
Diciamolo senza troppi giri di parole: il web è una vera e propria giungla che cresce a vista d’occhio. Ogni giorno spuntano oltre 252.000 nuovi siti web e solo l’indice di Google contiene più di 30 miliardi di pagine. Se ti sei mai domandato come fanno i motori di ricerca a stare dietro a tutto questo – o come le aziende riescano a pescare informazioni utili in questo mare di dati – sappi che non sei l’unico. Dopo anni nel mondo SaaS e dell’automazione, la domanda che mi fanno più spesso è: “Ma web crawling e web scraping non sono la stessa cosa?” Spoiler: sono due mondi diversi, e confonderli può farti perdere tempo e risorse.
Che tu sia un commerciale a caccia di nuovi lead, un responsabile e-commerce che tiene d’occhio i prezzi, o semplicemente vuoi fare bella figura in riunione, vediamo insieme cosa fa davvero un web crawler, in cosa si distingue da uno scraper e perché scegliere lo strumento giusto (come Thunderbit) può evitarti un sacco di grane – e magari anche salvarti il weekend.
Web Crawler: le Basi – Cos’è un Web Crawler?

Immagina il bibliotecario più pignolo che tu abbia mai visto, che non solo sistema i libri, ma ogni giorno passa in rassegna ogni scaffale per vedere se c’è qualcosa di nuovo. Ecco, un web crawler fa proprio questo: solo che invece dei libri, esplora miliardi di pagine web. Un web crawler (detto anche spider o bot) è un programma automatico che naviga il web in modo sistematico, seguendo i link da una pagina all’altra e catalogando tutto quello che trova. È così che motori di ricerca come Google e Bing costruiscono i loro enormi indici, rendendo il web consultabile per tutti noi.
Se hai mai sentito nominare “Googlebot” o “Bingbot”, sono proprio loro i crawler più famosi che lavorano dietro le quinte. Esistono anche strumenti più moderni come Firecrawl, che permettono a sviluppatori e aziende di esplorare interi siti e trasformarli in dati strutturati per l’AI o per analisi.
Ma attenzione: il crawling serve alla scoperta – cioè trovare e indicizzare pagine, non estrarre dati specifici. Qui entra in gioco il web scraping (ne parliamo tra poco).
Come Funziona il Web Crawling?
Facciamo un viaggio nella giornata tipo di un web crawler. Immaginalo come un esploratore digitale con uno zaino pieno di “seed URL”, cioè i punti di partenza. Ecco come si muove:
- Seed URLs: Il crawler parte da una lista di indirizzi web già noti.
- Fetch & Parse: Visita ogni URL, scarica la pagina e cerca nuovi link.
- Segui i Link: Ogni nuovo link trovato viene aggiunto alla lista delle cose da visitare (la famosa “frontiera” degli URL).
- Indicizzazione: Durante il percorso, il crawler memorizza informazioni su ogni pagina – a volte tutto il contenuto, a volte solo i metadati.
- Rispetto delle regole: Controlla il file robots.txt di ogni sito per vedere se può procedere e fa delle pause tra una richiesta e l’altra per non stressare i server.
- Aggiornamento continuo: Visto che il web cambia di continuo, i crawler tornano periodicamente sulle pagine per tenere l’indice sempre aggiornato.
È un po’ come mappare una città camminando in ogni strada, segnando ogni nuovo vicolo e negozio, e aggiornando la mappa ogni volta che qualcosa cambia.
Componenti Chiave di un Web Crawler
Anche se non sei un tecnico, è utile sapere cosa c’è “sotto il cofano”:
- URL Frontier (Coda): La lista principale degli URL da visitare.
- Fetcher/Downloader: La parte che scarica effettivamente la pagina web.
- Parser: Il “lettore” che estrae i link e, a volte, altre informazioni dalla pagina.
- Deduplicazione & Filtro URL: Evita che il crawler giri in tondo o visiti la stessa pagina più volte.
- Archivio/Indice Dati: Dove vengono conservati tutti i contenuti scoperti per usi futuri.
Pensa a una catena di montaggio: uno prende il giornale, un altro evidenzia i titoli, un altro ancora archivia i ritagli e qualcuno tiene traccia di quali giornali prendere dopo.
Come Fare Web Crawling su un Sito: Strumenti e Metodi
Se lavori in azienda, potresti pensare di costruire un crawler da zero. Il mio consiglio? Lascia perdere. A meno che tu non voglia creare il prossimo Google, ci sono già tanti strumenti che fanno il lavoro duro per te.
Strumenti di web crawling più usati:
- Scrapy: Open source, pensato per sviluppatori, ottimo per progetti di grandi dimensioni.
- Apache Nutch: Usato per l’indicizzazione di big data e la ricerca.
- Heritrix: Lo strumento dell’Internet Archive per l’archiviazione del web.
- Screaming Frog SEO Spider: Il preferito dagli esperti SEO per analizzare e controllare i siti.
- Firecrawl: Moderno, API-driven, permette di esplorare e trasformare interi siti in dati strutturati.
Attenzione: Molti di questi strumenti richiedono competenze tecniche. Anche i tool “no-code” possono avere una curva di apprendimento – tra selezione di elementi HTML, cambiamenti nei siti o gestione di contenuti dinamici. Se ti serve solo estrarre dati da poche pagine, probabilmente non hai bisogno di un crawler completo.
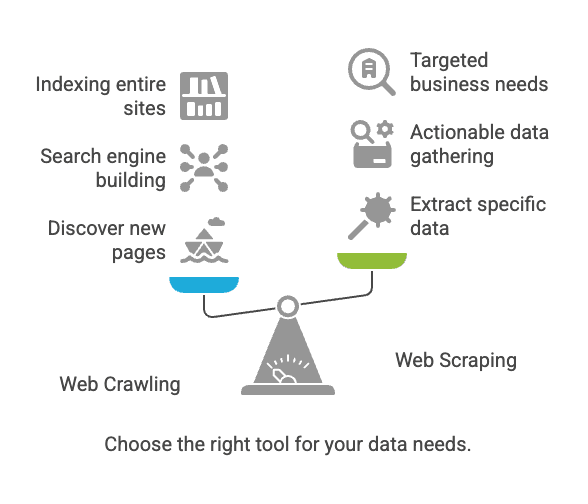
Web Crawling vs. Web Scraping: Qual è la Differenza?
Qui nasce spesso la confusione. Crawling e scraping sono collegati, ma non sono la stessa cosa.
| Aspetto | Web Crawling | Web Scraping |
|---|---|---|
| Obiettivo | Scoprire e indicizzare pagine web | Estrarre dati specifici dalle pagine |
| Analogia | Bibliotecario che cataloga ogni libro | Copiare le informazioni chiave da alcune pagine |
| Risultato | Elenco di URL, contenuti delle pagine, mappa del sito | Dati strutturati (CSV, Excel, JSON, ecc.) |
| Utilizzato da | Motori di ricerca, strumenti SEO, archiviatori | Vendite, e-commerce, analisti, ricercatori |
| Scala tipica | Miliardi di pagine (copertura ampia) | Decine/migliaia di pagine (mirato) |
In parole povere: Il crawling serve a trovare le pagine; lo scraping a prendere i dati che ti interessano (nimbleway.com).
Sfide Comuni e Best Practice nel Web Crawling e Scraping
Le difficoltà più frequenti
- Cambiamenti nella struttura dei siti: Anche una piccola modifica può mandare in tilt il tuo strumento (octoparse.com).
- Contenuti dinamici: Molti siti caricano dati tramite JavaScript, che i crawler base non vedono.
- Barriere anti-bot: CAPTCHAs, blocchi IP e login possono fermarti.
- Scalabilità: Esplorare migliaia di pagine può sovraccaricare il tuo computer (o farti bloccare l’IP).
- Aspetti legali/etici: Estrarre dati pubblici di solito è ok, ma controlla sempre termini e privacy del sito (web.instantapi.ai).
Best Practice
- Scegli lo strumento giusto: Se non sai programmare, parti da un estrattore web no-code.
- Definisci i tuoi obiettivi: Sii chiaro su quali dati ti servono e perché.
- Rispetta le regole dei siti: Controlla sempre
robots.txte i termini d’uso. - Non sovraccaricare i siti: Inserisci pause tra le richieste; non stressare i server.
- Prevedi manutenzione: I siti cambiano – aspettati di dover aggiornare la configurazione.
- Tieni i dati puliti e sicuri: Conserva i risultati in modo sicuro e controlla duplicati o errori.
Casi d’Uso Tipici: Crawling vs. Scraping
Web Crawling
- Indicizzazione per motori di ricerca: Googlebot e Bingbot esplorano il web per mantenere aggiornati i risultati (en.wikipedia.org).
- Archiviazione web: L’Internet Archive esplora i siti per la Wayback Machine.
- Audit SEO: Gli strumenti analizzano il tuo sito per trovare link rotti o tag mancanti.
Web Scraping
- Monitoraggio prezzi: I rivenditori estraggono i prezzi dei concorrenti dalle loro pagine prodotto (nextgeninvent.com).
- Lead generation: I team commerciali estraggono contatti da directory online.
- Aggregazione contenuti: Siti di news o annunci raccolgono dati da più fonti.
- Ricerche di mercato: Gli analisti estraggono recensioni o dati social per analisi di sentiment.
Curiosità: Oltre l’82% delle aziende e-commerce utilizza il web scraping per raccogliere dati esterni. Se non lo fai tu, probabilmente lo fanno i tuoi concorrenti.
Quando Usare Web Crawling e Quando Web Scraping?
Ecco una mini-checklist:
-
Devi scoprire nuove pagine o indicizzare un intero sito?
→ Usa il web crawling.
-
Sai già dove si trovano i dati che ti servono (pagine o sezioni specifiche)?
→ Usa il web scraping.
-
Stai costruendo un motore di ricerca o vuoi archiviare il web?
→ Il crawling è la scelta giusta.
-
Ti servono dati concreti per vendite, prezzi o analisi?
→ Lo scraping è la soluzione.
-
Non sei sicuro?
→ Parti dallo scraping. Nella maggior parte dei casi aziendali, il crawling completo non serve.
Se lavori in azienda, probabilmente ti serve lo scraping: dati mirati e strutturati, subito pronti all’uso.
Web Scraping per le Aziende: Il Vantaggio di Thunderbit
Vediamo ora perché la maggior parte degli utenti business – soprattutto chi non è tecnico – dovrebbe concentrarsi sullo scraping, e perché Thunderbit è pensato proprio per te.
Ho visto troppi team perdere giorni (o settimane) a lottare con strumenti di scraping “facili” che poi si rivelano complicati. Per questo abbiamo creato Thunderbit: per rendere l’estrazione dei dati dal web semplice come due clic.
Ecco cosa rende Thunderbit unico:
- Flusso in due clic: Premi “AI Suggerisci Campi”, poi “Estrai”. Tutto qui. Niente codice, niente selettori complicati.
- Supporto per URL e PDF multipli: Devi estrarre dati da una lista di URL o anche da PDF? Thunderbit lo fa senza problemi.
- Esporta ovunque: Invia i dati direttamente su Google Sheets, Airtable, Notion o scaricali in CSV/JSON. Nessun costo aggiuntivo.
- Scraping di sottopagine: Thunderbit può visitare automaticamente sottopagine (come dettagli prodotto) e arricchire la tua tabella dati.
- AI Autofill: Automatizza la compilazione di moduli e le attività ripetitive sul web – il tuo assistente digitale per le mansioni noiose.
- Estrattori Email & Telefono gratuiti: Raccogli tutti i contatti di una pagina con un solo clic.
- Scraping in cloud o da browser: Scegli la modalità che preferisci – Thunderbit può estrarre dati in cloud (velocissimo) o direttamente dal browser (ideale per pagine con login).
- Zero curva di apprendimento: Pensato per team di vendita, e-commerce e marketing che vogliono solo risultati.
Se vuoi approfondire, dai un’occhiata alle nostre guide su come estrarre prodotti Amazon, estrarre risultati di ricerca Google o importare dati web in Excel.
Estrai dati da qualsiasi sito con l’AI in 2 clic
Thunderbit vs. Estrattore Web Tradizionale
Ecco un confronto diretto per chi lavora in azienda:
| Funzionalità/Esigenza | Thunderbit | Estrattore Web Tradizionale (es. Scrapy, Nutch) |
|---|---|---|
| Configurazione | 2 clic, nessun codice | Setup tecnico, spesso richiede script |
| Curva di apprendimento | Minima | Ripida (soprattutto per chi non programma) |
| Gestione sottopagine | Automatica, guidata dall’AI | Script manuali o configurazioni avanzate |
| URL/PDF multipli | Supporto integrato | Di solito non supportato nativamente |
| Formati di output | Google Sheets, Airtable, Notion, CSV | CSV, JSON (integrazione spesso manuale) |
| Adattabilità | L’AI si adatta ai cambiamenti dei siti | Aggiornamenti manuali necessari |
| Casi d’uso aziendali | Vendite, e-commerce, SEO, operations | Indicizzazione motori di ricerca, ricerca, archiviazione |
| Pianificazione | Scheduling in linguaggio naturale | Cron job o scheduler esterni |
| Prezzo | Da 15$/mese, piano gratuito disponibile | Gratis/open source, ma costi di setup/manutenzione più alti |
| Supporto | UI moderna, pensata per l’utente | Community, orientato agli sviluppatori |
Thunderbit punta a portarti dal “mi serve questo dato” al “ecco il mio foglio di calcolo” nel minor tempo possibile – senza dover chiedere aiuto all’IT.
Conclusione: Scegliere l’Approccio Giusto per la Tua Azienda

Ricapitolando:
- Il web crawling serve a scoprire e indicizzare pagine – ideale per motori di ricerca e audit dei siti.
- Il web scraping serve a estrarre dati specifici e utili – perfetto per lead, monitoraggio prezzi o aggregazione contenuti.
- Per la maggior parte delle aziende, lo scraping è la soluzione. E non serve essere programmatori.
Il web diventa ogni giorno più grande e complesso. Ma con l’approccio e lo strumento giusto, puoi trasformare il caos in opportunità. Se sei stufo di strumenti complicati o di aspettare l’IT, prova Thunderbit: ti sorprenderà cosa puoi fare in due clic (e magari ti riprendi anche il weekend).
Vuoi vedere Thunderbit in azione? Scarica la nostra estensione Chrome o scopri altri consigli e guide sul Blog di Thunderbit.
Installa l’estensione Chrome di Thunderbit
Buon scraping (non crawling – a meno che tu non voglia costruire il prossimo Google)!
Domande Frequenti
1. Mi servono sia un web crawler che uno scraper per la mia azienda?
Non per forza. Se sai già quali pagine contengono i dati che ti servono, un estrattore web come Thunderbit è più che sufficiente. I crawler sono utili soprattutto quando devi scoprire nuove pagine – ad esempio per mappare un intero sito o fare audit SEO.
2. Il web scraping è legale?
In generale, estrarre dati pubblici è legale – soprattutto se non aggiri login, non violi i termini d’uso e non raccogli informazioni sensibili. Tuttavia, è sempre meglio controllare il file robots.txt e la privacy policy del sito, soprattutto per usi commerciali.
3. In cosa Thunderbit è diverso dagli altri strumenti di web scraping?
Thunderbit è pensato per chi lavora in azienda e non programma. A differenza degli scraper tradizionali che richiedono conoscenze HTML o configurazioni manuali, Thunderbit usa l’AI per identificare i campi, navigare tra le sottopagine e restituire i dati nel formato che ti serve – tutto in due clic.
4. Thunderbit gestisce siti dinamici e pagine con login?
Sì. Thunderbit offre scraping da browser per sessioni con login e contenuti dinamici, oltre allo scraping in cloud per velocità e scalabilità. Puoi scegliere la modalità migliore in base ai dati che ti servono.
Approfondimenti
- Cos’è il Data Scraping e come farlo nel 2025
- Quanti siti web esistono al mondo?
- Cos’è un web crawler? | Come funzionano i web spider | Cloudflare
Prova gratis l’Estrattore Web AI Get Started Free




