Oggi tutti parlano di decisioni basate sui dati, ma spesso ci si dimentica di quanto sia lungo e snervante raccogliere dati a mano. Se ti è mai capitato di dover fare data scraping manualmente, sai bene quanto possa essere una seccatura. Ho visto tante aziende arrancare nel mettere in pratica strategie data-driven proprio perché la raccolta dati è lenta e poco efficiente. Se ti ritrovi in questa situazione, qui troverai soluzioni innovative che possono davvero fare la differenza.
💡 In questo articolo ti porto nel mondo del data scraping e ti mostro come le nuove tecnologie stanno rivoluzionando il settore. Vedremo insieme i limiti dei vecchi metodi, i vantaggi dell’estrazione dati con l’AI e ti darò consigli pratici per applicarla davvero nel tuo lavoro.
Cos'è il Data Scraping?
Il data scraping, o estrazione dati tramite estrattore web, consiste nel recuperare informazioni strutturate da pagine web usando strumenti dedicati (spesso organizzando tutto in tabelle). È il modo più veloce per raccogliere grandi quantità di dati. Ad esempio, puoi estrarre dati pubblici da Google Maps per generare lead, recuperare codici prodotto da Amazon per analisi di mercato o rivendita, oppure raccogliere recensioni da Yelp per capire meglio i tuoi clienti.
L’Evoluzione Tecnologica del Data Scraping
Fino a pochi anni fa, raccogliere dati sembrava roba da smanettoni o richiedeva ore e ore di copia-incolla. Ma ora siamo nel 2025 e l’AI ha cambiato le carte in tavola. Il data scraping non è più solo per programmatori o per chi si arrangia con automazioni basilari.
I Metodi Tradizionali Non Bastano Più
I siti web di oggi sono sempre più complessi: contenuti che si caricano in modo dinamico (con React o Vue), dati di ogni tipo (testi, video, immagini) e strutture che cambiano spesso (più template nella stessa pagina). Gli studi più recenti mettono in luce tre grossi problemi dei metodi tradizionali di estrazione dati:
-
Costi di Manutenzione Alti I vecchi estrattori web vanno aggiornati a mano di continuo (in media 3-5 ore al mese per ogni sito). Appena un sito cambia framework, il 60% dei selettori XPath smette di funzionare. Gli strumenti AI, grazie ai modelli linguistici e all’intelligenza del codice, si adattano da soli al 90% dei cambiamenti strutturali, tagliando i costi di manutenzione del 60-80%. Sui siti moderni fatti con React/Vue, gli strumenti AI mantengono stabile l’estrazione dati grazie alla comprensione semantica, anche se cambiano i nomi delle classi.
-
Dati Limitati I metodi classici estraggono solo dati strutturati, perdendo informazioni preziose come:
- Dati nascosti nelle immagini
- Testi all’interno di articoli
- Dati non strutturati senza tag HTML
-
Problemi di Qualità dei Dati I metodi tradizionali fanno fatica con i contenuti dinamici, portando a dati incompleti o sbagliati:
- Nelle liste paginati (tipo prodotti e-commerce), gli scraper classici catturano solo il 30-50% dei dati visibili.
- Sulle pagine a scorrimento infinito (come i feed social), si perde oltre il 60% dei dati utili.
- Alti tassi di errore nell’allineamento di dati non strutturati (liste disallineate).
Qui entrano in gioco strumenti AI come Thunderbit. Vediamo perché sono così utili.
L’Ascesa del Data Scraping con l’AI
Nel 2025, l’AI – soprattutto i Large Language Model (LLM) – ha raggiunto livelli incredibili. Questi modelli capiscono e generano linguaggio naturale, gestiscono analisi dati complesse e offrono soluzioni molto più efficienti. Oggi tanti strumenti di data scraping sfruttano i LLM per superare i limiti dei vecchi metodi. Dopo aver provato 13 strumenti di data scraping negli ultimi mesi, ti consiglio Thunderbit Estrattore Web AI.
Ecco perché Thunderbit fa la differenza:
-
Interazione Semplice e Potente: Puoi scrivere comandi in italiano semplice e il sistema crea da solo il piano di scraping, riducendo i tempi di configurazione dell’87% rispetto agli strumenti classici.
-
Vantaggi dell’Estensione Chrome per Data Scraping: Come estensione browser, Thunderbit ti offre:
- Estrazione dati immediata
- Supporto per pagine dinamiche e a scorrimento infinito
- Estrazione anche da pagine che richiedono login
-
Gestione Avanzata di Dati Multimodali: Thunderbit gestisce diversi tipi di dati, come:
- Estrazione di testi da articoli
- Estrazione di tabelle finanziarie da PDF
- Riconoscimento di dati da più immagini e creazione di tabelle
- Estrazione e sintesi di sottotitoli da video
Con Thunderbit puoi affrontare qualsiasi scenario di raccolta dati. Ecco come funziona.
Come Fare Data Scraping con l’AI
Segui questi quattro step per sfruttare al massimo le funzioni di estrattore web AI di Thunderbit:
-
Installa l’Estensione Chrome Vai sul sito Thunderbit e scarica l’estensione dal Chrome Web Store. Una volta installata, fissala sulla barra degli strumenti del browser.
-
Registrati e Ottieni Crediti Gratuiti Registrati tramite l’estensione per ricevere crediti di prova. Potrai così testare le funzioni principali come estrattore web AI, compilazione automatica dei moduli e sintesi intelligente. Ti consiglio di provare prima la modalità playground gratuita per vedere quanto è efficace.
-
Avvia lo Smart Scraping Scegli un template dalla sidebar di Thunderbit. Usa descrizioni in italiano naturale per selezionare i dati e il formato che vuoi, imposta le tue preferenze e avvia l’estrazione con un click.
Funzionalità Avanzate di Scraping (Pro Tier)
Abbonandoti al Pro Tier di Thunderbit (o attivando la prova gratuita), sblocchi queste funzioni:

-
Gestione Dati Multimodali Affronta scenari complessi come estrazione da PDF (bilanci, manuali), estrazione dati da immagini (etichette prezzi, schede tecniche) e scraping di sottotitoli video. Il sistema standardizza automaticamente i dati non strutturati.
-
Scraping Profondo delle Sottopagine Puoi accedere a tutti i sottolink di una pagina (come pagine prodotto o recensioni utenti), riconoscere i dati collegati e unirli automaticamente nella tabella principale. Perfetto per cataloghi e-commerce, annunci immobiliari e molto altro.
-
Libreria di Template Pronti Usa subito template ottimizzati per oltre 30 piattaforme come LinkedIn, Amazon e Zillow, che si adattano automaticamente ai cambiamenti delle pagine. I nuovi utenti risparmiano in media l’83% del tempo di configurazione.
-
Scraping in Blocco Avvia più attività di scraping insieme, importando elenchi di URL per l’estrazione dati in batch.
-
Gestione Intelligente della Paginazione Riconosce e gestisce automaticamente contenuti paginati (inclusi pulsanti "carica altro" e navigazione tra pagine), supportando anche lo scrolling infinito. Testato per estrarre oltre 200 pagine di prodotti e-commerce.
Guida Pratica a Thunderbit
Scenario 1: Raccolta Dati Immobiliari
Se lavori nel settore immobiliare e vuoi raccogliere dati da Zillow, o sei un investitore a caccia di occasioni, un estrattore web affidabile è il tuo asso nella manica. L’estrattore web AI di Thunderbit ti permette di estrarre tutte le informazioni chiave sugli immobili da Zillow, così resti sempre aggiornato e competitivo. Guarda il video tutorial su come estrarre dati da Zillow con Thunderbit.
Scenario 2: Ricerca Talenti e Clienti
Se lavori nelle risorse umane o nelle vendite e cerchi nuovi contatti, un estrattore web affidabile può cambiarti la vita. Thunderbit ti permette di estrarre facilmente dati importanti da LinkedIn, semplificando la ricerca di talenti e la gestione dei lead. Dopo averlo provato, dimenticherai le ricerche manuali e il copia-incolla. Ecco un tutorial su come estrarre dati da LinkedIn con Thunderbit.
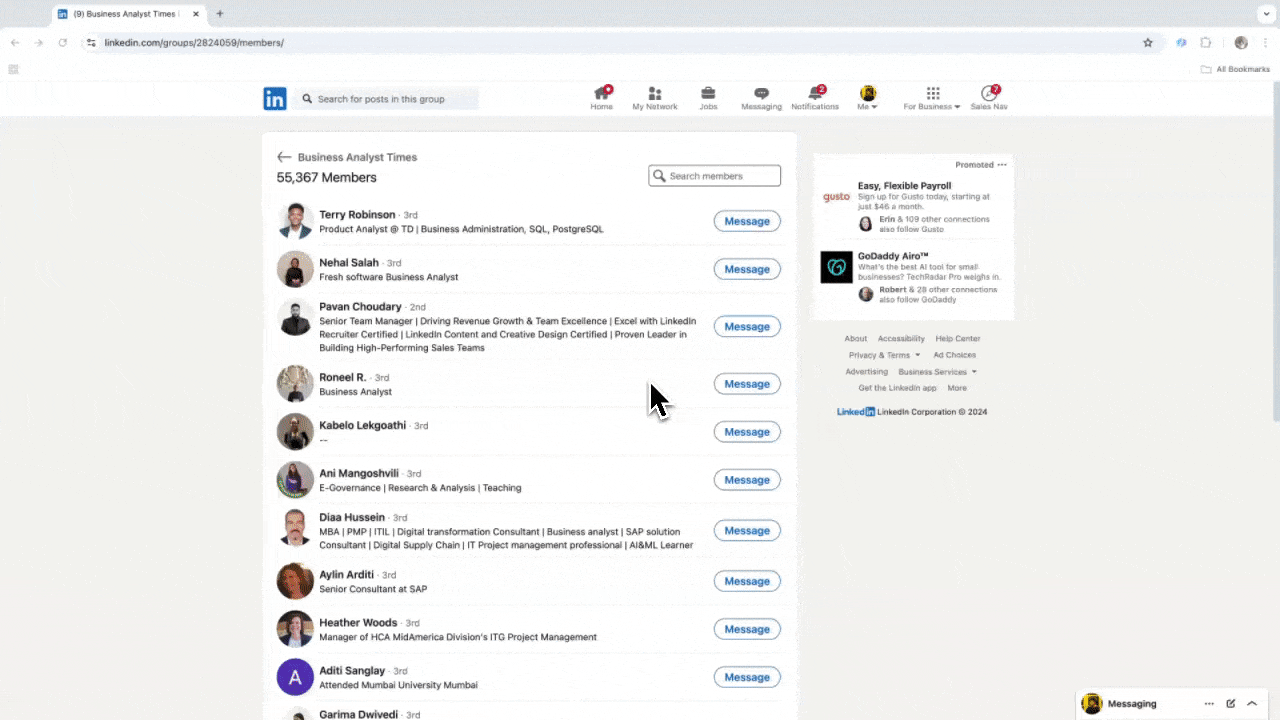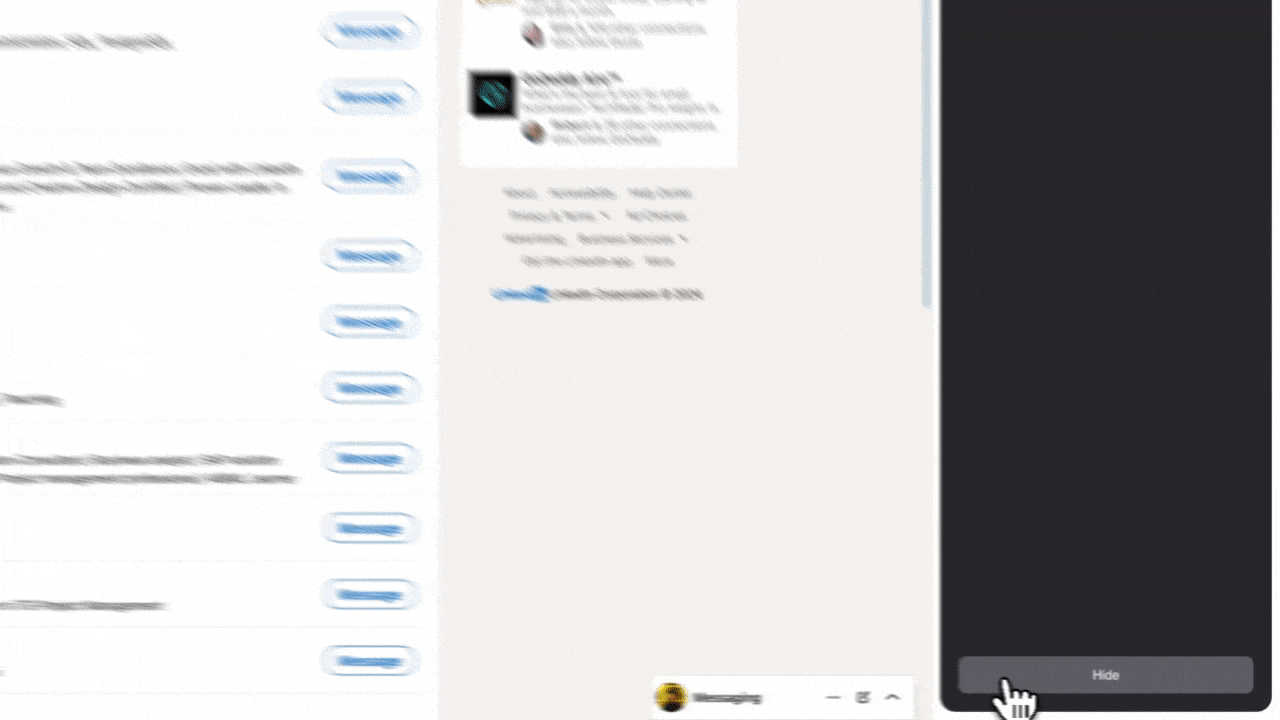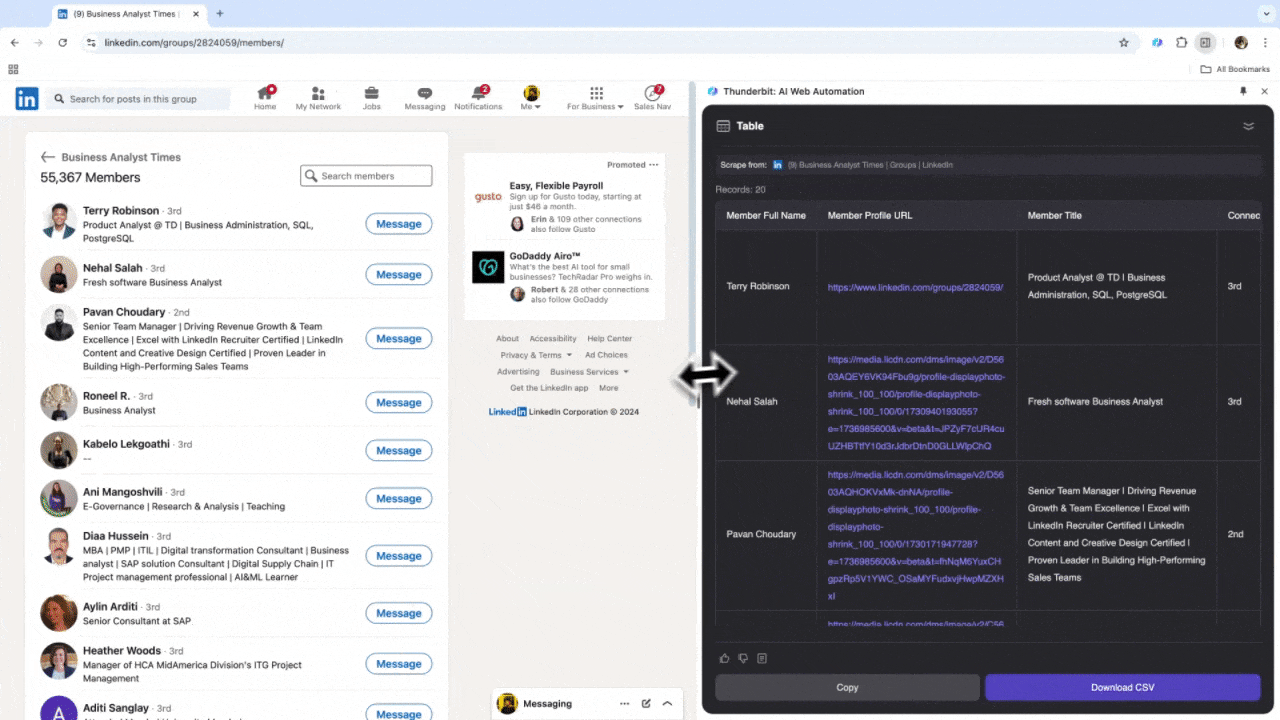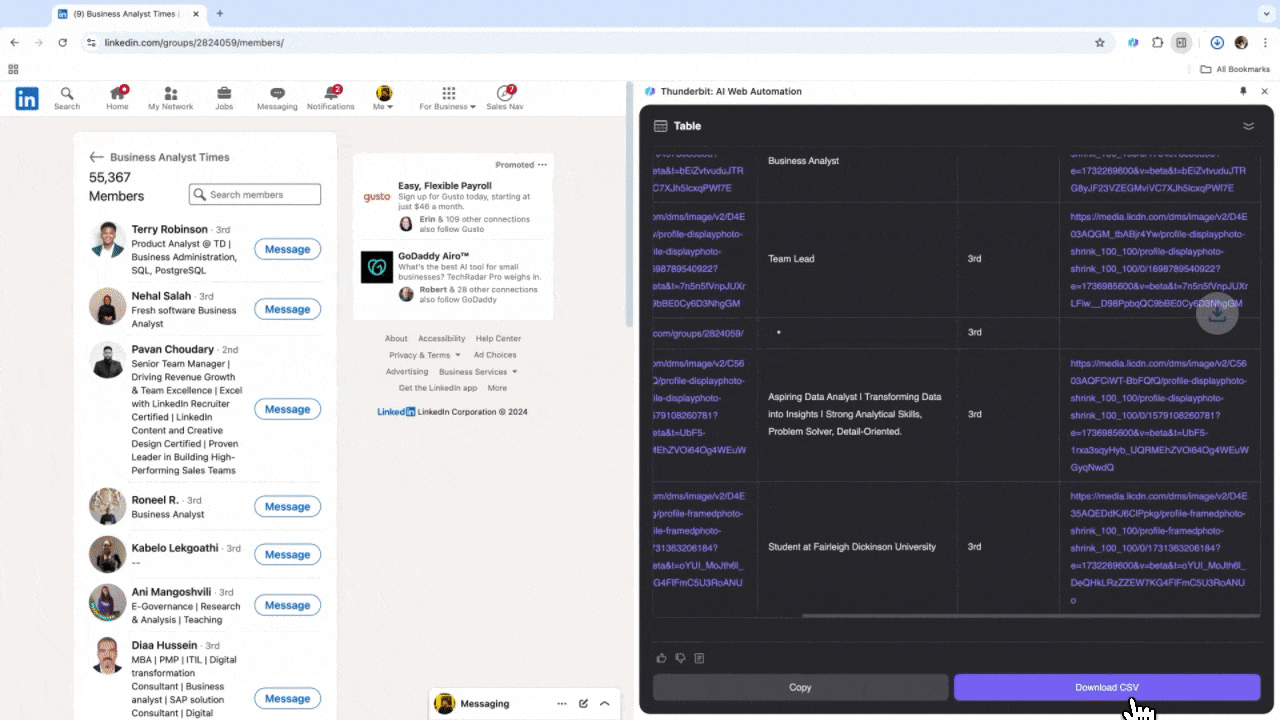
Scenario 3: Analisi di Mercato e Targeting Clienti
Se sei un imprenditore che raccoglie dati geolocalizzati per analisi di mercato, o un commerciale in cerca di nuovi clienti locali, un estrattore web affidabile può rivoluzionare il tuo lavoro. Thunderbit ti permette di estrarre facilmente dati chiave da Google Maps, aiutandoti a prendere decisioni informate e ottimizzare la tua strategia.
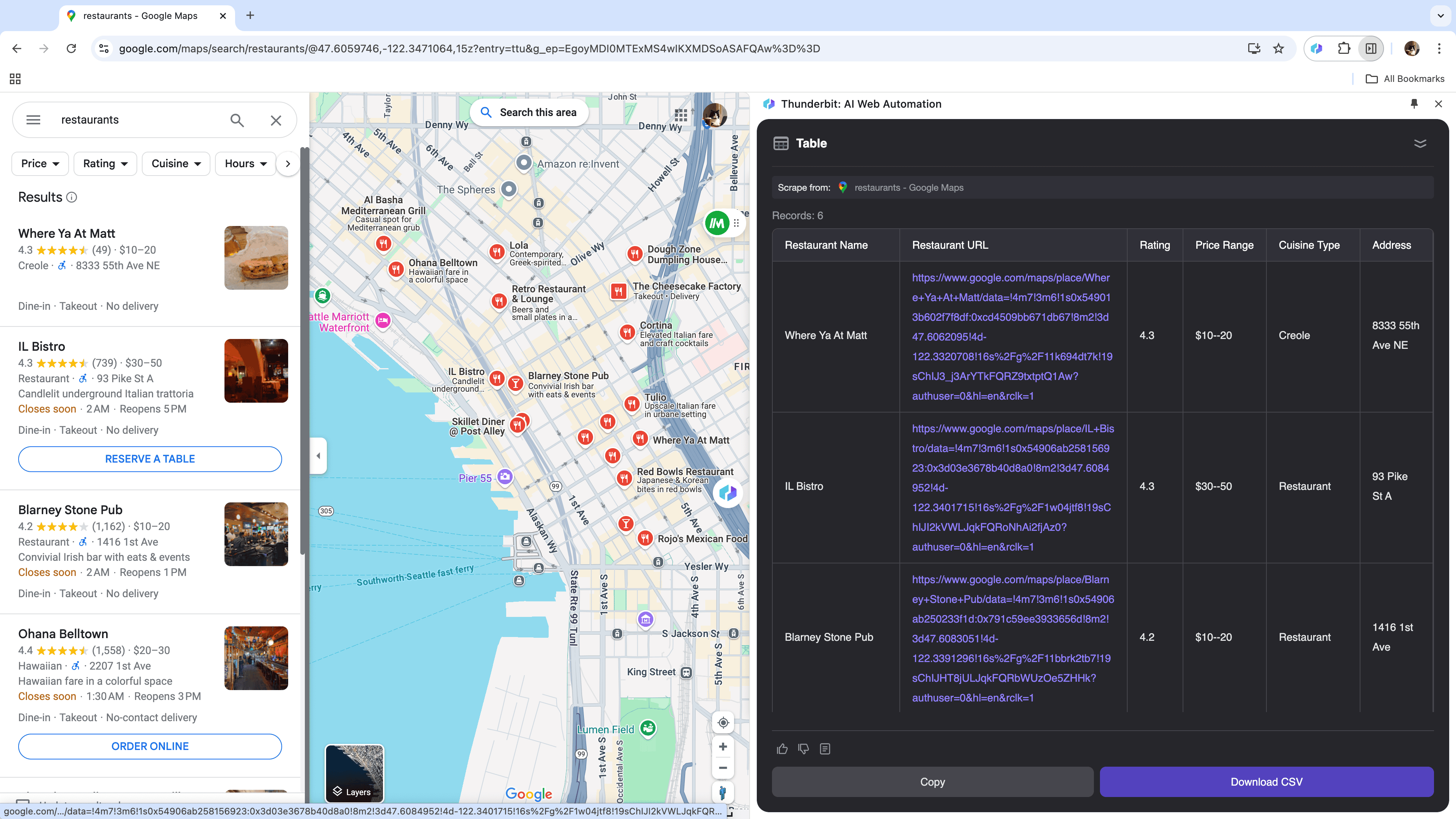
Scenario 4: Analisi Dati E-commerce
Se vendi online e vuoi monitorare la concorrenza o seguire le tendenze di mercato, Thunderbit è lo strumento che fa per te! Puoi raccogliere facilmente dati su prodotti da Amazon, incluse descrizioni dettagliate, prezzi e recensioni utenti.
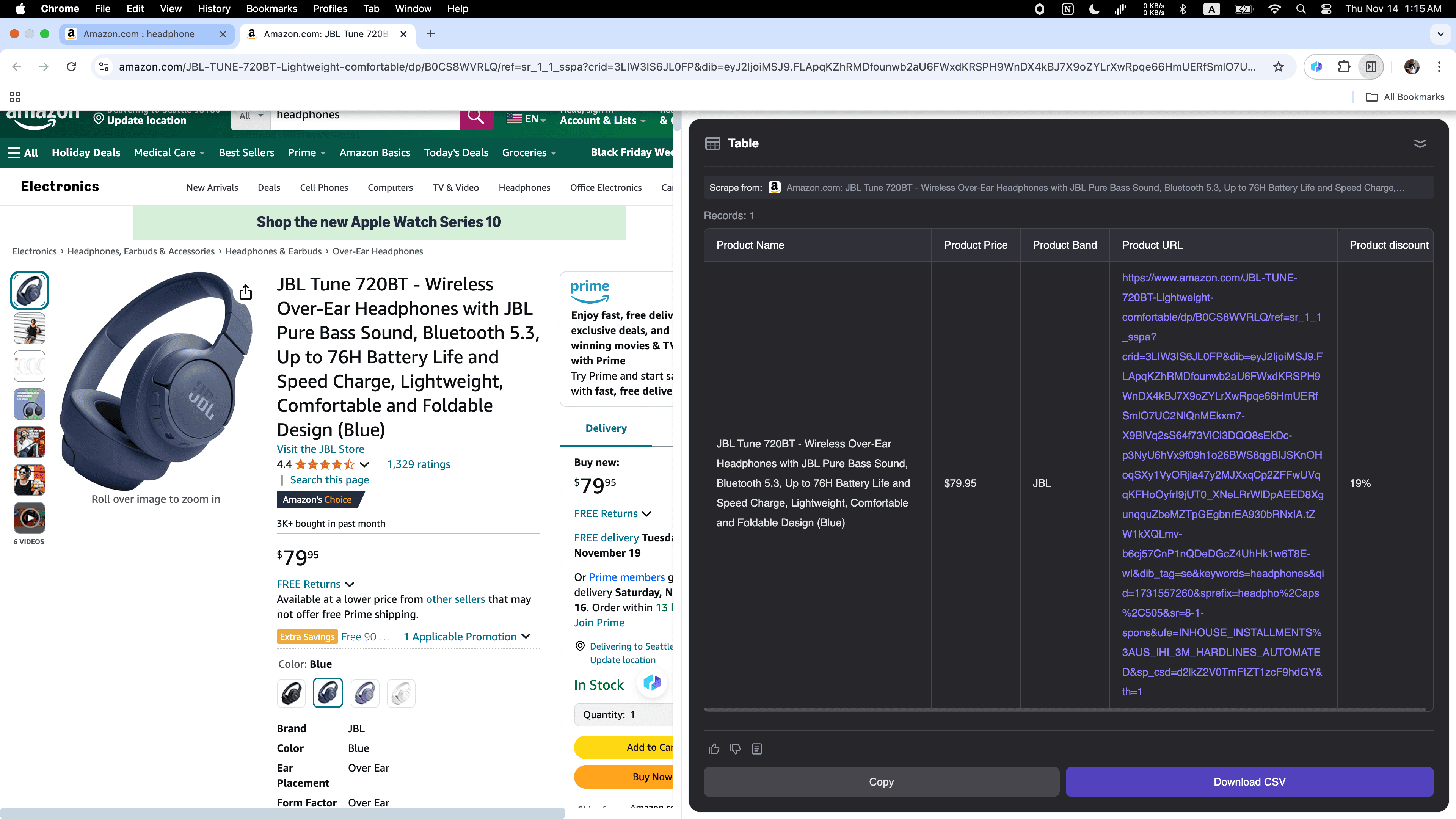
Thunderbit Estrattore Web AI rivoluziona la raccolta dati per le aziende, rendendola più veloce, semplice ed efficiente che mai. Che tu stia cercando immobili, nuovi clienti o analizzando il mercato e-commerce, gli estrattori web AI ti fanno risparmiare tempo e fatica. Sfrutta la potenza dell’AI nel web scraping e porta la tua produttività a un nuovo livello. Pronto a iniziare? Prova Thunderbit e scopri un nuovo modo di lavorare con i dati.
Consigli Esclusivi per la Pulizia dei Dati
Con gli estrattori tradizionali, la vera fatica arriva dopo: la pulizia dei dati. L’AI di Thunderbit può occuparsi della pulizia già durante lo scraping, grazie ai LLM, riducendo l’impegno dell’83% grazie a queste funzioni innovative:
Consiglio 1: Allineamento Intelligente dei Campi
Quando raccogli dati diversi da più fonti (ad esempio LinkedIn e Zillow insieme), l’AI di Thunderbit crea mappature semantiche in automatico:
- Riconosce i campi corrispondenti tra fonti diverse (es. "price" ↔ "prezzo" ↔ "Price")
- Unisce in modo intelligente campi simili (es. "area" e "superficie")
- Standardizza i dati tra piattaforme (es. "posizione attuale" di LinkedIn e "stato immobile" di Zillow unificati come tag)
Consiglio 2: Completamento Contestuale
Grazie alla comprensione contestuale dei LLM, Thunderbit raggiunge un tasso di completamento dati del 99%:
- Completamento indirizzi: Compila automaticamente città e stato partendo dal CAP (es. 10001 → New York City, NY)
- Inferenza percorso professionale: Prevede possibili esperienze lavorative in base al percorso di studi su LinkedIn
Consiglio 3: Ottimizzazione dei Dati
- Traduzione multilingue (supporta 12 lingue in tempo reale, tra cui inglese, cinese e giapponese)
- Sintesi intelligente (riassume una descrizione prodotto di 500 parole in tre punti chiave)
- Unificazione delle unità di misura (conversione automatica piedi quadrati ↔ metri quadrati, Fahrenheit ↔ Celsius)
- Standardizzazione dei formati (date in formato YYYY-MM-DD, valuta in USD)
Consiglio 4: Verifica della Qualità
- Correzione automatica degli errori: Sistema automaticamente errori di formato (es. numero di telefono +01 138-1234-5678 → +113812345678)
- Validazione logica: Verifica che "anno di costruzione" sia precedente a "ultima ristrutturazione"
Consiglio 5: Tagging Intelligente AI
Genera automaticamente tag intelligenti tramite NLP:
- Tag di sentiment analysis (classifica automaticamente le recensioni come positive/negative/neutre)
- Tag di valore commerciale (es. "clienti ad alto potenziale"/"immobili da seguire")
- Tag di settore (classifica i profili LinkedIn come "tech|finanza|sanità")
Le Sfide del Data Scraping
Nonostante i grandi vantaggi, il data scraping presenta anche delle sfide. Le questioni legali sono fondamentali: regolamenti come GDPR e CCPA impongono regole severe sulla raccolta dati, richiedendo attenzione e conformità alle normative sulla privacy. Inoltre, molti siti usano sistemi di difesa avanzati come Cloudflare per bloccare le attività di scraping tramite restrizioni IP.
Il Futuro del Data Scraping nell’Era dell’AI
L’evoluzione dell’AI sta trasformando il web scraping in una soluzione aziendale intuitiva. Immagina di inserire semplicemente un dominio (es. zillow.com) e la tua richiesta (es. "estrai tutti gli annunci immobiliari a New York"), e vedere l’AI mappare automaticamente ogni dato rilevante – dai dettagli degli immobili alle tendenze di prezzo – senza configurazioni manuali. Questi sistemi intelligenti integreranno i dati estratti nei flussi di lavoro aziendali, ad esempio inserendo automaticamente i lead di LinkedIn nel CRM o inviando metriche e-commerce ai dashboard di analisi. Il riconoscimento avanzato dei pattern permetterà uno scraping predittivo, monitorando in anticipo cambi di inventario o nuove tendenze di mercato. L’AI gestirà anche la compliance in tempo reale, adattando i parametri di scraping alle normative in evoluzione e mantenendo tracce di audit trasparenti.
Questo cambio di paradigma guidato dall’AI non solo democratizza l’accesso all’intelligence aziendale, ma ridefinisce il modo in cui le organizzazioni interagiscono con i dati web. Chi adotta per primo soluzioni di scraping AI come Thunderbit avrà un vantaggio competitivo decisivo nelle decisioni data-driven.
Domande Frequenti
-
Cos’è Thunderbit? Thunderbit è un’estensione browser intelligente basata su LLM, pensata per la raccolta dati moderna. Offre estrazione web AI e gestione multimodale dei dati, supportando l’estrazione completa da pagine dinamiche, PDF, immagini e video. Come soluzione locale, gestisce direttamente pagine che richiedono login (come LinkedIn) e si adatta automaticamente ai cambiamenti dei framework front-end.
-
Come funziona l’estrattore web AI di Thunderbit? L’estrattore web AI di Thunderbit usa l’AI per estrarre dati strutturati dai siti. Puoi cliccare su "AI Suggerisci Colonne" per far suggerire all’AI come estrarre i dati dal sito, poi su "Estrai" per raccogliere i dati. In due click puoi processare dati da qualsiasi sito, PDF o immagine.
-
Qual è la differenza tra scraping di liste e scraping di sottopagine? Lo scraping di liste è ottimizzato per scenari paginati (come le liste prodotti e-commerce), riconosce automaticamente la logica di paginazione ed estrae migliaia di dati. Lo scraping di sottopagine usa una struttura ad albero (es. annunci Zillow → pagine dettaglio → planimetrie), creando automaticamente relazioni tra tabelle principali e secondarie tramite associazione semantica.
-
Thunderbit è adatto anche a chi non programma? Thunderbit è pensato per l’interazione in linguaggio naturale: basta descrivere ciò che ti serve, come "nome, email, telefono", e il sistema genera automaticamente il piano di scraping. I nostri dati mostrano che l’85% degli utenti completa la prima raccolta dati in meno di 10 minuti, senza alcuna conoscenza di programmazione web.
-
Che tipi di dati può gestire Thunderbit? Thunderbit riconosce in modo intelligente molti tipi di dati:
- Dati strutturati: tabelle, liste (es. specifiche prodotto Amazon)
- Dati non strutturati: testi di recensioni, PDF (riconoscimento automatico)
- Dati multimodali: etichette prezzo in immagini, estrazione sottotitoli da video
- Dati dinamici: contenuti a scorrimento infinito, immagini caricate in lazy loading
- Dati correlati: mappatura di relazioni tra pagine (es. contatti LinkedIn → informazioni aziendali)
-
Come si inizia a usare Thunderbit? Scopri di più sulle nostre funzionalità di scraping o esplora la nostra libreria di template per iniziare subito.
Approfondisci: