

Att optimera Apollo-listeforespørsler handlar inte bara om teknik — det är en överlevnadsfråga för alla som förlitar sig på nyhetsdata i realtid, automatiserad nyhetsextraktion eller snabba arbetsflöden inom sälj och drift. Jag har sett på nära håll hur en seg listeforespørsel kan förvandla en smidig dashboard till en flaskhals, där säljteam stirrar på laddningsikoner och operationsfolk tvingas improvisera i kalkylblad. I en värld där 60 % av säljares tid redan går förlorad på icke-säljande uppgifter räknas varje millisekund.
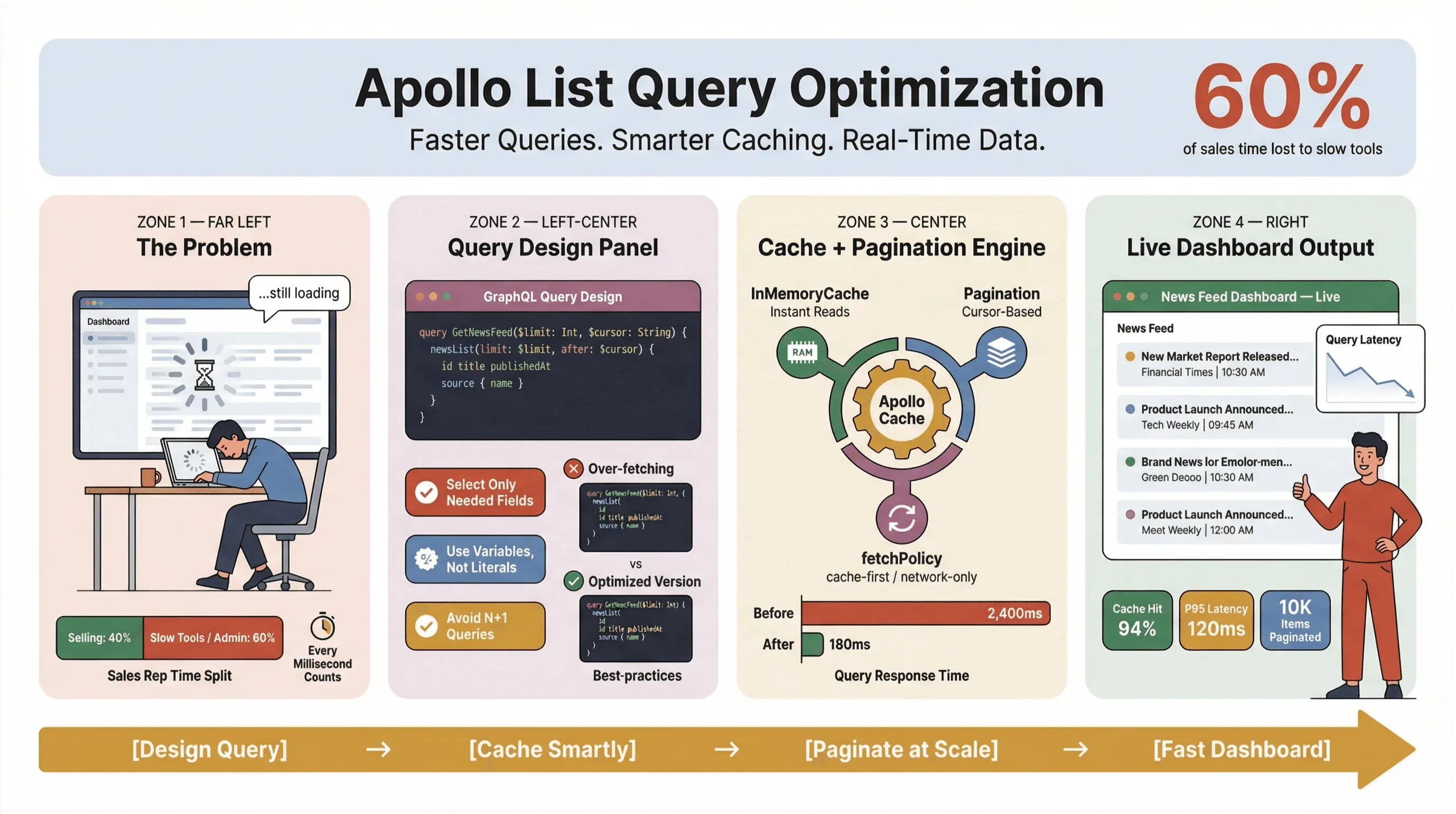
Så hur håller man Apollo Client-listeforespørseler snabba, stabila och konsekventa i stor skala — särskilt när du skrapar nyheter, följer leads eller driver affärskritiska dashboards? I den här guiden går jag igenom arbetssätten som faktiskt håller i produktion: frågedesign, cache, paginering och hur du kan koppla in no-code-verktyg som Thunderbit för att automatisera det tråkiga arbetet med nyhetsextraktion.
--- Oavsett om du är utvecklare, produktchef eller bara personen alla skyller på när dashboarden går långsamt, är det här din handbok för prestanda i Apollo GraphQL-listor.
Testa Thunderbit för automatiserad nyhetsextraktion
Varför optimera Apollo-listforespørslor? (apollo client list performance, optimize apollo list queries)
Låt oss vara ärliga: ingen vill vänta på att nyhetsrubriker eller säljleads ska laddas. I affärsmiljöer — särskilt de som bygger på automatiserad nyhetsextraktion eller realtidsdata — är långsamma Apollo-listeforespørseler inte bara störande; de kostar pengar, försenar beslut och skickar folk tillbaka till manuellt arbete. Återkommande forskning från Slack Workforce Lab visar gång på gång att kontorsarbetare lägger ungefär en tredjedel — och i nyare rapporter närmare 40 % — av sin dag på lågmälda, repetitiva uppgifter, ofta för att verktygen splittrar arbetet över långsamma gränssnitt.
Så här blir det när listeforespørseler inte är optimerade:
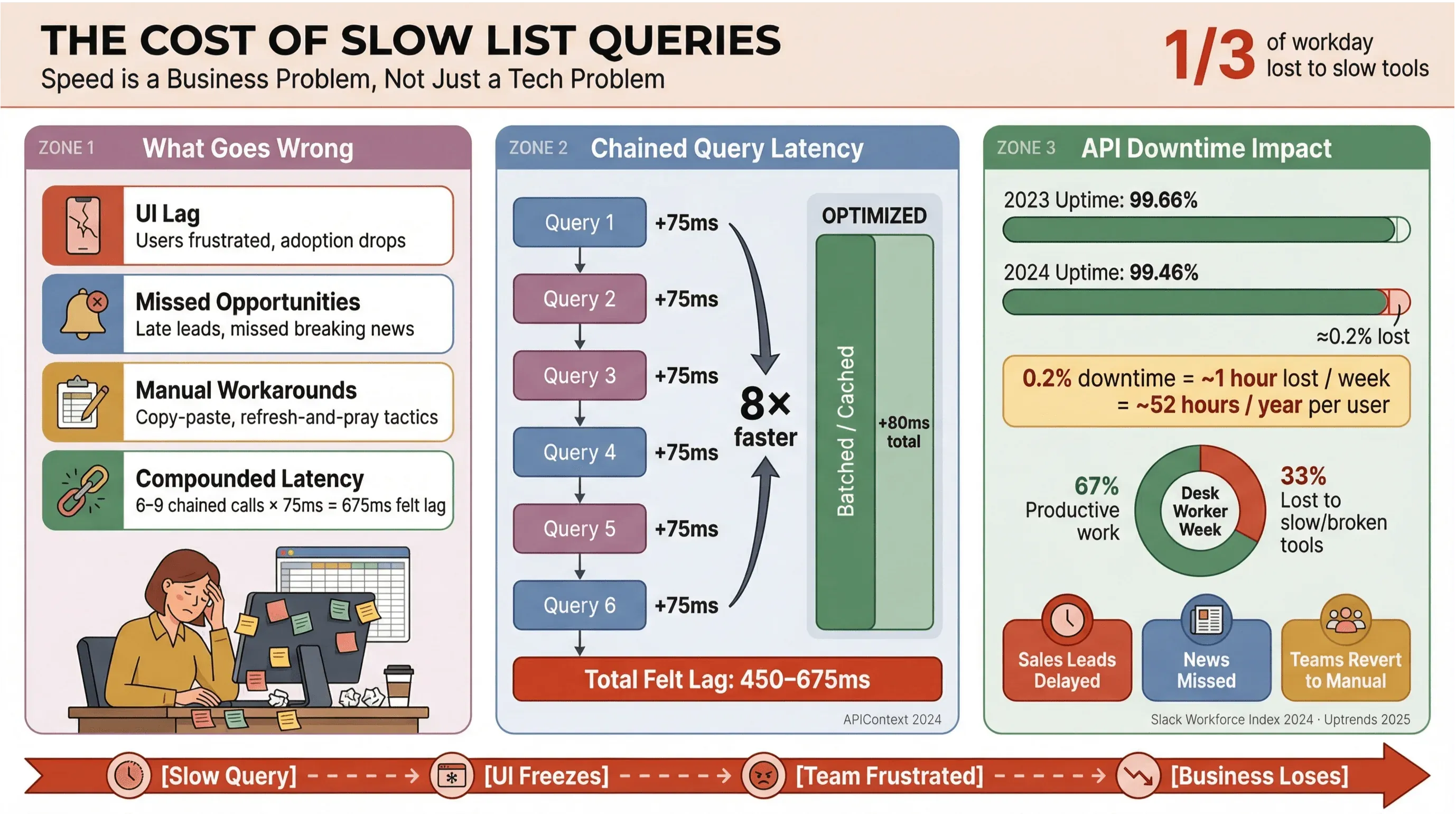
- Segt gränssnitt: Användare upplever fördröjningar, vilket skapar frustration och sämre användning.
- Missade möjligheter: Inom sälj eller nyhetsbevakning kan bara några sekunders fördröjning göra att du missar ett hett lead eller en nyhet.
- Manuella nödlösningar: Team går tillbaka till copy-paste, kalkylblad eller strategin “uppdatera och hoppas”.
- Hopad latens: Varje långsam API-anrop staplas på varandra — om ditt arbetsflöde triggar 6–9 beroende förfrågningar kan en modest fördröjning på 75 ms per anrop växa till en upplevd fördröjning på 450–675 ms (APIContext).
Och det handlar inte bara om hastighet. API-nedtid ökar, och den genomsnittliga upptiden har sjunkit från 99,66 % till 99,46 % på bara ett år — vilket innebär nästan en timmes förlorad produktivitet per vecka för appar med många listor. När din verksamhet bygger på nyhetsdata i realtid är det en risk du inte har råd med.
Välj rätt datastruktur och rätt fält (apollo graphql list best practices)
Ett av de vanligaste misstagen jag ser, och ja, jag har gjort det själv, är att behandla varje listeforespørsel som om den vore en detaljförfrågan. I GraphQL kan du hämta exakt det du behöver — så använd den möjligheten. Att hämta för mycket data är performance-fienden nummer ett, särskilt i verktyg för nyhetsinsamling och dashboards i realtid.
Anpassa fält för automatiserad nyhetsextraktion
Säg att du bygger ett nyhetsflöde. Behöver du verkligen hela artikeltexten, alla taggar, kommentarer och författarbios i din listeforespørsel? Troligen inte. Så här ser skillnaden ut:
Effektiv listeforespørsel:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Ineffektiv listeforespørsel (gör inte så här):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Den första förfrågan är slimmad och effektiv — perfekt för sortering, filtrering och radrendering. Den andra? En detaljförfrågan i förklädnad, som drar in enorma datamängder och bromsar allt (GraphQL spec, Apollo best practices).
Proffstips: Använd en tvåstegsmodell — hämta bara lättviktiga fält i listan och ladda tunga detaljer (som fulltext eller NLP-anrikning) först när användaren öppnar ett objekt eller för muspekaren över det.
Utnyttja Apollo Client-cache för snabbare förfrågningar (apollo client list performance)
Apollo Client-cache är den enskilt viktigaste hävstången för prestanda i listeforespørseler. När den är rätt konfigurerad kan den hjälpa dig att:
- Visa upprepade förfrågningar direkt utan nya nätverksanrop
- Minska serverbelastning och API-kostnader
- Skapa smidig navigering fram och tillbaka samt snabba filterbyten
Men cache är inte magi — det kräver lite konfiguration och disciplin.
Sätt effektiva cache-regler
Apollo stöder flera fetch policies:
| Policy | Vad den gör | Bäst för nyhetslistor |
|---|---|---|
| cache-first | Läser från cache, hämtar från nätverket om data saknas | Återbesökta listor, filterbyten, navigering fram och tillbaka |
| network-only | Hämtar alltid från nätverket | Manuell uppdatering, “senaste rubrikerna” |
| cache-and-network | Returnerar cache först och uppdaterar sedan med nätverksdata | Snabb första rendering + bakgrundsuppdatering (perfekt för nyhetsflöden) |
| no-cache | Hämtar alltid, lagrar aldrig i cache | Enstaka känsliga förfrågningar (sällsynt för listor) |
För nyhetsdata i realtid gillar jag cache-and-network — användaren får resultat direkt och datan uppdateras i bakgrunden. Var bara försiktig med att gränssnittet kan blinka till om objekten sorteras om vid uppdatering (GitHub issue).
Tips för cache-konfiguration:
- Använd stabila ID:n (
ideller_id) för normalisering (Apollo cache docs). - Finjustera cachestorlek och garbage collection för stora listor (memory management).
- Undvik att lagra stora, onormaliserade blobbar under
ROOT_QUERY— det kan få appen att sega ner (community report).
Implementera paginering och begränsa antal objekt (apollo graphql list best practices)
Om du laddar hundratals eller tusentals nyhetsartiklar eller säljleads på en gång ber du om problem. Paginering är inte bara en UX-funktion — det är en prestandanödvändighet.
Apollo stöder både offset-baserad och cursor-baserad paginering. Så här står de sig mot varandra:
| Typ av paginering | Fördelar | Nackdelar | Bäst för |
|---|---|---|---|
| Offset-baserad | Enkel, lätt att implementera | Kan hoppa över eller duplicera objekt om datan ändras | Oföränderliga eller små listor |
| Cursor-baserad | Stabil, hanterar datändringar bra | Lite mer komplex | Nyhetsflöden, stora listor |
För de flesta realtidslistor med nyheter eller leads är cursor-baserad paginering rätt väg att gå. Den håller datan konsekvent även när nya objekt tillkommer eller gamla raderas (GraphQL Foundation).
Tips för Apollo-paginering:
- Konfigurera
keyArgsför att styra cache-nycklar för paginerade fält (docs). - Implementera en
merge-funktion för att slå ihop sidor i cachen. - Använd
fetchMoreför att ladda fler sidor utan att skriva över tidigare resultat.
Praktiska pagineringsmönster för verktyg för nyhetskrapning
Ett typiskt användargränssnitt för nyhetsskrapning kommer att:
- Visa de senaste 20–50 rubrikerna (endast lättviktiga fält)
- Ladda mer vid scroll eller klick på “nästa sida”
- Hämta detaljer först när det behövs
Det håller gränssnittet snabbt, API:t lugnt och användarna effektiva.
Integrera Thunderbit för automatiserad nyhetsextraktion
Nu till den stora frågan: var kommer all den här strukturerade nyhetsdatan ifrån från början? Där kommer Thunderbit in i bilden.
Skaffa Thunderbit Chrome-tillägget Get Started Free
Thunderbit är ett no-code AI-webbskrapnings-tillägg för Chrome som kan extrahera nyhetsrubriker, URL:er, källor, författare, publiceringsdatum, sammanfattningar och bilder från i princip vilken webbplats som helst — helt utan kod. Jag har sett team använda Thunderbit för att automatisera hela nyhetsextraktionen och förvandla ostrukturerade webbsidor till ren, strukturerad data som kan matas direkt in i en databas eller GraphQL API.
Kombinera Thunderbit med Apollo för nyhetsdata i realtid
Här är ett arbetsflöde jag gillar för sälj- och driftteam som behöver uppdaterade nyheter:
- Extraktionslager: Använd Thunderbits News Scraper template för att hämta strukturerad nyhetsdata från utvalda webbplatser enligt ett schema.
- Lagringslager: Spara den insamlade datan i en databas som är optimerad för snabb åtkomst.
- GraphQL-lager: Exponera ett listfält
newsFeedoch ett detaljfältnewsArticle(id)via ditt API. - Klientlager: Använd Apollo Client för att hämta listan (slimmade fält, paginerad) och hämta detaljer först när det behövs.
Det här flödet “skrapa → lagra → fråga” gör att dina Apollo-frågor alltid arbetar med färsk, strukturerad data — utan manuellt copy-paste eller sköra skript.
Bonus: Thunderbit kan också berika dina listor med extra fält, som sentiment eller kategori, med hjälp av sina AI-drivna fältförslag, vilket gör ditt nyhetsflöde ännu smartare.
Steg-för-steg: Optimera Apollo-listforespørslor
Redo att sätta detta i praktiken? Här är min checklista för att optimera Apollo-listforespørslor:
-
Gör förfrågningarna smalare
- Begär bara de fält som behövs för att rendera listan (titel, URL, tidsstämpel osv.).
- Flytta tunga fält (fulltext, bilder, enrichment) till detaljförfrågningar.
-
Implementera paginering
- Använd cursor-baserad paginering för stora eller föränderliga listor.
- Konfigurera
keyArgsochmergeför korrekt cache-hantering.
-
Utnyttja Apollo-cachen
- Normalisera objekt med stabila ID:n.
- Välj rätt fetch policy (
cache-and-networkär utmärkt för nyheter). - Justera cachestorlek och garbage collection efter datamängd.
-
Koppla in automatiserad extraktion
- Använd Thunderbit för att automatisera nyhetsskrapning och hålla datan färsk.
- Exportera strukturerad data direkt till din databas eller kalkylblad.
-
Övervaka och felsök
- Använd Apollo Client Devtools för att inspektera förfrågningar, cache och prestanda.
- Håll koll på stora cache-skrivningar, för många bevakade förfrågningar och hackigt gränssnitt.
- Följ p95/p99-latens och felnivåer (New Relic, Uptrends).
Övervaka och felsök frågeprestanda
Apollo Devtools är ovärderliga här. Du kan:
- Inspektera aktiva förfrågningar och cache-status
- Hitta dubblettförfrågningar eller för många watchers
- Identifiera stora cache-objekt eller problem med normalisering
Om du ser segt gränssnitt eller långsamma uppdateringar, kontrollera:
- För stora listförfrågningar (slimma ner dem)
- Dålig cache-normalisering (fixa dina ID:n)
- Problem i pagineringssammanfogningen (granska
keyArgsochmerge)
Och glöm inte att mäta tail latency — inte bara genomsnitt. Det är där den verkliga användarfrustrationen gömmer sig.
Jämförelse mellan traditionell och AI-driven nyhetsskrapning
Låt oss vara ärliga: att skrapa nyhetsdata brukade innebära att skriva egna skript, hantera headless browsers och hoppas att webbplatsens layout inte ändrades över en natt. Nu, med AI-drivna verktyg som Thunderbit, kan du automatisera hela processen — ingen kod, inget drama.
| Tillvägagångssätt | Styrkor | Begränsningar för affärsanvändare |
|---|---|---|
| Skriptbaserad scraping | Fullt anpassningsbar, billig i stor skala | Kräver mycket underhåll och utvecklingstid |
| Hantterade scrapingplattformar | Snabb att komma igång, sköter anti-bot-hantering | Kräver fortfarande konfiguration, kostnader ökar med användning |
| AI-driven extraktion (Thunderbit) | Klarar stökiga layouter, ingen kod behövs | Utdatan behöver kvalitetssäkras, integreras med ditt schema |
| No-code visuella scrapers | Tillgängligt för icke-utvecklare | Kan gå sönder vid UI-ändringar, begränsad skala |
| Proxy-/unblocker-infrastruktur | Går runt blockeringar, stödjer hög genomströmning | Kräver fortfarande extraktionslogik, compliance-risker |
Juridisk notis: Det är i allmänhet lagligt att skrapa offentliga data, men respektera alltid användarvillkor och rate limits (Reuters).
Viktiga lärdomar för bästa praxis för Apollo GraphQL-listor
Här är kärnan i allt:
- Optimera för hastighet och tydlighet: Slimma listeforespørseler, använd paginering och cacha aggressivt.
- Struktur är viktigt: Hämta bara det du behöver — flytta tunga fält till detaljförfrågningar.
- Cachen är din vän: Använd Apollo-normalisering och fetch policies för att leverera data direkt.
- Automatisera extraktion: Verktyg som Thunderbit gör nyhetsskrapning och listberikning tillgängligt för alla.
- Övervaka och förbättra: Använd Devtools och observability-dashboards för att upptäcka flaskhalsar tidigt.
För sälj-, drift- och nyhetsteam betyder de här metoderna mindre väntan, mer agerande — och betydligt färre Slack-meddelanden om “varför går det här så långsamt?”.
Slutsats: Nästa steg för att optimera dina Apollo-listforespørslor
Om du fortfarande kör tunga, opaginerade eller cache-ovänliga listeforespørseler är det dags att granska och uppgradera. Börja enkelt: trimma fälten, lägg till paginering och finjustera cachen. Ta sedan nästa steg genom att integrera automatiserade extraktionsverktyg som Thunderbit för att hålla din data färsk och handlingsbar.
Vill du gå djupare? Kolla in Apollo-dokumentationen, Thunderbit Blog eller gå med i Apollo Community för verkliga tips och felsökning. Och om du är redo att automatisera din nyhetsextraktion, prova Thunderbits News Scraper template — det är en game changer för alla som behöver realtidsdata utan huvudvärk.
Använd Thunderbits News Scraper-template
Om du inte gör något annat efter att ha läst detta: trimma fälturvalet i dina listeforespørslor, lägg till cursor-baserad paginering och välj en rimlig fetch policy. Bara de tre förändringarna brukar räcka för att ta en listeforespørsel från märkbar fördröjning till i princip omärklig — och frigöra dig så att du kan fokusera på datan, inte laddningstillståndet.
Vanliga frågor
1. Varför blir Apollo-listforespørslor långsamma i dashboards för nyheter eller sälj?
Listeforespørslor kan bli långsamma om de hämtar för mycket data, saknar paginering eller inte cachelagras korrekt. I snabba arbetsflöden som nyhetsbevakning byggs även små fördröjningar på, vilket leder till segt gränssnitt och förlorad produktivitet.
2. Vad är bästa sättet att strukturera Apollo-listforespørslor för automatiserad nyhetsextraktion?
Begär bara de fält som behövs för att visa listan, till exempel titel, URL och tidsstämpel. Flytta tunga fält, som full artikeltext eller bilder, till detaljförfrågningar och använd paginering för att hålla payloaden liten och snabb.
3. Hur förbättrar Apollo Clients cache listprestanda?
Apollo-cachen lagrar tidigare hämtad data och gör att återkommande förfrågningar kan besvaras direkt. Rätt cache-normalisering och fetch policies, som cache-and-network, kan dramatiskt snabba upp listvyer och minska belastningen på servern.
4. Hur kan Thunderbit hjälpa till med nyhetsskrapning och Apollo-integration?
Thunderbit är en no-code AI-webbskrapare som extraherar strukturerad nyhetsdata från vilken webbplats som helst. Du kan använda den för att automatisera nyhetsextraktion och sedan föra in datan i din databas eller GraphQL API för användning i Apollo Client.
5. Vilka verktyg kan jag använda för att övervaka och felsöka prestandan i Apollo-listforespørslor?
Apollo Client Devtools låter dig inspektera förfrågningar, cache-status och prestanda i realtid. Kombinera detta med observability-dashboards som New Relic eller Uptrends för att följa latens och felnivåer, och förbättra din frågedesign steg för steg för bästa resultat.
Vill du ha fler tips om web scraping, automation och arbetsflöden för realtidsdata? Kolla in Thunderbit Blog för fördjupningar, guider och det senaste inom AI-driven produktivitet.
Testa Thunderbit AI-webbskrapare Get Started Free
Läs mer
- Så optimerar du Apollo-listor för effektiv leadhantering
- Apollo Data Enrichment: funktioner, fördelar och AI-boost
- Så bemästrar du Apollo Prospecting: en steg-för-steg-guide
- Så använder du paginering i webbskrapning för effektiv extraktion
- Så använder du paginering i webbskrapning för effektiv extraktion




