
Webben är inte längre bara en digital lekplats – den har blivit världens största datalager, och allt från säljteam till marknadsanalytiker tävlar om att utnyttja dess potential. Men om vi ska vara ärliga: att manuellt samla in webbdata är ungefär lika kul som att försöka bygga ihop en IKEA-möbel utan instruktioner (och med en hög skruvar över). I takt med att företag blir allt mer beroende av färsk marknadsinformation, konkurrenskraftiga priser och leadgenerering, har behovet av smarta och pålitliga verktyg för datainsamling aldrig varit större. Faktum är att nästan för att fatta beslut, och den globala marknaden för web scraping väntas .
Om du är less på att kopiera och klistra, missar nya leads eller bara är nyfiken på vad som är möjligt när du låter automatiseringen ta över, har du hamnat helt rätt. Jag har själv lagt år på att bygga och testa verktyg för 웹 스크래퍼 (och ja, lett teamet på ), så jag vet hur rätt verktyg kan förvandla timmar av monotont slit till en smidig tvåklickslösning. Oavsett om du är nybörjare utan kodningskunskaper eller utvecklare som vill ha full kontroll, hjälper den här listan över de 10 bästa verktygen dig att hitta rätt.
Varför det är viktigt att välja rätt verktyg för datainsamling
Skillnaden mellan ett bra och ett halvdant verktyg för datainsamling handlar inte bara om bekvämlighet – det kan vara avgörande för företagets tillväxt. När du automatiserar 웹 스크래퍼 sparar du inte bara tid (en G2-användare rapporterade ), du minskar också risken för fel, öppnar nya möjligheter och ser till att teamet alltid jobbar med den senaste och mest korrekta datan. Manuell research är långsam, lätt att göra fel i och ofta inaktuell när du är klar. Med rätt verktyg kan du hålla koll på konkurrenter, följa priser eller bygga leadlistor på några minuter – inte dagar.
Ett exempel: en skönhetsåterförsäljare använde 웹 스크래퍼 för att följa konkurrenters lager och priser, . Sådana resultat får du inte med kalkylblad och handpåläggning.
Så utvärderade vi de bästa verktygen för datainsamling
Med så många alternativ kan det kännas som speed-dating på en techkonferens att välja rätt verktyg. Här är vad jag kollade på för att hitta guldkornen:
- Användarvänlighet: Kan du komma igång utan att vara Python-proffs? Finns det visuellt gränssnitt eller AI-stöd för dig som inte är teknisk?
- Automatisering: Klarar verktyget paginering, undersidor, dynamiskt innehåll och schemaläggning? Kan det köra i molnet för större jobb?
- Pris och skalbarhet: Finns det gratisnivå eller prisvärda startpaket? Hur ökar kostnaden när du behöver mer data?
- Funktioner och integration: Kan du exportera till Excel, Google Sheets eller via API? Finns det mallar, schemaläggning eller inbyggd datarensning?
- Målgrupp: Vem är verktyget egentligen byggt för – affärsanvändare, utvecklare eller större företag?
Jag har även lagt till en jämförelsetabell i slutet så du snabbt kan se hur verktygen står sig mot varandra.
Nu kör vi – här är de 10 bästa verktygen för effektiv 웹 스크래퍼 2025.
1. Thunderbit
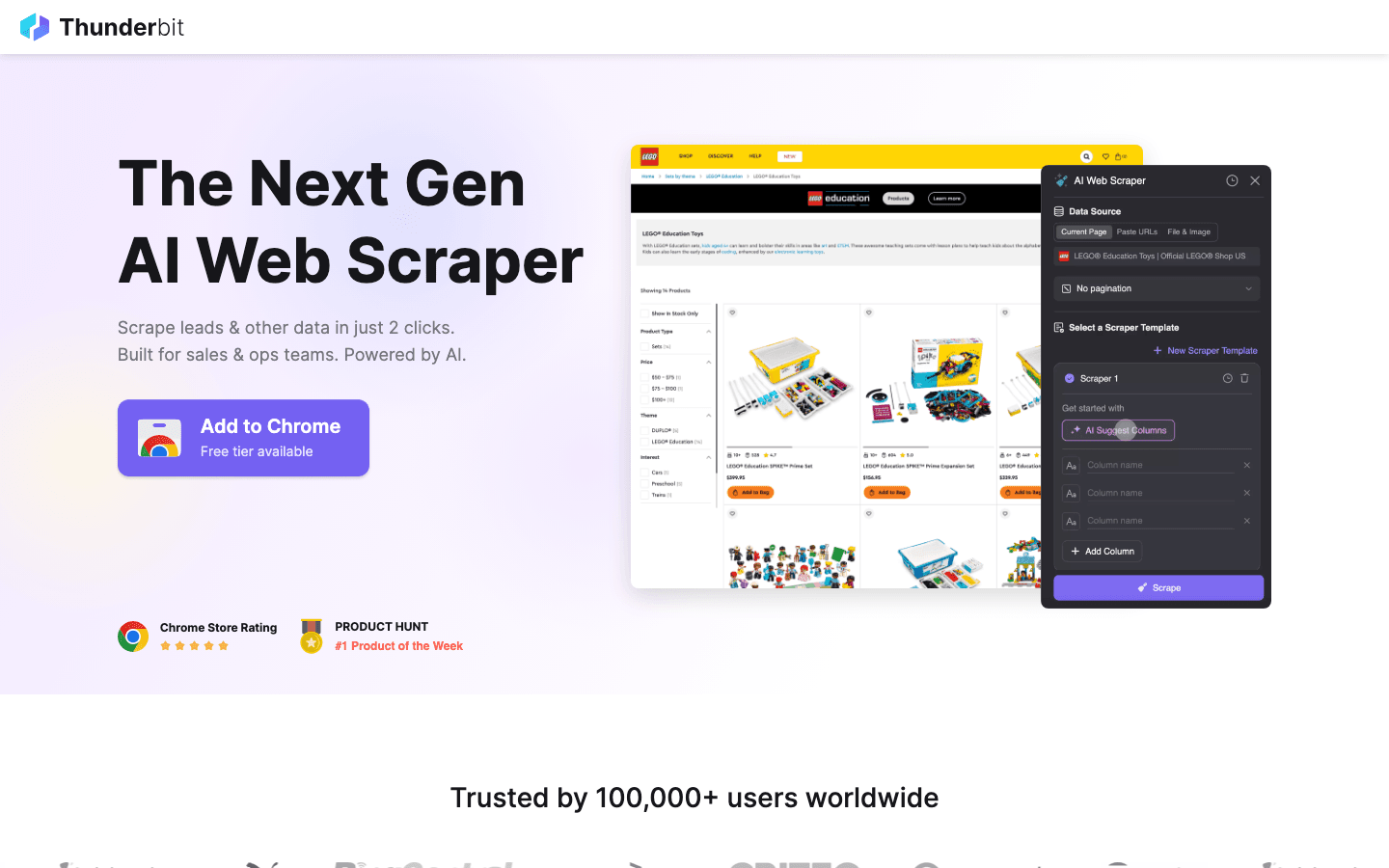 är mitt förstahandsval för dig som vill att datainsamling ska vara lika smidigt som att beställa hemkörning. Som en AI-driven Chrome-tillägg handlar Thunderbit om 2-klicks scraping: klicka på “AI Föreslå Fält” så identifierar AI:n vad som finns på sidan, klicka sedan på “Hämta” för att samla in datan. Ingen kodning, inga krångliga inställningar – bara snabba resultat.
är mitt förstahandsval för dig som vill att datainsamling ska vara lika smidigt som att beställa hemkörning. Som en AI-driven Chrome-tillägg handlar Thunderbit om 2-klicks scraping: klicka på “AI Föreslå Fält” så identifierar AI:n vad som finns på sidan, klicka sedan på “Hämta” för att samla in datan. Ingen kodning, inga krångliga inställningar – bara snabba resultat.
Varför älskar sälj-, marknads- och e-handelsteam Thunderbit? Det är byggt för verkliga affärsflöden:
- AI Föreslå Fält: AI:n läser av sidan och föreslår de bästa kolumnerna att hämta – namn, priser, e-postadresser, med mera.
- Undersidescraping: Behöver du mer detaljer? Thunderbit kan automatiskt besöka varje undersida (t.ex. produktdetaljer eller LinkedIn-profiler) och komplettera din tabell.
- Direkt export: Skicka datan direkt till Excel, Google Sheets, Airtable eller Notion. Alla exporter är gratis.
- Färdiga mallar: För populära sajter (Amazon, Zillow, Instagram) finns färdiga mallar för ännu snabbare resultat.
- Gratis dataexport: Ingen betalvägg för att få ut din data.
- Schemalagd scraping: Ställ in återkommande jobb på vanlig svenska (“varje måndag kl 9”) – perfekt för prisbevakning eller veckovisa leadlistor.
Thunderbit använder ett kreditsystem (1 kredit = 1 rad), med för upp till 6 sidor (eller 10 med testboost). Betalplaner börjar på 15 USD/månad för 500 krediter, vilket gör det prisvärt för team i alla storlekar.
Vill du se Thunderbit i praktiken? Kolla in vår eller . Det är verktyget jag själv önskar att jag haft när jag drunknade i manuell datainmatning.
2. Octoparse
 är en tungviktare inom datainsamling, särskilt för företag som behöver kraftfulla lösningar. Det erbjuder ett visuellt skrivbordsgränssnitt (Windows och Mac) där du kan bygga arbetsflöden med pek-och-klick – ingen kodning krävs. Men låt dig inte luras av det enkla gränssnittet: Octoparse hanterar inloggningar, oändlig scroll, roterande proxies och till och med CAPTCHA.
är en tungviktare inom datainsamling, särskilt för företag som behöver kraftfulla lösningar. Det erbjuder ett visuellt skrivbordsgränssnitt (Windows och Mac) där du kan bygga arbetsflöden med pek-och-klick – ingen kodning krävs. Men låt dig inte luras av det enkla gränssnittet: Octoparse hanterar inloggningar, oändlig scroll, roterande proxies och till och med CAPTCHA.
- 500+ färdiga mallar: Kom igång snabbt med mallar för Amazon, Twitter, LinkedIn och fler.
- Molnbaserad scraping: Kör jobb på Octoparse servrar, schemalägg och skala upp för stora projekt.
- API-åtkomst: Integrera data direkt i dina affärssystem eller databaser.
- Avancerad automatisering: Klarar dynamiskt innehåll, paginering och flerstegsflöden.
Det finns en för upp till 10 uppgifter, men de flesta företag väljer Standard (~83 USD/mån) eller Professional (~299 USD/mån). Inlärningskurvan är lite brantare än Thunderbit, men behöver du skrapa tusentals sidor pålitligt är Octoparse ett toppval.
3. Scrapy
 är guldstandarden för utvecklare som vill ha full kontroll över sina datainsamlingsprojekt. Det är ett open source Python-ramverk där du kan koda egna spindlar (crawlers) för vilken webbplats som helst. Om du kan tänka det, kan du bygga det med Scrapy.
är guldstandarden för utvecklare som vill ha full kontroll över sina datainsamlingsprojekt. Det är ett open source Python-ramverk där du kan koda egna spindlar (crawlers) för vilken webbplats som helst. Om du kan tänka det, kan du bygga det med Scrapy.
- Full programmerbarhet: Skriv Python-kod för att exakt styra hur du hämtar och tolkar data.
- Asynkront och snabbt: Hanterar tusentals sidor parallellt för storskaliga projekt.
- Utbyggbart: Lägg till middleware för proxies, headless browsers eller egen logik.
- Starkt community: Massor av guider, plugins och stöd för knepiga scraping-scenarier.
Scrapy är gratis och open source, men kräver programmeringskunskaper. Har du ett tekniskt team eller vill bygga en skräddarsydd pipeline är Scrapy svårslaget. För icke-tekniska användare är det dock en brant tröskel.
4. ParseHub
 är ett visuellt, kodfritt verktyg som passar perfekt för icke-tekniska användare som behöver hantera komplexa webbplatser. Med pek-och-klick kan du välja element, definiera åtgärder och bygga arbetsflöden – även för sidor med dynamiskt innehåll eller krånglig navigation.
är ett visuellt, kodfritt verktyg som passar perfekt för icke-tekniska användare som behöver hantera komplexa webbplatser. Med pek-och-klick kan du välja element, definiera åtgärder och bygga arbetsflöden – även för sidor med dynamiskt innehåll eller krånglig navigation.
- Visuell arbetsflödesbyggare: Klicka för att välja data, ställ in paginering och hantera popups eller dropdowns.
- Klarar dynamiskt innehåll: Fungerar med JavaScript-tunga sidor och interaktiva webbplatser.
- Molnkörning & schemaläggning: Kör scraping i molnet och schemalägg återkommande jobb.
- Export till CSV, Excel eller via API: Enkel integration med dina favoritverktyg.
ParseHub har en gratisplan (5 projekt), med betalplaner från . Det är lite dyrare än vissa konkurrenter, men det visuella upplägget gör det tillgängligt för analytiker, marknadsförare och forskare som behöver mer än ett enkelt Chrome-tillägg.
5. Apify
 är både en plattform och en marknadsplats för web crawling. Här finns ett stort bibliotek av färdiga “Actors” (färdiga scrapers) för populära sajter, samt möjligheten att bygga och köra egna crawlers i molnet.
är både en plattform och en marknadsplats för web crawling. Här finns ett stort bibliotek av färdiga “Actors” (färdiga scrapers) för populära sajter, samt möjligheten att bygga och köra egna crawlers i molnet.
- 5 000+ färdiga Actors: Skrapa Google Maps, Amazon, Twitter och fler direkt.
- Egen skriptning: Utvecklare kan använda JavaScript eller Python för avancerade crawlers.
- Molnskalning: Kör jobb parallellt, schemalägg och hantera data i molnet.
- API & integration: Koppla resultaten till dina appar, arbetsflöden eller datapipelines.
Apify har en flexibel , med betalplaner från 29 USD/mån (pay-as-you-go för beräkningskraft). Det finns en viss inlärningskurva, men vill du ha både färdiga lösningar och full anpassning är Apify ett kraftfullt val.
6. Data Miner
 är ett Chrome-tillägg byggt för snabba, mallbaserade datainsamlingar. Perfekt för affärsanvändare som vill hämta data från tabeller eller listor utan krångel.
är ett Chrome-tillägg byggt för snabba, mallbaserade datainsamlingar. Perfekt för affärsanvändare som vill hämta data från tabeller eller listor utan krångel.
- Stort mallbibliotek: Över tusen färdiga recept för vanliga sajter (LinkedIn, Yelp, etc).
- Pek-och-klick-extraktion: Välj en mall, förhandsgranska datan och exportera direkt.
- Webbläsarbaserat: Fungerar med din nuvarande session – bra för sidor bakom inloggning.
- Export till CSV eller Excel: Få ut datan till kalkylblad på sekunder.
täcker 500 sidor/månad, med betalplaner från 20 USD/mån. Bäst för små, snabba jobb eller när du behöver data direkt – men räkna inte med att det klarar jättestora projekt eller avancerad automation.
7. Import.io
 är en plattform på företagsnivå för organisationer som behöver kontinuerlig och pålitlig webbintegration av data. Det är mer än bara en crawler – det är en tjänst som levererar ren, strukturerad data direkt till dina affärssystem.
är en plattform på företagsnivå för organisationer som behöver kontinuerlig och pålitlig webbintegration av data. Det är mer än bara en crawler – det är en tjänst som levererar ren, strukturerad data direkt till dina affärssystem.
- Kodfri extraktion: Visuell inställning för att definiera vilken data som ska hämtas.
- Dataflöden i realtid: Strömma data till dashboards, analysverktyg eller databaser.
- Efterlevnad & pålitlighet: Hanterar IP-rotation, anti-bot och juridisk efterlevnad.
- Managed services: Import.io:s team kan sätta upp och underhålla dina scrapers.
Prissättningen är , med 14 dagars gratis test för SaaS-plattformen. Om ditt företag är beroende av ständigt uppdaterad webbdata (t.ex. detaljhandel, finans eller marknadsanalys) är Import.io värt att titta på.
8. WebHarvy
 är ett skrivbordsbaserat verktyg för Windows-användare som vill ha en pek-och-klick-lösning utan prenumeration. Särskilt populärt bland småföretag och privatpersoner som föredrar engångsköp.
är ett skrivbordsbaserat verktyg för Windows-användare som vill ha en pek-och-klick-lösning utan prenumeration. Särskilt populärt bland småföretag och privatpersoner som föredrar engångsköp.
- Visuell mönsterigenkänning: Klicka på dataelement så identifierar WebHarvy automatiskt upprepade mönster.
- Hanterar text, bilder och mer: Extraherar alla vanliga datatyper, inklusive e-post och URL:er.
- Paginering & schemaläggning: Navigera på flersidiga sajter och ställ in schemalagda scrapingjobb.
- Export till Excel, CSV, XML, JSON eller SQL: Flexibla exportmöjligheter för alla arbetsflöden.
En licens för en användare kostar , vilket gör det till ett prisvärt val för regelbunden användning – men notera att det bara finns för Windows.
9. Mozenda
 är en molnbaserad plattform för datainsamling, byggd för affärsprocesser och löpande databehov. Den kombinerar en skrivbordsdesigner (Windows) med kraftfull molnexekvering och automation.
är en molnbaserad plattform för datainsamling, byggd för affärsprocesser och löpande databehov. Den kombinerar en skrivbordsdesigner (Windows) med kraftfull molnexekvering och automation.
- Visuell agentbyggare: Designa extraktionsrutiner med pek-och-klick.
- Molnskalning: Kör flera agenter parallellt, schemalägg jobb och hantera data centralt.
- Datakonsol: Kombinera, filtrera och rensa dataset efter extraktion.
- Företagsstöd: Dedikerade kontomanagers och managed services för större team.
Planer börjar på , med högre nivåer för fler användare och mer processorkraft. Mozenda passar företag som behöver pålitlig, återkommande webbdata i sin dagliga verksamhet.
10. BeautifulSoup
 är det klassiska Python-biblioteket för att tolka HTML och XML. Det är ingen fullfjädrad crawler, men älskas av utvecklare för små, skräddarsydda scrapingprojekt.
är det klassiska Python-biblioteket för att tolka HTML och XML. Det är ingen fullfjädrad crawler, men älskas av utvecklare för små, skräddarsydda scrapingprojekt.
- Enkel HTML-tolkning: Extrahera data från statiska webbsidor på ett smidigt sätt.
- Fungerar med Python Requests: Kombinera med andra bibliotek för hämtning och crawling.
- Flexibelt & lättviktigt: Perfekt för snabba skript eller utbildningsprojekt.
- Stort community: Massor av guider och svar på Stack Overflow.
BeautifulSoup är , men du behöver skriva kod och hantera crawlinglogik själv. Bäst för utvecklare eller nyfikna som vill förstå grunderna i 웹 스크래퍼.
Jämförelsetabell: Verktyg för datainsamling i överblick
| Verktyg | Användarvänlighet | Automationsnivå | Pris | Exportalternativ | Bäst för |
|---|---|---|---|---|---|
| Thunderbit | Mycket enkel, kodfri | Hög (AI, undersidor) | Gratis test, från $15/mån | Excel, Sheets, Airtable, Notion, CSV | Sälj, marknad, e-handel, icke-tekniska användare |
| Octoparse | Medel, visuell UI | Mycket hög, moln | Gratis, $83–$299/mån | CSV, Excel, JSON, API | Företag, datateam, dynamiska sajter |
| Scrapy | Låg (Python krävs) | Hög (anpassningsbar) | Gratis, open source | Valfritt (via kod) | Utvecklare, storskaliga projekt |
| ParseHub | Hög, visuell | Hög (dynamiska sajter) | Gratis, från $189/mån | CSV, Excel, JSON, API | Icke-tekniska, komplexa webbstrukturer |
| Apify | Medel, flexibel | Mycket hög, moln | Gratis, $29–$999/mån | CSV, JSON, API, molnlagring | Utvecklare, företag, färdiga eller egna aktörer |
| Data Miner | Mycket enkel, webbläsare | Låg (manuell) | Gratis, $20–$99/mån | CSV, Excel | Snabba, enstaka extraktioner, små dataset |
| Import.io | Medel, managed | Mycket hög, företag | Anpassat, volymbaserat | CSV, JSON, API, direktintegration | Företag, kontinuerlig dataintegration |
| WebHarvy | Hög, skrivbord | Medel (schemaläggning) | $129 engångsavgift | Excel, CSV, XML, JSON, SQL | Småföretag, Windows-användare, regelbunden scraping |
| Mozenda | Medel, visuell | Mycket hög, moln | $250–$450+/mån | CSV, Excel, JSON, moln, DB | Löpande, storskalig affärsverksamhet |
| BeautifulSoup | Låg (Python krävs) | Låg (manuell kodning) | Gratis, open source | Valfritt (via kod) | Utvecklare, nybörjare, små skript |
Så väljer du rätt verktyg för datainsamling till ditt team
Att välja det bästa verktyget handlar inte om att hitta det “kraftfullaste” – utan om att hitta det som passar teamets kompetens, behov och budget. Här är mina snabba tips:
- Icke-tekniska eller affärsanvändare: Börja med Thunderbit, ParseHub eller Data Miner för snabba resultat och enkel start.
- Företag eller storskaliga behov: Titta på Octoparse, Mozenda eller Import.io för automatisering, schemaläggning och support.
- Utvecklare eller skräddarsydda projekt: Scrapy, Apify eller BeautifulSoup ger full kontroll och flexibilitet.
- Prispressade eller engångsjobb: WebHarvy (Windows) eller Data Miner (webbläsare) är prisvärda och enkla.
Testa alltid dina toppval med en gratis testperiod på de sidor du faktiskt vill skrapa – det som funkar på en sajt kanske inte funkar på en annan. Och glöm inte integration: behöver du datan i Sheets, Notion eller en databas, se till att verktyget stöder det direkt.
Slutsats: Få ut affärsvärde med rätt verktyg för datainsamling
Webbdata är den nya oljan – men bara om du har rätt verktyg för att utvinna och förädla den. Med moderna verktyg för datainsamling kan du förvandla timmar av manuell research till minuter av automatiserad insikt – och därmed driva smartare försäljning, vassare marknadsföring och mer flexibla processer. Oavsett om du bygger leadlistor, följer konkurrenter eller bara är trött på att kopiera och klistra, finns det ett verktyg på listan som gör livet enklare.
Så, se över teamets behov, testa några av dessa verktyg och upptäck hur mycket mer du kan åstadkomma när du låter automatiseringen göra grovjobbet. Och vill du se hur AI-drivet, 2-klicks scraping fungerar i praktiken, . Lycka till med skrapandet – och må din data alltid vara färsk, strukturerad och redo att användas.
Vanliga frågor
1. Vad är ett verktyg för datainsamling och varför behöver jag ett?
Ett verktyg för datainsamling automatiserar processen att hämta information från webbplatser. Det sparar tid, minskar fel och hjälper team att samla aktuell data för försäljning, marknadsföring, research och drift – mycket mer effektivt än manuell kopiering.
2. Vilket verktyg är bäst för icke-tekniska användare?
Thunderbit, ParseHub och Data Miner är toppval för dig utan kodningskunskaper. Thunderbit sticker ut med sitt AI-drivna 2-klicksflöde, medan ParseHub erbjuder ett visuellt upplägg för mer komplexa sajter.
3. Hur skiljer sig prissättningen mellan olika verktyg?
Priserna varierar mycket: vissa verktyg (som Thunderbit och Data Miner) har gratisnivåer och prisvärda månadsplaner, medan företagsplattformar (som Import.io och Mozenda) har anpassad eller volymbaserad prissättning. Kontrollera alltid att kostnaden matchar dina databehov.
4. Kan jag använda dessa verktyg för schemalagd, återkommande datainsamling?
Ja – verktyg som Thunderbit, Octoparse, Apify, Mozenda och Import.io stöder schemalagda eller återkommande körningar, vilket gör dem perfekta för prisbevakning, leadgenerering eller marknadsanalys.
5. Vad ska jag tänka på innan jag väljer ett verktyg för datainsamling?
Tänk på teamets tekniska kompetens, hur komplexa sidor du behöver skrapa, datavolym, integrationsbehov och budget. Testa några verktyg på dina verkliga uppgifter innan du bestämmer dig för en betalplan.
För fler guider och tips, besök .
Läs mer