Ti è mai successo di trovarti su un sito dove le informazioni sono nascoste dietro una marea di link, costringendoti a cliccare ovunque per trovare quello che ti serve? È una vera seccatura, soprattutto perché sempre più portali tendono a “spezzettare” i dati importanti nelle sottopagine. Questo rende la vita difficile a chi deve raccogliere tanti dati: gli sviluppatori si ritrovano a scrivere script infiniti per esplorare ogni angolo del sito, mentre chi non programma deve cliccare manualmente su ogni link. Ma niente paura: oggi ci sono soluzioni come il list crawling (estrazione massiva) e il subpage scraping.
List Crawling e Subpage Scraping: il succo
| Strumento | Facilità d'Uso | Qualità dei Dati | Miglior Utilizzo |
|---|---|---|---|
| List Crawling | ★★ | ★★★ | Siti web di grandi dimensioni |
| Subpage Scraping | ★★★★★ | ★★★★ | Estrazioni leggere, formati dati specifici |
Cos’è il List Crawling
Definizione di List Crawling
Il list crawling, o scraping massivo, è una tecnica per estrarre dati partendo da una lista di URL. In pratica, si parte da un elenco di indirizzi web, spesso ottenuto con un altro crawler. La qualità di questa lista è fondamentale: se gli URL portano a pagine con strutture diverse, i dati raccolti saranno disomogenei e ci vorrà parecchio tempo per sistemarli. Questo metodo è perfetto per aziende, ricercatori e analisti che hanno bisogno di grandi quantità di dati strutturati e omogenei. Spesso, però, serve una bella pulizia manuale per rendere i dati davvero utilizzabili.
Come Funziona

Il list crawling di solito segue questi step:
- Preparare una Lista di URL: Si parte da un elenco di pagine da analizzare.
- Inviare Richieste HTTP: Il sistema manda richieste a questi URL per scaricare il contenuto HTML.
- Estrarre i Dati: Si usano strumenti come BeautifulSoup, XPath o regex per recuperare testi, immagini e link.
- Salvare i Dati: Tutto viene organizzato e salvato in un database o in un foglio di calcolo per analisi future.
Dopo la raccolta, è fondamentale pulire e analizzare i dati con strumenti come statistiche descrittive, analisi temporali, correlazioni e clustering. L’intelligenza artificiale può velocizzare e migliorare tutto il processo, automatizzando le operazioni e alzando la qualità dei dati.
Prova la funzione Bulk Scraping di Thunderbit Estrattore Web AI per semplificare ancora di più la raccolta.
Strumenti Consigliati
-
- Pro: Interfaccia semplice, parsing flessibile, funzioni avanzate
- Contro: Richiede uso locale e dipende dal browser
- Ideale per: Raccolta dati di alta qualità, dove la precisione è fondamentale
- Scrapy
- Pro: Potente, super personalizzabile, perfetto per scraping su larga scala
- Contro: Curva di apprendimento ripida, serve saper programmare
- Ideale per: Progetti di raccolta dati massicci
- Beautiful Soup
- Pro: Facile da usare, documentazione chiara, parsing versatile
- Contro: Prestazioni nella media, non gestisce operazioni asincrone
- Ideale per: Progetti piccoli, analisi dati
- Selenium
- Pro: Gestisce pagine dinamiche, simula l’utente
- Contro: Lento, consuma molte risorse
- Ideale per: Pagine generate da JavaScript
Scopri il Subpage Scraping

Cos’è il Subpage Scraping
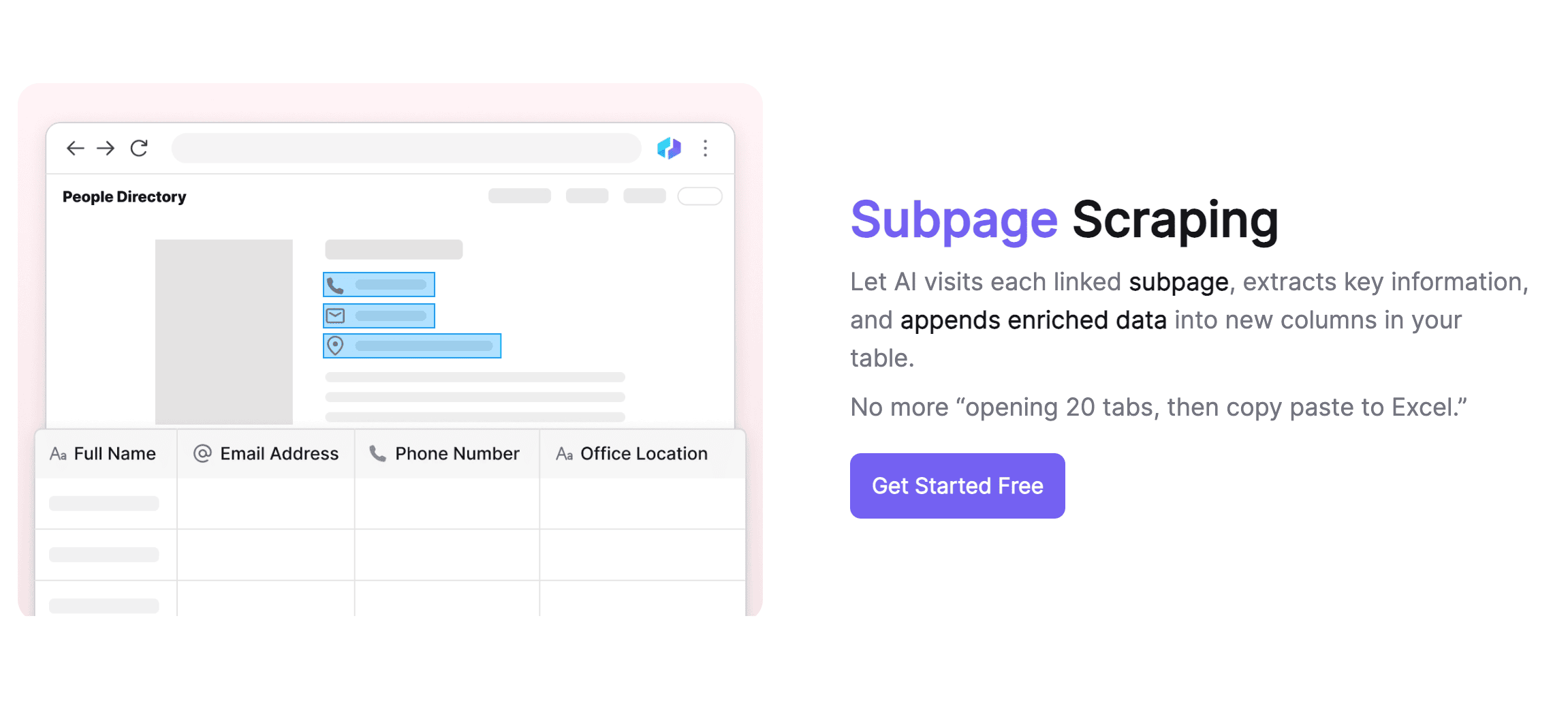
Il subpage scraping è una tecnica che permette di estrarre dati da una lista presente in una pagina web e di unire le informazioni delle sottopagine in una tabella principale. Thunderbit ha portato questa innovazione sfruttando l’AI del suo Estrattore Web AI. È la soluzione ideale per pagine con sottopagine, come schede prodotto, blog o siti di navigazione. Il vero punto di forza? Raccogliere e integrare in modo intelligente i dati delle sottopagine nella tabella principale.
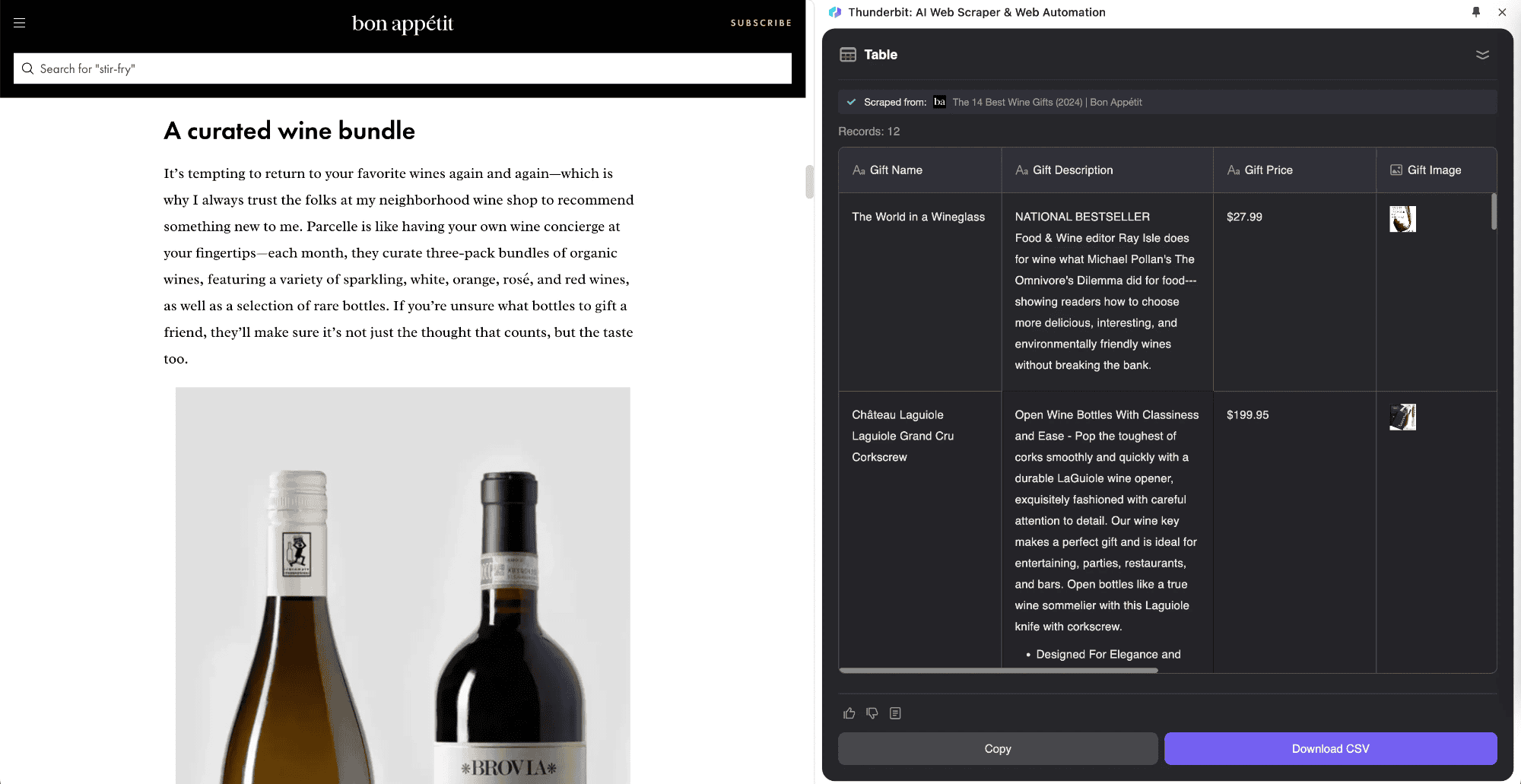
Per esempio, se stai leggendo un articolo “Borsa Oggi” e vuoi estrarre la lista delle quotazioni, puoi usare . Definisci la tua tabella e lo strumento estrarrà le quotazioni, aprirà le pagine in tempo reale e unirà i dati nella tabella principale. Così puoi registrare informazioni precise mentre navighi tra le notizie. L’Estrattore Web AI di Thunderbit si adatta a pagine diverse, cosa che gli strumenti classici non riescono a fare.
Perché Usarlo?
Thunderbit Estrattore Web AI offre funzioni che aumentano efficienza e precisione nella raccolta dati.
Estrazione Intelligente dei Dati
Thunderbit Estrattore Web AI sfrutta l’intelligenza artificiale per estrarre dati in modo intelligente, adattandosi automaticamente ai cambiamenti nella struttura delle pagine. Gli utenti possono descrivere i dati che vogliono in linguaggio naturale e il sistema genera le regole di estrazione. Questo rende la raccolta dati semplice anche per chi non è tecnico, migliorando la precisione. Thunderbit supporta testo, link, immagini e molto altro, per ogni esigenza.
Gestione Avanzata delle Sottopagine
Thunderbit è fortissimo nella gestione delle sottopagine. Riconosce e accede in modo intelligente alle sottopagine, usando un solo template per gestire layout diversi. L’AI si adatta ai cambiamenti strutturali delle pagine, così non devi preoccuparti di estrarre dati da sottopagine diverse. Thunderbit unisce automaticamente i contenuti delle sottopagine nella tabella principale, aiutandoti a organizzare meglio le informazioni. Inoltre, si distingue per la qualità dei dati, agendo come un assistente AI che pulisce e formatta i dati, svolgendo compiti ripetitivi come l’etichettatura.
Gestione Efficiente dei Dati
Thunderbit offre strumenti avanzati per la gestione dei dati, supportando diversi formati di esportazione e integrazioni con piattaforme come Google Sheets, Airtable e Notion. Puoi collegare un template di scraping a un foglio Google per avere tutti i dati raccolti in un unico posto, oppure integrarli nel Database di Notion. Queste opzioni flessibili ti permettono di scegliere il metodo di archiviazione più adatto. L’etichettatura e la classificazione dei dati si adattano automaticamente ai formati delle piattaforme di gestione, rendendo più efficiente la fase successiva di organizzazione.
Template Pratici Preimpostati
Per lavorare più velocemente, Thunderbit mette a disposizione tanti template già pronti. Coprono la raccolta dati e-commerce (come , ), estrazione di informazioni immobiliari (come ), analisi social (come , ), e raccolta di dati aziendali (siti web aziendali, elenchi business). Questi template fanno risparmiare tempo e garantiscono coerenza e precisione nella raccolta dati.
Guida Passo Passo
Come Implementare il Subpage Scraping
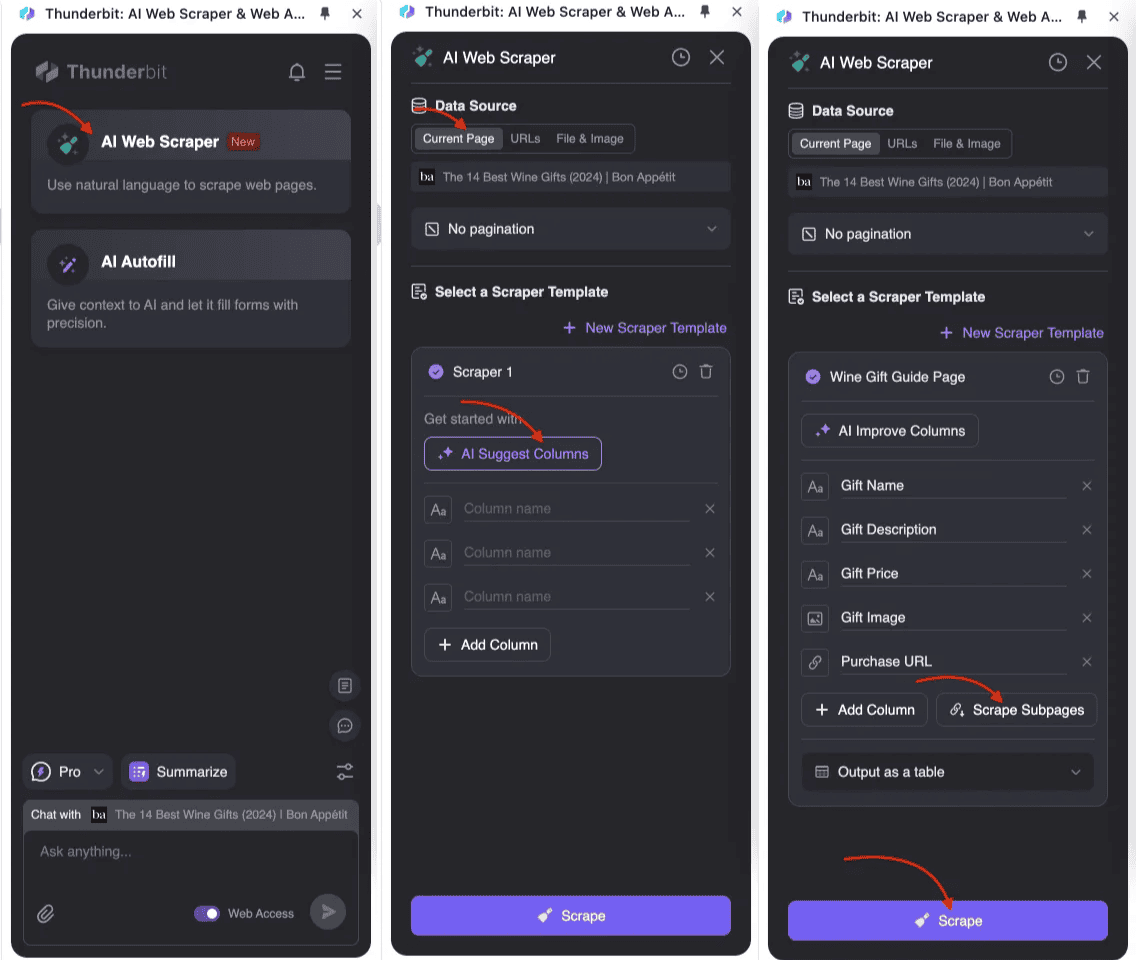
- : Apri Thunderbit Estrattore Web AI e crea un nuovo template di scraping.
- Definisci la Struttura della Tabella Principale: Nelle impostazioni della tabella, aggiungi i campi che vuoi raccogliere, come titolo, prezzo e descrizione. Per i dati delle sottopagine, crea i campi corrispondenti e abilita il subpage scraping.
- Avvia lo Scraper: Thunderbit estrarrà prima i dati dalla pagina principale, poi visiterà automaticamente ogni sottopagina, raccoglierà le informazioni e le unirà nella tabella principale. Tutto il processo è guidato dall’AI, senza bisogno di scrivere codice complicato.
Come Implementare il List Crawling
Per chi sviluppa, ci sono diversi linguaggi e strumenti per fare list crawling. Python è il più gettonato per la sua semplicità e le tante librerie disponibili. Ecco un esempio base in Python che usa requests e BeautifulSoup per estrarre dati:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Esempio di utilizzo
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Conclusioni
Oggi i dati sono il vero motore delle aziende. Chi sa raccogliere e analizzare informazioni in modo efficace ha una marcia in più. I dati aiutano le imprese a capire il mercato e i bisogni dei clienti, offrendo spunti preziosi per sviluppare prodotti e strategie di marketing. Ma raccogliere e organizzare in modo efficiente la mole di dati sparsi online è una bella sfida.
Con strumenti come Thunderbit, le aziende non devono più preoccuparsi della raccolta dati. È come avere un assistente fidato che trova per te le informazioni più utili tra montagne di dati, aiutandoti a prendere decisioni più sicure. Grazie alle sue capacità di raccolta e analisi intelligente, puoi accedere facilmente a dati su concorrenti, tendenze di mercato, recensioni utenti e molto altro, per scelte di business più informate.
Thunderbit non solo semplifica la raccolta, ma offre anche strumenti potenti per elaborare e analizzare i dati. Può pulire e strutturare automaticamente le informazioni raccolte, generando report intuitivi che aiutano a scoprire subito dettagli nascosti. Per chi deve monitorare costantemente il mercato, la funzione di raccolta automatica di Thunderbit è una soluzione efficiente e che fa risparmiare tempo.
In un’epoca dove i dati fanno la differenza, avere uno strumento come Thunderbit è un vero asso nella manica. Migliora l’efficienza nella raccolta dati e supporta la trasformazione digitale delle aziende. Con l’importanza crescente dei dati nelle decisioni aziendali, strumenti intelligenti come Thunderbit diventeranno indispensabili per restare competitivi.
Domande Frequenti
-
Cos’è Thunderbit? è un’estensione Chrome pensata per aiutare le aziende ad automatizzare le attività web. Offre funzioni come Estrattore Web AI, AI Clipboard e AI Web Chat per estrarre dati, compilare moduli e grazie all’AI. È uno strumento di produttività che fa risparmiare tempo e semplifica le attività ripetitive online.
-
Come funziona l’Estrattore Web AI di Thunderbit? L’Estrattore Web AI di Thunderbit usa l’intelligenza artificiale per estrarre dati strutturati dai siti. Gli utenti possono cliccare su "AI Suggerisci Colonne" per lasciare che l’AI proponga come estrarre i dati dal sito corrente, poi cliccare su "Estrai" per raccogliere le informazioni. Può gestire dati da qualsiasi sito, PDF o immagine in pochi click.
-
Qual è la differenza tra list crawling e subpage scraping? Il list crawling, o scraping massivo, consiste nell’estrarre dati da una lista di URL, ideale per siti di grandi dimensioni. Il subpage scraping invece estrae dati da una pagina e dalle sue sottopagine, unendo tutto in una tabella principale. L’Estrattore Web AI di Thunderbit è efficace in entrambi i metodi, offrendo estrazione e gestione dati intelligenti.
-
Thunderbit è adatto anche a chi non sa programmare? Assolutamente sì! Thunderbit è pensato per essere semplice anche per chi non ha competenze tecniche. Grazie alle funzioni AI, basta descrivere i dati che vuoi in linguaggio naturale e il sistema genera le regole di estrazione, rendendo la raccolta dati accessibile a tutti.
-
Che tipi di dati può gestire Thunderbit? Thunderbit supporta diversi tipi di dati, tra cui testo, link e immagini. È perfetto per raccolta dati e-commerce, informazioni immobiliari, analisi social e raccolta dati aziendali.
-
Come posso iniziare a usare Thunderbit? Per iniziare, scarica l’estensione Chrome di Thunderbit dalla . Una volta installata, puoi esplorare funzioni come Estrattore Web AI, AI Clipboard e AI Web Chat per aumentare la tua produttività online.
-
Thunderbit offre template preimpostati? Sì, Thunderbit mette a disposizione tanti per lavorare più velocemente. Coprono e-commerce, immobiliare, social media e raccolta dati aziendali, aiutando a risparmiare tempo e garantire coerenza e precisione.
-
Come garantisce Thunderbit la qualità dei dati? Thunderbit usa l’AI per estrarre e processare i dati in modo intelligente, adattandosi automaticamente ai cambiamenti delle pagine. Offre anche strumenti per la pulizia e la formattazione, agendo come un assistente AI che automatizza i compiti ripetitivi e migliora la qualità dei dati.
-
Esempi di utilizzo dell’Estrattore Web Gli hanno tantissime applicazioni pratiche. Ad esempio, puoi per ricerche di mercato, oppure per analisi documentali. Molte aziende hanno bisogno di per analisi. Con strumenti AI, ora puoi senza scrivere codice complicato. Per l’analisi social, puoi usare strumenti specifici come o per raccogliere dati utili alle tue campagne marketing.
Scopri di più: