Låt oss vara ärliga — Amazon är i praktiken hela internets varuhus, matbutik och elektronikaffär i ett. Om du jobbar med sälj, e-handel eller drift vet du redan att det som händer på Amazon inte stannar på Amazon — det påverkar prissättning, lagernivåer och till och med nästa stora produktlansering. Men här är problemet: alla de där lockande produktdetaljerna, priserna, betygen och recensionerna är inlåsta bakom ett webbgränssnitt som är byggt för shoppare, inte för datatörstiga team. Så hur får du ut den datan utan att spendera helgerna på att kopiera och klistra som om det vore 1999?
Det är här web scraping kommer in. I den här guiden visar jag två sätt att extrahera produktdata från Amazon: det klassiska upplägget där du kavlar upp ärmarna och kodar det i Python, och det moderna alternativet där du låter AI göra det tunga jobbet med en no code-webbskrapare som . Jag går igenom riktig Python-kod, med alla fallgropar och workaroundar, och sedan visar jag hur Thunderbit kan ge dig samma data på bara ett par klick — helt utan kodning. Oavsett om du är utvecklare, affärsanalytiker eller bara trött på manuell datainmatning, så har jag dig täckt.
Varför extrahera produktdata från Amazon? (amazon scraper python, web scraping with python)
Amazon är inte bara världens största nätbutik — det är också världens största öppna marknad för konkurrensanalys. Med och är Amazon en guldgruva för alla som vill:

- Övervaka priser (och justera dina i realtid)
- Analysera konkurrenter (följa deras nya lanseringar, betyg och recensioner)
- Generera leads (hitta säljare, leverantörer eller till och med potentiella partners)
- Prognostisera efterfrågan (genom att bevaka lagernivåer och försäljningsrankningar)
- Upptäcka marknadstrender (genom att gräva i recensioner och sökresultat)
Och det är inte bara teori — riktiga företag ser faktisk avkastning. Till exempel använde en elektronikåterförsäljare skrapad prisdata från Amazon för att , medan ett annat varumärke såg efter att ha automatiserat konkurrenternas prisbevakning.
Här är en snabb tabell över användningsområden och vilken typ av avkastning du kan förvänta dig:
| Användningsområde | Vem använder det | Typisk avkastning / nytta |
|---|---|---|
| Prisbevakning | E-handel, drift | 15%+ högre vinstmarginal, 4% högre försäljning, 30% mindre analytiker-tid |
| Konkurrentanalys | Sälj, produkt, drift | Snabbare prisjusteringar, bättre konkurrenskraft |
| Marknadsundersökning (recensioner) | Produkt, marknadsföring | Snabbare produktutveckling, bättre annonstexter, SEO-insikter |
| Leadgenerering | Sälj | 3 000+ leads/månad, 8+ sparade timmar per säljare och vecka |
| Lager- och efterfrågeprognoser | Drift, supply chain | 20% minskning av överlager, färre slutsålda produkter |
| Trendspaning | Marknadsföring, ledning | Tidig upptäckt av heta produkter och kategorier |
Och här är det viktiga: rapporterar nu mätbart värde från dataanalys. Om du inte skrapar Amazon lämnar du insikter — och pengar — på bordet.
Översikt: Amazon Scraper Python jämfört med no code-webbskrapare
Det finns två huvudsakliga sätt att få ut Amazon-data ur webbläsaren och in i dina kalkylblad eller dashboards:
-
Amazon Scraper Python (web scraping with python):
Skriv ditt eget skript med Python-bibliotek som Requests och BeautifulSoup. Det ger dig full kontroll, men du behöver kunna koda, hantera anti-bot-skydd och underhålla skriptet när Amazon ändrar sin sajt.
-
No code-webbskrapare (som Thunderbit):
Använd ett verktyg där du pekar, klickar och extraherar data — utan programmering. Moderna verktyg som använder till och med AI för att räkna ut vilken data som ska hämtas, hantera undersidor och paginering, och exportera direkt till Excel eller Google Sheets.
Så här står de sig mot varandra:
| Kriterium | Python-skrapare | No code (Thunderbit) |
|---|---|---|
| Installationstid | Hög (installera, koda, felsöka) | Låg (installera tillägg) |
| Krävd kompetens | Kodning krävs | Ingen (peka och klicka) |
| Flexibilitet | Obegränsad | Hög för vanliga användningsfall |
| Underhåll | Du fixar koden | Verktyget uppdaterar sig självt |
| Hantering av anti-bot | Du hanterar proxies och headers | Inbyggt, hanteras åt dig |
| Skalbarhet | Manuell (trådar, proxies) | Molnskrapning, parallelliserad |
| Dataexport | Anpassad (CSV, Excel, databas) | Ett klick till Excel, Sheets |
| Kostnad | Gratis (din tid + proxies) | Freemium, betala för skala |
I nästa avsnitt går jag igenom båda metoderna — först hur du bygger en Amazon-skrapare i Python, med riktig kod, och sedan hur du gör samma sak med Thunderbits AI-webbskrapare.
Kom igång med Amazon Scraper Python: förutsättningar och installation
Innan vi dyker ner i koden, se till att din miljö är redo.
Du behöver:
- Python 3.x (ladda ner från )
- En kodredigerare (jag gillar VS Code, men vad som helst fungerar)
- Följande bibliotek:
requests(för HTTP-förfrågningar)beautifulsoup4(för HTML-parsing)lxml(snabb HTML-parser)pandas(för datatabeller/export)re(reguljära uttryck, inbyggt)
Installera biblioteken:
1pip install requests beautifulsoup4 lxml pandasProjektupplägg:
- Skapa en ny mapp för ditt projekt.
- Öppna redigeraren, skapa en ny Python-fil (t.ex.
amazon_scraper.py). - Du är redo att köra!
Steg för steg: web scraping med Python för Amazon produktdata
Låt oss gå igenom hur man skrapar en enskild Amazon-produktsida. (Oroa dig inte, vi kommer snart till hur du skrapar flera produkter och sidor.)
1. Skicka förfrågningar och hämta HTML
Först hämtar vi HTML för en produktsida. (Byt ut URL:en mot valfri Amazon-produkt.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Obs! Den här enkla förfrågan kommer sannolikt att blockeras av Amazon. Du kan få ett 503-fel eller en CAPTCHA i stället för produktsidan. Varför? För att Amazon vet att du inte är en riktig webbläsare.
Hantera Amazons anti-bot-skydd
Amazon gillar inte bottar. För att undvika att blockeras behöver du:
- Sätta ett User-Agent-headervärde (låtsas vara Chrome eller Firefox)
- Roterande User-Agents (använd inte samma varje gång)
- Begränsa takten på dina förfrågningar (lägg in slumpmässiga pauser)
- Använda proxies (för storskalig skrapning)
Så här sätter du headers:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Vill du göra det lite mer avancerat? Använd en lista med User-Agents och rotera dem för varje förfrågan. För större jobb vill du använda en proxy-tjänst (det finns gott om dem), men för skrapning i mindre skala räcker headers och fördröjningar oftast.
Extrahera viktiga produktfält
När du har HTML-koden är det dags att parsa den med BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Nu hämtar vi det viktiga:
Produkttitel
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NonePris
Amazons pris kan ligga på några olika ställen. Testa dessa:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textBetyg och antal recensioner
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # t.ex. "1,554 ratings"Huvudbildens URL
Amazon gömmer ibland högupplösta bilder i JSON inne i HTML-koden. Här är ett snabbt regex-trick:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneEller hämta bildtaggen för huvudbilden:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneProduktdetaljer
Specifikationer som varumärke, vikt och mått finns ofta i en tabell:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueEller, om Amazon använder formatet ”detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Skriv ut resultaten:
1print("Titel:", product_title)
2print("Pris:", price)
3print("Betyg:", rating, "baserat på", reviews_count, "recensioner")
4print("URL till huvudbild:", main_image_url)
5print("Detaljer:", details)Skrapa flera produkter och hantera paginering
En produkt är bra, men du vill sannolikt ha en hel lista. Så här skrapar du sökresultat och flera sidor.
Hämta produktlänkar från en söksida
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Hantera paginering
Amazons sök-URL:er använder &page=2, &page=3 osv.
1for page in range(1, 6): # skrapa de första 5 sidorna
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page=\{page\}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... extrahera produktlänkar som ovan ...Loop genom produktsidor och exportera till CSV
Samla produktdata i en lista av dictionaries och använd sedan pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # lista med dicts
3df.to_csv("amazon_products.csv", index=False)Eller till Excel:
1df.to_excel("amazon_products.xlsx", index=False)Bästa praxis för Amazon Scraper Python-projekt
Låt oss vara ärliga — Amazon ändrar hela tiden sin sajt och bekämpar skrapare. Så här håller du projektet igång:
- Rotera headers och User-Agents (använd ett bibliotek som
fake-useragent) - Använd proxies för skrapning i stor skala
- Begränsa förfrågningstakten (slumpmässiga
time.sleep()-pauser mellan förfrågningar) - Hantera fel på ett snyggt sätt (försök igen vid 503, backa om du blockeras)
- Skriv flexibel parslogik (leta efter flera selektorer per fält)
- Övervaka HTML-förändringar (om skriptet plötsligt returnerar
Noneför allt, kontrollera sidan) - Respektera robots.txt (Amazon förbjuder skrapning i många sektioner — skrapa ansvarsfullt)
- Rensa datan medan du arbetar (ta bort valutasymboler, kommatecken och blanksteg)
- Håll kontakten med communityn (forum, Stack Overflow, Reddits r/webscraping)
Checklista för att underhålla din skrapare:
- [ ] Rotera User-Agents och headers
- [ ] Använd proxies om du skrapar i stor skala
- [ ] Lägg till slumpmässiga fördröjningar
- [ ] Dela upp koden i moduler för enkla uppdateringar
- [ ] Övervaka blockeringar eller CAPTCHAs
- [ ] Exportera data regelbundet
- [ ] Dokumentera dina selektorer och din logik
För en djupare genomgång, kolla in min .
Det no code-alternativet: skrapa Amazon med Thunderbit AI Web Scraper
Okej, så du har sett Python-vägen. Men tänk om du inte vill koda — eller om du bara vill få ut datan på två klick och gå vidare med livet? Då kommer in i bilden.
Thunderbit är ett Chrome-tillägg för AI-webbskrapning som låter dig extrahera produktdata från Amazon (och data från i princip vilken webbplats som helst) utan någon kod alls. Här är varför jag gillar det:
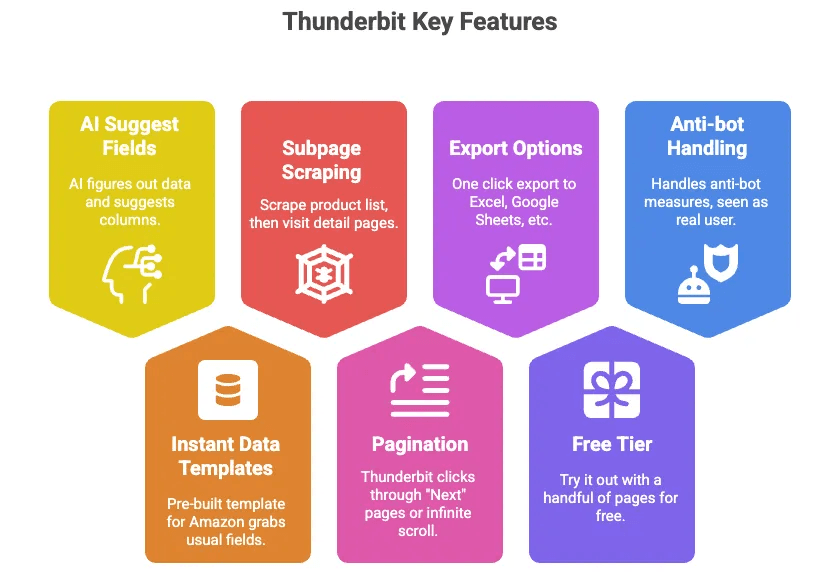
- AI föreslår fält: Klicka bara på en knapp, så räknar Thunderbits AI ut vilken data som finns på sidan och föreslår kolumner (som Titel, Pris, Betyg osv.).
- Direkta datamallar: För Amazon finns en färdig mall som hämtar alla vanliga fält — ingen installation behövs.
- Skrapning av undersidor: Skrapa en produktlista och låt sedan Thunderbit besöka varje produkts detaljsida och hämta mer information automatiskt.
- Paginering: Thunderbit kan klicka sig igenom ”Nästa”-sidor eller oändlig scroll åt dig.
- Export till Excel, Google Sheets, Airtable, Notion: Ett klick, och datan är redo att användas.
- Gratisnivå: Testa med ett antal sidor gratis.
- Hanterar anti-bot åt dig: Eftersom det körs i din webbläsare (eller i molnet) ser Amazon det som en riktig användare.
Steg för steg: använda Thunderbit för att skrapa produktdata från Amazon
Så här enkelt är det:
-
Installera Thunderbit:
Ladda ner och logga in.
-
Öppna Amazon:
Gå till den Amazon-sida du vill skrapa (sökresultat, produktsida, vad som helst).
-
Klicka på ”AI Suggest Fields” eller använd en mall:
Thunderbit föreslår kolumner att extrahera (eller så kan du välja Amazon Product-mallen).
-
Granska kolumnerna:
Justera kolumnerna om du vill (lägg till/ta bort fält, byt namn osv.).
-
Klicka på ”Scrape”:
Thunderbit hämtar datan från sidan och visar den i en tabell.
-
Hantera undersidor och paginering:
Om du skrapade en lista, klicka på ”Scrape Subpages” för att besöka varje produkts detaljsida och hämta mer information. Thunderbit kan också klicka sig igenom ”Next”-sidor automatiskt.
-
Exportera din data:
Klicka på ”Export to Excel” eller ”Export to Google Sheets”. Klart.
-
(Valfritt) Schemalägg skrapning:
Behöver du den här datan varje dag? Använd Thunderbits schemaläggare för att automatisera det.
Det är allt. Ingen kod, ingen felsökning, inga proxies, inga huvudbry. För en visuell genomgång, kolla in eller sidan för .
Amazon Scraper Python jämfört med no code-webbskrapare: sida vid sida
Låt oss sammanställa allt:
| Kriterium | Python-skrapare | Thunderbit (no code) |
|---|---|---|
| Installationstid | Hög (installera, koda, felsöka) | Låg (installera tillägg) |
| Krävd kompetens | Kodning krävs | Ingen (peka och klicka) |
| Flexibilitet | Obegränsad | Hög för vanliga användningsfall |
| Underhåll | Du fixar koden | Verktyget uppdaterar sig självt |
| Hantering av anti-bot | Du hanterar proxies och headers | Inbyggt, hanteras åt dig |
| Skalbarhet | Manuell (trådar, proxies) | Molnskrapning, parallelliserad |
| Dataexport | Anpassad (CSV, Excel, databas) | Ett klick till Excel, Sheets |
| Kostnad | Gratis (din tid + proxies) | Freemium, betala för skala |
| Bäst för | Utvecklare, specialanpassade behov | Affärsanvändare, snabba resultat |
Om du är en utvecklare som gillar att mecka och behöver något riktigt skräddarsytt är Python din vän. Om du vill ha hastighet, enkelhet och ingen kod är Thunderbit vägen att gå.
När ska du välja Python, no code eller AI-webbskrapare för Amazon-data?
Välj Python om:
- Du behöver speciallogik eller vill integrera skrapning i dina backend-system
- Du skrapar i mycket stor skala (tiotusentals produkter)
- Du vill lära dig hur skrapning fungerar under huven
Välj Thunderbit (no code, AI-webbskrapare) om:
- Du vill ha data snabbt, utan kodning
- Du är affärsanvändare, analytiker eller marknadsförare
- Du behöver göra det möjligt för teamet att hämta data själva
- Du vill slippa krånglet med proxies, anti-bot-skydd och underhåll
Använd båda om:
- Du vill prototypa snabbt med Thunderbit och sedan bygga en anpassad Python-lösning för produktion
- Du vill använda Thunderbit för datainsamling och Python för datarensning/analys
För de flesta affärsanvändare täcker Thunderbit 90% av behoven för Amazon-skrapning på en bråkdel av tiden. För de andra 10% — det superanpassade, storskaliga eller djupt integrerade — är Python fortfarande kung.
Slutsats och viktiga lärdomar
Att skrapa produktdata från Amazon är en superkraft för alla sälj-, e-handels- eller driftteam. Oavsett om du bevakar priser, analyserar konkurrenter eller bara försöker bespara teamet från ändlöst copy-paste finns det en lösning för dig.
- Python-skrapning ger dig full kontroll, men kommer med en inlärningskurva och löpande underhåll.
- No code-webbskrapare som Thunderbit gör extrahering av Amazon-data tillgänglig för alla — ingen kod, inget huvudbry, bara resultat.
- Den bästa metoden? Använd det verktyg som passar dina färdigheter, din tidsplan och dina affärsmål.
Om du är nyfiken, testa Thunderbit — det är gratis att börja med, och du kommer att bli förvånad över hur snabbt du kan få fram den data du behöver. Och om du är utvecklare, var inte rädd för att kombinera verktyg: ibland är det snabbaste sättet att bygga att låta AI göra de tråkiga delarna åt dig.
Vanliga frågor
1. Varför skulle ett företag vilja skrapa produktdata från Amazon?
Genom att skrapa Amazon kan företag övervaka priser, analysera konkurrenter, samla in recensioner för produktresearch, prognostisera efterfrågan och generera säljleads. Med över 600 miljoner produkter och nästan 2 miljoner säljare på Amazon är det en rik källa till konkurrensinformation.
2. Vilka är de största skillnaderna mellan att använda Python och no code-verktyg som Thunderbit för att skrapa Amazon?
Python-skrapare ger maximal flexibilitet men kräver kodningskunskap, installationstid och löpande underhåll. Thunderbit, en no code-AI-webbskrapare, låter användare extrahera Amazon-data direkt via ett Chrome-tillägg — ingen kod krävs, med inbyggd hantering av anti-bot och export till Excel eller Sheets.
3. Är det lagligt att skrapa data från Amazon?
Amazons användarvillkor förbjuder i allmänhet skrapning, och de har aktiva anti-bot-skydd. Många företag skrapar ändå offentligt tillgänglig data, så länge de agerar ansvarsfullt, till exempel genom att respektera hastighetsgränser och undvika för många förfrågningar.
4. Vilken typ av data kan jag extrahera från Amazon med web scraping-verktyg?
Vanliga fält är produkttitlar, priser, betyg, antal recensioner, bilder, produktspecifikationer, tillgänglighet och till och med säljarinformation. Thunderbit stöder också skrapning av undersidor och paginering för att samla in data från flera listningar och sidor.
5. När ska jag välja Python-skrapning framför ett verktyg som Thunderbit, eller tvärtom?
Använd Python om du behöver full kontroll, speciallogik eller planerar att integrera skrapning i backend-system. Använd Thunderbit om du vill ha snabba resultat utan kodning, behöver skala enkelt eller är en affärsanvändare som söker en lösning med lågt underhåll.
Vill du gå djupare? Kolla in de här resurserna:
Glad skrapning — och må dina kalkylblad alltid vara uppdaterade.