Det pågår en tyst revolution på kontor överallt – och den har varken med pingisbord eller kombucha på tapp att göra. Det handlar om enkel webbextrahering: att vem som helst, inte bara 개발자, kan plocka ut användbar data från webben på minuter i stället för dagar. Om du någon gång har suttit och stirrat på en webbplats och tänkt att du bara vill få ut alla namn, priser eller e‑postadresser och lägga dem i ett kalkylark, så är du verkligen inte ensam. Jag har snackat med säljare, marknadsförare och operativa team som säger exakt samma sak: ”Varför är det här fortfarande så krångligt?”
Sanningen är att efterfrågan på smidiga metoder för web scraping skjuter i höjden. Enligt använder 65 % av organisationer generativ AI i minst en affärsfunktion, och webbdataextrahering håller snabbt på att bli ett av de mest eftertraktade användningsområdena. Marknaden för web scraping väntas nå , och verksamhetsnära användare – särskilt de utan teknisk bakgrund – pushar hårt för verktyg som gör datauttag lika enkelt som att kopiera och klistra in. Men vad betyder ”enkel webbextrahering” egentligen, och hur kan du använda det för att förenkla ditt arbetsflöde? Låt oss reda ut det.
Enkel webbextrahering för icke-tekniska användare: noll kod, noll huvudvärk
Vi börjar med grunderna: Vad är ”enkel webbextrahering”? I praktiken handlar det om att förvandla webben – som ofta är rörig och ständigt förändras – till rena, strukturerade tabeller utan att skriva en enda rad kod. För verksamhetsanvändare utan teknisk bakgrund är det här en riktig game changer. Du slipper be IT om hjälp, du slipper brottas med Python-skript och du slipper ge upp när en webbplats plötsligt ändrar layout över en natt.
Varför är det här extra viktigt just nu? Webben är mer dynamisk än någonsin. Sajter kör oändlig scroll, popups och avancerad JavaScript som får traditionella skrapor att gå sönder hela tiden. Samtidigt har pressen på affärsteam att leverera insikter – snabbt – aldrig varit större. Inom säger 98 % av organisationerna att offentlig webbdata är avgörande eller mycket viktig för verksamheten, och mer än hälften använder den dagligen.
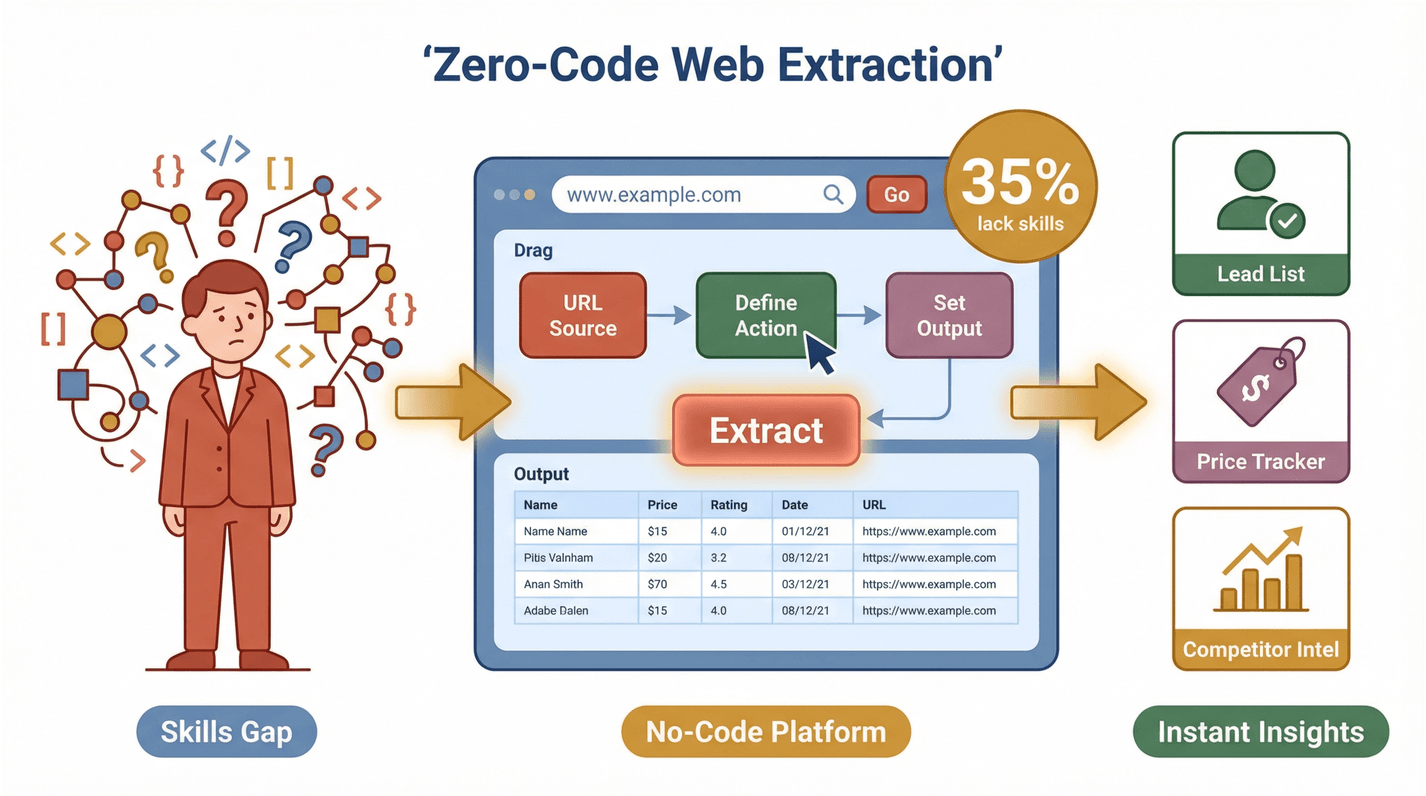
Men här kommer det viktiga: de flesta av de här teamen är inte tekniska. En färsk undersökning visade att 35 % av organisationerna saknar rätt kompetens för webbdataextrahering, och 33 % saknar rätt verktyg. Det är en enorm möjlighet för no‑code-lösningar. När fler kan hämta och använda webbdata öppnas en ny nivå av produktivitet – oavsett om du bygger en leadlista, bevakar konkurrenter eller följer priser.
No-code/low-code-vågen: därför spelar den roll
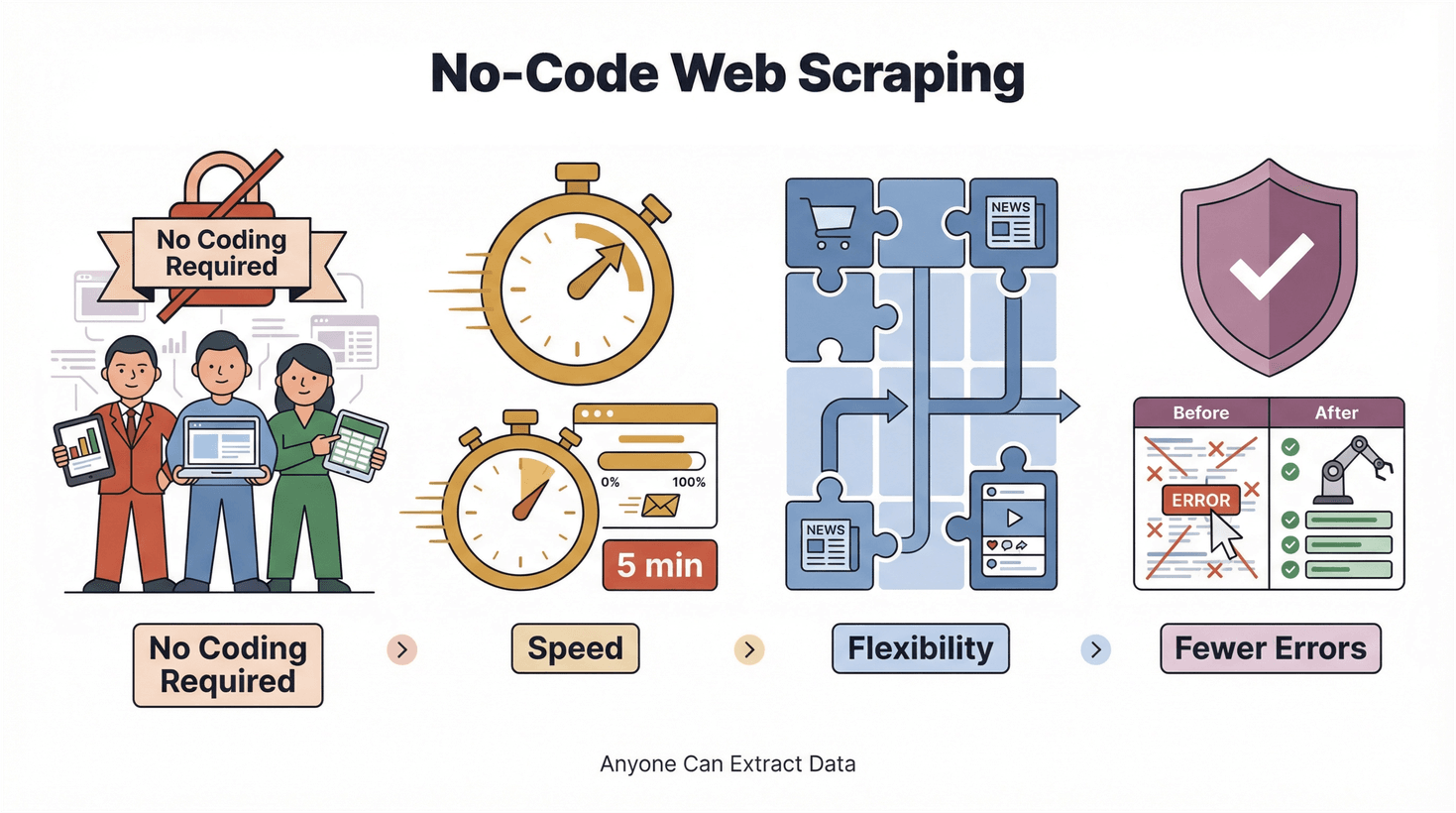
Framväxten av no‑code och low‑code handlar om att göra teknik tillgänglig för fler. Det är inte bara ett buzzword från Silicon Valley – det är en verklig förändring i hur arbete utförs. För web scraping innebär det:
- Ingen kod behövs: Alla kan extrahera data, inte bara ingenjörer.
- Hastighet: Resultat på minuter, inte dagar.
- Flexibilitet: Anpassa dig direkt till nya sajter och nya databehov.
- Färre fel: Automatisering minskar risken för copy‑paste-missar.
Och det bästa? Du behöver inte bli någon teknikguru för att hänga med.
Varför traditionella web scraping-verktyg är så frustrerande
Om vi ska vara ärliga: klassiska web scraping-verktyg känns ofta byggda av och för 개발자 – inte för verksamhetsanvändare. Jag har sett det på nära håll: team blir peppade på ett nytt projekt, men kör fast när verktyget börjar prata om CSS-selektorer, XPath eller reguljära uttryck. Då kommer de tomma blickarna och mejlen om ”kanske nästa kvartal”.
Det här är det som brukar gå snett:
- Kod krävs: Många äldre verktyg förväntar sig att du skriver skript eller konfigurerar komplexa mallar.
- Jobbig uppstart: Du måste mappa varje fält, hantera inloggningsflöden och sätta upp proxies för att inte bli blockerad.
- Skör logik: Webbplatser ändrar layout och plötsligt slutar skrapan fungera. Nu felsöker du kod i stället för att göra ditt jobb.
- Tungt underhåll: Varje gång en sajt uppdateras börjar du om.
Inte konstigt att visar att de största tekniska utmaningarna är blockering/ban av IP-adresser (56 %), dynamiskt innehåll (55 %) och CAPTCHAs (52 %). Även avancerade team har svårt att hänga med.
Samtidigt vill verksamhetsanvändare bara ha ett enkelt och pålitligt sätt att få in data i kalkylark eller CRM. Det är där enkel webbextrahering och smidiga metoder för web scraping kommer in.
Så gör Thunderbit enkel webbextrahering möjlig
Här blir det extra intressant – för det här är exakt problemet vi ville lösa på . Vårt mål är att göra web scraping så enkelt att vem som helst kan använda det, oavsett teknisk bakgrund.
Thunderbit är ett som gör webbextrahering till en process på två klick. Så här funkar det:
- Beskriv vad du vill ha: Skriv med vanligt språk vilken data du behöver. Till exempel: ”Extrahera alla produktnamn och priser från den här sidan.”
- Klicka på ”AI Suggest Fields”: Thunderbits AI läser sidan och föreslår de bästa kolumnerna att hämta – som ”Namn”, ”Pris”, ”E‑post” eller ”Bild”.
- Klicka på ”Scrape”: Thunderbit sköter resten – sidindelning, undersidor och även inloggat innehåll vid behov.
Klart. Ingen kod, inga mallar, ingen krånglig uppstart. Gränssnittet är byggt för verksamhetsroller – sälj, marknad, e‑handel, fastigheter – som vill ha resultat direkt.
Thunderbits AI-drivna arbetsflöde: smartare, inte svårare
Det verkliga tricket är AI:n. Thunderbit chansar inte bara – den läser sidan, fattar kontexten och strukturerar datan automatiskt. Vill du gå ett steg längre kan du lägga till egna instruktioner per fält (t.ex. ”kategorisera den här kolumnen” eller ”översätt till engelska”), men de flesta klickar bara och kör.
Det AI-drivna upplägget ger:
- Färre fel: AI:n anpassar sig till olika layouter, så du får jämna resultat även när sajter ändras.
- Snabbare start: Du slipper bygga mallar eller skriva skript.
- Mer användbar data: Thunderbit kan märka upp, kategorisera och till och med berika data medan den skrapar.
Vill du nörda ner dig kan du läsa eller vårt . Du kan också hitta fler guider på , som och .
Thunderbits unika funktioner för smidiga metoder för web scraping
Det som skiljer Thunderbit från mängden är inte bara AI:n – utan hela arbetsflödet, byggt för verkliga affärsbehov. Här är några funktioner som användare uppskattar:
- Automatisk sidhantering: Thunderbit klarar flersidiga listor och oändlig scroll utan konfiguration.
- Skrapning av undersidor: Behöver du mer detaljer? Thunderbit kan besöka varje undersida (t.ex. produktdetaljer eller LinkedIn-profiler) och berika datasetet automatiskt.
- Export vart du vill: Skicka data direkt till Excel, Google Sheets, Airtable, Notion eller ladda ner som CSV/JSON. Inga fler copy‑paste-maraton.
- Fungerar på inloggade sidor: Skrapa data från sajter som kräver inloggning – Thunderbit kör i din webbläsare och ser det du ser.
- AI-baserad märkning och kategorisering: Lägg till instruktioner för att klassificera, tagga eller översätta data när du hämtar den.
- Schemalagd skrapning: Skapa återkommande jobb för att hålla datan uppdaterad – perfekt för prisbevakning eller lead-uppföljning.
Och ja, allt detta finns i ett verktyg som används av över .
Automatisk sidindelning och extrahering från undersidor
En av de största huvudvärkarna med web scraping är att hantera paginerade listor eller inbäddade detaljsidor. Med Thunderbit behöver du inte ens tänka på det. AI:n upptäcker sidindelning (oavsett om det är en ”Nästa”-knapp eller oändlig scroll) och följer länkar till undersidor automatiskt. Det betyder att du kan hämta hundratals eller tusentals poster i ett svep – utan manuell klickning.
Till exempel: om du skrapar en produktlista på Amazon kan Thunderbit hämta alla produkter över flera sidor och sedan gå in på varje produktsida för att plocka recensioner, betyg eller säljarinfo. Som en outtröttlig assistent som aldrig blir trött.
Export i flera format och CRM-koppling
Data är bara värdefull om du faktiskt kan använda den. Thunderbit låter dig exportera i det format teamet behöver – Excel, Google Sheets, Airtable, Notion eller CSV/JSON. Du kan även skicka data direkt till ditt CRM eller andra arbetsflödesverktyg, så att sälj och drift alltid har den senaste informationen.
Den här direkta kopplingen sparar massor av tid. Inget mer städande av röriga exporter eller omformatering av kolumner – Thunderbits AI tar hand om det.
Verkliga användningsfall för enkel webbextrahering
Var gör enkel webbextrahering störst skillnad? Här är några scenarier jag sett från Thunderbit-användare:
Lead-uttag för sälj
Säljteam lever på sina leadlistor. Med Thunderbit kan du skrapa kontaktuppgifter från LinkedIn, Google Maps eller företagskataloger på några minuter. Öppna sidan, klicka på ”AI Suggest Fields” och låt Thunderbit hämta namn, e‑post, telefonnummer och företagsdetaljer till ett kalkylark som är redo att användas.
En säljchef berättade att de tidigare lade timmar varje vecka på att kopiera och klistra in leads. Nu bygger de riktade listor på en bråkdel av tiden – och teamet kan fokusera på outreach i stället för datainmatning.
E‑handel och marknadsbevakning
E‑handelsteam använder Thunderbit för att följa konkurrenters SKU:er, priser och recensioner på Amazon, Shopify och andra plattformar. Vill du bevaka prisändringar eller nya produktlanseringar? Sätt upp en schemalagd skrapning och få färsk data levererad till ditt Google Sheet varje morgon.
Thunderbits skrapning av undersidor är extra användbar här – du kan hämta produktdetaljer, bilder och till och med kundrecensioner utan att lyfta ett finger.
Insamling av fastighetsdata
Fastighetsproffs använder Thunderbit för att samla in objektlistor, priser och mäklarinfo från sajter som Zillow eller Realtor.com. AI:n hanterar sidindelning och undersidor, så du får en komplett och uppdaterad marknadsbild – perfekt för analys eller kundrapporter.
En analytiker inom fastigheter delade att det som tidigare tog en hel eftermiddag nu tar några klick. Det är kraften i smidiga metoder för web scraping.
Jämförelse: traditionella vs. smidiga metoder för web scraping
Låt oss sammanfatta med en jämförelse sida vid sida:
| Funktion | Traditionella skrapor | Enkel webbextrahering (Thunderbit) |
|---|---|---|
| Kod krävs | Ja (skript, selektorer) | Nej (AI + naturligt språk) |
| Starttid | Hög (mallar, konfig) | Låg (2 klick) |
| Underhåll | Ofta (går sönder när sajter ändras) | Minimalt (AI anpassar sig) |
| Hanterar sidindelning | Manuell konfiguration | Automatiskt |
| Extrahering från undersidor | Komplex logik | 1 klick |
| Exportformat | Ofta begränsat | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Fungerar på inloggade sidor | Ibland (med konfig) | Ja (webbläsarbaserat) |
| Datamärkning/kategorisering | Manuell efterbearbetning | AI-baserat, inbyggt |
| Schemaläggning/övervakning | Ibland (avancerat) | Ja (enkel uppsättning) |
Skillnaden är enorm. Med Thunderbit kan vem som helst hämta, strukturera och använda webbdata – utan tekniska förkunskaper.
Framtidstrender inom enkel webbextrahering och smidiga metoder för web scraping
Framåt ser det riktigt lovande ut för enkel webbextrahering. AI blir bara smartare, och efterfrågan på no‑code-verktyg växer snabbt. Enligt använder 78 % av organisationer AI i minst en funktion, och agentiska system – AI-verktyg som kan hantera webbarbetsflöden i flera steg – blir allt vanligare.
Vad betyder det för verksamhetsanvändare? Mer kraft, mindre krångel. När AI fortsätter att utvecklas kommer vi att se:
- Än smartare fältigenkänning: AI kommer att förstå mer komplex data och relationer.
- Bättre integrationer: Direktkopplingar till fler affärsverktyg och plattformar.
- Högre tillförlitlighet: Mindre som går sönder och jämnare resultat, även på dynamiska eller skyddade sajter.
- Ökad tillgänglighet: Webbextrahering blir en standardfärdighet för alla, inte bara tekniker.
Och ja – Thunderbit ligger i framkant av den här utvecklingen.
Slutsats och viktigaste insikterna
Webben är världens största databas – men fram till nyligen var det mest 개발자 som kunde utnyttja den. Det förändras snabbt. Med enkel webbextrahering och smidiga metoder för web scraping kan vem som helst förvandla webbplatser till användbar data på några minuter.
Det här är det viktigaste att ta med sig:
- No‑code webbextrahering är här för att stanna: Verktyg som Thunderbit gör det möjligt för alla att samla in och använda webbdata – utan tekniska kunskaper.
- AI är nyckeln: Genom att automatisera fältval, sidindelning, undersidor och datamärkning sparar AI-baserade skrapor tid och minskar fel.
- Affärsnyttan är tydlig: Team inom sälj, e‑handel och fastigheter ser redan högre produktivitet, färskare data och bättre beslut.
- Framtiden är ännu ljusare: När AI och no‑code utvecklas blir webbdataextrahering lika vardagligt som att skicka ett mejl.
Om du är trött på manuell copy‑paste, frustrerad över skrapor som går sönder eller bara nyfiken på vad som är möjligt – testa . Du kan och börja extrahera data gratis – ingen setup, ingen kod, inget krångel.
Vill du fördjupa dig ytterligare kan du besöka för fler guider, tips och exempel från verkligheten.
Vanliga frågor (FAQ)
1. Vad är ”enkel webbextrahering” och vem passar det för?
Enkel webbextrahering syftar på no‑code, AI-drivna metoder för web scraping som gör att vem som helst – särskilt verksamhetsanvändare utan teknisk bakgrund – snabbt och enkelt kan hämta strukturerad data från webbplatser. Det passar utmärkt för team inom sälj, marknad, e‑handel och operations som behöver användbar data utan tekniskt strul.
2. Hur skiljer sig Thunderbit från traditionella web scraping-verktyg?
Thunderbit använder AI för att automatisera fältval, sidindelning och extrahering från undersidor. Till skillnad från traditionella skrapor som kräver kod eller komplexa mallar kan du i Thunderbit beskriva behovet med vanligt språk och hämta data med bara två klick.
3. Klarar Thunderbit dynamiska eller flersidiga webbplatser?
Ja. Thunderbit upptäcker och hanterar automatiskt sidindelning (inklusive oändlig scroll) och kan följa länkar till undersidor för djupare datauttag – med minimal uppsättning.
4. Vilka exportalternativ stödjer Thunderbit?
Thunderbit låter dig exportera data direkt till Excel, Google Sheets, Airtable, Notion, CSV eller JSON. Du kan också integrera med CRM och andra arbetsflödesverktyg för smidiga processer.
5. Är det säkert och etiskt att använda verktyg för enkel webbextrahering som Thunderbit?
Thunderbit uppmuntrar ansvarsfull och etisk web scraping. Respektera alltid webbplatsers användarvillkor, undvik att skrapa personuppgifter utan samtycke och använd hastighetsbegränsning för att inte störa tjänsten. För mer om bästa praxis, se .
Redo att låsa upp kraften i webbdata? Testa Thunderbit idag och se hur enkel webbextrahering kan förändra ditt arbetsflöde.
Läs mer