
Webben är proppfull av värdefull data – men det mesta är inte byggt för att bara laddas ner. År 2025 har webbskrapning gått från att vara en nördig specialgrej till ett måste för team som bevakar priser, jobb, bostäder och konkurrenter. Utmaningen? När du börjar med webbskrapning github märker du snabbt att GitHub svämmar över av skrapningsprojekt. Vissa är riktigt välgjorda, andra är rena mardrömmen, och många har inte rörts på flera år. Så hur väljer du rätt – särskilt om du inte är utvecklare?
I den här guiden går jag igenom de 15 bästa webbskrapningsprojekten på GitHub för 2025. Men jag nöjer mig inte med en enkel lista – jag jämför dem utifrån hur krånglig installationen är, vilka användningsfall de passar, stöd för dynamiskt innehåll, hur väl de underhålls, exportmöjligheter och vem de faktiskt är byggda för. Och om du är less på att bråka med kod visar jag varför no-code och AI-drivna verktyg som håller på att rita om kartan för både affärsanvändare och icke-tekniska team.
Så valde vi ut de 15 bästa webbskrapningsprojekten på GitHub
Vi kan lika gärna säga det rakt ut: alla github-projekt är inte skapade lika. Vissa är testade av tusentals användare, andra är helgbyggen som aldrig tog sig längre än “funkar på min dator”. För den här listan fokuserade jag på projekt som klarar följande:
- GitHub-stjärnor & community: Projekt med tydlig användning (från några tusen till 90k+ stjärnor) och aktiva bidragsgivare.
- Nylig aktivitet: Verktyg som faktiskt uppdateras 2025 – inte digitala fossil.
- Dokumentation & användbarhet: Tydliga guider, exempel och en rimlig inlärningskurva.
- Verklig användning: Används i riktiga affärs- eller forskningscase, inte bara “hello world”-demos.
Och eftersom webbskrapning inte är one-size-fits-all jämför jag varje projekt på:
- Installations- & uppstartskomplexitet: Kommer du igång på minuter, eller fastnar du i drivrutiner och beroenden?
- Passar användningsfallet: Är det byggt för e-handel, nyheter, forskning eller något annat?
- Stöd för dynamiska webbsidor: Klarar det moderna, JavaScript-tunga sajter?
- Projektets hälsa: Underhålls det aktivt, eller är senaste commit så gammal att den kan rösta?
- Export av data: Får du data som går att använda direkt, eller bara rå HTML?
- Målgrupp: Är det för Python-nybörjare, data engineers eller icke-tekniska team?
Varje projekt får en snabbtagg för dessa kriterier, så att du snabbt kan hitta det som passar – oavsett om du är kodninja eller bara vill ha datan i ett Google Sheet.

Installations- & uppstartskomplexitet: Hur snabbt kan du börja skrapa?
Om vi ska vara helt ärliga: den största tröskeln för de flesta är att ens få en skrapare att rulla. Så här delar jag in uppstartskomplexiteten:
- Plug & Play (ingen konfiguration): Installera och kör. Minimal setup, perfekt för nybörjare.
- Mellan (kommandorad, lite kod): Kräver viss kodning eller CLI, men är ändå hanterbart om du skrivit script tidigare.
- Avancerat (drivrutiner, anti-bot, djup kodning): Kräver miljösetup, webbläsardrivrutiner eller rejäla Python/JS-kunskaper.
Så här placerar sig toppprojekten:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (för slutanvändare efter driftsättning)
- Mellan: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Avancerat: Heritrix, Apache Nutch (båda kräver Java, konfigfiler eller big data-stackar)
Om du inte är utvecklare är “Plug & Play” eller no-code-alternativ dina bästa vänner. För alla andra betyder “Mellan” att du behöver skriva lite kod, men inget som borde ge panik – om du inte är allergisk mot klammerparenteser.
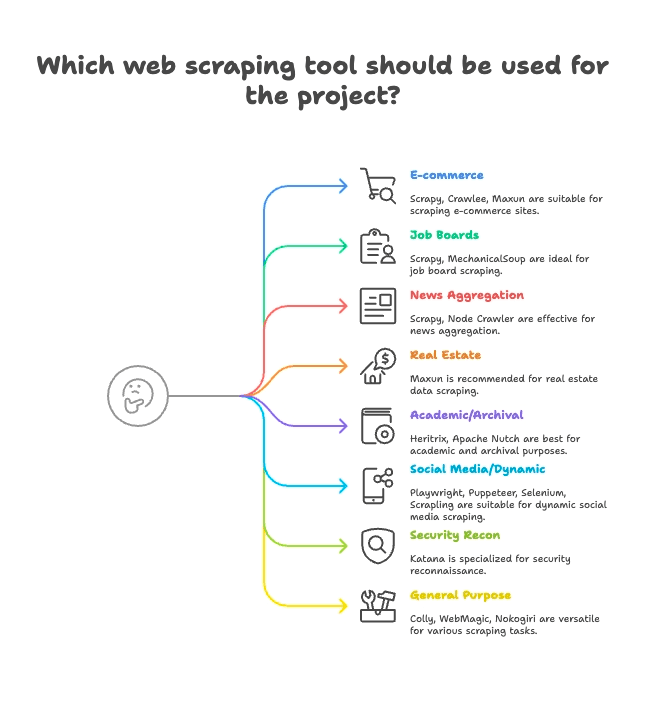
Grupperat efter användningsfall: Hitta rätt skrapare för din bransch
Alla skrapare är inte byggda för samma typ av jobb. Så här grupperar jag de 15 bästa efter vad de passar bäst för:
E-handel & prisbevakning
- Scrapy: Storskalig skrapning av produkter över många sidor
- Crawlee: Flexibel, funkar för både statiska och dynamiska e-handelssajter
- Maxun: No-code, perfekt för snabba utdrag av produktlistor
Jobbportaler & rekrytering
- Scrapy: Hanterar paginering och strukturerade listningar
- MechanicalSoup: Bra för jobbportaler bakom inloggning
Nyheter & innehållsaggregering
- Scrapy: Byggt för att crawla nyhetssajter i stor skala
- Node Crawler: Snabbt för statisk nyhetsaggregering
Bostäder & fastigheter
- Thunderbit: AI-driven skrapning av undersidor för listningar + detaljsidor
- Maxun: Visuell markering för fastighetsdata
Akademisk forskning & webbarkivering
- Heritrix: Arkivering av hela sajter (WARC-filer)
- Apache Nutch: Distribuerad crawling för forskningsdataset
Sociala medier & dynamiskt innehåll
- Playwright, Puppeteer, Selenium: Skrapa dynamiska flöden, simulera inloggningar
- Scrapling: “Stealth”-skrapning för sajter med anti-bot-skydd
Säkerhet & rekognosering
- Katana: Snabb URL-upptäckt och säkerhetscrawling
Allmänt / multipurpose
- Colly: Högpresterande Go-skrapning för valfri sajt
- WebMagic: Java-baserat och flexibelt för många domäner
- Nokogiri: Ruby-parsning för egna script
Stöd för dynamiska webbsidor: Klarar GitHub-projekten moderna sajter?
Moderna webbplatser älskar JavaScript. React, Vue, infinite scroll, AJAX – om du någon gång försökt skrapa en sida och fått ett stort, fett “ingenting” vet du exakt hur irriterande det kan vara.
Så här hanterar projekten dynamiskt innehåll:
- Fullt JS-stöd (headless browser):
- Selenium: Styr riktiga webbläsare och kör all JS
- Playwright: Flera webbläsare, flera språk, robust JS-stöd
- Puppeteer: Headless Chrome/Firefox med full JS-rendering
- Crawlee: Växlar mellan HTTP och webbläsare (via Puppeteer/Playwright)
- Katana: Valfritt headless-läge för JS-tolkning
- Scrapling: Integrerar Playwright för “stealth” JS-skrapning
- Maxun: Använder webbläsare under huven för dynamiskt innehåll
- Inget inbyggt JS-stöd (endast statisk HTML):
- Scrapy: Behöver Selenium/Playwright-plugin för JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Hämtar bara HTML och klarar inte JS direkt
Här sticker Thunderbits AI ut: den identifierar och skrapar dynamiskt innehåll automatiskt – ingen manuell setup, inga plugins, inget strul med selektorer. Klicka bara på “AI Suggest Fields” och låt verktyget göra jobbet, även på React-tunga sajter. Vill du förstå mer om hur det funkar, se .
Projektstatus & tillförlitlighet: Fungerar skraparen även nästa år?
Det finns få saker som är mer frustrerande än att bygga ett arbetsflöde runt ett verktyg och sen inse att det är övergivet. Så här står sig toppprojekten:
- Aktivt underhållna (täta uppdateringar):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Stabila men långsammare uppdateringar:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Underhållsläge (specialiserat, långsamt):
- Heritrix:
- Apache Nutch:
Thunderbit är en hanterad tjänst, så du behöver aldrig ligga sömnlös över övergiven kod. Vårt team håller AI, mallar och integrationer uppdaterade – och du får onboarding, guider och support om du kör fast.
Datahantering & export: Från rå HTML till data som går att använda
Att hämta data är bara halva grejen. Du behöver den i ett format som teamet faktiskt kan jobba med – CSV, Excel, Google Sheets, Airtable, Notion eller till och med ett live-API.
- Inbyggd strukturerad export:
- Scrapy: CSV-, JSON- och XML-export
- Crawlee: Flexibla dataset och lagring
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- Manuell datahantering (användardefinierat):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Du skriver kod för att spara/exportera
- Specialiserad export:
- Heritrix: WARC (webbarkivfiler)
- Apache Nutch: Rått innehåll till lagring/index
Thunderbits strukturerade export och integrationer sparar massor av tid för affärsanvändare. Inget mer CSV-trixande eller “glue code” – klicka och datan är redo.
Målgrupp: Vem bör använda vilket GitHub-projekt?
Alla verktyg passar inte alla. Här är vem jag skulle rekommendera för respektive:
- Python-nybörjare: MechanicalSoup, Scrapling (om du vill testa något mer avancerat)
- Data engineers: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA & automationsproffs: Selenium, Playwright, Puppeteer
- Säkerhetsforskare: Katana
- Ruby-utvecklare: Nokogiri
- Java-utvecklare: WebMagic, Heritrix, Apache Nutch
- Icke-tekniska användare / affärsteam: Maxun, Thunderbit
- Growth hackers, analytiker: Maxun, Thunderbit
Om du inte är bekväm med kod, eller bara vill ha resultat snabbt, är Thunderbit och Maxun de mest raka valen. För alla andra: välj verktyget som matchar ditt språk och ditt användningsfall.
Topp 15 webbskrapningsprojekt på GitHub: Detaljerad jämförelse
Nu går vi igenom varje projekt, grupperat efter användningsfall, med snabbtaggar och höjdpunkter.
E-handel, prisbevakning och generell crawling
— 57.1k stjärnor, uppdatering juni 2025

- Sammanfattning: Asynkront Python-ramverk på hög nivå för storskalig crawling och skrapning.
- Setup: Mellan (Python-kod, async-ramverk)
- Användningsfall: E-handel, nyheter, forskning, flersidiga “spiders”
- JS-stöd: Nej (kräver Selenium/Playwright-plugin)
- Projektstatus: Aktivt underhållet
- Dataexport: CSV, JSON, XML inbyggt
- Målgrupp: Utvecklare, data engineers
- Höjdpunkter: Skalar bra, robust, massor av plugins. Brant inlärningskurva för nybörjare.
— 17.9k stjärnor, 2025

- Sammanfattning: Fullmatat Node.js-bibliotek för både statisk och dynamisk webbskrapning.
- Setup: Mellan (Node/TS-kod)
- Användningsfall: E-handel, sociala medier, automation
- JS-stöd: Ja (integration med Puppeteer/Playwright)
- Projektstatus: Mycket aktivt
- Dataexport: Flexibelt (dataset, lagring)
- Målgrupp: Utvecklingsteam i JS/TS
- Höjdpunkter: Verktyg mot blockering, enkelt att växla mellan HTTP- och webbläsarläge.
— 13k stjärnor, juni 2025

- Sammanfattning: Open source no-code-plattform för datautvinning från webben med visuellt gränssnitt.
- Setup: Mellan (serverdrift), Enkel (för slutanvändare)
- Användningsfall: Allmänt, e-handel, affärsskrapning
- JS-stöd: Ja (webbläsare under huven)
- Projektstatus: Aktivt och växande
- Dataexport: CSV, Excel, Google Sheets, JSON API
- Målgrupp: Icke-tekniska användare, analytiker, team
- Höjdpunkter: Peka-och-klicka-skrapning, navigering i flera nivåer, kan self-hostas.
Jobbportaler, rekrytering och enkla interaktioner
— 4.8k stjärnor, 2024

- Sammanfattning: Python-bibliotek för att automatisera formulär och enkel navigering.
- Setup: Plug & Play (Python, minimal kod)
- Användningsfall: Jobbportaler bakom inloggning, statiska sajter
- JS-stöd: Nej
- Projektstatus: Moget, lätt underhållet
- Dataexport: Ingen inbyggd (manuellt)
- Målgrupp: Python-nybörjare, snabba script
- Höjdpunkter: Simulerar webbläsarsessioner med några rader kod. Inte för dynamiska sajter.
Nyhetsaggregering & statiskt innehåll
— 6.8k stjärnor, 2024

- Sammanfattning: Snabb, parallell server-side crawler med Cheerio-parsning.
- Setup: Mellan (Node callbacks/async)
- Användningsfall: Nyheter, snabb statisk skrapning
- JS-stöd: Nej (endast HTML)
- Projektstatus: Medelaktivt (v2 beta)
- Dataexport: Ingen inbyggd (användardefinierat)
- Målgrupp: Node.js-utvecklare, behov av hög samtidighet
- Höjdpunkter: Asynkron crawling, rate limiting, välbekant jQuery-lik API.
Fastigheter, listningar och skrapning av undersidor

- Sammanfattning: AI-drivet no-code Web Scraper för affärsanvändare.
- Setup: Plug & Play (Chrome-tillägg, setup med 2 klick)
- Användningsfall: Fastigheter, e-handel, sälj, marknadsföring, valfri webbplats
- JS-stöd: Ja (AI upptäcker dynamiskt innehåll automatiskt)
- Projektstatus: Uppdateras kontinuerligt, hanterad tjänst
- Dataexport: Ett klick till Sheets, Airtable, Notion, CSV, JSON
- Målgrupp: Icke-tekniska användare, affärsteam, sälj, marknadsföring
- Höjdpunkter: AI “Suggest Fields”, skrapning av undersidor, direkt export, onboarding, mallar, .
Akademisk forskning & webbarkivering
— 3k stjärnor, 2023

- Sammanfattning: Internet Archives arkiveringscrawler i webbskala.
- Setup: Avancerat (Java-app, konfigfiler)
- Användningsfall: Webbarkivering, domänomfattande crawls
- JS-stöd: Nej (hämtar bara)
- Projektstatus: Underhållet (långsamt men stabilt)
- Dataexport: WARC (webbarkivfiler)
- Målgrupp: Arkiv, bibliotek, institutioner
- Höjdpunkter: Skalar bra, robust, standardkompatibelt. Inte för riktad skrapning.
— 3k stjärnor, 2024

- Sammanfattning: Open source-crawler för big data och sökmotorer.
- Setup: Avancerat (Java + Hadoop för skala)
- Användningsfall: Sökmotorcrawling, big data
- JS-stöd: Nej (endast HTTP)
- Projektstatus: Aktivt (Apache)
- Dataexport: Rått innehåll till lagring/index
- Målgrupp: Företag, big data, akademisk forskning
- Höjdpunkter: Plugin-arkitektur, distribuerad crawling.
Sociala medier, dynamiskt innehåll och automation
— ~30k stjärnor, 2025

- Sammanfattning: Webbläsarautomation för skrapning och testning, stöd för alla stora webbläsare.
- Setup: Mellan (drivrutiner, flera språk)
- Användningsfall: JS-tunga sajter, testflöden, sociala medier
- JS-stöd: Ja (full webbläsarautomation)
- Projektstatus: Aktivt, moget
- Dataexport: Ingen (manuellt)
- Målgrupp: QA-ingenjörer, utvecklare
- Höjdpunkter: Flera språk, simulerar verkligt användarbeteende.
— 73.5k stjärnor, 2025

- Sammanfattning: Modern webbläsarautomation för skrapning och E2E-testning.
- Setup: Mellan (script i flera språk)
- Användningsfall: Moderna webbappar, sociala medier, automation
- JS-stöd: Ja (headless eller riktig webbläsare)
- Projektstatus: Mycket aktivt
- Dataexport: Ingen (hanteras av användaren)
- Målgrupp: Utvecklare som behöver robust webbläsarkontroll
- Höjdpunkter: Cross-browser, auto-wait, nätverksinterception.
— 90.9k stjärnor, 2025

- Sammanfattning: API på hög nivå för automation i Chrome/Firefox.
- Setup: Mellan (Node-script)
- Användningsfall: Headless Chrome-skrapning, dynamiskt innehåll
- JS-stöd: Ja (Chrome/Firefox)
- Projektstatus: Aktivt (Chrome-teamet)
- Dataexport: Ingen (byggs i kod)
- Målgrupp: Node.js-utvecklare, front-end-proffs
- Höjdpunkter: Djup webbläsarkontroll, skärmdumpar, PDF, nätverksinterception.
— 5.4k stjärnor, juni 2025

- Sammanfattning: “Stealth”-inriktad, högpresterande skrapning med anti-bot-funktioner.
- Setup: Mellan (Python-kod)
- Användningsfall: Stealth-skrapning, anti-bot, dynamiska sajter
- JS-stöd: Ja (Playwright-integration)
- Projektstatus: Aktivt, i framkant
- Dataexport: Ingen inbyggd (manuellt)
- Målgrupp: Python-utvecklare, hackers, data engineers
- Höjdpunkter: Stealth, proxy, anti-blockering, async.
Säkerhetsrekognosering
— 13.8k stjärnor, 2025

- Sammanfattning: Snabb webbcrawler för säkerhet, automation och länkupptäckt.
- Setup: Mellan (CLI-verktyg eller Go-bibliotek)
- Användningsfall: Säkerhetscrawling, upptäckt av endpoints
- JS-stöd: Ja (headless-läge valfritt)
- Projektstatus: Aktivt (ProjectDiscovery)
- Dataexport: Textutdata (URL-listor)
- Målgrupp: Säkerhetsforskare, Go-utvecklare
- Höjdpunkter: Hastighet, samtidighet, headless JS-parsning.
Allmänt / multipurpose-skrapning
— 24.3k stjärnor, 2025

- Sammanfattning: Snabbt och elegant skrapningsramverk för Go.
- Setup: Mellan (Go-kod)
- Användningsfall: Hög prestanda, generell skrapning
- JS-stöd: Nej (endast HTML)
- Projektstatus: Aktivt, nyliga commits
- Dataexport: Ingen inbyggd (användardefinierat)
- Målgrupp: Go-utvecklare, prestandafokuserade team
- Höjdpunkter: Async, rate limiting, distribuerad skrapning.
— 11.6k stjärnor, 2023

- Sammanfattning: Flexibelt Java-ramverk för crawling, i Scrapy-stil.
- Setup: Mellan (Java, enkelt API)
- Användningsfall: Generell webbskrapning i Java
- JS-stöd: Nej (kan byggas ut med Selenium)
- Projektstatus: Aktivt community
- Dataexport: Utbyggbara pipelines
- Målgrupp: Java-utvecklare
- Höjdpunkter: Trådpool, schemaläggare, anti-blockering.
— 6.2k stjärnor, 2025

- Sammanfattning: Snabb, native HTML/XML-parser för Ruby.
- Setup: Plug & Play (Ruby gem)
- Användningsfall: HTML/XML-parsning i Ruby-appar
- JS-stöd: Nej (endast parsning)
- Projektstatus: Aktivt, följer Ruby-utvecklingen
- Dataexport: Ingen (formattera med Ruby)
- Målgrupp: Ruby-utvecklare, Rails-utvecklare
- Höjdpunkter: Hastighet, standardefterlevnad, säkert som standard.
Snabböversikt: Jämförelsetabell över funktioner
Här är en snabb tabell – plus Thunderbit som jämförelse:
| Projekt | Uppstartskomplexitet | Användningsfall | JS-stöd | Underhåll | Dataexport | Målgrupp | GitHub-stjärnor |
|---|---|---|---|---|---|---|---|
| Scrapy | Mellan | E-handel, nyheter | Nej | Aktivt | CSV, JSON, XML | Utvecklare, data engineers | 57.1k |
| Crawlee | Mellan | Flexibelt, automation | Ja | Mycket aktivt | Flexibla dataset | JS/TS-team | 17.9k |
| MechanicalSoup | Plug & Play | Statiskt, formulär | Nej | Moget | Ingen (manuellt) | Python-nybörjare | 4.8k |
| Node Crawler | Mellan | Nyheter, statiskt | Nej | Medel | Ingen (manuellt) | Node.js-utvecklare | 6.8k |
| Selenium | Mellan | JS-tungt, testning | Ja | Aktivt | Ingen (manuellt) | QA, utvecklare | ~30k |
| Heritrix | Avancerat | Arkivering, forskning | Nej | Underhållet | WARC | Arkiv, institutioner | 3k |
| Apache Nutch | Avancerat | Big data, sök | Nej | Aktivt | Rått innehåll | Företag, forskning | 3k |
| WebMagic | Mellan | Java, allmänt | Nej | Aktivt community | Utbyggbara pipelines | Java-utvecklare | 11.6k |
| Nokogiri | Plug & Play | Ruby-parsning | Nej | Aktivt | Ingen (manuellt) | Ruby-utvecklare | 6.2k |
| Playwright | Mellan | Dynamiskt, automation | Ja | Mycket aktivt | Ingen (manuellt) | Utvecklare, QA | 73.5k |
| Katana | Mellan | Säkerhet, upptäckt | Ja | Aktivt | Textutdata | Säkerhet, Go-utvecklare | 13.8k |
| Colly | Mellan | Hög prestanda, allmänt | Nej | Aktivt | Ingen (manuellt) | Go-utvecklare | 24.3k |
| Puppeteer | Mellan | Dynamiskt, automation | Ja | Aktivt | Ingen (manuellt) | Node.js-utvecklare | 90.9k |
| Maxun | Enkel (användare) | No-code, business | Ja | Aktivt | CSV, Excel, Sheets, API | Icke-tekniska, analytiker | 13k |
| Scrapling | Mellan | Stealth, anti-bot | Ja | Aktivt | Ingen (manuellt) | Python-utvecklare, hackers | 5.4k |
| Thunderbit | Plug & Play | No-code, business | Ja | Hanterat, uppdaterat | Sheets, Airtable, Notion | Icke-tekniska, affärsanvändare | N/A |
Varför Thunderbit är bästa valet för icke-tekniska och affärsanvändare
De flesta open source-projekt på GitHub är byggda av utvecklare, för utvecklare. Det betyder att installation, underhåll och felsökning liksom ingår i dealen. Om du är affärsanvändare, marknadsförare, sales ops – eller bara vill ha resultat utan regex-huvudvärk – är Thunderbit byggt för dig.
Därför sticker Thunderbit ut:
- No-code och AI-drivet enkelt: Installera , klicka på “AI Suggest Fields” och börja skrapa. Ingen Python, inga selektorer, inget “pip install”-drama.
- Stöd för dynamiska sidor: Thunderbits AI läser och extraherar data från moderna, JavaScript-tunga sajter (React, Vue, AJAX) utan manuell setup.
- Skrapning av undersidor: Behöver du hämta detaljer från varje produkt eller annons? Thunderbits AI kan klicka igenom undersidor och slå ihop allt i en tabell – utan specialkod.
- Export som funkar i verksamheten: Export med ett klick till Google Sheets, Airtable, Notion, CSV eller JSON. Perfekt för leads, prisbevakning eller innehållsaggregering.
- Löpande uppdateringar & support: Thunderbit är en hanterad tjänst – ingen risk för “abandonware”. Du får onboarding, guider och ett växande mallbibliotek för vanliga sajter.
- Rätt för målgruppen: Thunderbit är för icke-tekniska användare, affärsteam och alla som prioriterar snabbhet och stabilitet framför att pilla med kod.
Thunderbit används av över 30 000 användare globalt, inklusive team på Accenture, Grammarly och Puma. Och ja – vi har till och med varit Product Hunts #1 Product of the Week.
Vill du se hur enkelt webbskrapning kan vara? .
Slutsats: Välj rätt webbskrapningslösning för 2025
Kärnan är enkel: GitHub är en guldgruva av kraftfulla skrapningsverktyg, men de flesta är byggda för utvecklare. Om du gillar att koda ger ramverk som Scrapy, Crawlee, Playwright och Colly maximal kontroll. Om du jobbar med akademi eller säkerhet är Heritrix, Nutch och Katana ofta rätt val.
Men om du är affärsanvändare, analytiker eller bara vill ha data – snabbt, strukturerat och redo att användas – är Thunderbit vägen framåt. Ingen setup, inget underhåll, ingen kod. Bara resultat.
Vad är nästa steg? Testa ett GitHub-projekt som matchar din nivå och ditt användningsfall. Eller om du vill hoppa över inlärningskurvan och se resultat på några minuter: och börja skrapa redan idag.
Vill du fördjupa dig i webbskrapning kan du läsa fler guider på , till exempel eller .
Lycka till med skrapningen – och må din data alltid vara strukturerad, ren och redo att användas. Om du kör fast: det finns förmodligen ett GitHub-repo för det… eller så kan du låta Thunderbits AI göra jobbet åt dig.