Estrattore Web IDCrawl
Scelto da professionisti di aziende leader














Dati di Idcrawl che restano utilizzabili
Usa idcrawl per estrarre dati più velocemente, in modo più pulito e su larga scala con Thunderbit.
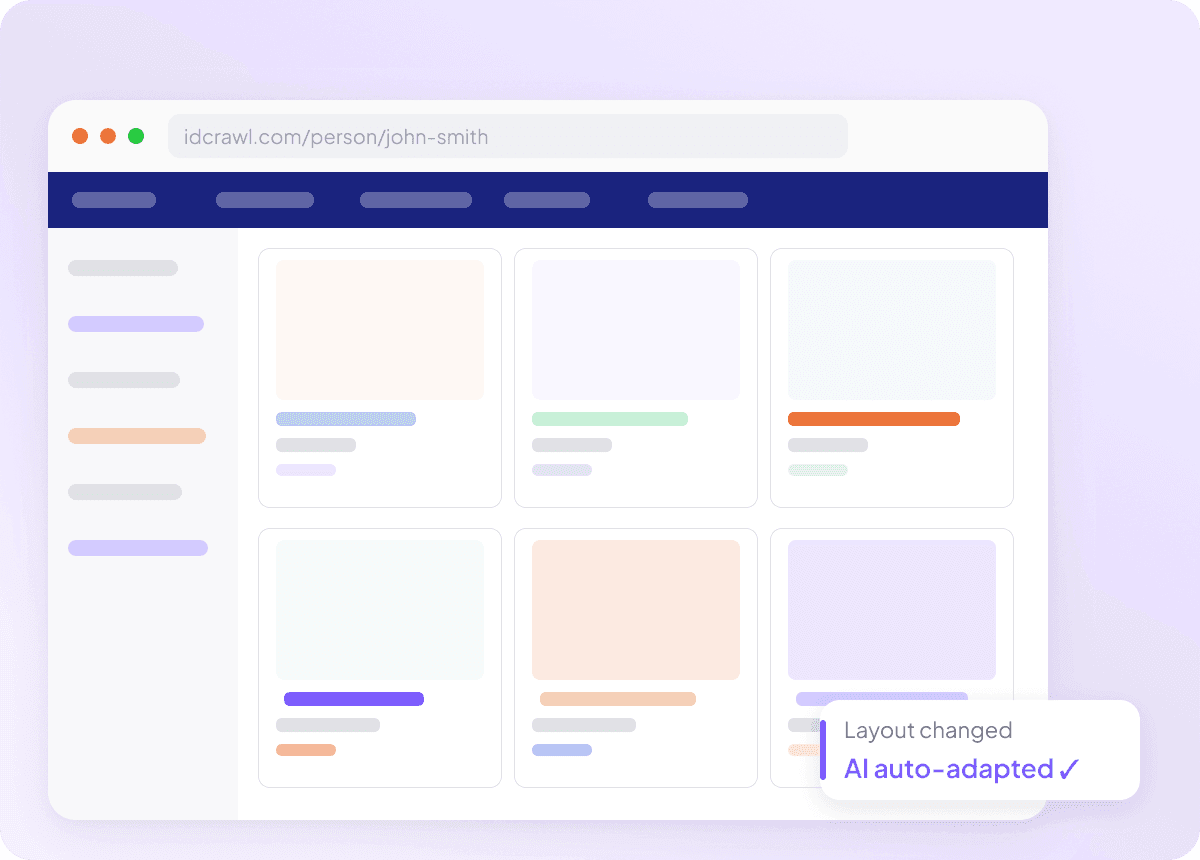
Si adatta quando Idcrawl cambia
Gli scraper che si rompono a ogni aggiornamento del sito sono inutili, soprattutto quando stai cercando di estrarre nome completo, titolo di lavoro, nome dell’azienda, indirizzo email, numero di telefono e profilo LinkedIn da idcrawl. Thunderbit legge la pagina in base al significato, non a selettori fissi, quindi può adattarsi quando il layout cambia. Passi meno tempo a sistemare gli scraper e più tempo a ottenere i dati che ti servono.
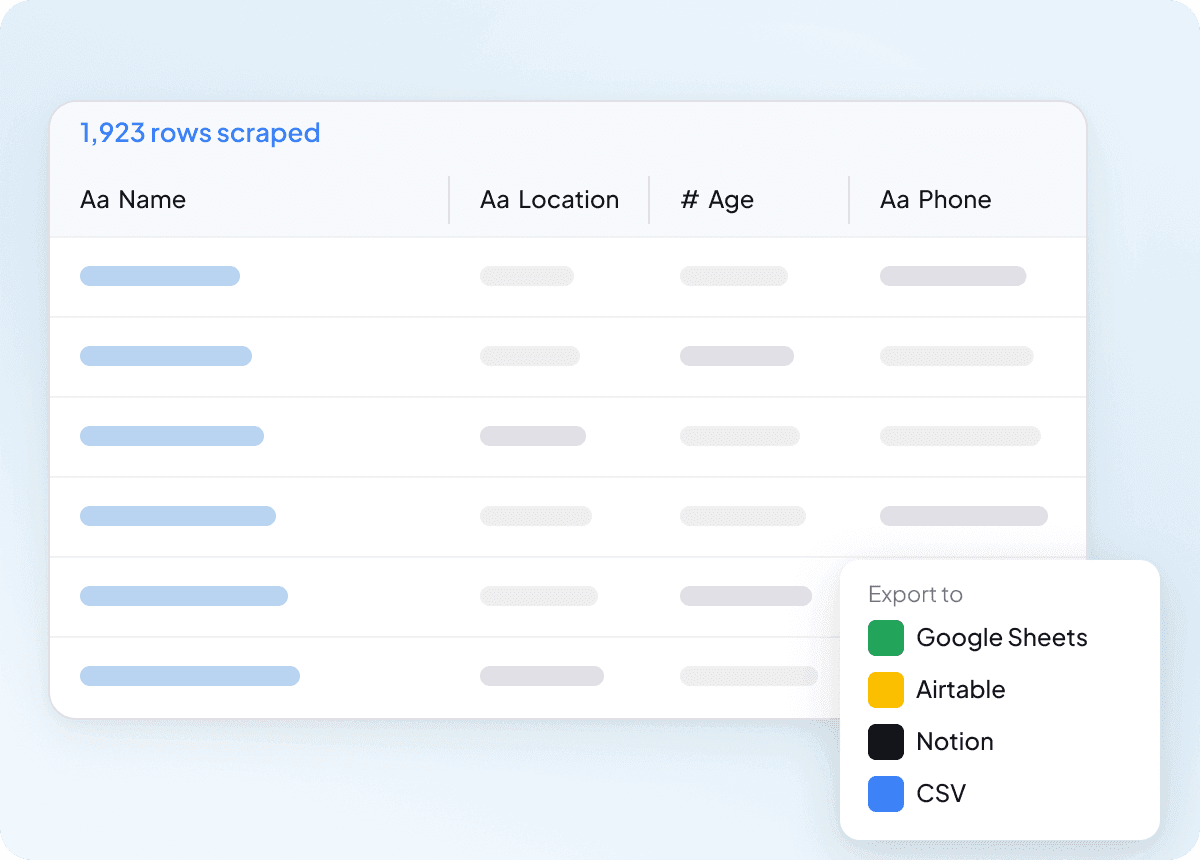
Dati puliti fin dall’inizio
I dati grezzi sono solo l’inizio del vero lavoro, e i risultati di idcrawl spesso vanno ripuliti prima di essere utili. Thunderbit struttura e formatta i dati durante l’estrazione, così ciò che esporti è già pulito e pronto all’uso. Questo significa meno ordinamento, meno rielaborazioni e un passaggio più fluido al tuo team.
Scraping di massa di Idcrawl in un colpo solo
Fare scraping di una pagina idcrawl alla volta non è scalabile quando ti serve un lungo elenco di contatti. Thunderbit può eseguire scraping di massa di centinaia di pagine in una sola volta, così puoi fornirgli un elenco di URL ed estrarre nome completo, titolo di lavoro, nome dell’azienda, indirizzo email, numero di telefono e profilo LinkedIn da tutte. È un modo molto più semplice per trasformare un grande elenco in dati utilizzabili.

Perché Thunderbit è diverso dai tradizionali scraper di idcrawl?
Un modo più semplice per estrarre dati da idcrawl senza correzioni continue.
Scraper tradizionali
Il modo vecchio di fare le coseThunderbit AI
L’approccio più intelligenteNon fidarti solo della nostra parola
Scopri cosa dicono gli utenti di Thunderbit.







Domande frequenti
Correlati casi d'uso
Esplora altri casi d'uso del web scraper di Thunderbit.

Estrattore ReverseAustralia
L’Estrattore ReverseAustralia di Thunderbit ti permette di raccogliere dati dalle pagine di reclami e commenti di ReverseAustralia. Grazie ai suggerimenti intelligenti basati su AI, puoi estrarre rapidamente numeri di telefono, descrizioni dei reclami, testi dei commenti, nomi degli utenti e molto altro per analisi o ricerche. Perfetto per marketer, ricercatori e aziende che desiderano dati strutturati sui feedback.
Scopri di più ->
Estrattore White Pages
L'Estrattore White Pages di Thunderbit ti permette di raccogliere dati dagli elenchi telefonici e aziendali di White Pages grazie ai suggerimenti intelligenti basati su AI. In pochi clic puoi ottenere nomi, numeri di telefono, indirizzi e siti web, ideali per generare contatti, attività di marketing o ricerche di mercato.
Scopri di più ->
Estrattore Web BestPrice GR
L’Estrattore Web AI di Thunderbit per BestPrice GR ti permette di raccogliere in pochi clic elenchi di prodotti, prezzi e informazioni dettagliate da BestPrice.gr. È la soluzione ideale per team di vendita, marketing ed e-commerce che vogliono ottenere dati strutturati in modo rapido ed efficiente.
Scopri di più ->
Estrattore iBegin
L'Estrattore iBegin di Thunderbit ti permette di raccogliere risultati di ricerca aziendali e informazioni dettagliate sulle imprese dal sito iBegin. Grazie ai suggerimenti intelligenti basati su AI, puoi velocemente ottenere nomi aziendali, recapiti, indirizzi, valutazioni e molto altro per generazione di lead, ricerche di mercato o analisi marketing.
Scopri di più ->
Estrattore di Elenchi Aziendali TripAdvisor
L'Estrattore di Elenchi Aziendali TripAdvisor di Thunderbit ti permette di raccogliere dati dagli elenchi aziendali, dall'hub delle risorse e dal forum dei proprietari di TripAdvisor. Grazie ai suggerimenti AI per i campi, puoi velocemente ottenere nomi delle risorse, URL, descrizioni, argomenti dei forum, autori e contenuti dei post per ricerche, marketing o analisi.
Scopri di più ->Estrattore DialIndia
L'Estrattore DialIndia di Thunderbit ti permette di raccogliere dati dai profili aziendali e dalle directory di viaggio di DialIndia grazie ai suggerimenti intelligenti dei campi basati su AI. Raccogli nomi aziendali, dettagli di contatto, sedi e descrizioni per ricerche, marketing o generazione di lead in pochi clic.
Scopri di più ->Pronto a dare una marcia in più all'estrazione dati?
Unisciti a oltre 100.000 professionisti che già usano Thunderbit per automatizzare i loro flussi di web scraping.
La prova gratuita offre crediti illimitati per 8 pagine web.