Scraper per Substack

Scelto da professionisti di aziende leader














Sblocca i dati di Substack con Thunderbit
Invia i dati di Substack direttamente alle tue app
Basta copiare e incollare manualmente dettagli delle pubblicazioni Substack come nome dell'autore, titolo dell'articolo e numero di iscritti. Con Thunderbit, un solo clic invia i dati estratti direttamente su Google Sheets, Notion o Airtable. Analizza le tendenze delle pubblicazioni e le performance dei contenuti senza il noioso lavoro manuale.
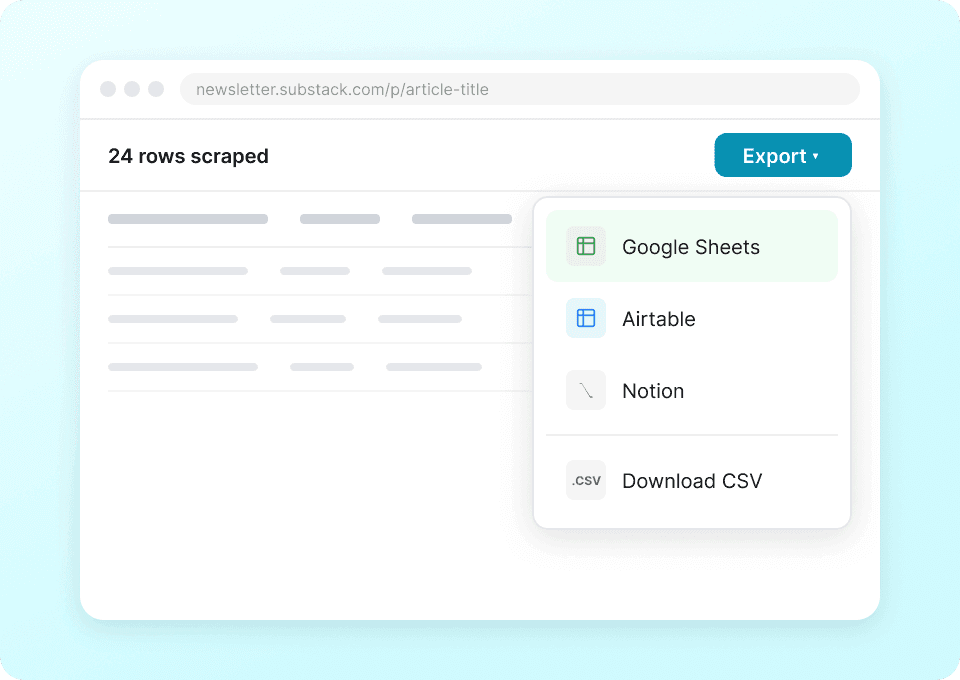
Un solo scraper per Substack e oltre
Non restare bloccato con uno scraper diverso per ogni sito web. Thunderbit funziona subito su Substack e include oltre 50 modelli preconfigurati per altre piattaforme popolari. Estrai descrizioni delle pubblicazioni, contenuti degli articoli e altro ancora, poi usa lo stesso strumento per raccogliere dati ovunque tu voglia.
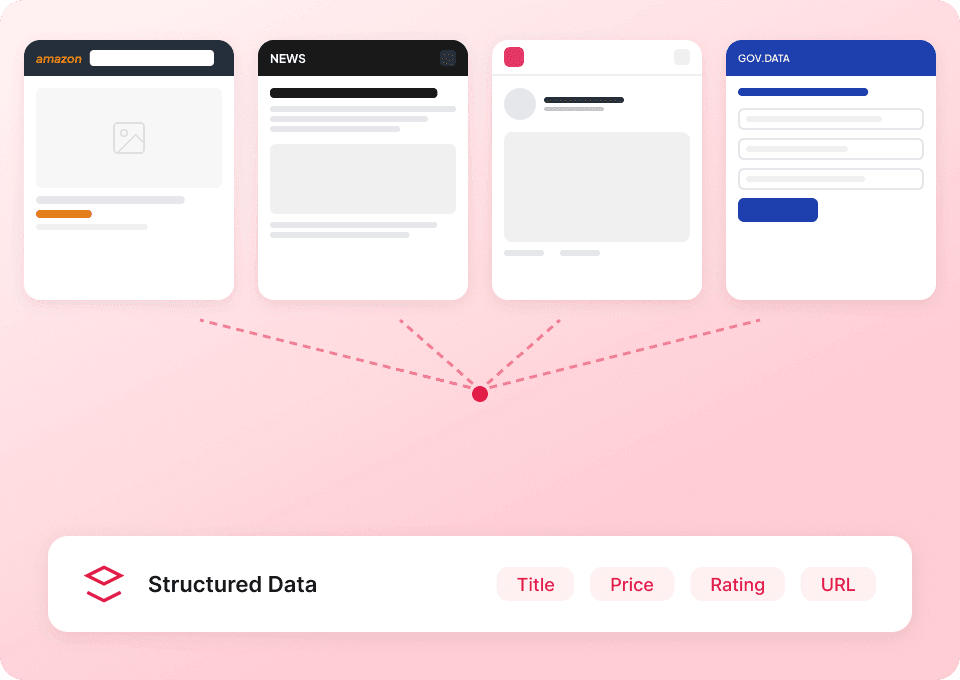
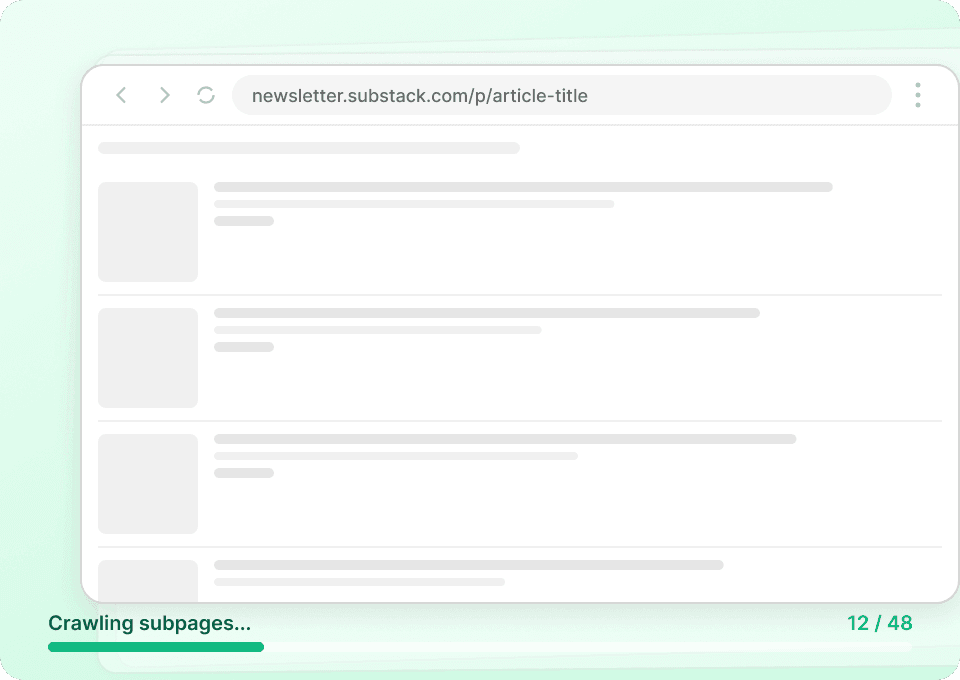
Ottieni la storia completa di Substack
Le pagine elenco delle pubblicazioni su Substack mostrano solo dei riepiloghi. Thunderbit visita automaticamente la sottopagina di ogni articolo per estrarre il contenuto completo, offrendoti un dataset completo. Ottieni in un solo passaggio il titolo completo dell'articolo, il nome dell'autore, il nome della pubblicazione e il contenuto dell'articolo.
Hai difficoltà a estrarre dati da Substack in modo efficace?
Scopri perché Thunderbit supera gli scraper tradizionali per i dati di Substack.
Scraper tradizionali
Il vecchio modo di fare le coseThunderbit
L'approccio più intelligenteNon fidarti solo della nostra parola
Scopri cosa dicono i nostri utenti di Thunderbit.








Domande frequenti
Correlati casi d'uso
Esplora altri casi d'uso del web scraper di Thunderbit.

Estrattore Tieba
L'Estrattore Tieba di Thunderbit ti permette di raccogliere dati da Baidu Tieba, inclusi argomenti popolari e categorie del forum. Grazie ai suggerimenti intelligenti basati su AI, puoi velocemente ottenere nomi degli argomenti, URL, conteggi dei post e attività degli utenti per ricerche, marketing o creazione di contenuti. Perfetto per analizzare tendenze e discussioni sui social media all'interno di Tieba.
Scopri di più ->
Estrattore United Airlines
Clicca e seleziona per raccogliere dati dei voli United Airlines, come numero del volo, orario di arrivo e aeroporto di partenza: al resto ci pensa Thunderbit AI.
Scopri di più ->
Estrattore White Pages
L'Estrattore White Pages di Thunderbit ti permette di raccogliere dati dagli elenchi telefonici e aziendali di White Pages grazie ai suggerimenti intelligenti basati su AI. In pochi clic puoi ottenere nomi, numeri di telefono, indirizzi e siti web, ideali per generare contatti, attività di marketing o ricerche di mercato.
Scopri di più ->
Estrattore People-Search
L’Estrattore People-Search di Thunderbit ti permette di raccogliere dati strutturati da profili People-Search e pagine di ricerca telefonica inversa. Grazie ai suggerimenti AI per i campi, puoi velocemente ottenere nomi, città, numeri di telefono, email e molto altro per attività di ricerca, marketing o generazione di contatti. Perfetto per marketer, ricercatori e aziende che cercano dati pubblici e informazioni di contatto.
Scopri di più ->
Estrattore UpCity
L'Estrattore UpCity di Thunderbit ti permette di raccogliere dati dagli elenchi di agenzie pubblicitarie e dalle recensioni dei provider su UpCity. Grazie ai suggerimenti AI per i campi, puoi velocemente ottenere nomi delle agenzie, sedi, valutazioni, contatti e contenuti dettagliati delle recensioni per analisi o ricerche. Perfetto per marketer, ricercatori e imprenditori che desiderano dati strutturati da UpCity.
Scopri di più ->
Estrattore Web HKTVmall
Raccogli nomi dei prodotti, prezzi e persino valutazioni dei clienti dalle inserzioni di HKTVmall in pochi clic, senza alcuna configurazione complessa.
Scopri di più ->Pronto a potenziare la tua estrazione dati?
Unisciti a oltre 100.000 professionisti che già usano Thunderbit per automatizzare i loro workflow di web scraping.
La prova gratuita offre crediti illimitati per 8 pagine web.