
Mitt första skrapningsprojekt bestod av ett hemmabyggt Python-skript, en delad proxy och en bön. Det gick sönder var tredje dag.
År 2026 tar skrapnings-API:er hand om de svåra bitarna — proxies, rendering, CAPTCHAs, återförsök — så att du slipper. De är ryggraden i allt från prisbevakning till AI-träningsdataflöden.
Men det finns en twist: AI-drivna verktyg som Thunderbit gör nu många API-användningsfall onödiga för dig som inte utvecklar. Mer om det längre ned.
Här är 10 skrapnings-API:er som jag har använt eller utvärderat — vad varje lösning är bra på, var den brister och när du kanske inte behöver ett API alls.
Varför överväga Thunderbit AI i stället för traditionella webbskrapnings-API:er?
Innan vi går igenom listan med API:er, låt oss ta upp elefanten i rummet: AI-driven automatisering. Jag har ägnat år åt att hjälpa team automatisera det tråkiga arbetet, och jag kan säga det rakt ut — det finns en anledning till att fler företag hoppar över kodtunga API:er och går direkt till AI-agenter som Thunderbit.
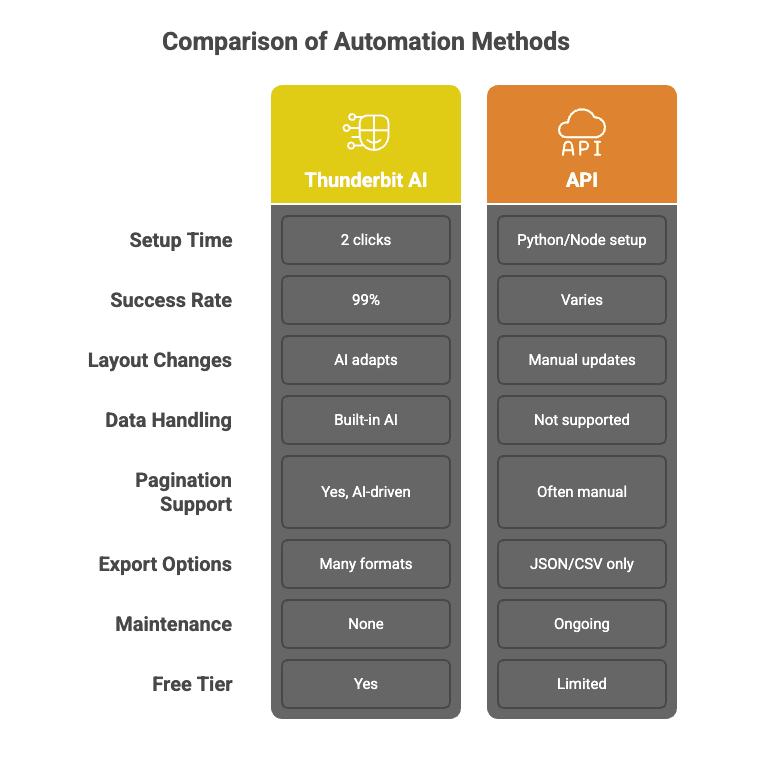
Det här är vad som skiljer Thunderbit från traditionella webbskrapnings-API:er:
-
Vattenfallsbaserade API-anrop för 99 % träffsäkerhet
Thunderbits AI nöjer sig inte med att anropa ett enda API och hoppas på det bästa. Det använder ett vattenfallsmönster — väljer automatiskt den bästa skrapningsmetoden för varje uppgift, gör nya försök vid behov och garanterar en träffsäkerhet på 99 %. Du får datan, inte huvudvärken.
-
Kodfritt upplägg med två klick
Glöm Python-skript och krångel med API-dokumentation. Med Thunderbit klickar du bara på “AI Suggest Fields” och “Scrape”. Klart. Till och med min mamma skulle kunna använda det (och hon tror fortfarande att “molnet” bara är dåligt väder).
-
Batchskrapning: snabb och exakt
Thunderbits AI-modell kan bearbeta tusentals olika webbplatser parallellt och anpassa sig till varje layout i farten. Det är som att ha en armé av praktikanter — bara utan kaffepauser.
-
Underhållsfritt
Webbplatser ändras hela tiden. Traditionella API:er? De går sönder. Thunderbit? AI:n läser sidan på nytt varje gång, så du slipper uppdatera kod när en sajt justerar layouten eller lägger till en ny knapp.
-
Anpassad datautvinning och efterbearbetning
Behöver du att datan rensas, märks, översätts eller sammanfattas? Thunderbit kan göra det som en del av extraktionen — tänk dig att slänga in 10 000 webbsidor i ChatGPT och få tillbaka en perfekt strukturerad datamängd.
-
Skrapning av undersidor och paginering
Thunderbits AI kan följa länkar, hantera paginering och till och med berika din tabell med data från undersidor — allt utan egen kod.
-
Gratis dataexport och integrationer
Exportera till Excel, Google Sheets, Airtable, Notion eller ladda ned som CSV/JSON — inga betalväggar, inget trams.
Här är en snabb jämförelse som sätter det i perspektiv:
Vill du se det i praktiken? Kolla in Thunderbit Chrome-tillägget.
Vad är ett API för dataskrapning?
Låt oss backa bandet lite. Ett API för dataskrapning är ett verktyg som låter dig extrahera data från webbplatser programmatiskt — utan att bygga egna skrapare från grunden. Tänk på det som en robot du kan skicka ut för att hämta de senaste priserna, recensionerna eller annonserna, och som kommer tillbaka med datan i ett snyggt, strukturerat format (oftast JSON eller CSV).
Hur fungerar de? De flesta skrapnings-API:er hanterar de stökiga bitarna — roterande proxies, CAPTCHAs, rendering av JavaScript — så att du kan fokusera på det du faktiskt behöver: datan. Du skickar en begäran (oftast med en URL och några parametrar), och API:et returnerar innehållet, redo för ditt arbetsflöde.
Huvudfördelar:
- Snabbhet: API:er kan skrapa tusentals sidor per minut.
- Skalbarhet: Behöver du bevaka 10 000 produkter? Inga problem.
- Integration: Koppla in mot ditt CRM, BI-verktyg eller data warehouse med minimal friktion.
Men som vi ska se är inte alla API:er skapade lika — och inte alla är så “ställ in och glöm” som de påstår.
Hur jag utvärderade dessa API:er
Jag har tillbringat mycket tid i frontlinjen — testat, brutit sönder och ibland råkat DDoSa mina egna servrar (säg inget till mitt gamla IT-team). För den här listan fokuserade jag på:
- Tillförlitlighet: Fungerar det faktiskt, även på knepiga sajter?
- Hastighet: Hur snabbt levererar det resultat i stor skala?
- Pris: Är det prisvärt för startups och skalbart för företag?
- Skalbarhet: Klarar det miljontals förfrågningar, eller faller det ihop vid 100?
- Utvecklarvänlighet: Är dokumentationen tydlig? Finns det SDK:er och kodexempel?
- Support: När det spårar ur (och det gör det), finns hjälp att få?
- Användaromdömen: Verkliga recensioner, inte bara marknadsföringssnack.
Jag lutade mig också tungt mot praktiska tester, analys av recensioner och feedback från Thunderbit-communityn (vi är ett petigt gäng).
De 10 API:erna värda att överväga 2026
Redo för huvudnumret? Här är min uppdaterade lista över de bästa webbskrapnings-API:erna och plattformarna för affärsanvändare och utvecklare 2026.
1. Oxylabs
 Översikt:
Översikt:
Oxylabs är tungviktsmästaren för webbdatautvinning i företagsklass. Med en enorm proxy-pool och specialiserade API:er för allt från SERP:er till e-handel är det förstahandsvalet för Fortune 500-bolag och alla som behöver tillförlitlighet i stor skala.
Viktiga funktioner:
- Enormt proxynätverk (residential, datacenter, mobile, ISP) i 195+ länder
- Skrapnings-API:er med anti-bot, CAPTCHA-lösning och headless browser-rendering
- Geotargeting, sessionspersistens och hög datanoggrannhet (95 %+ träffsäkerhet)
- OxyCopilot: AI-assistent som automatiskt genererar parserkod och API-frågor
Prissättning:
Från cirka 49 USD/månad för ett enskilt API, 149 USD/månad för allt-i-ett-åtkomst. Inkluderar en gratis provperiod på 7 dagar med upp till 5 000 förfrågningar.
Användaromdömen:
Betyg 4,8/5 på G2, prisas för tillförlitlighet och support. Nackdelen? Det är dyrt — men du får vad du betalar för.
2. ScrapingBee
 Översikt:
Översikt:
ScrapingBee är utvecklarens bästa vän — enkelt, prisvärt och fokuserat. Du skickar en URL, så hanterar det headless Chrome, proxies och CAPTCHAs, och returnerar den renderade sidan eller bara datan du behöver.
Viktiga funktioner:
- Headless browser-rendering (stöd för JavaScript)
- Automatisk IP-rotering och CAPTCHA-lösning
- Stealth-proxypool för svåra sajter
- Minimal uppsättning — bara ett API-anrop
Prissättning:
Gratis nivå med cirka 1 000 anrop/månad. Betalda planer börjar runt 29 USD/månad för 5 000 förfrågningar.
Användaromdömen:
Konsekvent 4,8/5 på G2. Utvecklare älskar enkelheten; icke-kodare kan tycka att det är lite för avskalat.
3. Apify
 Översikt:
Översikt:
Apify är webbskrapningens schweiziska armékniv. Du kan bygga egna skrapare (“Actors”) i JavaScript eller Python, eller använda deras stora bibliotek med färdigbyggda actors för populära sajter. Det är så flexibelt som du behöver att det ska vara.
Viktiga funktioner:
- Egna och färdigbyggda skrapare (Actors) för nästan vilken sajt som helst
- Molninfrastruktur, schemaläggning och proxihantering ingår
- Dataexport till JSON, CSV, Excel, Google Sheets med mera
- Aktiv community och Discord-support
Prissättning:
Gratis evighetsplan med 5 USD/månad i krediter. Betalda planer börjar på 39 USD/månad.
Användaromdömen:
4,7+ på G2/Capterra. Utvecklare älskar flexibiliteten; nybörjare möter en brantare inlärningskurva.
Se hur Apify står sig mot Thunderbit
4. Decodo (tidigare Smartproxy)
 Översikt:
Översikt:
Decodo (omprofilerat från Smartproxy) handlar om värde och enkelhet. Det kombinerar robust proxyinfrastruktur med skrapnings-API:er för allmän webb, SERP:er, e-handel och sociala medier — allt i samma prenumeration.
Viktiga funktioner:
- Enhetligt skrapnings-API för alla ändpunkter (inga separata tillägg längre)
- Specialiserade skrapare för Google, Amazon, TikTok och mer
- Användarvänlig dashboard med playground och kodgeneratorer
- Support via livechatt dygnet runt
Prissättning:
Från cirka 50 USD/månad för 25 000 förfrågningar. Gratis provperiod i 7 dagar med 1 000 förfrågningar.
Användaromdömen:
Prisad för “mycket för pengarna” och snabb support. 4,7/5 på G2.
5. Octoparse
 Översikt:
Översikt:
Octoparse är no-code-mästaren. Om du ogillar kod men älskar data låter den här skrivbordsappen med klickgränssnitt och molnfunktioner dig bygga skrapare visuellt och köra dem lokalt eller i molnet.
Viktiga funktioner:
- Visuell arbetsflödesbyggare — klicka bara för att välja datafält
- Molnextraktion, schemaläggning och automatisk IP-rotering
- Mallar för populära sajter och en marknadsplats för anpassade skrapare
- Octoparse AI: integrerar RPA och ChatGPT för datarensning och arbetsflödesautomatisering
Prissättning:
Gratis plan för upp till 10 lokala uppgifter. Betalda planer börjar på 119 USD/månad (molnfunktioner, obegränsat antal uppgifter). 14 dagars gratis provperiod för premiumfunktioner.
Användaromdömen:
4,4/5 på G2. Älskad av icke-kodare, men avancerade användare kan stöta på begränsningar.
6. Bright Data
 Översikt:
Översikt:
Bright Data är monstret i rummet — om du behöver skala, hastighet och alla funktioner man kan tänka sig är det här plattformen för dig. Med världens största proxynätverk och en kraftfull scraping-IDE är den byggd för enterprise.
Viktiga funktioner:
- 150M+ IP-adresser (residential, mobile, ISP, datacenter)
- Web Scraper IDE, färdigbyggda datainsamlare och färdiga dataset att köpa
- Avancerat anti-bot-skydd, CAPTCHA-lösning och stöd för headless browser
- Fokus på compliance och juridik (Ethical Web Data-initiativet)
Prissättning:
Betala per användning: cirka 1,05 USD per 1 000 förfrågningar, proxies från 3–15 USD/GB. Gratis provperiod för de flesta produkter.
Användaromdömen:
Prisad för prestanda och funktioner, men priset och komplexiteten kan vara ett hinder för mindre team.
7. WebAutomation
 Översikt:
Översikt:
WebAutomation är en molnbaserad plattform byggd för dig som inte utvecklar. Med en marknadsplats för färdigbyggda extraktorer och en no-code-byggare är den perfekt för affärsanvändare som vill ha data, inte kod.
Viktiga funktioner:
- Färdigbyggda extraktorer för populära sajter (Amazon, Zillow med mera)
- No-code-byggare med klickgränssnitt
- Molnbaserad schemaläggning, dataleverans och underhåll ingår
- Radbaserad prissättning (betala för det du extraherar)
Prissättning:
Projektplan för 74 USD/månad (~400k rader/år), pay-as-you-go för 1 USD per 1 000 rader. 14 dagars gratis provperiod med 10 miljoner krediter.
Användaromdömen:
Användare älskar hur lätt det är att komma igång och den transparenta prissättningen. Supporten är hjälpsam, och teamet sköter underhållet.
8. ScrapeHero
 Översikt:
Översikt:
ScrapeHero började som en konsulttjänst för anpassad skrapning och erbjuder nu en självbetjänad molnplattform. Du kan använda färdigbyggda skrapare för populära sajter eller beställa helt hanterade projekt.
Viktiga funktioner:
- ScrapeHero Cloud: färdigbyggda skrapare för Amazon, Google Maps, LinkedIn och mer
- No-code-drift, schemaläggning och molnleverans
- Anpassade lösningar för unika behov
- API-åtkomst för programmatiska integrationer
Prissättning:
Molnplaner börjar så lågt som 5 USD/månad. Anpassade projekt från 550 USD per sajt (engångsavgift).
Användaromdömen:
Prisad för tillförlitlighet, datakvalitet och support. Bra för att skala från gör-det-själv-lösningar till hanterade lösningar.
9. Sequentum
 Översikt:
Översikt:
Sequentum är företagets schweiziska armékniv — byggd för compliance, spårbarhet och massiv skala. Om du behöver SOC-2-certifiering, revisionsspår och teamsamarbete är det här ditt verktyg.
Viktiga funktioner:
- Lågkodig agentdesigner (klickgränssnitt plus scripting)
- Molnbaserad SaaS eller lokal installation
- Inbyggd proxihantering, CAPTCHA-lösning och headless browsers
- Revisionsspår




