Amazon har och i sitt sortiment. Om du någon gång har försökt kopiera produktnamn, priser, betyg och ASIN:er manuellt till ett kalkylark vet du hur frustrerande det är — och hur snabbt det växer.
Jag jobbar på , där vi bygger en AI-webbskrapare, så jag ägnar mycket tid åt att fundera på hur folk extraherar data från webbplatser. Men för den här artikeln ville jag göra något som ingen annan sammanställning verkar göra: rada upp sju faktiska Chrome-tillägg som du kan installera och köra på Amazon, testa dem på samma sidor och ge ett rakt svar om vad som fungerar, vad som inte gör det och var varje verktyg passar in. Jag utvärderade varje tillägg utifrån åtta kriterier som direkt speglar de frustrationer jag ser i forum och från våra egna användare — saker som AI-baserad fältdetektering, skrapning av undersidor, risk för blockering, gratisnivåer och exportalternativ. Oavsett om du är Amazon-säljare, marknadsförare eller bara trött på att kopiera och klistra in, är den här guiden för dig.
Varför skrapa produktdata från Amazon överhuvudtaget?
Så vem skrapar egentligen Amazon, och varför?
Det korta svaret är nästan alla som säljer, marknadsför eller forskar om produkter online. Amazon säger att i butiken kommer från oberoende säljare, och de säljarna bevakar ständigt varandra. Här är de vanligaste användningsområdena jag ser:
| Användningsfall | Vem gör det | Vad de får ut |
|---|---|---|
| Övervakning av konkurrentpriser | Säljare, pristeam, byråer | Pris- och tillgänglighetsdata i realtid för konkurrerande produkter |
| Produktresearch och trendbevakning | Amazon-säljare, marknadsanalytiker | Upptäck växande kategorier, nya aktörer och förändringar i efterfrågan |
| Analys av omdömeskänsla | Private label-säljare, varumärkesteam | Återkommande klagomål, funktioner som saknas och möjligheter |
| Leadgenerering (kontakt till säljare) | Partihandelsteam, byråer | Säljarens namn, butiker och kontaktinformation |
| Övervakning av katalog och lager | E-handelsdrift, varumärkesskydd | Följ lagernivåer, ändringar i produktlistningar och obehöriga säljare |
| Optimering av sökord och produktlistningar | Varumärkesägare, marknadsplatsoperatörer | Data om söktermer, listingtext och konkurrenters sökord |
Avkastningen är konkret. Amazons egna case studies visar att efter att de optimerat för toppsökord med strukturerad data. Och en visade att anställda lägger mer än 9 timmar i veckan på repetitiv datainmatning. Om du kan automatisera ens en del av det frigör du rejält med tid för faktiskt beslutsfattande.
Vad kännetecknar ett riktigt bra Amazon Scraper-tillägg för Chrome? (Mina testkriterier)
Alla Chrome-tillägg är inte skapade lika — och de flesta jämförelseartiklar blandar ihop API:er, skrivbordsappar och webbläsartillägg som om de vore utbytbara. Det är de inte. Här är ramen jag använde, och varför varje kriterium spelar roll:
- Enkel installation – Kan en icke-teknisk användare få resultat på under 5 minuter? (Forum bekräftar att detta är en toppfråga.)
- AI-driven fältdetektering – Identifierar verktyget produktfält automatiskt, eller måste du konfigurera selectors manuellt? (Ingen konkurrerande artikel tar ens upp detta som kategori.)
- Skrapning av undersidor / detaljsidor – Kan du berika listningsdata med information från produktsidan i samma arbetsflöde?
- Hantering av bot-skydd / blockeringsrisk – Hur hanterar det Amazons aggressiva bot-detektering? (Den i användarforum.)
- Stöd för sidnumrering – Kan det automatiskt skrapa över flera resultatsidor?
- Gratisnivå / prissättning – Vad får du faktiskt utan att betala? (Användare frågar uttryckligen efter gratisalternativ, och ingen konkurrent ger ett praktiskt svar.)
- Exportalternativ – CSV, Excel, Google Sheets, Airtable, Notion?
- Schemaläggning och automatisering – Kan du ställa in det så att det körs återkommande?
Jag testade varje tillägg på Amazons amerikanska sökresultat och produktsidor, med samma sökningar och samma förutsättningar.

AI-driven vs. selector-baserad skrapning: varför det spelar roll för Amazon
Det finns en skillnad som ingen annan Amazon-skrapningssammanställning tar upp — och det är den enskilt största faktorn för hur mycket underhåll din skrapare kommer att kräva.
De flesta Chrome-tillägg för skrapning fungerar genom att mappa CSS-selectors till datafält. Du (eller verktygets mall) pekar ut HTML-elementet för ”pris” eller ”titel”, och skraparen hämtar det som finns där. Problemet? Amazon ändrar sin underliggande HTML och CSS för att sabotera skrapare. Forumanvändare beskriver hashade eller skiftande klassnamn som .
Så här jämförs de tre huvudansatserna:
| Metod | Så fungerar det | När Amazon ändrar layout |
|---|---|---|
| Selector-baserad (traditionell) | Användaren mappar manuellt CSS-selectors till fält | Går sönder – användaren måste konfigurera om |
| Mallbaserad | Förbyggda recept för Amazon-sidor | Går sönder tills utvecklaren uppdaterar mallen |
| AI-driven (t.ex. Thunderbit) | AI läser sidinnehållet och identifierar fält automatiskt | Anpassar sig automatiskt – inget underhåll |
Bara ett av de sju tillägg jag testade — Thunderbit — använder AI-baserad fältdetektering som standardväg. Resten förlitar sig på selectors eller mallar, vilket innebär mer underhåll när Amazon oundvikligen ändrar sina sidor. Förståelsen av den här skillnaden kommer att spara dig mycket frustration längre fram.
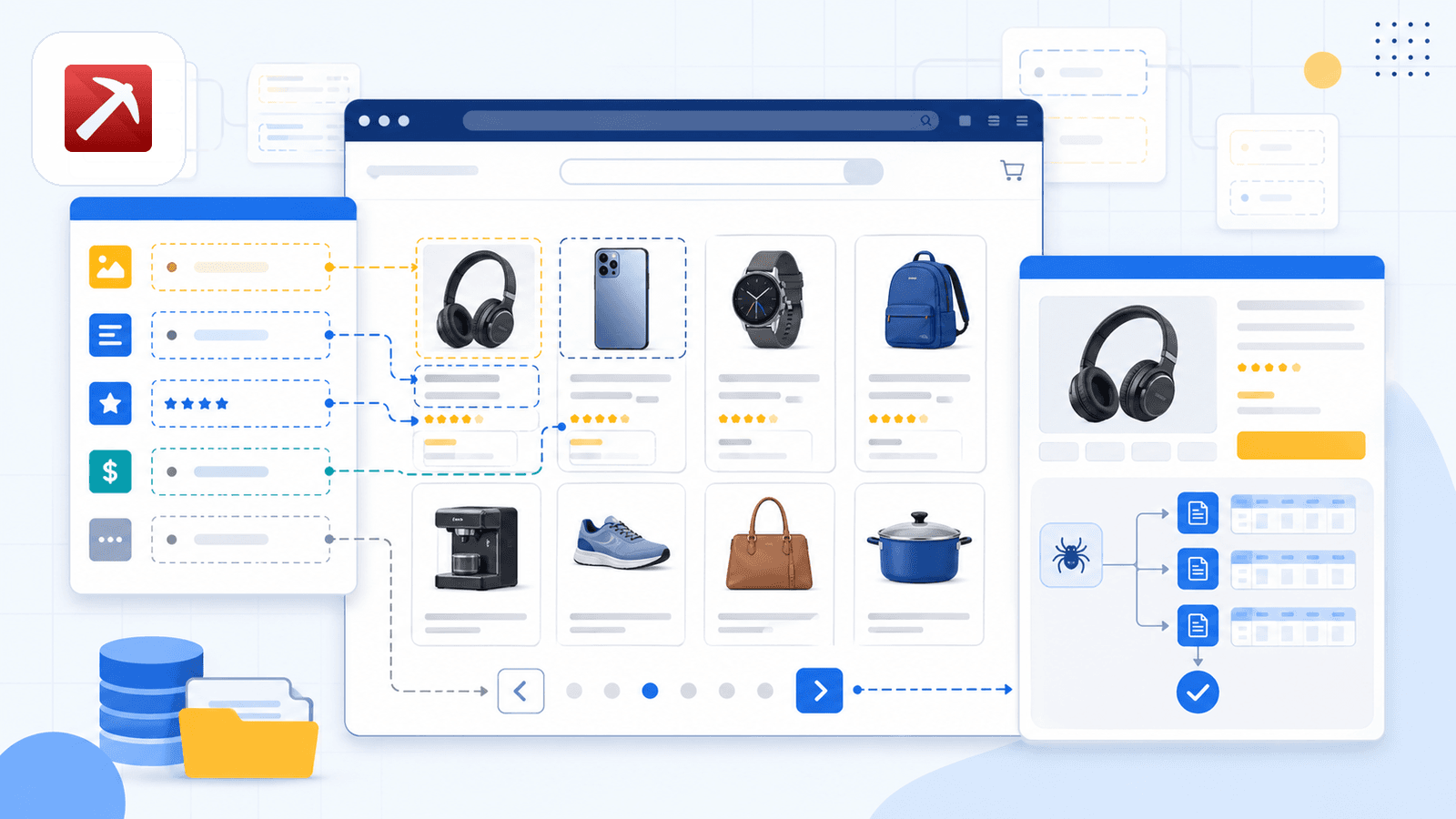
1. Thunderbit – Det AI-drivna Amazon Scraper-tillägget för Chrome
är verktyget vi har byggt i vårt företag, så jag är öppen med det. Men jag tycker också på riktigt att det är det bästa valet för icke-tekniska användare som vill ha snabb och korrekt Amazon-data utan att brottas med selectors eller kod.
Den främsta skillnaden är AI Suggest Fields. När du öppnar en Amazon-sökresultatsida och klickar på knappen läser Thunderbits AI sidan och föreslår kolumnnamn — titel, pris, betyg, ASIN, antal recensioner, produkt-URL och mer. Du behöver inte konfigurera någonting. AI:n listar ut vad som finns på sidan och föreslår rätt fält och datatyper.
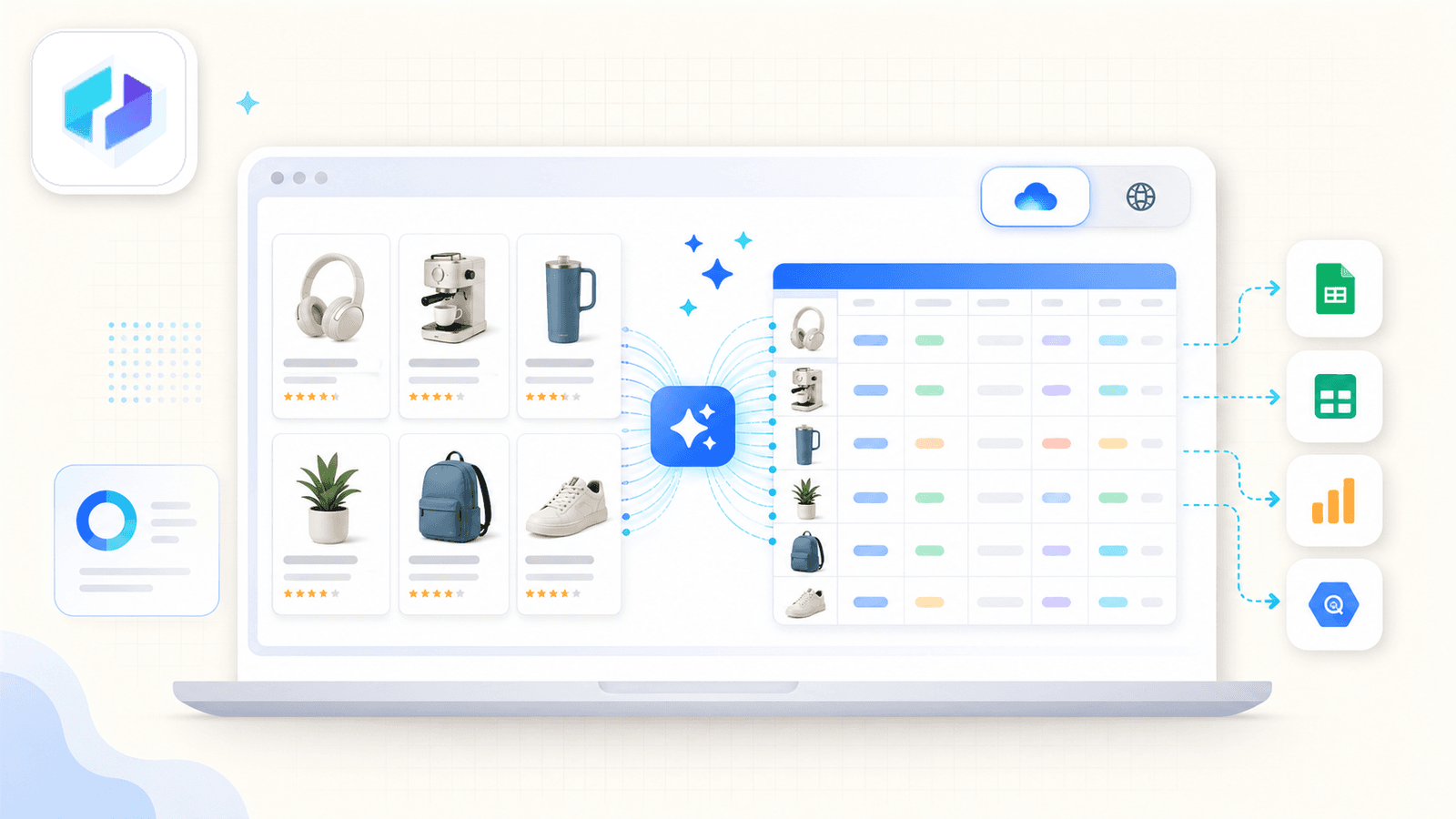
Så här ser en typisk Amazon-skrapning ut:
- Installera och öppna en Amazon-sökresultatsida.
- Klicka på AI Suggest Fields – AI:n identifierar och föreslår kolumner.
- Klicka på Skrapa – data fylls i direkt.
- För populära Amazon-sidor kan du också använda den förbyggda för en riktig 1-klicksupplevelse.
Det som verkligen särskiljer Thunderbit är skrapning av undersidor. Efter att du har skrapat listningssidan klickar du på Skrapa undersidor – Thunderbit besöker varje produkt-URL och lägger till detaljfälten (fullständiga beskrivningar, punktlistor, säljarinformation, bild-URL:er) i samma tabell. De flesta konkurrerande tillägg erbjuder helt enkelt inte detta.
Det finns också en växling mellan moln och webbläsare. Molnläget kan skrapa upp till 50 sidor samtidigt för offentliga listningar. Webbläsarläget använder din egen Chrome-session – perfekt när du är inloggad i Seller Central eller behöver hålla dig under radarn.
Schemaläggning uttrycks på vanlig svenska: beskriv tidsintervallet, så omvandlar AI:n det till ett schema.
Exportalternativen omfattar Excel, Google Sheets, Airtable, Notion, CSV och JSON – allt ingår i gratisnivån.
För- och nackdelar med Thunderbit
Fördelar:
- AI identifierar fält automatiskt – ingen selector-inställning, inget underhåll när Amazon ändrar layout
- Berikning av undersidor med ett klick
- Växling mellan moln och webbläsare för flexibilitet och lägre blockeringsrisk
- Bredast exportstöd (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Schemaläggning med naturligt språk
- Förbyggd Amazon-mall för omedelbara resultat
Nackdelar:
- Kreditbaserat system betyder att tunga användare behöver en betald plan
- AI-baserad fältdetektering lägger till ett kort bearbetningssteg (några sekunder)
- Nyare verktyg, så mindre community-dokumentation än äldre alternativ
Thunderbit-prissättning
- Gratisnivå: 6 sidor (10 med testbonus), inkluderar AI-funktioner och alla exportformat
- Betalda planer: Från cirka 9 USD/månad (årsvis) för 500 krediter; 1 kredit = 1 utmatningsrad
- Se för de senaste detaljerna
2. Instant Data Scraper – Det gratis, avskalade alternativet
Instant Data Scraper är ett Chrome-tillägg som automatiskt känner igen tabulär data på webbsidor med hjälp av heuristiska algoritmer. Det har funnits i flera år och är fortfarande ett av de mest nedladdade gratisverktygen för skrapning i Chrome Web Store.
På Amazon aktiverar du tillägget på en sökresultatsida, och det försöker automatiskt identifiera datatabellen. Ibland behöver du klicka på ”try another table” om den första identifieringen missar målet. För enkla engångsskrapningar fungerar det ganska bra.
Det finns dock en viktig brasklapp för 2026: den officiella landningssidan säger nu att Instant Data Scraper inte längre ägs, utvecklas eller stöds av Web Robots. Det betyder inga uppdateringar, inga buggfixar och inga nya funktioner. I en rapporterade en att verktyget hanterade översiktssidor men fastnade när det krävdes klick på detaljnivå.
För- och nackdelar med Instant Data Scraper
Fördelar:
- 100 % gratis, inget konto behövs
- Lätt och snabbt för enkla tabeller
- Stöd för grundläggande sidnumrering (klick på ”Nästa”)
Nackdelar:
- Ingen AI-baserad fältdetektering (litar på mönsterigenkänning, vilket kan misstolka Amazons komplexa layout)
- Ingen skrapning av undersidor
- Endast CSV/Excel-export
- Ingen schemaläggning, inget molnalternativ
- Underhålls inte längre – går sönder när Amazon ändrar layout, och ingen fixar det
3. Web Scraper – Veteranen för manuell konfiguration
Web Scraper är en av de mest etablerade Chrome-tilläggsbaserade skraparna och bygger på en visuell sitemap-byggare. Du öppnar DevTools, skapar en ”sitemap” genom att peka och klicka för att definiera selectors, konfigurerar sidnumrering och kan följa länkar till produkternas detaljsidor.
Web Scraper erbjuder också en mall för Amazon Products Listings Scraper i sin marknadsplats, som hanterar navigering, sidnumrering och extrahering från produktsidor. Deras steg-för-steg-guide går igenom en åttastegsinstallation – installera, generera selectors, konfigurera sidnumrering, följ produktlänkar, kör lokalt eller i molnet.
Molnversionen lägger till schemaläggning, API-åtkomst, proxyrotation, CAPTCHA-kringgående och integration med Google Sheets.

För- och nackdelar med Web Scraper
Fördelar:
- Moget, väldokumenterat och stöds av en community
- Gratis webbläsartillägg (obegränsad lokal användning)
- Mallar för Amazon i marknadsplatsen
- Molnalternativ för skalning (schemaläggning, IP-rotation, integrationer)
- Stöd för att följa länkar till produktsidor (delvis berikning av undersidor)
Nackdelar:
- Kräver manuell inställning av selectors – brantare inlärning för icke-tekniska användare
- Ingen AI-baserad automatisk fältdetektering
- Mallar kan gå sönder när Amazon uppdaterar layouten
- Avancerade funktioner bakom betalda molnplaner
Web Scraper-prissättning
- Gratis: Chrome-tillägg, obegränsad lokal skrapning
- Molnplaner: Från 50 USD/månad (Project), 100 USD/månad (Professional), från 200 USD/månad (Scale)
4. Octoparse – Plattformen med många funktioner (och en brasklapp för Chrome-tillägget)
Octoparse är en kraftfull no-code-plattform för skrapning med förbyggda Amazon-mallar för produktdetaljer, sökordssökning och recensioner. Den stöder molnskrapning, schemaläggning och arbetsflöden i flera steg.
Det finns dock en viktig nyans: Octoparse Chrome Web Store-tillägg listas för närvarande som Octoparse AI Web Automation, och det anges uttryckligen att det bara fungerar tillsammans med Octoparse AI Bot på Windows. Den faktiska skrapupplevelsen är alltså först och främst plattformsbaserad, inte tilläggsbaserad. Om du letar efter ett rent ”installera och skrapa i Chrome”-flöde är Octoparse mer som en skrivbordsapp med webbläsarhjälp.
Med det sagt är mallarna utmärkta. Du anger en sök-URL, Octoparse extraherar automatiskt produktdata, och du kan bygga egna arbetsflöden med point-and-click-selectors, sidnumrering och länkföljning för detaljsidor.
För- och nackdelar med Octoparse
Fördelar:
- Robust funktionsuppsättning med Amazon-mallar
- Molnnoder för hastighet, schemaläggning och extraktion av undersidor via arbetsflöden
- Hanterar sidnumrering bra
- Bra för komplexa skrapkedjor i flera steg
Nackdelar:
- Full kapacitet kräver skrivbordsappen – inte en ren Chrome-tilläggsupplevelse
- Ingen AI-baserad fältföreslagning (det finns en separat produkt, Chat4Data, men det är ett annat tillägg)
- Gratisplanen begränsas till cirka 50 000 exporterade dataposter per månad, 10 000 rader per export
- Gränssnittet kan kännas komplext för nybörjare
Octoparse-prissättning
- Gratis: Begränsad (lokal extraktion, 50K exporttak)
- Standard: cirka 75–83 USD/månad
- Professional: cirka 208–249 USD/månad
- Tillägg: IP-rotation för 3 USD/GB, CAPTCHA-lösning för 2–2,50 USD per 1 000
5. Axiom.ai – No-code-byggaren för botar
Axiom.ai är ett Chrome-tillägg för att bygga automationsbotar i webbläsaren med en visuell no-code-byggare. Det är mer ett allmänt automatiseringsverktyg än en dedikerad skrapare, men det har mallar för Amazon-skrapning och guider för ASIN-extraktion.
Du skapar en bot (eller hämtar en mall) som loopar genom produkt-URL:er i ett Google Sheet, besöker varje sida, extraherar data via point-and-click-selectors och skriver tillbaka resultaten till arket. Schemaläggning finns i betalda planer, och molnkörningar erbjuds nu med start från 1 bot i molnet på Starter och Pro, upp till 20 samtidiga molnbotar på Ultimate.
För- och nackdelar med Axiom.ai
Fördelar:
- Mångsidig no-code-automatisering (inte bara skrapning)
- Inbyggd integration med Google Sheets
- Schemaläggning och molnkörning i betalda planer
- Mallar för Amazon
- Bra för arbetsflöden i flera steg utöver datainsamling
Nackdelar:
- Tyngre installation för en enkel skrapning (kräver botdesign, konfiguration av Google Sheet, test av loopar)
- Ingen AI-baserad fältdetektering
- Ingen berikning av undersidor med ett klick (du måste bygga ett separat botsteg)
- Export begränsas till Google Sheets eller CSV
Axiom.ai-prissättning
- Gratis: 2 timmars körtid
- Starter: 15 USD/månad
- Pro: 50 USD/månad
- Pro Max: 150 USD/månad
- Ultimate: 250 USD/månad
6. Data Miner – Tillägget som bygger på recept
Data Miner är ett Chrome-tillägg som fokuserar på att extrahera data med hjälp av ”recept” — fördefinierade eller egna skrapmallar. Du söker efter ett befintligt Amazon-recept i det publika biblioteket eller skapar ditt eget genom att välja sidkomponenter.
Data Miner stöder sidnumrering via funktionen Next Page Automation, och det finns också ett Crawl Scrape-arbetsflöde för att besöka detalj-URL:er och tillämpa ett andra recept. Så det är inte ”ingen skrapning av undersidor” — men det är en manuell process i flera steg snarare än berikning med ett klick.
Den stora begränsningen är gratisnivån: 500 sidor/månad, och vissa domäner är begränsade i gratisversionen. Recepten är sajtspecifika, och Data Miners egen dokumentation varnar för att om sajten ändras och referensens HTML-kod ändras, kommer receptet inte att fungera.
För- och nackdelar med Data Miner
Fördelar:
- Lätt att köra ett befintligt recept
- Community-bibliotek med recept
- Stöd för sidnumrering och crawl av detaljsidor (manuell konfiguration)
- Enkelt gränssnitt
Nackdelar:
- Gratisnivån begränsad till 500 sidor/månad
- Ingen AI-baserad fältdetektering
- Recept går sönder när Amazon ändrar layout
- Ingen molnskrapning, ingen schemaläggning i publika dokument
- Export: CSV, Excel, urklipp; Google Sheets på betalda planer
Data Miner-prissättning
- Gratis: 500 sidor/månad
- Betald: 19,99, 49, 99, 200 USD/månad med ökande gränser och funktioner
7. Helium 10 – Amazons säljardrivna intelligenssvit
Helium 10 är en heltäckande verktygssvit för Amazon-säljare, inte en generell webbskrapare. Deras Chrome-tillägg (Xray) lägger data direkt ovanpå Amazons sökresultat och visar uppskattad försäljning, intäkter, recensionstrender, BSR med mera. Det är byggt för Amazon-säljare som gör produktresearch, inte för att extrahera rå siddata.
Helium 10 har visserligen en gratisplan 2026, men åtkomsten till Chrome-tillägget är begränsad i gratisversionen. Tillägget kan exportera resultat i CSV eller Excel och stöder arbetsflöden via urklipp.
För- och nackdelar med Helium 10
Fördelar:
- Djupa Amazon-specifika insikter (försäljningsuppskattningar, sökordsdata, BSR-trender)
- Används av professionella säljare
- Molnbaserad data och schemaläggning för sökords- och rankningsspårning
- Gratisplan finns (begränsad)
Nackdelar:
- Inte en allmän skrapare – kan inte extrahera anpassade fält från godtyckliga sidor
- Dyrt jämfört med verktyg som fokuserar på skrapning
- Begränsade exportformat (CSV, Excel)
- Ingen AI-baserad fältdetektering, ingen berikning av undersidor i skrapningsmening
Helium 10-prissättning
- Gratis: Begränsad åtkomst, inklusive Chrome-tillägg
- Starter: 49 USD/månad
- Platinum: 229 USD/månad
- Diamond: 359 USD/månad
Amazon Scraper-tillägg för Chrome jämförda: hela jämförelsen sida vid sida
Här är den ärliga jämförelsetabellen. Jag har korrigerat några antaganden från tidigare utkast efter praktisk testning och verifiering 2026:
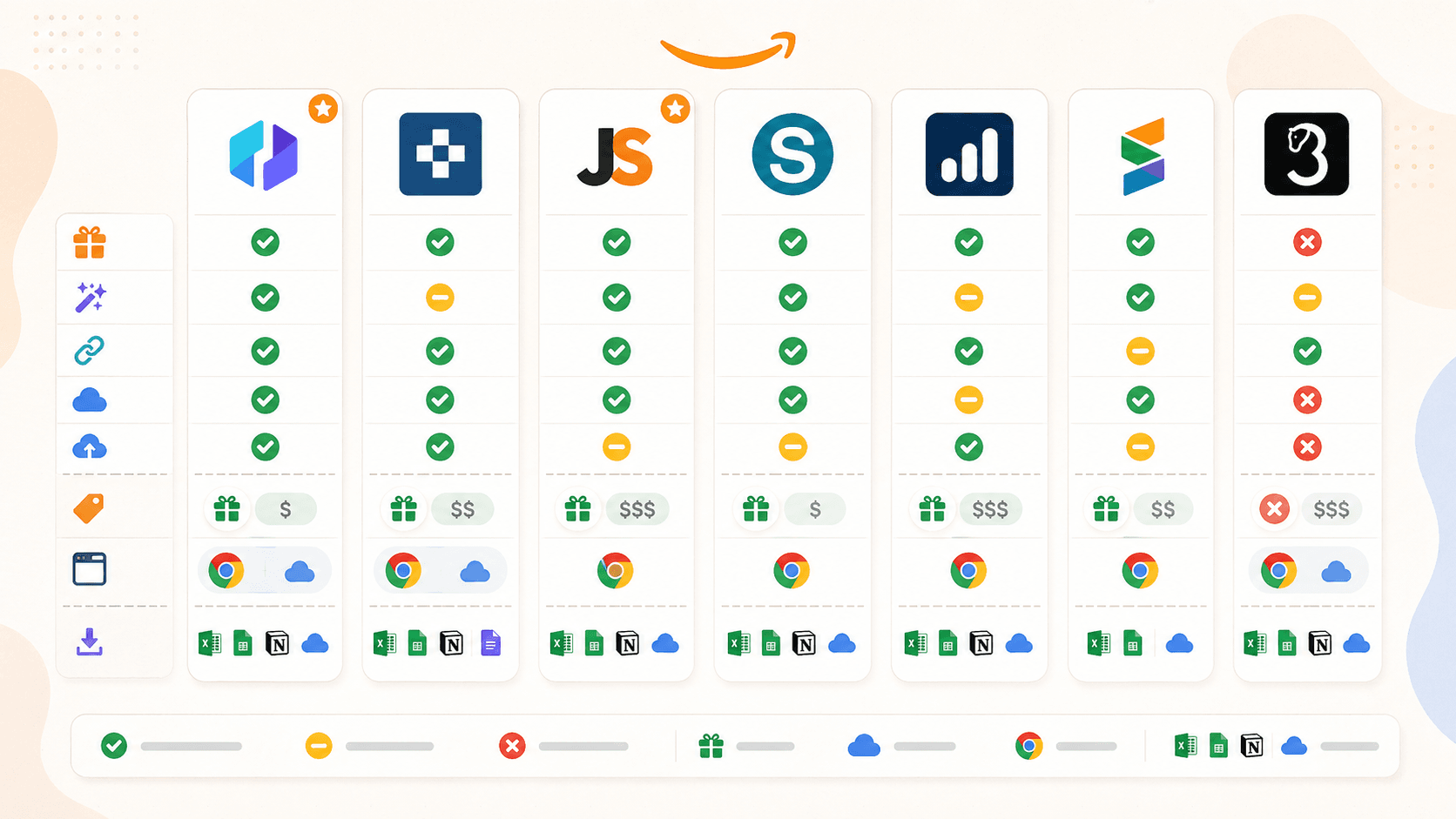
| Funktion | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Huvudkategori | AI-skrapartillägg | Gratis heuristisk skrapare | Selector-/mallbaserad skrapare | No-code-plattform för skrapning | Byggare för webbläsarbotar | Receptbaserat skrapartillägg | Överlägg för säljarresearch |
| AI-förslag av fält | Ja | Nej | Nej | Nej (separat Chat4Data) | Nej | Nej | Nej |
| Berikning av undersidor | Ja (1 klick) | Nej | Ja (manuell sitemap) | Ja (arbetsflöde) | Ja (manuellt botsteg) | Ja (manuell crawl) | Ej tillämpligt |
| Molnskrapning | Ja | Nej | Ja (betald) | Ja (betald) | Ja (betald) | Nej | Molnbaserad analys |
| Schemaläggning | Ja | Nej | Ja (betald) | Ja (betald) | Ja (betald) | Nej | Ja (spårning av sökord/rankning) |
| Gratisnivå | Ja (6–10 sidor) | Ja (helt gratis) | Ja (endast webbläsare) | Ja (begränsad) | Ja (2 tim körtid) | Ja (500 sidor/mån) | Ja (begränsad) |
| Förbyggd Amazon-mall | Ja | Nej | Ja | Ja | Ja (guider) | Receptbibliotek | Ej tillämpligt |
| Export till Sheets/Airtable/Notion | Ja (alla) | Endast CSV/Excel | CSV, Excel, JSON; Sheets via moln | CSV, Excel, JSON, mer | Google Sheets, CSV | CSV, Excel; Sheets på betalda planer | CSV, Excel |
Några saker sticker ut. Thunderbit är det enda tillägget med AI-baserad fältdetektering och de bredaste exportalternativen i gratisnivån. Instant Data Scraper är det enklaste gratisalternativet, men det underhålls inte längre. Web Scraper och Octoparse är kraftfulla för användare som vill lägga tid på installationen, men inget av dem är en ren ”installera och kör”-upplevelse i tilläggsform. Axiom.ai är bäst för flerstegsautomatisering utöver skrapning. Data Miner är enkelt för att köra befintliga recept, men gratisnivån är snäv. Helium 10 är ett verktyg för säljarintelligens, inte en generell skrapare.
Moln vs. webbläsarskrapning för Amazon: det du behöver veta om blockeringsrisk
Det här är elefanten i rummet. Amazon upptäcker och blockerar aktivt automatiserad skrapning. Användare på Reddit rapporterar , och Amazons egna säger uttryckligen att licensen inte inkluderar ”any use of data mining, robots, or similar data gathering and extraction tools”.
Så vad är den praktiska skillnaden mellan webbläsar- och molnskrapning?
- Webbläsarskrapning körs i din egen Chrome-session – riktiga cookies, inloggat läge, naturligt surfbeteende. Det ser mer mänskligt ut vid låg volym men binder upp din webbläsare.
- Molnskrapning använder fjärrservrar för hastighet (Thunderbit hanterar 50 sidor åt gången i molnläge), men kräver begränsning av frekvens och proxyrotation för att undvika upptäckt.
Här är en beslutsmatris jag använder:
| Scenario | Rekommenderat läge | Varför |
|---|---|---|
| Skrapa 20 produktsidor för research | Webbläsare | Låg volym, naturligt beteende |
| Övervaka 500 konkurrent-SKU:er varje vecka | Moln | Hastighet är viktig, offentlig data |
| Skrapa medan du är inloggad i Seller Central | Webbläsare | Behöver din inloggningssession |
| Engångsexport i bulk av en kategori | Moln | Parallell skrapning för hastighet |
Bland de sju tilläggen finns molnskrapning i Thunderbit, Web Scraper (betalt), Octoparse (betalt), Axiom.ai (betalt) och Helium 10 (för sin analys). Instant Data Scraper och Data Miner är endast för webbläsare.
Praktiska tips för att minska blockeringsrisk: Håll begärningsintervallen rimliga, undvik skrapning under rusningstid och rotera user agents om ditt verktyg stöder det. Och lova aldrig dig själv ”noll risk” — hantera den bara.
Från listningssida till produktsida: hur skrapning av undersidor fungerar på Amazon
Det här arbetsflödet underskattas — och ingen konkurrerande artikel visar det från början till slut.
När du skrapar en Amazon-sökresultatsida får du sammanfattningsdata: produktnamn, priser, betyg, ASIN:er och produkt-URL:er. Men ofta behöver du också data från detaljsidan — fullständiga beskrivningar, punktlistor, bild-URL:er, säljarinformation, uppdelning av recensioner. Det är där skrapning av undersidor kommer in.
Med Thunderbit ser arbetsflödet ut så här:
- Skrapa Amazons sökresultatsida → få en tabell med produkter (titel, pris, betyg, ASIN, produkt-URL).
- Klicka på ”Skrapa undersidor” → Thunderbit besöker varje produkt-URL och lägger till detaljfälten (beskrivning, antal recensioner, säljarens namn, bild-URL:er osv.) i samma tabell.
- Exportera den berikade tabellen till Google Sheets, Airtable, Notion eller Excel.
AI:n upptäcker strukturen på undersidorna och berikar tabellen automatiskt — ingen manuell konfiguration. Enligt min erfarenhet sparar det minst en timme per batch jämfört med att öppna varje produktsida och kopiera fälten för hand.
Andra verktyg kan också göra detta, men med mer arbete:
- Web Scraper: Du konfigurerar en sitemap för att följa produktlänkar och definierar selectors för varje detaljfält. Det fungerar, men är en manuell process i flera steg.
- Octoparse: Du bygger ett arbetsflöde med steg som följer länkar. Kraftfullt, men inte med ett klick.
- Axiom.ai: Du designar en bot-loop som besöker varje URL och extraherar data. Flexibelt, men kräver färdighet i att bygga botar.
- Data Miner: Du använder funktionen Crawl Scrape för att besöka sparade URL:er och tillämpa ett andra recept. Manuellt och beroende av recept.
- Instant Data Scraper och Helium 10: Inget arbetsflöde för berikning av undersidor.
Om du regelbundet behöver både listningsdata och detaljdata från Amazon bör verktyget du väljer göra det här arbetsflödet enkelt — inte bara möjligt.
Den ärliga uppdelningen av gratisnivåerna: vad du faktiskt får utan att betala
Forumanvändare frågar om detta mer än något annat, och ingen konkurrerande artikel svarar öppet på det.
| Tillägg | Gratisnivå | Vad du får gratis | När du behöver uppgradera |
|---|---|---|---|
| Thunderbit | Ja (6 sidor, 10 med test) | AI-förslag för fält, alla exportformat (Excel, Sheets, Airtable, Notion), e-post-/telefonextraktorer | När du behöver fler sidor eller schemalagd skrapning |
| Instant Data Scraper | Ja (helt gratis) | Grundläggande tabelligenkänning, CSV/Excel-export | Ej tillämpligt (ingen betalversion, men inga uppdateringar heller) |
| Web Scraper | Ja (endast webbläsare) | Skrapning i webbläsaren, CSV-export | Molnskrapning, schemaläggning, integrationer |
| Octoparse | Ja (begränsad) | Cirka 50K export/månad, lokal extraktion | Fler poster, molnnoder |
| Axiom.ai | Ja (2 tim körtid) | Grundläggande automationer, Google Sheets | Fler körningar, schemaläggning, moln |
| Data Miner | Ja (500 sidor/mån) | Recept, CSV/Excel, Next Page Automation | Fler sidor, Sheets, crawl-funktioner |
| Helium 10 | Ja (begränsad) | Begränsad åtkomst till Chrome-tillägget | Fullt Xray, sökordsverktyg, schemaläggning |
Den viktigaste insikten: Thunderbits gratisnivå inkluderar AI-funktioner och alla exportformat — de flesta konkurrenter låser avancerad export eller AI bakom betalda planer. Instant Data Scraper är helt gratis men saknar AI, undersidor och schemaläggning (och underhålls inte längre). Helium 10 har visserligen en gratisplan, men tillgången till tillägget är begränsad och det är inte en allmän skrapare.
Min rekommendation per scenario:
- ”Jag vill bara testa” → Instant Data Scraper (helt gratis) eller Thunderbits gratisnivå
- ”Jag behöver regelbunden, pålitlig skrapning” → Thunderbit eller Web Scrapers betalda planer
- ”Amazon-säljare som behöver marknadsintelligens” → Helium 10
Vilket Amazon Scraper-tillägg för Chrome ska du välja?
Efter att ha testat alla sju är min ärliga bedömning:
- Bäst för icke-tekniska användare som vill ha snabba, AI-drivna resultat: Thunderbit. AI identifierar fält automatiskt, berikar undersidor med ett klick, bredaste exportalternativen, växling mellan moln och webbläsare. Om du vill gå från Amazon-sida till kalkylark på under två minuter är det här mitt val.
- Bästa helt gratis alternativet för snabba engångsskrapningar: Instant Data Scraper. Ingen kostnad, inget konto, men begränsade funktioner och inte längre underhålls.
- Bäst för användare som är bekväma med manuell konfiguration: Web Scraper. Flexibel sitemap-byggare, bra molnalternativ, väl dokumenterad.
- Bäst för komplexa skrapkedjor i flera steg: Octoparse (skrivbord + tillägg) eller Axiom.ai (webbläsarbotar). Båda är kraftfulla, men inget av dem är ett rent ”installera och kör”-tillägg för Chrome.
- Bäst för enkel receptbaserad extraktion: Data Miner. Lätt att använda befintliga recept, men begränsad gratisnivå och ingen AI.
- Bäst för Amazon-säljarintelligens (inte generell skrapning): Helium 10. Byggt för ändamålet, djup egen data, men dyrt och inte en allmän skrapare.
Om du vill se hur AI-driven Amazon-skrapning faktiskt ser ut, . Jag tror att du kommer att bli förvånad över hur mycket du kan åstadkomma med bara några klick. Och om Thunderbit inte är helt rätt för dig, prova ett par andra från den här listan — det har aldrig varit bättre än nu att sluta kopiera och klistra in och börja skrapa smartare.
För fler tips om Amazon-skrapning, kolla in våra guider om , och . Du kan också titta på handledningar på .
Vanliga frågor
1. Är det lagligt att skrapa produktdata från Amazon?
Skrapning av offentligt synlig data är generellt tillåten, men Amazons förbjuder uttryckligen datautvinning och automatiserad extraktion utan skriftligt samtycke. Den här artikeln utgör inte juridisk rådgivning — granska alltid Amazons villkor innan du skrapar i större skala.
2. Kan Amazon upptäcka och blockera Chrome-tillägg som skrapar?
Ja. Amazon har antibotsystem som kan utlösa CAPTCHA:er, strypa förfrågningar eller blockera IP-adresser. Rimliga förfrågningshastigheter, webbläsarbaserad skrapning för små jobb och molnskrapning med begränsad hastighet för större jobb kan minska risken. Se avsnittet om moln vs. webbläsare ovan för en praktisk beslutsmatris.
3. Vilken data kan du skrapa från Amazon med ett Chrome-tillägg?
Vanliga fält inkluderar produktnamn, priser, betyg, antal recensioner, ASIN:er, säljarens namn, beskrivningar, bild-URL:er, tillgänglighet och fraktinformation. AI-drivna verktyg som Thunderbit kan automatiskt identifiera och föreslå dessa fält utan manuell inställning.
4. Behöver jag kodkunskaper för att använda ett Amazon Scraper-tillägg för Chrome?
Nej — alla sju verktyg som testades är designade för icke-tekniska användare. Vissa kräver mer inställning (Web Scraper, Octoparse, Axiom.ai) medan andra nästan är helt konfigurationsfria (Thunderbit, Instant Data Scraper). Avvägningen handlar oftast om flexibilitet kontra användarvänlighet.
5. Vilket Amazon Scraper-tillägg för Chrome har bäst gratisnivå?
Thunderbits gratisnivå inkluderar AI-baserad fältdetektering och alla exportformat (Sheets, Airtable, Notion, Excel, CSV, JSON), vilket de flesta konkurrenter låser bakom betalda planer. Instant Data Scraper är helt gratis men saknar AI, undersidor och schemaläggning. Data Miner erbjuder 500 gratis sidor/månad. Helium 10:s gratisplan är begränsad och fokuserad på säljresearch, inte generell skrapning.
Läs mer