Din CRM är bara så vass som datan du stoppar in. Och den mest värdefulla datan finns ofta ute i det öppna på offentliga webbplatser – inte gömd bakom dyra tredjepartsdatabaser.
webbextraktor-verktyg gör om rörig webbdata till prydliga kalkylark. De bästa fixar det på några minuter, helt utan kod.
Jag har kört de här verktygen i skarpa lägen – byggt leadlistor, följt konkurrenters priser och hämtat produktkataloger. Här är 12 som faktiskt levererade, rankade efter hur bra de funkade för verkliga affärsuppgifter.
Varför webbextraktorer är en affärsnödvändighet
Om vi ska vara helt ärliga: webben är världens största (och stökigaste) databas. Och 2026 är det företagen som kan reda ut kaoset och göra om det till insikter som drar ifrån. Enligt är datadrivna företag 5 % mer produktiva och 6 % mer lönsamma än konkurrenterna. Det är inte en avrundningsgrej – det är en konkret konkurrensfördel.
Verktyg för webbextrahering (ibland kallade webbsidesextraktorer eller lösningar för webbextrahering) är den där hemliga ingrediensen. De gör att säljteam kan hämta data från offentliga kataloger, sociala medier och företagswebbplatser för att bygga riktade prospektlistor – istället för att köpa in gamla leadlistor eller hoppas att praktikanten inte kroknar mitt i ett copy‑paste-maraton (). Marknads- och e‑handelsteam använder webbextraktor-lösningar för att spåra konkurrentpriser, bevaka lagersaldon och jämföra produkter i realtid – John Lewis tillskriver till exempel web scraping en 4 % försäljningsökning bara genom smartare prissättning ().
Men det är inte bara siffror. webbextraktor-verktyg sparar brutalt mycket tid (en användare sa att de sparade ”hundratals timmar” genom att automatisera datainsamling) och minskar risken för mänskliga fel (). Drift- och operationsteam sätter numera upp scrapers som löpande samlar in data som annars hade tagit praktikanter veckor – och frigör timmar som tidigare försvann i monotont kopiera‑klistra (). Och med AI-drivna extraktorer kan även icke-tekniska användare förvandla webbplatser till strukturerad data för analys ().
Slutsats? Om du inte använder en webbextraktor 2026 lämnar du sannolikt både insikter (och pengar) på bordet.
Så valde vi de 12 bästa webbextraktorerna
Med så många alternativ inom webbextrahering – hur väljer man rätt? Jag plöjde igenom massor av verktyg, men bara 12 tog sig hela vägen in på listan. Det här vägde tyngst:
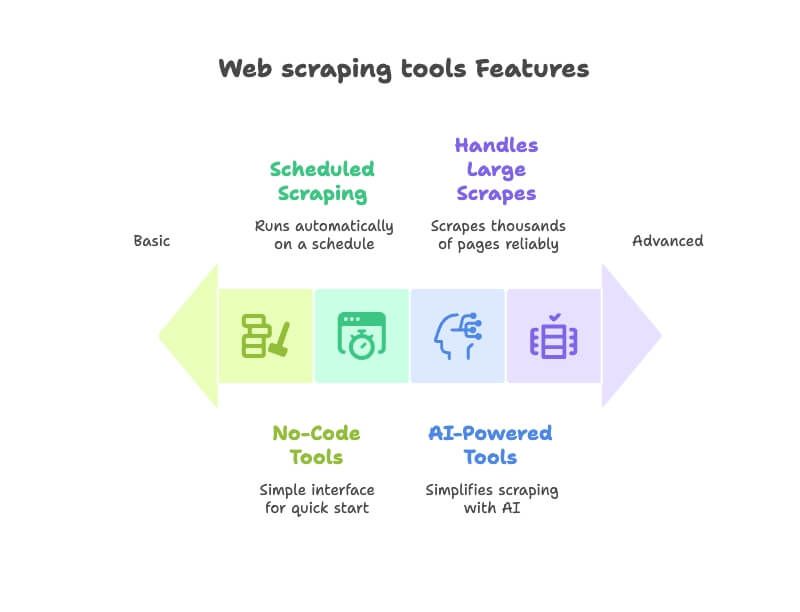
- Användarvänlighet: Kan en icke-teknisk användare komma igång snabbt utan att skriva kod? Jag prioriterade no‑code/low‑code-verktyg med tydliga gränssnitt ().
- AI-funktioner: Nästa generations verktyg som använder AI för att förenkla scraping – t.ex. automatiskt hitta datafält, hantera navigering eller låta dig beskriva behov på vanlig svenska/engelska ().
- Automatisering & schemaläggning: De bästa webbextraktorerna går på autopilot. Jag valde verktyg som kan schemalägga återkommande körningar eller bevaka webbplatser över tid ().
- Export & integrationer: Går det enkelt att exportera till Excel, Google Sheets, Airtable eller Notion? Extra plus för arbetsflödesintegrationer ().
- Skalbarhet och tillförlitlighet: Oavsett om du hämtar från en sida eller tusentals ska verktyget klara det. Jag tog även hänsyn till omdömen kring stabilitet.
- Affärsnära användningsfall: Jag lyfte fram verktyg som är populära hos sälj, marknad, e‑handel och operations – inte bara bland utvecklare.
Vissa verktyg här är AI-drivna nykomlingar, andra är branschklassiker. Gemensamt är att de hjälper dig göra webben till din egen affärsdatabas – utan huvudvärk.
Snabb jämförelse: webbextraktorverktyg i korthet
Här är en översikt över de 12 webbextraktorverktyg jag går igenom, så att du snabbt ser skillnaderna:
| Verktyg | AI-automatisering | Användarvänlighet | Bästa användningsfall |
|---|---|---|---|
| Thunderbit | Ja – AI föreslår fält och hanterar sidor automatiskt | Mycket enkelt (Chrome-tillägg, ingen kod) | Snabb scraping för leads, priser m.m. för icke-tekniska användare som vill ha resultat på minuter. |
| Octoparse | Begränsat (mallbaserat, ingen AI) | Enkelt för de flesta (visuellt dra-och-släpp-gränssnitt) | Anpassade scrapingflöden (med inloggning, paginering) för analytiker som vill ha kontroll utan kod. |
| Browse AI | Delvis – peka-och-klicka-”robotar” | Enkelt (no‑code, molnbaserat) | Automatiserad bevakning av data (priser, annonser m.m.) enligt schema, med aviseringar och integrationer. |
| WebScraper.io | Nej (manuell konfiguration) | Medel (webbläsartillägg med sitemap-upplägg) | Visuell scraping av webbplatser i flera nivåer för användare som kan konfigurera steg. |
| ScraperAPI | N/A (API-tjänst, hanterar proxies via API) | Kräver kod (API-integration) | Högvolymsuttag av webbdata för techteam – proxies & CAPTCHAs hanteras för storskalig scraping. |
| Data Miner | Nej | Mycket enkelt (webbläsartillägg med en-klick-mallar) | Snabb engångsextrahering från sidor (särskilt tabeller eller listor) direkt till CSV/Excel. |
| Simplescraper | Nej (vissa AI-assisterade funktioner) | Enkelt (peka-och-klicka-receptbyggare) | No‑code scraping med integrationer – perfekt för att skicka webbdata till Google Sheets, Airtable eller API. |
| Instant Data Scraper | Ja – upptäcker datatabeller automatiskt | Mycket enkelt (bara klicka, ingen setup) | Omedelbar gratis scraping av HTML-tabeller och listor för alla (perfekt för snabba datauttag). |
| ScrapeStorm | Ja – AI identifierar sidelement | Enkelt (visuellt gränssnitt; plattformsoberoende app) | Storskaliga eller komplexa projekt utan kod, inklusive schemalagda körningar. |
| Apify | Viss – färdiga ”actor”-botar finns | Medel (webbgränssnitt; kod valfritt) | Skalbar molnscraping och automation via färdiga eller egna script. |
| ParseHub | Nej (scriptlöst men manuell setup) | Enkelt för grundläggande användning (visuell editor; desktopapp) | Scraping av dynamiska eller komplexa sajter (AJAX-innehåll) via no‑code-gränssnitt. |
| OutWit Hub | Nej | Enkelt (desktopapp med GUI) | Enkel, offline dataextrahering och innehållsarkivering för mindre projekt. |
De flesta verktyg erbjuder en gratisnivå eller provperiod samt abonnemang i flera nivåer. Fokus här ligger på funktioner och användningsfall snarare än pris.
Thunderbit: AI-driven webbextraktor för alla

Vi börjar med Thunderbit – ja, det är mitt eget verktyg, men häng med. Branschen håller på att skifta från ”bygg och konfigurera din egen scraper” till ”säg bara till AI:n vad du vill ha”. Thunderbit är det första verktyget jag sett (och varit med och byggt) som på riktigt känns som en AI-assistent för data snarare än ännu en ”crawler”.
Med slipper du XPath, CSS-selektorer och regex. Du beskriver bara vad du vill ha på vanlig engelska – som ”hämta titel, författare och datum från den här sidan” – och Thunderbits AI löser resten (). Klicka på ”AI Suggest Fields”, så läser Thunderbit sidan, föreslår kolumner och hanterar till och med undersidor och paginering automatiskt ().
Och det handlar inte bara om att hämta data. Thunderbit kan rensa, omvandla, kategorisera och till och med översätta fält medan den skrapar. Behöver du standardisera telefonnummer, sammanfatta beskrivningar eller översätta produktnamn? Lägg till en kort instruktion så fixar AI:n det. När du är klar exporterar du direkt till Excel, Google Sheets, Airtable eller Notion ().
Det som verkligen skiljer Thunderbit är noll setup och i princip ingen inlärningskurva. Det är ett Chrome-tillägg, så du är igång på sekunder. Inga plugins, ingen konfiguration, inget tekniksnack. Därför har det blivit en favorit för sälj-, marknads- och operationsteam som behöver resultat – snabbt (). Gratisnivån låter dig testa hela flödet, och betalplanerna är rimliga (tänk ”mindre än din månatliga kaffebudget” för de flesta team).
Vill du känna på hur AI-baserad webbextrahering funkar i praktiken? och testa. Dina copy‑paste-dagar kan vara räknade.
Octoparse: Visuell webbextraktor för anpassade arbetsflöden
Octoparse är en riktig klassiker inom visuell web scraping. Det är en desktopapp med ett peka-och-klicka-gränssnitt – du interagerar med webbsidan, markerar datan du vill ha och Octoparse bygger ett arbetsflöde i bakgrunden (). Du kan hantera inloggningar, sätta upp paginering och till och med automatisera formulärinlämningar, utan att skriva kod.
En av Octoparse största styrkor är biblioteket med 500+ färdiga mallar för populära sajter (Amazon, Twitter, LinkedIn m.fl.), så ofta kan du bara ladda en mall och börja extrahera (). För mer komplexa sajter kan du växla till manuellt läge och konfigurera varje steg visuellt. Octoparse klarar innehåll som laddas efter klick eller scroll, och kan använda proxies samt lösa CAPTCHAs för tuffare jobb. Det finns även ett molnalternativ för schemaläggning och körning i större skala.
Nackdelen? Det finns en viss inlärningskurva, särskilt för avancerade scenarier. Men för icke-programmerare och dataanalytiker som vill ha ett skräddarsytt scrapingflöde utan kod är Octoparse ett stabilt val ().
Browse AI: Automatiserad webbextrahering med färdiga robotar
Browse AI har en smart idé: du ”tränar en robot” genom att peka och klicka på datan du vill ha, och den lär sig att hämta samma typ av data på liknande sidor (). Allt är molnbaserat och no‑code, så du slipper scripts och servrar.
Det som gör Browse AI extra intressant är automatisering och bevakning. Du kan schemalägga robotarna och få aviseringar när data ändras (t.ex. när en konkurrent sänker priset eller en ny jobbannons dyker upp). De har också ett bibliotek med färdiga robotar för vanliga uppgifter – så du kan ofta börja med en färdig lösning och justera efter behov ().
Browse AI integrerar med tusentals appar via Zapier och Make och kan exportera direkt till Google Sheets eller via API/webhooks (). Det passar perfekt för kontinuerlig bevakning och återkommande datainsamling, särskilt om du vill ha hands-off-aviseringar och integrationer.
WebScraper.io: Webbläsarbaserad webbsidesextraktor

WebScraper.io (ofta bara ”Web Scraper”) är ett webbläsartillägg där du bygger ”sitemaps” – visuella planer för hur en webbplats ska navigeras och vilka element som ska extraheras (). Du definierar selektorer för datan och länkarna som ska följas (t.ex. ”klicka på nästa för paginering” eller ”besök varje produktlänk för detaljer”).
Det finns en viss tröskel, men du skriver ingen kod – du markerar element och sätter extraktionsåtgärder. Web Scraper stödjer navigering i flera nivåer, paginering och även infinite scroll (men du behöver ange stegen manuellt). Det är flexibelt och körs i webbläsaren, så du kan skrapa sajter bakom inloggning genom att logga in själv.
WebScraper.io passar bra för ”medborgaranalytiker” som är bekväma med webbsidors struktur och vill ha ett gratis, flexibelt verktyg. En pålitlig arbetshäst om du är villig att bygga dina egna sitemaps.
ScraperAPI: API-först webbextraktor för utvecklare och team
Alla team vill inte ha peka-och-klicka – ibland behöver du en backend-lösning som skickar webbdata direkt in i appar eller databaser. ScraperAPI är en API-först webbextraktor: du skickar in en URL och får tillbaka rå HTML eller extraherad data, medan tjänsten hanterar det svåra – proxies, geografisk IP-rotation, headless browsers och CAPTCHAs ().
ScraperAPI har en pool på över 40 miljoner proxies i 50+ länder och hanterar 36 miljarder förfrågningar per månad (). Det är bäst för storskalig, automatiserad scraping där stabilitet och anti-blockering är avgörande. Du behöver kunna koda för att använda det, men om du bygger datapipelines eller vill integrera scraping i en produkt är ScraperAPI ett toppval.
Data Miner: Chrome-tillägg för snabb webbsidesextrahering

Data Miner är ett Chrome-tillägg för affärsanvändare och researchers som behöver få ut data snabbt. Det erbjuder en peka-och-klicka-upplevelse och ett bibliotek med färdiga scraping-”recept” för vanliga mönster som tabeller, listor eller specifika sajter ().
Installera tillägget, gå till sidan du vill hämta från och klicka på Data Miner-ikonen. Välj ett recept eller skapa ett eget genom att markera element på sidan. Perfekt för engångsjobb eller snabba behov – som när en säljare plockar ut leads från en katalog eller en e‑handelsansvarig jämför konkurrentpriser.
Data Miner är enkelt, sitter i webbläsaren och passar för interaktiv scraping på begäran.
Simplescraper: No‑code webbextraktor för snabba resultat

Simplescraper lever upp till namnet. Det är ett no‑code Chrome-tillägg (och webbapp) där du visuellt markerar data på en sida och skapar ett ”recept” för extrahering (). Du kan följa länkar för att skrapa undersidor, hantera paginering och till och med göra din scraping till en API-endpoint med ett klick.
Simplescraper sticker ut med sina integrationsmöjligheter – du kan skicka data direkt till Google Sheets, Airtable eller verktyg som Zapier (). Det finns även molnscraping och schemaläggning för återkommande jobb samt en ”AI Enhance”-funktion som kan rensa eller analysera data med GPT.
Vill du ha snabba resultat och smidiga integrationer är Simplescraper som en schweizisk armékniv för lättviktig web scraping.
Instant Data Scraper: snabb webbextrahering för tabeller och listor
Ibland vill du bara ha datan nu, utan någon setup. Då är Instant Data Scraper (IDS) helt rätt. Det är ett gratis Chrome-tillägg känt för en-klick-scraping av tabellbaserad data (). Aktivera tillägget så hittar IDS automatiskt tabeller eller listor på sidan. Det kan även hantera paginering och infinite scroll genom att klicka sig igenom alla sidor.
IDS är 100 % gratis, ingen registrering, ingen kod, ingen väntan. Perfekt för vardagliga eller akuta behov – som när en säljare snabbt behöver en leadlista eller en student vill hämta data från Wikipedia-tabeller. Om den hittar din data har du den på sekunder.
ScrapeStorm: Molnbaserad webbextraktor med AI-stöd
ScrapeStorm är ett AI-drivet web scraping-verktyg som kombinerar ett visuellt gränssnitt med kraftfulla AI-algoritmer (). Du anger en URL och AI:n identifierar automatiskt datafält – listor, tabeller, nästa-sida-knappar och mer.
ScrapeStorm stödjer flera plattformar (Windows, Mac, Linux) och erbjuder både desktop- och molnbaserad scraping. Du kan schemalägga uppgifter, köra flera jobb parallellt och exportera till Excel, CSV, JSON eller till och med ladda upp till en databas (). Det är särskilt populärt inom e‑handel och marknadsanalys, och kan även tolka data från bilder eller PDF:er med hjälp av AI.
Behöver du en smart assistent för storskaliga eller komplexa scrapingprojekt är ScrapeStorm värt att kika på.
Apify: Marknadsplats för webbextraktorer och automationsplattform

Apify är inte bara en scraper – det är en plattform för web scraping och automation. Du kör ”actors”, alltså script för scraping eller webbläsarautomation. Den stora styrkan är Apifys marknadsplats med färdiga actors för vanliga uppgifter (). Behöver du skrapa alla recensioner från en e‑handel? Det finns sannolikt en actor för det.
För utvecklare kan du skriva egna scrapers i Node.js eller Python och driftsätta dem i molnet. Det är skalbart, automatiserbart och integreras via API. Apify passar bäst för power users och organisationer som ser webbdata som en strategisk resurs – t.ex. löpande storskalig scraping eller integration i en datapipeline.
ParseHub: Visuell webbsidesextraktor för komplexa sajter

ParseHub är en desktopapp (med molnalternativ) som är känd för att klara komplexa, dynamiska webbplatser. Du navigerar på sajten i ett webbläsarliknande gränssnitt, klickar på datapunkter och ParseHub bygger din scraper (). Den stödjer villkorslogik, nästlade extraktioner, AJAX-innehåll och mer.
ParseHub är ofta valet när andra verktyg inte lyckas skrapa en sajt korrekt. Det används av researchers, analytiker och småföretagare som behöver hantera knepiga webbplatser. Det finns en inlärningskurva, men om du har en svår sajt att skrapa och inte vill koda är ParseHub ett toppalternativ.
OutWit Hub: Desktop-webbextraktor för innehållsarkivering

OutWit Hub är lite old school, men det är en desktopapplikation som är bra på att hämta många olika typer av innehåll (länkar, bilder, e‑postadresser m.m.) och organisera det (). Det fungerar som en blandning av webbläsare och kalkylark – gå till en sida så kan OutWit Hub extrahera tabeller, listor, bilder och mer.
Det är särskilt användbart för innehållsarkivering eller research – som att skrapa alla inlägg från ett forum eller ladda ner en samling filer. Det är ett desktopverktyg, så du kör lokalt och behåller datan privat. OutWit Hub passar bäst för små till medelstora scrapinguppgifter där du vill ha ett rakt och enkelt desktopgränssnitt.
Vilken webbextraktor passar bäst för dina behov?
Tolv verktyg, tusen användningsfall. Så vilken ska du välja? Här är min snabbguide:
-
För total nybörjare eller snabba engångsjobb:
Testa Instant Data Scraper för enkla tabeller och listor (gratis och direkt). Data Miner är ett annat lättanvänt alternativ med fler mallar om du ofta skrapar liknande sidor.
-
För icke-tekniska användare som behöver löpande scraping eller integrationer:
Thunderbit ger det smidigaste flödet med sin AI-drivna metod – perfekt för affärsanvändare som vill ha resultat snabbt och ofta. Browse AI är toppen för kontinuerlig bevakning och aviseringar. Simplescraper är bra om du vill att datan ska flöda in i Google Sheets eller en intern app via API.
-
För komplexa webbplatser eller anpassade flöden utan kod:
Välj en visuell scraper som Octoparse eller ParseHub. Octoparse är lätt att komma igång med och har många mallar. ParseHub klarar riktigt komplexa dynamiska sajter och ger fin kontroll. WebScraper.io är också bra om du vill konfigurera egna sitemaps.
-
För utvecklare eller data engineers som behöver skala:
ScraperAPI är byggt för att bädda in web scraping i mjukvara eller köra storskaliga projekt. Apify passar när du vill ha en skalbar plattform med en marknadsplats av färdiga eller egna script.
-
För innehållstung extrahering eller offline-användning:
OutWit Hub är ett bra val för systematisk insamling och arkivering av innehåll, särskilt om du föredrar ett desktopverktyg för integritet eller kontroll.
Många team använder, helt ärligt, flera verktyg beroende på uppgift. Du kan börja med Instant Data Scraper för något enkelt, gå över till Thunderbit eller Octoparse för ett mer omfattande projekt och använda ScraperAPI eller Apify när du behöver industrialisera processen. Det fina är att de flesta har gratisnivå eller provperiod, så du kan testa dig fram.
Slutsats: framtiden för webbextrahering för affärsteam
Verktyg för webbextrahering har tagit enorma kliv. 2026 är de helt mainstream. Den stora trenden? Web scraping blir enklare, mer automatiserat och mer integrerat i vardagens arbetsflöden (). AI-drivna scrapers gör att även komplexa, dynamiska webbplatser kan hanteras utan specialistkunskap. Som en data engineer uttryckte det: ”När AI-verktyg för web scraping kom kunde jag göra uppgifter mycket snabbare och i större skala... med AI ingår [datarensning] automatiskt i mitt arbetsflöde.”
En annan stor förändring är att gränserna mellan scraping, bevakning och automation suddas ut. Verktyg som Browse AI och Thunderbit hämtar inte bara data – de håller den uppdaterad och kan till och med utföra åtgärder (som att fylla i formulär eller trigga aviseringar). Ökningen i användning är tydlig – en stor plattform såg månatliga aktiva användare öka med över 140 % på ett år (). Företag i alla storlekar inser att tillgång till offentlig webbdata (etiskt och lagligt) är avgörande för att fortsätta vara konkurrenskraftiga.
För affärsteam är budskapet egenmakt. Du behöver inte vänta i veckor på en utvecklare eller nöja dig med magkänsla. Verktygen i den här listan lägger webbdata i dina händer, med gränssnitt och funktioner anpassade för verkliga behov inom sälj, marknad, operations och mer. Och med utvecklingen framåt väntar jag mig ännu mer lättanvända gränssnitt, smartare AI och djupare integration med BI- och analysplattformar inom kort.
Kom bara ihåg: respektera webbplatsers användarvillkor och robots.txt-regler, och se till att du följer dataskyddslagstiftning. Etisk scraping är viktigt för att det här ska hålla över tid.
Oavsett om du börjar med ett gratis tillägg eller rullar ut en enterprise‑klassad scrapingflotta har det aldrig varit ett bättre läge att göra webbens information till konkreta insikter. Webbextraktor-revolutionen är här – välj ett verktyg, testa och lås upp värdet som gömmer sig mitt framför ögonen. Din datadrivna framtid är bara ett klick bort.
Vanliga frågor
1. Vad är en webbextraktor och varför är den viktig för företag?
En webbextraktor är ett verktyg som automatiskt samlar in strukturerad data från webbplatser. Den är viktig eftersom den hjälper företag att göra rörig onlineinformation till användbara insikter – öka produktiviteten, förbättra lönsamheten och slippa manuell datainsamling.
2. Vem kan använda webbextraktorer – behöver jag tekniska kunskaper?
Många moderna webbextraktorer kräver inga tekniska kunskaper. Verktyg som Thunderbit, Browse AI och Instant Data Scraper är byggda för icke-tekniska användare med intuitiva gränssnitt, AI-automatisering och no‑code-flöden.
3. Hur kan sälj-, marknads- och operationsteam dra nytta av webbextraktorer?
Säljteam kan bygga leadlistor från onlinekataloger, marknadsteam kan bevaka konkurrentpriser och operationsteam kan automatisera datainsamlingsprocesser. Verktygen sparar tid, minskar fel och ger färska, pålitliga insikter för strategiska beslut.
4. Vad ska jag titta efter när jag väljer ett webbextraktorverktyg?
Viktiga faktorer är användarvänlighet, AI-funktioner, automatisering/schemaläggning, integration med verktyg som Google Sheets eller Airtable, skalbarhet och hur väl det matchar ditt användningsfall (t.ex. säljleads, prisbevakning, innehållsarkivering).
5. Finns det gratis eller billiga webbextraktorverktyg?
Ja, många webbextraktorer har gratisnivåer eller prisvärda planer. Instant Data Scraper är helt gratis för grundläggande behov, medan Thunderbit, Simplescraper och Data Miner erbjuder generösa gratisplaner med möjlighet att uppgradera vid behov.
Vill du lära dig mer om webbextrahering, AI-scraping eller hur du gör webbplatser till teamets nästa stora fördel? Besök för fler guider, tips och berättelser från verkligheten inom dataautomation.