
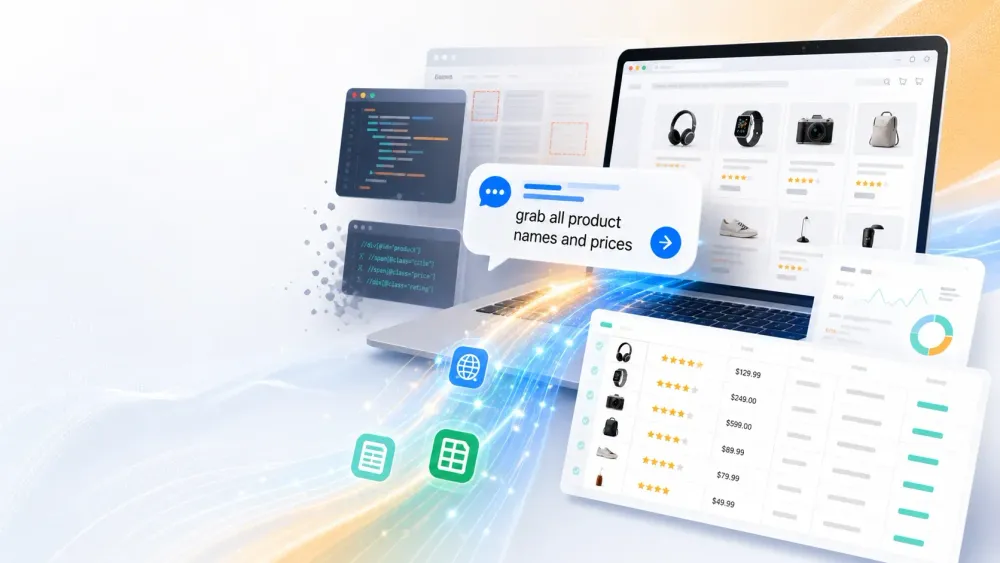
År 2015 betydde skrapning att man bad en utvecklare om ett Python-skript eller tillbringade en helg med att lära sig XPath. År 2026 skriver du ”hämta alla produktnamn och priser”, så sköter AI resten.
Det skiftet gick fort. Över 2 miljoner företag förlitar sig nu på webbskrapning. Marknaden passerade 1 miljard dollar 2024 och är på väg att fördubblas till 2030.
Den största drivkraften? AI-webbskrapare. De anpassar sig när layouten ändras. De förstår sidinnehåll, inte bara HTML-taggar. Och de fungerar för människor som aldrig har skrivit en rad kod.
Jag har ägnat månader åt att testa 15 av dem. Här är vad jag kom fram till — inklusive varför Thunderbit (ja, företaget jag var med och grundade) knep förstaplatsen.
Varför AI håller på att förändra skrapning av webbsidor: den nya eran för webbskrapverktyg
Skrapa data från vilken webbplats som helst med AI Get Started Free
Låt oss vara ärliga: traditionell webbskrapning var aldrig byggd för den genomsnittliga företagsanvändaren. Allt handlade om kod, selektorer och att hoppas att skriptet inte skulle gå sönder nästa gång en webbplats ändrade layout. Men AI och LLM:er har vänt upp och ner på allt.
Så här:
- Instruktioner på naturligt språk: I stället för att brottas med kod säger du bara vad du vill ha. Verktyg som Thunderbit tolkar dina instruktioner på vanlig engelska och sätter upp extraktionen åt dig (källa).
- Adaptivt lärande: AI-skrpare kan anpassa sig till layoutförändringar på webbplatser, vilket minskar underhållsproblemen.
- Hantering av dynamiskt innehåll: Moderna sajter älskar JavaScript och oändlig scrollning. AI-drivna verktyg interagerar med de här elementen och fångar upp data som äldre skrapare skulle missa.
- Strukturerad utdata med AI-parsning: LLM-baserade skrapare förstår faktiskt sidinnehåll och ger ren, strukturerad data som resultat.
- Automatisk kringgående av bot-skydd: AI-skrpare kan gå förbi anti-skrapningsåtgärder och använda proxies/headless browsers för att undvika IP-blockeringar.
- Integrerade dataflöden: De bästa verktygen hämtar inte bara data — de levererar den dit du behöver den, med export med ett klick till Google Sheets, Airtable, Notion med mera (källa).
Resultatet? Webbskrapning är nu en punkt-och-klick-upplevelse (eller till och med chattliknande), vilket öppnar dörren för sälj-, marknadsförings- och driftteam — inte bara utvecklare — att använda webdata direkt.
15 AI-webbskrapare värda din uppmärksamhet 2026
Låt oss gå igenom de 15 bästa AI-webbskraparna, med Thunderbit först. Jag berättar om varje verktygs kärnfunktioner, målgrupp, prissättning och vad som gör att det sticker ut. Och ja, jag kommer att vara ärlig om var varje verktyg glänser — och var det kanske inte gör det.
1. Thunderbit: AI-webbskraparen för alla
Jag är förstås lite partisk här, men Thunderbit är den AI-webbskrapare jag önskar att jag hade haft för flera år sedan. Här är varför den är nummer 1 på listan:
- Extraktion med naturligt språk: Du ”chattar” med Thunderbit. Beskriv bara vilken data du vill ha — ”skrapa alla produktnamn och priser från den här sidan” — så sköter AI resten (källa). Ingen kod, inga selektorer, inga bekymmer.
- Skrapning av undersidor och på flera nivåer: Thunderbit kan följa länkar och skrapa undersidor. Du kan till exempel skrapa en produktlista och sedan klicka in på varje produkt för detaljer, allt i ett svep.
- Omedelbart strukturerad utdata: AI:n formaterar och rensar data i farten, föreslår relevanta fält, normaliserar format och sammanfattar eller kategoriserar till och med text.
- Brett stöd för olika källor: Thunderbit är inte bara för HTML — det kan extrahera från PDF-filer och bilder med inbyggd OCR och visions-AI (källa).
- Affärsintegrationer: Exportera med ett klick till Google Sheets, Airtable, Notion eller Excel (källa). Schemalägg skrapningar och mata in data direkt i teamets arbetsflöde.
- Förbyggda mallar: För sajter som Amazon, LinkedIn, Zillow med flera erbjuder Thunderbit förgjorda ”recept” för skrapning för datautvinning med ett klick.
- Användarvänligt och lättillgängligt: Gränssnittet är punkt-och-klick, med en intuitiv assistent. Användare rapporterar att de kommer igång på några minuter.

Thunderbit används av över 30 000 användare världen över, inklusive team på Accenture, Grammarly och Puma. Säljteam använder det för att bygga leadlistor, mäklare samlar bostadsannonser och marknadsförare bevakar konkurrenter — allt utan att skriva en enda rad kod.
Prissättning: Det finns en gratis nivå (skrapa upp till 100 steg/månad), och betalda planer börjar på 14,99 dollar per månad. Även pro-planerna är prisvärda för privatpersoner och små team.
Thunderbit är det närmaste jag har sett att ”göra webben till en databas” — och det är byggt för alla, inte bara ingenjörer.
Prova Thunderbit Chrome-tillägg
2. Crawl4AI
Vem det är för: Utvecklare och tekniska team som bygger anpassade pipelines.
Crawl4AI är ett öppen källkod-baserat ramverk i Python, optimerat för hastighet och storskalig skrapning, med LLM-integration i åtanke. Det är blixtsnabbt, stöder headless browsers för dynamiskt innehåll och kan strukturera skrapad data så att den enkelt kan matas in i AI-flöden.
- Bäst för: Utvecklare som behöver en kraftfull och anpassningsbar crawler-motor.
- Prissättning: Gratis (MIT-licens). Du behöver hosta och köra det själv.
3. ScrapeGraphAI
Vem det är för: Utvecklare och analytiker som bygger AI-agenter eller komplexa dataflöden.
ScrapeGraphAI är ett promptdrivet bibliotek i öppen källkod för Python som omvandlar webbplatser till strukturerade datagrafen med hjälp av LLM:er. Du kan skriva prompts som ”Extrahera alla produktnamn, priser och betyg från de första 5 sidorna”, så bygger det ett arbetsflöde för skrapning åt dig (källa).
- Bäst för: Tekniskt kunniga användare som vill ha flexibel, promptbaserad skrapning.
- Prissättning: Gratis för biblioteket med öppen källkod; moln-API från 20 dollar per månad.
4. Firecrawl
Vem det är för: Utvecklare som bygger AI-agenter eller storskaliga dataflöden.
Firecrawl är en AI-fokuserad crawler-plattform och API som gör hela webbplatser till ”LLM-ready”-data (källa). Den ger ut Markdown eller JSON, hanterar dynamiskt innehåll och integreras med ramverk som LangChain och LlamaIndex.
- Bäst för: Utvecklare som behöver mata live webdata till AI-modeller.
- Prissättning: Öppen källkod-kärnan är gratis; molnplaner börjar på 19 dollar per månad.
5. Browse AI
Vem det är för: Företagsanvändare, growth hackers och analytiker.
Browse AI är en no-code-plattform med ett punkt-och-klick-gränssnitt. Du ”tränar” en robot genom att klicka på den data du vill ha, och AI:n generaliserar mönstret för framtida skrapningar. Den hanterar inloggningar, oändlig scrollning och kan övervaka webbplatser för förändringar.
- Bäst för: Icke-tekniska användare som vill automatisera datainsamling och övervakning.
- Prissättning: Gratis plan (50 krediter/månad); betalda planer börjar på 19 dollar per månad.
6. LLM Scraper
Vem det är för: Utvecklare som vill att AI ska göra parsningen.
LLM Scraper är ett öppen källkod-bibliotek i JavaScript/TypeScript som låter dig definiera ett dataschema och låta en LLM extrahera den datan från vilken webbsida som helst. Det bygger på Playwright, stöder flera LLM-leverantörer och kan till och med generera återanvändbar kod.
- Bäst för: Utvecklare som vill förvandla vilken webbsida som helst till strukturerad data med hjälp av LLM:er.
- Prissättning: Gratis (MIT-licens).
7. Reader (Jina Reader)
Vem det är för: Utvecklare som bygger LLM-applikationer, chatbots eller sammanfattare.
Jina Reader är ett API som extraherar ren text och strukturerad data från webbsidor (och till och med PDF-filer/bilder), och returnerar Markdown eller JSON som är redo för LLM:er. Det drivs av en anpassad AI-modell och kan till och med skriva bildtexter.
- Bäst för: Att hämta rent och läsbart innehåll till LLM:er eller fråge- och svarssystem.
- Prissättning: Gratis API (ingen nyckel behövs för grundläggande användning).
8. Bright Data
Vem det är för: Företag och professionella användare som behöver skala, regelefterlevnad och tillförlitlighet.
Bright Data är en tungviktare inom webdataindustrin, med ett massivt proxy-nätverk och AI-drivna skrapverktyg. De erbjuder färdiga skrapare, ett generellt Web Scraper API och dataflöden som är ”LLM-ready”.
- Bäst för: Organisationer som behöver pålitlig webdata i stor skala.
- Prissättning: Användningsbaserat, premium. Gratis provperiod finns.
9. Octoparse
Vem det är för: Icke-tekniska till semi-tekniska användare.
Octoparse är ett väletablerat no-code-verktyg med en visuell arbetsflödesdesigner och AI-driven autodetektering. Det hanterar inloggningar, oändlig scrollning och kan exportera data i olika format.
- Bäst för: Analytiker, småföretagare eller forskare.
- Prissättning: Gratis nivå finns; betalda planer börjar på 119 dollar per månad.
10. Apify
Vem det är för: Utvecklare och teknikteam som behöver anpassad skrapning/automation.
Apify är en molnplattform för att köra skrapskript (”actors”) och erbjuder en marknadsplats med färdigbyggda actors. Den är skalbar, integreras med AI och stöder proxyhantering.
- Bäst för: Utvecklare som vill köra egna skript i molnet.
- Prissättning: Gratis nivå; användningsbaserade betalda planer börjar på 49 dollar per månad.
11. Zyte (Scrapy Cloud)
Vem det är för: Utvecklare och företag som behöver skrapning i företagsklass.
Zyte är företaget bakom Scrapy och erbjuder en molnplattform samt AI-driven automatisk extraktion. Det hanterar schemaläggning, proxies och stora projekt.
- Bäst för: Dev-team som driver långsiktiga skrapningsprojekt.
- Prissättning: Gratis provperioder till anpassade företagsplaner.
12. Webscraper.io
Vem det är för: Nybörjare, journalister och forskare.
Webscraper.io är ett populärt Chrome-tillägg för datautvinning med punkt-och-klick. Det är enkelt, gratis för lokal användning och erbjuder en molntjänst för större jobb.
- Bäst för: Snabba, engångsbaserade skrapningsuppgifter.
- Prissättning: Gratis tillägg; molnplaner från cirka 50 dollar per månad.
13. ParseHub
Vem det är för: Icke-tekniska användare som behöver mer kraft än grundläggande verktyg.
ParseHub är en skrivbordsapp med ett visuellt arbetsflöde för att skrapa dynamiskt innehåll, inklusive kartor och formulär. Den kan köra projekt i molnet och erbjuder ett API.
- Bäst för: Digitala marknadsförare, analytiker och journalister.
- Prissättning: Gratis nivå (200 sidor/körning); betalda planer börjar på 189 dollar per månad.
14. Diffbot
Vem det är för: Företag och AI-bolag som behöver strukturerad webdata i stor skala.
Diffbot använder datorseende och NLP för att automatiskt extrahera data från vilken webbsida som helst och erbjuder API:er för artiklar, produkter och ett enormt kunskapsgrafnät.
- Bäst för: Marknadsinformation, finans och träningsdata för AI.
- Prissättning: Premium, från cirka 299 dollar per månad.
15. DataMiner
Vem det är för: Icke-tekniska användare, särskilt inom sälj, marknad och journalistik.
DataMiner är ett Chrome-tillägg för snabb webdatautvinning med punkt-och-klick. Det har ett bibliotek med förbyggda ”recept” och kan exportera direkt till Google Sheets.
- Bäst för: Snabba uppgifter som att exportera tabeller eller listor till kalkylblad.
- Prissättning: Gratis nivå (500 sidor/dag); Pro börjar på cirka 19 dollar per månad.
Jämförelse av de bästa AI-webbskraparna: vilken passar dina behov?
Här är en översiktlig jämförelse som hjälper dig att hitta rätt:
| Verktyg | Användning av AI/LLM | Användarvänlighet | Utdata/integration | Perfekt för | Prissättning |
|---|---|---|---|---|---|
| Thunderbit | Gränssnitt på naturligt språk; AI föreslår fält | Enklast (no-code-chatt) | Export till Sheets, Airtable, Notion | Icke-tekniska team | Gratis nivå; Pro från ca 30 dollar/månad |
| Crawl4AI | AI-redo skrapning; integrera LLM:er | Svårt (kod i Python) | Bibliotek/CLI; integrera via kod | Utvecklare som behöver snabba AI-dataflöden | Gratis |
| ScrapeGraphAI | LLM-promptpipelines för skrapning | Medel (viss kodning eller API) | API/SDK; JSON-utdata | Utvecklare/analytiker som bygger AI-agenter | Gratis OSS; API från 20 dollar/månad |
| Firecrawl | Skrapar till LLM-redo Markdown/JSON | Medel (API/SDK-användning) | SDK:er (Py, Node etc.); LangChain-integration | Utvecklare som matar live webdata till AI | Gratis + betalt moln |
| Browse AI | AI-assisterad punkt-och-klick | Enkelt (no-code) | Över 7000 appintegrationer (Zapier) | Icke-tekniska användare som automatiserar webbövervakning | Gratis 50 körningar; Betalt från 19 dollar/månad |
| LLM Scraper | Använder LLM:er för att parsa sida till schema | Svårt (kod i TS/JS) | Kodbibliotek; JSON-utdata | Utvecklare som vill att AI ska göra parsningen | Gratis (använd egen LLM-API) |
| Reader (Jina) | AI-modell extraherar text/JSON | Enkelt (enkelt API-anrop) | REST API returnerar Markdown/JSON | Utvecklare som lägger till webbsökning/innehåll till LLM:er | Gratis API |
| Bright Data | AI-förbättrade skrap-API:er; stort proxy-nätverk | Svårt (API, tekniskt) | API:er/SDK:er; dataströmmar eller datamängder | Företagsskala | Användningsbaserat |
| Octoparse | AI autodetektion av listor | Medel (no-code-app) | CSV/Excel, API för resultat | Semi-tekniska användare | Gratis begränsat; 59–166 dollar/månad |
| Apify | Vissa AI-funktioner (Actors, AI-guider) | Svårt (kodskript) | Omfattande API; integreras med LangChain | Utvecklare som behöver anpassad skrapning i molnet | Gratis nivå; pay-as-you-go |
| Zyte (Scrapy) | ML-baserad autoextraktion; Scrapy-ramverk | Svårt (kod i Python) | API, Scrapy Cloud-gränssnitt; JSON/CSV | Dev-team, långsiktiga projekt | Anpassad prissättning |
| Webscraper.io | Ingen AI (manuella mallar) | Enkelt (webbläsartillägg) | CSV-nedladdning, Cloud API | Nybörjare, snabba engångsskrapningar | Gratis tillägg; Cloud cirka 50 dollar/månad |
| ParseHub | Ingen uttrycklig LLM; visuell byggare | Medel (no-code-app) | JSON/CSV; API för körningar i molnet | Icke-utvecklare som skrapar komplexa sajter | Gratis 200 sidor; Betalt från 189 dollar/månad |
| Diffbot | AI-vision/NLP för alla sidor; kunskapsgraf | Enkelt (bara API-anrop) | API:er (Article/Prod/...) + frågor till Knowledge Graph | Företag, strukturerad webdata | Från cirka 299 dollar/månad |
| DataMiner | Ingen LLM; community-recept | Enklast (webbläsargränssnitt) | Export till Excel/CSV; Google Sheets | Icke-tekniska användare som skrapar till kalkylblad | Gratis begränsat; Pro cirka 19 dollar/månad |
Verktygskategorier: från utvecklarnas kraftpaket till affärsvänliga webskrapare
För att göra den här listan mer överskådlig kan vi dela in verktygen i några kategorier:
1. Kraftpaket för utvecklare och öppen källkod
- Exempel: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Styrkor: Hög flexibilitet, skala och anpassningsmöjligheter. Bra för att bygga egna pipelines eller integrera med AI-modeller.
- Avvägningar: Kräver kodkunskaper och mer konfiguration.
- Användningsfall: Bygga ett eget dataflöde, skrapa komplexa sajter eller integrera med interna system.
2. AI-integrerade skrapagenter
- Exempel: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Styrkor: Minskar glappet mellan skrapning och förståelse av data. Gränssnitt på naturligt språk gör dem tillgängliga.
- Avvägningar: Vissa är fortfarande under utveckling; kanske inte erbjuder detaljstyrning.
- Användningsfall: Snabba svar eller dataset, bygga autonoma agenter eller mata live data till LLM:er.
3. No-code/low-code-webbskrapare för företag
- Exempel: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Styrkor: Användarvänliga, kräver lite eller ingen kod, bra för återkommande affärsuppgifter.
- Avvägningar: Kan få problem med mycket komplexa sajter eller riktigt stor skala.
- Användningsfall: Leadgenerering, konkurrentbevakning, forskningsprojekt och engångsuttag av data.
4. Dataplattformar och tjänster för företag
- Exempel: Bright Data, Diffbot, Zyte
- Styrkor: Kompletta lösningar, hanterade tjänster, regelefterlevnad och tillförlitlighet i stor skala.
- Avvägningar: Högre kostnad, mer onboarding krävs.
- Användningsfall: Storskaliga, alltid aktiva dataflöden, marknadsinformation och träningsdata för AI.
Så väljer du rätt AI-webbskrapare för dina behov av skrapning av webbsidor
Vad är dataskrapning och hur gör man det Get Started Free
Att välja rätt verktyg kan kännas överväldigande, så här är min steg-för-steg-guide:
- Definiera dina mål och datakrav tydligt: Vilka sajter och vilken data behöver du? Hur ofta? Hur mycket? Vad ska du använda den till?
- Bedöm din tekniska nivå: Ingen kod? Prova Thunderbit, Browse AI eller Octoparse. Lite skriptande? LLM Scraper eller DataMiner. Starka utvecklarkunskaper? Crawl4AI, Apify eller Zyte.
- Tänk på frekvens och skala: Engångsjobb? Använd gratisverktyg. Återkommande? Leta efter schemaläggningsfunktioner. Storskaligt? Företagsverktyg eller öppen källkod i stor skala.
- Budget och prismodell: Gratisplaner är utmärkta för testning. Prenumeration eller användningsbaserad prissättning beror på dina behov.
- Test och proof of concept: Testa några verktyg på din riktiga data. De flesta har gratis nivåer.
- Underhåll och support: Vem fixar saker om sajten ändras? No-code-verktyg med AI kan automatiskt rätta mindre förändringar; öppen källkod bygger på dig eller communityn.
- Matcha verktyg med scenarier: Säljteam som skrapar leads? Thunderbit eller Browse AI. Forskare som samlar tweets? DataMiner eller Webscraper.io. AI-modell som behöver nyhetsartiklar? Jina Reader eller Zyte. Bygger du en jämförelsesajt? Apify eller Zyte.
- Planera för en backup: Ibland fungerar inte ett verktyg för en viss sajt. Ha en reservplan.
Det ”rätta” verktyget är det som ger dig den data du behöver med minst friktion och inom din budget. Ibland är det en kombination.
Thunderbit vs. traditionella webbskrapverktyg: vad gör det unikt?
Låt oss vara specifika kring varför Thunderbit är annorlunda:
- Gränssnitt på naturligt språk: Ingen kod, inga punkt-och-klick-krumbukter. Beskriv bara vad du vill ha (källa).
- Ingen konfiguration och mallförslag: Thunderbit upptäcker automatiskt paginering, undersidor och föreslår till och med mallar för vanliga sajter (källa).
- AI-driven datarensning och berikning: Sammanfatta, kategorisera, översätt och berika data medan du skrapar (källa).
- Färre underhållsproblem: Thunderbits AI är motståndskraftig mot mindre ändringar på sajter, vilket minskar risken för att något går sönder.
- Integration med affärsverktyg: Direkt export till Google Sheets, Airtable, Notion — inga fler CSV-strul (källa).
- Snabb väg till nytta: Gå från idé till data på minuter, inte dagar.
- Inlärningskurva: Om du kan surfa på webben och beskriva vad du behöver kan du använda Thunderbit.
- Anpassningsförmåga: Skrapa webbplatser, PDF-filer, bilder och mer — allt med samma verktyg.
Thunderbit är inte bara en skrapare — det är en dataassistent som passar in i ditt arbetsflöde, oavsett om du arbetar med sälj, marknad, e-handel eller fastigheter.
Prova Thunderbit AI-webbskrapare
Bästa praxis för skrapning av webbsidor med AI-webbskraparverktyg
För att få ut så mycket som möjligt av AI-webbskrapare är här mina bästa tips:
- Definiera tydligt dina databehov: Vet vilka fält du vill ha, hur många sidor och vilket format du behöver.
- Utnyttja AI-förslag: Använd verktygens fältdetektering och AI-förslag för att fånga viktig data du annars skulle missa (källa).
- Börja smått och validera: Testa på ett litet urval, kontrollera resultatet och justera vid behov.
- Hantera dynamiskt innehåll: Se till att ditt verktyg stöder dynamiskt innehåll och interaktioner (paginering, oändlig scrollning osv.).
- Respektera webbplatsers policyer: Kontrollera robots.txt, undvik att skrapa känslig data och respektera hastighetsbegränsningar.
- Integrera för automation: Använd exportfunktioner och webhooks för att koppla den skrapade datan direkt till ditt arbetsflöde.
- Säkerställ datakvaliteten: Gör rimlighetskontroller, använd efterbearbetning och bevaka fel.
- Var kortfattad med prompts: När du använder AI-drivna verktyg ger tydliga och specifika instruktioner bättre resultat.
- Lär av communityn: Gå med i forum och communities för tips och felsökning.
- Håll dig uppdaterad: AI-verktyg utvecklas snabbt — håll koll på nya funktioner och förbättringar.
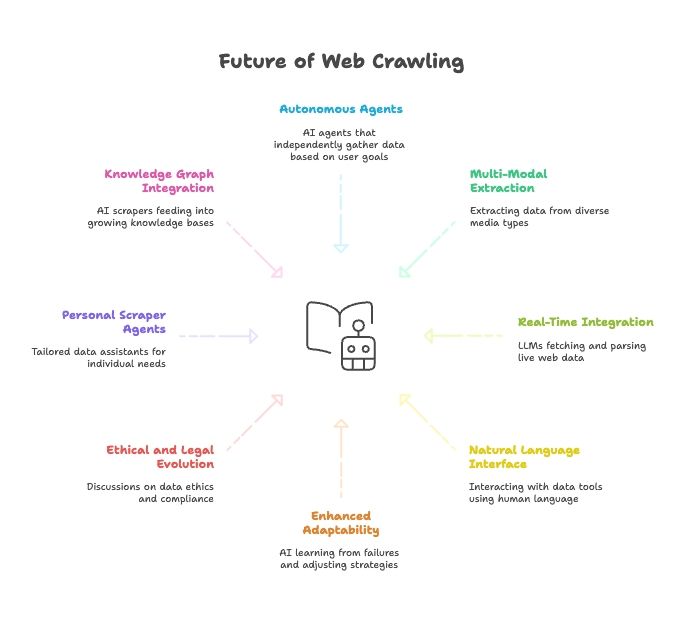
Framtiden för webbskrapning: AI, LLM:er och framväxten av agenter för webskrapning på naturligt språk
Om vi blickar framåt går utvecklingen där AI och webbskrapning möts bara snabbare och snabbare:
- Helt autonoma skrapagenter: Snart säger du bara till en AI-agent vad slutmålet är, så räknar den ut hur datan ska hämtas.
- Multimodal dataextraktion: Skrapare kommer att hämta data från text, bilder, PDF-filer och till och med videor.
- Realtidsintegration med AI-modeller: LLM:er kommer att ha inbyggda moduler för att hämta och parsa live webdata.
- Allt på naturligt språk: Vi kommer att prata med våra dataverktyg som vi pratar med människor, vilket gör datainsamling och transformation tillgängligt för alla.
- Förbättrad anpassningsförmåga: AI-skrapare kommer att lära sig av misslyckanden och automatiskt anpassa strategier.
- Etisk och juridisk utveckling: Räkna med mer diskussion om dataetik, regelefterlevnad och skälig användning.
- Personliga skrapagenter: Föreställ dig en personlig dataassistent som samlar in nyheter, jobbannonser och mer, skräddarsytt efter dina behov.
- Integration med kunskapsgrafer: AI-skrapare kommer kontinuerligt att mata växande kunskapsbaser och driva smartare AI.
Kort sagt? Framtiden för webbskrapning är sammanflätad med framtiden för AI. Verktygen blir smartare, mer autonoma och mer tillgängliga för varje dag som går.
Slutsats: lås upp affärsvärde med rätt AI-webbskrapare
Webbskrapning har gått från en nischad, teknisk färdighet till en central affärsförmåga — tack vare AI. De 15 verktyg jag har gått igenom här representerar det bästa som är möjligt 2026, från utvecklarnas kraftpaket till affärsvänliga assistenter.
Den verkliga hemligheten? Att välja rätt verktyg kan dramatiskt öka värdet du får ut av webdata. För icke-tekniska team är Thunderbit det enklaste sättet att förvandla webben till en strukturerad, analysredo databas — ingen kod, inget krångel, bara resultat.
Så oavsett om du samlar leads, bevakar konkurrenter eller matar din nästa generations AI-modell, ta dig tid att utvärdera dina behov, testa några verktyg och se vad som fungerar för dig. Och om du vill uppleva framtidens webbskrapning redan idag, prova Thunderbit. De insikter du behöver är bara en prompt bort.
Nyfiken på mer? Kolla in Thunderbit Blog för fördjupningar, guider och det senaste inom AI-driven dataextraktion.
Vidare läsning:
- Vad är dataskrapning och hur gör man det 2026
- Så skrapar du webbplatsdata till Excel med AI
- De bästa webbskrapverktygen och programvarorna 2026
Prova AI-webbskrapare Get Started Free
Vanliga frågor
1. Vad är en AI-webbskrapare och hur skiljer den sig från traditionella webbskrapare?
En AI-webbskrapare använder naturlig språkbehandling och maskininlärning för att förstå, extrahera och strukturera webdata. Till skillnad från traditionella skrapare som kräver manuell kodning och XPath-selektorer kan AI-verktyg hantera dynamiskt innehåll, anpassa sig till layoutförändringar och tolka användarinstruktioner på vanlig engelska.
2. Vem bör använda AI-verktyg för webbskrapning som Thunderbit?
Thunderbit är byggt för både icke-tekniska och tekniska användare. Det är idealiskt för sälj-, marknadsförings-, drift-, forsknings- och e-handelsproffs som vill extrahera strukturerad data från webbplatser, PDF-filer eller bilder — utan att skriva kod.
3. Vilka funktioner gör Thunderbit utmärkande jämfört med andra AI-webbskrapare?
Thunderbit erbjuder ett gränssnitt på naturligt språk, skrapning på flera nivåer, automatisk datastrukturering, OCR-stöd och smidiga exporter till plattformar som Google Sheets och Airtable. Det innehåller också AI-drivna fältförslag och förbyggda mallar för populära sajter.
4. Finns det gratisalternativ för AI-webbskrapning 2026?
Ja. Många verktyg som Thunderbit, Browse AI och DataMiner erbjuder gratisplaner med begränsad användning. För utvecklare ger öppen källkod-alternativ som Crawl4AI och ScrapeGraphAI full funktionalitet utan kostnad, även om de kräver teknisk installation.
5. Hur väljer jag rätt AI-webbskrapare för mina behov?
Börja med att identifiera dina datamål, din tekniska nivå, budget och skalkrav. Om du vill ha en enkel no-code-lösning är Thunderbit eller Browse AI bra val. För storskaliga eller anpassade behov passar verktyg som Apify eller Bright Data bättre.




