

C’era un tempo in cui per portarsi a casa quello che serviva da un sito bastava un “tasto destro, salva con nome”. Quei giorni sono finiti da un pezzo. Oggi il web è insieme una giungla e una miniera: contenuti che si aggiornano al volo, link che si nascondono, pop-up che spuntano da ogni angolo, menu su più livelli. Chi ha provato a tirare fuori tutte le schede prodotto da un e-commerce moderno, o a recuperare ogni singolo annuncio da un portale immobiliare, lo sa già—gli estrattori web di una volta non bastano più. È esattamente il vuoto che riempiono i deep crawler: strumenti di nuova generazione capaci di scendere in profondità, frugare in ogni anfratto e restituirti solo le informazioni che contano davvero.
Ma cosa sono, nel concreto, i deep crawler? Perché stanno conquistando aziende di ogni settore, dalle vendite al marketing? E come fa uno strumento come Thunderbit a rendere il deep crawling un gioco da ragazzi, anche per chi non ha mai scritto una riga di codice? Andiamo con ordine: basi, impatto sul business e il motivo per cui i deep crawler sono diventati l’asso nella manica di chi vuole spremere davvero i dati online.
Cos'è un Deep Crawler? Le Basi da Sapere
Estrai dati da qualsiasi sito con l’AI Get Started Free
In due parole, un deep crawler è un estrattore web specializzato, costruito per muoversi dentro siti complessi—stratificati, ricchi di contenuti che si caricano in modo dinamico. A differenza dei crawler tradizionali, che si accontentano di ciò che trovano sulla pagina principale, un deep crawler segue i link, si infila tra menu e sottosezioni, gestisce le pagine che si aggiornano e recupera persino i dati nascosti dietro tab o sezioni che si aprono solo dopo un click.
Immagina un crawler classico come chi entra in biblioteca e legge soltanto i titoli sugli scaffali vicino alla porta. Un deep crawler, invece, è quello che si addentra tra i corridoi, sfoglia ogni volume, legge le note a piè di pagina e magari dà pure un’occhiata oltre la porta con scritto “Solo personale” (se non è chiusa a chiave, s’intende).
Nel mondo dell’estrazione dati, in concreto un deep crawler sa:
- Muoversi tra più livelli di un sito (categorie, sottocategorie, pagine di dettaglio)
- Estrarre contenuti dinamici caricati via JavaScript o nascosti dietro le azioni dell’utente
- Gestire paginazioni complesse e scroll infiniti
- Seguire i link interni per non lasciarsi sfuggire nulla di importante
 Con il volume dei dati web arrivato a 149 zettabyte nel 2024 e siti che si fanno più intricati di giorno in giorno, i deep crawler sono ormai indispensabili per chi vuole spingersi oltre la superficie.
Con il volume dei dati web arrivato a 149 zettabyte nel 2024 e siti che si fanno più intricati di giorno in giorno, i deep crawler sono ormai indispensabili per chi vuole spingersi oltre la superficie.
Deep Crawler vs. Crawler Tradizionale: Le Differenze Che Contano
Andiamo al sodo: cosa distingue davvero un deep crawler dai crawler “normali” di cui forse hai già sentito parlare?
Crawler Tradizionali: Solo la Superficie
I crawler tradizionali (i cosiddetti “shallow crawler”) puntano tutto su velocità e quantità. Vanno benissimo per scansionare in fretta un sito, raccogliere ciò che sta sulle pagine principali e tirare dritto. È lo stesso approccio dei motori di ricerca: indicizzare il maggior numero di pagine nel minor tempo possibile, senza scavare in ogni sezione.
Dove si fermano i crawler tradizionali:
- Saltano spesso i dati nascosti dietro menu, tab o elementi dinamici
- Vanno in difficoltà con i siti pieni di JavaScript o con i contenuti che si caricano dopo l’apertura della pagina
- Non reggono le navigazioni a più passaggi né le strutture complicate
- Rischiano di restituirti dataset incompleti o a pezzi
Deep Crawler: Oltre la Superficie
Il deep crawler, al contrario, nasce per scavare: segue ogni link utile, attraversa le liste paginate, raccoglie dati da sottopagine, pop-up e contenuti che compaiono solo dopo un’interazione. Qui non conta la velocità, ma la completezza e la precisione.
Le carte vincenti dei deep crawler:
- Navigazione avanzata: seguono i link in modo ricorsivo, gestiscono strutture su più livelli ed evitano pagine duplicate o vicoli ciechi (SEO-Wiki).
- Estrazione di contenuti dinamici: interagiscono con il JavaScript, espandono le sezioni nascoste ed estraggono dati che appaiono solo dopo un’azione dell’utente (Scientific Reports).
- Più efficienza: si concentrano sulle aree che contano, riducono i doppioni e i dati inutili e si assicurano che nulla di importante vada perduto (Medium).
- Completezza: raccolgono tutto in un colpo solo—dalle liste principali alle pagine di dettaglio fino ai documenti collegati.
Se hai mai provato a estrarre tutte le recensioni di una scheda prodotto, o a mettere insieme ogni annuncio di un portale immobiliare (dati dell’agente nascosti in sottopagina compresi), avrai sbattuto la testa contro i limiti dei crawler classici. È esattamente lì che i deep crawler cambiano le carte in tavola.
Come i Deep Crawler Raggiungono la Completezza dei Dati e una Navigazione Avanzata
Ma come ci riescono, in pratica? Tutto ruota attorno a tre mosse: seguire i link, navigare in modo ricorsivo e gestire i contenuti dinamici.
Estrazione da Sottopagine e Navigazione Multi-Livello
Un deep crawler non si ferma alla prima schermata. Ecco la sua routine:
- Individua i link interni (i vari “Vedi dettagli”, “Pagina successiva”, “Mostra altro”)
- Li segue verso sottopagine, viste di dettaglio o perfino pop-up
- Estrae i dati da ogni livello, fondendo tutto in un unico dataset ordinato
Questo metodo—detto anche “crawling ricorsivo” o “estrazione multi-livello”—è perfetto per i siti dove le informazioni sono sparpagliate su più pagine: annunci con dettagli su pagine separate, directory in cui i contatti compaiono solo dopo un click.
Gestione di Paginazione e Contenuti Dinamici
I siti moderni amano nascondere i dati dietro pulsanti “Carica altro”, scroll infiniti o tab gestiti via JavaScript. I deep crawler sono fatti apposta per:
- Riconoscere i controlli di paginazione e interagirci
- Scorrere o cliccare gli elementi dinamici
- Aspettare che i contenuti si carichino prima di estrarre
Così porti a casa un dataset completo, non solo quel che si vedeva al primo caricamento della pagina (Thunderbit Blog).
Tracciamento dei Link e Estrazione Multi-Livello
Una delle parti più delicate del deep crawling è non lasciarsi sfuggire i dati nascosti o annidati. Per riuscirci, i deep crawler usano algoritmi che:
- Tengono traccia dei link già visitati (niente doppioni né giri a vuoto)
- Danno la precedenza alle pagine importanti (viste di dettaglio, documenti scaricabili)
- Gestiscono i casi spinosi (pop-up, sezioni espandibili, contenuti caricati via AJAX)
In ambito business è cruciale: perdere anche solo un contatto o una specifica di prodotto può voler dire un’occasione mancata o un’analisi a metà (Simplescraper).
Thunderbit: Deep Crawling Semplificato con l’AI
Fino a poco fa il deep crawling era roba per sviluppatori e data engineer. Bisognava scrivere script su misura, gestire ogni caso limite e rimettere mano al codice ogni volta che un sito cambiava aspetto. Con Thunderbit la musica cambia: il deep crawling diventa accessibile a tutti—anche a chi non ha mai programmato.
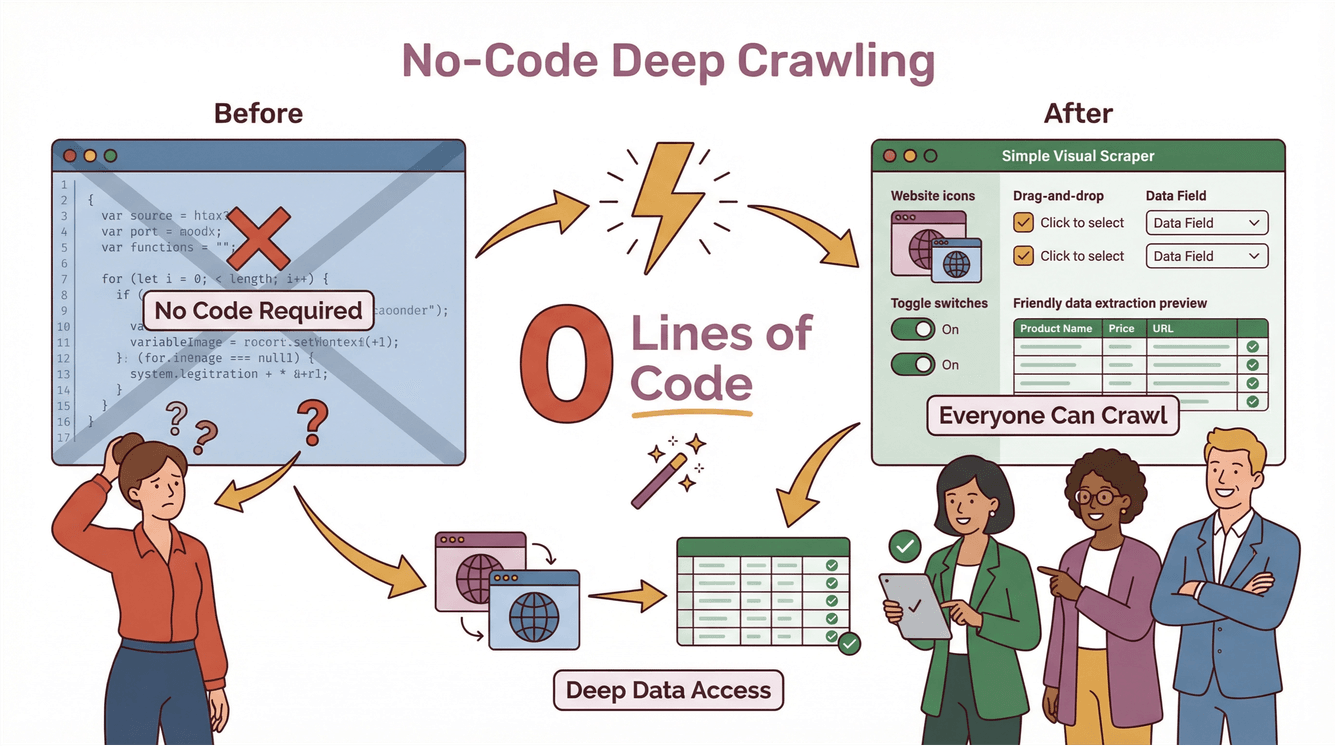
Le Funzionalità Deep Crawler di Thunderbit in Pratica
Ecco come Thunderbit rende il deep crawling alla portata di chiunque:
- AI Suggerisci Campi: un click su “AI Suggerisci Campi” e l’AI di Thunderbit analizza la pagina, propone le colonne migliori da estrarre e prepara i prompt per ciascun campo.
- Estrazione da Sottopagine: vuoi più dettagli? Thunderbit visita in automatico ogni sottopagina (schede prodotto, profili agente, tab recensioni) e arricchisce la tua tabella con i dati extra.
- Contenuti Dinamici sotto controllo: Thunderbit dialoga con paginazione, scroll infiniti ed elementi dinamici—senza che tu debba toccare nulla a mano.
- No-Code, Due Passaggi: descrivi cosa ti serve, clicca su “Estrai” e al resto pensa Thunderbit. Esporti i dati direttamente su Excel, Google Sheets, Notion o Airtable—senza costi extra né limiti (Thunderbit Blog).
Prova gratis Deep Crawler di Thunderbit
Esempio Pratico: Deep Crawling con Thunderbit
Poniamo che tu voglia raccogliere tutti gli annunci immobiliari di un sito, contatti degli agenti inclusi—quelli nascosti nelle sottopagine:
- Apri la pagina degli annunci su Chrome.
- Clicca sull’estensione Thunderbit.
- Usa “AI Suggerisci Campi” per far proporre a Thunderbit colonne come “Titolo annuncio”, “Prezzo”, “Indirizzo” e “Link agente”.
- Clicca su “Estrai”. Thunderbit raccoglie tutti gli annunci principali.
- Clicca su “Estrai Sottopagine”. Thunderbit entra in ogni profilo agente, recupera numeri di telefono, email e altro, e fonde tutto nella tabella principale.
- Esporta su Google Sheets o Excel—pronti per il team commerciale o operativo.
Niente codice, niente template, niente mal di testa. E se il sito cambia, l’AI di Thunderbit si riadatta da sola (Thunderbit Docs).
Vantaggi per il Business: Come i Deep Crawler Cambiano le Regole per Vendite e Marketing
Bene, i deep crawler sono affascinanti—ma che ritorno concreto portano al business? Vediamo dove fanno la differenza.
Scopri Nuove Opportunità su E-commerce, Immobiliare e Siti Competitor
Per chi lavora in vendite e marketing, i deep crawler sono una vera miniera d’oro. Ti permettono di:
- Estrarre ogni prodotto, prezzo e recensione dai siti e-commerce—anche quando i dati stanno dietro più livelli o tab
- Aggregare annunci immobiliari (dettagli e contatti degli agenti nascosti compresi)
- Sorvegliare i siti dei competitor per nuovi prodotti, variazioni di prezzo o tendenze di mercato (GetMonetizely)
- Costruire liste di lead più ricche raccogliendo contatti da directory, eventi o portali di nicchia
Con il deep crawling non porti a casa solo più dati—porti a casa dati migliori e più utili per orientare davvero le tue strategie.
Deep Scraping per l’Intelligence Competitiva
Supponi che il tuo team commerciale voglia puntare sulle aziende che hanno appena lanciato un prodotto nuovo. Un deep crawler può:
- Setacciare i siti dei competitor a caccia di nuove pagine prodotto
- Seguire i link verso comunicati stampa o aggiornamenti per gli investitori
- Estrarre i dettagli chiave (date di lancio, prezzi, caratteristiche)
- Importare il tutto nel tuo CRM o nei tuoi strumenti di analisi
Il risultato? Decisioni più rapide e più informate—e un vantaggio reale su chi si ferma alla raccolta di superficie.
Compliance e Best Practice: Cosa Tenere a Mente Quando Usi un Deep Crawler
Da grandi capacità di crawling derivano grandi responsabilità. Un deep crawler può raggiungere una quantità enorme di dati—ma non significa che sia sempre lecito raccoglierli tutti. Ecco i punti da non perdere di vista:
Privacy dei Dati e Copyright
- Rispetta i termini di servizio: molti siti indicano nei TOS cosa è consentito. Ignorarli può aprire grane legali (Apify Blog).
- Niente dati personali o riservati senza un’autorizzazione esplicita.
- Occhio al copyright: non ripubblicare né rivendere contenuti estratti prima di aver verificato i diritti.
Crawling Responsabile
- Modera le richieste: non sommergere i siti di richieste tutte in una volta.
- Dai un’occhiata al robots.txt: non è legge, ma è buona educazione rispettare le preferenze di crawling del sito.
- Stai al passo con le normative: regole come GDPR e CCPA possono incidere su quali dati puoi raccogliere e su come li usi (Octoparse).
Per andare più a fondo, leggi È legale il web scraping nel 2025?.
Come Scegliere il Deep Crawler Giusto per la Tua Azienda
Scopri i prezzi di Thunderbit Deep crawling accessibile per team di ogni dimensione. Get Started Free
Come si individua il deep crawler più adatto? Ecco ciò che fa davvero la differenza:
- Facilità d’uso: anche chi non è tecnico riesce a configurarlo in pochi minuti? (Thunderbit: sì.)
- Scalabilità: regge siti grandi, tante pagine e contenuti dinamici?
- Strumenti per la compliance: ti aiuta a restare in regola con le normative?
- Integrazione: puoi esportare i dati nei tool che già usi (Excel, Sheets, Notion, Airtable)?
- Manutenzione: si adatta da solo ai cambiamenti dei siti o dovrai sistemare gli script ogni settimana?
Thunderbit è nato esattamente con questi criteri in testa. Ci si affidano oltre 30.000 utenti in tutto il mondo, dai freelance alle grandi aziende, con prezzi accessibili anche alle piccole imprese: si parte da appena 15$/mese.
Inizia il deep crawling con Thunderbit
In Sintesi: Il Futuro del Deep Crawling nella Strategia Dati Aziendale
I punti da portarsi a casa:
- I deep crawler sono indispensabili per estrarre dati completi e precisi dai siti moderni, sempre più complessi e dinamici.
- Vanno oltre i crawler tradizionali, gestendo navigazione multi-livello, contenuti dinamici e dati nascosti.
- I team aziendali li usano per ottenere insight, far crescere le vendite, sorvegliare i competitor e decidere più in fretta.
- La compliance è centrale: estrai con responsabilità, rispetta privacy e regole.
- Thunderbit rende il deep crawling alla portata di tutti, tra funzionalità AI, interfaccia no-code ed export dei dati senza limiti.
Se vuoi superare la raccolta di superficie e iniziare a scavare per davvero, scarica l’estensione Chrome di Thunderbit e scopri quanto può essere semplice il deep crawling. Per altri spunti, passa dal Blog di Thunderbit: guide, best practice e tutte le novità sull’estrazione dati con l’AI.
Domande Frequenti
1. Cos’è un deep crawler e in cosa si differenzia da un normale estrattore web?
Un deep crawler è uno strumento di estrazione pensato per muoversi tra più livelli di un sito, recuperando informazioni da sottopagine, contenuti dinamici e sezioni nascoste. A differenza dei crawler tradizionali, che si fermano in superficie, garantisce una raccolta completa seguendo i link e gestendo strutture complesse.
2. Perché le aziende hanno bisogno dei deep crawler nel 2025?
I siti sono sempre più intricati e i dati si annidano dietro menu, tab o elementi dinamici. I deep crawler permettono di estrarre dataset completi per vendite, marketing, ricerca e analisi competitiva—cosa che i crawler di base non riescono a fare.
3. Come Thunderbit semplifica il deep crawling per chi non è tecnico?
Thunderbit usa l’AI per suggerire i campi, gestire l’estrazione da sottopagine e i contenuti dinamici—tutto da un’interfaccia semplice e senza codice. Basta descrivere ciò che serve, cliccare su “Estrai” ed esportare i risultati nei propri strumenti preferiti.
4. Quali aspetti di compliance devo considerare usando un deep crawler?
Rispetta sempre i termini di servizio dei siti, evita di estrarre dati personali o riservati senza permesso e tieniti aggiornato sulle normative privacy come GDPR e CCPA. Un uso responsabile dei dati è la chiave per ridurre i rischi legali.
5. I deep crawler possono aiutare il mio team commerciale e marketing a ottenere risultati migliori?
Senza dubbio. Permettono di accedere a dati più ricchi e utili da e-commerce, portali immobiliari e siti dei competitor—alimentando lead generation, analisi di mercato e decisioni più rapide. Con strumenti come Thunderbit, perfino i team non tecnici ottengono gli insight che servono per crescere.
Prova Deep Crawler AI con Thunderbit Get Started Free
Scopri di più




