
Siamo sinceri: il web è un posto selvaggio, selvaggio. Ogni giorno mi sembra di stare davanti a un idrante digitale: notizie, recensioni, annunci di prodotti, tweet, offerte immobiliari, di tutto e di più, che scorrono fuori in un flusso disordinato e non strutturato. E se gestisci un’azienda, dare un senso a tutto questo caos può sembrare come cercare un ago in un pagliaio… mentre il pagliaio è in fiamme. (Ci sono passato. Non è divertente.)
Ma ecco il punto: nascosti in tutto quel rumore online ci sono veri tesori—insight che possono far crescere le vendite, battere la concorrenza e automatizzare le attività noiose che nessuno vuole fare. È qui che entra in gioco il web scraping. Con gli strumenti giusti, puoi trasformare quella montagna di dati web non strutturati in fogli di calcolo ordinati e utili, pronti per la tua prossima grande mossa. E da persona che ha passato anni nel SaaS e nell’automazione, posso dirti che il web scraping non è più solo per chi programma. È per chiunque voglia lavorare in modo più intelligente, non più duro.
Significato di Web Scraping: trasformare il caos online in dati utilizzabili

Quindi, che cos’è esattamente il web scraping? Niente gergo, andiamo al sodo: il web scraping è il processo di usare un software per estrarre informazioni specifiche dai siti web e convertirle in formati strutturati—pensa a Excel, Google Sheets o a un database. Immagina di avere un assistente digitale che copia senza sosta le informazioni esatte di cui hai bisogno da migliaia di pagine web e le organizza per te. In poche parole, questo è il web scraping.
Potresti sentire anche parlare di “data scraping”. Ecco la differenza: data scraping è un termine ampio per indicare l’estrazione di dati da qualsiasi fonte (siti web, PDF, immagini, e via dicendo). Web scraping riguarda nello specifico l’estrazione di dati dai siti web su Internet. In altre parole, tutto il web scraping è data scraping, ma non tutto il data scraping è web scraping. (Un po’ come tutti i quadrati sono rettangoli, ma non tutti i rettangoli sono quadrati.)
Se vuoi una definizione più formale, il web scraping è “data scraping usato per estrarre dati dai siti web” (Wikipedia). Ma nella pratica è semplicemente automazione per la ricerca online—niente più copia e incolla fino a farti venire male alle dita.
Perché il web scraping è importante per le aziende moderne
Cos’è il data scraping e come farlo nel 2025 Get Started Free
Parliamo di business. Perché il web scraping è così importante oggi? Perché Internet sta affogando nei dati non strutturati—circa l’80%–90% di tutti i nuovi dati è non strutturato, dai post sui social agli annunci di prodotti. IDC prevede che il volume globale di dati raggiungerà 175 zettabyte entro il 2025—una quantità enorme.
Ecco il problema: il 60–80% del tempo dei dipendenti viene sprecato solo per trovare e preparare i dati, non per analizzarli. È come assumere uno chef per sbucciare patate tutto il giorno invece di cucinare. Come ha detto Michael Shulman, Head of Machine Learning di Kensho: “Poiché la maggior parte dei dati del mondo è non strutturata, la capacità di analizzarli e agire su di essi rappresenta una grande opportunità.”
Il web scraping ribalta la situazione. Invece di andare manualmente a caccia sui siti web, automatizzi il processo—raccogliendo dati live, in tempo reale, da qualsiasi parte del web. Non sorprende che il 71% delle aziende di servizi finanziari e più della metà delle aziende retail/e-commerce usino già il web scraping per ottenere dati esterni. I dati non sono solo il nuovo petrolio: sono la nuova valuta, e il web scraping è il modo in cui li incassi.
Casi d’uso comuni del web scraping in diversi settori
Il web scraping non è uno strumento monouso. Si usa ovunque—dai team vendite agli analisti immobiliari. Ecco alcuni esempi concreti:
- Lead di vendita e prospecting B2B: estrai dati da job board o directory aziendali per costruire liste lead nuove e mirate. Un’azienda SaaS ha visto un aumento del 40% nei lead qualificati automatizzando questo processo.
- Prezzi e monitoraggio prodotti e-commerce: i retailer estraggono dai siti dei concorrenti prezzi e disponibilità, aggiornando i propri prezzi quasi in tempo reale. Il risultato? Più vendite e clienti fedeli.
- Annunci immobiliari: aggregatori e investitori estraggono da siti immobiliari annunci, prezzi e trend—così individuano immobili sottovalutati e quartieri in forte crescita (case study).
- Viaggi e ospitalità: estrai da siti di compagnie aeree e hotel tariffe, disponibilità e recensioni—alimentando strumenti di comparazione prezzi e analisi del sentiment.
- Finanza e investimenti: gli hedge fund estraggono di tutto, dai documenti SEC alle recensioni dei prodotti, alla ricerca di segnali di dati alternativi. Il 71% delle società finanziarie usa ormai il web scraping nelle proprie operazioni.
In sostanza: se sul web c’è un dato di valore, c’è un modo per estrarlo e trasformarlo in valore per il business.
Come funziona il web scraping: dal sito al foglio di calcolo
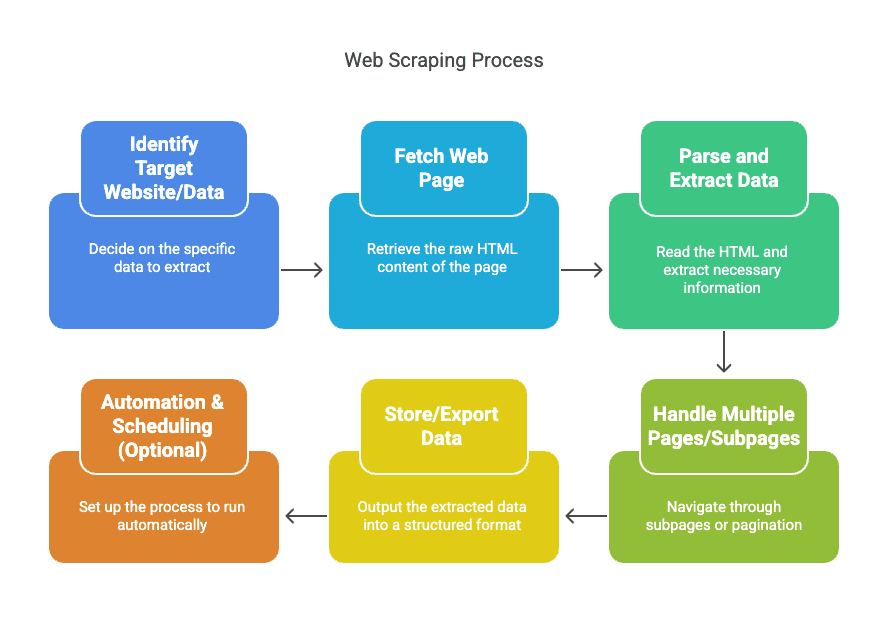
Semplifichiamo il processo. Il web scraping non è magia—è una pipeline. Ecco come funziona di solito:
- Identifica il sito/la fonte dati di destinazione: decidi cosa vuoi ottenere (ad esempio nomi e prezzi dei prodotti da xyz).
- Recupera la pagina web: lo scraper recupera l’HTML grezzo, proprio come fa il browser.
- Analizza ed estrae i dati: lo strumento legge l’HTML e tira fuori le informazioni che ti servono (come prezzi, nomi, recensioni).
- Gestisci più pagine/sottopagine: gli scraper possono seguire link verso sottopagine o cliccare automaticamente attraverso la paginazione.
- Salva/esporta i dati: esporta tutto in un formato strutturato—CSV, Excel, Google Sheets o database.
- Automazione e pianificazione (opzionale): imposta l’esecuzione su base programmata, così i dati restano aggiornati senza muovere un dito.
Fare tutto a mano richiederebbe un’eternità (e parecchio caffè). Con il web scraping automatizzi l’intero processo—trasformando ore di lavoro ripetitivo in minuti.
Il ruolo degli strumenti di scraping e dei servizi di web scraping
Ora parliamo di strumenti. Le opzioni sono tante: estensioni per browser, piattaforme cloud e software desktop. Ecco una panoramica veloce:
- Estensioni per browser: strumenti leggeri, point-and-click, che vivono nel browser. Ottimi per lavori rapidi e semplici.
- Software desktop: applicazioni complete con interfacce visive—gestiscono login, infinite scroll e molto altro.
- Piattaforme cloud: eseguono gli scraper su server remoti—ideali per attività su larga scala e sempre attive.
- Codice personalizzato: per i più tecnici—scrivi i tuoi script per avere il massimo controllo (ma anche il massimo numero di grattacapi).
Perché usare questi strumenti invece del copia e incolla? Tre motivi: velocità, scalabilità e affidabilità. Un buon scraper può elaborare migliaia di pagine nel tempo che ti serve per scaldare il pranzo nel microonde. In più, ottieni dati puliti e strutturati—niente refusi, niente dettagli mancanti.
Dati strutturati vs non strutturati: perché il web scraping è essenziale
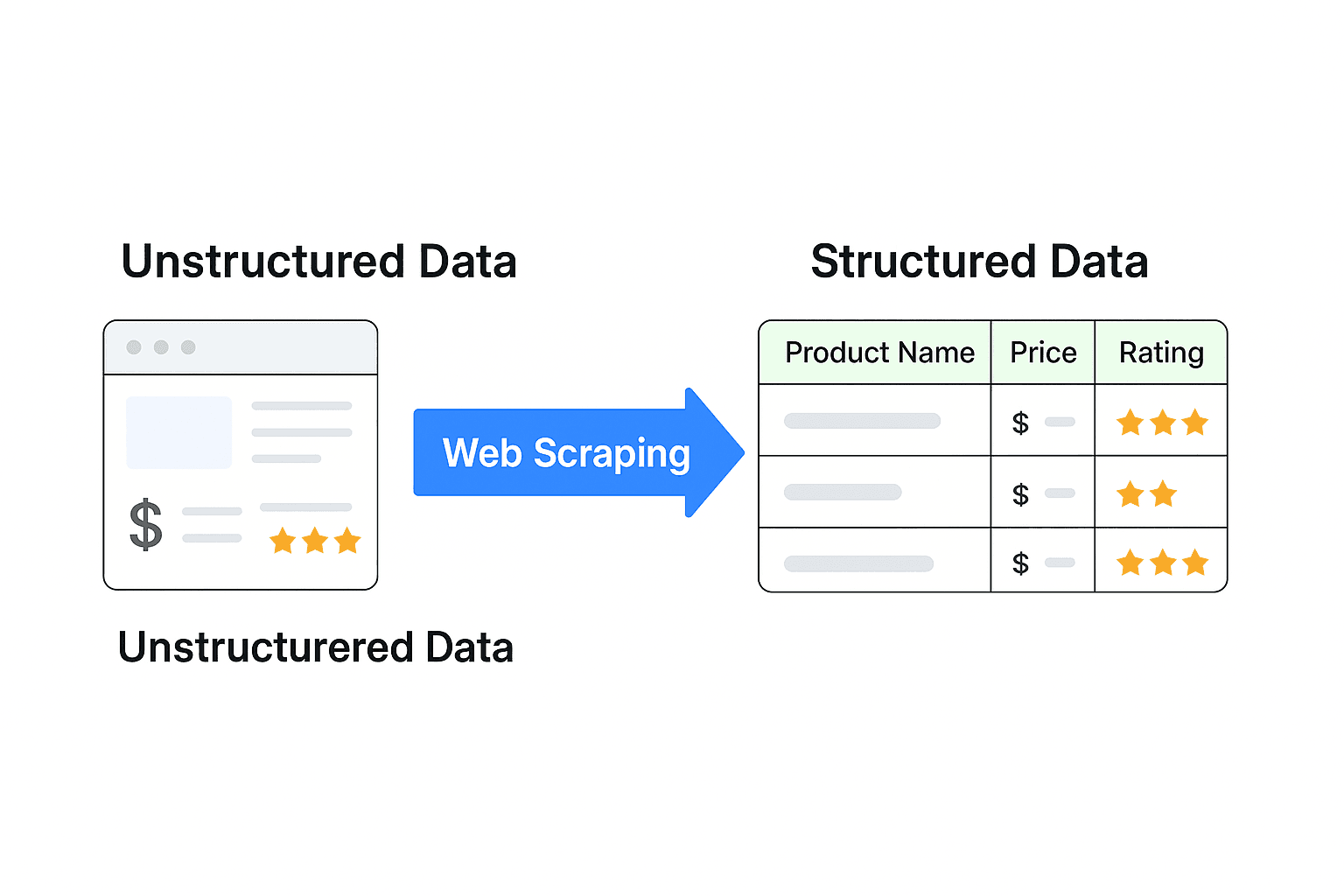
Ecco il punto centrale: la maggior parte dei dati web è non strutturata. È pensata per gli esseri umani, non per le macchine. Pensa a una pagina prodotto con immagini, recensioni e prezzi tutti mescolati insieme. Non puoi semplicemente buttarli in Excel e iniziare ad analizzarli.
I dati strutturati—come un foglio di calcolo con colonne per “Nome prodotto”, “Prezzo” e “Valutazione”—sono ciò che alimenta analytics, dashboard e decisioni. Il web scraping è il ponte che trasforma contenuti web caotici in informazioni pulite e utilizzabili.
Ecco un dato impressionante: solo circa il 50% dei dati non strutturati di un’organizzazione viene persino analizzato. Il resto? Potenziale sprecato. Il web scraping ti aiuta a sbloccarlo.
Tipi di soluzioni di web scraping: codice, no-code e strumenti basati su AI
Vediamo le opzioni:
- Soluzioni basate sul codice: scrivi script in Python (usando librerie come BeautifulSoup o Scrapy), JavaScript o R. Massima flessibilità, ma servono competenze di programmazione—e pazienza quando i siti cambiano e lo script si rompe.
- Soluzioni no-code: strumenti visivi (estensioni browser, app desktop, piattaforme cloud) che ti permettono di configurare gli scrape con i clic, non con il codice. Perfetti per chi in azienda vuole solo risultati.
- Scraper basati su AI: i nuovi arrivati della categoria. Questi strumenti usano l’AI per rilevare automaticamente cosa estrarre, adattarsi ai cambiamenti del sito e persino estrarre dati da PDF o immagini. Thunderbit è un esempio perfetto.
Da persona che ha visto entrambi i mondi—scrivere codice e usare strumenti no-code—posso dire questo: per la maggior parte degli utenti business, gli scraper no-code o basati su AI sono la scelta giusta. Perché lottare con il codice quando puoi ottenere gli stessi risultati in due clic?
Le caratteristiche chiave da cercare in uno strumento di scraping
Estrarre dati da qualsiasi sito web usando l’AI Get Started Free
Non tutti gli scraper sono uguali. Ecco cosa cerco io (e cosa consiglio a ogni team aziendale):
- Facilità d’uso: riesci a partire senza leggere un manuale lungo come un romanzo?
- Rilevamento dei campi con AI: suggerisce automaticamente cosa estrarre?
- Supporto per sottopagine e paginazione: sa gestire elenchi su più pagine e aprire le pagine di dettaglio?
- Opzioni di esportazione: puoi inviare i dati direttamente a Excel, Google Sheets, Airtable o Notion?
- Pianificazione: puoi impostarlo e dimenticartene, con estrazioni automatiche secondo il tuo calendario?
- Riconoscimento dei tipi di dati: riconosce email, numeri di telefono, immagini e altro?
- Template per siti popolari: estrazione in 1 clic per Amazon, Zillow, Instagram, ecc.
Per i team sales, e-commerce e operations, queste funzionalità significano meno lavoro manuale, meno errori e molto più tempo da dedicare a ciò che conta davvero.
Thunderbit: il più semplice AI Web Scraper per tutti
Va bene, è il momento del piccolo spunto promozionale—ma solo perché credo davvero in ciò che stiamo costruendo con Thunderbit.
Thunderbit è un’estensione Chrome per web scraping basata su AI, pensata per gli utenti business, non solo per gli sviluppatori. Ecco cosa la rende diversa:
- Suggerimento campi con AI: basta cliccare “AI Suggest Fields” e Thunderbit legge la pagina, consiglia le colonne migliori e configura tutto per te. Niente più supposizioni o tentativi con i selettori.
- Scraping in 2 clic: apri la pagina, lascia che l’AI suggerisca i campi, clicca “Scrape”. Fatto. È davvero così semplice.
- Sottopagine e paginazione: l’AI di Thunderbit rileva ed estrae automaticamente sottopagine ed elenchi paginati—senza configurazioni extra.
- Scheduled Scraper: vuoi monitorare prezzi o lead ogni giorno? Basta descrivere la pianificazione (“ogni mattina alle 9”), aggiungere gli URL e Thunderbit fa il resto.
- Esportazione istantanea: invia i dati direttamente a Excel, Google Sheets, Airtable o Notion—senza costi nascosti, senza percorsi tortuosi.
- Extractor specializzati: estrazione in 1 clic di email, numeri di telefono e immagini—completamente gratis.
- AI Autofill: usa l’AI per compilare moduli online e automatizzare i flussi di lavoro, non solo per estrarre dati.
- Analisi di documenti e immagini: carica PDF, Word, file Excel o immagini—l’AI di Thunderbit estrarrà le tabelle e strutturerà i dati per te.
E sì, c’è anche un piano gratuito (fino a 6 pagine da estrarre), così puoi provarlo senza alcun rischio. Se ti serve di più, i piani a pagamento partono da 15 $ al mese per 500 righe—molto più conveniente della maggior parte degli strumenti enterprise.
Non prendere solo la mia parola. Gli utenti ci hanno detto cose come: “Thunderbit è, senza dubbio, il web scraper più semplice che abbia mai usato. Sono passato dal passare ore a scrivere script all’estrarre interi siti in pochi minuti—con solo pochi clic.” È il tipo di feedback che ripaga tutte le sessioni di coding notturne.
Vuoi vedere Thunderbit in azione? Dai un’occhiata al nostro canale YouTube o leggi di più sul blog di Thunderbit.
Prova gratis l’estensione Chrome di Thunderbit
Best practice di web scraping per team non tecnici
Il web scraping è potente, ma un po’ di cautela aiuta molto. Ecco i miei consigli principali per iniziare:
- Rispetta le policy dei siti: controlla sempre i termini di servizio e il robots.txt del sito. Attieniti ai dati pubblici e usali in modo responsabile.
- Non sovraccaricare i server: sii gentile—non martellare un sito con richieste continue. La maggior parte degli strumenti consente di impostare ritmi di crawling o ritardi.
- Inizia in piccolo: prova lo scraper prima su poche pagine. Assicurati di ottenere i dati che ti servono prima di scalare.
- Gestisci la paginazione: non dimenticare di estrarre tutte le pagine, non solo la prima.
- Valida i tuoi dati: pulisci e controlla i risultati—rimuovi duplicati, sistema la formattazione e verifica che non manchi nulla.
- Mantieni ordine: documenta cosa hai estratto, quando e da dove. Ti eviterà molti problemi in seguito.
- Controlla se esistono API: a volte c’è un’API ufficiale che fornisce i dati in modo più semplice e affidabile rispetto all’estrazione dell’HTML.
- Monitora i cambiamenti: i siti cambiano. Se lo scraper smette di funzionare, potrebbe essere il momento di aggiornare la configurazione (o lasciare che se ne occupi l’AI).
- Usa lo strumento giusto: se uno strumento non funziona, prova un altro. Non aver paura di sperimentare.
- Resta etico: solo perché puoi estrarre qualcosa non significa sempre che debba farlo. Rispetta privacy e proprietà dei dati.
Per approfondire, dai un’occhiata alla nostra guida: Cos’è il data scraping e come farlo nel 2025.
Conclusione: sbloccare valore di business con il web scraping

Tiriamo le somme. Il web è pieno di dati preziosi, ma la maggior parte è bloccata in formati non strutturati. Il web scraping è la chiave che sblocca quei dati—trasformando il caos in chiarezza e il lavoro ripetitivo in crescita.
Che tu lavori nelle vendite, nell’e-commerce, nel real estate o nelle operations, il web scraping può aiutarti a:
- Generare lead più freschi e di qualità migliore
- Monitorare concorrenti e mercati in tempo reale
- Automatizzare flussi di lavoro noiosi e risparmiare ore ogni settimana
- Prendere decisioni più intelligenti, più rapide e basate sui dati
E grazie agli strumenti moderni—soprattutto alle soluzioni basate su AI come Thunderbit—non devi essere uno sviluppatore o un data scientist per iniziare. Ti basta scegliere un progetto, provare uno strumento (la nostra estensione Chrome è un ottimo punto di partenza) e vedere quanto di più puoi ottenere quando lasci che l’automazione faccia il lavoro pesante.
In un mondo in cui “i dati sono il nuovo petrolio”, il web scraping è la tua pompa. Quindi vai pure—trasforma quell’idrante di dati online in un flusso costante di insight e guarda la tua azienda prosperare.
Buono scraping! E se mai dovessi trovarti in difficoltà, sai dove trovarmi (o almeno dove trovare Thunderbit).
Inizia a fare scraping con Thunderbit AI
Domande frequenti
1. Che cos’è il web scraping, in parole semplici?
Il web scraping consiste nell’usare un software per estrarre automaticamente dati specifici dai siti web—come prezzi, recensioni o offerte di lavoro—e trasformarli in qualcosa di utile, come un foglio di calcolo. Pensalo come assumere un tirocinante robot per fare tutto il lavoro noioso di copia e incolla al posto tuo, 24/7.
2. Devo saper programmare per usarlo?
Non più. Grazie agli strumenti no-code e basati su AI come Thunderbit, puoi estrarre dati dai siti con un paio di clic—niente Python, niente debugging, nessun problema. Se sai navigare sul web, sai anche estrarre dati dal web.
3. Che tipo di dati posso estrarre?
Praticamente tutto ciò che è pubblico online:
- Inserzioni e prezzi dei prodotti
- Immobili
- Annunci di lavoro
- Directory aziendali
- Biografie sui social media
- Tabelle e immagini nei PDF (sì, anche quelle)
Se è online e visibile, c’è un modo per estrarlo.
4. Il web scraping è legale?
In generale sì—a patto che tu stia estraendo dati pubblici in modo responsabile. Non sovraccaricare i server, rispetta i termini di servizio ed evita di estrarre dati personali o protetti da login. In caso di dubbio, sii etico e mantieni tutto pulito.
Leggi di più
- 3 modi in cui il web scraping alimenta la crescita aziendale
- Case study: come un retailer ha usato lo scraping per aumentare le vendite
- Perché i dati esterni sono il futuro della strategia competitiva
Prova AI Web Scraper Get Started Free




