

Il web scraping è ormai una marcia in più per i team aziendali di oggi: che tu sia nelle vendite, nelle operation o nel marketing, riuscire a raccogliere dati dal web in modo rapido può davvero fare la differenza tra un progetto che decolla e uno che resta al palo. Con la corsa alle decisioni data-driven, le aziende cercano strumenti che siano non solo veloci, ma anche affidabili e pronti a scalare. Ed è qui che entra in scena Rust: un linguaggio di programmazione moderno che sta conquistando sempre più spazio nel mondo dell’estrazione dati dal web, soprattutto per chi ha bisogno di velocità e sicurezza.
Non si tratta solo di una moda del momento: Rust è stato eletto per diversi anni di fila il "linguaggio di programmazione più amato" nel Sondaggio degli Sviluppatori di Stack Overflow, e il suo utilizzo nel backend e nella data engineering è in forte crescita. Ma cosa vuol dire davvero “fare web scraping in Rust” per chi lavora in azienda? E come si confronta con soluzioni no-code come Thunderbit, pensate per chi non ha un background tecnico? Scopriamolo insieme, senza bisogno di essere dei nerd del codice.
Cos’è il Web Scraping con Rust? Spiegato in modo semplice
In parole povere, il web scraping è il modo per estrarre automaticamente dati dai siti web. Immagina di avere un assistente digitale che gira per centinaia (o migliaia) di pagine online, copia le informazioni che ti servono—prezzi, contatti, recensioni—e te le restituisce già ordinate e pronte all’uso. Un bel risparmio di tempo per chi ha bisogno di dati freschi per generare lead, fare analisi di mercato, monitorare prezzi e molto altro.
Rust è un linguaggio di programmazione famoso per le sue performance, la sicurezza nella gestione della memoria e l’affidabilità. Diversamente dai linguaggi più datati, che spesso si portano dietro bug o rallentamenti, Rust è pensato per intercettare gli errori ancora prima che il codice venga eseguito. Per il web scraping, questo si traduce in strumenti super veloci e molto meno soggetti a crash o perdite di memoria—un vantaggio enorme quando si lavora con grandi quantità di dati.
E non è solo una questione da sviluppatori: i benefici di Rust si sentono anche in azienda. Scraping più veloce e sicuro vuol dire dati più aggiornati, meno errori e analisi più affidabili per tutto il team.
Perché scegliere Rust per il Web Scraping? I vantaggi per le aziende
Perché sempre più team stanno puntando su Rust per il web scraping, quando Python e JavaScript sono stati i re indiscussi per anni? Ecco i motivi principali:
- Prestazioni top: Rust viene compilato direttamente in codice macchina, quindi è molto più veloce rispetto a linguaggi interpretati come Python o JavaScript. Se devi fare scraping su larga scala—parliamo di milioni di pagine—questa velocità si traduce in un vero vantaggio competitivo.
- Sicurezza della memoria: Il modo in cui Rust gestisce la memoria (senza garbage collector e con regole ferree di proprietà) riduce di molto bug e crash. I tuoi processi di scraping hanno meno probabilità di bloccarsi a metà, risparmiando tempo e grattacapi.
- Affidabilità: Il compilatore di Rust è severissimo su tipi ed errori, così tanti problemi vengono intercettati prima ancora di lanciare il programma. Il risultato? Flussi di lavoro più stabili e prevedibili.
- Concorrenza: Rust rende più semplice scrivere codice che fa più cose insieme (ne parliamo tra poco), fondamentale per estrarre dati da tante pagine in parallelo.
E rispetto a Python o JavaScript? Questi linguaggi sono più facili per iniziare, ma quando si tratta di performance e affidabilità su grandi volumi, mostrano i loro limiti. I punti di forza di Rust ti permettono di raccogliere più dati, più in fretta e con meno problemi—un bel boost per la tua azienda.
La forza dell’asincronia in Rust: Web Scraping efficiente su larga scala
Qui Rust dà davvero il meglio: la programmazione asincrona. In parole semplici, il codice asincrono permette al tuo estrattore di recuperare dati da tanti siti contemporaneamente, senza dover aspettare che ogni richiesta finisca prima di iniziare la successiva. Un vero game changer quando serve raccogliere grandi quantità di dati in poco tempo.
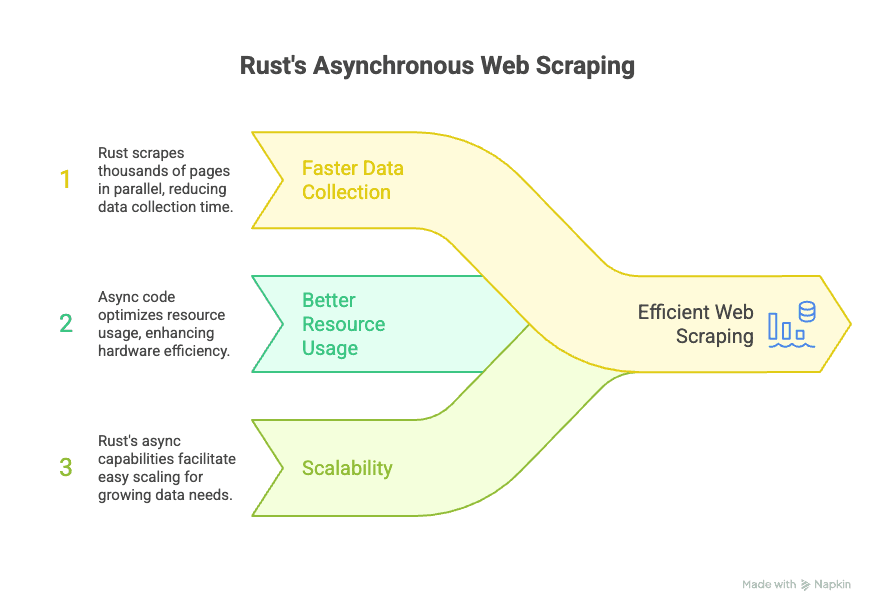
L’ecosistema asincrono di Rust si basa su librerie come Tokio e async-std, che permettono al tuo estrattore di gestire migliaia di richieste in contemporanea senza bloccare tutto. Per chi lavora in azienda, questo significa:
- Raccolta dati più veloce: Puoi estrarre migliaia di pagine in parallelo, tagliando drasticamente i tempi per creare il tuo dataset.
- Risorse usate meglio: Il codice asincrono è più efficiente, quindi puoi fare di più anche con hardware non potentissimo.
- Scalabilità: Se le tue esigenze di dati crescono, Rust ti permette di scalare senza dover riscrivere tutto da capo.
In pratica, il tuo team può reagire ai cambiamenti di mercato, monitorare la concorrenza o generare lead in tempo reale—senza dover aspettare ore (o giorni) per scaricare i dati.
Come funziona il Web Scraping con Rust? Una panoramica step by step
Vuoi capire come si svolge di solito un processo di web scraping in Rust? Ecco una panoramica semplice e senza tecnicismi:
- Impostazione: Decidi quali dati vuoi raccogliere e da quali siti.
- Recupero dati: Usi librerie come Reqwest per scaricare le pagine web.
- Parsing dei contenuti: Con Scraper o Select estrai le informazioni che ti servono (nomi prodotti, prezzi, email) dall’HTML.
- Gestione della paginazione/sottopagine: Scrivi la logica per navigare tra più pagine o seguire i link alle sottopagine (vedi sotto).
- Esportazione dei dati: Salvi i dati estratti in un formato strutturato—CSV, Excel o direttamente in un database—pronto per essere usato dal tuo team.
Ogni libreria ha il suo compito: Reqwest si occupa del "recupero", Scraper/Select del "parsing", e puoi usare le funzioni di Rust o librerie esterne per esportare e organizzare i risultati.
Gestire siti complessi: come Rust affronta paginazione e sottopagine
Spesso lo scraping aziendale non si ferma a una sola pagina. Potresti dover:
- Estrarre tutti i prodotti da un catalogo su più pagine
- Raccogliere recensioni sparse su diverse sottopagine
- Ottenere contatti da directory annidate
Rust è perfetto per queste sfide. Il suo sistema di tipi e la gestione rigorosa degli errori rendono più facile scrivere codice che può:
- Riconoscere e seguire automaticamente i pulsanti "Avanti" o i link di paginazione
- Visitare sottopagine (come dettagli prodotto o profili autore) e unire quei dati al dataset principale
- Gestire cambiamenti imprevisti (come pagine mancanti o link rotti) senza far saltare tutto
Per esempio, un estrattore Rust può partire da una lista principale di prodotti, seguire ogni link di paginazione e poi visitare la pagina di dettaglio di ogni prodotto—raccogliendo prezzo, descrizione e recensioni. Il risultato? Un dataset completo e aggiornato, pronto per l’analisi.
Thunderbit vs. Codice Rust: il vantaggio no-code per i team aziendali
Arriviamo all’elefante nella stanza: non tutti hanno tempo (o voglia) di costruire un estrattore Rust da zero. Qui entra in gioco Thunderbit.
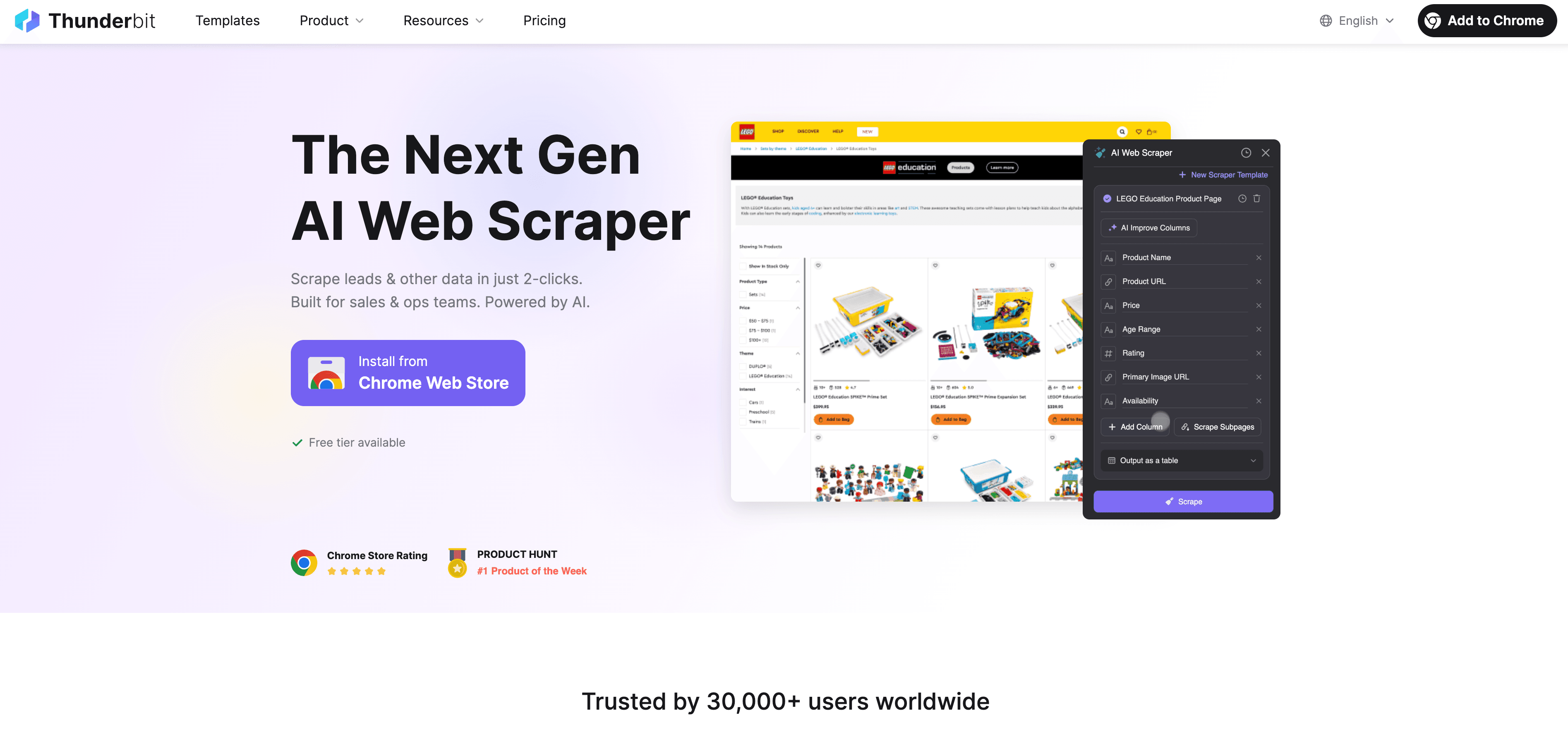
Thunderbit è un Estrattore Web AI senza codice pensato proprio per chi lavora in azienda. Invece di scrivere codice, basta:
- Aprire la Thunderbit Chrome Extension
- Navigare sul sito da cui vuoi estrarre i dati
- Cliccare su “AI Suggerisci Campi” e lasciare che l’AI di Thunderbit proponga quali dati estrarre
- Premere “Estrai” ed esportare i risultati direttamente su Excel, Google Sheets, Airtable o Notion
Niente template, niente codice, niente sbattimenti. Thunderbit gestisce anche paginazione e estrazione da sottopagine in automatico—proprio come un estrattore Rust fatto su misura, ma con un’interfaccia super intuitiva.
Prova gratis Thunderbit Estrattore Web AI
Quando scegliere Thunderbit invece di Rust? Scegli lo strumento giusto
Quale approccio fa per il tuo team? Ecco una tabella riassuntiva:
| Scenario | Thunderbit | Rust |
|---|---|---|
| Generazione rapida di lead per le vendite | ✅ Facilissimo e veloce | Possibile, ma eccessivo |
| Monitoraggio prezzi dei concorrenti (ecommerce) | ✅ No-code, programmabile | ✅ Per integrazioni personalizzate |
| Scraping di flussi di lavoro complessi e su misura | Possibile, ma limitato | ✅ Controllo totale, altamente personalizzabile |
| Pipeline dati integrate e su larga scala | Possibile (tramite API) | ✅ Ideale per integrazioni profonde |
| Utenti non tecnici (vendite, operation, marketing) | ✅ Pensato per te | ❌ Richiede competenze di programmazione |
| Prototipazione rapida o attività una tantum | ✅ Pronto in 2 click | Possibile, ma più lento da avviare |
In breve: Thunderbit è perfetto per chi vuole estrarre dati in modo rapido e affidabile senza complicazioni tecniche. Rust è la scelta giusta quando serve il massimo controllo, logiche personalizzate o scraping su scala molto ampia.
Esempio pratico: Web Scraping con Rust in azione
Facciamo un esempio concreto. Immagina di essere un analista di mercato e dover raccogliere dati su tutti i laptop di un grande sito ecommerce. Il sito ha la paginazione (più pagine di prodotti) e ogni prodotto ha una pagina di dettaglio con specifiche e recensioni.
Con Rust, potresti:
- Usare Reqwest per scaricare la pagina principale dell’elenco prodotti
- Analizzare l’HTML con Scraper per estrarre i link ai prodotti
- Riconoscere e seguire il pulsante “Avanti” per estrarre tutte le pagine
- Per ogni prodotto, visitare la pagina di dettaglio ed estrarre specifiche/recensioni
- Gestire eventuali errori (come pagine mancanti) in modo robusto, riprovando se serve
- Esportare il dataset finale in CSV o sulla tua piattaforma di analisi
Il valore per il business? Ottieni una panoramica completa e aggiornata del mercato—fondamentale per decisioni su prezzi, inventario e strategie di marketing.
Sfide e considerazioni chiave per il Web Scraping con Rust
Ovviamente, anche con tutti i vantaggi di Rust, il web scraping può presentare delle sfide. Ecco le più comuni (e come Rust può aiutare):
- Cambiamenti nei siti: Se la struttura del sito cambia, l’estrattore potrebbe smettere di funzionare. La tipizzazione rigorosa di Rust aiuta a individuare questi problemi in anticipo, ma dovrai comunque aggiornare il codice.
- Misure anti-bot: Molti siti usano CAPTCHA o limiti di frequenza. La velocità di Rust può aiutare a restare sotto i radar, ma a volte serve aggiungere ritardi o usare proxy.
- Formattazione dei dati: Non tutti i dati sono puliti—gli strumenti di parsing di Rust aiutano a gestire HTML disordinato o incoerente.
- Manutenzione: Gli estrattori personalizzati richiedono manutenzione continua. In azienda, questo vuol dire collaborare con i tecnici o valutare strumenti no-code come Thunderbit per le attività ricorrenti.
Cos'è il Data Scraping e Come Farlo nel 2025 Get Started Free
Consiglio pratico: Che tu usi Rust o Thunderbit, rispetta sempre i termini di servizio dei siti e le normative sulla privacy quando estrai dati.
Conclusione: Sfrutta il Web Scraping con Rust (e oltre) per il business
Il web scraping è ormai una skill fondamentale per qualsiasi azienda che voglia restare competitiva in un mondo guidato dai dati. Rust offre prestazioni, sicurezza e affidabilità senza rivali per chi ha bisogno di soluzioni su misura e su larga scala—soprattutto quando velocità e stabilità sono cruciali. Ma per la maggior parte degli utenti aziendali, la barriera tecnica è reale.
Qui Thunderbit fa la differenza: porta la potenza del web scraping a tutti, con un’interfaccia AI no-code che gestisce anche compiti complessi come paginazione ed estrazione da sottopagine. Che tu sia un commerciale che crea una lista di lead, un ecommerce manager che monitora i prezzi o un analista che raccoglie dati di mercato, Thunderbit ti permette di ottenere i dati che ti servono—subito.
In sintesi:
- Rust è una soluzione potente per scraping personalizzato e su larga scala—ideale per team tecnici.
- Thunderbit rende il web scraping accessibile anche a chi non sa programmare.
- Scegli lo strumento giusto: Rust per la massima personalizzazione, Thunderbit per velocità e semplicità.
Estrai dati da qualsiasi sito web con l'AI Get Started Free
Vuoi provare il web scraping per la tua azienda? Scarica Thunderbit e scopri quanto può essere semplice estrarre dati. Oppure, se sei pronto a investire in una soluzione su misura, esplora l’ecosistema Rust per scraping ad alte prestazioni.
Prova Estrattore Web AI Get Started Free
Domande Frequenti
1. Cos’è il web scraping con Rust e in cosa si differenzia dagli altri linguaggi?
Fare web scraping con Rust vuol dire usare questo linguaggio per automatizzare l’estrazione di dati dai siti web. Rispetto a Python o JavaScript, Rust si distingue per velocità, sicurezza della memoria e affidabilità, rendendolo ideale per scraping su larga scala o mission-critical.
2. Rust è adatto a utenti aziendali non tecnici che hanno bisogno di web scraping?
Rust è molto potente, ma richiede competenze di programmazione. Per chi non ha conoscenze tecniche, strumenti come Thunderbit offrono un approccio no-code e guidato dall’AI, rendendo l’estrazione dati accessibile a tutti.
3. Come gestisce Rust compiti complessi come paginazione o sottopagine?
Il sistema di tipi e le librerie asincrone di Rust rendono più semplice scrivere codice che naviga tra pagine, segue link a sottopagine e gestisce errori—così ottieni dataset più completi e affidabili.
4. Quando conviene usare Thunderbit invece di sviluppare un estrattore Rust personalizzato?
Scegli Thunderbit quando vuoi estrarre dati in modo rapido e semplice, senza scrivere codice—perfetto per team di vendita, marketing e operation. Rust è la scelta giusta per flussi di lavoro molto personalizzati, su larga scala o profondamente integrati, che richiedono competenze tecniche.
5. Quali sono le principali sfide del web scraping con Rust e come affrontarle?
Le difficoltà più comuni sono i cambiamenti nei siti, le misure anti-bot e la manutenzione continua. Le funzionalità di sicurezza di Rust aiutano a individuare gli errori in anticipo, ma dovrai comunque aggiornare il codice quando i siti cambiano. Per attività ricorrenti, uno strumento no-code come Thunderbit può farti risparmiare tempo e fatica.
Per approfondire:




