
Trasiga länkar. Föräldralösa sidor. En gammal “test”-sida från 2019 som Google av någon anledning lyckats indexera. Om du har ansvar för en webbplats känner du igen den där frustrationen.
En bra webbplats-crawler fångar upp allt sånt – och ritar upp hela sajten så att du faktiskt kan fixa problemen. Men många blandar ihop “web crawler” med “web scraper”. Det är två olika grejer.
Jag har testat 10 gratis crawlers på riktiga webbplatser. Vissa är klockrena för SEO-granskningar. Andra passar bättre för datautvinning. Här är vad som faktiskt funkade – och vad som inte gjorde det.
Vad är en webbplats-crawler? Grunderna du behöver
Vi tar det direkt: en website crawler är inte samma sak som en web scraper. Jag fattar – begreppen kastas runt lite hur som helst, men de har helt olika jobb. Tänk en crawler som sajtens kartograf: den går igenom varje hörn, följer varje länk och bygger en karta över alla sidor. Målet är upptäckt: hitta URL:er, förstå strukturen och indexera innehåll. Det är i princip det sökmotorer som Google gör med sina botar – och det SEO-verktyg använder för att kolla sajtens hälsa ().
En web scraper är däremot mer som en data-letare. Den bryr sig inte om hela kartan – den vill åt guldet: produktpriser, företagsnamn, recensioner, e-postadresser, you name it. Scrapers plockar ut specifika fält från sidorna som crawlers hittar ().
En snabb liknelse:
- Crawler: Personen som går igenom varje gång i mataffären och inventerar allt som finns.
- Scraper: Personen som går rakt till kaffehyllan och skriver ner priset på varje ekologisk blandning.
Varför spelar det här någon roll? För att om du bara vill hitta alla sidor på din webbplats (t.ex. för en SEO-audit) behöver du en crawler. Om du vill hämta alla produktpriser från en konkurrents sajt behöver du en scraper – eller helst ett web crawler-verktyg som klarar båda.
Varför använda en online web crawler? Viktiga affärsfördelar
Varför lägga tid på web crawling överhuvudtaget? För att webben inte direkt blir mindre. Faktum är att över för att optimera sina sajter, och vissa SEO-verktyg crawlar [7 miljarder] sidor varje dag (https://martechvibe.com/article/top-10-web-crawler-platforms/#:~:text=Link%20Assistant%E2%80%99s%20website%20auditor%20SEO,Audi%2C%20Microsoft%2C%20IBM%2C%20and%20MasterCard).
Det här kan crawlers hjälpa dig med:
- SEO-audits: Hitta trasiga länkar, saknade titlar, duplicerat innehåll, föräldralösa sidor och mer ().
- Länkkontroll & QA: Fånga 404:or och omdirigeringsloopar innan användarna gör det ().
- Skapa sitemaps: Generera XML-sitemaps automatiskt för sökmotorer och planering ().
- Innehållsinventering: Bygg en lista över alla sidor, deras hierarki och metadata.
- Efterlevnad & tillgänglighet: Kontrollera varje sida mot WCAG, SEO och juridiska krav ().
- Prestanda & säkerhet: Flagga långsamma sidor, för stora bilder eller säkerhetsproblem ().
- Data för AI & analys: Mata crawlad data till analys- eller AI-verktyg ().
Här är en snabb tabell som kopplar användningsfall till roller:
| Användningsfall | Passar bäst för | Nytta / resultat |
|---|---|---|
| SEO & sajtgranskning | Marknad, SEO, småföretagare | Hitta tekniska problem, optimera struktur, förbättra ranking |
| Innehållsinventering & QA | Content managers, webbansvariga | Granska eller migrera innehåll, hitta trasiga länkar/bilder |
| Leadgenerering (scraping) | Sälj, affärsutveckling | Automatisera prospektering, fyll CRM med färska leads |
| Konkurrentbevakning | E-handel, produktchefer | Bevaka konkurrentpriser, nya produkter, lagerförändringar |
| Sitemap & strukturkloning | Utvecklare, DevOps, konsulter | Klona struktur för redesign eller backup |
| Innehållsaggregering | Forskare, media, analytiker | Samla data från flera sajter för analys eller trendbevakning |
| Marknadsanalys | Analytiker, AI-tränings-team | Samla stora datamängder för analys eller AI-modellträning |
()
Så valde vi de bästa gratisverktygen för webbplats-crawling
Jag har lagt många sena kvällar (och mer kaffe än jag vill erkänna) på att testa web crawler-verktyg, plöja dokumentation och köra provcrawls. Det här var mina kriterier:
- Teknisk kapacitet: Klarar den moderna sajter (JavaScript, inloggningar, dynamiskt innehåll)?
- Användarvänlighet: Funkar den för icke-tekniska användare, eller krävs terminal-magi?
- Begränsningar i gratisplanen: Är den verkligen gratis – eller bara en teaser?
- Tillgänglighet online: Är det ett molnverktyg, en desktop-app eller ett kodbibliotek?
- Unika funktioner: Gör den något extra – som AI-extraktion, visuella sitemaps eller händelsestyrd crawling?
Jag testade varje verktyg, kollade användarfeedback och jämförde funktioner sida vid sida. Om ett verktyg fick mig att vilja kasta ut datorn genom fönstret, hamnade det inte på listan.
Snabb jämförelse: 10 bästa gratis webbplats-crawlers
| Verktyg & typ | Kärnfunktioner | Bästa användningsfall | Tekniska krav | Gratisplan |
|---|---|---|---|---|
| BrightData (Moln/API) | Enterprise-crawling, proxies, JS-rendering, CAPTCHA-lösning | Datainsamling i stor skala | Viss teknisk vana hjälper | Gratis test: 3 scrapers, 100 poster vardera (ca 300 poster totalt) |
| Crawlbase (Moln/API) | API-crawling, anti-bot, proxies, JS-rendering | Utvecklare som behöver backend-infrastruktur | API-integration | Gratis: ~5 000 API-anrop i 7 dagar, sedan 1 000/månad |
| ScraperAPI (Moln/API) | Proxy-rotation, JS-rendering, asynkron crawling, färdiga endpoints | Utvecklare, prisbevakning, SEO-data | Minimal setup | Gratis: 5 000 API-anrop i 7 dagar, sedan 1 000/månad |
| Diffbot Crawlbot (Moln) | AI-crawl + extraktion, knowledge graph, JS-rendering | Strukturerad data i skala, AI/ML | API-integration | Gratis: 10 000 credits/månad (ca 10k sidor) |
| Screaming Frog (Desktop) | SEO-audit, länk/meta-analys, sitemap, anpassad extraktion | SEO-audits, sajtansvariga | Desktop-app, GUI | Gratis: 500 URL:er per crawl, endast grundfunktioner |
| SiteOne Crawler (Desktop) | SEO, prestanda, tillgänglighet, säkerhet, offline-export, Markdown | Utvecklare, QA, migrering, dokumentation | Desktop/CLI, GUI | Gratis & open source, 1 000 URL:er i GUI-rapport (konfigurerbart) |
| Crawljax (Java, OpenSrc) | Händelsestyrd crawl för JS-tunga sajter, statisk export | Utvecklare, QA för dynamiska webbappar | Java, CLI/konfig | Gratis & open source, inga gränser |
| Apache Nutch (Java, OpenSrc) | Distribuerad, plugin-baserad, Hadoop-integration, egen sök | Egna sökmotorer, storskalig crawl | Java, kommandorad | Gratis & open source, endast infrastrukturkostnad |
| YaCy (Java, OpenSrc) | Peer-to-peer crawl & sök, integritet, index för webb/intranät | Privat sök, decentralisering | Java, webbläsar-UI | Gratis & open source, inga gränser |
| PowerMapper (Desktop/SaaS) | Visuella sitemaps, tillgänglighet, QA, webbläsarkompatibilitet | Byråer, QA, visuell kartläggning | GUI, enkelt | Gratis test: 30 dagar, 100 sidor (desktop) eller 10 sidor (online) per scan |
BrightData: Molnbaserad webbplats-crawler i enterprise-klass

BrightData är “tungt artilleri” inom web crawling. Det är en molnplattform med ett enormt proxy-nätverk, JavaScript-rendering, CAPTCHA-lösning och en IDE för skräddarsydda crawls. Om du kör datainsamling i stor skala – tänk prisbevakning på hundratals e-handelssajter – är BrightDatas infrastruktur svårslagen ().
Styrkor:
- Klarar svåra sajter med anti-bot-skydd
- Skalar för enterprise-behov
- Färdiga mallar för vanliga sajter
Begränsningar:
- Ingen permanent gratisnivå (bara test: 3 scrapers, 100 poster vardera)
- Kan vara overkill för enkla audits
- Viss inlärningskurva för icke-tekniska användare
Behöver du crawla webben i stor skala är BrightData som att hyra en Formel 1-bil. Räkna bara inte med att den är gratis efter provturen ().
Crawlbase: API-styrd gratis web crawler för utvecklare

Crawlbase (tidigare ProxyCrawl) handlar om programmatisk crawling. Du anropar deras API med en URL och får tillbaka HTML – medan proxies, geotargeting och CAPTCHAs hanteras i bakgrunden ().
Styrkor:
- Hög träffsäkerhet (99%+)
- Klarar JS-tunga sajter
- Perfekt att bygga in i egna appar och flöden
Begränsningar:
- Kräver API- eller SDK-integration
- Gratisplan: ~5 000 API-anrop i 7 dagar, sedan 1 000/månad
Om du är utvecklare och vill crawla (och kanske även scrapa) i skala utan att hantera proxies själv är Crawlbase ett stabilt val ().
ScraperAPI: Gör dynamisk web crawling enklare

ScraperAPI är API:t som säger “låt mig bara hämta sidan”. Du skickar en URL, och tjänsten sköter proxies, headless browsers och anti-bot – och levererar HTML (eller strukturerad data för vissa sajter). Den är särskilt bra för dynamiska sidor och har en generös gratisnivå ().
Styrkor:
- Väldigt enkelt för utvecklare (bara ett API-anrop)
- Hanterar CAPTCHAs, IP-blockeringar och JavaScript
- Gratis: 5 000 API-anrop i 7 dagar, sedan 1 000/månad
Begränsningar:
- Inga visuella crawl-rapporter
- Du behöver själv skripta logiken om du vill följa länkar
Vill du få in web crawling i din kodbas på några minuter är ScraperAPI ett självklart val.
Diffbot Crawlbot: Automatisk upptäckt av webbplatsstruktur

Diffbot Crawlbot är där det blir riktigt smart. Den crawlar inte bara – den använder AI för att klassificera sidor och extrahera strukturerad data (artiklar, produkter, event osv.) till JSON. Som en robotpraktikant som faktiskt fattar vad den läser ().
Styrkor:
- AI-driven extraktion, inte bara crawling
- Klarar JavaScript och dynamiskt innehåll
- Gratis: 10 000 credits/månad (ca 10k sidor)
Begränsningar:
- Mer för utvecklare (API-integration)
- Inte ett visuellt SEO-verktyg – mer för dataprojekt
Behöver du strukturerad data i skala, särskilt för AI eller analys, är Diffbot en riktig kraftmaskin.
Screaming Frog: Gratis SEO-crawler för desktop

Screaming Frog är den klassiska desktop-crawlern för SEO-audits. Den crawlar upp till 500 URL:er per körning (gratisversionen) och ger dig allt: trasiga länkar, meta-taggar, duplicerat innehåll, sitemaps och mer ().
Styrkor:
- Snabb, grundlig och välkänd i SEO-världen
- Ingen kod krävs – ange URL och kör
- Gratis upp till 500 URL:er per crawl
Begränsningar:
- Endast desktop (ingen molnversion)
- Avancerade funktioner (JS-rendering, schemaläggning) kräver licens
Om du tar SEO på allvar är Screaming Frog nästan ett måste – men räkna inte med att crawla en sajt med 10 000 sidor gratis.
SiteOne Crawler: Export av statisk sajt och dokumentation

SiteOne Crawler är en schweizisk armékniv för tekniska granskningar. Den är open source, funkar på flera plattformar och kan crawla, auditera och till och med exportera sajten till Markdown för dokumentation eller offline-användning ().
Styrkor:
- Täcker SEO, prestanda, tillgänglighet och säkerhet
- Export för arkivering eller migrering
- Gratis & open source, utan användningsgränser
Begränsningar:
- Mer teknisk än vissa GUI-verktyg
- GUI-rapporten är som standard begränsad till 1 000 URL:er (kan ändras)
Är du utvecklare, QA eller konsult som vill ha ordentlig insyn (och gillar open source) är SiteOne en riktig doldis till pärla.
Crawljax: Open source Java-crawler för dynamiska sidor
Crawljax är en specialist: den är byggd för att crawla moderna, JavaScript-tunga webbappar genom att simulera användarbeteenden (klick, formulärifyllnad osv.). Den är händelsestyrd och kan till och med skapa en statisk version av en dynamisk sajt ().
Styrkor:
- Svårslagen för SPAs och AJAX-tunga sajter
- Open source och utbyggbar
- Inga användningsgränser
Begränsningar:
- Kräver Java och viss programmering/konfiguration
- Inte för icke-tekniska användare
Behöver du crawla en React- eller Angular-app som en riktig användare är Crawljax din vän.
Apache Nutch: Skalbar distribuerad webbplats-crawler

Apache Nutch är veteranen bland open source-crawlers. Den är byggd för enorma, distribuerade crawls – tänk att skapa en egen sökmotor eller indexera miljontals sidor ().
Styrkor:
- Skalar till miljarder sidor med Hadoop
- Väldigt konfigurerbar och utbyggbar
- Gratis & open source
Begränsningar:
- Brant inlärningskurva (Java, kommandorad, konfig)
- Inte för små sajter eller “casual” användning
Vill du crawla webben i stor skala och inte backar för kommandoraden är Nutch rätt verktyg.
YaCy: Peer-to-peer web crawler och sökmotor
YaCy är en udda fågel på bästa sätt: en decentraliserad crawler och sökmotor. Varje instans crawlar och indexerar sajter, och du kan gå med i ett peer-to-peer-nätverk för att dela index med andra ().
Styrkor:
- Integritetsfokus utan central server
- Bra för privat sök eller intranät-indexering
- Gratis & open source
Begränsningar:
- Resultaten beror på nätverkets täckning
- Kräver viss setup (Java, webbläsar-UI)
Om du gillar decentralisering eller vill bygga din egen sökmotor är YaCy ett riktigt spännande alternativ.
PowerMapper: Visuell sitemap-generator för UX och QA

PowerMapper handlar om att göra sajtens struktur tydlig för ögat. Den crawlar webbplatsen och skapar interaktiva sitemaps, och den kollar även tillgänglighet, webbläsarkompatibilitet och grundläggande SEO ().
Styrkor:
- Visuella sitemaps är guld för byråer och designers
- Kontrollerar tillgänglighet och efterlevnad
- Enkelt GUI – inga tekniska kunskaper krävs
Begränsningar:
- Endast gratis test (30 dagar, 100 sidor desktop/10 sidor online per scan)
- Fullversionen är betald
Behöver du visa upp en sitemap för kunder eller dubbelkolla efterlevnad är PowerMapper ett smidigt val.
Så väljer du rätt gratis web crawler för dina behov
Med så många alternativ – hur väljer man rätt? Här är min snabbguide:
- För SEO-audits: Screaming Frog (mindre sajter), PowerMapper (visuellt), SiteOne (djupa audits)
- För dynamiska webbappar: Crawljax
- För storskalig crawl eller egen sök: Apache Nutch, YaCy
- För utvecklare som behöver API: Crawlbase, ScraperAPI, Diffbot
- För dokumentation eller arkivering: SiteOne Crawler
- För enterprise-skala med testperiod: BrightData, Diffbot
Viktiga faktorer att väga in:
- Skalbarhet: Hur stor är sajten eller crawl-jobbet?
- Användarvänlighet: Är du bekväm med kod, eller vill du klicka dig fram?
- Export: Behöver du CSV, JSON eller integration med andra verktyg?
- Support: Finns community eller hjälpdokumentation när du kör fast?
När web crawling möter web scraping: varför Thunderbit är ett smartare val
Här är grejen: de flesta crawlar inte webbplatser bara för att få en snygg karta. Ofta vill man i slutändan ha strukturerad data – oavsett om det handlar om produktlistor, kontaktuppgifter eller en innehållsinventering. Det är exakt där kommer in.
Thunderbit är inte bara en crawler eller en scraper – det är ett AI-drivet Chrome-tillägg som kombinerar båda. Så här funkar det:
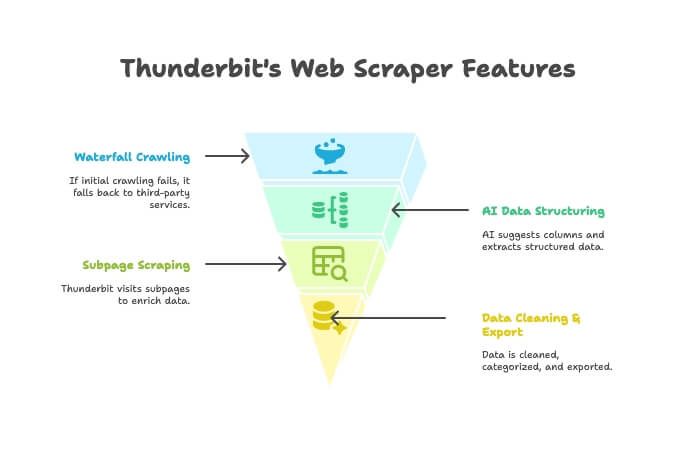
- AI Crawler: Thunderbit utforskar sajten, precis som en crawler.
- Waterfall Crawling: Om Thunderbits egen motor inte kommer åt sidan (t.ex. på grund av tuffa anti-bot-skydd) växlar den automatiskt över till tredjepartstjänster – utan att du behöver ställa in något.
- AI-strukturering av data: När HTML:en är hämtad föreslår Thunderbits AI rätt kolumner och extraherar strukturerad data (namn, priser, e-post osv.) utan att du skriver en enda selector.
- Scraping av undersidor: Behöver du detaljer från varje produktsida? Thunderbit kan automatiskt besöka varje undersida och berika din tabell.
- Datarensning & export: Sammanfatta, kategorisera, översätta och exportera till Excel, Google Sheets, Airtable eller Notion med ett klick.
- No-code och enkelt: Kan du använda en webbläsare kan du använda Thunderbit. Ingen kod, inga proxies, inget strul.
När ska du välja Thunderbit istället för en traditionell crawler?
- När slutmålet är ett rent, användbart kalkylark – inte bara en lista med URL:er.
- När du vill automatisera hela kedjan (crawla, extrahera, rensa, exportera) på ett ställe.
- När du värdesätter tid och sinnesro.
Du kan och se själv varför så många företagsanvändare byter.
Slutsats: få ut maximalt av gratis webbplats-crawlers
Webbplats-crawlers har blivit rejält mycket vassare. Oavsett om du är marknadsförare, utvecklare eller bara vill hålla sajten i bra skick finns det ett gratis (eller åtminstone gratis att testa) web crawler-verktyg för dig. Från enterprise-plattformar som BrightData och Diffbot, till open source-pärlor som SiteOne och Crawljax, till visuella kartläggare som PowerMapper – utbudet är bredare än någonsin.
Men om du vill ha ett smartare, mer integrerat sätt att gå från “jag behöver den här datan” till “här är mitt kalkylark”, testa Thunderbit. Det är byggt för företagsanvändare som vill ha resultat – inte bara rapporter.
Redo att börja crawla? Ladda ner ett verktyg, kör en scan och se vad du har missat. Och om du vill gå från crawling till användbar data på två klick, .
För fler djupdykningar och praktiska guider, besök .
FAQ
Vad är skillnaden mellan en webbplats-crawler och en web scraper?
En crawler upptäcker och kartlägger alla sidor på en sajt (tänk: bygger en innehållsförteckning). En scraper plockar ut specifika datafält (som priser, e-post eller recensioner) från de sidorna. Crawlers hittar – scrapers gräver ().
Vilken gratis web crawler är bäst för icke-tekniska användare?
För mindre sajter och SEO-audits är Screaming Frog lätt att använda. För visuell kartläggning är PowerMapper bra (under testperioden). Thunderbit är enklast om målet är strukturerad data och du vill ha en no-code-upplevelse direkt i webbläsaren.
Finns det webbplatser som blockerar web crawlers?
Ja – vissa sajter använder robots.txt eller anti-bot-skydd (som CAPTCHAs eller IP-blockering) för att stoppa crawlers. Verktyg som ScraperAPI, Crawlbase och Thunderbit (med waterfall crawling) kan ofta ta sig förbi, men crawla alltid ansvarsfullt och respektera sajtens regler ().
Har gratis webbplats-crawlers begränsningar i antal sidor eller funktioner?
Oftast, ja. Till exempel är Screaming Frogs gratisversion begränsad till 500 URL:er per crawl; PowerMappers test är 100 sidor. API-baserade verktyg har ofta månatliga kreditgränser. Open source-verktyg som SiteOne eller Crawljax har vanligtvis inga hårda gränser, men du begränsas av din hårdvara.
Är det lagligt och integritetsmässigt okej att använda en web crawler?
I regel är det lagligt att crawla offentliga webbsidor, men kontrollera alltid sajtens användarvillkor och robots.txt. Crawla aldrig privat eller lösenordsskyddad data utan tillstånd, och tänk på integritetslagar om du extraherar personuppgifter ().