Hai mai provato a tenere d’occhio centinaia di siti concorrenti, solo per scoprire che ti servirebbe una squadra intera (o litri di caffè) per copiare e incollare tutti quei dati a mano? Non sei il solo. Oggi i dati online sono oro puro per chi lavora in vendite, marketing, ricerca o operations. Pensa che il web scraping ormai rappresenta più di e l’81% dei retailer americani usa estrattori automatici per monitorare i prezzi (). Insomma, sono i bot a fare il lavoro sporco.
Ma come funzionano davvero questi bot? E perché così tanti team scelgono Node.js—il motore JavaScript che fa girare buona parte del web moderno—per costruire i propri node web crawler? Dopo anni nel mondo SaaS e dell’automazione (e come CEO di ), ho visto come gli strumenti giusti possano trasformare la raccolta dati da incubo a superpotere competitivo. Vediamo insieme cos’è davvero un node web crawler, come funziona e come anche chi non scrive codice può sfruttarlo al massimo.
Node Web Crawler: Le Basi
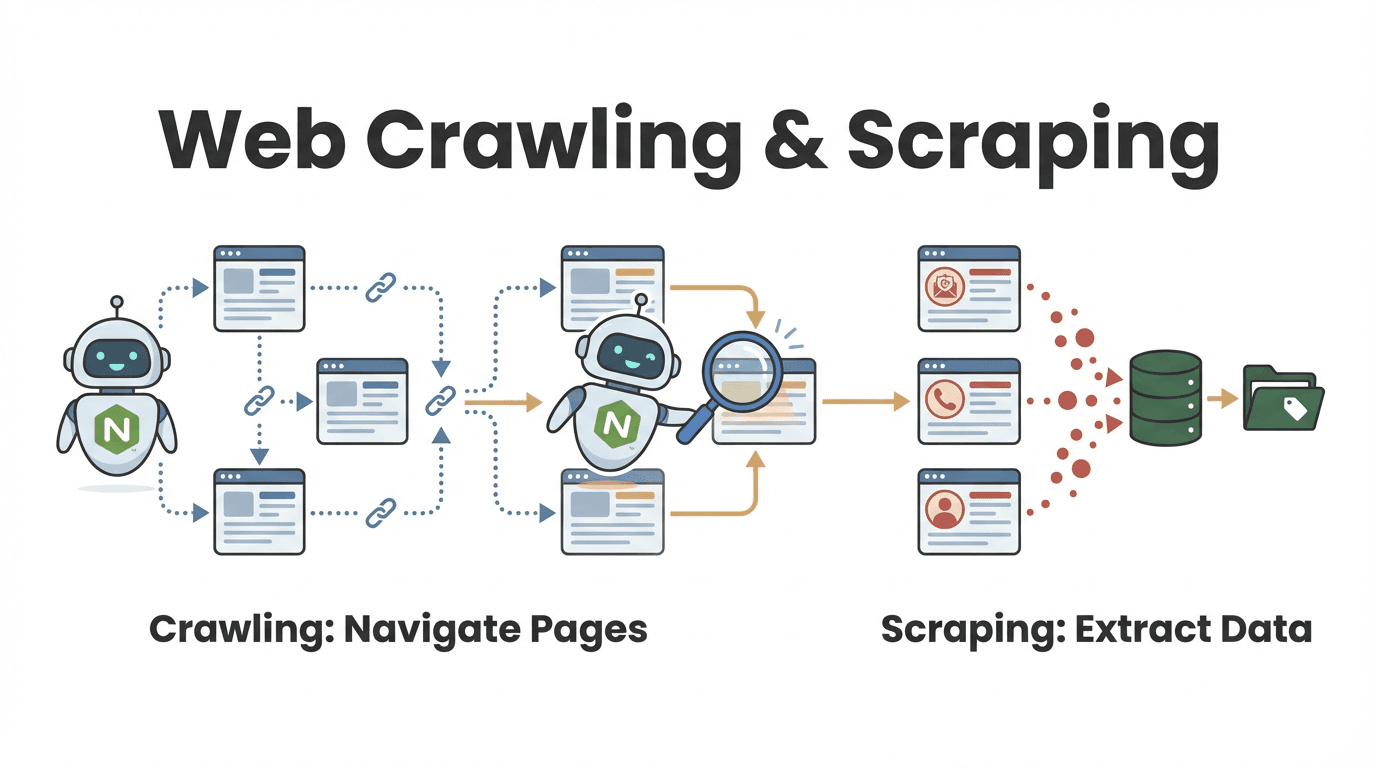
Partiamo dalle fondamenta. Un node web crawler è un programma—scritto con Node.js—che visita in automatico le pagine web, segue i link e raccoglie informazioni. Immaginalo come uno stagista digitale instancabile: gli dai un URL di partenza, lui gira tra le pagine, prende i dati che ti servono e continua finché non ha esplorato tutto il sito (o solo le parti che ti interessano).
Ma qual è la differenza tra web crawling e web scraping? È una domanda che mi fanno spesso, soprattutto chi lavora in azienda:
- Web crawling vuol dire scoprire e navigare tante pagine. È come sfogliare tutti i libri di una biblioteca per trovare quelli che parlano di un certo argomento.
- Web scraping invece è estrarre informazioni specifiche da quelle pagine—tipo copiare le citazioni più interessanti da ogni libro.
Nella pratica, la maggior parte dei node web crawler fa entrambe le cose: trova le pagine giuste e ne tira fuori i dati che servono (). Ad esempio, un team commerciale può esplorare una directory per trovare tutti i profili aziendali e poi estrarre i contatti da ciascuno.
Come Funziona un Node Web Crawler?
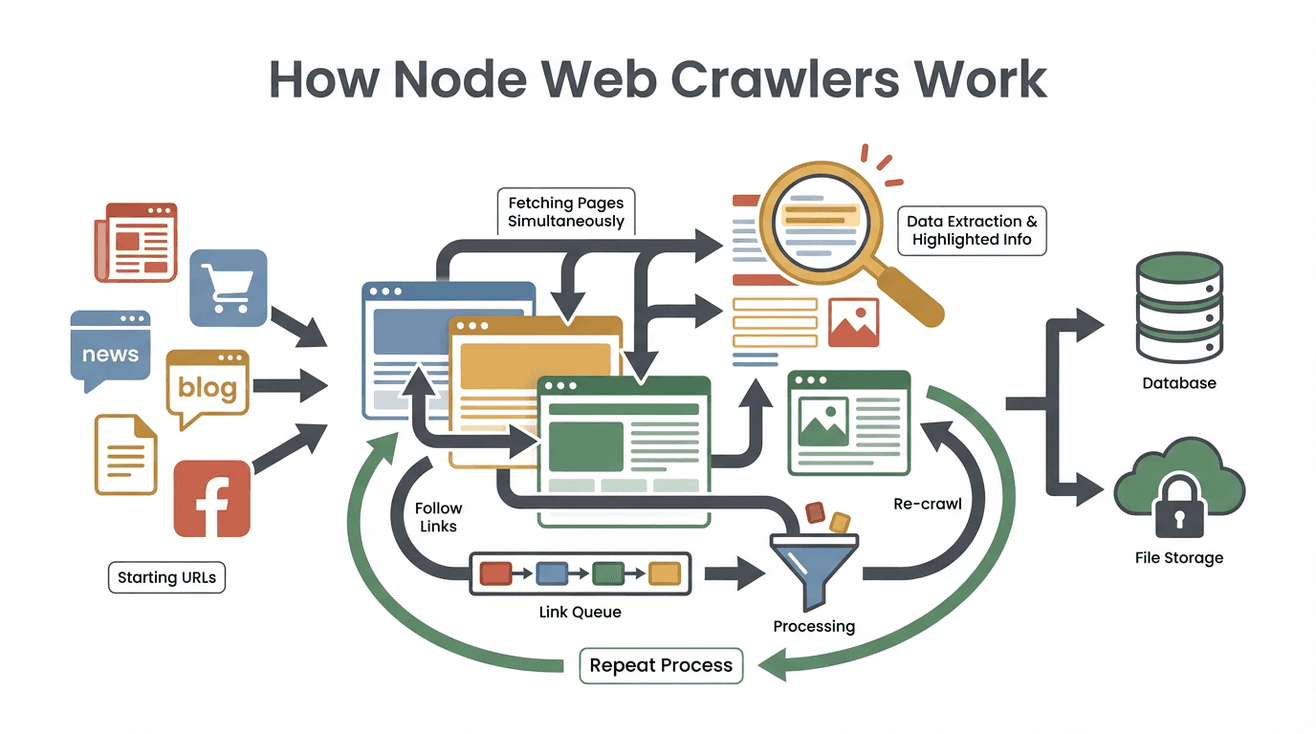 Facciamo chiarezza sul processo. Ecco come lavora, passo dopo passo, un classico node web crawler:
Facciamo chiarezza sul processo. Ecco come lavora, passo dopo passo, un classico node web crawler:
- URL di partenza: Dai al crawler uno o più link iniziali (tipo la homepage o una pagina elenco prodotti).
- Scarica il contenuto: Il crawler recupera l’HTML di ogni pagina—proprio come fa il browser, ma senza caricare immagini o grafica.
- Estrae i dati utili: Con strumenti come Cheerio (simile a jQuery per Node), seleziona le informazioni che ti interessano—nomi, prezzi, email, ecc.
- Trova e mette in coda nuovi link: Analizza ogni pagina per trovare altri link (come “Pagina successiva” o dettagli prodotto) e li aggiunge a una lista di cose da visitare (il famoso “crawl frontier”).
- Ripete il ciclo: Continua a visitare nuovi link, estrarre dati ed espandere la ricerca finché non ha coperto tutto quello che hai chiesto.
- Salva i risultati: Tutti i dati raccolti vengono salvati—di solito in formato CSV, JSON o direttamente in un database.
- Si ferma quando ha finito: Il crawler si ferma quando non trova più nuovi link o raggiunge un limite che hai impostato.
Un esempio pratico: vuoi raccogliere tutte le offerte di lavoro da un sito di annunci. Parti dalla pagina principale, estrai tutti i link alle singole offerte, visiti ciascuna, prendi i dettagli e continui a seguire i “Prossimi” finché hai l’elenco completo.
Il segreto dietro le quinte? L’architettura event-driven e non bloccante di Node.js permette al crawler di gestire tante pagine in contemporanea, senza restare bloccato da siti lenti. È come avere una squadra di stagisti che lavorano in parallelo—ma senza dover ordinare pizze.
Perché Node.js è Così Usato per i Web Crawler
Perché proprio Node.js? Perché non Python, Java o altri linguaggi? Ecco cosa rende Node.js perfetto per il web crawling:
- Event-driven e I/O non bloccante: Node.js può gestire decine (o centinaia) di richieste insieme, senza rallentare. Mentre una pagina si carica, ne elabora già altre ().
- Prestazioni elevate: Node si basa sul motore V8 di Google (lo stesso di Chrome), quindi è velocissimo, soprattutto nell’analisi e gestione di grandi quantità di dati web.
- Ecosistema ricco: Esistono librerie Node per ogni esigenza: Cheerio per il parsing HTML, Got per le richieste HTTP, Puppeteer per la navigazione headless e framework come Crawlee per gestire grandi volumi ().
- Sinergia con JavaScript: Visto che la maggior parte dei siti usa JavaScript, Node.js può interagire nativamente. E lavorare con dati JSON è una passeggiata.
- Reattività in tempo reale: Vuoi monitorare decine di siti per variazioni di prezzo o notizie? La concorrenza di Node ti permette di farlo quasi in tempo reale.
Non stupisce che strumenti come Crawlee e Cheerio siano scelti da .
Funzionalità Chiave di un Node Web Crawler
I node web crawler sono veri coltellini svizzeri per i dati online. Ecco cosa offrono di solito—e come queste funzioni rispondono alle esigenze aziendali:
| Funzione/Caratteristica | Come Funziona nei Node Crawler | Esempio di Utilizzo Aziendale |
|---|---|---|
| Navigazione automatica | Segue link e pagine paginati in modo automatico | Lead generation: esplora tutte le pagine di una directory online |
| Estrazione dati | Raccoglie campi specifici (nome, prezzo, contatti) tramite selettori o pattern | Monitoraggio prezzi: estrae i prezzi dei prodotti dai siti concorrenti |
| Gestione concorrente di più pagine | Scarica ed elabora molte pagine in parallelo (grazie all’async di Node.js) | Aggiornamenti in tempo reale: monitora più siti di notizie contemporaneamente |
| Output dati strutturato | Salva i risultati in CSV, JSON o direttamente su database | Analytics: invia i dati raccolti a dashboard BI o CRM |
| Logica e filtri personalizzabili | Permette di aggiungere regole, filtri o pulizia dati direttamente nel codice | Controllo qualità: salta pagine obsolete, trasforma i formati dei dati |
Ad esempio, un team marketing può usare un node crawler per raccogliere tutti i post di blog da siti di settore, estrarre titoli e URL ed esportarli su Google Sheets per la pianificazione dei contenuti.
Thunderbit: L’Alternativa No-Code ai Node Web Crawler
Ed ecco la parte interessante (e molto più divertente per chi non programma). è un’estensione Chrome con intelligenza artificiale che ti permette di estrarre dati dal web—senza scrivere una riga di codice.
Come funziona? Apri l’estensione, clicchi su “AI Suggerisci Campi” e l’AI di Thunderbit legge la pagina, suggerisce quali dati estrarre e li organizza in una tabella. Vuoi tutti i nomi e prezzi dei prodotti di un sito? Basta dirlo in italiano, e Thunderbit fa il resto. Devi estrarre dati da sottopagine o gestire la paginazione? Thunderbit lo fa con un click.
Le funzioni che preferisco di Thunderbit:
- Interfaccia in linguaggio naturale: Descrivi cosa ti serve; l’AI si occupa della parte tecnica.
- Suggerimenti AI per i campi: Thunderbit analizza la pagina e propone le colonne migliori da estrarre.
- Crawling di sottopagine senza codice: Estrai dati da pagine di dettaglio (come prodotti o profili) e unisci tutto automaticamente.
- Esportazione strutturata: Invia subito i dati su Excel, Google Sheets, Airtable o Notion.
- Esportazione dati gratuita: Nessun costo nascosto per scaricare i risultati.
- Automazione e pianificazione: Imposta estrazioni ricorrenti con orari in linguaggio naturale (“ogni lunedì alle 9”).
- Estrazione contatti: Email, numeri di telefono e immagini in un click—tutto gratis.
Per chi lavora in azienda, significa passare da “mi serve questo dato” a “ecco il mio foglio Excel” in pochi minuti, non giorni. E secondo le , anche chi non è tecnico crea liste di lead, monitora prezzi e fa ricerca—senza mai scrivere una riga di codice.
Node Web Crawler vs Thunderbit: Il Confronto per le Aziende
Quale soluzione scegliere? Ecco un confronto diretto:
| Criterio | Node.js Web Crawler (Codice Personalizzato) | Thunderbit (Estrattore Web AI No-Code) |
|---|---|---|
| Tempo di configurazione | Da ore a giorni (scrittura codice, debug, setup) | Pochi minuti (installa, clicca, estrai) |
| Competenze tecniche | Richiede programmazione (Node.js, HTML, selettori) | Nessuna programmazione; linguaggio naturale e click |
| Personalizzazione | Massima flessibilità; gestisce qualsiasi logica o flusso | Limitato alle funzioni integrate e all’AI |
| Scalabilità | Scalabilità elevata (ma serve gestire server, proxy, ecc.) | Cloud integrato per lavori da medi a grandi volumi |
| Manutenzione | Continua (aggiornare codice se i siti cambiano, fix errori) | Minima (l’AI di Thunderbit si adatta ai cambiamenti) |
| Gestione anti-bot | Serve implementare proxy, delay, browser headless, ecc. | Gestito automaticamente dal backend di Thunderbit |
| Integrazione | Integrazione profonda possibile (API, database, workflow) | Esporta su Sheets, Notion, Airtable, Excel, CSV |
| Costo | Strumenti gratuiti, ma costi di sviluppo e server | Piano gratuito, poi a consumo o abbonamento |
Quando scegliere Node.js:
- Hai bisogno di logiche molto personalizzate o integrazioni avanzate.
- Hai sviluppatori a disposizione e vuoi il massimo controllo.
- Devi estrarre dati su larga scala o creare un prodotto basato su dati web.
Quando scegliere Thunderbit:
- Vuoi risultati rapidi, senza complicazioni.
- Non sei uno sviluppatore (o non vuoi diventarlo).
- Devi estrarre dati da vari siti per attività quotidiane.
- Preferisci semplicità d’uso e adattabilità AI.
Molti team partono con Thunderbit per ottenere risultati veloci, poi passano a soluzioni Node personalizzate se le esigenze diventano più complesse o su larga scala.
Le Sfide Più Comuni con i Node Web Crawler
I node web crawler sono potenti, ma non senza ostacoli. Ecco le principali difficoltà (e come affrontarle):
- Difese anti-scraping: I siti usano CAPTCHA, blocchi IP e sistemi anti-bot. Serve ruotare proxy, randomizzare header e a volte usare browser headless come Puppeteer ().
- Contenuti dinamici: Molti siti caricano dati con JavaScript o scroll infinito. Il semplice parsing HTML non basta—potresti dover simulare la navigazione reale o usare API.
- Parsing e pulizia dati: Non tutte le pagine sono ordinate. Bisogna gestire formati incoerenti, dati mancanti e codifiche strane.
- Manutenzione: I siti cambiano. Il codice si rompe. Prevedi aggiornamenti regolari e gestione degli errori.
- Aspetti legali ed etici: Rispetta sempre
robots.txt, i termini dei siti e le leggi sulla privacy. Non estrarre dati sensibili o protetti da copyright.
Best practice:
- Usa framework come Crawlee che gestiscono molti di questi problemi in automatico.
- Implementa retry, delay e log degli errori.
- Aggiorna regolarmente i tuoi crawler.
- Fai scraping in modo responsabile—non sovraccaricare i siti e rispetta le regole.
Integrazione dei Node Web Crawler con i Servizi Cloud
Per progetti di raccolta dati seri e continuativi, far girare il crawler sul proprio PC non basta. Ecco perché conviene integrare con il cloud:
- Funzioni serverless: Puoi distribuire il tuo crawler Node come AWS Lambda o Google Cloud Function. Pianifica esecuzioni automatiche (ad esempio ogni giorno o ogni ora) e salva i risultati su storage cloud come S3 o BigQuery ().
- Crawler containerizzati: Impacchetta il crawler in Docker e fallo girare su AWS Fargate, Google Cloud Run o Kubernetes. Così puoi scalare e gestire migliaia di pagine in parallelo.
- Workflow automatizzati: Usa scheduler cloud (come AWS EventBridge) per avviare i crawler, salvare i risultati e alimentarli in dashboard di analytics o modelli di machine learning.
I vantaggi? Scalabilità, affidabilità e automazione “imposta e dimentica”. Oggi —e la percentuale è in crescita.
Quando Scegliere un Node Web Crawler o una Soluzione No-Code
Sei ancora indeciso? Ecco una checklist veloce:
-
Hai bisogno di personalizzazione avanzata, workflow unici o integrazione con sistemi interni?
→ node web crawler -
Sei un utente business che vuole dati subito, senza programmare?
→ Thunderbit (o altro strumento no-code) -
È un’attività occasionale o poco frequente?
→ Thunderbit -
È un’operazione critica, continuativa e su larga scala?
→ Node.js (con integrazione cloud) -
Hai sviluppatori e tempo per la manutenzione?
→ Node.js -
Vuoi che anche i colleghi non tecnici possano estrarre dati in autonomia?
→ Thunderbit
Il mio consiglio? Parti con una soluzione no-code per risultati rapidi e prototipi. Se le esigenze crescono, puoi sempre investire in un crawler Node personalizzato. Molti team scoprono che Thunderbit copre il 90% dei casi d’uso—risparmiando tempo e fatica.
Conclusione: Sblocca il Potenziale dei Dati Web per la Tua Azienda
 L’estrazione di dati dal web non è più solo roba da “smanettoni”—è ormai una necessità per ogni business. Che tu scelga di costruire un node web crawler o di affidarti a uno strumento AI come , l’obiettivo è sempre lo stesso: trasformare il caos del web in informazioni strutturate e utili.
L’estrazione di dati dal web non è più solo roba da “smanettoni”—è ormai una necessità per ogni business. Che tu scelga di costruire un node web crawler o di affidarti a uno strumento AI come , l’obiettivo è sempre lo stesso: trasformare il caos del web in informazioni strutturate e utili.
Node.js offre la massima flessibilità e potenza, soprattutto per progetti complessi o su larga scala. Ma per la maggior parte delle aziende, la diffusione di strumenti AI no-code permette di ottenere dati in modo rapido, affidabile e senza scrivere codice.
Visto che quasi , chi saprà padroneggiare i dati web sarà sempre un passo avanti. Che tu sia sviluppatore, marketer o semplicemente stufo di copiare e incollare, non c’è mai stato momento migliore per scoprire la potenza del web crawling.
Vuoi provarlo? gratis e scopri quanto è semplice estrarre dati dal web. E se vuoi approfondire, visita il per guide, consigli e storie dal mondo dell’automazione.
Domande Frequenti
1. Qual è la differenza tra un node web crawler e un web scraper?
Un node web crawler scopre e naviga automaticamente tra le pagine (come un ragno nella sua tela), mentre un web scraper estrae dati specifici da quelle pagine. La maggior parte dei crawler Node fa entrambe le cose: trova le pagine e raccoglie le informazioni che ti servono.
2. Perché Node.js è così usato per creare web crawler?
Node.js è event-driven e non bloccante, quindi può gestire molte richieste contemporaneamente. È veloce, ha un ecosistema di librerie vastissimo ed è perfetto per estrazioni dati in tempo reale o su grandi volumi.
3. Quali sono le principali sfide con i node web crawler?
Le difficoltà più comuni sono le difese anti-bot (CAPTCHA, blocchi IP), i contenuti dinamici (siti ricchi di JavaScript), la pulizia dei dati e la manutenzione continua quando i siti cambiano. Usare framework e best practice aiuta, ma serve competenza tecnica.
4. In cosa Thunderbit è diverso da un node web crawler?
Thunderbit è un estrattore web AI no-code. Invece di programmare, usi un’estensione Chrome e il linguaggio naturale per estrarre dati. È ideale per chi vuole risultati rapidi senza programmare.
5. Quando usare un node web crawler e quando Thunderbit?
Scegli Node.js per progetti molto personalizzati, su larga scala o con integrazioni avanzate—soprattutto se hai sviluppatori. Scegli Thunderbit per attività di scraping quotidiane, rapide o per dare autonomia anche ai colleghi non tecnici.
Vuoi migliorare la raccolta dati? Prova o scopri di più sul . Buon crawling!
Approfondisci