den verkliga totalkostnaden. .
Snabbkontroller direkt i OpenClaw
För vardagsövervakning räcker fyra kommandon i sessionen:
/status— visar kontextanvändning, senaste input-/outputtokens, uppskattad kostnad/usage full— användningsfooter per svar/context detail— tokenfördelning per fil, förmåga och verktyg/compact [guidance]— tvinga komprimering med valfri fokussträng
Kör /context detail före och efter att du gör konfigurationsändringar. Så mäter du om dina optimeringar faktiskt fungerade.
OpenClaws billigaste modeller: vilka budget-LLM:er klarar egentligen agentiskt arbete?
Det är här de flesta guider spårar ur. De visar en pristabell, pekar på billigaste raden och är klara. Men benchmarkresultat förutsäger inte verklig agentisk prestanda — något communityn har påpekat högt och tydligt. Som en användare uttryckte det: "benchmarks säger inte mycket om vilken som fungerar bäst för agentisk AI."
Den viktiga insikten: den billigaste modellen är inte alltid det billigaste utfallet. En modell som misslyckas och måste köras om fyra gånger kostar mer än en mellanklassmodell som . I produktionssystem med agenter bör du räkna med en — och om fem LLM-anrop är kedjade och steg fyra fallerar, så kör en naiv retry om alla fem stegen.
Här är min kapabilitetsmatris, med ett "Real Agentic Score" baserat på faktiska användarrapporter snarare än syntetiska benchmarkresultat:
| Modell | Input $/1M | Output $/1M | Tillförlitlighet vid verktygskallning | Resonemang i flera steg | Real Agentic Score (1–5) | Bäst för |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Blandat — ibland loopar | Grundläggande | ⭐2.5 | Heartbeats, enkla uppslag |
| GPT-OSS-120B | $0.04 | $0.19 | Godtagbar | Godtagbar | ⭐3.0 | Budgetexperiment, fartkänsligt arbete |
| DeepSeek V3.2 | $0.26 | $0.38 | Ojämn (6 öppna ärenden) | Bra | ⭐3.0 | Resonemangstungt, minimalt verktygsanrop |
| Kimi K2.5 | $0.38 | $1.72 | Bra (via :exacto) | Godtagbar | ⭐3.5 | Enkel till medelsvår kodning |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Bra | Bra | ⭐4.0 | Allroundmodell för daglig kodning |
| Claude Haiku 4.5 | $1.00 | $5.00 | Utmärkt | Bra | ⭐4.5 | Pålitlig fallback i mellanklassen |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Utmärkt | Utmärkt | ⭐5.0 | Komplexa flerstegsuppgifter |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Utmärkt | Utmärkt | ⭐5.0 | Spara till de allra svåraste problemen |
En varning om DeepSeek och Gemini Flash för verktygskallning
DeepSeek V3.2 ser bra ut på pappret — 72–74 % på , 11–36 gånger billigare än Sonnet. I praktiken dokumenterar i Cline, Roo Code, Continue och NVIDIA NIM trasigt beteende vid verktygskallning. Composios jämförelse sammanfattar det så här: "." Zvi Mowshowitz sammanfattade det kort: "."
Gemini 2.5 Flash har en liknande lucka. En tråd i Google AI Developers Forum med rubriken "Very frustrating experience with Gemini 2.5 function calling performance" inleds med: "."
OpenRouter flaggade en viktig nyans: "." Om du routar billiga modeller via OpenRouter, håll utkik efter :exacto-taggen — ett tyst leverantörsbyte kan över en natt förvandla en pålitlig billig modell till en dyr retry-loop.
När du ska använda respektive modell
- Gemini Flash-Lite: Heartbeats, keep-alive-pingar, enkla frågor och svar. Aldrig för flerstegs verktygskallning.
- MiniMax M2.5/M2.7: Din dagliga modell för allmän kodning. till en bråkdel av Sonnet-priset.
- Claude Haiku 4.5: Den pålitliga fallbacken när billiga modeller fastnar i verktygskallningar. Utmärkt tillförlitlighet vid verktygskallning till ungefär en tredjedel av Sonnet-priset.
- Claude Sonnet 4.6: Komplexa agentiska uppgifter i flera steg. Här får du valuta för pengarna.
- Claude Opus: Spara den till de svåraste problemen. Låt den inte vara standard för något.
(Modellpriser ändras ofta — kontrollera aktuella priser på eller direkt hos leverantören innan du låser en konfiguration.)
De dolda tokenläckorna som de flesta guider hoppar över
Forumanvändare rapporterar att specifika funktioner kan sänka kostnaderna drastiskt när de stängs av, men ingen guide jag hittat ger en enhetlig checklista över alla dolda läckor med deras verkliga tokenpåverkan. Här är hela genomgången:
| Dold kostnadsdränering | Tokenkostnad per förekomst | Så fixar du det | Konfigurationsnyckel |
|---|---|---|---|
| Standardheartbeat på Opus | ~100 000 tokens/körning utan isolering | Haiku-override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Start av delagenter | ~20 000 tokens per start innan något arbete utförs | Routa delagenter till Haiku | subagents.model |
| Inladdning av hela kodbasens kontext | ~3 000–15 000 tokens per auto-explore | .clawignore för node_modules, dist, lockfiler | .clawrules + .clawignore |
| Automatisk minnessummering | ~500–2 000 tokens/session | Stäng av eller minska frekvensen | memory: false eller memory.max_context_tokens |
| Ackumulering av konversationshistorik | ~500+ tokens/turn (kumulativt) | Starta nya sessioner mellan orelaterade uppgifter | Disciplin med /clear |
| Verktygsöverhead från MCP-servrar | ~7 000 tokens för 4 servrar; 50 000+ för 5+ | Håll MCP minimalt | Ta bort oanvända MCP:er |
| Initiering av skills/plugins | 200–1 000 tokens per inläst skill | Stäng av oanvända skills | skills.entries.<name>.enabled: false |
| Agent Teams (planläge) | ~7x normal sessionskostnad | Använd endast när arbetet verkligen är parallellt | Föredra sekventiellt |
Heartbeat-läckan förtjänar ett eget upprop. Som standard körs heartbeats på huvudmodellen (Opus) var 30:e minut. Om du sätter isolatedSession: true minskar det från cirka 100 000 tokens per körning — en minskning på 95–98 % för just den posten.
Tre snabba vinster som sparar mest tokens på under två minuter
Alla tre är riskfria och tar under två minuter:
-
/clearmellan orelaterade uppgifter (5 sekunder). Det här är den enskilt största tokenbespararen. Forumkonsensus sätter den till bara genom att rensa sessionshistoriken innan nytt arbete påbörjas. Kom ihåg Messages-bucketen på 185k tokens från/context-dumpen?/cleartar bort den. -
/model haiku-4.5för grovjobbet (10 sekunder). Taktiskt modellbyte ger för rutinuppgifter. Haiku hanterar de flesta enkla kodändringar, filuppslag och commitmeddelanden utan problem. -
Håll
.clawrulesunder 200 rader + lägg till.clawignore(90 sekunder). Din rules-fil laddas vid varje enda meddelande. Vid 200 rader är det ungefär 1 500–2 000 tokens per vändning; vid 1 000 rader är det 8 000–10 000 tokens som permanent belastar varje anrop. Tillsammans med en.clawignoresom exkluderarnode_modules/,dist/, lockfiler och genererad kod hävdar en utvecklare enbart genom denna disciplin.
Steg för steg: tre färdiga konfigurationer för att kapa OpenClaw tokenförbrukning

Nedan följer tre kompletta, kommenterade openclaw.json-konfigurationer — från "kom igång direkt" till "full optimeringsstack". Varje exempel innehåller kommentarer i raden och uppskattade månadskostnader.
Innan du börjar:
- Svårighetsgrad: Nybörjare (Config A) → Medel (Config B) → Avancerad (Config C)
- Tidsåtgång: cirka 5 minuter för Config A, cirka 15 minuter för Config C
- Det du behöver: OpenClaw installerat, en texteditor, tillgång till
~/.openclaw/openclaw.json
Config A: Nybörjare — spara bara pengar
Fem rader. Ingen komplexitet. Byter standardmodell från Opus till Sonnet, stänger av minnesöverhead och isolerar heartbeats till Haiku.
1// ~/.openclaw/openclaw.json
2{
3 "agents": {
4 "defaults": {
5 "model": { "primary": "anthropic/claude-sonnet-4-6" }, // var Opus — omedelbar besparing på 3-5x
6 "heartbeat": {
7 "every": "55m", // matcha 1h cache-TTL för maximal cacheträff
8 "model": "anthropic/claude-haiku-4-5", // Haiku för pingar, inte Opus
9 "isolatedSession": true // ~100k → 2-5k tokens per körning
10 }
11 }
12 },
13 "memory": { "enabled": false } // sparar ~500-2k tokens/session
14}Vad du bör se efter att ha applicerat detta: Kör /status före och efter. Din kostnad per anrop bör sjunka märkbart, och heartbeat-poster i din OpenRouter Activity-sida bör visa Haiku i stället för Opus.
| Användningsnivå | Standard (Opus) | Config A (Sonnet + Haiku-heartbeats) | Besparing |
|---|---|---|---|
| Lätt (~10 frågor/dag) | ~$100 | ~$35 | 65% |
| Medel (~50 frågor/dag) | ~$500 | ~$250 | 50% |
| Tung (~200 frågor/dag) | ~$1,750 | ~$900 | 49% |
Config B: Medel — smart routing i tre nivåer
Primär Sonnet för riktigt arbete. Haiku för delagenter och komprimering. Gemini Flash-Lite som budgetfallback när Claude är strypt. Fallbackkedjor hanterar avbrott hos leverantörer automatiskt.
1{
2 "agents": {
3 "defaults": {
4 "model": {
5 "primary": "anthropic/claude-sonnet-4-6",
6 "fallbacks": [
7 "anthropic/claude-haiku-4-5", // om Sonnet är strypt
8 "google/gemini-2.5-flash-lite" // ultrabillig sista utväg
9 ]
10 },
11 "models": {
12 "anthropic/claude-sonnet-4-6": {
13 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
14 }
15 },
16 "heartbeat": {
17 "every": "55m", // 55 min < 1h cache-TTL = cacheträffar
18 "model": "google/gemini-2.5-flash-lite", // ören per ping
19 "isolatedSession": true,
20 "lightContext": true // minimal kontext i heartbeat-anrop
21 },
22 "subagents": {
23 "maxConcurrent": 4, // ned från standard 8
24 "model": "anthropic/claude-haiku-4-5" // delagenter behöver inte Sonnet
25 },
26 "compaction": {
27 "mode": "safeguard",
28 "model": "anthropic/claude-haiku-4-5", // kompakteringssammanfattningar via Haiku
29 "memoryFlush": { "enabled": true }
30 }
31 }
32 }
33}Förväntat resultat: Delagentposter i loggarna bör nu visa Haiku-prissättning. Heartbeats bör kosta nästan ingenting. Din fallbackkedja gör att ett Claude-avbrott inte stoppar sessionen — den degraderas mjukt till Gemini.
| Användningsnivå | Standard | Config B | Besparing |
|---|---|---|---|
| Lätt | ~$100 | ~$20 | 80% |
| Medel | ~$500 | ~$150 | 70% |
| Tung | ~$1,750 | ~$500 | 71% |
Config C: Power user — full optimeringsstack
Per-delagent-modell, kontextkomprimering låst till Haiku, vision-routing till Gemini Flash, strama .clawrules + .clawignore, inaktiverade oanvända skills. Det här är konfigurationen som tar dig till 85–90 % besparing.
1{
2 "agents": {
3 "defaults": {
4 "workspace": "~/clawd",
5 "model": {
6 "primary": "anthropic/claude-sonnet-4-6",
7 "fallbacks": [
8 "openrouter/anthropic/claude-sonnet-4-6", // annan leverantör som backup
9 "minimax/minimax-m2-7", // billig daglig fallback
10 "anthropic/claude-haiku-4-5" // sista utväg
11 ]
12 },
13 "models": {
14 "anthropic/claude-sonnet-4-6": {
15 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
16 },
17 "minimax/minimax-m2-7": {
18 "params": { "maxTokens": 8192 }
19 }
20 },
21 "heartbeat": {
22 "every": "55m",
23 "model": "google/gemini-2.5-flash-lite",
24 "isolatedSession": true,
25 "lightContext": true,
26 "activeHours": "09:00-19:00" // inga heartbeats nattetid
27 },
28 "subagents": {
29 "maxConcurrent": 4,
30 "model": "anthropic/claude-haiku-4-5"
31 },
32 "contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
33 "compaction": {
34 "mode": "safeguard",
35 "model": "anthropic/claude-haiku-4-5",
36 "identifierPolicy": "strict",
37 "memoryFlush": { "enabled": true }
38 },
39 "bootstrapMaxChars": 12000, // ned från standard 20000
40 "imageModel": "google/gemini-3-flash" // vision-uppgifter via billig modell
41 }
42 },
43 "memory": { "enabled": true, "max_context_tokens": 800 }, // minimalt minne
44 "skills": {
45 "entries": {
46 "web-search": { "enabled": false },
47 "image-generation": { "enabled": false },
48 "audio-transcribe": { "enabled": false }
49 }
50 }
51}Exempel på override per delagent — klistra in i ~/.openclaw/agents/lint-runner/SOUL.md:
1---
2name: lint-runner
3description: Kör lint-/formatkontroller och tillämpar triviala fixar
4tools: [Bash, Read, Edit]
5model: anthropic/claude-haiku-4-5
6---Minimalt användbar .clawignore — den här ensam kapar typiska bootstraps från 150k tecken ner mot 30–50k:
1node_modules/
2dist/
3build/
4.next/
5coverage/
6.venv/
7vendor/
8*.lock
9package-lock.json
10yarn.lock
11pnpm-lock.yaml
12*.min.js
13*.min.css
14**/__snapshots__/
15**/*.snap| Användningsnivå | Standard | Config C | Besparing |
|---|---|---|---|
| Lätt | ~$100 | ~$12 | 88% |
| Medel | ~$500 | ~$90 | 82% |
| Tung | ~$1,750 | ~$220 | 87% |
De här siffrorna stämmer överens med två oberoende rapporter från verkliga användare: Praney Behls dokumenterade (90 % nedskärning), och LaoZhangs fallstudier som visar med partiell optimering.
Använd kommandot /model för att styra OpenClaw tokenförbrukning i farten
Kommandot /model byter aktiv modell för nästa vändning samtidigt som hela kontexten i samtalet bevaras — ingen reset, ingen förlorad historik. Det här är den dagliga vanan som bygger upp besparingar över tid.
Praktiskt arbetssätt:
- Jobbar du med en knepig refaktorering över flera filer? Stanna på Sonnet.
- Snabbfråga som "vad gör det här regexuttrycket?"?
/model haiku, fråga, och byt sedan tillbaka med/model sonnet. - Commit-meddelande eller putsning av dokumentation?
/model flash-lite, klart.
Du kan skapa alias i openclaw.json under commands.aliases för att mappa kortnamn (haiku, sonnet, opus, flash) till fulla provider-strängar. Sparar några tangenttryckningar vid varje byte.
Matematik: 50 frågor/dag på Sonnet landar ungefär på 3 dollar/dag. Samma 50 frågor fördelade 70/20/10 mellan Haiku/Sonnet/Opus blir cirka 1,10 dollar/dag. Över en månad innebär det 90 dollar → 33 dollar — 63 % billigare utan att byta verktyg, bara vanor.
Bonus: spåra OpenClaw modellpriser mellan leverantörer med Thunderbit
Med så många modeller och leverantörer — OpenRouter, direkt via Anthropic API, Google AI Studio, DeepSeek, MiniMax — ändras priser ofta. Anthropic sänkte Opus output-priser med ungefär 67 % över en natt. Google drog ner Gemini-gränserna på gratisnivån i december 2025. Att hålla ett statiskt kalkylark uppdaterat manuellt är en förlorad kamp.
löser detta utan någon scrapingkod. Det är en -baserad AI-webbskrapare byggd just för den här typen av strukturerad datautvinning.
Så här arbetar jag:
- Öppna OpenRouter-sidan för modeller i Chrome och klicka på Thunderbits "AI Suggest Fields". Den läser sidan och föreslår kolumner — modellnamn, ingångspris, utgångspris, kontextfönster, leverantör.
- Klicka på Scrape och exportera direkt till Google Sheets.
- Schemalägg en scraping i vanlig svenska — "varje måndag klockan 9, skrapa om OpenRouter-listan med modeller" — så körs det automatiskt i molnet.
Efter det uppdaterar din personliga prisbevakning sig själv. Varje modell som plötsligt blir 30 % billigare — eller varje leverantör som får Exacto-taggen — dyker upp i måndagsarket utan att du gör något alls. Vi har skrivit mer om på vår blogg.
Jämför du priser mellan direkta leverantörssidor (Anthropic, Google, DeepSeek)? Thunderbits skrapning av undersidor följer varje modellänk till detaljsidan och hämtar priser per leverantör — användbart när du vill veta om det är billigare att routa Kimi K2.5 via OpenRouter än att gå direkt genom . Se för gratisnivå och planinformation.
Viktiga lärdomar för att minska OpenClaw tokenförbrukning
Ramverket: Förstå → Övervaka → Routa → Optimera.
Åtgärderna som ger störst effekt, i ordning:
- Låt inte Opus vara standard. Byt huvudmodell till Sonnet eller MiniMax M2.7. Det här ensamt ger 3–5 gånger lägre kostnad.
- Isolera heartbeats. Sätt
isolatedSession: trueoch routa heartbeats till Gemini Flash-Lite. Då förvandlas en drain på cirka 100k tokens till cirka 2–5k. - Routa delagenter till Haiku. Varje start lägger in runt 20k tokens kontext innan något arbete ens börjat. Låt inte det ske på Opus.
- Använd
/clearkonsekvent. Gratis, tar 5 sekunder, och communityn är enig om att det sparar mer än någon annan enskild åtgärd. - Lägg till
.clawignore. Genom att exkluderanode_modules, lockfiler och byggartefakter minskar bootstrap-kontexten dramatiskt. - Övervaka med
/context detailföre och efter ändringar. Om du inte kan mäta det, kan du inte förbättra det.
Den billigaste modellen beror på uppgiften. Gemini Flash-Lite för heartbeats. MiniMax M2.7 för daglig kodning. Haiku för tillförlitlig verktygskallning. Sonnet för komplexa fler-stegsuppgifter. Opus för de verkligt svåraste problemen — och inget annat.
De flesta läsare kan få 50–70 % besparing på en enda eftermiddag med Config A eller B. De fulla 85–90 % kräver att allt ovan staplas — modellrouting, fixar av dolda läckor, .clawignore, och disciplin med sessionerna — men det går, och det håller i längden.
Vanliga frågor
1. Hur mycket kostar OpenClaw per månad?
Det beror helt på din konfiguration, användningsvolym och modellval. Lätta användare (~10 frågor/dag) brukar ligga på 5–30 dollar/månad med optimering, eller 100+ dollar med standardinställningar. Medelanvändare (~50 frågor/dag) hamnar ofta på 90–400 dollar/månad. Tunga användare kan nå med standardvärden — ett dokumenterat extremfall var 5 623 dollar på en enda månad. Anthropics egna interna telemetri pekar på ett medianvärde runt .
2. Vilken är den billigaste OpenClaw-modellen som ändå fungerar bra för kodning?
är den bästa allmänna dagliga modellen — bra tillförlitlighet vid verktygskallning, SWE-Pro 56,22, till ungefär 0,28/1,10 dollar per miljon tokens. För heartbeats och enkla uppslag är Gemini 2.5 Flash-Lite till 0,10/0,40 dollar svårslagen. Claude Haiku 4.5 till 1/5 dollar är den pålitliga fallbacken i mellanklassen när du behöver utmärkt verktygskallning utan att betala Sonnet-priser.
3. Kan jag använda modeller på gratisnivå med OpenClaw?
Tekniskt sett ja. GPT-OSS-120B är gratis via OpenRouters :free-tagg och NVIDIA Build. Gemini Flash-Lite har en gratisnivå (15 RPM, 1 000 förfrågningar/dag). DeepSeek ger . Men gratisnivåer har aggressiva rate limits, långsammare hastighet och osäker tillgänglighet. Billiga betalmodeller — ören per miljon tokens — är betydligt mer pålitliga för regelbunden användning.
4. Tappar jag kontexten om jag byter modell mitt i en konversation med /model?
Nej. /model bevarar hela sessionskontexten — nästa vändning routas till den nya modellen med hela historiken intakt. Det här är verifierat i OpenClaws konceptdokumentation och fungerar på samma sätt i Claude Code. Du kan fritt växla mellan Haiku för snabba frågor och Sonnet för komplexa uppgifter utan att förlora något.
5. Vad är det snabbaste sättet att minska min OpenClaw-räkning redan idag?
Skriv /clear mellan orelaterade uppgifter. Det är gratis, tar fem sekunder och tömmer samtalshistoriken som skickas om vid varje API-anrop. En verklig session visade i ackumulerad meddelandehistorik — allt detta skickades och debiterades om vid varje enda vändning. Att rensa det innan du börjar ett nytt jobb är den vana som ger högst avkastning.