
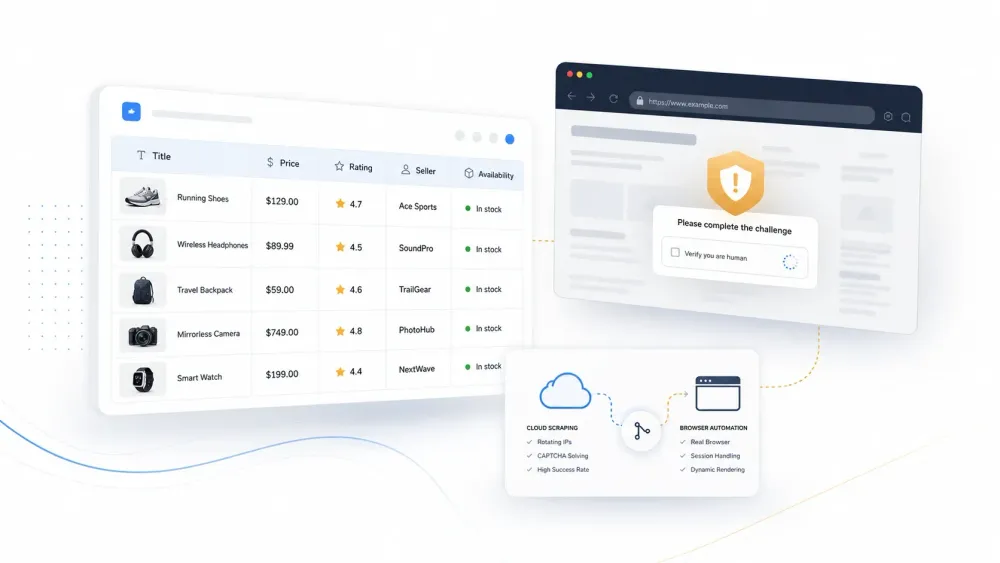
Varje AI-webbskrapare ser lysande ut i sin produktdemo. Sedan pekar du den mot en verklig webbplats med Cloudflare-skydd, och den skickar tillbaka en utmaningssida samtidigt som den självsäkert säger att den hittade 47 produktlistningar.
Jag har ägnat de senaste månaderna åt att utvärdera skrapverktyg för vårt team på Thunderbit. Glappet mellan demoresultat och driftsäkerhet är konsekvent den största frustrationen jag ser i communitys. En Reddit-användare sammanfattade det perfekt: "Vad håller i produktion och vad fungerar bara i en demo innan det dör två veckor senare?" Med 31 produkter listade på Capterra bara i kategorin webbscraping, plus dussintals fler Chrome-tillägg, API-leverantörer och actor-marknadsplatser, är valparadoxen på riktigt. Så jag testade 12 av dem.
Den här artikeln utvärderar 12 AI-webbskrapare mot produktionskriterier: hantering av antibot-skydd, skalbarhet, kvalitet på strukturerad utdata, kostnadseffektivitet, stöd för dynamiska sajter och flexibilitet för utvecklare. Inga funktionschecklistor. Inga marknadsföringsskärmdumpar. Bara det som faktiskt fungerar när demon är över.
Se hur en produktionsklar AI-webbskrapare ser ut
Varför de flesta AI-webbskrapare faller efter demon
Mönstret är förutsägbart. Ett verktygs presentationssida visar hur det extraherar rena kolumner från en enkel produktsida. Du installerar det, testar på en skyddad e-handelsplattform och får något av följande:
- Ett
200 OK-svar som innehåller en Cloudflare-utmaningssida i stället för verklig data - Rena resultat för de första 5 sidorna, sedan tysta fel eller påhittade rader
- Perfekt extrahering i dag, trasiga selektorer nästa vecka efter en mindre layoutuppdatering
Det här är inte undantag. Det är normen.
Som en praktiker uttryckte det på Reddit: "Skraparen returnerar ett 200 med en Cloudflare-utmaningssida, din agent försöker resonera kring det, hallucinerar, och du har ingen aning om varför."
Grundproblemet är arkitektoniskt. De flesta demos visar tolkningslagret på rena offentliga sidor, medan det verkliga arbetet faller på hämtlagret. Produktionssajter lägger till bot-skydd, dynamisk rendering, kapslade detaljsidor, oändlig scroll, inloggat läge, lokalvariation och föränderliga layouter.
Ett verktyg kan se fantastiskt ut i en produktdemo och ändå kollapsa redan i det första seriösa kundflödet.
Därför utvärderar den här artikeln varje verktyg utifrån produktionsberedskap snarare än en funktionschecklista. De sex kriterier jag använde:
| Kriterium | Varför det spelar roll |
|---|---|
| Hantering av antibot/CAPTCHA | Skyddade sajter fallerar innan extraktionskvalitet ens spelar roll |
| Skalbarhet bortom demo | Batchjobb och parallella körningar avslöjar operativa gränser |
| Kvalitet på strukturerad utdata | Användare behöver ren JSON/CSV, inte rå HTML som kräver manuell städning |
| Token-/kostnadseffektivitet | AI-extraktion kan bli dyrare än själva skrapningen |
| Stöd för dynamiska/JS-tunga sajter | Moderna sidor kräver renderad DOM, inte statisk HTML |
| No-code kontra API-flexibilitet | Säljteam och dataingenjörer har olika behov |
Om du vill ha en snabb överblick på marknadsnivå över hur webbscraping förändrades under de senaste två åren, är den här Browserless-föreläsningen en bra inledning innan du jämför verktyg ett och ett.
Var AI faktiskt hjälper i en scraping-pipeline (och var den inte gör det)
En seglivad myt i den här marknaden är att "AI-webbskrapare" betyder att AI sköter allt från början till slut. Konsensus i communityn är förvånansvärt tydlig: skrapare först, LLM sedan. En användares raka sammanfattning: "Du använder AI för att läsa en skärmdump av en webbsida. Du använder inte AI för att koda själva skraparen."
Scraping-pipelinen har tre tydliga lager, och AI:s värde varierar kraftigt mellan dem:
Crawling och hämtning: infrastrukturnivån
Det är här förfrågningarna sker: proxies, headless-browsers, sessionshantering, CAPTCHA-lösning, återförsök. AI gör nästan inget nyttigt här. Du behöver fortfarande proxy-pooler, browser fingerprinting och unblocking-infrastruktur. Det är här de flesta verktyg fallerar först i produktion.
Parsning och extrahering: där AI glänser
När du väl har rent sidinnehåll är AI utmärkt på att omvandla ostrukturerad HTML till strukturerade fält. Schema-baserad extrahering, adaptiv fältidentifiering och hantering av layoutvariationer utan bräckliga XPath-selektorer är AI:s starka sida inom scraping.
Efterbearbetning: etikettering, översättning, kategorisering
Efter extraheringen tillför AI värde genom att kategorisera produkter, översätta text, normalisera telefonnummer eller sammanfatta beskrivningar. Det är en bra matchning, men bara om den extraherade datan redan är korrekt.
Så här fördelar sig de 12 verktygen över dessa lager:
| Verktyg | Crawling/hämtning | Parsning/extrahering | Efterbearbetning | Bästa beskrivning |
|---|---|---|---|---|
| Thunderbit | Stark | Stark | Stark | Fullstack no-code AI-skrapare |
| Octoparse | Stark | Medel | Låg | Regelbaserad visuell skrapare med molninfrastruktur |
| Browse AI | Medel | Medel | Medel | Molnrobotplattform med fokus på övervakning |
| Firecrawl | Medel | Stark | Låg–medel | API för utvecklare för extrahering |
| Apify | Stark | Medel–stark | Medel | Actor-marknadsplats och orkestrering |
| Gumloop | Medel | Medel | Stark | Automatisering av arbetsflöden med skrapnoder |
| Bright Data | Mycket stark | Medel | Låg–medel | Infrastrukturstack för enterprise |
| Bardeen | Medel | Medel | Stark | Webbläsarautomatisering för GTM-arbetsflöden |
| Diffbot | Låg–medel | Mycket stark | Medel | Förtränad extrahering plus kunskapsgraf |
| ScrapingBee | Stark | Låg–medel | Låg | API för hämtning och unblocking |
| Instant Data Scraper | Låg | Medel (enkla sidor) | Låg | Snabb heuristisk skrapare direkt i webbläsaren |
| ParseHub | Medel | Medel | Låg | Visuell skrivbords-skrapare för komplexa interaktioner |
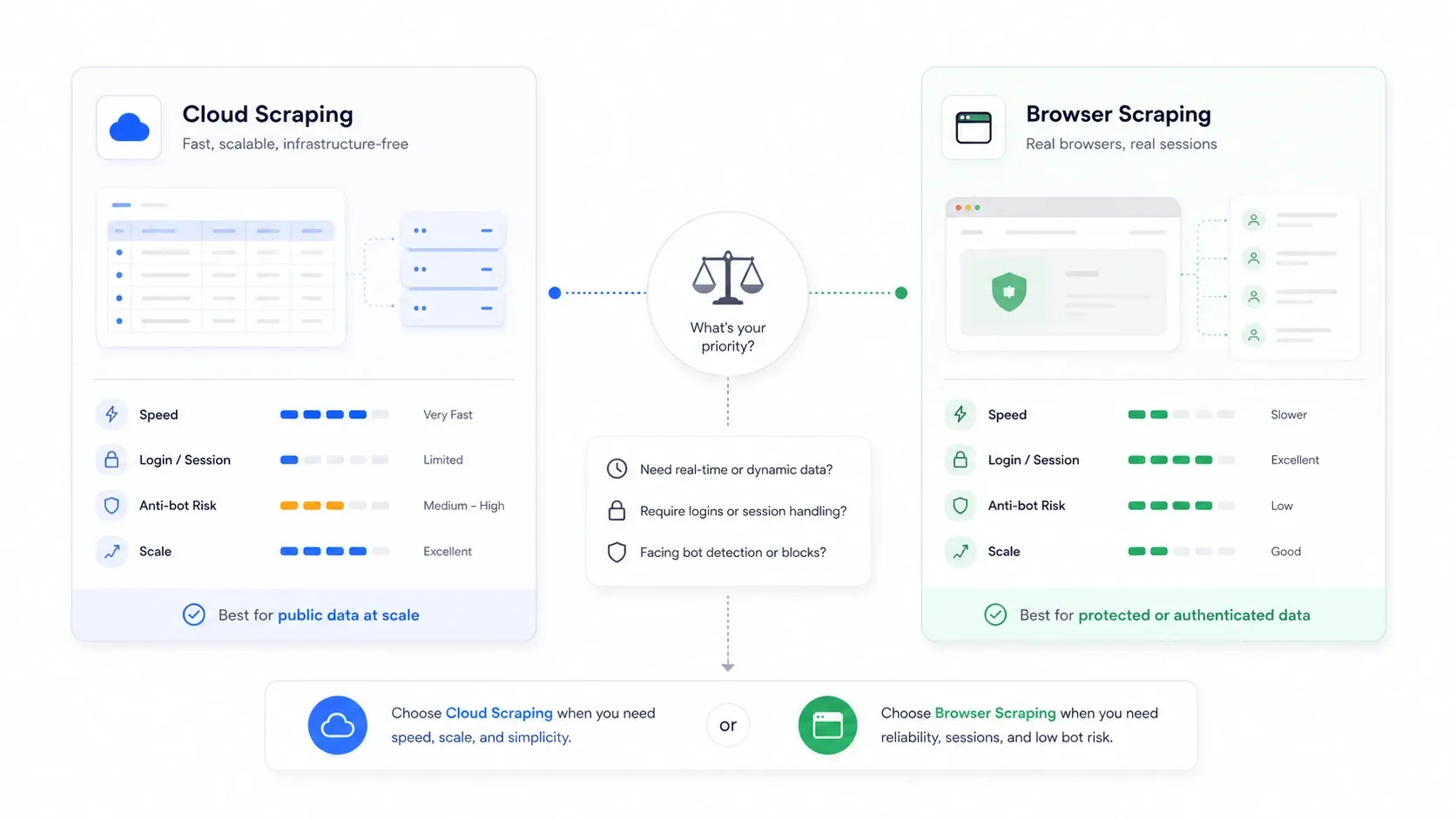
Molnskrapning kontra webbläsarskrapning: valet ingen förklarar
Det här är det arkitekturbeslut som de flesta sammanställningsartiklar helt ignorerar, och det är ofta viktigare än vilket verktyg du väljer.
Molnskrapning betyder att fjärrservrar hämtar sidor åt dig. Webbläsarskrapning betyder att extraheringen sker i din egen webbläsarsession, med dina cookies, din IP och din autentiserade status.
| Scenario | Bättre läge | Varför |
|---|---|---|
| Offentliga e-handels- och listningssajter i stor skala | Moln | Snabbare parallellism och ingen flaskhals på den lokala datorn |
| Sajter som kräver inloggning eller autentisering | Webbläsare | Återanvänder dina riktiga sessionscookies |
| Sajter som straffar datacenter-IP:er | Webbläsare | Ser ut som vanlig användartrafik |
| Stora återkommande övervakningsjobb | Moln | Enklare schemaläggning och kontinuitet |
| Engångsjobb som är sköra och känsliga för antibot | Webbläsare | Enklare att inspektera vad sajten faktiskt renderade |
Det här är också ekonomiskt viktigt. Apifys rapport State of Web Scraping 2026 visade att 65,8 % av utövarna ökade användningen av proxies år över år, och 62 %+ rapporterade högre infrastrukturkostnader. Antibot är inte bara ett tekniskt problem. Det är en budgetfråga.
De flesta verktyg erbjuder bara ett läge. Här är fördelningen:
| Verktyg | Moln | Webbläsare | Båda |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (lokalt) | ✅ |
| Browse AI | ✅ | Endast setup | — |
| Firecrawl | ✅ | API för interaktivt | — |
| Apify | ✅ | ✅ (via actors) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Begränsat (offentliga sidor) | ✅ | Delvis |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (betald) | ✅ (desktop) | ✅ |
De 12 AI-webbskraparna i korthet
Här är huvudjämförelsen mellan alla 12 verktyg:
| Verktyg | Bäst för | Gratisnivå | Moln/Webbläsare | API-åtkomst | Schemalagd skrapning | Hantering av antibot |
|---|---|---|---|---|---|---|
| Thunderbit | Icke-tekniska team | ✅ (6 sidor) | Båda | ✅ | ✅ | Stark |
| Octoparse | Malltung scraping | ✅ (begränsad) | Båda | ✅ | ✅ | Medel–stark |
| Browse AI | Övervakning av förändringar | ✅ (begränsad) | Främst moln | ✅ | ✅ | Medel |
| Firecrawl | Extraktionspipelines för utvecklare | ✅ (1 000 credits/mån) | Moln plus webbläsar-API | ✅ | Nej | Medel |
| Apify | Utvecklingsteam plus marknadsplats | ✅ ($5 gratisanvändning) | Båda | ✅ | ✅ | Stark med tillägg |
| Gumloop | Automatisering av arbetsflöden | ✅ (5 000 credits/mån) | Båda | ✅ | ✅ | Medel |
| Bright Data | Enterprise-dataåtkomst | Test / credits | Båda | ✅ | Extern | Mycket stark |
| Bardeen | Webbläsarautomatisering för sälj och ops | ✅ (100 credits) | Webbläsar-först | Begränsad | ✅ | Medel-låg |
| Diffbot | Strukturerade extraktions-API:er | ✅ (10 000 credits) | Moln | ✅ | Nej | Låg på hämtning / hög på extraktion |
| ScrapingBee | Hämtning och unblocking för utvecklare | ✅ (1 000 credits) | Moln | ✅ | Nej | Stark |
| Instant Data Scraper | Gratis engångsskrapningar | ✅ (helt gratis) | Endast webbläsare | Nej | Nej | Låg |
| ParseHub | Komplexa visuella arbetsflöden | ✅ (5 projekt) | Desktop plus moln | ✅ | ✅ (betald) | Medel |
Förstå hur AI-extrahering passar in i en verklig scraping-pipeline
1. Thunderbit
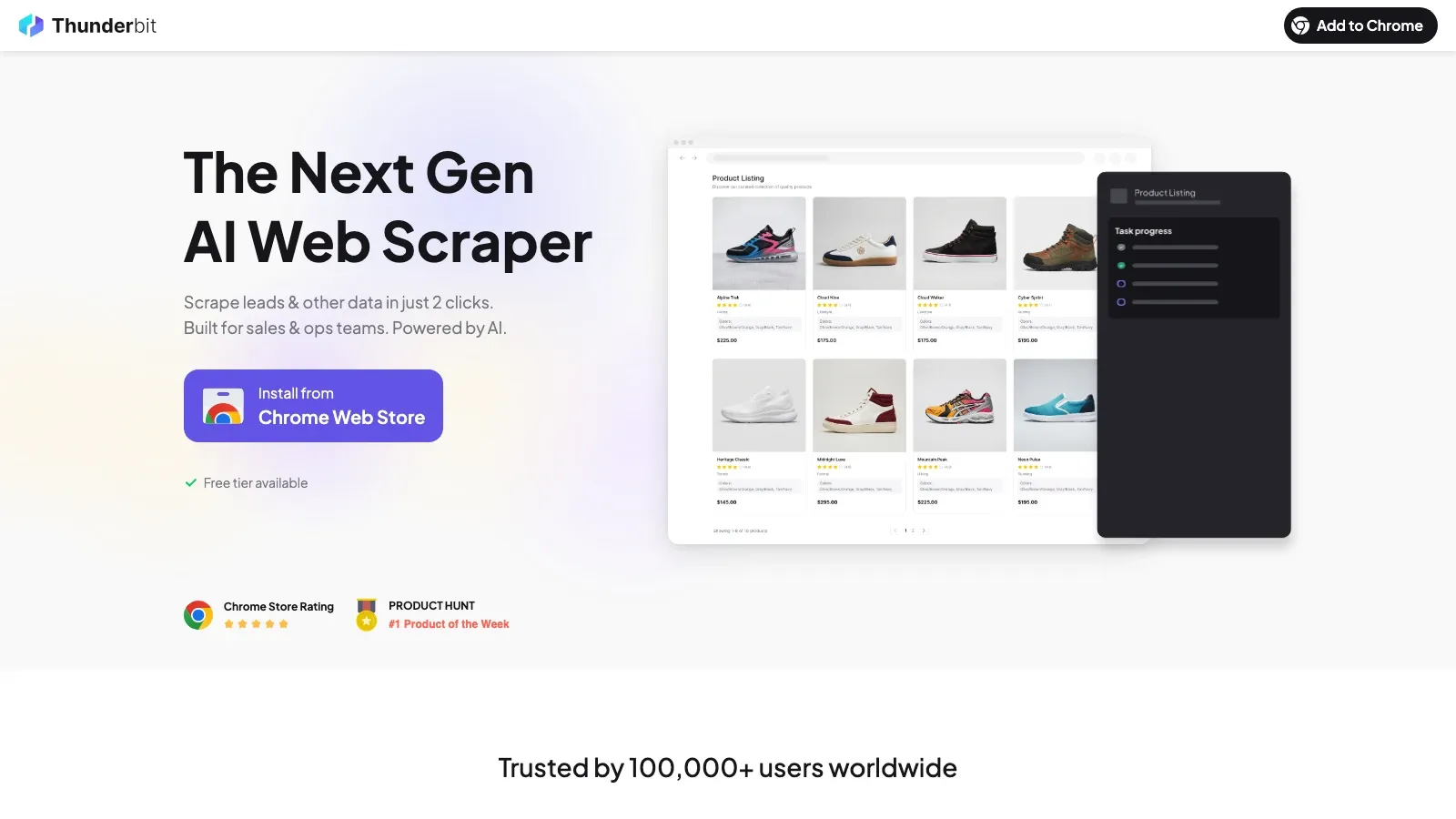
Thunderbit är den AI-webbskrapare vi byggde specifikt för icke-tekniska team som behöver data av produktionskvalitet utan att skriva kod eller hantera infrastruktur. Kärnflödet är verkligen två klick: AI Suggest Fields läser sidan och föreslår kolumner, sedan kör Scrape extraheringen i moln- eller webbläsarläge.
Det som skiljer den från andra no-code-skrapare är arkitekturen. Thunderbit separerar crawlningsfrågor som molninfrastruktur, proxyrotation, antibot-hantering och JavaScript-rendering från AI-extraktion som läser HTML och outputar strukturerade kolumner. Det matchar det expertrekommenderade mönstret "skrapare först, LLM sedan", men paketerat i ett Chrome-tilläggsflöde som säljare och operativa chefer faktiskt kan använda.
Viktiga styrkor
- Både moln- och webbläsarskrapning i samma gränssnitt. Växla mellan lägen beroende på om målwebbplatsen är offentlig eller kräver din autentiserade session. Molnläget hanterar upp till 50 sidor parallellt.
- AI läser om sidstrukturen varje gång. Inget XPath-underhåll. När en sajt uppdaterar sin layout anpassar sig Thunderbit automatiskt vid nästa körning.
- Skrapning av undersidor. AI besöker länkade detaljsidor och berikar huvudtabellen utan manuell konfigurering.
- Field AI Prompts. Anpassad etikettering, översättning och kategorisering under extraheringen i stället för som ett separat efterbearbetningssteg.
- Gratis export till Google Sheets, Excel, Airtable och Notion.
- Omedelbara skrapmallar för populära sajter som Amazon, Zillow och LinkedIn.
- Schemaläggning med naturligt språk. Säg "skrapa varje måndag klockan 9" så omvandlas det till ett återkommande schema.
- Öppet API med Distill- och Extract-endpoints, batchbearbetning upp till 100 URL:er och publicerad samtidighet från 2 i gratisversionen till 50 i Pro 1.
Vad som kan förbättras
- Gratisnivån är medvetet liten.
- Chrome-tilläggscentrerad för no-code-upplevelsen. Utvecklare som vill ha API-bara arbetsflöden behöver använda Open API separat.
- Inte rätt verktyg om ditt främsta behov är rå proxy-infrastruktur utan extrahering.
Prissättning
Gratisnivå finns. No-code-planer börjar från $9/månad vid årlig debitering eller $15/månad vid månadsdebitering för Starter. API-prissättning är separat: gratis engångs 600 enheter, därefter $16/månad vid årlig debitering för Starter API och $40/månad vid årlig debitering för Pro 1 API. Se Thunderbit Prissättning och API-prissättning.
Bäst för: Sälj-, e-handels- och operationsteam som behöver strukturerad webdata utan stöd från utvecklare.
2. Octoparse
Octoparse är en visuell arbetsflödesbyggare för webbscraping med ett stort bibliotek av färdiga mallar. Den har funnits tillräckligt länge för att ha mogen molninfrastruktur, och den hanterar paginering väl på strukturerade, förutsägbara webbplatser.
Viktiga styrkor
- Omfattande färdiga skrapmallar för populära sajter
- Molnextrahering med schemalagda körningar
- IP-rotation och CAPTCHA-lösning som betalda tillägg
- API-åtkomst på högre planer
Vad som kan förbättras
- AI-funktionerna är lättare än LLM-native verktyg. Fältförslag bygger fortfarande mer på mallar än på adaptiv läsning.
- Komplexa eller ovanliga layouter kräver betydande manuell finjustering i den visuella redigeraren.
- Inlärningskurvan blir brantare när du behöver villkorslogik eller kringgå blockeringar.
Prissättning
Gratis plan finns för alltid. Officiell prisinformation i hjälpcentret pekar just nu på Standard från $75/månad vid årlig debitering och Professional från $208/månad vid årlig debitering, medan vissa lokaliserade sidor och uppgraderingsvägar visar högre månadsekvivalenter. Det viktiga är att Octoparse prissättning numera blandar prenumerationsnivåer med betalda tillägg som residential proxies och CAPTCHA-lösning.
Bäst för: Analytiker och operationsteam som skrapar strukturerade, mallvänliga sajter i måttlig skala.
3. Browse AI
Browse AI är en molnbaserad no-code-plattform byggd främst för övervakning av webbplatsförändringar över tid, såsom konkurrentpriser, lagerstatus och innehållsuppdateringar. Skrapning är en del av produkten, men den verkliga skillnaden är det återkommande övervaknings- och varningssystemet.
Viktiga styrkor
- Inbyggd förändringsdetektering och varningar
- No-code-robotinspelare med klick-och-peka-upplägg
- Färdiga robotar för populära sajter
- Premium-proxy-stöd på högre planer
Vad som kan förbättras
- Kreditbaserad prissättning blir snabbt dyr när detaljsidor övervakas i stor skala
- Mindre attraktivt för engångsextrahering i stor skala än API-först-verktyg
- Måttlig antibot-hantering; vissa sajter kräver fortfarande premium-proxies eller kringgåenden
Prissättning
Gratis konto finns. Betalda planer börjar runt $19/månad vid årlig debitering för Starter, med högre kredit- och övervakningsnivåer ovanför det.
Bäst för: Team som behöver löpande övervakning av konkurrentpriser, innehållsförändringar eller lagernivåer snarare än engångsextrahering i bulk.
4. Firecrawl
Firecrawl är ett utvecklarfokuserat API som omvandlar webbsidor till ren Markdown eller strukturerad JSON. Det ligger främst i extraktionslagret och är utmärkt för team som bygger RAG-pipelines eller matar webbinnehåll till LLM:er.
Viktiga styrkor
- Utmärkt kvalitet på Markdown-utdata för nedströms LLM-flöden
- Rent API med scrape, crawl, map, search, extract och browser actions
- Stöd för batchbearbetning
- Samtidighet från 2 i gratisversionen till 100 i Growth
Vad som kan förbättras
- Ingen no-code-gränssnitt och kräver utvecklarkompetens
- Inbyggd hjälp för proxy och antibot finns, men Firecrawl är inte positionerat som en dedikerad unblocking-leverantör
- Ingen schemaläggare från första part för återkommande jobb
- Inte kostnadseffektivt för icke-utvecklare som bara vill ha ett kalkylblad med data
Prissättning
Gratisplanen inkluderar 1 000 credits per månad. Betalda planer börjar på $16/månad vid årlig debitering för Hobby och skalar upp med fler credits, mer samtidighet och webbläsaranvändning. Webbläsarsessioner debiteras separat i credits.
Bäst för: Utvecklare som bygger LLM-pipelines, RAG-system eller anpassade extraheringsflöden och behöver ren Markdown eller JSON från webbsidor.
5. Apify
Apify är en plattform med en marknadsplats av färdiga skrap-actors plus verktyg för att bygga egna. Se det som ett orkestreringslager där du väljer eller bygger specialiserade skrapare för specifika sajter och sedan schemalägger och hanterar dem via ett gemensamt API.
Viktiga styrkor
- Enorm actor-marknadsplats med communitybyggda skrapare för hundratals sajter
- Stark API och SDK för utvecklare
- Inbyggd proxyhantering och schemaläggning
- Integrerar med många nedströmsverktyg
Vad som kan förbättras
- "No-code" är bara delvis sant när du lämnar marknadsplatsen och behöver egen logik
- Actor-tillförlitlighet beror på communityns underhåll
- Priset kan eskalera eftersom compute, actor-kostnader och proxies staplas på varandra
Prissättning
Gratisnivån inkluderar $5 i månatliga plattformskrediter. Betalda planer börjar på $39/månad för Starter, med skalorienterade nivåer ovanför det.
Bäst för: Utvecklingsteam som vill ha återanvändbara, schemaläggbara scraping-flöden med ett stort ekosystem av färdiga lösningar.
6. Gumloop
Gumloop är en no-code-plattform för arbetsflödesautomatisering som innehåller en nod för webbscraping. Det verkliga värdet ligger inte i skrapningen ensam. Det är att koppla extrahering till LLM:er, Google Sheets, CRM-system och andra verktyg i en enda visuell yta.
Viktiga styrkor
- Visuell drag-and-drop-byggare för arbetsflöden
- Integrerar skrapning med LLM:er och nedströms affärsverktyg i ett enda flöde
- Gratisplanen annonseras just nu med 5 000 credits/månad
- Tidsbaserad schemaläggning för återkommande arbetsflöden
- Grundläggande skrapning och interaktiva Web Agent-lägen täcker både enkla och mer avancerade flöden
Vad som kan förbättras
- Skrapmotorn är mindre robust än dedikerade AI-webbskrapare
- Begränsad djup i antibot och proxy jämfört med specialiserade leverantörer
- Samtidighet och triggergränser är snävare på gratisplaner
- Inte idealiskt för storskalig, högvolyms-skrapning som primärt användningsfall
Prissättning
Gratisplan finns. Gumloop slog i slutet av 2025 ihop sin tidigare Solo- och Team-struktur till en Pro-plan, och den offentliga kommunikationen sedan dess fokuserar mer på generösare gratiscredits och samlade betalda nivåer än på scraper-first-prissättning.
Bäst för: Team som vill att skrapning bara ska vara ett steg i ett bredare automatiserat arbetsflöde: skrapa, analysera och skicka vidare till affärsverktyg.
Om du vill se hur ett AI-inbyggt extraktionsflöde känns i praktiken innan du läser resten av listan, är den här Thunderbit-genomgången den mest relevanta produktdemonstrationen för icke-tekniska team.
7. Bright Data
Bright Data är enterprise-infrastrukturstacken på den här listan. Om ditt problem är "Jag kommer inte förbi botskyddet på den här sajten hur jag än försöker" är Bright Data förmodligen svaret, men det kommer med enterprise-komplexitet och prissättning som matchar.
Viktiga styrkor
- Branschledande proxynätverk över residential, datacenter och mobila IP:er
- Web Unlocker för antibot och CAPTCHA-bypass
- Scraping Browser med inbyggd unblocking
- Förinsamlade dataset att köpa
- Full programmatisk kontroll via API och SDK
Vad som kan förbättras
- Inte byggt för icke-tekniska användare
- Prissättningen speglar enterprise-positioneringen
- AI-extraktion är inte den främsta anledningen att köpa plattformen
Prissättning
Browser API börjar på $8/GB pay as you go, med lägre pris per GB vid större månatliga åtaganden. Andra Bright Data-produkter som Unlocker, Scraper APIs, datasets och proxy-pooler använder olika prisenheter.
Bäst för: Datateam i enterprise som behöver skrapa hårt skyddade sajter i stor skala och har teknisk personal för att hantera infrastrukturen.
8. Bardeen
Bardeen är ett verktyg för webbläsarautomatisering med fokus på klick, ifyllning av formulär och skrapning där AI-driven dataextraktion ligger ovanpå. Det förstås bäst som ett GTM-flödesverktyg som råkar skrapa, inte som ett skrapverktyg som råkar göra GTM.
Viktiga styrkor
- Intuitiv automation i playbook-stil där skrapning är ett steg
- Officiella skrapare underhållna av Bardeens team för populära sajter
- Stark integration med CRM, Google Sheets, Slack och andra affärsverktyg
- Bra för lead-skrapning, berikning och arbetsflöden för CRM-export
Vad som kan förbättras
- Webbläsarförst-arkitekturen begränsar obevakad skrapning i hög volym
- Molnskrapning fungerar bara på offentliga sidor, inte på låsta sådana
- Antibot-hanteringen är i stort sett det din webbläsarsession redan ger
- AI-extraktionen kan ha svårt med komplexa eller icke-standardiserade sidlayouter
Prissättning
Gratisplanen inkluderar 100 månatliga credits. Offentlig supportdokumentation hänvisar till äldre $15/månad Pro-prissättning för befintliga användare, medan Bardeens nuvarande kommersiella paketering är mer enterprise- och arbetsflödesorienterad än klassisk lågpris-skrapning.
Bäst för: Sälj- och operationsteam som behöver skrapning som en del av ett bredare arbetsflöde för webbläsarautomatisering.
9. Diffbot
Diffbot använder datorseende och NLP för att läsa webbsidor som en människa och skickar ut strukturerad data för artiklar, produkter, diskussioner och organisationer. Det är en av de högst kvalitetssäkrade extraktions-API:erna som finns om dina sidor passar dess förtränade modeller.
Viktiga styrkor
- Förtränade extraktionsmodeller för artiklar, produkter, diskussioner med mera
- Knowledge Graph med miljarder entiteter för databerikning
- Stark kvalitet på strukturerad utdata för stödda sidtyper
- Tydligt utvecklar-API med publicerade rate limits
Vad som kan förbättras
- Ingen no-code-gränssnitt
- Ingen inbyggd crawling, proxyhantering eller antibot-hantering
- Dyrt för små team
- Mindre flexibel på icke-standardiserade sidtyper än schema-prompt-extraktorer
Prissättning
Gratisplanen inkluderar 10 000 credits. Startup är $299/månad för 250 000 credits, och Plus är $899/månad för 1 000 000 credits.
Bäst för: Utvecklingsteam som behöver högprecisions-strukturerad extrahering från standardiserade sidtyper och är beredda att hantera hämtningen separat.
10. ScrapingBee
ScrapingBee är ett webbscraping-API med fokus på hämtnings- och unblocking-lagret. Du skickar en URL, verktyget hanterar proxies, headless-browser-rendering och antibot-försvar, och det returnerar HTML eller valfritt extraherad data.
Viktiga styrkor
- Inbyggd proxyrotation och antibot-hantering
- Stöd för JavaScript-rendering
- Enkelt REST API
- Endpoint för skrapning av Google Search
- Publicerad samtidighet per plan
Vad som kan förbättras
- AI-extraktionsfunktionerna är begränsade
- Ingen no-code-gränssnitt
- Ingen inbyggd schemaläggning eller övervakning
- Ett
200-svar med en block-sida kan fortfarande räknas som en lyckad förfrågan
Prissättning
Gratisplanen inkluderar 1 000 API credits. Betalda planer börjar på $49/månad och skalar upp med högre samtidighet och förfrågningsvolym.
Bäst för: Utvecklare som främst behöver pålitlig sidhämtning förbi antibot-skydd och som kommer att hantera extraheringen med egen kod eller ett separat verktyg.
11. Instant Data Scraper
Instant Data Scraper är ett gratis Chrome-tillägg med över 1 000 000 användare som automatiskt känner igen datamönster på en sida och låter dig exportera till CSV eller Excel. Det finns inget AI-förslag av fält i LLM-mening. Det använder heuristisk mönsteridentifiering.
Viktiga styrkor
- Helt gratis, inget konto krävs
- Datadetektering med ett klick på många listnings- och tabellsidor
- Hanterar paginering på vissa sajter
- Extremt låg tröskel att komma igång
- Underhålls fortfarande, med uppdateringar i Chrome Web Store under 2026
Vad som kan förbättras
- Inget AI-drivet fältförslag eller datamärkning
- Ingen molnskrapning, schemaläggning eller API
- Kämpar med komplexa layouter, dynamiskt innehåll och JS-tunga sajter
- Ingen antibot-hantering utöver det din webbläsare redan kan ladda
- Export begränsad till CSV och Excel
Prissättning
Gratis. För alltid.
Bäst för: Alla som behöver en snabb, engångs skrapning av en enkel listningssida och inte vill skapa ett konto eller betala något.
12. ParseHub
ParseHub är en skrivbordsapplikation med ett visuellt, klicka-och-peka-gränssnitt för att bygga skrapprojekt. Den kan hantera komplex kapslad data, AJAX-laddat innehåll, oändlig scroll och dropdown-interaktioner som enklare tillägg ofta missar.
Viktiga styrkor
- Visuellt selektorsgränssnitt för att definiera extraktionsregler
- Hanterar kapslad data, dropdowns, oändlig scroll och AJAX-innehåll
- Gratisnivå med upp till 5 projekt
- Export till JSON, CSV och Excel
- Molnschemaläggning och IP-rotation på betalda planer
Vad som kan förbättras
- Endast desktop-arbetsflöde, ingen bekvämlighet som webbläsartillägg ger
- Långsammare körhastighet jämfört med molnnativa verktyg
- Projekt går sönder när sajtens layout ändras eftersom det inte finns något AI-lager som läser om sidan
- Begränsade AI-funktioner och en mer gammaldags känsla av visuell skrapare
Prissättning
Gratisplan finns med 5 projekt och 200 sidor per körning. Betalda planer börjar på $189/månad med schemaläggning, IP-rotation och högre gränser.
Bäst för: Icke-tekniska användare som behöver skrapa komplexa interaktiva sajter och är beredda att lägga tid på att sätta upp ett visuellt arbetsflöde.
Så kommer du igång med en AI-webbskrapare i 5 steg
Varje verktyg på den här listan har ett annat onboardingflöde. Jag använder Thunderbit som konkret exempel eftersom det bäst matchar sökintentionen "jag behöver bara att det här fungerar på en riktig sida".
Steg 1: Installera och navigera
Installera Thunderbit Chrome-tillägget och gå till sidan du vill skrapa: en produktsida, en katalog eller en fastighetsportal.
Steg 2: Låt AI föreslå dina datafält
Klicka på AI Suggest Fields. AI:n läser den aktuella sidan och föreslår kolumnnamn och datatyper. På en produktsida kan den föreslå Produktnamn, Pris, Betyg, Bild-URL och Beskrivning.
Steg 3: Anpassa fälten med AI-prompter
Justera kolumnerna om standardinställningarna inte riktigt stämmer. Lägg till Field AI Prompts för anpassade transformationer som "översätt beskrivningen till spanska", "kategorisera som Elektronik, Hem eller Mode" eller "extrahera bara det numeriska priset".
Steg 4: Välj moln- eller webbläsarläge och skrapa
Välj molnskrapning för offentliga sajter eller webbläsarskrapning för autentiserade eller hårt skyddade mål. Klicka sedan på Scrape.
Steg 5: Exportera din data till valfri plats
Exportera resultaten till Google Sheets, Excel, Airtable eller Notion. Exporter är gratis.
Vad händer om sajtens layout ändras?
Det här är den viktigaste produktionsfördelen med AI-inbyggda extraktorer framför regelbaserade verktyg. Traditionella skrapare som ParseHub och äldre Octoparse-flöden förlitar sig på XPath-selektorer eller CSS-sökvägar. När en sajt uppdaterar sin HTML-struktur går dessa selektorer sönder och du är tillbaka vid manuell omkonfigurering.
AI-drivna extraktorer som Thunderbit läser om sidstrukturen varje gång. Det betyder inget XPath-underhåll och inga sköra selektorer. AI:n anpassar sig automatiskt till layoutförändringar vid nästa körning.
Schemalagd skrapning och API-åtkomst: power user-funktionerna ingen recenserar
Engångsskrapningar är bra för research. Produktionsfall som prisövervakning, uppdatering av lead-listor och lageruppföljning kräver återkommande extrahering och programmatisk åtkomst. Dessa funktioner skiljer leksaker från verktyg.
Stöd för schemaläggning
| Verktyg | Inbyggd schemaläggning | Noteringar |
|---|---|---|
| Thunderbit | ✅ | Uppställning med naturligt språk |
| Octoparse | ✅ | Schemalagda molnkörningar |
| Browse AI | ✅ | Kärnfunktion i produkten |
| Firecrawl | ❌ | Använd extern cron |
| Apify | ✅ | Fulla cron-uttryck |
| Gumloop | ✅ | Tidsbaserade workflow-triggers |
| Bright Data | Extern | Orkestreras vanligtvis via kundens system |
| Bardeen | ✅ | Schemaläggning av playbooks |
| Diffbot | ❌ | API-först, extern orkestrering |
| ScrapingBee | ❌ | Endast API |
| Instant Data Scraper | ❌ | Manuellt webbläsarverktyg |
| ParseHub | ✅ (betald) | Premiumfunktion |
Jämförelse av utvecklar-API
| Verktyg | Signal för samtidighet eller hastighet | Prissättningsmodell |
|---|---|---|
| Thunderbit | 2 → 50 samtidiga | Kreditbaserad |
| Firecrawl | 2 → 100 samtidiga | Kreditbaserad |
| Apify | Beror på plan | Compute-enheter |
| Gumloop | Planbegränsad samtidighet i arbetsflöden | Kreditbaserad |
| Diffbot | 5 anrop/min → 25 anrop/sek | Kreditbaserad |
| ScrapingBee | 10 → 200 samtidiga | API-kreditbaserad |
| Bright Data | Browser API marknadsför obegränsade samtidiga förfrågningar | GB-baserad |
Om ditt användningsfall är mer tekniskt och du försöker avgöra hur mycket infrastruktur du vill äga, är den här genomgången av Firecrawl ett användbart, exekveringsorienterat komplement till produktjämförelserna ovan.
Hur du väljer rätt AI-webbskrapare
Efter att ha testat alla 12 verktyg, här är hur jag skulle välja:
- Icke-tekniskt team som behöver data snabbt: Börja med Thunderbit. Tvåklicksflödet, gratis export och växling mellan webbläsare och moln täcker de flesta affärsbehov inom scraping utan stöd från utvecklare.
- Behöver löpande övervakning och varningar: Browse AI är byggt för just detta. Det är inte den starkaste engångsextraktorn, men förändringsdetektering är en förstklassig funktion.
- Utvecklare som bygger en LLM-pipeline: Firecrawl för Markdown- eller JSON-extrahering, eller Diffbot för förtränad strukturerad extrahering. Para ihop något av dem med ScrapingBee eller Bright Data om du behöver seriös antibot-hantering i hämtlagret.
- Behöver en marknadsplats med färdiga skrapare: Apify har det största actor-ekosystemet. Var bara beredd på underhåll när actors går sönder.
- Enterprise-skala, hårt skyddade mål: Bright Data. Inget annat matchar dess proxyinfrastruktur, men budget och teknisk personal måste också matcha.
- Vill ha skrapning som del av större automation: Gumloop eller Bardeen, beroende på om du automatiserar arbetsflöden eller webbläsarbaserade GTM-uppgifter.
- Behöver bara en snabb gratis skrapning: Instant Data Scraper. Ingen setup, ingen kostnad, ingen komplexitet, men också ingen schemaläggning, ingen AI och inget moln.
- Komplexa interaktiva sajter med dropdowns och AJAX: ParseHub hanterar fortfarande detta bättre än de flesta tillägg, även om underhållsbördan är verklig.
Testa Thunderbit på en riktig sida innan du satsar på en större stack
Slutsats
Marknaden för AI-webbskrapare 2026 är full av verktyg som ser imponerande ut i demos och gör en besviken i produktion. Glappet mellan "fungerar på en marknadsföringsskärmdump" och "fungerar på en skyddad e-handelsplats klockan 03.00 enligt schema" är där de flesta köpare slösar tid och pengar.
Den viktigaste insikten från utvärderingen av alla 12 verktyg är enkel: hämtlagret är fortfarande den svåra delen. AI är utmärkt på extrahering och efterbearbetning, men ersätter inte proxy-infrastruktur, antibot-hantering eller sessionshantering. De bästa verktygen löser båda lagren, som Thunderbit och Bright Data, eller är ärliga med vilket lager de täcker, som Firecrawl för extrahering och ScrapingBee för hämtning.
Om du vill se hur en produktionsklar AI-webbskrapare ser ut utan att skriva kod, testa Thunderbit. Gratisnivån räcker för att prova hela arbetsflödet på riktiga sidor. Om dina behov är mer utvecklarorienterade, para ihop ett extraktions-API med en dedikerad hämtningstjänst och bespara dig frustrationen av att förvänta dig att ett enda verktyg ska göra allt.
Vanliga frågor
Varför misslyckas de flesta AI-webbskrapare på riktiga webbplatser efter att ha fungerat bra i demos?
Demos visar vanligtvis extrahering på rena, oskyddade sidor. Verkliga sajter lägger till Cloudflare-skydd, dynamisk JavaScript-rendering, paginering, inloggningskrav och ofta föränderliga layouter. De flesta verktyg hanterar tolknings- och extraktionslagret väl men saknar robust infrastruktur för hämtlagret.
Vad är skillnaden mellan molnskrapning och webbläsarskrapning, och när ska jag använda respektive?
Molnskrapning använder fjärrservrar för att hämta sidor, vilket är snabbare, mer parallellt och skalbart. Webbläsarskrapning körs i din egen webbläsarsession och är bättre för autentiserade sajter eller sajter med aggressiv bot-detektering. Thunderbit är ett av få verktyg som erbjuder båda lägena i samma gränssnitt.
Kan jag använda en AI-webbskrapare för återkommande uppgifter som prisövervakning?
Ja, men bara om verktyget stöder schemalagd skrapning. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen och ParseHub på betalda planer erbjuder alla schemaläggning.
Vilken AI-webbskrapare är bäst om jag saknar kodningskunskaper?
Thunderbit ger snabbast väg till användbar data för icke-tekniska användare. Instant Data Scraper är helt gratis men begränsad till enkla sidor. Browse AI och Octoparse erbjuder visuella gränssnitt med mer setup. ParseHub är kraftfullt för komplexa interaktiva sajter men har brantare inlärningskurva.
Hur mycket kostar AI-webbscraping i produktionsklass egentligen?
Spannet är stort. Instant Data Scraper är gratis. Thunderbit, Firecrawl och Browse AI erbjuder gratis ingångspunkter med billiga betalda planer. Mellanklassverktyg som Octoparse, ParseHub och ScrapingBee kan kosta från cirka $49 till $189 per månad. Enterprise-lösningar som Bright Data och Diffbot börjar betydligt högre.




