Se ti sei mai chiesto come le aziende trasformano una montagna di dati grezzi e sparsi in dashboard eleganti e insight potenziati dall’AI, non sei il solo. Il segreto? Tutto parte dal data ingestion, l’eroe silenzioso che sta all’inizio di ogni processo aziendale basato sui dati. In un mondo in cui nel 2025 genereremo (cioè 21 zeri, se stai contando), portare i dati dal punto A al punto B — in modo rapido, preciso e in un formato utilizzabile — non è mai stato così importante.
Ho lavorato per anni nel SaaS e nell’automazione, e ho visto con i miei occhi come la giusta strategia di data ingestion possa fare la fortuna o il fallimento di un business. Che tu stia gestendo lead commerciali, monitorando i trend di mercato o semplicemente cercando di far funzionare le operazioni senza intoppi, capire come funziona il data ingestion (e come sta evolvendo) è il primo passo per sbloccare un vero valore di business. Quindi andiamo al punto: che cos’è il data ingestion, perché è così importante e in che modo strumenti moderni come stanno cambiando le regole del gioco per tutti, dagli analisti agli imprenditori?
Che cos’è il Data Ingestion? La base del business guidato dai dati
Alla base, data ingestion è il processo di raccolta, importazione e caricamento dei dati da più sorgenti in un sistema centrale — come un database, un data warehouse o un data lake — così da poterli analizzare, visualizzare o usare per prendere decisioni aziendali. Pensalo come la “porta d’ingresso” della tua pipeline dati: è il modo in cui porti tutti quegli ingredienti grezzi (fogli di calcolo, API, log, pagine web, flussi da sensori) in cucina prima di iniziare a preparare insight.
Il data ingestion è la primissima fase di qualsiasi pipeline dati (), perché abbatte i silos e assicura che dati di alta qualità e aggiornati siano disponibili per analytics, business intelligence e machine learning. Senza di esso, le tue informazioni preziose restano intrappolate in sistemi isolati — “invisibili per chi ne ha bisogno”, come ha detto un esperto del settore.
Ecco come si inserisce nel quadro generale:
- Data ingestion: raccoglie dati grezzi da varie sorgenti e li porta in un archivio centrale.
- Data integration: combina e allinea i dati provenienti da fonti diverse, facendoli lavorare insieme.
- Data transformation: pulisce, formatta e arricchisce i dati per prepararli all’analisi.
Pensa al data ingestion come al trasporto della spesa da diversi negozi a casa. L’integrazione è l’ordine che dai nella dispensa, mentre la trasformazione è la preparazione e la cottura del pasto.
Perché il Data Ingestion è importante per le organizzazioni moderne
Diciamolo chiaramente: nel business di oggi, dati tempestivi e ben ingestiti sono un asset strategico. Le aziende che padroneggiano il data ingestion possono abbattere i silos, ottenere insight in tempo reale e prendere decisioni più rapide e intelligenti. Al contrario, un ingestion fatto male significa report lenti, opportunità perse e decisioni basate su dati vecchi o incompleti.
Ecco alcuni modi concreti in cui un data ingestion efficiente crea valore per il business:
| Caso d’uso | Come aiuta un data ingestion efficiente |
|---|---|
| Generazione di lead commerciali | Consolida i lead provenienti da moduli web, social media e database in un unico sistema quasi in tempo reale, così i team di vendita possono rispondere più velocemente e aumentare i tassi di conversione. |
| Dashboard operative | Alimenta continuamente le piattaforme di analytics con dati dai sistemi di produzione, fornendo KPI aggiornati al management e consentendo azioni correttive rapide. |
| Vista cliente a 360° | Integra i dati dei clienti tra CRM, supporto, e-commerce e social media per creare profili unificati utili a marketing personalizzato e assistenza proattiva (Cake.ai). |
| Manutenzione predittiva | Ingestisce grandi volumi di dati da sensori e IoT, consentendo ai modelli di analytics di rilevare anomalie e prevedere i guasti prima che accadano, riducendo i fermi macchina e i costi. |
| Analytics del rischio finanziario | Trasmette i dati delle transazioni e i feed di mercato nei modelli di rischio, offrendo a banche e trader una visione in tempo reale delle esposizioni e consentendo il rilevamento immediato delle frodi. |
E i numeri non mentono: il , ma questi investimenti rendono davvero solo se i dati possono essere ingestiti e considerati affidabili.
Data Ingestion vs. Data Integration e Data Transformation: facciamo chiarezza
È facile perdersi nel gergo, quindi facciamo ordine:
- Data Ingestion: la fase iniziale di raccolta e importazione dei dati grezzi dai sistemi sorgente. In pratica: “portare tutto in cucina”.
- Data Integration: combinare e allineare dati provenienti da fonti diverse, garantendo coerenza e una visione unificata. In pratica: “organizzare la dispensa”.
- Data Transformation: convertire i dati da grezzi a utilizzabili — pulendoli, formattandoli, aggregandoli e arricchendoli. In pratica: “preparare e cucinare il pasto”.
Un malinteso comune è pensare che ingestion ed ETL (Extract, Transform, Load) siano la stessa cosa. In realtà, l’ingestion è solo la parte di “extract” — cioè il prelievo dei dati grezzi. Integrazione e trasformazione arrivano dopo, rendendo i dati pronti per l’analisi ().
Perché è importante? Se ti serve solo un dataset veloce da una pagina web, può bastarti uno strumento di ingestion leggero. Ma se devi unire e ripulire dati provenienti da cinque sistemi diversi, ti serviranno anche integrazione e trasformazione.
I metodi tradizionali di Data Ingestion: ETL e i suoi limiti
Per decenni, il metodo di riferimento per il data ingestion è stato l’ETL (Extract, Transform, Load). I data engineer scrivevano script o usavano software specializzati per prelevare periodicamente i dati dai sistemi sorgente, pulirli e formattarli, quindi caricarli in un data warehouse. Di solito tutto questo seguiva una cadenza batch — pensa ad aggiornamenti notturni.
Ma con l’esplosione di volume e varietà dei dati, l’ETL tradizionale ha iniziato a mostrare i suoi limiti:
- Configurazione complessa e lunga: costruire e mantenere pipeline ETL richiedeva molto codice e competenze specialistiche. I team non tecnici dovevano aspettare che l’IT sistemasse tutto ().
- Colli di bottiglia del batch processing: i job ETL lavoravano a blocchi, ritardando la disponibilità dei dati. In un mondo in cui gli insight immediati contano, aspettare ore o giorni semplicemente non basta ().
- Problemi di scalabilità e velocità: le pipeline legacy spesso faticavano a gestire i volumi enormi di oggi, richiedendo continue ottimizzazioni e aggiornamenti.
- Rigidità e scarsa flessibilità: aggiungere nuove sorgenti o cambiare gli schemi era complicato, spesso con il rischio di rompere la pipeline o dover rifare gran parte del lavoro.
- Manutenzione elevata: le pipeline potevano fallire per i motivi più diversi, richiedendo attenzione costante da parte degli engineer.
- Limitato ai dati strutturati: l’ETL classico era pensato per righe e colonne ordinate, non per i dati disordinati e non strutturati (come pagine web o immagini) che oggi rappresentano .
In breve: l’ETL era ottimo in un’epoca più semplice, ma oggi fatica a stare al passo con la velocità, la scala e la diversità dei dati moderni.
L’ascesa del Data Ingestion moderno: soluzioni automatizzate e guidate dall’AI
Ecco la nuova era: strumenti moderni di data ingestion che sfruttano automazione, scalabilità cloud e AI per rendere la raccolta dei dati più veloce, più semplice e più flessibile.
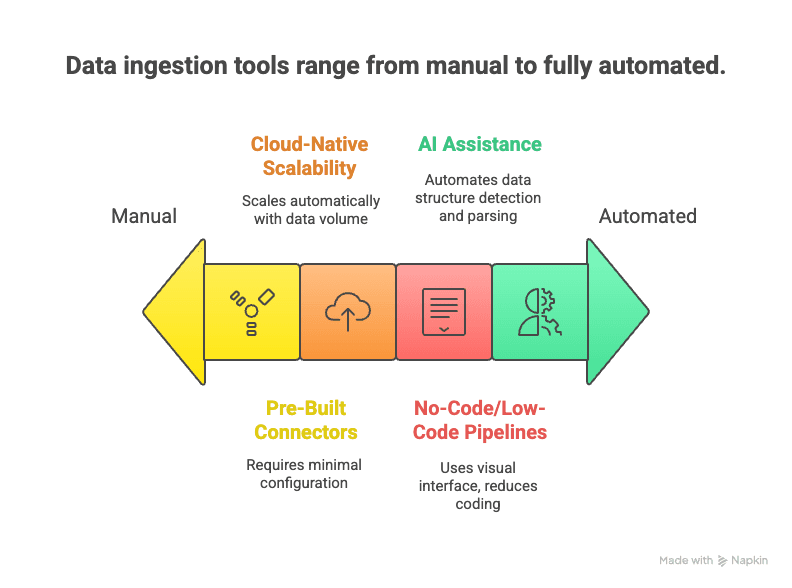
Ecco cosa li distingue:
- Pipeline no-code/low-code: interfacce drag-and-drop e assistenti AI permettono agli utenti di configurare i flussi di dati senza scrivere codice ().
- Connettori predefiniti: centinaia di connettori pronti all’uso per le sorgenti dati più diffuse — basta inserire le credenziali e via.
- Scalabilità cloud-native: i servizi cloud elastici possono gestire enormi flussi di dati in tempo reale ().
- Supporto real-time e streaming: gli strumenti moderni supportano sia ingestion in streaming sia batch, così puoi scegliere ciò che si adatta meglio alle tue esigenze ().
- Assistenza AI: l’AI può rilevare automaticamente la struttura dei dati, consigliare regole di parsing e persino eseguire controlli di qualità al volo ().
- Supporto per dati non strutturati: tecniche di NLP e computer vision possono trasformare pagine web, PDF o immagini disordinate in tabelle strutturate.
- Meno manutenzione: i servizi gestiti si occupano di monitoraggio, scalabilità e aggiornamenti, così puoi concentrarti sull’uso dei dati e non sul tenere in vita le pipeline.
Il risultato? Un data ingestion più rapido da configurare, più facile da modificare e capace di gestire l’attuale universo caotico dei dati.
Data Ingestion in azione: applicazioni di settore e sfide
Vediamo come il data ingestion si applica nel mondo reale — e quali sfide affrontano i diversi settori.
Retail ed e-commerce
I retailer ingestiscono dati da sistemi POS, store online, app fedeltà e persino sensori in negozio. Consolidando transazioni di vendita, clickstream dei siti web e log di inventario, possono ottenere una visione in tempo reale dei livelli di stock e dei trend di acquisto. La sfida? Gestire volumi elevati e dati veloci, soprattutto nei periodi di picco, e integrare le informazioni tra canali online e offline.
Finanza e banking
Banche e società di trading ingestiscono flussi di dati da transazioni, market feed e interazioni con i clienti. L’ingestion in tempo reale è fondamentale per il rilevamento delle frodi e la gestione del rischio. Ma con requisiti rigorosi di compliance e sicurezza, qualsiasi problema nel processo di ingestion può avere conseguenze serie.
Aziende tecnologiche e Internet
I giganti tech ingestiscono enormi flussi di eventi in tempo reale — ogni click, like o condivisione — per analizzare il comportamento degli utenti e alimentare i motori di raccomandazione. La scala è enorme, e la sfida consiste nel separare il segnale dal rumore, garantendo qualità e coerenza dei dati.
Sanità
Gli ospedali ingestiscono dati da cartelle cliniche elettroniche, sistemi di laboratorio e dispositivi medici per creare cartelle paziente unificate e abilitare analytics predittivi. I principali ostacoli? Interoperabilità (sistemi diversi che parlano “lingue” diverse) e privacy del paziente.
Real estate
Le società immobiliari ingestiscono dati da servizi di annunci, siti di property e registri pubblici per costruire database completi. La sfida è unire dati provenienti da fonti diverse — spesso non strutturate — e mantenerli aggiornati mentre gli annunci cambiano rapidamente.
Le sfide comuni a tutti i settori includono:
- Gestire la varietà dei dati (strutturati, semi-strutturati, non strutturati)
- Bilanciare esigenze real-time e batch
- Garantire qualità e coerenza dei dati
- Rispettare requisiti di sicurezza e compliance
- Scalare per gestire volumi di dati in crescita
Superare queste sfide è fondamentale per ottenere risultati di business migliori — analisi più accurate, decisioni in tempo reale e una compliance più solida.
Thunderbit: semplificare il Data Ingestion con l’AI Web Scraper
Ora parliamo di dove si colloca Thunderbit in questo quadro. è un’estensione Chrome con AI web scraper progettata per rendere il data ingestion dal web accessibile a tutti — anche se non sai nemmeno una riga di codice.
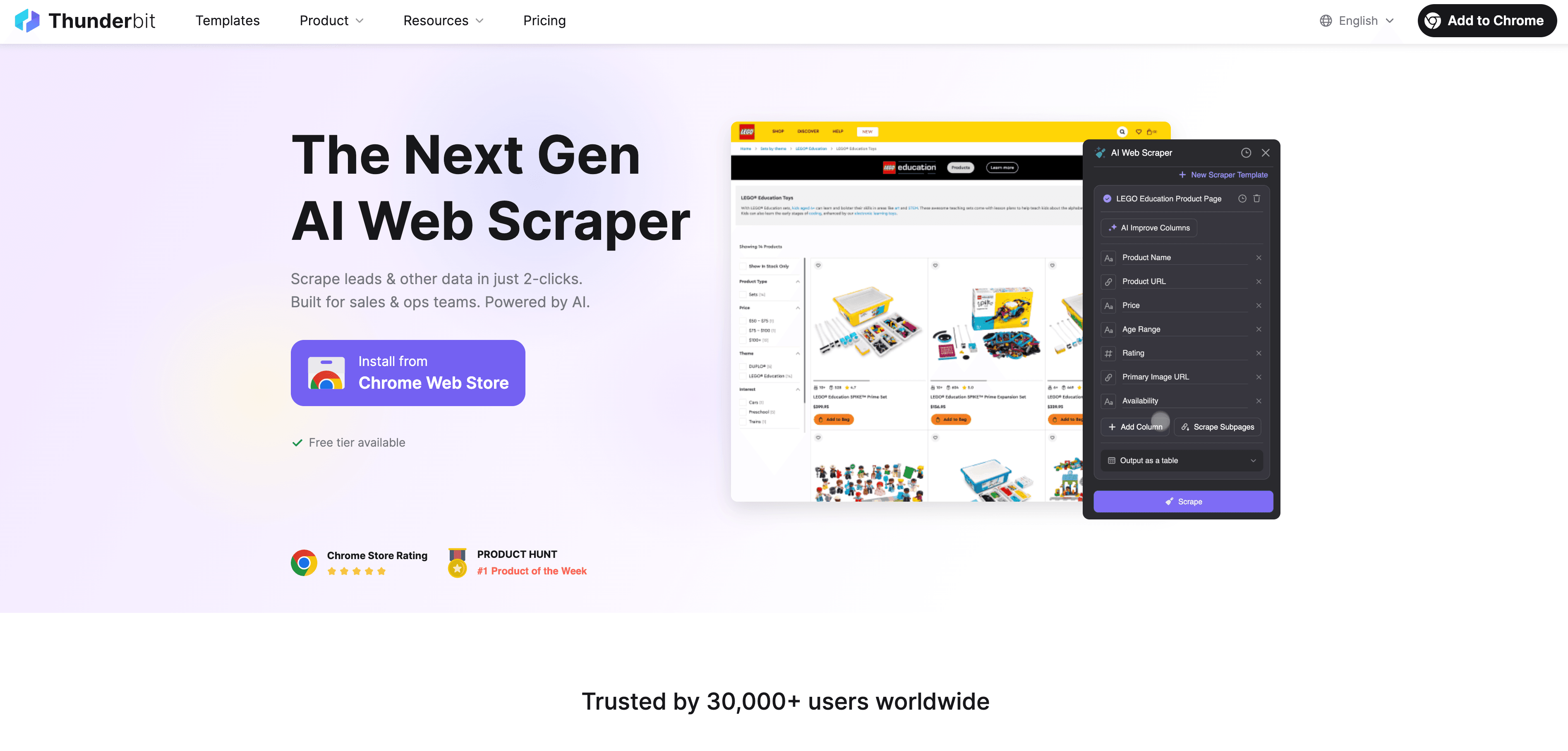
Ecco perché Thunderbit è una svolta per gli utenti business:
- Web scraping in 2 clic: passi da una pagina web disordinata a un dataset strutturato in due clic. Premi “AI Suggest Fields”, poi “Scrape” — e hai finito.
- Suggerimenti AI per i campi: l’AI di Thunderbit legge la pagina e ti consiglia le colonne migliori da estrarre, che tu stia guardando una directory aziendale, un elenco prodotti o un profilo LinkedIn.
- Scraping automatico delle sottopagine: ti servono più dettagli? Thunderbit può visitare ogni sottopagina (come schede prodotto o profili singoli) e arricchire automaticamente la tua tabella.
- Gestione della paginazione: riesce a gestire elenchi paginati e pagine con scroll infinito, così non perdi nessun dato.
- Template predefiniti: per siti popolari come Amazon, Zillow o Shopify, Thunderbit offre template in 1 clic — senza alcuna configurazione.
- Esportazione dati gratuita: esporta i dati direttamente in Excel, Google Sheets, Airtable o Notion, senza costi aggiuntivi.
- Scraping programmato: imposta job di scraping che si eseguono automaticamente a intervalli scelti (per esempio, controlli quotidiani sui prezzi dei concorrenti).
- AI Autofill: automatizza anche la compilazione dei moduli e altre attività web ripetitive.
Thunderbit è perfetto per i team sales che estraggono lead, per gli analisti ecommerce che monitorano i prezzi o per gli agenti immobiliari che raccolgono annunci di proprietà. L’obiettivo è trasformare rapidamente dati web non strutturati in insight azionabili.
Se vuoi vedere Thunderbit all’opera, guarda il nostro o esplora il nostro per altre guide.
Confronto tra soluzioni di Data Ingestion: approcci tradizionali vs moderni
Ecco un rapido confronto fianco a fianco:
| Criterio | Strumenti ETL tradizionali | Strumenti moderni AI/Cloud | Thunderbit (AI Web Scraper) |
|---|---|---|---|
| Competenze richieste | Alte (serve codice/IT) | Medie (low-code, un po’ di configurazione) | Basse (2 clic, nessun codice necessario) |
| Sorgenti dati | Strutturate (database, CSV) | Ampie (database, SaaS, API) | Qualsiasi sito web, dati non strutturati |
| Velocità di implementazione | Lenta (settimane/mesi) | Più rapida (giorni) | Istantanea (minuti) |
| Supporto real-time | Limitato (batch) | Forte (streaming/batch) | Su richiesta e programmato |
| Scalabilità | Difficile | Alta (cloud-native) | Media/Alta (cloud scraping) |
| Manutenzione | Elevata (pipeline fragili) | Media (servizi gestiti) | Bassa (l’AI si adatta ai cambiamenti) |
| Trasformazione | Rigida, a monte | Flessibile, dopo il caricamento | Base (prompt AI per i campi) |
| Caso d’uso migliore | Integrazione batch interna | Pipeline di analytics | Dati web, fonti esterne |
La conclusione? Scegli lo strumento in base al lavoro da fare. Per dati web o fonti non strutturate, Thunderbit è spesso l’opzione più veloce e semplice.
Il futuro del Data Ingestion: automazione e strategie cloud-first
Guardando avanti, il data ingestion sta diventando sempre più intelligente e automatizzato. Ecco cosa ci aspetta:
- Real-time come default: il vecchio paradigma batch sta scomparendo. Sempre più pipeline vengono progettate per dati in tempo reale e guidati da eventi ().
- Cloud-first e “Zero ETL”: le piattaforme cloud rendono più facile collegare sorgenti e destinazioni senza pipeline manuali.
- Automazione guidata dall’AI: il machine learning avrà un ruolo sempre più importante nella configurazione, nel monitoraggio e nell’ottimizzazione delle pipeline — individuando anomalie, correggendo errori e persino arricchendo i dati al volo.
- No-code e self-service: sempre più strumenti permetteranno ai business user di configurare i flussi di dati con il linguaggio naturale o con interfacce visuali.
- Ingestion edge e IoT: con la crescita dei dati generati all’edge, l’ingestion avverrà più vicino alla sorgente, con filtri e aggregazioni intelligenti.
- Governance e metadati: tagging automatico, tracciamento della lineage e compliance saranno integrati in ogni fase.
In sintesi: il futuro consiste nel rendere il data ingestion più veloce, più accessibile e più affidabile, così tu possa concentrarti sugli insight e non sull’infrastruttura.
Conclusione: i punti chiave per i business user
- Il data ingestion è il primo passaggio critico in qualsiasi iniziativa basata sui dati. Se vuoi insight, devi far entrare i dati — in modo rapido e affidabile.
- Strumenti moderni basati sull’AI come Thunderbit rendono il data ingestion accessibile a tutti, non solo ai professionisti IT. Con scraping in 2 clic, suggerimenti AI per i campi e job programmati, puoi trasformare dati web disordinati in vero valore per il business.
- Scegliere lo strumento giusto conta: usa l’ETL tradizionale per dati interni strutturati e stabili; strumenti cloud moderni per analytics ampi; e Thunderbit per dati web e non strutturati.
- Resta al passo con i tempi: automazione, cloud e AI stanno rendendo il data ingestion più intelligente e più semplice. Non restare fermo al passato: esplora nuove soluzioni e rendi la tua strategia dati a prova di futuro.
FAQ
1. Che cos’è il data ingestion, in parole semplici?
Il data ingestion è il processo di raccolta e importazione dei dati da varie sorgenti (come siti web, database o file) in un sistema centrale, così da poterli analizzare o usare per prendere decisioni aziendali. È il primissimo passo di qualsiasi pipeline dati.
2. In cosa il data ingestion è diverso da data integration e transformation?
Il data ingestion riguarda l’immissione dei dati grezzi. Il data integration combina e allinea i dati provenienti da fonti diverse, mentre il data transformation li pulisce e li formatta per l’analisi. In breve: ingestion = raccogliere, integration = organizzare, transformation = preparare e cucinare.
3. Quali sono le sfide più grandi dei metodi tradizionali di data ingestion?
I metodi tradizionali come l’ETL sono lenti da configurare, richiedono molto codice, faticano con i dati non strutturati e non riescono a stare al passo con le esigenze real-time di oggi. Inoltre, richiedono molta manutenzione e sono poco flessibili quando le sorgenti dati cambiano.
4. In che modo Thunderbit rende il data ingestion più semplice?
Thunderbit usa l’AI per permettere a chiunque di estrarre e strutturare dati web in soli due clic, senza bisogno di codice. Può gestire sottopagine, paginazione e persino programmare job ricorrenti, esportando direttamente in Excel, Google Sheets, Airtable o Notion.
5. Qual è il futuro del data ingestion?
Il futuro ruota attorno ad automazione, strategie cloud-first e pipeline guidate dall’AI. Aspettati più flussi di dati in tempo reale, una gestione più intelligente degli errori e strumenti che permettono ai business user di configurare il data ingestion con linguaggio naturale o interfacce visuali.
Scopri di più: