Temu når nu över i fler än 50 marknader. Produktkatalogen spänner över allt från köksprylar till tillbehör för husdjur och LED-lister. Om du jobbar med e-handel, dropshipping eller konkurrensbevakning har du säkert velat få in Temu-data i ett kalkylblad — och sedan upptäckt att Temu verkligen, verkligen inte vill att du ska göra det.
Jag har lagt mycket tid på att undersöka och testa scrapingverktyg för skyddade e-handelssajter. Temu är ett av de svåraste målen där ute. De flesta guider på nätet ger dig antingen en Python-handledning som slutar fungera inom en vecka eller pekar dig mot enterprise-API:er som kostar mer än din månatliga annonsbudget.
Verkligheten är att de flesta affärsanvändare — dropshippare, soloentreprenörer, marknadsteam — bara vill ha ett rent kalkylblad med produktnamn, priser, bilder, betyg och säljarinfo. De vill inte felsöka Playwright-skript klockan två på natten.
Den här guiden är byggd kring just det glappet: en praktisk, nivåindelad genomgång av de bästa Temu-scrapers som faktiskt fungerar 2026, plus bästa praxis som förvandlar rå scraping till löpande konkurrensbevakning. Oavsett om du är total nybörjare eller utvecklare som bygger en datapipeline finns det ett avsnitt för dig här.
Varför scrapa Temu? Toppanvändningsfall för affärsteam
Temu-data är inte bara intressant — den är strategiskt användbar.
Plattformen har blivit en prissättande kraft i produktkategorier med låga och medelhöga prispunkter. Även om du inte säljer på Temu jämför dina kunder sannolikt dina priser med det de ser där. Så här använder olika team Temu-data:
| Användningsfall | Data som behövs | Varför det spelar roll |
|---|---|---|
| Produktresearch för dropshipping | Titel, pris, bild, betyg, antal recensioner, antal sålda, varianter | Hittar lågprisprodukter med efterfrågesignaler för jämförelse mot Amazon, Shopify, AliExpress och TikTok Shop |
| Konkurrensprissättning | Aktuellt pris, ursprungspris, rabatt %, valuta, frakt, tidsstämpel | Bygger en utgångspunkt för prissättning och kampanjplanering |
| Produktanskaffning | Specifikationer, bilder, varianter, säljare/butik, artikel-ID, kategori | Identifierar produkttyper och leverantörsliknande listningar som är värda djupare verifiering |
| Analys av marknadstrender | Sökkterm, kategori, antal sålda, antal recensioner, betyg | Visar vilka produkter som tar fart i olika kategorier |
| Marknadsförings- och creative research | Titel, bild, antal recensioner, betyg, beskrivningar, kategorietiketter | Avslöjar budskap, visuella krokar, paket och påståenden som används av listningar med höga volymer |
| Lager- och tillgänglighetsövervakning | Produkt-URL, tillgänglighet, leveransestimat, pris, tidsstämpel | Fångar slut på lager, förändringar i lokala lager och prisrörelser över tid |
Publiken som söker efter "bästa Temu scrapers" brukar delas in i tre grupper. Icke-tekniska användare vill ha ett Chrome-tillägg som spottar ut ett kalkylblad. Halvtekniska användare vill ha ett visuellt verktyg med mallar och schemaläggning. Utvecklare vill ha ett API, ett Playwright-skript och en proxystrategi.
Den här artikeln täcker alla tre — men den börjar med den största gruppen: personer som behöver data, inte kod.
Det som gör de bästa Temu-scrapers utmärkande 2026
En scraper som klarar Amazon eller Shopify överlever inte nödvändigtvis Temu. Bedömningskriterierna för den här artikeln är:
- Tillförlitlighet på Temu — Ger den faktiskt tillbaka ren data, eller blir den blockerad, returnerar tomma rader eller går sönder efter en layoutändring?
- Enkel användning — Kan en affärsanvändare utan teknisk bakgrund komma igång utan att skriva kod?
- Datakompletthet — Stöder den berikning av undersidor (besök på varje produkts detaljsida för specifikationer, varianter och säljarinfo)?
- Underhållsarbete — Anpassar den sig när Temu ändrar sin sidstruktur?
- Schemaläggning och övervakning — Kan den köra återkommande scraping och exportera till en levande datamålplats?
- Exportmål — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Kostnadstransparens — Vad kostar ett realistiskt Temu-scrapingflöde faktiskt per månad?
Communityrapporter på beskriver konsekvent Temu som en av de svåraste e-handelssajterna att scrapa. En användare skrev att hen "inte ens kan få fram ett pris som köpare", medan en annan påpekade att Temu och Shopee har team som kontinuerligt förstärker sina anti-bot-mekanismer. Temuspecifik data om felfrekvens är inte offentligt benchmarkad, men visade att automatiserad trafik gick om mänsklig trafik, med bottar som stod för av all internettrafik. Det är den miljö Temu försvarar sig mot.
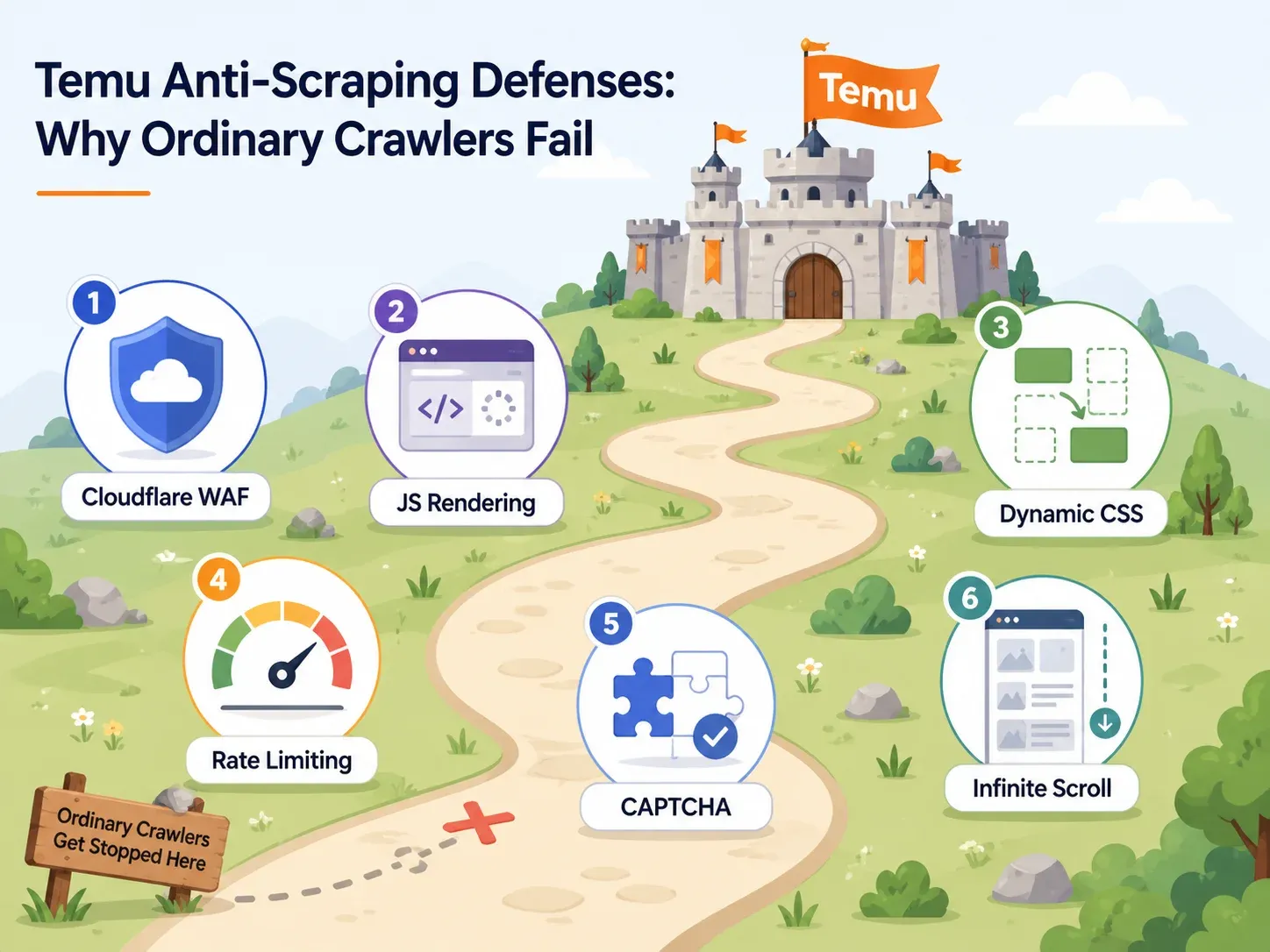
Temus anti-bot-försvar: varför de flesta scrapers misslyckas
De flesta artiklar om Temu-scraping ägnar en mening åt anti-bot-försvar: "Temu använder anti-bot." Det hjälper inte.
Om du väljer ett verktyg behöver du veta vilka försvar Temu använder och vilka verktygsfunktioner som slår ut vart och ett. Här är den praktiska kartan:
| Temus försvar | Vad det gör | Vilken verktygsfunktion som behövs | Exempel på verktyg |
|---|---|---|---|
| Cloudflare WAF / webbläsarkontroller | Blockerar automatiserade user agents, fingeravtryck av bottar, returnerar utmaningssidor | Molninfrastruktur med roterande residential-IP:er och riktiga webbläsarfingeravtryck | Thunderbit (molnscraping), Bright Data, Oxylabs, ScraperAPI |
| Tung JavaScript-rendering | Produktdata laddas via JS; rå HTML är tom | Headless browser eller full webbläsarrendering | Thunderbit (webbläsarscraping-läge), Playwright, Selenium, ParseHub, Apify browser actors |
| Dynamiska CSS-selektorer | Klassnamn ändras mellan deployment, vilket bryter CSS-baserade scrapers | AI-baserad fältidentifiering (inte beroende av fasta selektorer) | Thunderbit (AI läser sidan på nytt varje gång), Bright Data AI scraper builder |
| Rate limiting | Stryper snabba följdfrågor | Samtidiga molnförfrågningar med intelligent throttling | Thunderbit (upp till 50 sidor åt gången via molnet), ScraperAPI, Bright Data |
| CAPTCHA-utmaningar | Avbryter sessioner efter misstänkt beteende | Inbyggd CAPTCHA-lösning eller strategi med lägre utlösningsgrad | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Oändlig scroll / lazy loading | Bara de första produkterna visas utan interaktion | Smart scrollning, identifiering av paginering, interaktionsautomation | Thunderbit pagination, Apify smart scrolling, Octoparse workflow builder |
Cloudflare WAF och IP-blockering
Temus ytterdörr bevakas av webbläsarkontroller i Cloudflare-stil. Grundläggande HTTP-förfrågningar — den sorten som ett enkelt Python-anrop med requests.get() gör — utmanas, får 403 eller serveras ofullständig data.
Verktyg som fungerar här behöver roterande residential- eller mobil-IP:er och riktiga webbläsarfingeravtryck. rapporterade att icke-AI-bottar inledde 2025 med att stå för ungefär hälften av alla HTML-sidförfrågningar. Det är den skala av automatisering som plattformar som Temu försvarar sig mot.
JavaScript-rendering och dynamiska selektorer
Det är här de flesta nybörjarscrapers misslyckas tyst.
Om du tittar på Temus sidkälla hittar du ofta ett tomt skal — de faktiska produktkorten, priserna och bilderna injiceras via JavaScript efter att sidan laddats. En scraper som bara läser rå HTML kommer att returnera ingenting användbart. Utöver det ändras Temus CSS-klassnamn och DOM-strukturer mellan deployment. En scraper som förlitar sig på en fast CSS-selektor som .product-card__price fungerar idag och ger tomma kolumner i morgon.
AI-baserade scrapers (som ) läser sidan semantiskt varje gång, så de är inte beroende av att specifika klassnamn förblir oförändrade.
Rate limiting och CAPTCHA-utmaningar
Om du träffar Temu för snabbt eller för många gånger från samma IP utlöser du rate limits eller CAPTCHA-utmaningar. Vissa verktyg hanterar detta med intelligent throttling och inbyggd CAPTCHA-lösning. Andra lämnar det åt dig — vilket för en icke-teknisk användare i praktiken är en återvändsgränd.
För molnscraping är nyckeln samtidiga förfrågningar utspridda över rena IP:er med automatisk retry-logik.
Bästa Temu-scrapers per färdighetsnivå: en komplett genomgång
Hitta din rad och hoppa till rätt avsnitt:
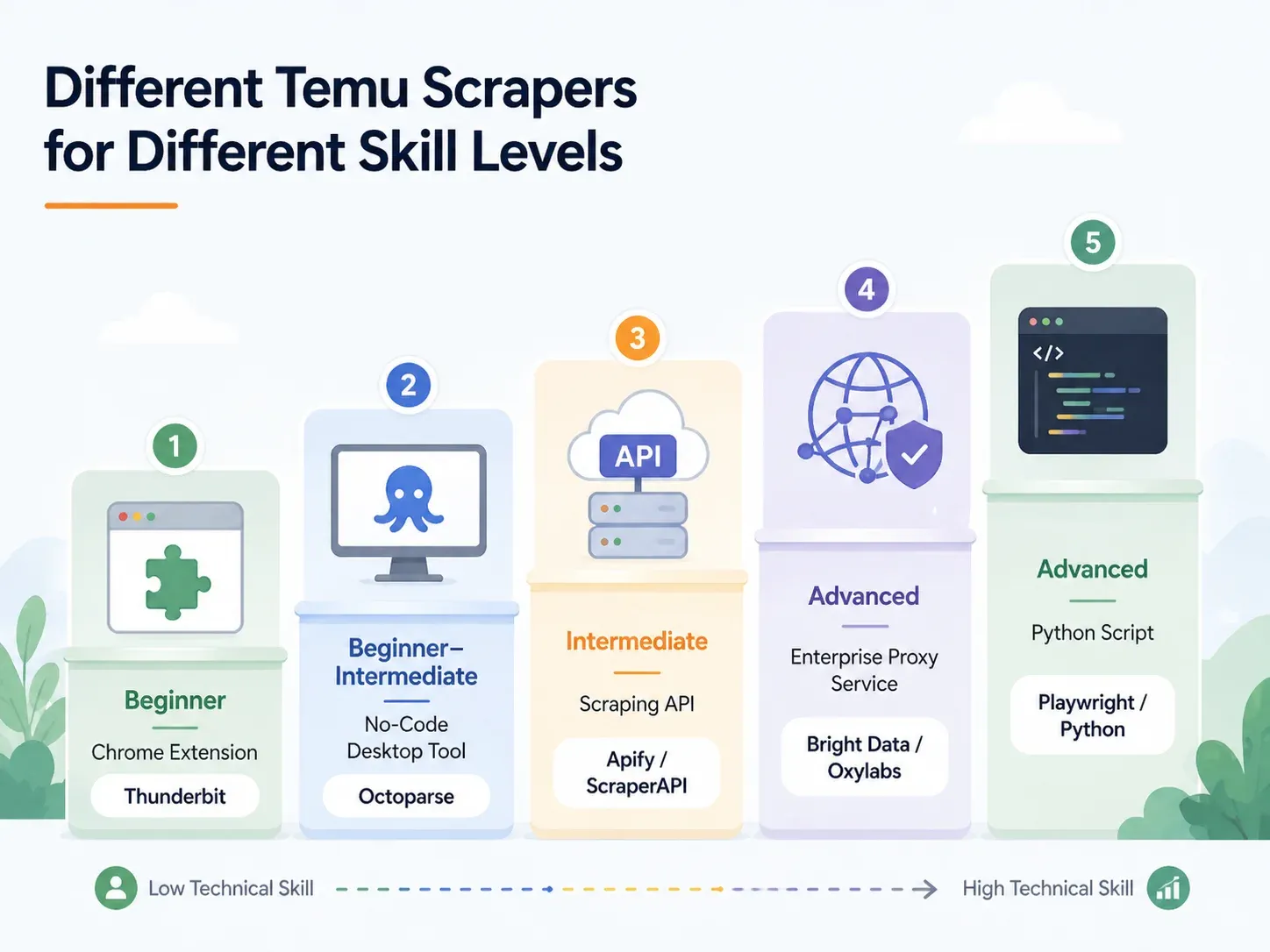
| Ansats | Färdighetsnivå | Installationstid | Hantering av anti-bot | Bäst för |
|---|---|---|---|---|
| AI Chrome-tillägg (t.ex. Thunderbit) | Nybörjare | < 2 min | Hanteras (moln eller webbläsare) | Dropshippare, marknadsförare, e-handelsteam |
| No-code desktopverktyg (t.ex. Octoparse, ParseHub) | Nybörjare–medel | 10–60 min | Delvis (proxykonfiguration behövs) | Regelbunden scraping med mallar |
| Scraping API/tjänst (t.ex. ScraperAPI, Apify) | Medel | 15–45 min | Inbyggt | Utvecklare som integrerar i pipelines |
| Hanterad proxy/enterprise (t.ex. Bright Data, Oxylabs) | Avancerad/Enterprise | Timmar–dagar | Full infrastruktur | Hög volym, leverans till datalager |
| Eget Python-skript (Playwright/Selenium) | Avancerad | 1–4 timmar+ | Manuellt (proxy + CAPTCHA-inställning) | Full kontroll, specialanpassning för edge-fall |
Thunderbit: bästa Temu-scraper för icke-tekniska användare
är ett AI-drivet Chrome-tillägg byggt för affärsanvändare — säljteam, e-handelsoperatörer, dropshippare, marknadsförare — som behöver strukturerad data från webbplatser utan att skriva kod. Jag arbetar på Thunderbit-teamet, så jag känner produkten väl. Jag ska vara rak med vad den gör och var den passar in.
Det centrala arbetsflödet är två klick: öppna en Temu-sida, klicka på AI Suggest Fields, granska de föreslagna kolumnerna (produktnamn, pris, bild, betyg osv.) och klicka sedan på Scrape.
Thunderbits AI läser sidstrukturen och föreslår kolumnnamn och datatyper automatiskt. Den förlitar sig inte på fasta CSS-selektorer, så när Temu ändrar sina klassnamn eller kortlayout anpassar sig scrapers.
Nyckelfunktioner för Temu:
- Molnscrapingläge: Snabbare för offentliga sidor, behandlar upp till 50 sidor åt gången. Bäst för kategorisidor, sökresultat och produktlistningar som inte kräver inloggning.
- Webbläsarscrapingläge: Använder din nuvarande Chrome-session, inklusive cookies, språk/region och inloggningsstatus. Bäst när region, popup-fönster eller inloggat innehåll påverkar vad sidan visar.
- Scrape Subpages: Efter att du har skrapat en listningssida klickar du på "Scrape Subpages" för att besöka varje produkts detaljsida och lägga till kolumner som fullständig beskrivning, varianter, säljarinfo, leveransestimat och specifikationer — utan extra konfiguration.
- Field AI Prompts: Kategorisera, översätt eller omformatera data under scraping. Till exempel: "Kategorisera den här produkten som Kitchen Utensils, Small Appliances, Storage eller Other."
- Schemalagd scraping: Ställ in ett schema i naturligt språk ("varje måndag kl. 9"), ange URL:er, och Thunderbit kör scraping i molnet och exporterar till Google Sheets, Airtable eller ett annat mål.
- Gratis export: Excel, CSV, Google Sheets, Airtable, Notion, JSON — ingen betalvägg för export. Bilder exporteras som faktiska bilagor i Airtable och Notion.
Priser: gratis nivå med upp till 6 sidor (eller 10 med en provboost); betalda planer börjar runt för 500 credits, där 1 credit = 1 outputrad.
Sida vid sida: Thunderbit jämfört med ett Python-skript på samma Temu-sida
Kontrasten är tydlig:
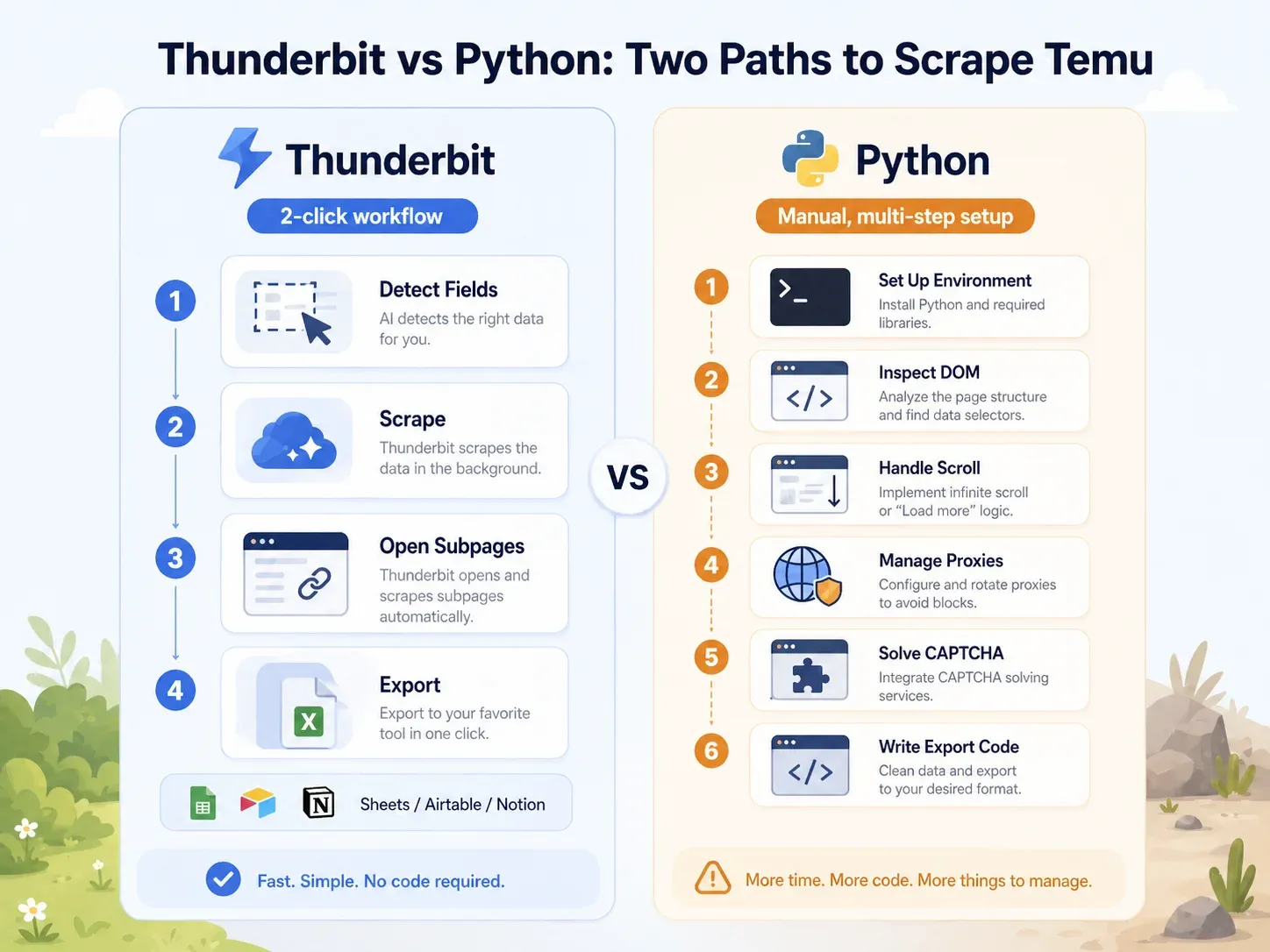
| Uppgift | Thunderbit | Python (Playwright) |
|---|---|---|
| Öppna Temu-kategorisida | Öppna sidan i Chrome | Sätt upp Python-miljö, installera Playwright, installera webbläsare |
| Identifiera fält | Klicka på "AI Suggest Fields" | Inspektera DOM, nätverksanrop, JSON-payloads |
| Hantera dynamisk laddning | Webbläsar-/molnläge + paginering | Skriv logik för scroll/wait, intercepta förfrågningar |
| Hantera blockeringar | Prova molnläge eller webbläsarläge | Lägg till proxies, headers, fingerprinting, retries, CAPTCHA |
| Extrahera listningsfält | Klicka på "Scrape" | Skriv selektorer eller logik för API-parsning |
| Berika produktsidor | Klicka på "Scrape Subpages" | Bygg en separat PDP-crawler |
| Exportera | Klicka Sheets/Airtable/Notion/Excel | Skriv integrationskod för CSV/JSON/Sheets |
| Typisk installation för en affärsanvändare | Under 2 minuter | Minst 1–4 timmar; löpande underhåll |
Ett minimalt Playwright-prototyp för Temu kan se ut så här (pseudokod — inte produktionsklart):
1from playwright.sync_api import sync_playwright
2with sync_playwright() as p:
3 browser = p.chromium.launch(headless=False)
4 page = browser.new_page()
5 page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
6 page.wait_for_load_state("networkidle")
7 for _ in range(8):
8 page.mouse.wheel(0, 2000)
9 page.wait_for_timeout(1200)
10 cards = page.locator("[data-product-id], a[href*='goods.html']")
11 # Produktionskod behöver fortfarande selektorer, proxies, retries,
12 # CAPTCHA-hantering, PDP-crawling och exportlogik.
13 print(cards.count())Det är 10+ rader innan du har extraherat ett enda fält, och du har inte ens rört proxies, CAPTCHA, PDP-berikning eller export. För en icke-teknisk användare komprimerar Thunderbit hela det arbetsflödet till ett par klick. För en utvecklare ger Python-vägen mer kontroll — men till en betydligt högre underhållskostnad.
Octoparse och ParseHub: no-code desktop-scrapers för Temu
Om du vill ha mer kontroll än ett Chrome-tillägg men inte vill skriva kod är Octoparse och ParseHub de främsta alternativen.
Octoparse har en offentlig Temu Details Scraper-mall. Dess exempelutdata innehåller produkt-ID:n, titlar, priser, säljar-/butiksdata, bild-URL:er, rabatter, butik-URL:er och detaljerade specifikationer. Det är en verklig fördel — du kan börja med en mall i stället för att bygga ett arbetsflöde från grunden. Octoparse stöder också molnextraktion, schemaläggning och visuell byggnad av arbetsflöden.
Brasklapparna för Temu:
- Anti-bot-tillägg (residential proxies till , CAPTCHA-lösning till $1–$1,50 per tusen) kan snabbt bli dyra.
- Mallar kan gå sönder när Temu ändrar sin layout. Du kan behöva uppdatera selektorer eller vänta på att Octoparse underhåller mallen.
- Installationen tar 10–60 minuter beroende på sidans komplexitet.
Octoparse-priser: gratis plan med 10 tasks och 50K månatlig dataexport; Standard runt $75/månad årsvis; Professional runt $108/månad årsvis. Tillägg för proxies, CAPTCHA och hanterade tjänster kostar extra.
ParseHub är en visuell desktop-/webbscraper som hanterar dynamiska sidor bra (den kör en full Chromium-browser). Betalda planer börjar dock på $189/månad, vilket är högt för en ensam operatör. Ingen stark offentlig Temu-specifik mall hittades i min research. ParseHub passar bättre för team som redan är bekväma med att bygga visuella scrapingprojekt.
| Verktyg | Styrkor för Temu | Svagheter på Temu | Pris |
|---|---|---|---|
| Octoparse | Offentlig Temu-mall, visuellt arbetsflöde, molnextraktion, schemaläggning | Mallunderhåll, anti-bot-tillägg ökar kostnaden | Gratis; cirka $75/mån årsvis Standard; cirka $108/mån årsvis Pro; tillägg extra |
| ParseHub | Hantering av dynamiska sidor, projektbyggare, IP-rotation i betalda planer | Högre startpris, ingen offentlig Temu-mall hittades | Betalda planer från $189/mån |
Scraping-API:er: ScraperAPI, Apify och Bright Data för Temu
API-baserade scrapingtjänster hanterar proxies, rendering och anti-bot-logik så att utvecklare kan fokusera på att parsa och lagra data. De passar när du bygger en pipeline, inte kör en engångsexport till ett kalkylblad.
ScraperAPI är ett utvecklar-API för proxyrotation och rendering. På prissidan listas en 7-dagars provperiod med 5 000 credits, Hobby för $49/månad för 100 000 credits och högre nivåer därifrån. Knäckfrågan för Temu: JavaScript-rendering och premium proxy-pooler kostar 10–75 credits per förfrågan beroende på nivå. Den kreditmultiplikationen gör att din effektiva kostnad per rad kan bli mycket högre än rubrikpriset.
Apify är en plattform med en marknadsplats för färdigbyggda "actors" (scrapers). Flera Temu-actors finns. En Temu Scraper som underhålls av communityn listar pay-per-event-prissättning kring $5 per 1 000 produkter på gratisnivån. En annan Temu Products Scraper listar $4 per 1 000 resultat. Risken: kvaliteten varierar, underhållet är beroende av communityn och vissa actors kan vara föråldrade eller gå sönder när Temu uppdaterar. Kontrollera alltid "last modified"-datumet och användarbetygen innan du bestämmer dig.
Bright Data är enterprise-alternativet. Deras Temu-scraper-sida säger att jobb körs på Bright Data-infrastruktur med proxyrotation, geo-targeting, CAPTCHA-/unblocking-logik och autoskalning. Utdataformaten inkluderar JSON, CSV, Parquet och direktleverans till S3, GCS, Azure Blob, BigQuery och Snowflake. Branschgranskningar rapporterar att Web Scraper API pay-as-you-go ligger runt $2,5 per 1 000 poster, med avtalade planer från omkring $499/månad. Kraftfullt, men prissatt för team med riktiga budgetar.
Oxylabs har också en dedikerad Temu Scraper API-sida. Planer börjar på $49/månad, med gratis provperiod upp till 2 000 resultat. Det är ett starkt alternativ till Bright Data för utvecklingsteam som vill ha strukturerad Temu-data via API.
| API/plattform | Temu-specifik evidens | Styrka | Svaghet | Bäst för |
|---|---|---|---|---|
| ScraperAPI | Ingen Temu-specifik sida hittades, men anti-bot-funktioner för e-handel dokumenterade | Enkel endpoint, JS-rendering, premium proxies | Kreditmultiplikatorer för premiumfunktioner; utvecklaren måste parsa data | Developer pipelines |
| Apify | Flera Temu-actors i marknadsplatsen | Snabbaste utvecklarvägen om actor matchar och underhålls | Kvaliteten varierar; vissa är föråldrade | Utvecklare som vill ha actor-marknadsplats + schemaläggning |
| Bright Data | Dedikerad Temu-scraper-sida | Enterprise-infrastruktur, unblocking, leverans till datalager | Dyrt; web scraping-begrepp krävs fortfarande | Datateam på enterprise-nivå |
| Oxylabs | Dedikerad Temu Scraper API-sida | Tydlig prissättning per resultat, JS-hantering, IP/CAPTCHA-påståenden | Utvecklar-API-arbetsflöde | Utvecklingsteam som behöver Temu-API-access |
Egna Python-skript (Playwright/Selenium): full kontroll, hög arbetsinsats
Egna Python-scrapers ger maximal flexibilitet — det är fördelen. Playwright är generellt en bättre startpunkt än Selenium för Temu tack vare sin auto-wait-modell och bättre hantering av JavaScript-tunga sidor.
Men avvägningen är brutal.
En prototyp tar 1–4 timmar. En produktionsklar scraper behöver proxyrotation, realistiska webbläsarfingeravtryck, CAPTCHA-strategi, retries, schemavalidering, lagring av output, övervakning, larm och juridisk granskning.
Och den går sönder. Reddit-communityn kring scraping beskriver om och om igen modern e-handelsscraping som instabil när sajter använder Cloudflare, JavaScript-rendering och anti-bot-fingeravtryck.
| Feltyp | Typisk orsak | Motåtgärd |
|---|---|---|
| Tom HTML / saknade produkter | JS laddar produktkort efter initial HTML | Använd Playwright, vänta på nätverk och DOM |
| Bara de första produkterna | Oändlig scroll / lazy loading | Scroll-loop, vänta på nätverksinaktivitet, tröskel för antal kort |
| Priser saknas eller är inkonsekventa | Region-/sessions-/valutastatus eller anti-bot-svar | Sätt locale, cookies, geotargeted proxy |
| 403 / challenge / CAPTCHA | IP-rykte, headless-fingeravtryck, förfrågningshastighet | Residential proxies, stealth-browser, lägre takt |
| Selektorbrott | DOM-/klassändringar, A/B-testning | Semantisk extraktion eller API-parsning om möjligt |
Egna skript är inte det "gratis" alternativet. De flyttar kostnaden från abonnemangsavgifter till utvecklartid, proxykostnader, CAPTCHA-kostnader och underhållsrisk. Om du har en scrapingingenjör i teamet och behöver ovanlig logik är detta rätt väg. För alla andra är det i praktiken det dyraste alternativet.
Bästa praxis: undersidescraping för komplett Temu-produktdata
Det här är den enskilt mest effektfulla bästa praxisen i artikeln — och nästan ingen annan guide tar upp den.
En Temu-kategori- eller söksida visar grunderna: titel, miniatyr, pris, ungefärligt betyg. Men de fält som faktiskt gör en rad användbar — detaljerade beskrivningar, varianter, fullständiga recensionstal, leveransestimat, säljar-namn, specifikationstabeller — finns på produktens detaljsida (PDP).
Om du bara skrapar listningssidan arbetar du med ett ofullständigt dataset.
Tvåstegsflödet:
- Steg 1 — Scrapa listningssidan (PLP): Extrahera produktnamn, pris, miniatyr och betyg från en Temu-sök- eller kategorisida.
- Steg 2 — Berika via undersidescraping: Besök varje produkts PDP och lägg till kolumner som fullständig beskrivning, antal recensioner, variantalternativ, leveranstid och säljarinfo.
Så här ser datan ut före och efter:
| Fält | Från PLP (Steg 1) | Tillagt från PDP (Steg 2) |
|---|---|---|
| Produkttitel | ✅ | — |
| Pris | ✅ | ✅ (verifierat / rabatt %) |
| Miniatyrbild | ✅ | — |
| Stjärnbetyg | ✅ | ✅ (med antal recensioner) |
| Fullständig beskrivning | ❌ | ✅ |
| Varianter (storlekar, färger) | ❌ | ✅ |
| Säljarens namn | ❌ | ✅ |
| Leveransestimat | ❌ | ✅ |
| Detaljerade specifikationer | ❌ | ✅ |
I Thunderbit är detta ett klick: efter din första scraping klickar du på "Scrape Subpages". AI:n besöker varje produkt-URL och lägger till de extra kolumnerna — ingen extra konfiguration, ingen separat spider, inget selektorunderhåll. Octoparse Temu Details-mall och Apifys Temu-actor stöder också fält på PDP-nivå, men med mer installation och underhåll. I Python skulle du behöva bygga en separat PDP-crawler, underhålla dess selektorer och hantera paginering inne på detaljsidorna — en betydande extra investering.
Bästa praxis: schemalagd Temu-scraping för löpande pris- och lagerövervakning
Engångsscraping är användbar för produktupptäckt. Konkurrensbevakning kräver upprepad observation.
Priser ändras, produkter tar slut, nya artiklar dyker upp dagligen och rabattdjupet skiftar med kampanjer. En veckovis eller daglig scraping skapar en historiktabell som teamet faktiskt kan agera på.
Tre användningsfall som är värda att automatisera:
- Prisövervakning: Följ en konkurrents 50 viktigaste Temu-SKU:er varje vecka. Få uppdaterade priser automatiskt exporterade till Google Sheets för en snabb jämförelse med din egen prissättning.
- Lager- och tillgänglighetsövervakning: Upptäck när en trendande produkt tar slut, en ny variant dyker upp eller leveransestimat ändras.
- Upptäckt av nya produkter/trender: Schemalägg en daglig scraping av Temus "New Arrivals" eller en prioriterad kategorisida. Sortera efter antal sålda eller antal recensioner för att tidigt få syn på produkter som stiger.
I Thunderbit ställer du in detta genom att beskriva intervallet i naturligt språk ("varje måndag kl. 9"), ange dina mål-URL:er och klicka på "Schedule." Scrapen körs i molnet och exporteras till ditt valda mål. Eftersom AI:n läser sidan på nytt varje gång anpassar sig schemalagda scrapes automatiskt till Temus layoutändringar — du behöver inte uppdatera selektorer när Temu designar om ett produktkort.
Alternativet: sätt upp ett cron-jobb, underhåll ett Python-skript, konfigurera proxyrotation, bygg en exportpipeline och fixa selektorer varje gång Temu ändrar layout. För ett icke-tekniskt team är det inte realistiskt. För en utvecklare innebär det löpande overhead. Apify och Bright Data stödjer också schemalagda körningar, men med mer teknisk installation och högre kostnadsnivåer.
Bästa praxis: Temu-dataflödet från början till slut (Scrapa → Rensa → Exportera → Agera)
De flesta scrapingguider slutar vid "ladda ner CSV."
Men affärsanvändare behöver data inne i de verktyg de faktiskt jobbar i — Google Sheets för samarbete, Airtable för produktdatabaser, Notion för teamdashboards. Den verkliga bästa praxisen är ett heltäckande arbetsflöde:
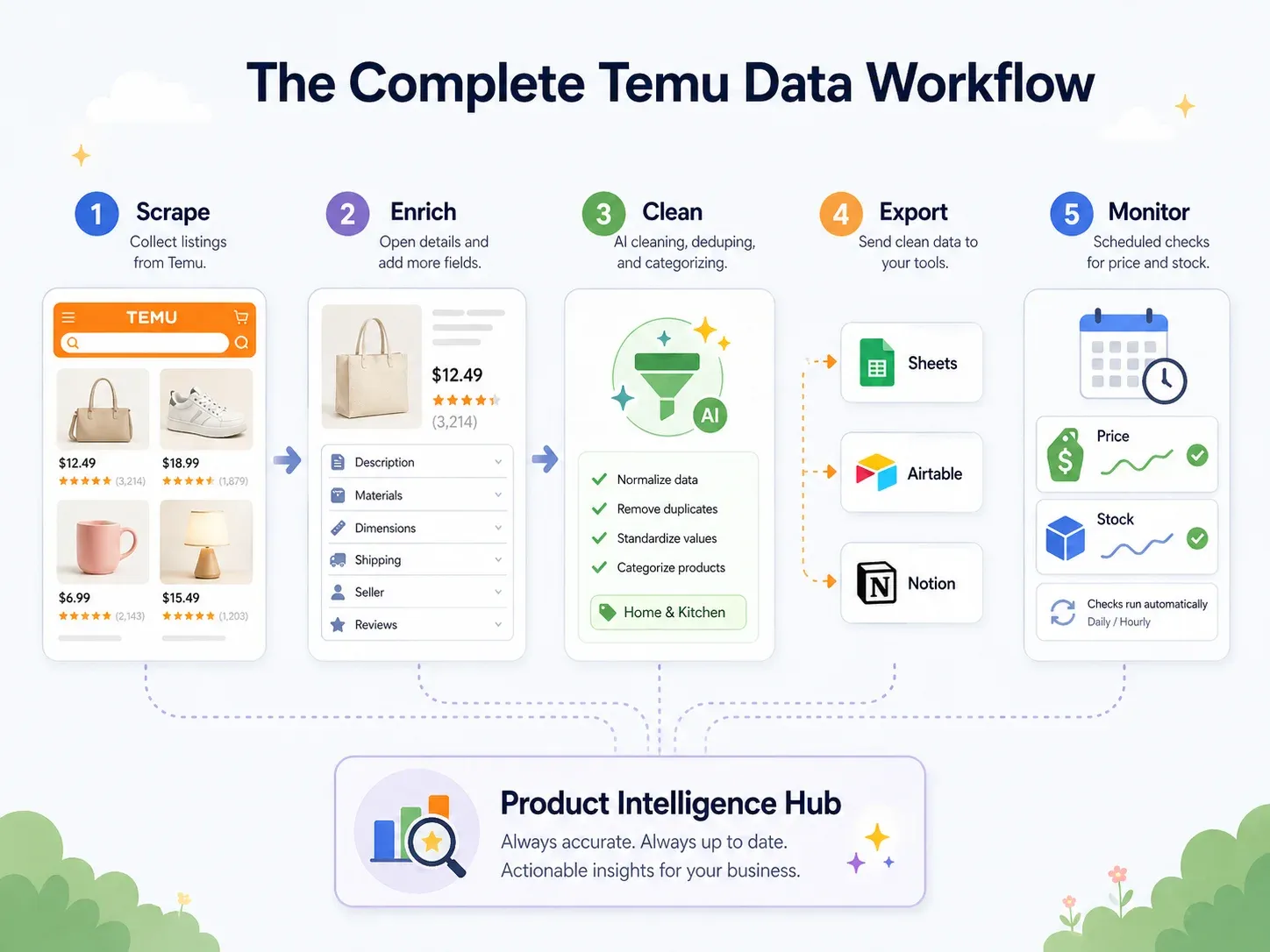
| Steg i arbetsflödet | Vad som händer | Thunderbit-funktion |
|---|---|---|
| Scrapa | Extrahera data från Temu-sidor | AI Suggest Fields → Scrape (2 klick) |
| Berika | Besök varje produkts detaljsida | Scrape Subpages (1 klick) |
| Rensa & märka | Kategorisera produkter, normalisera priser, översätt titlar | Field AI Prompt — märka, formatera, översätta under scraping |
| Exportera | Skicka data till affärsverktyg | Gratis export till Excel, Google Sheets, Airtable, Notion; ladda ner CSV/JSON |
| Övervaka | Följ förändringar över tid | Scheduled Scraper med naturliga språkintervall |
Här är ett konkret exempel: Du scrapar 200 Temu-produkter för kök. Under scrapen kategoriserar en Field AI Prompt automatiskt varje produkt i "Utensils / Small Appliances / Storage / Cleaning / Decor." Priserna normaliseras till numeriska USD-värden. Kinesiska produkttitlar översätts till engelska. Datan exporteras direkt till en Airtable-bas med produktbilder intakta (inte bara URL:er — faktiska bildbilagor, som beskrivs i ). En schemalagd scraping uppdaterar datan varje vecka.
Några användbara Field AI Prompt-instruktioner för Temu-data:
- "Kategorisera den här produkten som en av: Kitchen Utensils, Small Appliances, Storage, Cleaning, Decor, Other. Returnera bara kategorin."
- "Översätt produkttiteln till kortfattad engelska samtidigt som varumärken, mängder, storlekar och modellnummer bevaras."
- "Normalisera priset som ett tal utan valutasymboler."
- "Märk efterfrågan som High, Medium eller Low baserat på betyg, antal recensioner och antal sålda. Om data saknas, returnera Unknown."
Det här arbetsflödet förvandlar en rå scraping till en levande databas för produktintelligens — utan att en utvecklare bygger en separat ETL-pipeline.
Bästa Temu-scrapers jämförda: tabell sida vid sida
| Verktyg | Färdighetsnivå | Installationstid | Hantering av anti-bot | Undersidescraping | Schemaläggning | Exportalternativ | Prisnivå | Bäst för |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Nybörjare | Minuter | Webbläsarläge, molnläge, AI-fältdetektering | Ja (Scrape Subpages) | Ja (scheman i naturligt språk) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratis 6 sidor; betalt från cirka $9–15/mån för 500 credits | Icke-tekniska e-handelsteam, dropshippare |
| Octoparse | Nybörjare–medel | 10–60 min | Molnextraktion, proxy/CAPTCHA-tillägg | Ja (mallarbetsflöden) | Ja (betalda/molnplaner) | Excel, CSV, JSON, HTML, XML, databas, Google Sheets | Gratis; cirka $75/mån årsvis Standard; tillägg extra | Operatörer som vill ha visuella arbetsflöden + Temu-mall |
| ParseHub | Nybörjare–medel | 30–60 min | Dynamisk rendering, betald IP-rotation | Ja (projektflöden) | Betalda planer | CSV/JSON, Dropbox/S3 i betalda planer | Betalt från $189/mån | Team som bygger visuella projekt för dynamiska sajter |
| ScraperAPI | Utvecklare | Timmar | Proxyrotation, JS-rendering, premium-pooler | Kodas själv | DataPipeline/schemaläggare | HTML/JSON/CSV | Provperiod 5K credits; Hobby $49/mån; högre nivåer finns | Utvecklare som bygger egna Temu-pipelines |
| Apify | Medel | 10–30 min om actor passar | Actor-specifik webbläsar-/proxylogik | Beror på actor | Ja | JSON, CSV, Excel, API/datasets | Gratis plattform; Temu-actors cirka $4–5/1K produkter | Utvecklare/operatörer som kan granska actor-kvalitet |
| Bright Data | Avancerad/Enterprise | Timmar–dagar | Full proxy, CAPTCHA, unblocking, autoskalning | Kodas själv via scraper/API | Ja | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | Cirka $2,5/1K poster PAYG; avtal från cirka $499/mån | Enterprise-datateam, högvolymsuttag |
| Oxylabs | Avancerad | Timmar | JS-hantering, IP/CAPTCHA-påståenden | Kodas själv via API | Ja | JSON/API-utdata | Från $49/mån; provperiod upp till 2K resultat | Utvecklingsteam som behöver Temu-API-access |
| Custom Python (Playwright) | Avancerad | 1–4 timmar+; löpande underhåll | Manuella proxies, CAPTCHA, fingeravtryck | Helt anpassad | Cron/kö/manuellt | Anpassat | Utvecklarstid + proxy-/CAPTCHA-/hostkostnader | Edge-fall, team med scrapingingenjörer |
Vilken Temu-scraper ska du välja? Snabba rekommendationer
- Dropshippare som behöver snabb produktresearch? Börja med . Det är snabbaste vägen från "jag vill ha Temu-data" till "jag har ett kalkylblad." Om det fungerar på dina målsidor (och det bör göra det för de flesta offentliga kategori- och produktsidor) är du klar.
- Operatör som vill ha visuell kontroll och återanvändbara mallar? Octoparse har en offentlig Temu Details-mall och en visuell byggare för arbetsflöden. Räkna med 10–30 minuters installation och en del proxy-/CAPTCHA-konfiguration.
- Utvecklare som bygger en datapipeline eller ett internt verktyg? ScraperAPI eller Apify ger dig API-/actor-flöden som integreras med kod och schemalagda jobb. Granska Apify-actors noggrant — kolla underhållsstatus och användarbetyg.
- Enterprise-team som behöver Temu-data i hög volym och leverans till datalager? Bright Data är infrastrukturalternativet. Dyrt, men hanterar skala, unblocking och leverans till S3/BigQuery/Snowflake.
- Scrapingingenjör som behöver ovanlig logik? Egen Playwright/Selenium ger full kontroll. Budgetera bara för löpande underhåll, proxykostnader och CAPTCHA-hantering.
För de flesta icke-tekniska affärsanvändare rekommenderar jag att du testar Thunderbits gratisnivå först. Den omedelbara frågan är alltid "kan jag få de rader jag behöver från just den här Temu-sidan?" — och det kan du ta reda på på under två minuter utan att spendera någonting. För utvecklare: kör ett kostnad-per-framgångsrad-test över Apify, ScraperAPI och ett litet Playwright-prototyp innan du låser budget.
Vanliga frågor om att scrapa Temu
Är det lagligt att scrapa Temu?
Det beror på jurisdiktion, vilken data du samlar in, hur du får åtkomst och hur du använder datan. Temus begränsar uttryckligen automatiserad åtkomst, inklusive crawling, scraping eller spidering av sidor eller data. Amerikanska domstolar har gett viss gynnsam praxis för åtkomst till offentligt tillgänglig data (Ninth Circuits hiQ v. LinkedIn-beslut), men har också upprätthållit krav på avtalsbrott och intrång. Det korta svaret: att scrapa offentligt tillgänglig produktdata för forskning kan vara försvarbart i vissa sammanhang, men användarvillkor, integritetslagstiftning, upphovsrätt och hur du använder datan spelar alla roll. Detta är inte juridisk rådgivning — rådfråga jurist vid kommersiell användning.
Hur ofta ändrar Temu sin webbplatslayout?
Ingen offentlig frekvens har dokumenterats. Communityrapporter och verktygsekosystemet behandlar Temu som ett dynamiskt, ofta uppdaterat mål. Räkna med att CSS-selektorer kan gå sönder när som helst, och föredra AI-/semantisk extraktion eller aktivt underhållna mallar framför hårdkodade selektorer.
Kan jag scrapa Temu utan att bli blockerad?
För begränsade offentliga sidor med ansvarsfull takt, ja — särskilt med verktyg som har riktig webbläsarrendering, sessionsstöd och throttling. Inget verktyg ska ses som en universell garanti. Molnscraping med roterande IP:er fungerar bra för offentliga katalogsidor; webbläsarscraping med din nuvarande session fungerar bättre när region, inloggning eller popup-fönster påverkar datan.
Vilken data kan jag extrahera från Temus produktsidor?
Vanliga offentliga fält inkluderar produkttitel, URL, aktuellt pris, ursprungspris, rabattprocent, bild-URL:er, stjärnbetyg, antal recensioner, antal sålda, säljar-/butiksnamn, fraktinformation, kategori, produktspecifikationer, varianter (färger, storlekar) och tidsstämpel för scraping. De exakta fälten som finns beror på sidtyp (listning kontra detaljsida) och region.
Behöver jag proxies för att scrapa Temu?
För liten manuell scraping i webbläsarläge (några sidor åt gången) kanske du inte behöver det. För molnbaserad, schemalagd eller högvolymsinsamling är proxies eller hanterad anti-blockeringsinfrastruktur vanligtvis nödvändigt. Verktyg som Thunderbit, Bright Data och ScraperAPI paketerar proxyhantering i sina plattformar så att du slipper konfigurera det separat.
Om du vill fördjupa dig i närliggande ämnen kan du läsa våra guider om , , och . Du kan också se genomgångar på .
Läs mer